l论文作者开发一个算法计算抽样S方程中使用
I
(
c
,
v
)
≈
I
^
S
(
c
,
v
)
=
∑
i
=
1
m
−
1
τ
^
i
L
i
I(\boldsymbol{c}, \boldsymbol{v}) \approx \hat{I}_{\mathcal{S}}(\boldsymbol{c}, \boldsymbol{v})=\sum_{i=1}^{m-1} \hat{\tau}_{i} L_{i}
I(c,v)≈I^S(c,v)=i=1∑m−1τ^iLi
首先是通过利用约束方程 :
max
t
∈
[
0
,
M
]
∣
O
(
t
)
−
O
^
(
t
)
∣
≤
B
T
,
β
=
max
k
∈
[
n
−
1
]
{
exp
(
−
R
^
(
t
k
)
)
(
exp
(
E
^
(
t
k
+
1
)
)
−
1
)
}
,
\max _{t \in[0, M]}|O(t)-\widehat{O}(t)| \leq B_{\mathcal{T}, \beta}=\max _{k \in[n-1]}\left\{\exp \left(-\widehat{R}\left(t_{k}\right)\right)\left(\exp \left(\widehat{E}\left(t_{k+1}\right)\right)-1\right)\right\},
t∈[0,M]max∣O(t)−O
(t)∣≤BT,β=k∈[n−1]max{exp(−R
(tk))(exp(E
(tk+1))−1)}, 找到 样本
T
\Tau
T 这样
0
^
\hat 0
0^:
O
^
(
t
)
=
1
−
e
x
p
(
−
R
^
(
t
)
)
\widehat{O}(t)=1-exp(-\hat R(t))
O
(t)=1−exp(−R^(t))
提供了一个
ϵ
\epsilon
ϵ近似真实的不透明度
O
O
O, 其中
ϵ
\epsilon
ϵ为超参数,即
B
T
,
β
<
ϵ
B_{T,\beta} < \epsilon
BT,β<ϵ.第二,我们执行逆CDF抽样与
O
^
\hat O
O^.
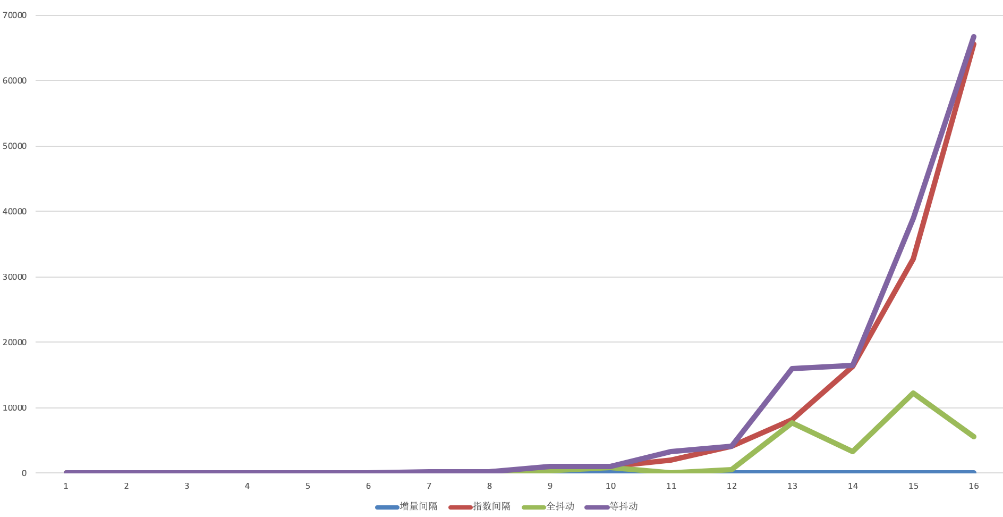
注意,从引理1可以得出,我们可以简单地选择足够大的n来保证 B T , β < ϵ B_{T,\beta} < \epsilon BT,β<ϵ。然而,这将导致过多的样本。相反,我们建议一个简单的算法来减少实际中所需的样本数量,并允许使用有限的样本点预算。简单地说,我们从均匀采样 T = T 0 T = T_0 T=T0开始,用引理2初始设置 β + > β \beta_+ > \beta β+>β满足 B T , β + ≤ ϵ B_{T,\beta_+} \le \epsilon BT,β+≤ϵ。然后,我们重复上采样 T T T以降低 β + \beta_+ β+,同时维持 B T , β + ≤ ϵ B_{T,\beta_+} \le \epsilon BT,β+≤ϵ。尽管这个简单的策略不能保证收敛,但我们发现 β + \beta_+ β+通常收敛于 β + \beta_+ β+(通常为85%,见图3),即使在不收敛的情况下,算法提供的 β + \beta_+ β+的不透明度近似仍然保持一个误差。算法如下所示(算法1)。

我们初始化
T
T
T(1号线算法1)均匀采样
T
0
=
{
t
i
}
i
=
1
n
,
t
k
=
(
k
−
1
)
M
n
−
1
,
k
∈
[
n
]
T_0 = \{t_i\} ^n_{i = 1}, t_k = \frac{(k−1)M}{n−1}, k∈[n]
T0={ti}i=1n,tk=n−1(k−1)M,k∈[n](我们在我们的实现中使用n = 128)。给定这个采样,我们接下来根据引理2选取
β
+
>
β
\beta_+ > \beta
β+>β,使得误差界满足要求的界(算法1中的第2行)。
为了降低
β
+
\beta_+
β+,同时保持
B
T
,
β
+
≤
ϵ
B_{T,\beta_+} \le \epsilon
BT,β+≤ϵ,将n个样本添加到T(算法1中的第4行),其中从每个间隔采样的点数与其当前误差界限成比例,公式:
m
a
x
t
∈
[
t
k
,
t
k
+
1
]
O
(
t
)
−
O
^
(
t
)
∣
≤
e
x
p
(
E
^
(
t
k
+
1
)
−
1
)
\underset{t\in[t_k,t_{k+1}]}{max} O(t)-\widehat{O}(t)| \le exp(\hat E(t_{k+1})-1)
t∈[tk,tk+1]maxO(t)−O
(t)∣≤exp(E^(tk+1)−1)
假设T被充分上采样并满足
B
T
,
β
+
≤
ϵ
B_{T,\beta_+} \le \epsilon
BT,β+≤ϵ,我们将
β
+
\beta_+
β+向
β
\beta
β减小。因为算法没有停止,所以我们有
B
T
,
β
+
≥
ϵ
B_{T,\beta_+} \ge \epsilon
BT,β+≥ϵ。因此,中值定理蕴含着存在
β
∈
(
β
,
β
+
)
\beta \in(\beta,\beta_+)
β∈(β,β+)使得
B
T
,
β
+
=
ϵ
B_{T,\beta_+} = \epsilon
BT,β+=ϵ。我们使用二分法(最多10次迭代)来有效地搜索
β
\beta
β并相应地更新
β
+
\beta_+
β+(算法1中的第6行和第7行)。该算法迭代运行,直到
B
T
,
β
+
≤
ϵ
B_{T,\beta_+} \le \epsilon
BT,β+≤ϵ或达到最大迭代次数5。无论哪种方式,我们都使用最终的
T
T
T和
β
+
\beta_+
β+(保证提供
B
T
,
β
+
≤
ϵ
B_{T,\beta_+} \le \epsilon
BT,β+≤ϵ)来估计当前的不透明度
O
O
O,算法1中的第10行)。最后,我们使用逆变换采样返回一个新的m = 64个样本O的集合(算法1中的第11行)。图3显示了算法1的定性说明,β = 0.001和= 0.1(典型值)。
引理1.固定 β > 0 \beta > 0 β>0。对于任何 ϵ > 0 \epsilon > 0 ϵ>0,足够密集的采样T将提供 B T , β + ≤ ϵ B_{T,\beta_+} \le \epsilon BT,β+≤ϵ。其次,在样本数固定的情况下,我们可以设置 β \beta β,使得误差界小于: ϵ \epsilon ϵ.
引理2.固定 n > 0 n > 0 n>0。对于任何 ϵ > 0 \epsilon>0 ϵ>0,有一个足够大的 β \beta β满足 β ≥ α M 2 a ( n − 1 ) l o g ( 1 + ϵ ) \beta \ge \frac{\alpha M^2}{a(n-1)log(1+\epsilon)} β≥a(n−1)log(1+ϵ)αM2将提供 B T , β + ≤ ϵ B_{T,\beta_+} \le \epsilon BT,β+≤ϵ.