一、论文简述
1. 第一作者:Xiaofeng Wang
2. 发表年份:2022
3. 发表期刊:ECCV
4. 关键词:MVS、3D重建、Transformer、极线几何
5. 探索动机:融合多视图代价体很关键,现有的方法效率低,引入了太多额外的参数,并且只关注了图像局部相关性的信息,忽略了深度信息的关联。
存在问题:Fusing source volumes is an essential step in the whole pipeline and many MVS approaches put efforts into it. The core of the fusing step is to explore correlations between multi-view images. MVSNet follows the philosophy that various images contribute equally to the 3D cost volume, and utilizes variance operation to fuse different source volumes. However, such fusing method ignores various illumination and visibility conditions of different views.
一些解决办法:”To alleviate this problem, Transmvsnet、Patchmatchnet、CDS-MVSNet enrich 2D feature semnatics via Deformable Convolution Network (DCN) and PVA-MVSNet、Vis-MVSNet leverage extra networks to learn per-pixel weights as a guidance for fusing multi-view features.
这些办法的缺点:However, these methods introduce onerous network parameters and restrict efficiency. Besides, they only concentrate on 2D local similarities as a criteria for correlating multiple views, neglecting depth-wise 3D associations, which could lead to inconsistency in 3D space.
6. 工作目标:通过Transformer,从数据本身学习3D关系,而不引入额外的学习参数。探索一种有效的方法来建模3D空间关联融合源视图体。
we explore an efficient approach to model 3D spatial associations for fusing source volumes. Our intuition is to learn 3D relations from data itself, without introducing extra learning parameters. Recent success in attention mechanism prompts that Transformer is appropriate for modeling 3D associations. The key advantage of Transformer is it leverages cross-attention to build data-dependent correlations, introducing minimal learnable parameters. Besides, compared with CNN, Transformer has expanded receptive field, which is more adept at constructing long-range 3D relations.
7. 核心思想:
- We propose a novel end-to-end Transformer-based method for multi-view stereo, named MVSTER. It leverages the proposed epipolar Transformer to efficiently learn 3D associations along epipolar line.
- An auxiliary monocular depth estimator is utilized to guide the query feature to learn depth discriminative information during training, which enhances feature semantics yet brings no efficiency compromises.
- We formulate depth estimation as a depth-aware classification problem and solve it with the entropy-regularized optimal transport, which produces finer depth estimations propagated in the cascade structure.
8. 实验结果:
Compared with MVSNet and CasMVSNet, our method reduces 88% and 73% relative depth hypotheses, making 80% and 51% relative reduction in running time, yet obtaining 34% and 14% relative improvements on the DTU benchmark, respectively. Besides, our method ranks first among all published works on Tanks&Temples-Advanced.
9.论文&代码下载:
https://arxiv.org/pdf/2204.07346v1.pdf
https://github.com/JeffWang987/MVSTER
二、实现过程
1. MVSTER概述
MVSTER网络结构如图所示。给定参考图像及其对应的源图像,首先利用特征金字塔网络提取2D多尺度特征。然后将源图像特征变化到参考摄像机截锥,通过可微单应性构造源体。随后,利用极极Transformer聚合源体并产生代价体,辅助分支进行单目深度估计以增强上下文。该体由轻量级3D CNN正则化以进行深度估计管道进一步以级联结构构建,以粗到细的方式传播深度图。为了减少深度传播过程中的错误深度假设,将深度估计制定为深度感知分类问题,并使用最优传输对其进行优化。最后给出了网络损失。

2. 2D编码器和3D单应性
应用类似FPN的网络提取参考图像及其邻近的源图像多尺度2D特征。fpn,其中图像降尺度M次以构建深度特征Fk。尺度k = 0表示图像的原始大小。通过单应性变化得到N−1个源体{Vi}N−1∈H×W ×C×D,其中D是假设深度的总数。
3. 极线Transformer
极性Transformer从不同的视图聚合源体。极线Transformer利用参考特征作为query,沿着极线匹配源特征(key),从而增强相应的深度(value)。具体来说,通过单目深度估计的辅助任务来丰富参考query。随后,交叉注意力在极线约束下计算query和source体之间的关联,生成注意力引导以聚合来自不同视图的特征体。 然后,通过轻量级 3D CNN 对聚合特征进行正则化。下面,我们首先给出query构造的细节,然后详细说明对极线Transformer 引导的特征聚合。 最后给出了轻量级正则化策略。
查询构建。如前所述,我们将参考特征视为对极线transformer的query。 然而,由浅层 2D CNN 提取的特征在非朗伯和低纹理区域的判别性降低。 为了解决这个问题,一些方法利用代价较高的的DCN或 ASPP 来丰富特征。 相比之下,本文提出了一种更有效的方法来增强query:构建一个辅助单目深度估计分支来规范query并学习深度判别特征。 在辅助分支中应用了单目深度估计任务中使用的通用解码器。 给定通过 FPN 提取的多尺度参考特征,通过插值扩展低分辨率特征图,并将其与后续尺度特征连接。 聚合的特征图被输入回归头以进行单目深度估计:

其中Φ(⋅)是单目深度解码器,I(⋅)是插值函数,[⋅,⋅]表示连接操作。 随后,针对不同尺度的查询单目深度估计。 值得注意的是,这种辅助分支仅用于训练阶段,指导网络学习深度感知特征。
极线Transformer引导聚合。Pipeline如图 2(a) 所示,旨在构建查询特征的3D关联。 然而,深度方向的3D空间信息不是由2D查询特征图明确传递的,因此我们首先通过homography warping恢复深度信息。 将查询特征pr的假设深度位置投影到源图像极线上,得到源体特征psi,j,即极线 transformer的key。因此,沿极线的关键特征被用来构建查询特征的深度 3D 关联,这是通过交叉注意力操作实现的:

其中vi∈C×D为{psi,j}沿深度维叠加计算,te为温度参数,wi为查询与键的相关的注意力。在图2(b)中可视化一个真实图像的例子,其中注意力集中在极线上最匹配的位置。

(a)极线Transformer聚合。利用单应性变化恢复参考特征的深度信息,然后在极限约束下交叉注意计算查询与源体之间的3D关联,生成注意力引导以聚合不同视角的特征体。(b) DTU数据集上交叉注意力得分的可视化,其中极线上点的不透明度表示注意力得分。
计算出的query和keys之间的注意力wi用于聚合values。对于Transformer的value设计,使用分组相关,以有效的方式测量参考特征与源体之间的视觉相似性:

〈·,·〉是内积。沿着通道维度进行堆叠,得到si∈G×D,这是Transformer的value。最后,通过极线注意力得分wi聚合value,以确定最终的代价体:

总之,对于所提出的极线Transformer,首先利用可分离的单目深度估计分支来增强深度判别2D语义,然后利用查询和键之间的交叉注意力来构建深度方向的 3D 关联。 最后,结合2D和3D信息用作聚合不同视图的指导。极线Transformer被设计为一个高效的聚合模块,其中没有引入可学习的参数,并且极线Transformer只学习依赖数据的关联。
轻量级正则化。由于非朗伯表面或物体遮挡,原始代价体容易受到噪声污染。 为了平滑最终的深度图,使用3D CNN来对代价体积进行正则化。 考虑到已将3D关联嵌入到cost volume中,在3D CNN 中省略了深度特征编码,这使其更有效。 具体来说,将卷积核大小从3 × 3 × 3减小到3 × 3 × 1,仅沿特征宽度和高度聚合代价体。 正则化概率体P ∈ H × W × D。在每像素深度置信度预测中是非常理想的,被用来在级联结构中进行深度估计。
4. 级联深度图传播
MVSTER设置了四个阶段的管道,其中四个阶段的输入分辨率为H × W × 64,H/2×W/2×32, H/4 × W/4 ×16, H/8 × W/8 ×8。第一阶段采用深度逆采样初始化深度假设,相当于像素空间等距采样。为了实现由粗到细的深度图传播,每个阶段的深度假设都以前一阶段的深度预测为中心,在假设的深度范围内统一生成Dk个假设。
5. 损失
虽然级联结构受益于粗到细的管道,但它很难从前面阶段引入的错误中恢复过来。为了缓解这个问题,一个简单的方法是在每个阶段生成一个更精细的深度图,特别是避免预测深度远离真实值。然而,以往的方法简单地将深度估计视为一个多类分类问题,对每个假设深度一视同仁,没有考虑它们之间的距离关系。例如,在下图中,最左边的子数字是一个真实深度,情况1和情况2是两个预测深度分布,他们的交叉熵损失是相同的,说明交叉熵损失不知道每个假设深度之间的相对距离。但是,case 1的深度预测超出了有效范围,无法正常传播到下一阶段。

在本文中,深度预测被表述为深度感知分类问题,它强调了预测深度与真实距离的惩罚。具体来说,用现成的Wasserstein距离来测量预测分布Pi∈D与真实分布Pθ,i∈D之间的距离:

其中,inf表示极值,Π(Pi, Pθ,i)是边缘分布为Pi和Pθ,i的所有可能分布的集合。这样的公式是受最优传输问题的启发,该问题计算将Pi传输到的最小功Pθi,可以通过沉角算法差分求解。
综上所述,损失函数由两部分组成:测量预测深度分布与真实值之间距离的Wasserstein损失和优化单目深度估计的L1损失:

6. 实验
6.1. 数据集
DTU, Tanks&Temples, BlendedMVS,ETH3D
6.2. 实现细节
假设深度数{Dk}每段设为8、8、4、4。组相关{Gk}设置为8,8,4,4。我们使用PyTorch[21]实现,在4台NVIDIA RTX 3090上进行训练,每个GPU上批大小为2的GPU。使用AdamW优化器[19]。
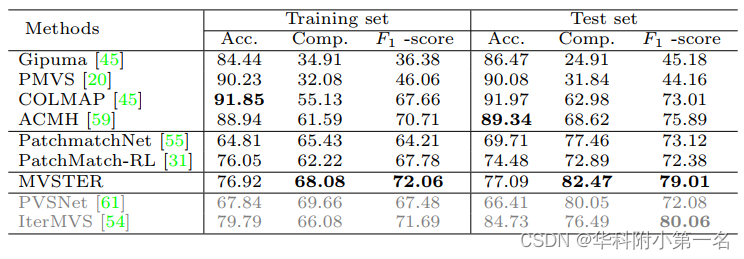
6.3. 与先进技术的比较

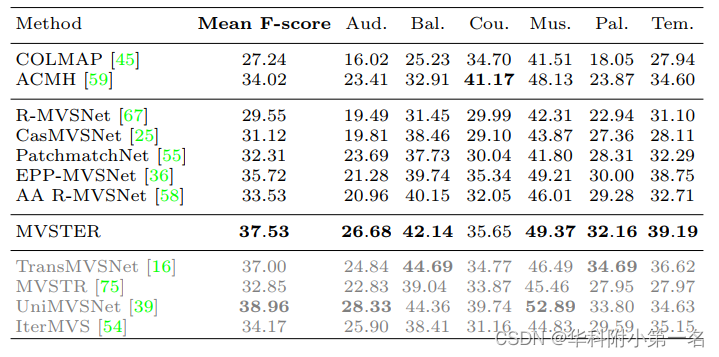
ETH3D