目录
- 原理
- 环境准备
- 操作系统(Centos7)
- Mysql客户端安装
- Psql客户端安装
- 数据库用户
- 导表脚本
- dbmysql2pgmysqlcopy
- 测试
- 在mysql中建表
- 导表测试
- 查看pg中的表
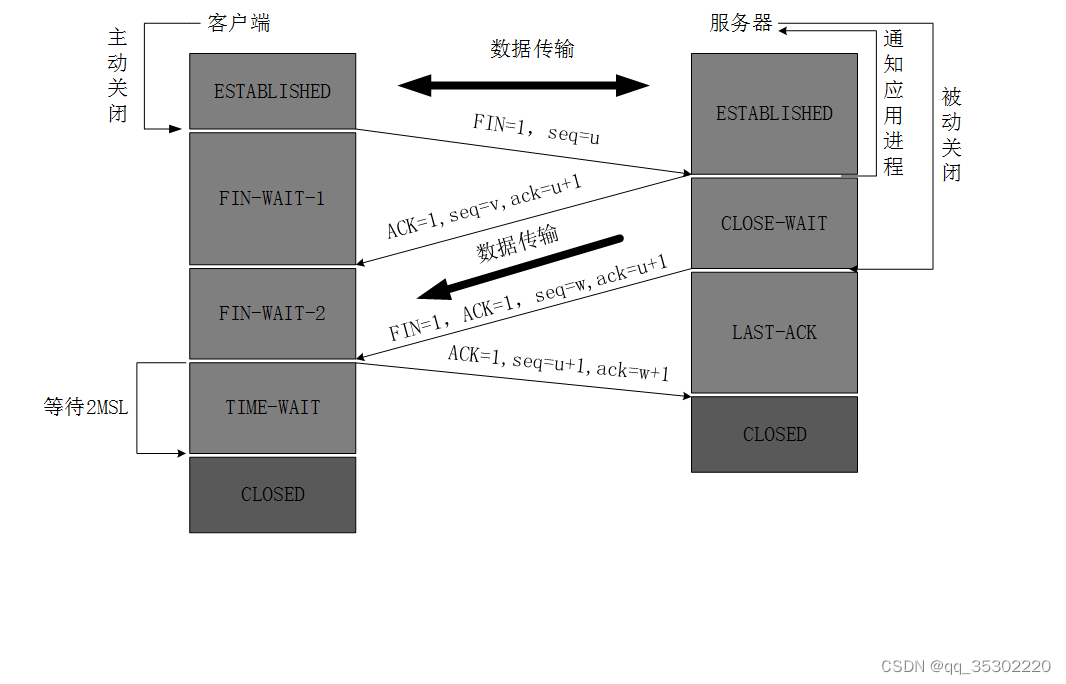
原理
Mysql抽取:mysql命令重定向到操作系统文件,处理成csv文件;
PG装载:copy方式将csv文件装载进PG。
环境准备
操作系统(Centos7)
useradd pgload
passwd pgload
mkdir -p /data/etl/mysql2pg/csv
mkdir -p /data/etl/mysql2pg/tmp
mkdir -p /data/etl/mysql2pg/log
mkdir -p /data/etl/mysql2pg/shell
chown -R pgload.pgload /data/etl
su - pgload
touch /data/etl/mysql2pg/shell/dbmysql2pgmysqlcopy
chmod +x /data/etl/mysql2pg/shell/dbmysql2pgmysqlcopy
echo 'export PATH=${PATH}:/data/etl/mysql2pg/shell
# mysqlselect作为mysql抽取数据的用户
export MYSQLID=mysqlselect:000000@10.10.10.10:3306/etl
# pgload为PG数据装载的用户
export PGID=pgload:000000@10.10.10.10:5432/etl' >> ~/.bash_profile
source ~/.bash_profile
Mysql客户端安装
- 由于rpm安装方式与系统自带的mariadb有冲突,所以只有卸载mariadb才能通过rpm方式进行安装;
- 所以,在此以压缩包的方式进行安装。
Mysql客户端下载地址
- 下载mysql客户端,我这里下载mysql5.7.34

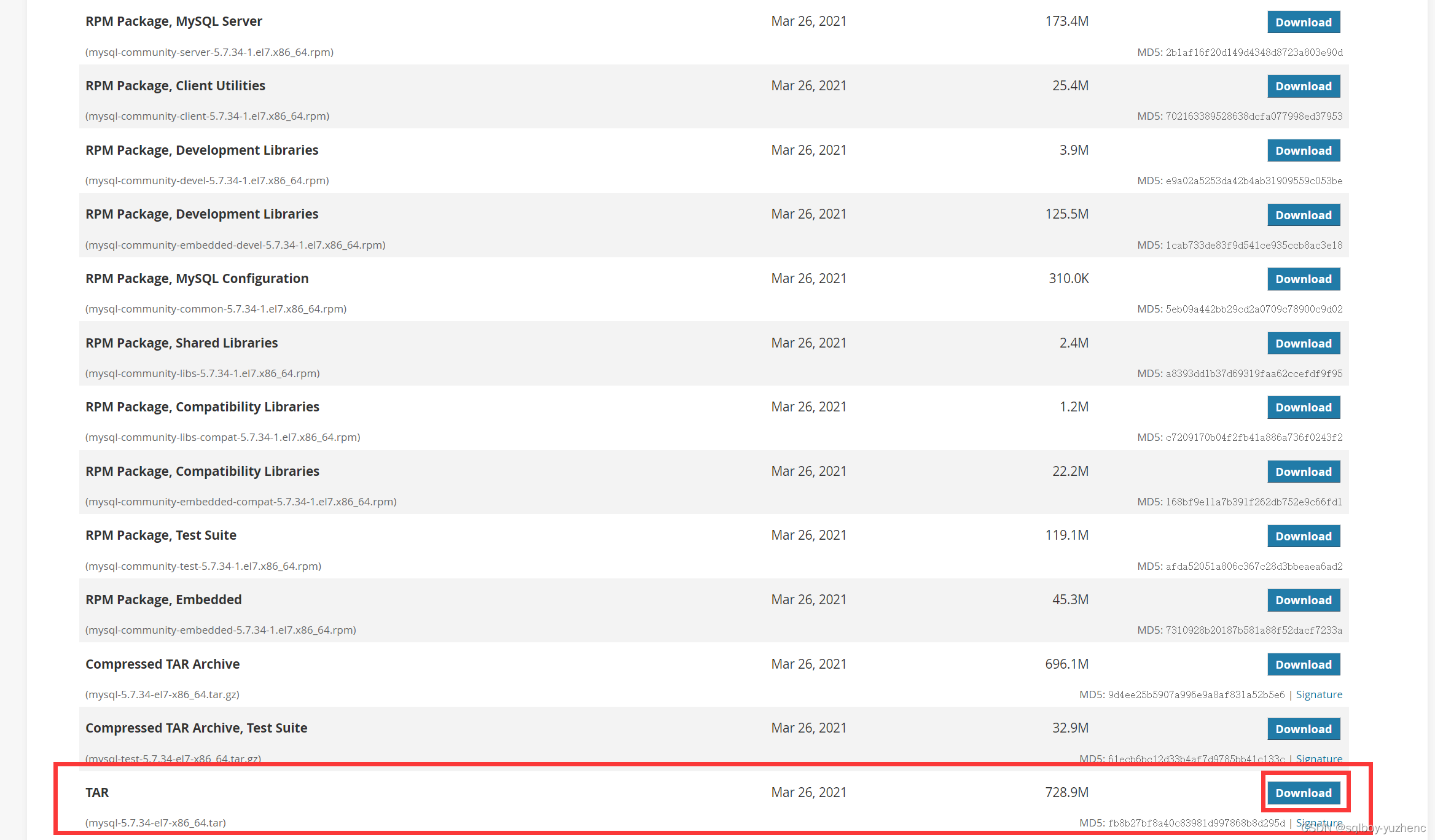
- 将下载好的压缩包进行一次解压得到2个文件

- 将 mysql-5.7.34-el7-x86_64.tar.gz 上传至服务器
cd /usr/local
rz
tar -zxvf mysql-5.7.34-el7-x86_64.tar.gz
mv mysql-5.7.34-el7-x86_64 mysql-client
# 配置环境变量
echo 'export PATH=$PATH:/usr/local/mysql-client/bin' >> /etc/profile
source /etc/profile
# 测试mysql命令
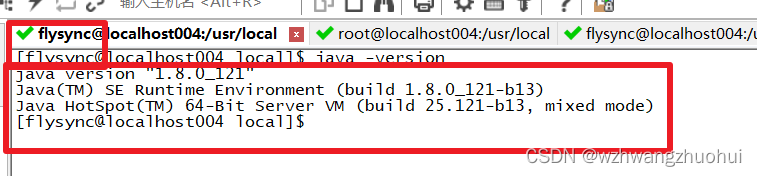
mysql -uroot -h10.10.10.10 -P3306 --database etl -e "select 1 from dual;" -p
Psql客户端安装
Psql客户端下载地址
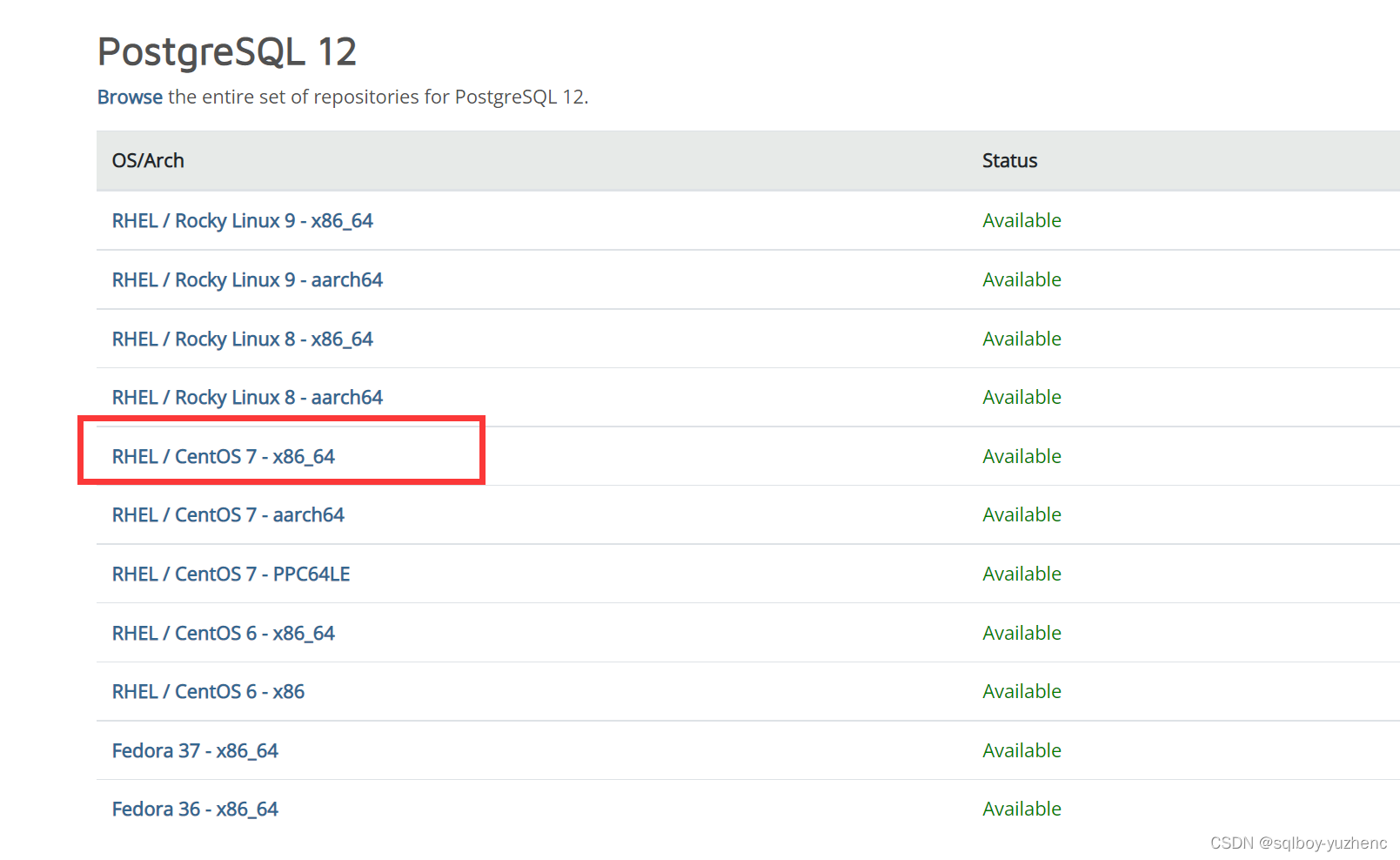
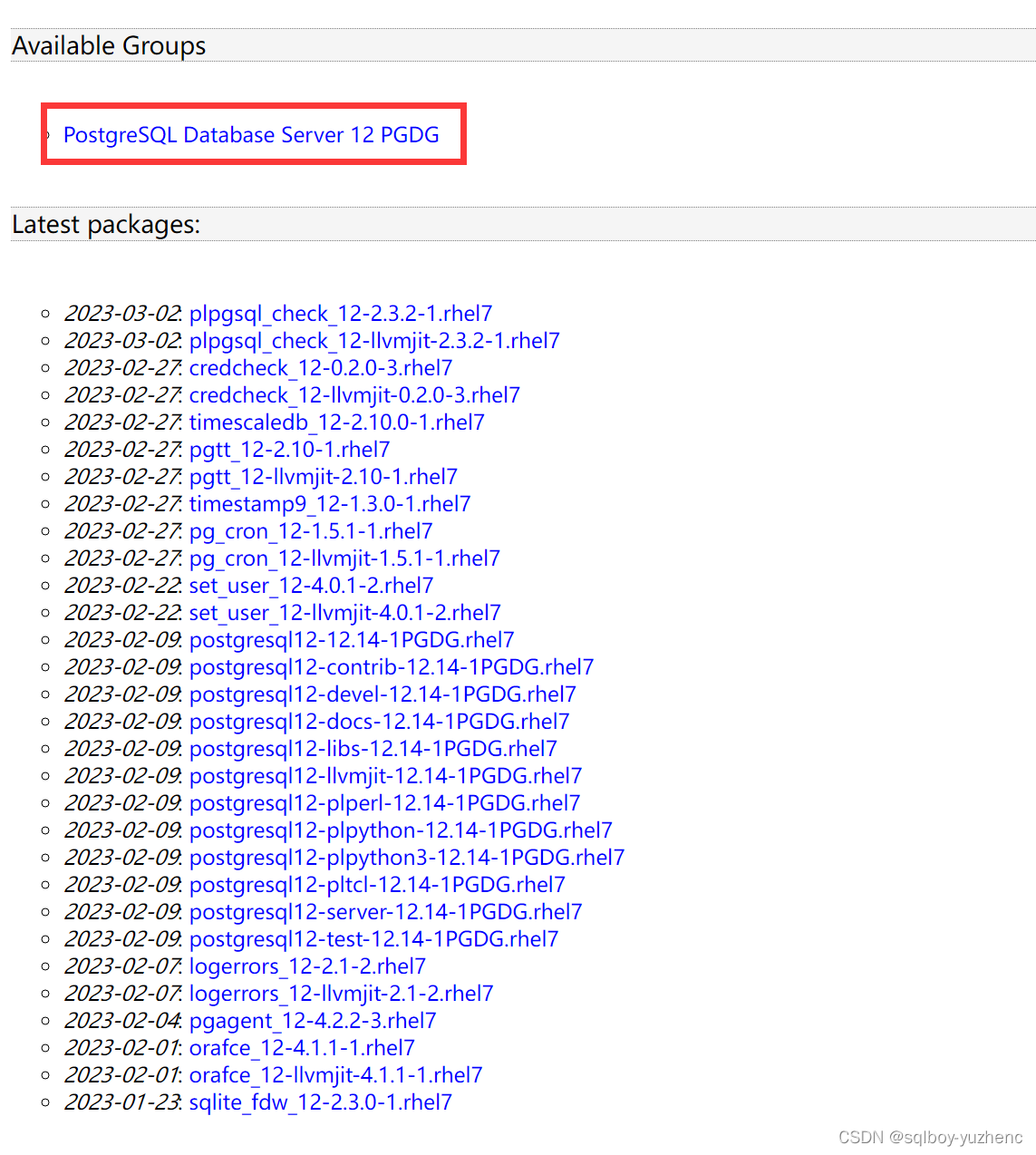
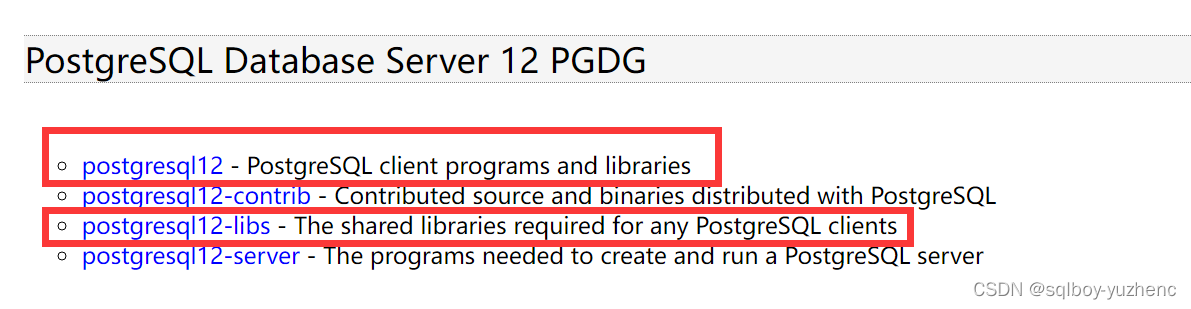
cd /opt
rz
rpm -ivh postgresql12-libs-12.11-1PGDG.rhel7.x86_64.rpm
rpm -ivh postgresql12-12.11-1PGDG.rhel7.x86_64.rpm
# 测试
psql etl -h 10.10.10.10 -p 5432 -U pgload -W
数据库用户
- Mysql
CREATE USER 'mysqlselect'@'%' IDENTIFIED BY '000000';
GRANT SELECT ON *.* TO 'mysqlselect'@'%';
- PG
--普通用户
create role yuzhenchao with login password '000000';
create schema yuzhenchao;
grant create,usage on schema yuzhenchao to yuzhenchao;
grant usage on schema yuzhenchao to public;
alter default privileges for role yuzhenchao revoke execute on functions from public;
alter default privileges in schema yuzhenchao revoke execute on functions from public;
alter default privileges in schema yuzhenchao grant select on tables to public;
alter default privileges for role yuzhenchao grant select on tables to public;
--集中用户(即专门用来做数据装载的用户)
create role pgload with login password '000000' connection limit 60;
create schema pgload;
grant create,usage on schema pgload to pgload;
grant usage on schema pgload to public;
alter default privileges for role pgload revoke execute on functions from public;
alter default privileges in schema pgload revoke execute on functions from public;
alter default privileges in schema pgload grant select on tables to public;
alter default privileges for role pgload grant select on tables to public;
--普通用户都要创建该函数
--为yuzhenchao用户创建sp_exec函数
create or replace function yuzhenchao.sp_exec(vsql varchar)
returns void --返回空
language plpgsql
security definer --定义者权限
as $function$
begin
execute vsql;
end;
$function$
;
alter function yuzhenchao.sp_exec(varchar) owner to yuzhenchao;
grant execute on function yuzhenchao.sp_exec(varchar) to yuzhenchao,pgload;
create or replace function pgload.sp_exec(vsql varchar)
returns void --返回空
language plpgsql
security definer --定义者权限
as $function$
begin
execute vsql;
end;
$function$
;
alter function pgload.sp_exec(varchar) owner to pgload;
grant execute on function pgload.sp_exec(varchar) to pgload;
--集中用户pgload创建该函数,新增用户则需要增加配置重新编译
create or replace function pgload.sp_execsql(exec_sql character varying,exec_user character varying)
returns void
language plpgsql
security definer
as $function$
/* 作者 : v-yuzhenc
* 功能 : 集中处理程序,以某用户的权限执行某条sql语句
* exec_sql : 需要执行的sql语句
* exec_user : 需要以哪个用户的权限执行该sql语句
* */
declare
p_user varchar := exec_user;
o_search_path varchar;
begin
--记录原来的模式搜索路径
execute 'show search_path;' into o_search_path;
--临时切换模式搜索路径
execute 'SET search_path TO '||p_user||',public,oracle';
case p_user
when 'yuzhenchao' then perform yuzhenchao.sp_exec(exec_sql);
when 'pgload' then perform pgload.sp_exec(exec_sql);
else raise exception '未配置该用户:%',p_user;
end case;
--恢复模式搜索路径
execute 'SET search_path TO '||o_search_path;
exception when others then
--恢复模式搜索路径
execute 'SET search_path TO '||o_search_path;
raise exception '%',sqlerrm;
end;
$function$
;
--将对应模式的对应模式的函数给对应的模式的拥有者
alter function pgload.sp_execsql(varchar,varchar) owner to pgload;
--将对应模式的sp_exec函数授权给定义者和集中用户execute权限
grant execute on function pgload.sp_execsql(varchar,varchar) to pgload;
导表脚本
dbmysql2pgmysqlcopy
#! /bin/bash
showuseage() {
echo "程序功能:mysql导出MYSQL数据库表,copy方式导入PG数据库
Useage: [dbmysql2pgmysqlcopy \${SCHEMANAME}.\${TABLENAME}]
-i [:可选,源数据库(MYSQL)帐号:username:passwd@hostname:port/dbname,默认定义在.bash_profile \${MYSQLID},不要出现这些字符:
冒号(:),艾特(@),空格( ),斜杠(/)]
-j [:可选,目标数据库(PG)帐号:username:passwd@hostname:port/dbname,默认定义在.bash_profile \${PGID},不要出现这些字符:
冒号(:),艾特(@),空格( ),斜杠(/)]
-o [:可选,指定需要导入到PG的schemaname,默认为MYSQL同名的schemaname(即MYSQL的数据库名)]
-f [:可选,可指定导入表名,常用于不同数据库或不同用户同一表名冲突、源表改名不影响后续应用、表名追加时间参数等情况,表名暂时限
定为:英文字母(不分大小写)、数字和任意组合,禁止使用特殊字符]
-8 [:可选,指定字符编码导出MYSQL数据,默认utf8]
-e [:可选,指定字符编码入库PG,默认utf8]
-u [:可选,指定表授权其他用户,指定且多个时使用逗号分开,如:'public'、'bss,apl',不要有空格]
-t [:可选,(test mod)调试模式,最多导出100行记录进行调试]
-a [:可选,指定where条件内容,如:'city_id in (0,755)'(无需转义)]
-c [:可选,不建表,直接导数据,表结构必须存在]
-z [:可选,导完表后的追加操作]
-I [:可选,过滤字段,建表时过滤掉过滤字段,逗号分隔,例如:serv_id,\"acc_nbr\"]
-s [:可选,指定字段,建表时只导指定的字段,逗号分隔,例如:serv_id,\"acc_nbr\"]
-d [:可选,指定字段特殊处理,原字段类型不变,字段处理后的值不能超出原来的精度,全角冒号顿号分隔,'字段名1:字段处理值1、字段名2:字段处理值2',
例如:COMPENSATETEXT:to_clob(COMPENSATETEXT)、update_time:to_date(to_char(update_time,'yyyymmdd hh24:mi:ss'),'yyyymmdd hh24:mi:ss')]
-v [:可选,指定某些字段对应PG的类型,全角冒号顿号分隔,字段名1:PG类型1、字段名2:PG类型2',例如:COMPENSATETEXT:text、update_time:date]"
}
# 退出之前删除临时文件
trap "rmtmpfile" EXIT
# 进度条程序
progress() {
M=0
local MAIN_PID=$1
local MAX_SECOND=14400
local SEP_SECOND=1
if [ -n "$2" ];then
SEP_SECOND=$2
fi
if [ -n "$3" ];then
MAX_SECOND=$3
fi
local MAX_SECOND=$[${MAX_SECOND}/${SEP_SECOND}]
while [ "$(ps -p ${MAIN_PID} | wc -l)" -ne "1" ] ; do
M=$[$M+1]
echo `date '+%Y-%m-%d %H:%M:%S'`"|WAIT|$M"
if [ $M -ge ${MAX_SECOND} ];then
echo `date '+%Y-%m-%d %H:%M:%S'`"|ERROR|后台程序处理超时"
kill $MAIN_PID
exit 2
fi
sleep ${SEP_SECOND}
done
}
function killPid(){
#根据程序的ppid获取程序的pid
PIDS=`ps -ef|awk '{if($3=='$1'){print $2} }'`;
#杀掉父程序的pid,防止子程序被杀掉后开启新的子程序
kill -s 9 $1
#如果获得了pid,则以已获得的pid作为ppid继续进行查找
if [ -n "$PIDS" ]; then
for PID in $PIDS
do
kill -9 $PID
done
fi
}
# 数据文件目录
CSVDIR=/data/etl/mysql2pg/csv
# 临时文件目录
TMPDIR=/data/etl/mysql2pg/tmp
# 日志目录
LOGDIR=/data/etl/mysql2pg/log
# 删除临时文件
rmtmpfile() {
# 删除临时文件
# PG装载生成的模板SQL
rm -f ${TMP_M2P_SQL}
# 模板SQL生成的PSQL脚本
rm -f ${TMP_M2P_PSQL}
# MYSQL抽取生成的模板SQL
rm -f ${TMP_TMP_SQL}
# 模板SQL生成的MYSQL抽取SQL
rm -f ${TMP_TMPO_SQL}
# csv文件路径
rm -f ${CSVFILEPATH}
# PGSQL执行日志
rm -f ${PSQL_EXEC_LOG}
# 关闭子进程
killPid $$
}
# 检测参数
# 没有参数直接退出
if [ $# -eq 0 ]
then
showuseage
exit -1
fi
# 限定第一个参数
PARAM1=$1
# 分析第一个参数中是否 - 开头
if [[ ${PARAM1} =~ ^-(.*?) ]]; then
#如果第一个参数第一个字符碰到-,
echo "dbmysql2pgmysqlcopy的第一个参数应为需要导入的MYSQL的表名!"
showuseage
exit -1
else
PARAM=${PARAM1}
fi
# MYSQL连接串
MYSQLDESC=${MYSQLID}
# PG连接串
PGDESC=${PGID}
# 调试模式
TESTMOD="-1"
# 条件
MYSQLCOND=" WHERE 1 = 1 "
# PG的schema
PGSCHEMA="-1"
# MYSQL的schema
MYSQLSCHEMA="-1"
# MYSQL的tablename
MYSQLTABLE="-1"
# PG的tablename
PGTNAME="-1"
# 授权用户
GRANTUSER="-1"
# 建表标记 默认建表
CREATEBJ="1"
# 追加操作
EXTRAOPT="-1"
# MYSQL导出编码
MYSQLENCODE="utf8"
# PG装载编码
PGENCODE="utf8"
# 字段忽略标记
IGNOREBJ="-1"
# 字段处理
COLUMNDEAL="-1"
# 指定类型
COLUMNTYPE="-1"
# 指定建为复制表
REPLICATEDBJ="-1"
# 日期处理标记
DATEFORMAT="-1"
# 指定字段
SPECIALCOLUMN="-1"
# 解析mysql表
PARAM=$1
ARRAY=(${PARAM//./ })
MYSQLSCHEMA=${ARRAY[0]}
MYSQLTABLE=${ARRAY[1]}
# 如果mysql表名被双引号包着,则直接去掉双引号
# 如果mysql表名没被双引号包着,则默认全部小写
if [[ "$MYSQLTABLE" =~ \"(.*?)\" ]];then
MYSQLTABLE=`echo ${MYSQLTABLE} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`
else
MYSQLTABLE=${MYSQLTABLE,,}
fi
# 如果mysql模式被双引号包着,则直接去掉双引号
# 如果mysql模式没被双引号包着,则默认小写
if [[ "$MYSQLSCHEMA" =~ \"(.*?)\" ]];then
MYSQLSCHEMA=`echo ${MYSQLSCHEMA} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`
else
MYSQLSCHEMA=${MYSQLSCHEMA,,}
fi
# 参数后移
shift
while getopts :i:j:f:o:8:e:u:t:a:cz:I:s:d:v: OPTS; do
case "$OPTS" in
i)
MYSQLDESC="$OPTARG"
;;
j)
PGDESC="$OPTARG"
;;
o)
PGSCHEMA="${OPTARG}"
;;
f)
PGTNAME="${OPTARG}"
;;
u)
GRANTUSER="${OPTARG}"
;;
t)
if [ $OPTARG -gt 0 -a $OPTARG -le 100 ];then
TESTMOD="$OPTARG"
fi
;;
a)
MYSQLCOND=`echo " WHERE $OPTARG" | sed "s/'/''/g"`
;;
c)
CREATEBJ=-1
;;
z)
EXTRAOPT="$OPTARG"
;;
8)
MYSQLENCODE="$OPTARG"
;;
e)
PGENCODE="$OPTARG"
;;
I)
IGNOREBJ="$OPTARG"
;;
s)
SPECIALCOLUMN="$OPTARG"
;;
d)
COLUMNDEAL="$OPTARG"
;;
v)
COLUMNTYPE="$OPTARG"
;;
:)
echo "$0 必须为 -$OPTARG 添加一个参数!"
exit -1
;;
?)
showuseage
exit -1
;;
esac
done
# 解析mysql连接串
ARRAY2=(${MYSQLDESC//@/ })
USERPWD=${ARRAY2[0]}
ARR4=(${USERPWD//:/ })
MYSQLUSER=${ARR4[0]}
MYSQLPWD=${ARR4[1]}
HPDB=${ARRAY2[1]}
ARR5=(${HPDB//:/ })
MYSQLHOST=${ARR5[0]}
PDB=${ARR5[1]}
ARR6=(${PDB//// })
MYSQLPORT=${ARR6[0]}
MYSQLDB=${ARR6[1]}
export MYSQL_PWD=$MYSQLPWD
MYSQLCONN="mysql -u$MYSQLUSER -h$MYSQLHOST -P$MYSQLPORT --database $MYSQLDB"
#分隔符
PGCSEP=","
PGQSEP='"'
PGESCAPE='\'
# 获取当前时间戳
TIMEST=`date +%Y%m%d%H%M%S`
# 日志路径
LOG_M2P_OUT=${LOGDIR}/m2p_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.out
# copy语句的输出路径
TMP_COPY_OUT=${TMPDIR}/copy_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.out
# PG装载生成的模板SQL
TMP_M2P_SQL=${TMPDIR}/m2p_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.sql
# 模板SQL生成的PSQL脚本
TMP_M2P_PSQL=${TMPDIR}/m2p_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.psql
# MYSQL抽取生成的模板SQL
TMP_TMP_SQL=${TMPDIR}/tmp_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.sql
# 模板SQL生成的MYSQL抽取SQL
TMP_TMPO_SQL=${TMPDIR}/tmpo_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.sql
# csv文件路径
CSVFILEPATH=${CSVDIR}/${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.csv
# PGSQL执行日志
PSQL_EXEC_LOG=${LOGDIR}/PG_${MYSQLSCHEMA}_${MYSQLTABLE}_$TIMEST.out
# 判断是否有表
tablebj=`${MYSQLCONN} -e "select 1 from information_schema.tables where table_name = '${MYSQLTABLE}' and table_schema = '${MYSQLSCHEMA}' union all select 1 from information_schema.views where table_name = '${MYSQLTABLE}' and table_schema = '${MYSQLSCHEMA}';" | sed '1d'`
if [ -z "$tablebj" ];then
echo `date '+%Y-%m-%d %H:%M:%S'`"|ERROR|表或视图不存在"
echo `date '+%Y-%m-%d %H:%M:%S'`"|ERROR|程序异常结束"
exit -1
fi
# 调试模式处理
if [ ! $TESTMOD = "-1" ];then
MYSQLCOND="${MYSQLCOND} limit ${TESTMOD}"
fi
# PGSCHEMA处理
# 如果PGSCHEMA等于"-1",则默认使用mysql同名schema
if [ "$PGSCHEMA" = "-1" ];then
PGSCHEMA=${MYSQLSCHEMA}
fi
# PGTNAME处理
# 如果PGTNAME等于"-1",则默认与源表同名
if [ "$PGTNAME" = "-1" ];then
PGTNAME=${MYSQLTABLE}
fi
# 如果PG表名被双引号包着,则直接去掉双引号
# 如果PG表名没被双引号包着,则转为小写
if [[ "$PGTNAME" =~ \"(.*?)\" ]];then
PGTNAME=`echo ${PGTNAME} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`
else
PGTNAME=${PGTNAME,,}
fi
# 如果PG模式被双引号包着,则直接去掉双引号
# 如果PG模式没被双引号包着,则转为小写
if [[ "$PGSCHEMA" =~ \"(.*?)\" ]];then
PGSCHEMA=`echo ${PGSCHEMA} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`
else
PGSCHEMA=${PGSCHEMA,,}
fi
# 解析PG连接串
ARRAY1=(${PGDESC//@/ })
USERPWD=${ARRAY1[0]}
ARR1=(${USERPWD//:/ })
PGUSER=${ARR1[0]}
PGPWD=${ARR1[1]}
HPDB=${ARRAY1[1]}
ARR2=(${HPDB//:/ })
PGHOST=${ARR2[0]}
PDB=${ARR2[1]}
ARR3=(${PDB//// })
PGPORT=${ARR3[0]}
PGDB=${ARR3[1]}
export PGPASSWORD="$PGPWD"
PGCONN="psql -d $PGDB -U $PGUSER -h $PGHOST -p $PGPORT"
# 格式化过滤字段
if [ "$IGNOREBJ" != "-1" ];then
IGNOREBJ_ARR=(${IGNOREBJ//,/ })
for I in "${!IGNOREBJ_ARR[@]}"
do
TMP=${IGNOREBJ_ARR[$I]}
if [[ "$TMP" =~ \"(.*?)\" ]];then
TMP="'`echo ${TMP} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`'"
else
TMP="'${TMP,,}'"
fi
if [ $I -eq 0 ];then
IGNOREBJ="$TMP"
else
IGNOREBJ="$TMP,${IGNOREBJ}"
fi
done
IGNOREBJ="column_name not in (${IGNOREBJ}) and "
else
IGNOREBJ=" "
fi
# 格式化指定字段
if [ "$SPECIALCOLUMN" != "-1" ];then
SPECIALCOLUMN_ARR=(${SPECIALCOLUMN//,/ })
for I in "${!SPECIALCOLUMN_ARR[@]}"
do
TMP=${SPECIALCOLUMN_ARR[$I]}
if [[ "$TMP" =~ \"(.*?)\" ]];then
TMP="'`echo ${TMP} | sed -e 's/^[\"]*//g' | sed -e 's/[\"]*$//g'`'"
else
TMP="'${TMP,,}'"
fi
if [ $I -eq 0 ];then
SPECIALCOLUMN="$TMP"
else
SPECIALCOLUMN="$TMP,${SPECIALCOLUMN}"
fi
done
SPECIALCOLUMN="column_name in (${SPECIALCOLUMN}) and "
else
SPECIALCOLUMN=" "
fi
# 判断PGUSER和PGSCHEMA是否一致
# 如果不一致,需要调用对方的权限执行psql
if [ "$PGUSER" = "$PGSCHEMA" ];then
USERSCHEMABJ="1"
else
USERSCHEMABJ="-1"
fi
# 创建日志
rm -f ${LOG_M2P_OUT}
touch ${LOG_M2P_OUT}
# 写入日志
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|导表准备开始" | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|拼接数据抽取脚本开始" | tee -a ${LOG_M2P_OUT}
rm -f ${TMP_TMP_SQL}
touch ${TMP_TMP_SQL}
rm -f ${TMP_TMPO_SQL}
touch ${TMP_TMPO_SQL}
#拼接导表语句
cat>${TMP_TMP_SQL}<<eof
select
'select ' dbsql
from
information_schema.tables
where
table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}';
eof
${MYSQLCONN} < ${TMP_TMP_SQL} | sed '1d' >> ${TMP_TMPO_SQL}
cat>${TMP_TMP_SQL}<<eof
select
columnname
from
(
select
concat(' ', case when ordinal_position = 1 then '' else ',' end, '\`', lower(column_name), '\`') columnname
,ordinal_position
from
information_schema.columns
where ${IGNOREBJ} ${SPECIALCOLUMN}
table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
order by
ordinal_position
) a;
eof
${MYSQLCONN} < ${TMP_TMP_SQL} | sed '1d' >> ${TMP_TMPO_SQL}
cat>${TMP_TMP_SQL}<<eof
select
'from \`${MYSQLSCHEMA}\`.\`${MYSQLTABLE}\`'
from
information_schema.tables
where
table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
union all
select
'${MYSQLCOND}'
from
information_schema.tables
where
table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}';
eof
${MYSQLCONN} < ${TMP_TMP_SQL} | sed '1d' >> ${TMP_TMPO_SQL}
#字段特殊处理替换
#COMPENSATETEXT:to_clob(COMPENSATETEXT)、update_time:to_date(to_char(update_time,'yyyymmdd hh24:mi:ss'),'yyyymmdd hh24:mi:ss')
COLUMNNAME=""
ORIGINROW=""
REPLACEROW=""
REPLACEROWNUM=""
OLD_IFS="$IFS"
if [ "$COLUMNDEAL" != "-1" ];then
IFS="、"
COLUMNDEAL_ARRAY=(${COLUMNDEAL})
for I in "${!COLUMNDEAL_ARRAY[@]}"
do
ORIGINROW=""
REPLACEROW=""
TMP=${COLUMNDEAL_ARRAY[$I]}
IFS=":"
TMP_ARRAY=(${TMP})
for J in "${!TMP_ARRAY[@]}"
do
TMP1=${TMP_ARRAY[$J]}
if [ $J -eq 0 ];then
if [[ "$TMP1" =~ \"(.*?)\" ]];then
COLUMNNAME=${TMP1}
ORIGINROW=" ,\`${TMP1}\`"
else
COLUMNNAME="\`${TMP1,,}\`"
ORIGINROW=" ,\`${TMP1,,}\`"
fi
else
REPLACEROW="${REPLACEROW}${TMP1}"
if [ $J -eq $[${#TMP_ARRAY[*]}-1] ];then
REPLACEROW=${REPLACEROW}' AS '${COLUMNNAME}
fi
fi
done
REPLACEROWNUM=`awk "/${ORIGINROW}/{print NR;exit;}" ${TMP_TMPO_SQL}`
if [ ${REPLACEROWNUM} -eq 2 ];then
REPLACEROW=' '$REPLACEROW
else
REPLACEROW=' ,'$REPLACEROW
fi
ORIGINROW=`sed -n "${REPLACEROWNUM}p" ${TMP_TMPO_SQL}`
#双引号和斜杠转义
ORIGINROW=${ORIGINROW//\"/\\\"}
REPLACEROW=${REPLACEROW//\"/\\\"}
ORIGINROW=${ORIGINROW//\//\\\/}
REPLACEROW=${REPLACEROW//\//\\\/}
sed -i "s/$ORIGINROW/$REPLACEROW/g" ${TMP_TMPO_SQL}
done
fi
IFS="$OLD_IFS"
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|拼接数据抽取脚本完成" | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|输出MYSQL脚本" | tee -a ${LOG_M2P_OUT}
cat ${TMP_TMPO_SQL} | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|拼接PG的数据装载脚本开始" | tee -a ${LOG_M2P_OUT}
rm -f ${TMP_M2P_SQL}
touch ${TMP_M2P_SQL}
cat>${TMP_M2P_SQL}<<EOF
select
case when '${USERSCHEMABJ}' = '-1' then 'select pgload.sp_execsql(\$\$' else '--自己导表无须调用pgload' end psql
from dual
union all
select 'drop table if exists "${PGSCHEMA}"."m2p_${PGTNAME}";' psql
from information_schema.tables
where table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
union all
select 'create table "${PGSCHEMA}"."m2p_${PGTNAME}" ('
from information_schema.tables
where table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
select columnname
from (
select concat(' ',case when ordinal_position = 1 then '' else ',' end,'"',lower(column_name),'"',' ',
case when data_type = 'int' then data_type
when data_type = 'varchar' then replace (column_type,'varchar(0)','varchar(1)')
when data_type = 'char' then replace(replace(column_type,'char','varchar'),'varchar(0)','varchar(1)')
when data_type = 'date' then 'date'
when data_type = 'datetime' then replace (column_type, data_type, 'timestamp')
when data_type = 'timestamp' then 'timestamp'
when data_type = 'bigint' then 'bigint'
when data_type = 'double' then 'double precision'
when data_type = 'smallint' then 'smallint'
when data_type = 'decimal' then replace (column_type,'unsigned zerofill','')
when data_type = 'longtext' then 'text'
when data_type = 'text' then 'text'
when data_type = 'tinyint' then 'int'
when data_type = 'longblob' then 'bytea'
when data_type = 'blob' then 'bytea'
when data_type = 'float' then 'real'
when data_type = 'tinytext' then 'text'
when data_type = 'mediumtext' then 'text'
when data_type = 'numeric' then 'numeric'
when data_type = 'time' then 'interval'
else 'varchar'
end
) columnname
,ordinal_position
from information_schema.columns
where ${IGNOREBJ} ${SPECIALCOLUMN} table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
order by ordinal_position
) a;
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
select PGPRI from (
select
case when primarykey is not null then concat(' ,primary key (',primarykey,'));') else '); ' end PGPRI
from (
select
group_concat(case when column_key = 'PRI' then concat('"',lower(column_name),'"') else null end order by ORDINAL_POSITION separator ',') primarykey
from information_schema.tables a, information_schema.columns b
where a.table_name = b.table_name
and a.table_schema = b.table_schema
and a.table_name = '${MYSQLTABLE}'
and a.table_schema = '${MYSQLSCHEMA}'
group by table_rows
) a
) a
union all
select
concat('comment on table "${PGSCHEMA}"."m2p_${PGTNAME}" is ''',replace(table_comment,'''',''''''),''';')
from information_schema.tables
where table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
and table_comment != ''
and table_comment is not null
union all
select
concat('comment on column "${PGSCHEMA}"."m2p_${PGTNAME}"."',lower(column_name),'" is ''',replace(column_comment,'''',''''''),''';')
from information_schema.columns
where table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
and column_comment != ''
and column_comment is not null
UNION ALL
select
'\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where
'${USERSCHEMABJ}' = '-1'
union all
select
'select pgload.sp_execsql(\$\$grant insert on table "${PGSCHEMA}"."m2p_${PGTNAME}" to "${PGUSER}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where
'${USERSCHEMABJ}' = '-1';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>>${TMP_M2P_PSQL}<<eof
\\copy "${PGSCHEMA}"."m2p_${PGTNAME}" FROM '${CSVFILEPATH}' WITH ( FORMAT csv,HEADER true,DELIMITER '${PGCSEP}',QUOTE '${PGQSEP}',ESCAPE '${PGESCAPE}');
eof
cat>${TMP_M2P_SQL}<<EOF
select
'select pgload.sp_execsql(\$\$' pgsql
from
dual
where
'${USERSCHEMABJ}' = '-1'
and '${CREATEBJ}' = '-1'
union all
select
'insert into "${PGSCHEMA}"."${PGTNAME}" (' insertsql
from
information_schema.tables
where
table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
and '${CREATEBJ}' = '-1';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
select
columnname
from
(
select
concat(' ', case when ordinal_position = 1 then '' else ',' end, '"', lower(column_name), '"') columnname
,ordinal_position
from
information_schema.columns
where ${IGNOREBJ} ${SPECIALCOLUMN}
table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
order by
ordinal_position
) a
where '${CREATEBJ}' = '-1';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
select
')' insertsql
from
information_schema.tables
where
table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
and '${CREATEBJ}' = '-1'
union all
select
'select ' insertsql
from
information_schema.tables
where
table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
and '${CREATEBJ}' = '-1';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
select
columnname
from
(
select
concat(' ', case when ordinal_position = 1 then '' else ',' end, '"', lower(column_name), '"') columnname
,ordinal_position
from
information_schema.columns
where ${IGNOREBJ} ${SPECIALCOLUMN}
table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
order by
ordinal_position
) a
where '${CREATEBJ}' = '-1';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
cat>${TMP_M2P_SQL}<<EOF
select
'from "${PGSCHEMA}"."m2p_${PGTNAME}";'
from
information_schema.tables
where
table_name = '${MYSQLTABLE}'
and table_schema = '${MYSQLSCHEMA}'
and '${CREATEBJ}' = '-1'
union all
select
'\$\$,\$\$${PGSCHEMA}\$\$);'
from
dual
where
'${USERSCHEMABJ}' = '-1'
and '${CREATEBJ}' = '-1'
union all
select
'drop table if exists "${PGSCHEMA}"."${PGTNAME}";'
from dual
where '${CREATEBJ}' = '1'
and '${USERSCHEMABJ}' = '1'
union all
select
'select pgload.sp_execsql(\$\$drop table if exists "${PGSCHEMA}"."${PGTNAME}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${CREATEBJ}' = '1'
and '${USERSCHEMABJ}' = '-1'
union all
select
'alter table "${PGSCHEMA}"."m2p_${PGTNAME}" rename to "${PGTNAME}";'
from dual
where '${CREATEBJ}' = '1'
and '${USERSCHEMABJ}' = '1'
union all
select
'select pgload.sp_execsql(\$\$alter table "${PGSCHEMA}"."m2p_${PGTNAME}" rename to "${PGTNAME}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${CREATEBJ}' = '1'
and '${USERSCHEMABJ}' = '-1'
union all
select
'drop table if exists "${PGSCHEMA}"."m2p_${PGTNAME}";'
from dual
where '${CREATEBJ}' = '-1'
and '${USERSCHEMABJ}' = '1'
union all
select
'select pgload.sp_execsql(\$\$drop table if exists "${PGSCHEMA}"."m2p_${PGTNAME}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${CREATEBJ}' = '-1'
and '${USERSCHEMABJ}' = '-1'
union all
select
'grant select on table "${PGSCHEMA}"."${PGTNAME}" to ${GRANTUSER};'
from dual
where '${GRANTUSER}' <> '-1'
and '${USERSCHEMABJ}' = '1'
union all
select
'select pgload.sp_execsql(\$\$grant select on table "${PGSCHEMA}"."${PGTNAME}" to "${GRANTUSER}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${GRANTUSER}' <> '-1'
and '${USERSCHEMABJ}' = '-1'
union all
select
'${EXTRAOPT}'
from dual
where '${EXTRAOPT}' <> '-1'
and '${USERSCHEMABJ}' = '1'
union all
select
'select pgload.sp_execsql(\$\$${EXTRAOPT}\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${EXTRAOPT}' <> '-1'
and '${USERSCHEMABJ}' = '-1'
union all
select
'analyze "${PGSCHEMA}"."${PGTNAME}";'
from dual
where '${USERSCHEMABJ}' = '1'
union all
select
'select pgload.sp_execsql(\$\$analyze "${PGSCHEMA}"."${PGTNAME}";\$\$,\$\$${PGSCHEMA}\$\$);'
from dual
where '${USERSCHEMABJ}' = '-1';
EOF
${MYSQLCONN} < ${TMP_M2P_SQL} | sed '1d' >> ${TMP_M2P_PSQL}
#指定字段类型
OLD_IFS="$IFS"
if [ "$COLUMNTYPE" != "-1" ];then
IFS="、"
COLUMNTYPE_ARRAY=(${COLUMNTYPE})
for I in "${!COLUMNTYPE_ARRAY[@]}"
do
ORIGINROW=""
REPLACEROW=""
TMP=${COLUMNTYPE_ARRAY[$I]}
IFS=":"
TMP_ARRAY=(${TMP})
for J in "${!TMP_ARRAY[@]}"
do
TMP1=${TMP_ARRAY[$J]}
if [ $J -eq 0 ];then
if [[ "$TMP1" =~ \"(.*?)\" ]];then
COLUMNNAME=${TMP1}
ORIGINROW=",${TMP1}"
else
COLUMNNAME="\"${TMP1,,}\""
ORIGINROW=",\"${TMP1,,}\""
fi
else
REPLACEROW="${REPLACEROW}${TMP1}"
if [ $J -eq $[${#TMP_ARRAY[*]}-1] ];then
REPLACEROW="${COLUMNNAME} ${REPLACEROW}"
fi
fi
done
REPLACEROWNUM=`awk "/${COLUMNNAME}/{print NR;exit;}" ${TMP_M2P_PSQL}`
if [ $REPLACEROWNUM -eq 4 ];then
REPLACEROW=' '$REPLACEROW
else
REPLACEROW=' ,'$REPLACEROW
fi
ORIGINROW=`sed -n "${REPLACEROWNUM}p" ${TMP_M2P_PSQL}`
#双引号和斜杠转义
ORIGINROW=${ORIGINROW//\"/\\\"}
REPLACEROW=${REPLACEROW//\"/\\\"}
ORIGINROW=${ORIGINROW//\//\\\/}
REPLACEROW=${REPLACEROW//\//\\\/}
#echo $ORIGINROW
#echo $REPLACEROW
#echo $REPLACEROWNUM
sed -i "s/$ORIGINROW/$REPLACEROW/g" ${TMP_M2P_PSQL}
done
fi
IFS="$OLD_IFS"
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|拼接PG的数据装载脚本完成" | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|输出PSQL脚本" | tee -a ${LOG_M2P_OUT}
cat ${TMP_M2P_PSQL} | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|导表准备完成" | tee -a ${LOG_M2P_OUT}
#开始抽取数据
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|从MYSQL抽取数据开始" | tee -a ${LOG_M2P_OUT}
rm -f ${CSVFILEPATH}
touch ${CSVFILEPATH}
extractmysqldata(){
${MYSQLCONN} < ${TMP_TMPO_SQL} | sed "s/\x00//g;s/\\\n/\n/g;s/${PGQSEP}/\\""${PGESCAPE}${PGQSEP}/g;s/\t/${PGQSEP}${PGCSEP}${PGQSEP}/g;s/^/${PGQSEP}&/g;s/$/&${PGQSEP}/g;s/${PGQSEP}NULL${PGQSEP}//g;s/${PGQSEP}${PGQSEP}//g;s/\\\t/\t/g" > ${CSVFILEPATH}
}
extractmysqldata &
EXTRACTMYSQLDATA_PID=$(jobs -p | tail -1)
progress "${EXTRACTMYSQLDATA_PID}" &
EXTRACTMYSQLDATA_PPID=$(jobs -p | tail -1)
wait "${EXTRACTMYSQLDATA_PID}"
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|从MYSQL抽取数据完成" | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|在PG中装载数据开始" | tee -a ${LOG_M2P_OUT}
loadmysqldata(){
#执行psql建表脚本
${PGCONN} >>${PSQL_EXEC_LOG} 2>&1 <<PSQL
\set ECHO all
\timing on
\! echo `date "+%Y %m %d %H:%M:%S"`
\i ${TMP_M2P_PSQL}
\! echo `date "+%Y %m %d %H:%M:%S"`
PSQL
}
loadmysqldata &
LOADMYSQLDATA_PID=$(jobs -p | tail -1)
progress "${LOADMYSQLDATA_PID}" &
LOADMYSQLDATA_PPID=$(jobs -p | tail -1)
wait "${LOADMYSQLDATA_PID}"
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|在PG中装载数据完成" | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|输出装载日志" | tee -a ${LOG_M2P_OUT}
cat ${PSQL_EXEC_LOG} | tee -a ${LOG_M2P_OUT}
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|导表日志:${LOG_M2P_OUT}" | tee -a ${LOG_M2P_OUT}
#获取PG装载的记录数
ERRORBJ=`cat ${LOG_M2P_OUT} | grep '^psql:' | grep -E 'FATAL:|ERROR:' | wc -l`
if [ ${ERRORBJ} -ne 0 ];then
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|数据导入失败" | tee -a ${LOG_M2P_OUT}
exit -1
else
PGNUM=`awk '{if($1=="COPY") print $2}' ${PSQL_EXEC_LOG}`
echo `date '+%Y-%m-%d %H:%M:%S'`"|INFO|数据导入成功:${PGNUM}" | tee -a ${LOG_M2P_OUT}
fi
测试
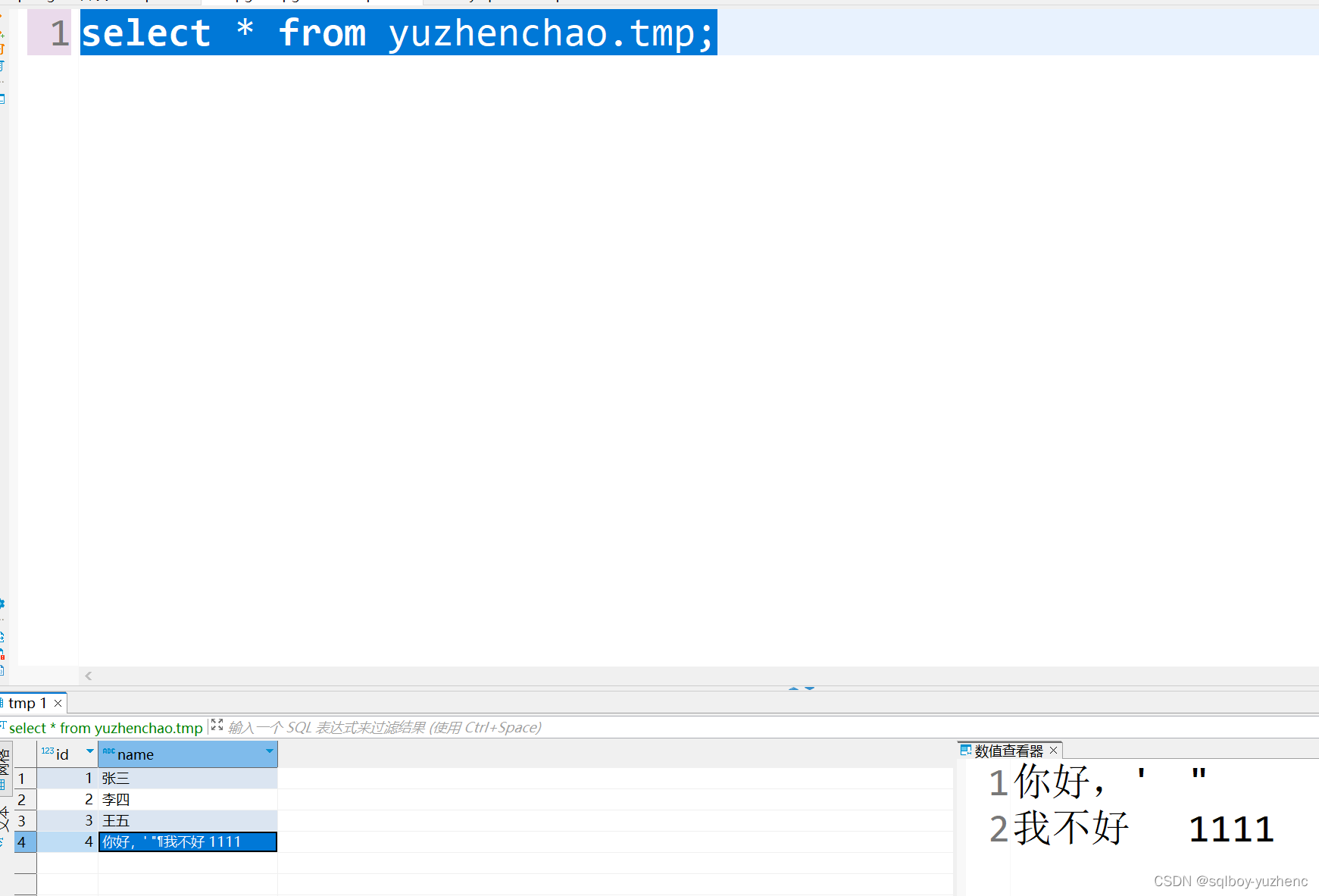
在mysql中建表
create table tmp (
id int primary key comment '主键'
,name varchar(50) comment '姓名'
);
insert into tmp values (1,'张三');
insert into tmp values (2,'李四');
insert into tmp values (3,'王五');
insert into tmp values (4,'你好,'' "
我不好 1111');

导表测试
[root@yzcdb-2 ~]# su - pgload
Last login: Tue Mar 7 08:56:24 CST 2023 on pts/0
[pgload@yzcdb-2 ~]$ dbmysql2pgmysqlcopy etl.tmp -o yuzhenchao
2023-03-07 14:02:12|INFO|导表准备开始
2023-03-07 14:02:12|INFO|拼接数据抽取脚本开始
2023-03-07 14:02:12|INFO|拼接数据抽取脚本完成
2023-03-07 14:02:12|INFO|输出MYSQL脚本
select
`id`
,`name`
from `etl`.`tmp`
WHERE 1 = 1
2023-03-07 14:02:12|INFO|拼接PG的数据装载脚本开始
2023-03-07 14:02:12|INFO|拼接PG的数据装载脚本完成
2023-03-07 14:02:12|INFO|输出PSQL脚本
select pgload.sp_execsql($$
drop table if exists "yuzhenchao"."m2p_tmp";
create table "yuzhenchao"."m2p_tmp" (
"id" int
,"name" varchar(50)
,primary key ("id"));
comment on column "yuzhenchao"."m2p_tmp"."id" is '主键';
comment on column "yuzhenchao"."m2p_tmp"."name" is '姓名';
$$,$$yuzhenchao$$);
select pgload.sp_execsql($$grant insert on table "yuzhenchao"."m2p_tmp" to "pgload";$$,$$yuzhenchao$$);
\copy "yuzhenchao"."m2p_tmp" FROM '/data/etl/mysql2pg/csv/etl_tmp_20230307140212.csv' WITH ( FORMAT csv,HEADER true,DELIMITER ',',QUOTE '"',ESCAPE '\');
select pgload.sp_execsql($$drop table if exists "yuzhenchao"."tmp";$$,$$yuzhenchao$$);
select pgload.sp_execsql($$alter table "yuzhenchao"."m2p_tmp" rename to "tmp";$$,$$yuzhenchao$$);
select pgload.sp_execsql($$analyze "yuzhenchao"."tmp";$$,$$yuzhenchao$$);
2023-03-07 14:02:12|INFO|导表准备完成
2023-03-07 14:02:12|INFO|从MYSQL抽取数据开始
2023-03-07 14:02:12|WAIT|1
2023-03-07 14:02:12|INFO|从MYSQL抽取数据完成
2023-03-07 14:02:12|INFO|在PG中装载数据开始
2023-03-07 14:02:13|WAIT|1
2023-03-07 14:02:13|INFO|在PG中装载数据完成
2023-03-07 14:02:13|INFO|输出装载日志
\timing on
Timing is on.
\! echo 2023 03 07 14:02:12
2023 03 07 14:02:12
\i /data/etl/mysql2pg/tmp/m2p_etl_tmp_20230307140212.psql
select pgload.sp_execsql($$
drop table if exists "yuzhenchao"."m2p_tmp";
create table "yuzhenchao"."m2p_tmp" (
"id" int
,"name" varchar(50)
,primary key ("id"));
comment on column "yuzhenchao"."m2p_tmp"."id" is '主键';
comment on column "yuzhenchao"."m2p_tmp"."name" is '姓名';
$$,$$yuzhenchao$$);
psql:/data/etl/mysql2pg/tmp/m2p_etl_tmp_20230307140212.psql:9: NOTICE: table "m2p_tmp" does not exist, skipping
sp_execsql
------------
(1 row)
Time: 17.889 ms
select pgload.sp_execsql($$grant insert on table "yuzhenchao"."m2p_tmp" to "pgload";$$,$$yuzhenchao$$);
sp_execsql
------------
(1 row)
Time: 1.558 ms
\copy "yuzhenchao"."m2p_tmp" FROM '/data/etl/mysql2pg/csv/etl_tmp_20230307140212.csv' WITH ( FORMAT csv,HEADER true,DELIMITER ',',QUOTE '"',ESCAPE '\');
COPY 4
Time: 32.051 ms
select pgload.sp_execsql($$drop table if exists "yuzhenchao"."tmp";$$,$$yuzhenchao$$);
sp_execsql
------------
(1 row)
Time: 3.049 ms
select pgload.sp_execsql($$alter table "yuzhenchao"."m2p_tmp" rename to "tmp";$$,$$yuzhenchao$$);
sp_execsql
------------
(1 row)
Time: 1.687 ms
select pgload.sp_execsql($$analyze "yuzhenchao"."tmp";$$,$$yuzhenchao$$);
sp_execsql
------------
(1 row)
Time: 1.848 ms
\! echo 2023 03 07 14:02:13
2023 03 07 14:02:13
2023-03-07 14:02:13|INFO|导表日志:/data/etl/mysql2pg/log/m2p_etl_tmp_20230307140212.out
2023-03-07 14:02:13|INFO|数据导入成功:4
Killed
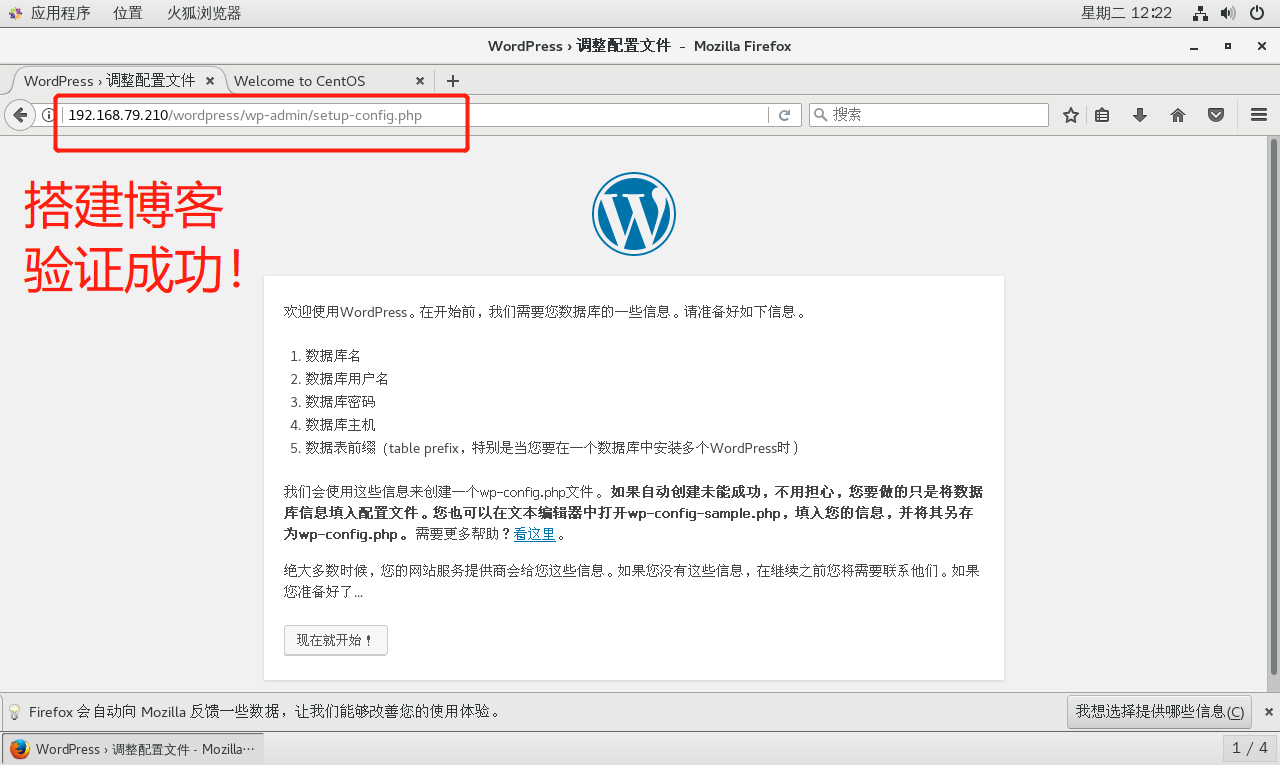
查看pg中的表







![[Python图像处理] 使用高通滤波器实现同态滤波](https://img-blog.csdnimg.cn/08769ddf988f48c88680b9ef14202be3.png#pic_center)