MySQL索引面试七连炮
- 0. 谈一下你对索引的理解
- 1. MySQL索引原理和数据结构能介绍一下吗
- 2. B+树和B树的区别
- 3. MySQL聚簇索引和非聚簇索引的区别
- 4. 使用MySQL索引都有什么原则
- 4.1 回表
- 4.2 索引覆盖
- 4.3 最左匹配
- 4.4 索引下推
- 5. 不同的存储引擎是如何进行数据的存储的
- 6. MySQL组合索引的结构是怎样的
- 7. MySQL索引是如何进行优化的
0. 谈一下你对索引的理解
首先。MySQL里面存的一些索引,索引的数据结构是通过B+树或者哈希表生成的。
存储引擎:
对于不同类型的索引,是与存储引擎相关的,如果你使用的是Myisam或者Innodb这样的存储引擎,那对应的数据类型就是B+树;如多使用的Memory这种存储引擎,那所使用的数据结构就是哈希表。不同的存储引擎表示的是不同的数据在磁盘上的组织形式。
为什么InnoDB和Myisam要使用B+树呢?
首先,我们得清楚,索引里面存储得是什么。一般情况下,索引里面存储的是Key,通过key去找到对应的value。对于这种key-value形式的数据,我们可以采用的数据结构有很多选择,比如:哈希表、二叉树、AVL树、B+树。
不管使用什么形式的二叉树,它最终都会导致树高度的增高,这就会使io的次数增多,使得整体的io访问的效率降低。而不使用哈希表是因为它不支持范围查找。
选择B+树这样的数据结构之后,他就会尽多的在一个数据节点里面存储数据,让树的高度变低,从而减少io的次数,提高数据访问的效率。
索引分类:
在MySQL里面有主键索引、唯一性索引、普通索引、组合索引、全文索引等各种索引。在日常的开发中,最常用到的可能就是主键索引和组合索引,在使用这两种索引的时候,会存在一系列问题,比如:回表、覆盖索引、最左匹配、索引下推。
在执行SQL语句的时候,可以通过索引的一些点来进行优化,提高我们对于数据的访问效率。
1. MySQL索引原理和数据结构能介绍一下吗
MySQL的索引底层使用B+树来进行数据的存储。
使用B+树的优点:
- B+树是一个多叉搜索树,可以进行数据的查找操作
- B+树的非叶子节点只存储Key值,这样就可以在一个数据节点里面存储更多的数据,从而降低树的高度,减少IO访问的次数,从而提高数据查询的效率。
- B+树的叶子节点存储数据的详细信息,每个数据在叶子节点上都有体现,并且这些叶子节点用链表的形式连接起来,从而支持范围查找。
2. B+树和B树的区别
我们先来看看两种数据结构的数据存储模型图:
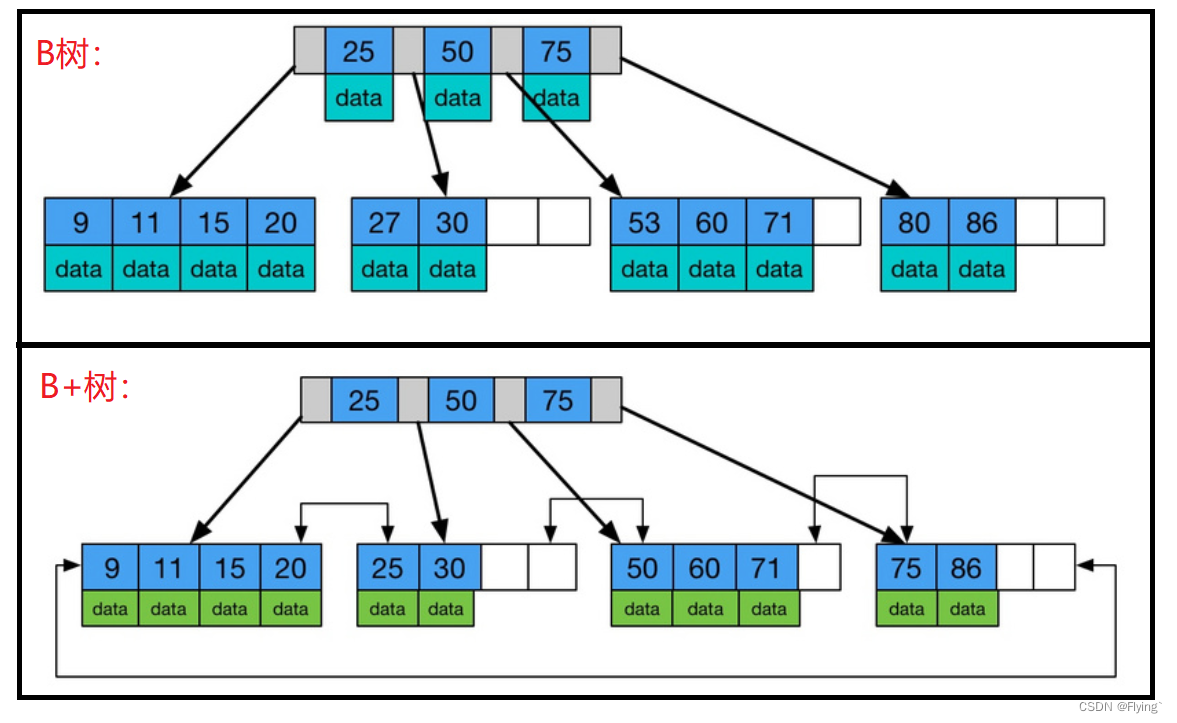
下面来总结一下两者的区别:
- B树的键值分布在整个树中;而B+只在叶子节点存储键值,非叶子节点只存储Key值
- B+树的叶子节点是以链表的形式进行存储,可以支持范围查询;而B树不行
- B+树的数据节点中只存储Key,而B树的数据节点中还存储data,这就意味着B+树单次磁盘 IO 的信息量大于B树,从这点来看B+树相对B-树磁盘 IO 次数少
3. MySQL聚簇索引和非聚簇索引的区别
想要理解聚簇索引和非聚簇索引的区别,那我们先来理解一下下面的这些东西:
对于InnoDB存储引擎,在插入数据的时候,数据必须和索引绑定到一起,索引可以是主键,可以是唯一性键,也可以是6字节的rowid。
在一个表中,可能有多个索引,但是数据只能有一份,不会造成文件的冗余。当数据跟某一个索引列绑定到一起的时候,其他的索引列应该如何检索数据呢?
方法是:将 已经跟数据绑定的索引列的值 放到其他索引的叶子节点。
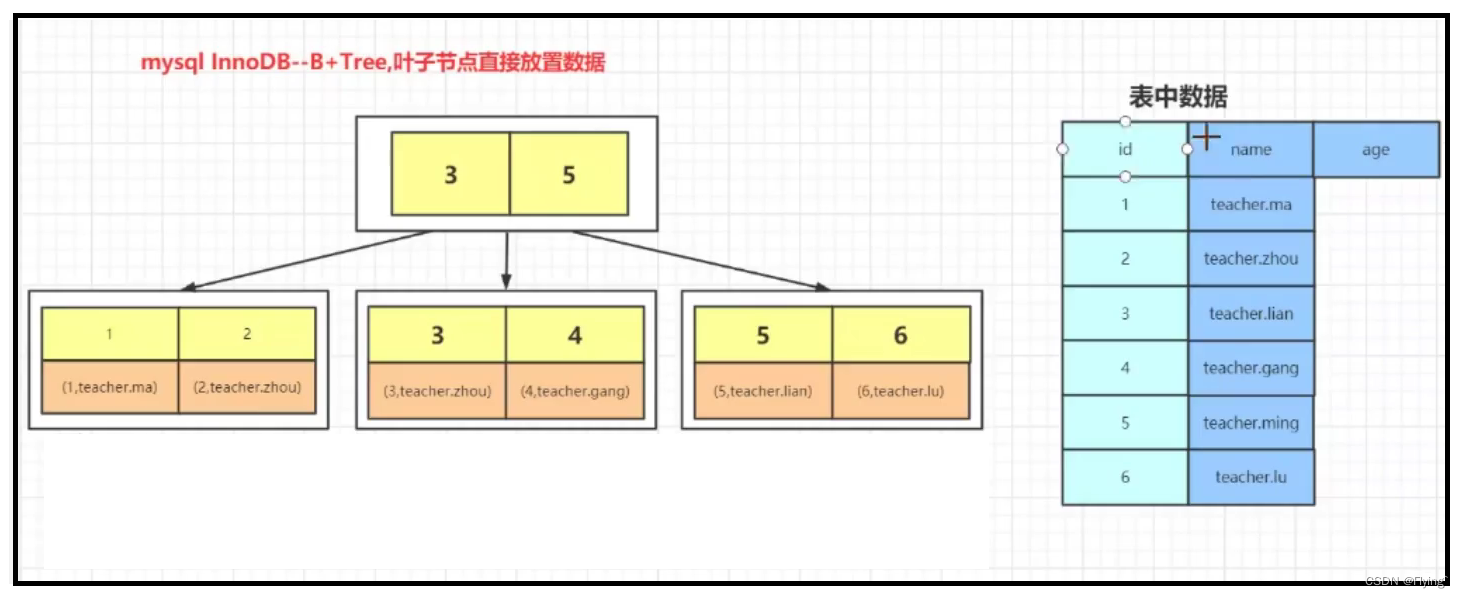
id为主键时,用主键建立的索引结构:
而id为主键时,以name建立的索引:
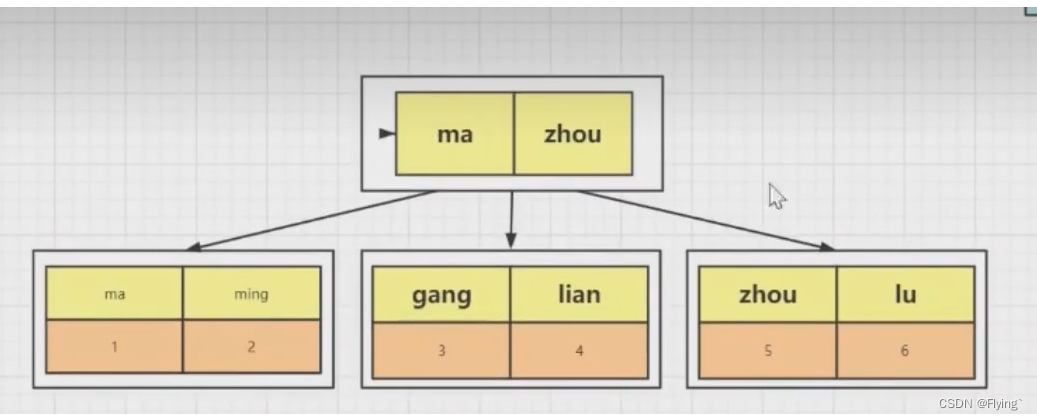
- InnoDB是通过B+树结构对主键创建索引,然后叶子节点存储记录,如果没有主键,就用唯一性键创建索引,如果没有唯一性键,就用6字节的row_id来作为主键创建索引。
- 如果创建索引的键是其他字段,那么在叶子节点存储的就是该记录的主键,然后再通过主键索引来找到对应的记录,这就做回表。
理解了上面这些,再来谈谈聚簇索引和非聚簇索引:
聚簇索引:索引跟数据放到一起,比如上面的 id
非聚簇索引:索引跟数据没有直接放到一起,需要通过回表才能查询到数据,比如上面的name
还有一个小知识:
- 在InnoDB存储引擎当中,既存在聚簇索引,也存在非聚簇索引。
- 在myisam存储引擎当中,只存在非聚簇索引,根本原因是:myisam存储引擎索引列单独是一个文件
4. 使用MySQL索引都有什么原则
4.1 回表
从某一个索引的叶子节点拿到聚簇索引的id值,然后再根据id值去聚簇索引里面找到对应的全量信息。设计回表查询的效率不高,一次回表使io次数翻倍,要尽量减少回表。
假设有一个表:id,name,age,gender四个列,id为主键,name为普通索引
当执行 select * from table where name = "zhangsan"时,它得先在name索引中找到主键id的值,然后再去id索引中查询全列信息。
4.2 索引覆盖
从索引的叶子节点中,能获取全量查询列的过程就叫做覆盖索引,覆盖索引不需要再回表。
假设有一个表:id,name,age,gender四个列,id为主键,name为普通索引
当执行 select id,name from table where name = "zhangsan"时,再name索引中,可以查到id,也可以查到name,此时就不需要再进行回表。
4.3 最左匹配
对于组合索引,要遵循最左匹配原则,即:索引的匹配顺序必须是从左向右。
假设有一个表:id,name,age,gender四个列,id为主键,name和age为组合索引
当执行如下语句的时候,那些能用到组合索引?
select * from table where name="zhangsan" and age=10;
select * from table where name="zhangsan";
select * from table where age=10;
select * from table where age=10 and name="zhangsan";
答案是:1,2,4可以使用组合索引。原因如下:
第1个是标准的顺序,没问题
第2个是查询name,符合最左匹配,也没问题
第3个把name跳过了,不符合组合索引的要求
第4个是mysql索引优化器对索引的顺序进行了调整,因为age和name的顺序对查询结果没有影响。
4.4 索引下推
MySQL的组成部门:
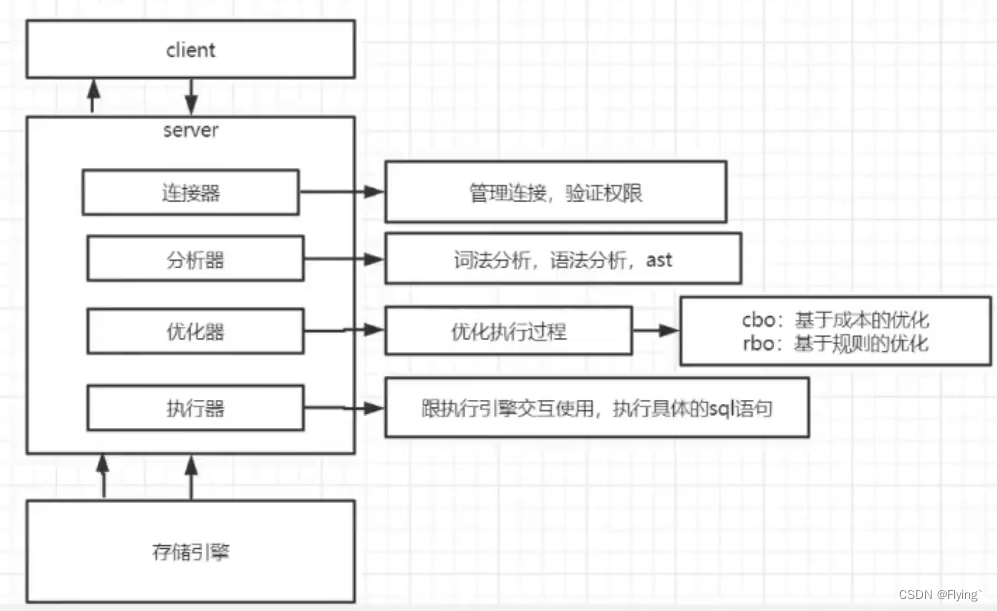
当执行 select * from table where name=“zhangsan” and age=10 时
- 在没有索引下推之前:先根据name去存储引擎拿到全量的数据,在将数据读取到server层,然后server层再根据age进行筛选,将最终结果返回给客户端
- 有了索引下推之后:直接根据name和age去存储引擎拿到全量数据,然后将最终结果返回给客户端
5. 不同的存储引擎是如何进行数据的存储的
在InnoDB中:

frm存储表结构相关的东西
ibd存储的是实际的数据
在Myisam中:
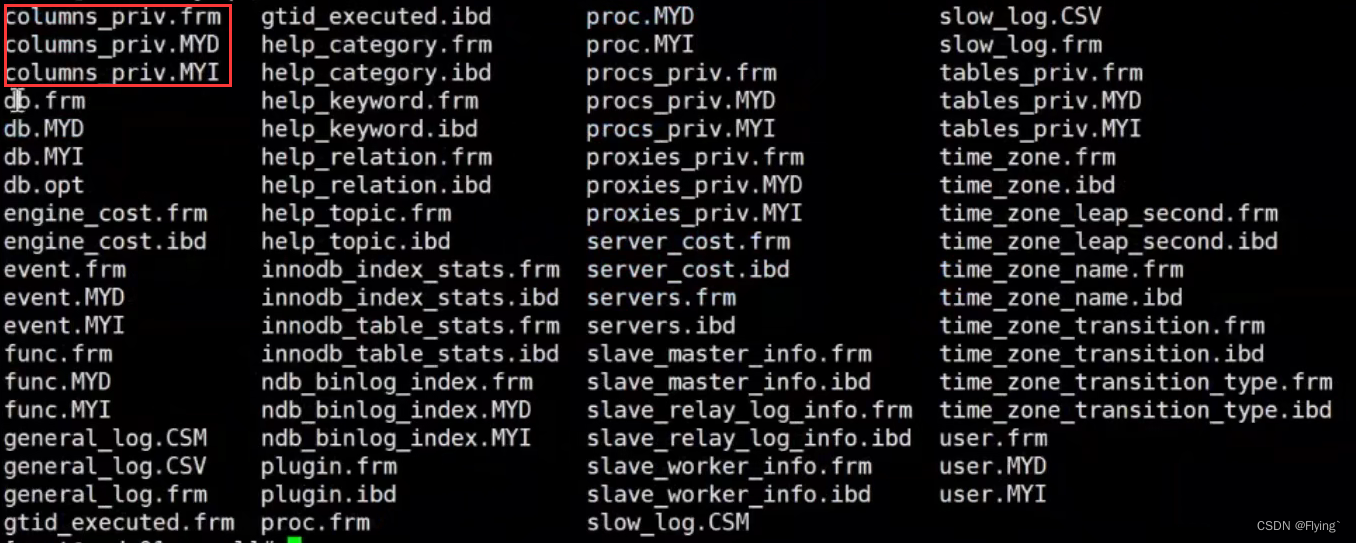
frm存储表结构相关东西
MYD存储数据
MYI存储索引
两者数据的存储的区别:在InnoDB中,数据和索引存储在一起,而在myisam当中,数据和索引分开存储,这也便是myisqm只有非聚簇索引的原因。
6. MySQL组合索引的结构是怎样的
和普通索引就一个区别:key值多为多个,即(key,key)——>value.
7. MySQL索引是如何进行优化的
待沉淀。