YOLOS是由华中科大提出的将Transformer迁移到计算机视觉领域的目标检测方法,其直接魔改ViT!本文首次证明,通过将一系列固定大小的非重叠图像块作为输入,可以以纯序列到序列的方式实现2D目标检测。

模型结构
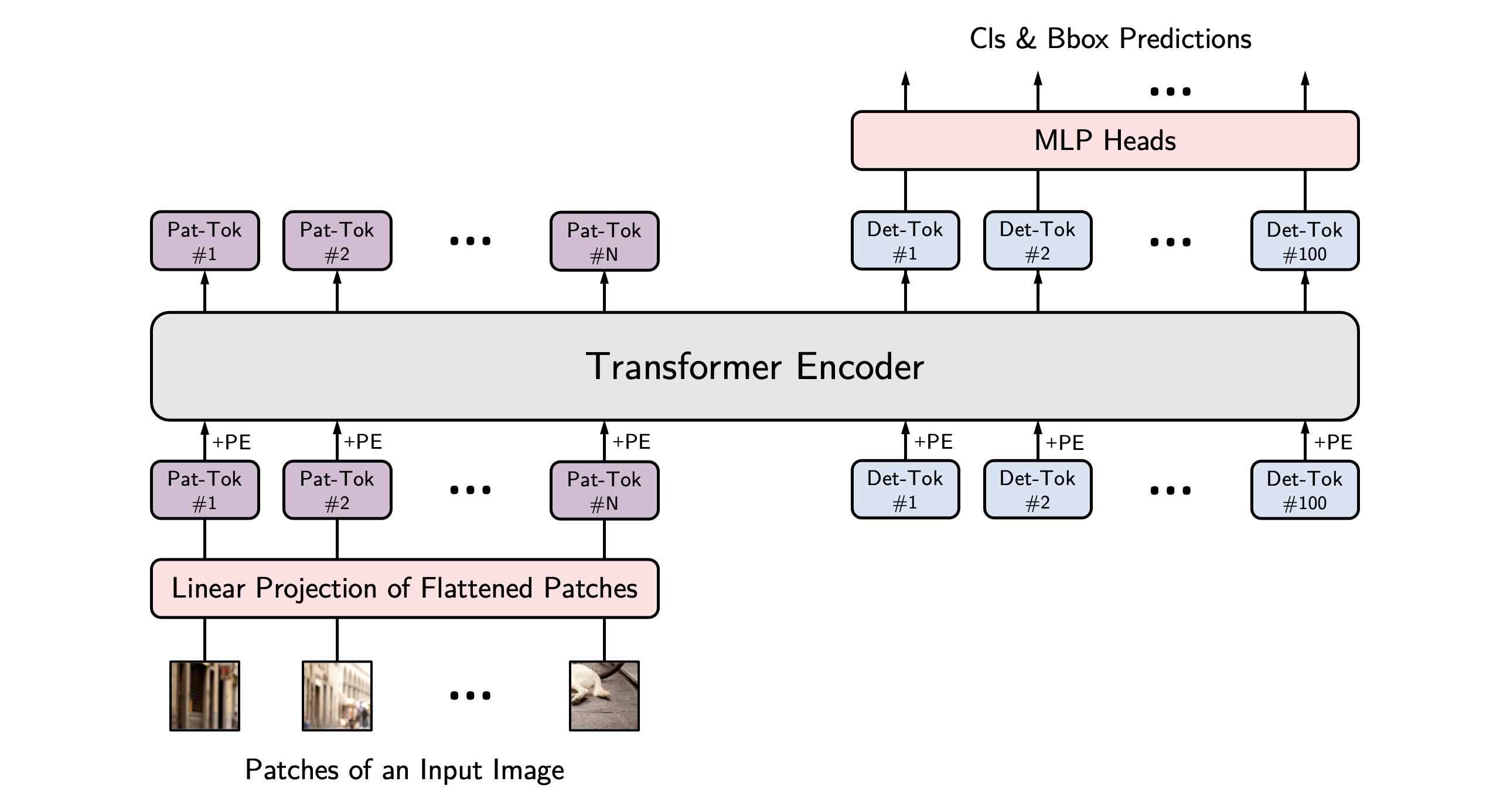
下面来调试一下该项目,该项目通过Transformer与YOLO相结合进行目标检测,Transformer可谓是自然语言处理领域的常青树,在迁移到计算机视觉领域后凭借其优异的性能引发关注。
该项目的结构参考的是DETR模型,因此在代码理解时我们可以以此为借鉴。
环境配置
首先是创建虚拟环境:
conda create -n yolos python=3.7
随后我们将项目上传到服务器上,完成后激活yolos环境并切换到项目根目录下执行安装依赖包命令
pip install -r requirements.txt

(博主曾在本地上下载pycocotools 包时时常报错,但在服务器上却正常,想必是与博主的下载通道相关)
随后
值得注意的是在代码中要求的是pytorch1.5及以上,而在运行过程中报错:
cannot import name ‘Dataloader’ from ‘torch.utils.data’
这是由于torch版本不匹配导致的,可以将代码中Dataloader改为torch.utils.data.DataLoader,并将前面的import屏蔽即可,抑或是像博主这样下载一个对应版本的torch,理论上torch 1.8以下就没有问题了。博主安装的是torch 1.6
conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch -y
随后环境基本就没有什么问题了。
随后便是代码的调试过程了,由于代码结构参考的DETR项目,因此我们的修改参数配置可以借鉴DETR的调试过程。当然,其实官方给出了readme已经讲解的很清楚了,我们按照其步骤来即可。
数据集配置
数据集使用的是COCO2017。建议不要从官网下载,很慢且极易被墙。
随后便是数据集的加载了,将数据集上传到服务器上(论文中实验数据集为COCO2017,该数据集很大,建议找个空闲时间上传)
随后将数据集解压,博主放置的路径为:
unzip annotations_trainval2017.zip
unzip val2017.zip
unzip train2017.zip
所需模型文件
这里的模型文件分为两种,一个是使用ImageNet做预训练得到的预训练模型,实验中在COCO数据集上训练时使用的便是该模型,另一个便是通过在COCO数据集上训练所得到的模型文件,供我们做评估使用。
当然我们在训练时可以不使用预训练模型,但对于Transformer这种没有先验知识的模型而言消耗无疑是巨大的。

模型训练
完成后按照官方给出的要求,我们在使用COCO数据集训练微调时,需要加载一下通过ImageNet数据集预训练的预训练模型:
Before finetuning on COCO, you need download the ImageNet pretrained
model to the /path/to/YOLOS/ directory
博主选择的是YOLOS-S这个预训练模型
To train the YOLOS-S model with 200 epoch pretrained Deit-S in the paper, run this command:
python -m torch.distributed.launch
--nproc_per_node=8
--use_env main.py
--coco_path /path/to/coco
--batch_size 1
--lr 2.5e-5
--epochs 150
--backbone_name small
--pre_trained /path/to/deit-small-200epoch.pth
--eval_size 800
--init_pe_size 512 864
--mid_pe_size 512 864
--output_dir /output/path/box_model
当然我们也可以直接运行main.py,只需要指定好参数即可。
主要就是配置一下数据集地址,init_pe_size,mid_pe_size,预训练模型。


至于其他的batch-size,num-workers根据自己电脑性能来即可。
不得不说,Transformer模型都是十分吃配置的,博主只能将batch-size设置为1(与官方给定参数相同)
由于模型与数据集太过庞大,训练起来也是十分缓慢。

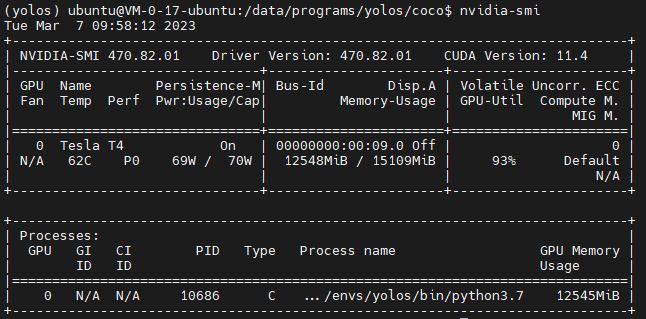
评估
这里评估即使用YOLOS-S模型在COCO数据集上训练的所得模型进行评估
关于模型评估,官方给出的步骤为:
To evaluate YOLOS-S model on COCO, run:
python -m torch.distributed.launch
--nproc_per_node=8
--use_env main.py
--coco_path /path/to/coco
--batch_size 1
--backbone_name small
--eval
--eval_size 800
--init_pe_size 512 864
--mid_pe_size 512 864
--resume /path/to/YOLOS-S
与训练时采用相同的方式,我们也可以使用运行main.py文件来实现。
可视化结果
Visualize box prediction and object categories distribution
可视化标注框预测和对象类别分布
To Get visualization in the paper, you need the finetuned YOLOS models on COCO, run following command to get 100 Det-Toks prediction on COCO val split, then it will generate /path/to/YOLOS/visualization/modelname-eval-800-eval-pred.json
python cocoval_predjson_generation.py
--coco_path /path/to/coco
--batch_size 1
--backbone_name small
--eval
--eval_size 800
--init_pe_size 512 864
--mid_pe_size 512 864
--resume /path/to/yolos-s-model.pth
--output_dir ./visualization
To get all ground truth object categories on all images from COCO val split, run following command to generate /path/to/YOLOS/visualization/coco-valsplit-cls-dist.json
python cocoval_gtclsjson_generation.py
--coco_path /path/to/coco
--batch_size 1
--output_dir ./visualization
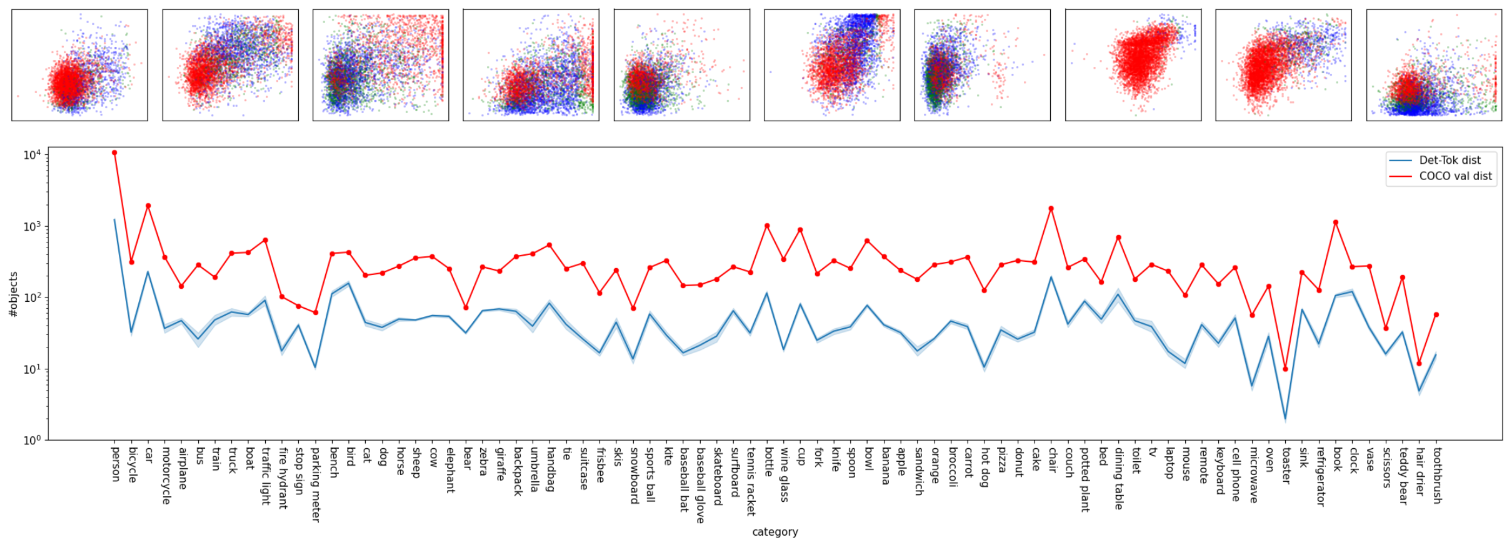
To visualize the distribution of Det-Toks’ bboxs and categories, run following command to generate .png files in /path/to/YOLOS/visualization/
python visualize_dettoken_dist.py
--visjson /path/to/YOLOS/visualization/modelname-eval-800-eval-pred.json
--cococlsjson /path/to/YOLOS/visualization/coco-valsplit-cls-dist.json

结语
再次发表一下对于调试该模型时的一些感悟:首先一定要认认真真阅读readme中给我们的指导,这会让我们的调试事半功倍。
其次关于这个模型,该模型根据论文中给出的结果与分析来看,其相较于当下的主流模型如yolov7,yolov8等还是由差距的,但这也意味着其改进空间巨大。Transformer作为NLP领域的中流砥柱,在迁移到计算机视觉后能够表现出如此性能已是出人意料,而这也给我们了许多启示。
对于该模型而言,博主觉得想要复现他的结果还是很难的,以训练为例,在使用COCO数据集时,面对如此庞大的数据集(在Transformer眼中这还只是小数据集)其运行起来是颇为耗时的,博主使用的Nvidia T4 显卡在这种状态也是力不从心。batch-size只能调整为1,而且在训练时,一个epochs所要耗费的时间也是极长的,初步估计可能需要一天时间,这对于我而言无疑是无法接受的。









![[Python图像处理] 使用高通滤波器实现同态滤波](https://img-blog.csdnimg.cn/08769ddf988f48c88680b9ef14202be3.png#pic_center)