Namenode 启动
- 前言
- 启动 Namenode 组件
- 启动脚本
- Namenode.initialize
- FSNamesystem.loadFromDisk
- FsImage.recoverTransitionRead
- FSImageFormat.load
- FSImageFormatProtobuf.load
- 反序列化加载FsImage文件内容
- FsImage内存数据结构
前言
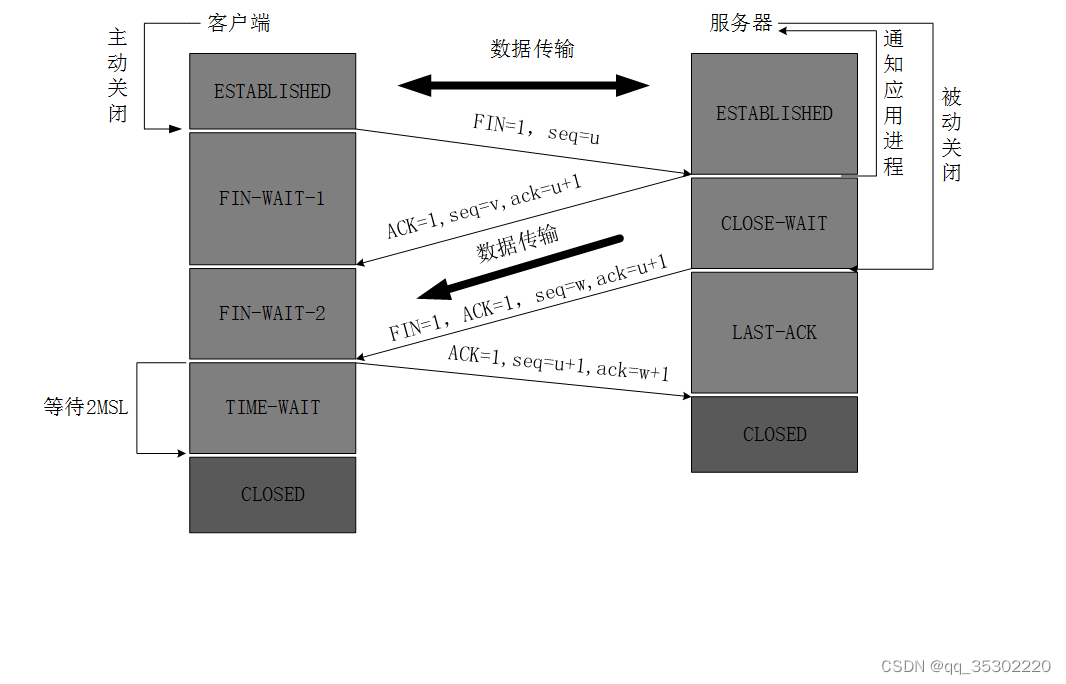
NameNode是HDFS中负责元数据管理的组件,它保存着整个文件系统的元数据信息,并且充当着指挥调度DataNode的作用。NameNode不仅在内存中保存着文件系统元数据信息,还会定期将文件系统的元数据(文件目录树、文件/ 目录元信息) 持久化到本地 fsImage 文件中, 以防止Namenode掉电或者进程异常崩溃。
如果Namenode实时地将内存中的元数据同步到fsimage文件中, 将会非常消耗资源且造成Namenode运行缓慢。 所以Namenode会先将元数据的修改操作保存在editlog文件中, 然后定期合并fsimage和editlog文件

启动 Namenode 组件
启动脚本
bin/hdfs --daemon start namenode
上述脚本会 调用 org.apache.hadoop.hdfs.server.namenode.NameNode的main方法
public static void main(String argv[]) throws Exception {
// ...省略
// 创建 namenode
NameNode namenode = createNameNode(argv, null);
// ...省略
}
创建 NameNode 的过程,先进行参数解析,判断是 format / rollback / bootstrapStandby 等等操作类型。然后依次执行改逻辑,本章节主要是正对NameNode的启动过程。
依次往下阅读 ,进入到 NameNode的构造函数中 调用 initialize(getConf());
Namenode.initialize
此方法主要做了如下事项:
- 配置安全相关的信息UserGroupInformation
- 启动 JvmPauseMonitor 检查
- 启动 HTTP 服务端 (9870)
- 初始化FSNameSystem 核心组件 ,加载镜像文件和编辑日志到内存
- 初始化rpc server 组件
- 启动 公共 服务
protected void initialize(Configuration conf) throws IOException {
if (conf.get(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS) == null) {
String intervals = conf.get(DFS_METRICS_PERCENTILES_INTERVALS_KEY);
if (intervals != null) {
conf.set(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS,
intervals);
}
}
UserGroupInformation.setConfiguration(conf);
loginAsNameNodeUser(conf);
NameNode.initMetrics(conf, this.getRole());
StartupProgressMetrics.register(startupProgress);
pauseMonitor = new JvmPauseMonitor();
pauseMonitor.init(conf);
pauseMonitor.start();
metrics.getJvmMetrics().setPauseMonitor(pauseMonitor);
if (conf.getBoolean(DFS_NAMENODE_GC_TIME_MONITOR_ENABLE,
DFS_NAMENODE_GC_TIME_MONITOR_ENABLE_DEFAULT)) {
long observationWindow = conf.getTimeDuration(
DFS_NAMENODE_GC_TIME_MONITOR_OBSERVATION_WINDOW_MS,
DFS_NAMENODE_GC_TIME_MONITOR_OBSERVATION_WINDOW_MS_DEFAULT,
TimeUnit.MILLISECONDS);
long sleepInterval = conf.getTimeDuration(
DFS_NAMENODE_GC_TIME_MONITOR_SLEEP_INTERVAL_MS,
DFS_NAMENODE_GC_TIME_MONITOR_SLEEP_INTERVAL_MS_DEFAULT,
TimeUnit.MILLISECONDS);
gcTimeMonitor = new Builder().observationWindowMs(observationWindow)
.sleepIntervalMs(sleepInterval).build();
gcTimeMonitor.start();
metrics.getJvmMetrics().setGcTimeMonitor(gcTimeMonitor);
}
if (NamenodeRole.NAMENODE == role) {
// 启动 HTTP 服务端 (9870)
startHttpServer(conf);
}
// 初始化FSNameSystem 核心组件 ,加载镜像文件和编辑日志到内存
loadNamesystem(conf);
startAliasMapServerIfNecessary(conf);
//初始化rpc server 组件
rpcServer = createRpcServer(conf);
initReconfigurableBackoffKey();
if (clientNamenodeAddress == null) {
// This is expected for MiniDFSCluster. Set it now using
// the RPC server's bind address.
clientNamenodeAddress =
NetUtils.getHostPortString(getNameNodeAddress());
LOG.info("Clients are to use " + clientNamenodeAddress + " to access"
+ " this namenode/service.");
}
// 如果是NameNode 设置NameNodeAddress 以及 FsImage
if (NamenodeRole.NAMENODE == role) {
httpServer.setNameNodeAddress(getNameNodeAddress());
httpServer.setFSImage(getFSImage());
if (levelDBAliasMapServer != null) {
httpServer.setAliasMap(levelDBAliasMapServer.getAliasMap());
}
}
// 一些公共服务的初始化
startCommonServices(conf);
startMetricsLogger(conf);
}
FSNamesystem.loadFromDisk
接着会调用 FSNamesystem 静态方法 loadFromDisk 加载 元数据
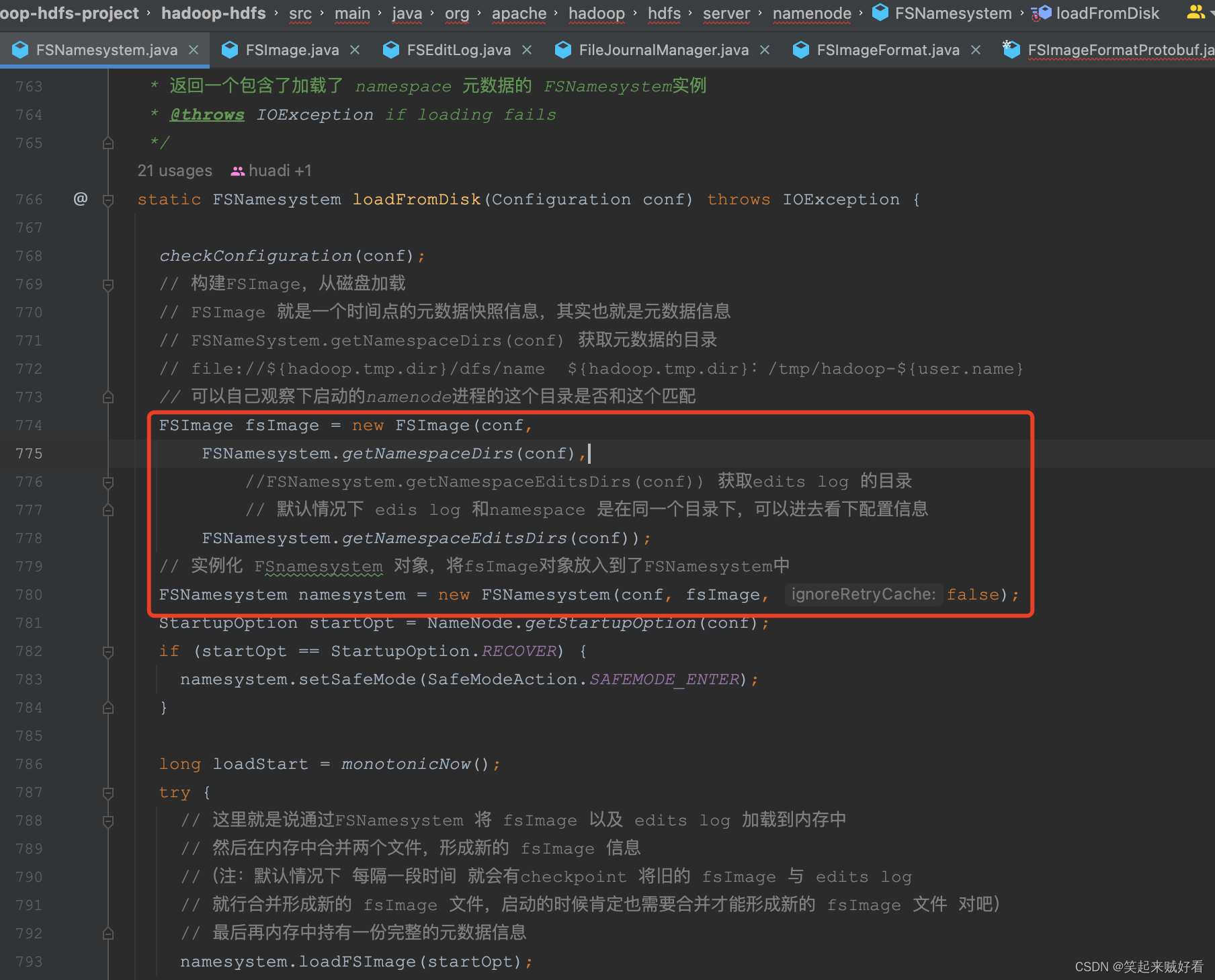
static FSNamesystem loadFromDisk(Configuration conf) throws IOException {
checkConfiguration(conf);
// 构建FSImage,从磁盘加载
// FSImage 就是一个时间点的元数据快照信息,其实也就是元数据信息
// FSNameSystem.getNamespaceDirs(conf) 获取元数据的目录
// file://${hadoop.tmp.dir}/dfs/name ${hadoop.tmp.dir}:/tmp/hadoop-${user.name}
// 可以自己观察下启动的namenode进程的这个目录是否和这个匹配
FSImage fsImage = new FSImage(conf,
FSNamesystem.getNamespaceDirs(conf),
//FSNamesystem.getNamespaceEditsDirs(conf)) 获取edits log 的目录
// 默认情况下 edis log 和namespace 是在同一个目录下,可以进去看下配置信息
FSNamesystem.getNamespaceEditsDirs(conf));
// 实例化 FSnamesystem 对象,将fsImage对象放入到了FSNamesystem中
FSNamesystem namesystem = new FSNamesystem(conf, fsImage, false);
StartupOption startOpt = NameNode.getStartupOption(conf);
if (startOpt == StartupOption.RECOVER) {
namesystem.setSafeMode(SafeModeAction.SAFEMODE_ENTER);
}
long loadStart = monotonicNow();
try {
// 这里就是说通过FSNamesystem 将 fsImage 以及 edits log 加载到内存中
// 然后在内存中合并两个文件,形成新的 fsImage 信息
//(注:默认情况下 每隔一段时间 就会有checkpoint 将旧的 fsImage 与 edits log
// 就行合并形成新的 fsImage 文件,启动的时候肯定也需要合并才能形成新的 fsImage 文件 对吧)
// 最后再内存中持有一份完整的元数据信息
namesystem.loadFSImage(startOpt);
} catch (IOException ioe) {
LOG.warn("Encountered exception loading fsimage", ioe);
fsImage.close();
throw ioe;
}
long timeTakenToLoadFSImage = monotonicNow() - loadStart;
LOG.info("Finished loading FSImage in " + timeTakenToLoadFSImage + " msecs");
NameNodeMetrics nnMetrics = NameNode.getNameNodeMetrics();
if (nnMetrics != null) {
nnMetrics.setFsImageLoadTime((int) timeTakenToLoadFSImage);
}
namesystem.getFSDirectory().createReservedStatuses(namesystem.getCTime());
return namesystem;
}
内存结构
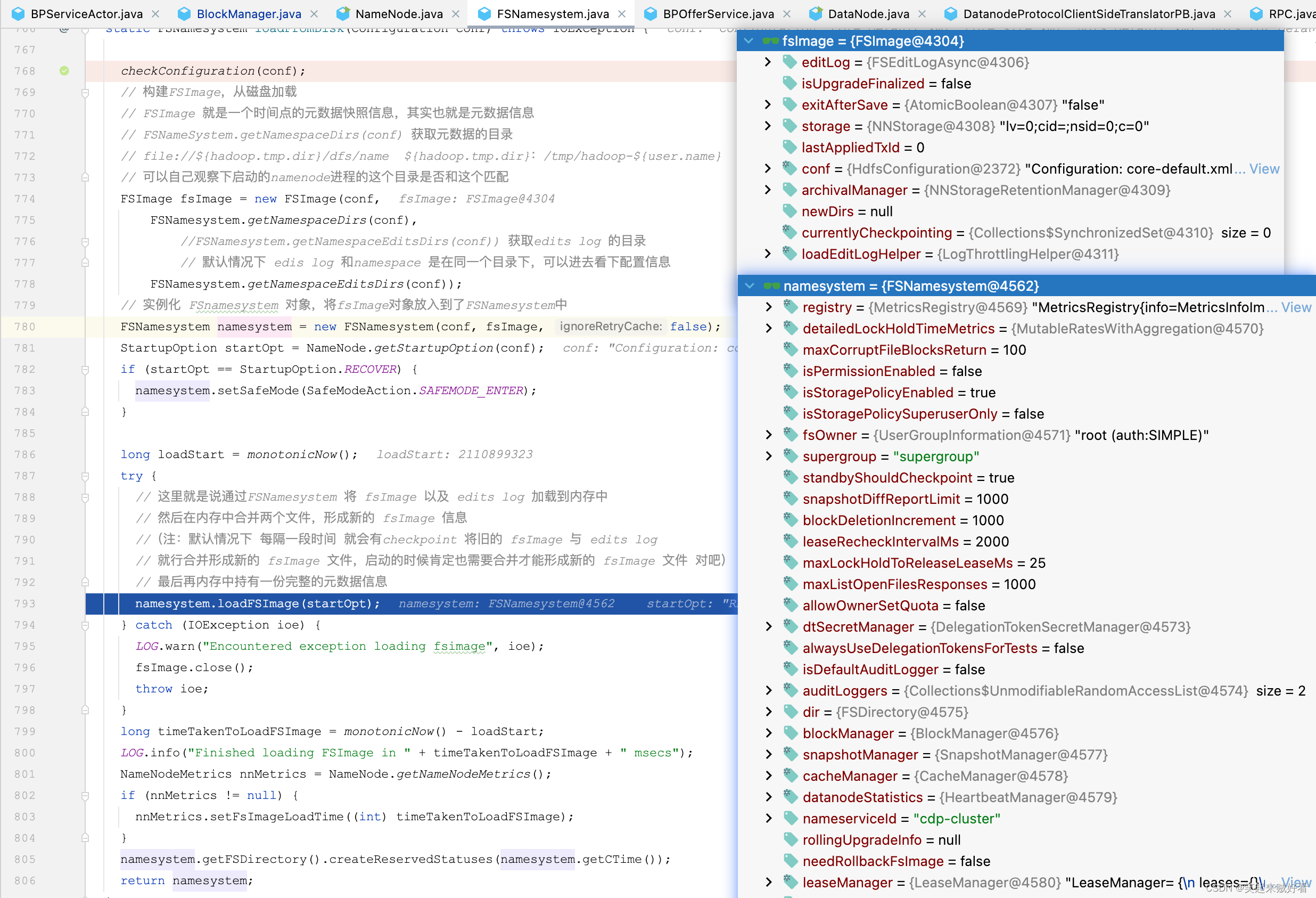
FSNameSystem这里采用了门面模式,自己不负责具体的加载逻辑,交给FsImage去干活。
继续看FsImage.recoverTransitionRead(StartupOption startOpt, FSNamesystem target,MetaRecoveryContext recovery)
FsImage.recoverTransitionRead
主要做了四件事:
- 检查每个数据目录,判断是否状态一致性
- Format unformatted dirs. 格式化未格式的目录
- Do transitions 转换操作
- 真正的加载 fsImage 和 edits log 文件进行合并
/**
* Analyze storage directories.
* Recover from previous transitions if required.
* Perform fs state transition if necessary depending on the namespace info.
* Read storage info.
* 分析存储的目录 就是存储 fsImage 以及 edits log 的目录
* 从以前的状态恢复
* 根据元信息 判断是否执行fs状态的转换
* 读取存储的信息
* 大概意思就是如果以前有 fsImage 和 edits log 就从文件信息中加载出来 并进行恢复
*
* @throws IOException
* @return true if the image needs to be saved or false otherwise
*/
boolean recoverTransitionRead(StartupOption startOpt, FSNamesystem target,
MetaRecoveryContext recovery)
throws IOException {
assert startOpt != StartupOption.FORMAT :
"NameNode formatting should be performed before reading the image";
// 获取fsImage 文件资源地址 其实也就是目录
Collection<URI> imageDirs = storage.getImageDirectories();
// 获取edits log 目录
Collection<URI> editsDirs = editLog.getEditURIs();
// none of the data dirs exist
if((imageDirs.size() == 0 || editsDirs.size() == 0)
&& startOpt != StartupOption.IMPORT)
throw new IOException(
"All specified directories are not accessible or do not exist.");
// 1. For each data directory calculate its state and
// check whether all is consistent before transitioning.
// 检查每个数据目录,判断是否状态一致性
// 进行数据恢复 里面就是对一些之前停机的时候 更新 回滚 新增数据的恢复操作
Map<StorageDirectory, StorageState> dataDirStates =
new HashMap<StorageDirectory, StorageState>();
boolean isFormatted = recoverStorageDirs(startOpt, storage, dataDirStates);
if (LOG.isTraceEnabled()) {
LOG.trace("Data dir states:\n " +
Joiner.on("\n ").withKeyValueSeparator(": ")
.join(dataDirStates));
}
if (!isFormatted && startOpt != StartupOption.ROLLBACK
&& startOpt != StartupOption.IMPORT) {
throw new IOException("NameNode is not formatted.");
}
int layoutVersion = storage.getLayoutVersion();
if (startOpt == StartupOption.METADATAVERSION) {
System.out.println("HDFS Image Version: " + layoutVersion);
System.out.println("Software format version: " +
HdfsServerConstants.NAMENODE_LAYOUT_VERSION);
return false;
}
if (layoutVersion < Storage.LAST_PRE_UPGRADE_LAYOUT_VERSION) {
NNStorage.checkVersionUpgradable(storage.getLayoutVersion());
}
if (startOpt != StartupOption.UPGRADE
&& startOpt != StartupOption.UPGRADEONLY
&& !RollingUpgradeStartupOption.STARTED.matches(startOpt)
&& layoutVersion < Storage.LAST_PRE_UPGRADE_LAYOUT_VERSION
&& layoutVersion != HdfsServerConstants.NAMENODE_LAYOUT_VERSION) {
throw new IOException(
"\nFile system image contains an old layout version "
+ storage.getLayoutVersion() + ".\nAn upgrade to version "
+ HdfsServerConstants.NAMENODE_LAYOUT_VERSION + " is required.\n"
+ "Please restart NameNode with the \""
+ RollingUpgradeStartupOption.STARTED.getOptionString()
+ "\" option if a rolling upgrade is already started;"
+ " or restart NameNode with the \""
+ StartupOption.UPGRADE.getName() + "\" option to start"
+ " a new upgrade.");
}
// 执行一些启动选项以及一些二更操作
storage.processStartupOptionsForUpgrade(startOpt, layoutVersion);
// 2. Format unformatted dirs.
for (Iterator<StorageDirectory> it = storage.dirIterator(); it.hasNext();) {
StorageDirectory sd = it.next();
StorageState curState = dataDirStates.get(sd);
switch(curState) {
case NON_EXISTENT:
throw new IOException(StorageState.NON_EXISTENT +
" state cannot be here");
case NOT_FORMATTED:
// Create a dir structure, but not the VERSION file. The presence of
// VERSION is checked in the inspector's needToSave() method and
// saveNamespace is triggered if it is absent. This will bring
// the storage state uptodate along with a new VERSION file.
// If HA is enabled, NNs start up as standby so saveNamespace is not
// triggered.
LOG.info("Storage directory " + sd.getRoot() + " is not formatted.");
LOG.info("Formatting ...");
sd.clearDirectory(); // create empty current dir
// For non-HA, no further action is needed here, as saveNamespace will
// take care of the rest.
if (!target.isHaEnabled()) {
continue;
}
// If HA is enabled, save the dirs to create a version file later when
// a checkpoint image is saved.
if (newDirs == null) {
newDirs = new HashSet<StorageDirectory>();
}
newDirs.add(sd);
break;
default:
break;
}
}
// 3. Do transitions
switch(startOpt) {
case UPGRADE:
case UPGRADEONLY:
doUpgrade(target);
return false; // upgrade saved image already
case IMPORT:
doImportCheckpoint(target);
return false; // import checkpoint saved image already
case ROLLBACK:
throw new AssertionError("Rollback is now a standalone command, " +
"NameNode should not be starting with this option.");
case REGULAR:
default:
// just load the image
}
// 真正的加载 fsImage 和 edits log 文件进行合并
return loadFSImage(target, startOpt, recovery);
}
因为FsImage load重载比较多,故直接到关键步骤。
此方法中判断是否支持 md5 加密
/**
*
* 这里面就不仔细去详细的跟到文件加载了,
* loadFSImage()方法就是最终加载文件的方法
* @param target
* @param recovery
* @param imageFile
* @param startupOption
* @throws IOException
*/
void loadFSImageFile(FSNamesystem target, MetaRecoveryContext recovery,
FSImageFile imageFile, StartupOption startupOption) throws IOException {
LOG.info("Planning to load image: " + imageFile);
StorageDirectory sdForProperties = imageFile.sd;
storage.readProperties(sdForProperties, startupOption);
if (NameNodeLayoutVersion.supports(
LayoutVersion.Feature.TXID_BASED_LAYOUT, getLayoutVersion())) {
// For txid-based layout, we should have a .md5 file
// next to the image file
boolean isRollingRollback = RollingUpgradeStartupOption.ROLLBACK
.matches(startupOption);
loadFSImage(imageFile.getFile(), target, recovery, isRollingRollback);
} else if (NameNodeLayoutVersion.supports(
LayoutVersion.Feature.FSIMAGE_CHECKSUM, getLayoutVersion())) {
// In 0.22, we have the checksum stored in the VERSION file.
String md5 = storage.getDeprecatedProperty(
NNStorage.DEPRECATED_MESSAGE_DIGEST_PROPERTY);
if (md5 == null) {
throw new InconsistentFSStateException(sdForProperties.getRoot(),
"Message digest property " +
NNStorage.DEPRECATED_MESSAGE_DIGEST_PROPERTY +
" not set for storage directory " + sdForProperties.getRoot());
}
loadFSImage(imageFile.getFile(), new MD5Hash(md5), target, recovery,
false);
} else {
// We don't have any record of the md5sum
loadFSImage(imageFile.getFile(), null, target, recovery, false);
}
}
调用 FSImageFormat的LoaderDelegator进行加载fsImage文件
FSImageFormat.load
private void loadFSImage(File curFile, MD5Hash expectedMd5,
FSNamesystem target, MetaRecoveryContext recovery,
boolean requireSameLayoutVersion) throws IOException {
// BlockPoolId is required when the FsImageLoader loads the rolling upgrade
// information. Make sure the ID is properly set.
target.setBlockPoolId(this.getBlockPoolID());
// 一个持有FSNamesystem 以及 conf 对象的 loader,加载器
FSImageFormat.LoaderDelegator loader = FSImageFormat.newLoader(conf, target);
loader.load(curFile, requireSameLayoutVersion);
// Check that the image digest we loaded matches up with what
// we expected
MD5Hash readImageMd5 = loader.getLoadedImageMd5();
if (expectedMd5 != null &&
!expectedMd5.equals(readImageMd5)) {
throw new IOException("Image file " + curFile +
" is corrupt with MD5 checksum of " + readImageMd5 +
" but expecting " + expectedMd5);
}
long txId = loader.getLoadedImageTxId();
LOG.info("Loaded image for txid " + txId + " from " + curFile);
lastAppliedTxId = txId;
storage.setMostRecentCheckpointInfo(txId, curFile.lastModified());
}
使用protobuf定义的fsimage文件的格式, 它包括了4个部分的信息
■ MAGIC: fsimage的文件头, 是“HDFSIMG1”这个字符串的二进制形式, MAGIC头标识了当前fsimage文件是使用protobuf格式序列化的。 FSImage类在读取fsimage文件时, 会先判断fsimage文件是否包含了MAGIC头, 如果包含了则使用protobuf格式反序列化fsimage文件。
■ SECTIONS: fsimage文件会将同一类型的Namenode元信息保存在一个section中,例如将文件系统元信息保存在NameSystemSection中, 将文件系统目录树中的所有INode信息保存在INodeSection中, 将快照信息保存在SnapshotSection中等。fsimage文件的第二个部分就是Namenode各类元信息对应的所有section, 每类section中都包含了对应Namenode元信息的属性.
■ FileSummary: FileSummary记录了fsimage文件的元信息, 以及fsimage文件保存的所有section的信息。 FileSummary中的ondiskVersion字段记录了fsimage文件的版本号(3.2.1 版本中这个字段的值为1) , layoutVersion字段记录了当前HDFS的文件
系统布局版本号, codec字段记录了fsimage文件的压缩编码, sections字段则记录了fsimage文件中各个section字段的元信息, 每个fsimage文件中记录的section在FileSummary中都有一个与之对应的section字段。 FileSummary的section字段记录了对应的fsimage中section的名称、 在fsimage文件中的长度, 以及这个section在fsimage中的起始位置。 FSImage类在读取fsimage文件时, 会先从fsimage中读取出FileSummary部分, 然后利用FileSummary记录的元信息指导fsimage文件的反序列化操作。
■ FileSummaryLength: FileSummaryLength记录了FileSummary在fsimage文件中所占的长度, FSImage类在读取fsimage文件时, 会首先读取FileSummaryLength获取FileSummary部分的长度, 然后根据这个长度从fsimage中反序列化出FileSummary
public void load(File file, boolean requireSameLayoutVersion)
throws IOException {
Preconditions.checkState(impl == null, "Image already loaded!");
InputStream is = null;
try {
is = Files.newInputStream(file.toPath());
byte[] magic = new byte[FSImageUtil.MAGIC_HEADER.length];
IOUtils.readFully(is, magic, 0, magic.length);
// 判断头信息,是否是Protobuf格式
if (Arrays.equals(magic, FSImageUtil.MAGIC_HEADER)) {
FSImageFormatProtobuf.Loader loader = new FSImageFormatProtobuf.Loader(
conf, fsn, requireSameLayoutVersion);
impl = loader;
loader.load(file);
} else {
Loader loader = new Loader(conf, fsn);
impl = loader;
loader.load(file);
}
} finally {
IOUtils.cleanupWithLogger(LOG, is);
}
}
FSImageFormatProtobuf.load
最后也是最重要的步骤,通过 FSImageFormatProtobuf 对元数据进行反序列化,生成内存中的数据结构
序列化完成后,FsNameSystem实例中存储这反序列化后的元数据信息。
SectionName是一个枚举类一共记录了12种类型. [按写入的fsimage的顺序进行排列]
| 序号 | 名称 | Section类型 | 描述 |
|---|---|---|---|
| 1 | NS_INFO | NameSystemSection | 命名空间信息 |
| 2 | ERASURE_CODING | ErasureCodingSection | EC纠删码 |
| 3 | INODE | INodeSection | 命名空间信息 |
| 4 | INODE_DIR | INodeDirectorySection | 命名空间信息 |
| 5 | FILES_UNDERCONSTRUCTION | FileUnderConstructionEntry | 命名空间信息 |
| 6 | SNAPSHOT | SnapshotSection | 快照信息 |
| 7 | SNAPSHOT_DIFF | NameSystemSection | 快照信息比对 |
| 8 | INODE_REFERENCE | INodeReferenceSection | inode引用信息 |
| 9 | SECRET_MANAGER | SecretManagerSection | 安全信息 |
| 10 | CACHE_MANAGER | CacheManagerSection | 缓存信息 |
| 11 | STRING_TABLE | StringTableSection | 命名空间信息 |
| 12 | NS_INFO | NameSystemSection | 权限 |
反序列化加载FsImage文件内容
private void loadInternal(RandomAccessFile raFile, FileInputStream fin)
throws IOException {
if (!FSImageUtil.checkFileFormat(raFile)) {
throw new IOException("Unrecognized file format");
}
FileSummary summary = FSImageUtil.loadSummary(raFile);
if (requireSameLayoutVersion && summary.getLayoutVersion() !=
HdfsServerConstants.NAMENODE_LAYOUT_VERSION) {
throw new IOException("Image version " + summary.getLayoutVersion() +
" is not equal to the software version " +
HdfsServerConstants.NAMENODE_LAYOUT_VERSION);
}
FileChannel channel = fin.getChannel();
// inode加载器
FSImageFormatPBINode.Loader inodeLoader = new FSImageFormatPBINode.Loader(
fsn, this);
FSImageFormatPBSnapshot.Loader snapshotLoader = new FSImageFormatPBSnapshot.Loader(
fsn, this);
ArrayList<FileSummary.Section> sections = Lists.newArrayList(summary
.getSectionsList());
Collections.sort(sections, new Comparator<FileSummary.Section>() {
@Override
public int compare(FileSummary.Section s1, FileSummary.Section s2) {
SectionName n1 = SectionName.fromString(s1.getName());
SectionName n2 = SectionName.fromString(s2.getName());
if (n1 == null) {
return n2 == null ? 0 : -1;
} else if (n2 == null) {
return -1;
} else {
return n1.ordinal() - n2.ordinal();
}
}
});
StartupProgress prog = NameNode.getStartupProgress();
/**
* beginStep() and the endStep() calls do not match the boundary of the
* sections. This is because that the current implementation only allows
* a particular step to be started for once.
*/
Step currentStep = null;
// 非常重要的参数,对于超大规模的集群,fsimage加载慢一直是通病,
// 此参数可以对其进行优化,通过多现场去并行加载section
boolean loadInParallel = enableParallelSaveAndLoad(conf);
ExecutorService executorService = null;
ArrayList<FileSummary.Section> subSections =
getAndRemoveSubSections(sections);
if (loadInParallel) {
executorService = getParallelExecutorService();
}
for (FileSummary.Section s : sections) {
channel.position(s.getOffset());
InputStream in = new BufferedInputStream(new LimitInputStream(fin,
s.getLength()));
in = FSImageUtil.wrapInputStreamForCompression(conf,
summary.getCodec(), in);
String n = s.getName();
SectionName sectionName = SectionName.fromString(n);
if (sectionName == null) {
throw new IOException("Unrecognized section " + n);
}
ArrayList<FileSummary.Section> stageSubSections;
switch (sectionName) {
case NS_INFO:
loadNameSystemSection(in);
break;
case STRING_TABLE:
loadStringTableSection(in);
break;
case INODE: {
currentStep = new Step(StepType.INODES);
prog.beginStep(Phase.LOADING_FSIMAGE, currentStep);
stageSubSections = getSubSectionsOfName(
subSections, SectionName.INODE_SUB);
if (loadInParallel && (stageSubSections.size() > 0)) {
inodeLoader.loadINodeSectionInParallel(executorService,
stageSubSections, summary.getCodec(), prog, currentStep);
} else {
inodeLoader.loadINodeSection(in, prog, currentStep);
}
}
break;
case INODE_REFERENCE:
snapshotLoader.loadINodeReferenceSection(in);
break;
case INODE_DIR:
stageSubSections = getSubSectionsOfName(
subSections, SectionName.INODE_DIR_SUB);
if (loadInParallel && stageSubSections.size() > 0) {
inodeLoader.loadINodeDirectorySectionInParallel(executorService,
stageSubSections, summary.getCodec());
} else {
inodeLoader.loadINodeDirectorySection(in);
}
inodeLoader.waitBlocksMapAndNameCacheUpdateFinished();
break;
case FILES_UNDERCONSTRUCTION:
inodeLoader.loadFilesUnderConstructionSection(in);
break;
case SNAPSHOT:
snapshotLoader.loadSnapshotSection(in);
break;
case SNAPSHOT_DIFF:
snapshotLoader.loadSnapshotDiffSection(in);
break;
case SECRET_MANAGER: {
prog.endStep(Phase.LOADING_FSIMAGE, currentStep);
Step step = new Step(StepType.DELEGATION_TOKENS);
prog.beginStep(Phase.LOADING_FSIMAGE, step);
loadSecretManagerSection(in, prog, step);
prog.endStep(Phase.LOADING_FSIMAGE, step);
}
break;
case CACHE_MANAGER: {
Step step = new Step(StepType.CACHE_POOLS);
prog.beginStep(Phase.LOADING_FSIMAGE, step);
loadCacheManagerSection(in, prog, step);
prog.endStep(Phase.LOADING_FSIMAGE, step);
}
break;
case ERASURE_CODING:
Step step = new Step(StepType.ERASURE_CODING_POLICIES);
prog.beginStep(Phase.LOADING_FSIMAGE, step);
loadErasureCodingSection(in);
prog.endStep(Phase.LOADING_FSIMAGE, step);
break;
default:
LOG.warn("Unrecognized section {}", n);
break;
}
}
if (executorService != null) {
executorService.shutdown();
}
}
如下是 内存中的 FsImage 数据结构
FsImage内存数据结构
FileSummary.json展示
ondiskVersion: 1
layoutVersion: 4294967230
sections {
name: "NS_INFO"
length: 36
offset: 8
}
sections {
name: "ERASURE_CODING"
length: 31
offset: 44
}
sections {
name: "INODE"
length: 26174
offset: 75
}
sections {
name: "INODE_DIR"
length: 1880
offset: 26249
}
sections {
name: "FILES_UNDERCONSTRUCTION"
length: 0
offset: 28129
}
sections {
name: "SNAPSHOT"
length: 5
offset: 28129
}
sections {
name: "INODE_REFERENCE"
length: 0
offset: 28134
}
sections {
name: "SECRET_MANAGER"
length: 9
offset: 28134
}
sections {
name: "CACHE_MANAGER"
length: 7
offset: 28143
}
sections {
name: "STRING_TABLE"
length: 102
offset: 28150
}
FileSummary的数据结构
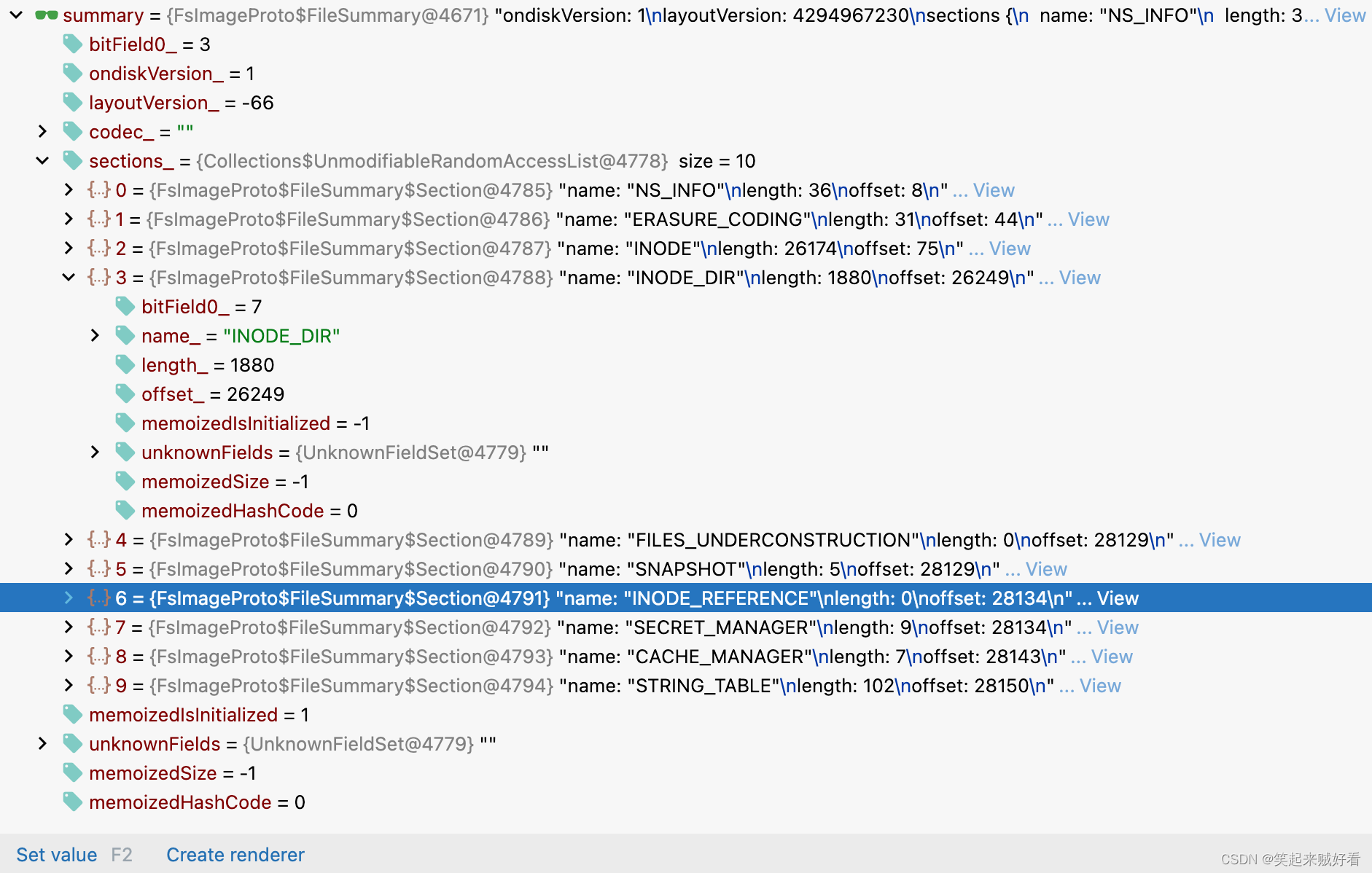
NameSystemSection的内存数据结构
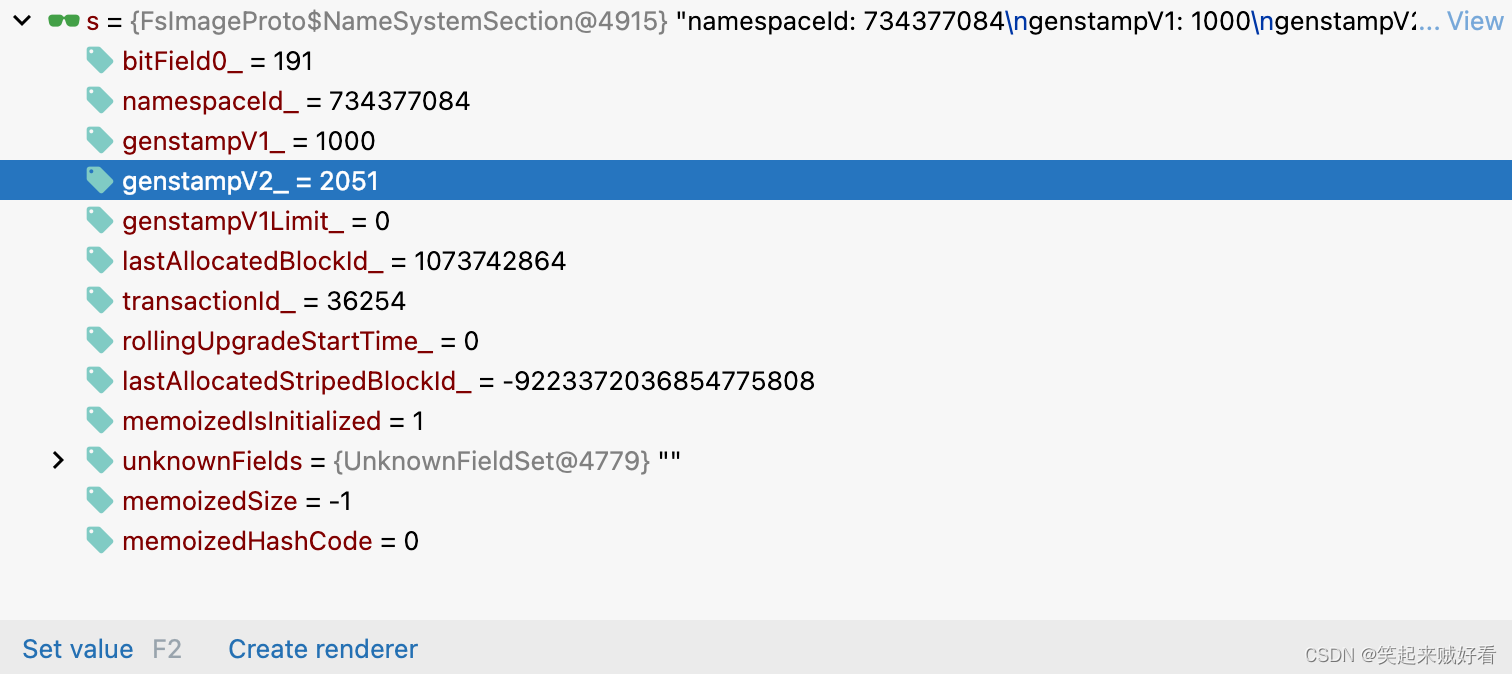
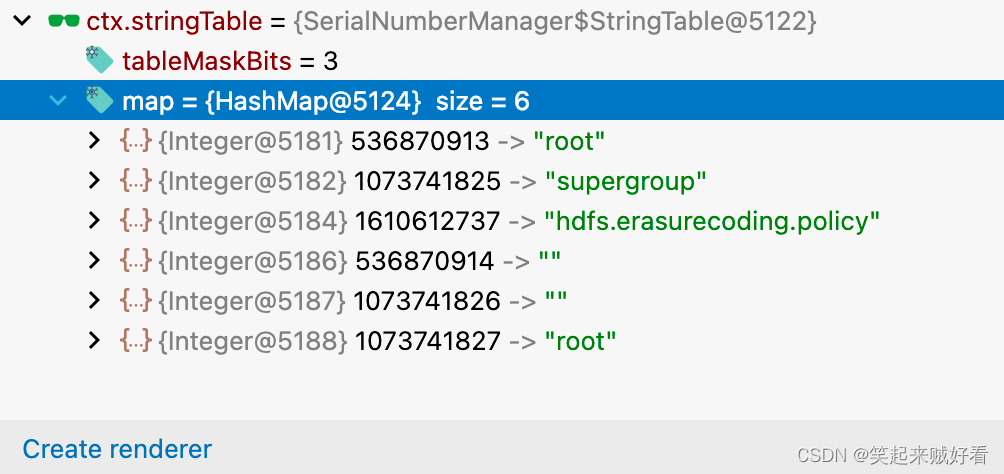
StringTable记录hdfs元数据的权限相关
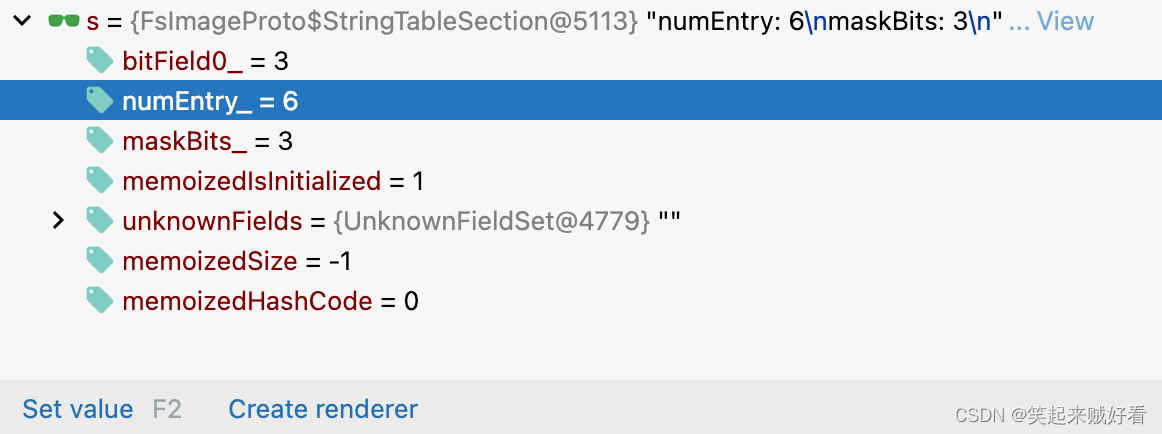
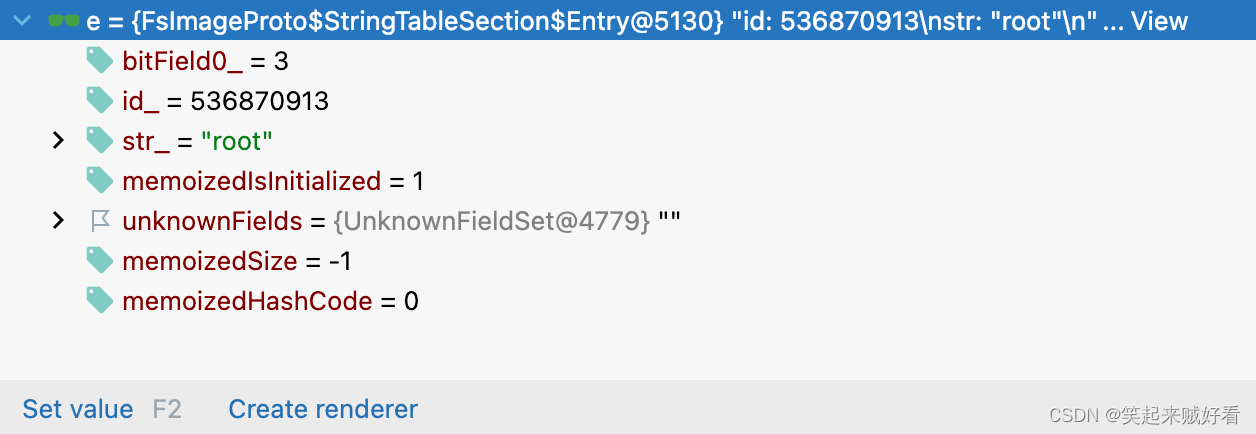
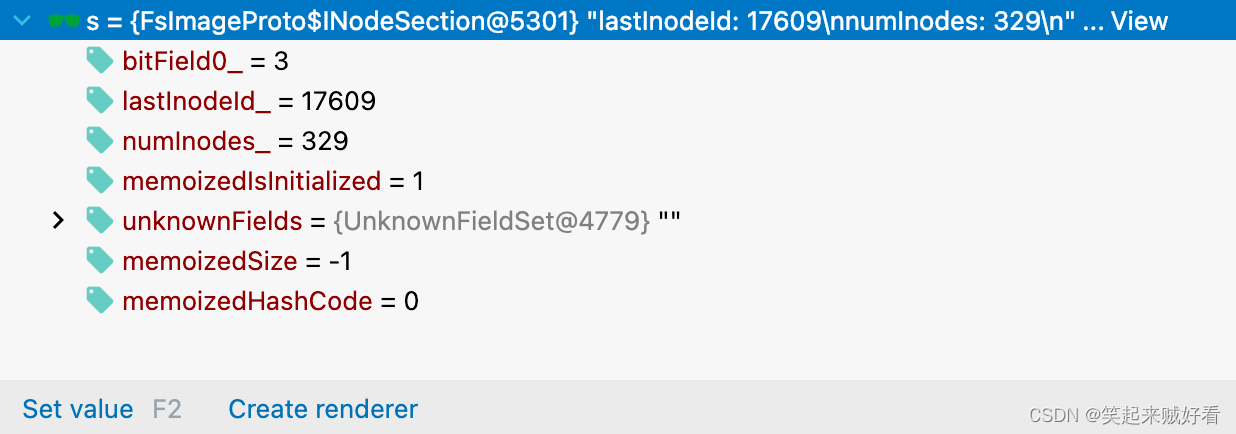
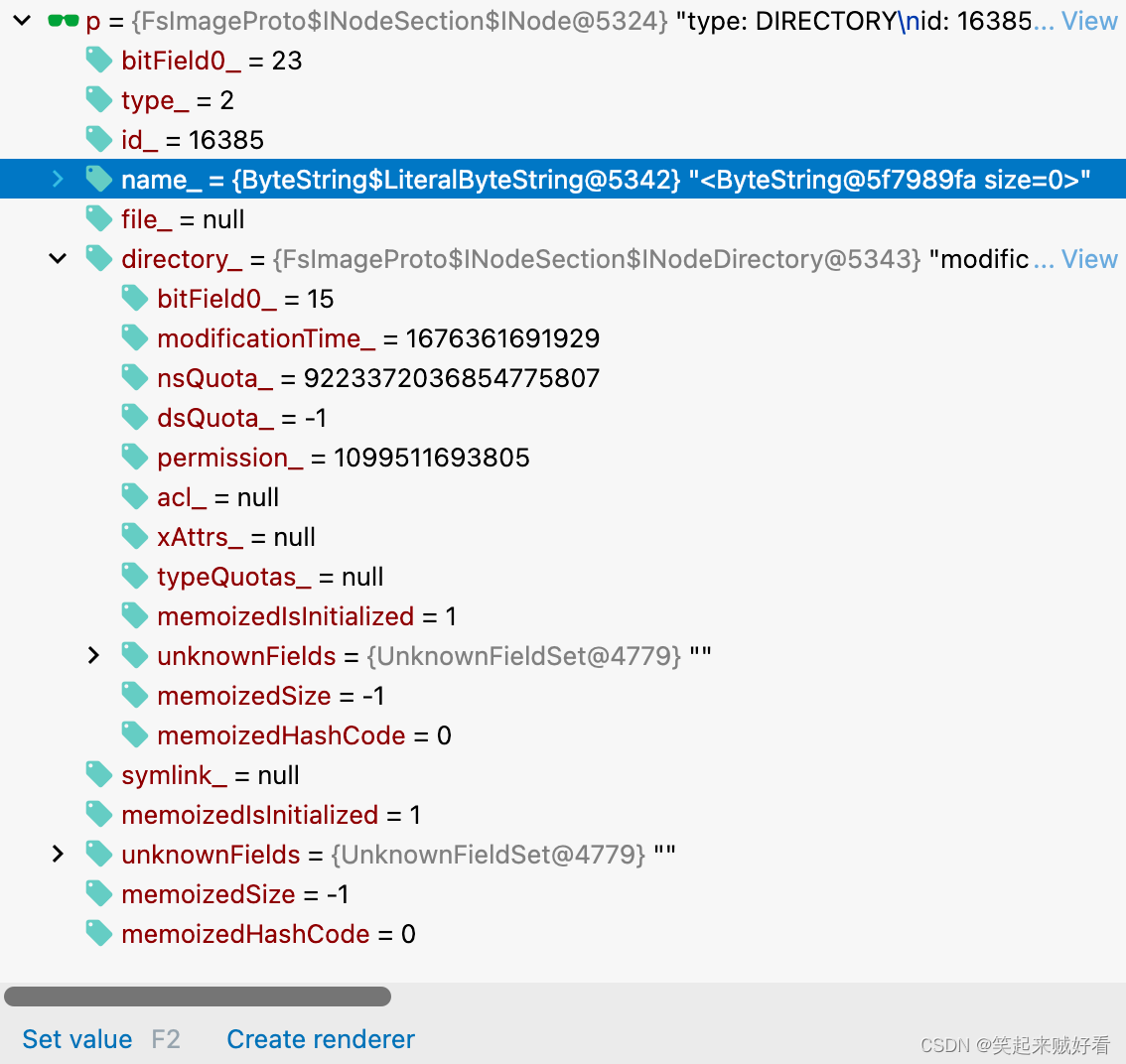
HDFS元数据中非常重要的 内容 INodeSection 结构
希望对正在查看文章的您有所帮助,记得关注、评论、收藏,谢谢您







![[Python图像处理] 使用高通滤波器实现同态滤波](https://img-blog.csdnimg.cn/08769ddf988f48c88680b9ef14202be3.png#pic_center)