目录
DIN
输入
输出:
与transformer注意力机制的区别与联系:
DINE
改善DIN
输入:
DSIN
动机:
DIN
适用与精排,论文: Deep Interest Network for Click-Through Rate Prediction
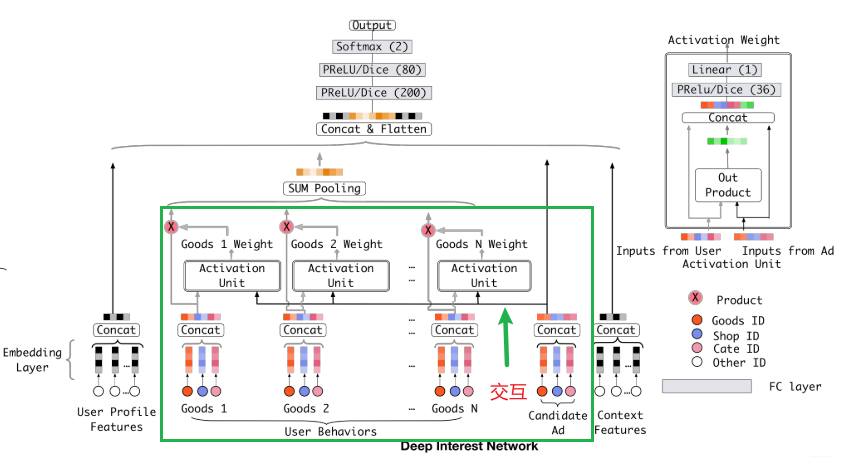
DIN模型提出的动机是利用target attention的方法,进行加权pooling,它为历史行为的物品和当前推荐物品计算一个attention score,然后加权pooling,这样的方法更能体现用户兴趣多样性。
DIN模型,增加了注意力机制,模型的创新点或者解决的问题就是使用了注意力机制来对用户的兴趣动态模拟, 而这个模拟过程存在的前提就是用户之前有大量的历史行为了,这样我们在预测某个商品广告用户是否点击的时候,就可以参考他之前购买过或者查看过的商品,这样就能猜测出用户的大致兴趣来,这样我们的推荐才能做的更加到位,所以这个模型的使用场景是非常注重用户的历史行为特征(历史购买过的商品或者类别信息)
输入
DIN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型),也就是指的上面的历史行为数据。而不同的类型特征也就决定了后面处理的方式会不同:
- Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
- Sparse型特征,为离散型特征建立Input层接收输入,然后需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进DNN, 但是这里面要注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。
- VarlenSparse型特征:这个一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入AttentionPoolingLayer去对这些历史行为特征加权合并,最后得到输出。
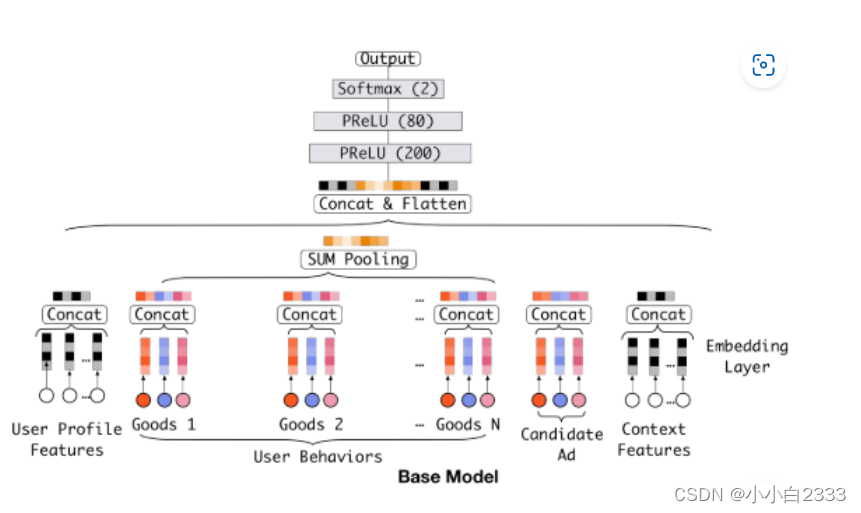
本身用户历史序列和候选序列(候选序列就是召回阶段召回的用户可能会点击的商品)之间没有关系,分别做embedding。
DIN就是通过对用户历史序列的每一个商品和候选商品做自注意力机制,这样候选商品中跟历史商品中相似度比较高的会引起模型的注意(相似度作为权重),排序是会注意这一部分与历史商品相似度高的商品。
把这个权重与原来的历史行为embedding相乘求和就得到了用户的兴趣表示, 这个东西的计算公式如下:
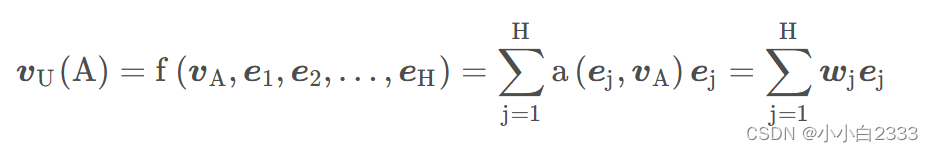
输出:
通过DNN网络的每个候选商品可能被点击的概率。
与transformer注意力机制的区别与联系:
区别:
在Transformer中使用的Attention是Scaled Dot-Product Attention, 是归一化的点乘Attention。是多头注意力,形成多个子空间,可以让模型去关注不同方面的信息。Q,K,V是一个东西,只是会乘以不同的权重矩阵

DIN不经过softmax ,没有归一化操作;Q是候选序列,K,V是历史序列。用 的单头注意力机制。
联系:都是运用注意力机制,通过相似度当权重,再将权重与和V矩阵实现求加权和。
DINE
改善DIN
以前的CTR预估方法都是直接将用户表现的表示向量当作兴趣,而没有通过具体的表现对隐藏的兴趣进行建模。 DIEN相比于之前的模型,即对用户的兴趣进行建模,又对建模出来的用户兴趣继续建模得到用户的兴趣变化过程。

图其实分解开就是:输入embedding,用户历史行为序列通过GRU(引入了一个损失,为了让行为序列中的每一个时刻都有一个target item进行监督训练,也就是使用下一个行为来监督兴趣状态的学习),通过注意力机制,再通过AUGRU,输出一个embedding,和另外的非行为相关特征进行concat。
DIEN模型的重点就是如何将用户的行为序列转换成与用户兴趣相关的向量,在DIN中是直接通过与target item计算序列中每个元素的注意力分数,然后加权求和得到最终的兴趣表示向量。在DIEN中使用了两层结构来建模用户兴趣相关的向量。
输入:
模型的输入可以分成两大部分,一部分是用户的行为序列(这部分会通过兴趣提取层及兴趣演化层转换成与用户当前兴趣相关的embedding),另一部分就是除了用户行为以外的其他所有特征,如Target id, Coontext Feature, UserProfile Feature,这些特征都转化成embedding的类型然后concat在一起(形成一个大的embedding)作为非行为相关的特征(这里可能也会存在一些非id类特征,应该可以直接进行concat)。最后DNN输入的部分由行为序列embedding和非行为特征embedding(多个特征concat到一起之后形成的一个大的向量)组成,将两者concat之后输入到DNN中。
详情可看[论文阅读]阿里DIEN深度兴趣进化网络之总体解读 (qq.com)
DSIN
[1905.06482] Deep Session Interest Network for Click-Through Rate Prediction (arxiv.org)
这个是在DIEN的基础上又进行的一次演化,这个模型的改进出发点依然是如何通过用户的历史点击行为,从里面更好的提取用户的兴趣以及兴趣的演化过程,这个模型就是从user历史行为信息挖掘方向上进行演化的。
动机:
作者发现用户的行为序列的组成单位,其实应该是会话(按照用户的点击时间划分开的一段行为),每个会话里面的点击行为呢? 会高度相似,而会话与会话之间的行为,就不是那么相似了,但是像DIN,DIEN这两个模型,DIN的话,是直接忽略了行为之间的序列关系,使得对用户的兴趣建模或者演化不是很充分,而DIEN的话改进了DIN的序列关系的忽略缺点,但是忽视了行为序列的本质组成结构。
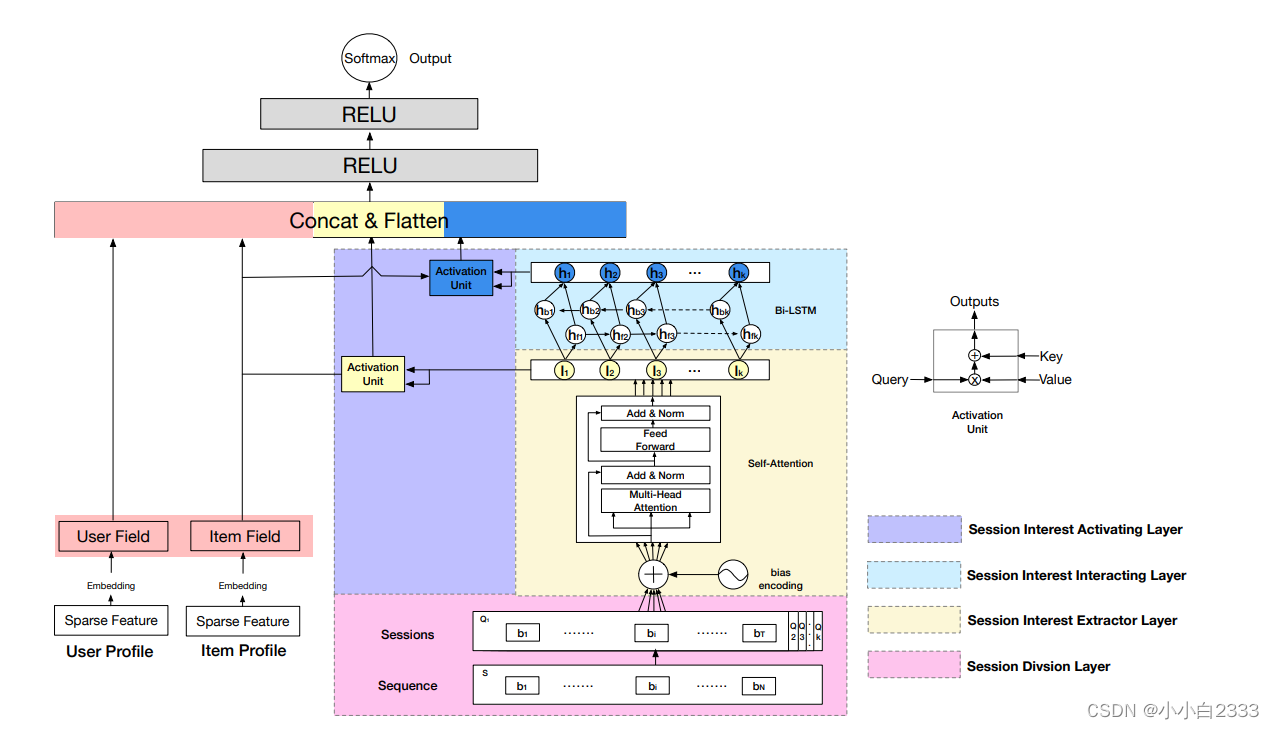
1.Session Divsion Layer
将用户的行为序列进行切分,首先将用户的点击行为按照时间排序,判断两个行为之间的时间间隔。
2.多头注意力(会话兴趣提取层)
每一段的商品时间的序列关系都要经过多头注意力机制。这个东西是在多个角度研究一个会话里面各个商品的关联关系, 相比GRU来讲,没有啥梯度消失,并且可以并行计算,比GRU可强大多了。(研究每个会话内部各个商品之间的关联关系)
3.会话交互层
研究会话与会话之间的关系。学习用户兴趣的演化规律,这里用了双向的LSTM,不仅看从现在到未来的兴趣演化,还能学习未来到现在的变化规律。
4.会话兴趣局部激活层
注意力机制, 每次关注与当前商品更相关的兴趣。
参考:
DIN (datawhalechina.github.io)
(1条消息) AI上推荐 之 AFM与DIN模型(当推荐系统遇上了注意力机制)_din ffm_翻滚的小@强的博客-CSDN博客
论文解读:Attention is All you need - 知乎 (zhihu.com)
炼丹面试官的面试笔记_炼丹笔记的博客-CSDN博客
DIEN (datawhalechina.github.io)
[论文阅读]阿里DIEN深度兴趣进化网络之总体解读 (qq.com)
DSIN (datawhalechina.github.io)
如有理解不对,请告诉我,我们可以一起讨论~共同进步~
后续更新:
LGB
MMoE