题目目录
- 1.简述DNS分离解析的工作原理,关键配置
- 2.apache有几种工作模式,分别简述两种工作模式及其优缺点?
- 3.写出172.0.0.38/27 的网络id与广播地址
- 4.写出下列服务使用的传输层协议(TCP/UDP)及默认端口
- 5.在局域网想获得192.168.1.2的MAC地址,在系统中如何操作?
- 6.TCP通信建立在连接的基础上,TCP连接的建立要使用( )次握手的过程,需要经过( )次断开的过程?
- 7. TCP和UDP的区别
- 8.TCP对应的应用层协议有哪些? UDP对应的应用层协议有哪些?
- 9.访问百度网站,有什么方法可以跟踪经过了哪些网络节点?
- 10. 使用awk统计httpd访问日志中每个客户端IP的出现次数?
- 11.正则表达式符号: *、+、?、[]、[^]、{n}分别代表什么含义?
- 12.Shell中对变量字串进行截取的方式有哪些?
- 13. 编写脚本,自动生成一个8位随机密码?
- 14.从日志/opt/bjca3/logs/ca_access.log中截取14点到16点的日志,将截取的日志导入到/tmp/ca_access.txt中,日志格式如下
- 15.编写脚本使用ping命令检测一组IP地址判断是否处于活跃状态。
- 16.如何查看httpd访问日志文件access.log中哪个IP访问最多?
- 17.如何修改Linux内核参数,调整进程可以打开的最大文件数量?
- 18. 如何将一个源码包软件转换称为一个RPM软件包?
- 19.简述什么是CDN?
- 20.用什么命令可以查看上一次服务器启动时间、上一次谁登陆过服务器?
- 21.Linux系统路由的查看和添加使用什么命令?
- 22.下面哪条命令用来显示一个程序所使用的库文件?
- 23.Nginx配置文件中location匹配数据的优先级?
- 24.怎么监控Tomcat的内存使用情况?
- 25.nginx的优化你都做过哪些?
- 26.Tomcat你做过哪些优化?
- 27.关于nginx access模块的面试题?
- 28.Nginx防盗链,防止其他网址链接我的图片或视频资源?
- 29.如何加强MySQL安全,请给出可行的具体措施?
- 30.MySQL数据库cpu飙升到500%的话他怎么处理?
- 31.请写出创建存储过程的语法格式?
- 32.请描述下列命令在配置MHA集群时的作用?
- 33.存储过程与函数的区别?
- 34.请阐述MySQL服务有哪些日志文件?
- 35.请阐述MySQL主从同步复制的工作过程?
- 36.MySQL主从原理?
- 37.MySQL主从复制存在哪些问题?
- 38.主从延迟产生的原因及解决方案?
- 39.判断主从延迟的方法?
- 40.Binlog工作模式有哪些?各什么特点,企业如何选择?
- 41.生产一主多从从库宕机,如何手工恢复?
- 42.误执行drop数据,如何通过xtrabackup恢复?
- 43.如何做主从数据一致性校验?
- 44.MySQL的MHA如何实现?
- 45.redis数据持久化的2种方式分别是什么?
- 46.简述redis支持的数据类型 (至少3种)?
- 47.请在横线处填写符合题意的答案?
- 48.什么是缓存雪崩?
- 49.什么是缓存穿透?
- 50.什么是缓存击穿?
1.简述DNS分离解析的工作原理,关键配置
答案:
DNS分离解析:针对同一个域名,为不同的客户机提供不同的解析结果
关键配置:通过view语句为客户端分类,在每个视图内使用match-client来匹配客户机的来源地址,每
个视图内都定义目标DNS区域但调用不同的地址库文件
2.apache有几种工作模式,分别简述两种工作模式及其优缺点?
答案:
Prefork、Worker和Event
Prefork模式为Apache默认使用的工作模式,在该模式下,采用的机制是预派生子进程的方式,使用单
独的进程来处理不同的请求,适合于小访问量的业务场景。
Worker模式使用不同的线程来处理不同的客户端请求,控制进程在启动后,根据配置文件中的
ThreadsPerChild值得大小,在进程下启动相应的线程数,这些线程并发的处理客户端的请求。
类似于worker的工作模式,最大区别是它解决了keep-alive场景下,长期被占用的线程的资源的浪费问题;
event模式下,会有一个专门的线程来管理这些keep-alive类型的线程,当有真实的请求过来的时
候,将请求传递给服务线程,执行完毕又允许它释放
httpd -V |grep -i “Server MPM”(查看工作模式)
3.写出172.0.0.38/27 的网络id与广播地址
/27的掩码对应的十进制方式掩码为255.255.255.224,编译成二进制为11111111.11111111.11111111.11100000,可以看出能变动的主机位为5位,所以一个子网最多能容纳主机为 2^5=32台,去掉前后的网络号和广播号,可用的主机数为30台。172.16.22.0这段地址按32个地址割接,可分为:
172.16.22.0-172.16.22.31
172.16.22.32-172.16.22.63
…
172.16.22.38位于172.16.22.32-172.16.22.63这一段内,所以它的网络好是172.16.22.32,广播号是172.16.22.63
4.写出下列服务使用的传输层协议(TCP/UDP)及默认端口
pop3、imap、smtp、dns、windows远程、DHCP、mysql
答案:
pop3 tcp 110
imap tcp 143
smtp tcp 25
dns tcp 53、udp 53
windows远程终端服务 (mstsc) tcp 3389
DHCP 服务端udp 67 客户端udp 68
mysql tcp 3306
5.在局域网想获得192.168.1.2的MAC地址,在系统中如何操作?
答案:
因为有arp协议可以根据ip地址解析mac地址,所以使用ping测试对方后输入 arp -a 即可查询arp缓存表
而得到mac地址。
6.TCP通信建立在连接的基础上,TCP连接的建立要使用( )次握手的过程,需要经过( )次断开的过程?
答案:
3,4
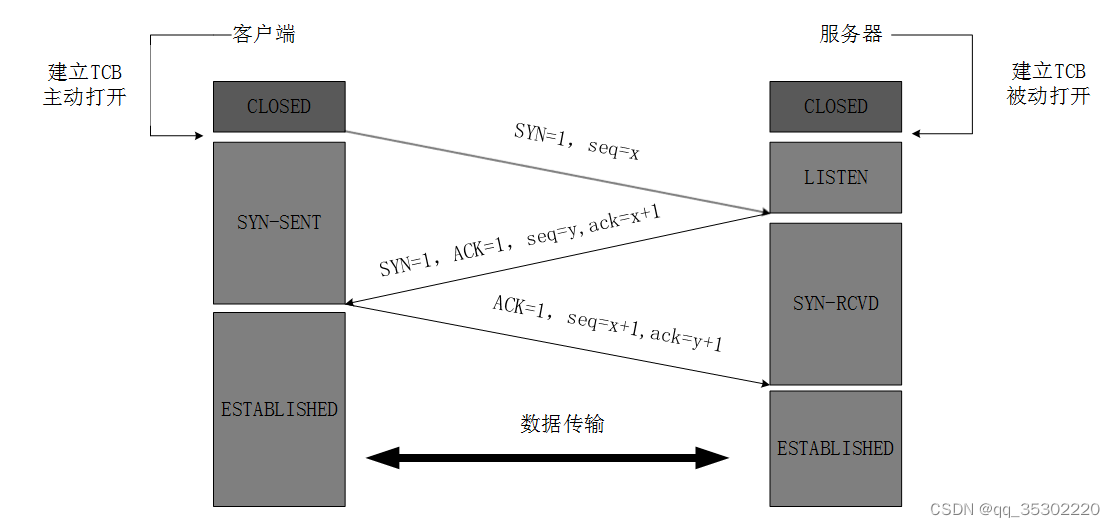
TCP连接的建立(三次握手)

最开始的时候客户端和服务器都是处于CLOSED状态。主动打开连接的为客户端,被动打开连接的是服务器。
1.TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态;
2.TCP客户进程也是先创建传输控制块TCB,然后向服务器发出连接请求报文,这是报文首部中的同部位SYN=1,同时选择一个初始序列号 seq=x ,此时,TCP客户端进程进入了 SYN-SENT(同步已发送状态)状态。TCP规定,SYN报文段(SYN=1的报文段)不能携带数据,但需要消耗掉一个序号。
3.TCP服务器收到请求报文后,如果同意连接,则发出确认报文。确认报文中应该 ACK=1,SYN=1,确认号是ack=x+1,同时也要为自己初始化一个序列号 seq=y,此时,TCP服务器进程进入了SYN-RCVD(同步收到)状态。这个报文也不能携带数据,但是同样要消耗一个序号。
4.TCP客户进程收到确认后,还要向服务器给出确认。确认报文的ACK=1,ack=y+1,自己的序列号seq=x+1,此时,TCP连接建立,客户端进入ESTABLISHED(已建立连接)状态。TCP规定,ACK报文段可以携带数据,但是如果不携带数据则不消耗序号。
5.当服务器收到客户端的确认后也进入ESTABLISHED状态,此后双方就可以开始通信了。
为什么TCP客户端最后还要发送一次确认呢?
一句话,主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。
如果使用的是两次握手建立连接,假设有这样一种场景,客户端发送了第一个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了,由于TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数据,然后关闭连接。此时此前滞留的那一次请求连接,网络通畅了到达了服务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务器再次建立连接,这将导致不必要的错误和资源的浪费。
如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由于服务器收不到确认,就知道客户端并没有请求连接。
TCP连接的释放(四次挥手)
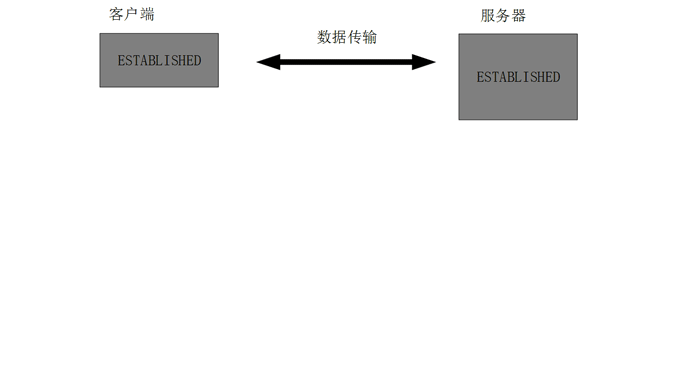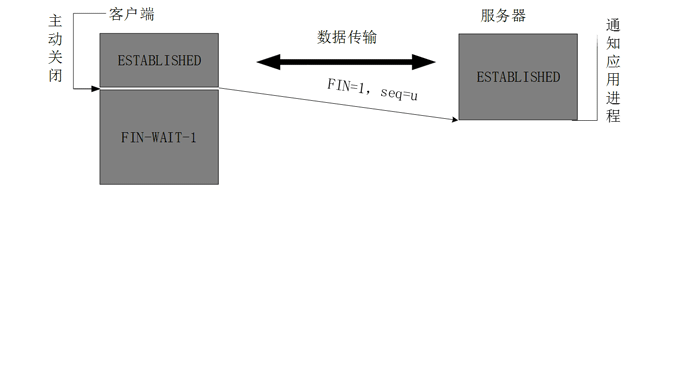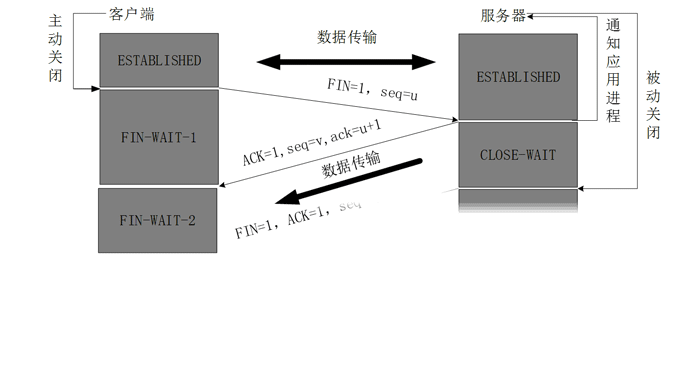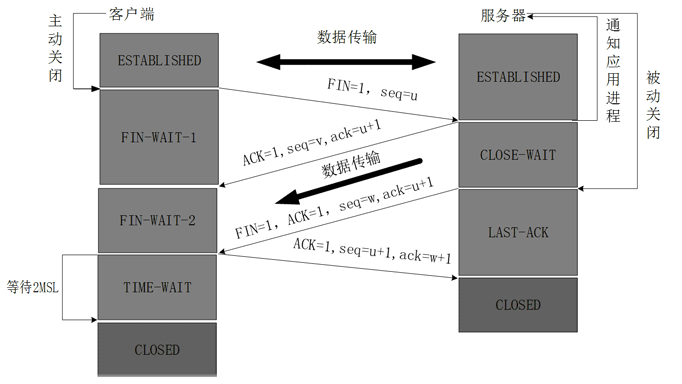
数据传输完毕后,双方都可释放连接。最开始的时候,客户端和服务器都是处于ESTABLISHED状态,然后客户端主动关闭,服务器被动关闭。
-
客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
-
服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
-
客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
-
服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
-
客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗ *∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
-
服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
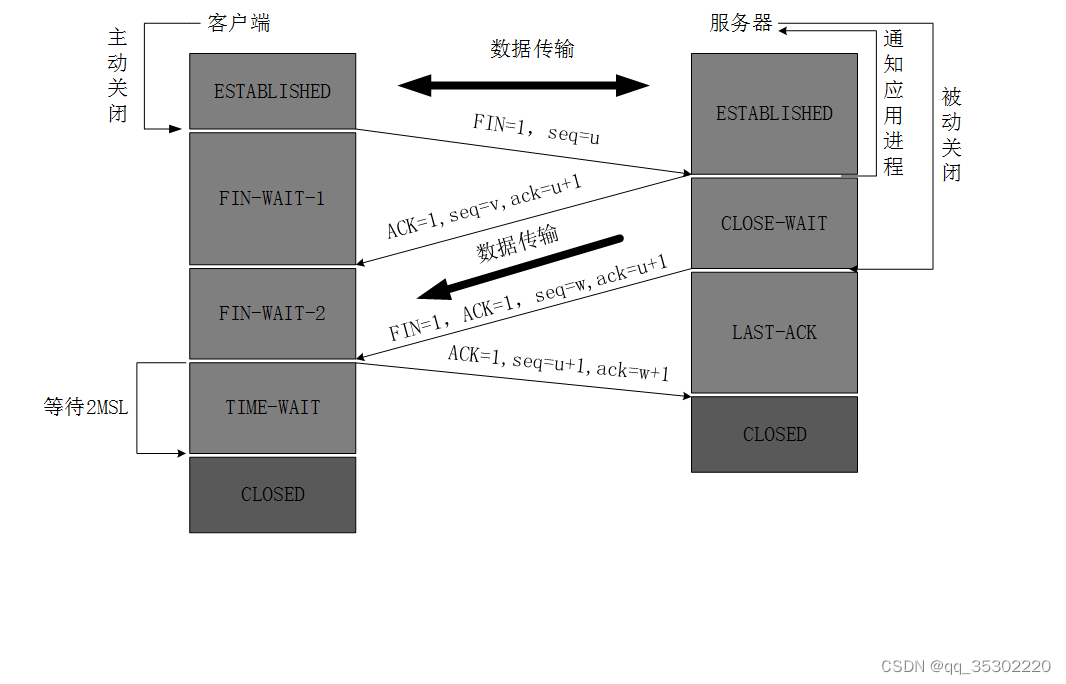
为什么客户端最后还要等待2MSL?
MSL(Maximum Segment Lifetime),TCP允许不同的实现可以设置不同的MSL值。
第一,保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK报文可能丢失,站在服务器的角度看来,我已经发送了FIN+ACK报文请求断开了,客户端还没有给我回应,应该是我发送的请求断开报文它没有收到,于是服务器又会重新发送一次,而客户端就能在这个2MSL时间段内收到这个重传的报文,接着给出回应报文,并且会重启2MSL计时器。
第二,防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现在本连接中。客户端发送完最后一个确认报文后,在这个2MSL时间中,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样新的连接中不会出现旧连接的请求报文。
为什么建立连接是三次握手,关闭连接确是四次挥手呢?
建立连接的时候, 服务器在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。
而关闭连接时,服务器收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必全部数据都发送给对方了,所以己方可以立即关闭,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送,从而导致多了一次。
如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
TCP有哪几个状态,分别是什么意思?
CLOSED:在超时或者连接关闭时候进入此状态.
LISTEN:服务器端等待连接的状态。
SYN_SENT:客户端发起连接。
SYN_RCVD:服务器端接收到了客户端的 SYN,此时服务器由 LISTEN 进入 SYN_RCVD状态,同时服务器端回应一个 ACK,然后再发送一个 SYN 即 SYN+ACK 给客户端。
ESTABLISHED:客户端接收到服务器端的 ACK 包(ACK,SYN)之后,也会发送一个 ACK 确认包,客户端进入 ESTABLISHED 状态,表明客户端这边已经准备好,但TCP 需要两端都准备好才可以进行数据传输。服务器端收到客户端的 ACK 之后会从 SYN_RCVD 状态转移到 ESTABLISHED 状态,表明服务器端也准备好进行数据传输了。这样客户端和服务器端都是 ESTABLISHED 状态,就可以进行后面的数据传输了。所以 ESTABLISHED 也可以说是一个数据传送状态。
FIN_WAIT_1:主动关闭的一方(执行主动关闭的一方既可以是客户端,也可以是服务器端,这里以客户端执行主动关闭为例),终止连接时,发送 FIN 给对方,然后等待对方返回 ACK 。
CLOSE_WAIT:接收到FIN 之后,被动关闭的一方进入此状态。具体动作是接收到 FIN,同时发送
ACK。TCP关闭是全双工过程,这里客户端执行了主动关闭,被动方服务器端接收到FIN 后也需要调用
close 关闭,这个 CLOSE_WAIT 就是处于这个状态,等待发送 FIN,发送了FIN 则进入 LAST_ACK 状
态。
FIN_WAIT_2:主动端(这里是客户端)先执行主动关闭发送FIN,然后接收到被动方返回的 ACK 后进入此状态。
LAST_ACK:被动方(服务器端)发起关闭请求,由状态2 进入此状态,具体动作是发送 FIN给对方,同时在接收到ACK 时进入CLOSED状态。
CLOSING:两边同时发起关闭请求时,主动方会由FIN_WAIT_1 进入此状态,等待被动方返回ACK。
TIME_WAIT:从状态变迁图看,四次挥手操作最后都会经过这样一个状态然后进入CLOSED状态。
7. TCP和UDP的区别
答案:
TCP是面向有连接型,UDP是面向无连接型;
TCP是一对一传输,UDP支持一对一、一对多、多对一和多对多的交互通信;
TCP是面向字节流的,即把应用层传来的报文看成字节流,将字节流拆分成大小不等的数据块,并添加
TCP首 部;UDP是面向报文的,对应用层传下来的报文不拆分也不合并,仅添加UDP首部;
TCP支持传输可靠性的多种措施,包括保证包的传输顺序、重发机制、流量控制和拥塞控制;UDP仅提
供最基本 的数据传输能力。
8.TCP对应的应用层协议有哪些? UDP对应的应用层协议有哪些?
答案:
TCP对应的典型的应用层协议:
FTP:文件传输协议,SSH:远程登录协议,HTTP:web服务器传输超文本到本地浏览器的超文本传输
协议。
UDP对应的典型的应用层协议:
DNS:域名解析协议,TFTP:简单文件传输协议,SNMP:简单网络管理协议。
9.访问百度网站,有什么方法可以跟踪经过了哪些网络节点?
答案:
windows系统使用tracert命令,linux系统使用traceroute命令可以跟踪路由
10. 使用awk统计httpd访问日志中每个客户端IP的出现次数?
答案:
awk ‘{ip[$1]++}END{for(i in ip){print ip[i],i}}’ /var/log/httpd/access_log
备注:定义数组,数组名称为ip,数字的下标为日志文件的第1列(也就是客户端的IP地址),++的目的
在于对客户端进行统计计数,客户端IP出现一次计数器就加1。END中的指令在读取完文件后执行,通过 循环将所有统计信息输出。
11.正则表达式符号: *、+、?、[]、[^]、{n}分别代表什么含义?
表示匹配前面的字符出现了任意次(包括0次)
表示匹配前面的字符出现了至少1次(1次或多次)
? 表示匹配前面的字符出现了0次或1次
[] 表示集合,匹配集合中的任意单个字符
[^] 表示对集合取反
{n} 表示精确匹配前面的字符出现了n次
12.Shell中对变量字串进行截取的方式有哪些?
答案:
echo ${变量名:开始位置:长度} #注意,起始位置从0开始
expr substr $变量名 开始位置 长度 #注意,起始位置从1开始
echo $变量名 | cut -b 开始位置-结束位置 #注意,起始位置从1开始
13. 编写脚本,自动生成一个8位随机密码?
答案:
vim test.sh
#!/bin/bash
Str="abcdefghijklnmopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ012345 6789"
pass=""
for i in {1..8}
do
num=$[RANDOM%${#Str}]
tmp=${Str:num:1}
pass+=$tmp
done
echo $pass
14.从日志/opt/bjca3/logs/ca_access.log中截取14点到16点的日志,将截取的日志导入到/tmp/ca_access.txt中,日志格式如下
[Fri Mar 17 13:59:00 2017] [debug] mod_cmp.c(1600):[client 192.168.97.8] [CMP] CMP_set_status: starting …
[Fri Mar 17 13:59:00 2017] [debug] mod_cmp.c(938):[client 192.168.97.8] [CMP] CMP_cu_integer_set: starting …
[Fri Mar 17 13:59:00 2017] [debug] mod_cmp.c(957):[client 192.168.97.8] [CMP] CMP_cu_integer_set: ending ok …
………
[Fri Mar 17 16:36:00 2017] [debug] mod_cmp.c(1014):[client 192.168.97.8] [CMP] cu_octet_str_set: starting …
[Fri Mar 17 16:36:00 2017] [debug] mod_cmp.c(1037):[client 192.168.97.8] [CMP] cu_octet_str_set: ending ok …
答案:
awk '$4>"13:00:00"&&$4<="16:59:00"' ca_access.log
15.编写脚本使用ping命令检测一组IP地址判断是否处于活跃状态。
要求(range:192.168.1.200-192.168.1.220,一个IP发送4个ping包,ping的过程不能输出信息到终
端)?
答案:
#!/bin/bash
for i in {200..220}
do
ping -c 4 -i 0.2 -W 1 192.168.1.$i &>/dev/null
if [ $? -ne 0 ];then
echo "192.168.1.$i is down"
fi
done
16.如何查看httpd访问日志文件access.log中哪个IP访问最多?
答案:
awk '{ip[$1]++} END{for(i in ip) {print i,ip[i]}}' /var/log/httpd/access_log | sort -nr
17.如何修改Linux内核参数,调整进程可以打开的最大文件数量?
答案:
临时规则
ulimit -Hn 数量
ulimit -Sn 数量
永久规则
#vim /etc/security/limit.conf
用户或组 soft nofile 数量
用户或组 hard nofile 数量
18. 如何将一个源码包软件转换称为一个RPM软件包?
答案:
1)安装rpmbuild工具
2)首先将源码包放到SOURCES目录下,
3)然后在SPECS目录下创建一个spec配置文件,并按特定格式要求编辑文件内容,SPECS文件可以定义:软件的描述信息,如何编译安装源码软件,对什么文件打包封装为RPM,安装前和安装后脚本等。
4)最后使用rpmbuild -ba spec文件。
19.简述什么是CDN?
答案:
CDN是内容分发网络,通过CDN可以将图片、视频、音频等精通文件分发到全国甚至是全球,让每个地
区的用户都可以访问距离自己最近的资源,可以起到加速的作用。
国内有哪些比较好的CDN厂商
蓝汛,网宿,阿里云,腾讯云,ucloud,七牛云
20.用什么命令可以查看上一次服务器启动时间、上一次谁登陆过服务器?
答案:
last(历史登陆记录),uptime(系统累计运行的时间),who -b(上次启动系统的时间)
21.Linux系统路由的查看和添加使用什么命令?
route -n //查看路由表信息
ip route add 192.168.2.0/24 via 192.168.1.1
//添加路由条目(route add)
//取192.168.2.0/24网络的默认网关是192.168.1.1
22.下面哪条命令用来显示一个程序所使用的库文件?
ldd 程序的绝对路径
比如# ldd /bin/ls命令可以查看ls这个程序调用了哪些库文件
23.Nginx配置文件中location匹配数据的优先级?
第一优先级:等号类型(=)的优先级最高。一旦匹配成功,则不再查找其他匹配项。
第二优先级:^~类型表达式。一旦匹配成功,则不再查找其他匹配项。
第三优先级:正则表达式类型(~ ~*)的优先级次之。如果有多个location的正则能匹配的话,则使用
正则表达式最长的那个。
第四优先级:常规字符串匹配类型。按前缀匹配。
location = /test {}
location ^~ /test {}
location ~ /test {}
location ~* /test {}
location / {}
24.怎么监控Tomcat的内存使用情况?
答案:
使用JDK自带的jconsole可以比较明了的看到内存的使用情况,线程的状态,当前加载的类的总量等;
JDK自带的jvisualvm可以下载插件(如GC等),可以查看更丰富的信息。如果是分析本地的Tomcat的话,
还可以进行内存抽样等,检查每个类的使用情况。
25.nginx的优化你都做过哪些?
gzip压缩优化,expires缓存,隐藏软件名称和版本号,禁止恶意域名解析,禁止通过IP地址访问网站(deny ip)
HTTP请求方法优化,防DOS攻击单IP并发连接的控制,与连接速率控制,严格设置web站点目录的权限
优化最大打开文件数量,自定义错误页面,nginx日志相关优化访问日志切割轮询
配置文件buffer和cache的优化,nginx加密传输优化 (SSL),精简nginx模块,状态页面
worker_processes 8;
worker_rlimit_nofile 65535;
use epoll;
client_header_buffer_size 4k;
open_file_cache max=65535 inactive=60s;
error_page 404 /404.html;
stub_status on;
expires 30d;
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
limit_req zone=one burst=5;
26.Tomcat你做过哪些优化?
1.Tomcat的运行模式 : bio,nio, apr
一般使用nio模式, bio效率低, apr对系统配置有一些更高的要求
2.关键配置
maxThreads: 最大线程数,默认是200,
minspareThread: 最小活跃线程数,默认是25
maxqueuesize: 最大等待队列个数
3.影响性能的配置:
compression 设置成on,开启压缩
禁用AJP连接器: 用nginx+Tomcat的架构,用不到AJP
enableLookups=false 关闭反查域名,直接返回ip,提高效率
disableUploadTimeou=false上传是否使用超时机制
acceptCount=300 , 当前所有可以使用的处理请求都被使用时,传入请求连接最大队列长队,超过 个数不予处理,默认是100
keepalive timeout=120000 场链接保持时间
4.优化jvm
/bin/catalina.sh
-server:jvm的server工作模式,对应的有client工作模式。
使用“java -version”可以查看当前工作 模式
27.关于nginx access模块的面试题?
编写一个Nginx的access配置,要求允许192.168.3.29/24的机器访问,允许10.1.20.6/16这个网段的所
有机器访问,允许34.26.157.0/24这个网段访问,除此之外的机器不允许访问。
location / {
access 192.168.3.29/24;
access 10.1.20.6/16;
access 34.26.157.0/24;
deny all;
}
28.Nginx防盗链,防止其他网址链接我的图片或视频资源?
Nginx的防盗链原理是加入location项,用正则表达式过滤图片或视频文件,对于信任的网址可以正常使
用我们的链接, 对于不信任的网址则返回相应的错误,在配置文件中加入以下代码:
# vim /usr/local/nginx/conf/nginx.conf
location ~* \.(jpg|gif|mp4)$ { //正则过滤图片和mp4文件
valid_referers none blocked *.test.com test.com;
//valid_referers定义哪些网址是合法来源,比如我的合作伙伴
//从这些网址可以过来,就链接我的资源
if ($invalid_referer) { //除了上面定义的合法友情网址,其他都算非法网址来源
return 404; //从非法网址来源的链接,都直接返回错误
}
}
29.如何加强MySQL安全,请给出可行的具体措施?
1.避免直接从互联网访问mysql数据库,确保特定主机才拥有访问权限
2.定期备份数据库
3.禁用或限制远程访问,在my.cnf文件里设置bind-address指定ip
4.移除test数据库(默认匿名用户可以访问test数据库)
5.禁用local infile
mysql> select load_file(“/etc/passwd”);
在my.cnf里[mysqld]下添加set-variable=local-infile=0
6.移除匿名账户和废弃的账户
7.限制mysql数据库用户的权限
8.移除和禁用.mysql_history文件
30.MySQL数据库cpu飙升到500%的话他怎么处理?
当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 mysqld 占用导致的,如果不是,找出
占用高的进程,并进行相关处理
如果是 mysqld 造成的,show processlist,看看里面跑的session 情况,是不是有消耗资源的 sql 在运
行。找出消耗高的sql,看看执行计划是否准确,index是否缺失,或者实在是数据量太大造成。
一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、
改SQL语句、改内存参数)之后,再重新跑这些SQL。
也有可能是突然有大量的session连进来导致cpu飙升,这种情况就需要跟应用一起来分析为何连接数会
激增,再做出相应的调整,比如说限制连接数等。
31.请写出创建存储过程的语法格式?
use 数据库名;
delimiter //
create procedure 名称(参数列表)
begin
功能代码
end
//
delimiter ;
32.请描述下列命令在配置MHA集群时的作用?
masterha_check_status,masterha_check_ssh,masterha_check_repl,masterha_manager
答案:
masterha_check_status 检查mha服务状态
masterha_check_ssh 检查ssh配置
masterha_check_repl 检查主从同步配置
masterha_manager 启动mha服务
33.存储过程与函数的区别?
函数:只能返回一个变量的限制。而存储过程可以返回多个。
函数是可以嵌入在sql中使用的,可以在select中调用,而存储过程不行
存储过程来说可以返回参数,而函数只能返回值或者表对象。
存储过程一般是作为一个独立的部分来执行,而函数可以作为查询语句的一个部分来调用
34.请阐述MySQL服务有哪些日志文件?
错误日志、binlog日志、查询日志、慢查询日志、事务日志、中继日志
35.请阐述MySQL主从同步复制的工作过程?
主库:binlog日志记录所有改变数据库数据的语句。
从库:IO线程负责从master上拉取 binlog 内容,放进 自己的relay log中。
从库:SQL线程执行relay log中的语句。
36.MySQL主从原理?
从库生成两个线程,一个I/O线程,一个SQL线程;
I/O线程去请求主库的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;
主库会生成一个 log dump 线程,用来给从库I/O线程传binlog;
SQL线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一
致。
37.MySQL主从复制存在哪些问题?
MySQL主从复制存在的问题:主库宕机后,数据可能丢失;从库只有一个SQL Thread ,主库写压力
大, 复制很可能延时。
解决方法: 用半同步复制解决数据丢失的问题,用并行复制解决从库复制延迟的问题。
38.主从延迟产生的原因及解决方案?
可能的原因:
1)主库的并发比较高的时候,产生的DDL数量超过了从库的一个SQL线程所承受的范围,那么延时就产
生了。
2)还有可能是与从库的大型query语句产生的了锁等待。
3)网络抖动
解决方案:
1)业务的持久化层的实现采用分库架构,MySQL服务可平行扩展,分散压力。
2)单个库读写分离,一主多从,主写从读,分散压力。这样从库压力比主库高,保护主库。
3)服务的基础架构在业务和MySQL之间加入redis的cache层。降低mysql的读压力。
4)不同业务的MySQL物理上放在不同机器,分散服务器的压力。
5)mysql主从同步加速。
1、sync_binlog在slave端设置为0
2、– logs-slave-updates 从服务器从主服务器接收到的更新不记入它的二进制日志
3、直接禁用slave端的binlog
39.判断主从延迟的方法?
可以通过命令 show slave status 查看
比如通过seconds_behind_master的值来判断
NULL - 表示io_thread或是sql_thread有任何一个发生故障,也就是该线程的Running状态是No,而非Yes
0 - 该值为零,是我们极为渴望看到的情况,表示主从复制状态正常
40.Binlog工作模式有哪些?各什么特点,企业如何选择?
1.row level行级模式
优点:记录数据详细(每行),主从一致
缺点:占用大量的磁盘空间,降低了磁盘的性能
2.statement level模式(默认)
优点:记录的简单,内容少 ,节约了IO,提高性能;缺点:导致主从不一致
3.MIXED混合模式
结合了statement和row模式的优点,会根据执行的每一条具体的SQL语句来区分对待记录的日志形式。
对于函数,触发器,存储过程会自动使用row level模式
企业场景选择:
1.互联网公司使用mysql的功能较少(不用存储过程、触发器、函数),选择默认的statement模式。
2.用到mysql的特殊功能(存储过程、触发器、函数)则选则MIXED模式。
3.用到mysql的特殊功能(存储过程、触发器、函数),有希望数据最大化一致则选择row模式。
41.生产一主多从从库宕机,如何手工恢复?
- 停止slave
- 导入备份数据
- 配置master.info信息
- 启动slave
- 检查从库状态
42.误执行drop数据,如何通过xtrabackup恢复?
- 关闭mysql服务
- 移除mysql的data目录及数据
- 将备份的数据恢复到mysql的data目录
- 启动mysql服务
43.如何做主从数据一致性校验?
主从一致性校验有多种工具 例如checksum、 mysqldiff、pt-table-checksum等。
44.MySQL的MHA如何实现?
MHA是一套优秀的实现MySQL高可用的解决方案,数据库的自动故障切换操作能做到在0~30秒之内完
成,MHA能确保在故障切换过程中最大限度保证数据的一致性,以达到真正意义上的高可用。
MHA的组成:
MHA Manager(管理节点)
- 管理所有数据库服务器
- 可以单独部署在一台独立的机器上
- 也可以部署在某台数据库服务器上
MHA Node(数据节点)
- 存储数据的MySQL服务器
- 运行在每台MySQL服务器上
MHA工作过程:
由Manager定时探测集群中的master节点;
当master故障时,Manager自动将拥有最新数据的slave提升为新的master。
45.redis数据持久化的2种方式分别是什么?
RDB:全称 Redis DataBase按照指定时间间隔,将内存中的数据集快照写入硬盘。
AOF: 全称Append Only File记录redis服务所有写操作不断的将新的写操作,追加 到文件的末尾。
46.简述redis支持的数据类型 (至少3种)?
字符类型:string
列表类型:list
Hash表类型:hash
集合类型:set
有序集合类型:zset
47.请在横线处填写符合题意的答案?
Redis服务默认监听端口号 6379
MongoDB服务默认监听端口号 27017
Memcached服务默认监听端口号22122
48.什么是缓存雪崩?
Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据设置过期时间,并采用
的是惰性删除+定期删除两种策略对过期键删除。
如果缓存数据设置的过期时间是相同的,并且Redis恰好将这部分数据全部删光了。这就会导致短时间
内,这些缓存同时失效,全部请求到数据库中,造成数据库瞬间压力飙升,可能导致数据崩溃。
什么是缓存雪崩?
Redis挂掉了,请求全部走数据库。
对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。
缓存雪崩如果发生了,很可能就把我们的数据库搞垮,导致整个服务瘫痪!
解决方法:
在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
对于Redis挂掉了,请求全部走数据库的情况,可以提前设计Redis高可用集群。
49.什么是缓存穿透?
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到
数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义,请
求的数据在缓存大量不命中,导致请求走数据库。缓存穿透如果发生了,也可能把我们的数据库搞垮,
导致整个服务瘫痪!
如何解决缓存穿透
由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者
压缩filter提前拦截,不合法就不让这个请求到数据库层!
当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从
缓存里边获取了。这种情况我们一般会将空对象设置一个较短的过期时间。
50.什么是缓存击穿?
某一个热点key,在不停地扛着高并发,当这个热点key在失效的一瞬间,持续的高并发访问就击破缓存
直接访问数据库,导致数据库宕机。
设置热点数据"永不过期" 加上互斥锁:上面的现象是多个线程同时去查询数据库的这条数据,那么我们
可以在第一个查询数据的请求上使用一个互斥锁来锁住它其他的线程走到这一步拿不到锁就等着,等第
一个线程查询到了数据,然后将数据放到redis缓存起来。后面的线程进来发现已经有缓存了,就直接走
缓存。
总结:
雪崩是大面积的key缓存失效;穿透是redis里不存在这个缓存key;击穿是redis某一个热点key突然失
效,最终的受害者都是数据库。