Spark DPP
- 分区剪裁
- 动态分区剪裁
DPP (Dynamic Partition Pruning,动态分区剪裁) : 过滤维度表后,能削减事实表的数据扫描量,提升关联计算的执行性能
分区剪裁
需求 :统计所有头部用户贡献的营业额,并按照营业额倒序排序
select (orders.price * order.quantity) as income,
users.name
from orders inner
join users on orders.userId = users.id
where users.type = 'Head User'
group by users.name
order by income desc
逻辑计划 :
- 事实表上没有过滤条件,左侧会全表扫描
- 维度表上有过滤条件
users.type = 'Head User',会用谓词下推,把过滤操作下推到数据源上,减少磁盘 I/O 开销
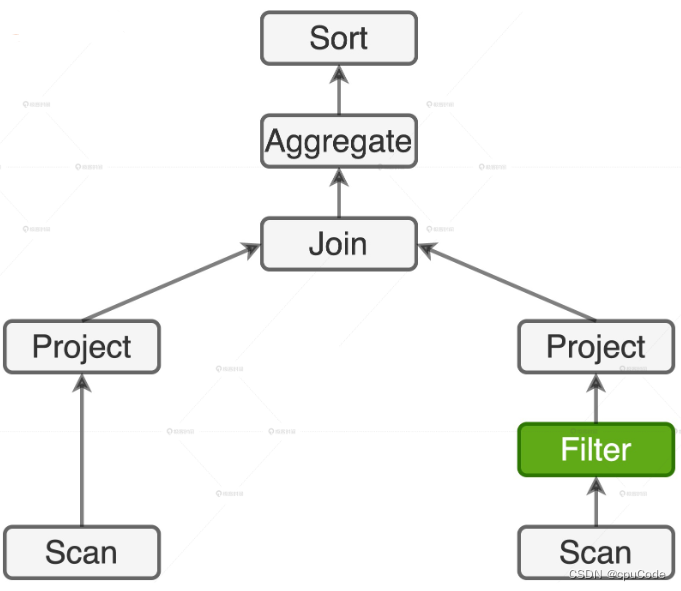
当用户表支持分区剪裁(Partition Pruning),I/O 效率的提升就会更加显著
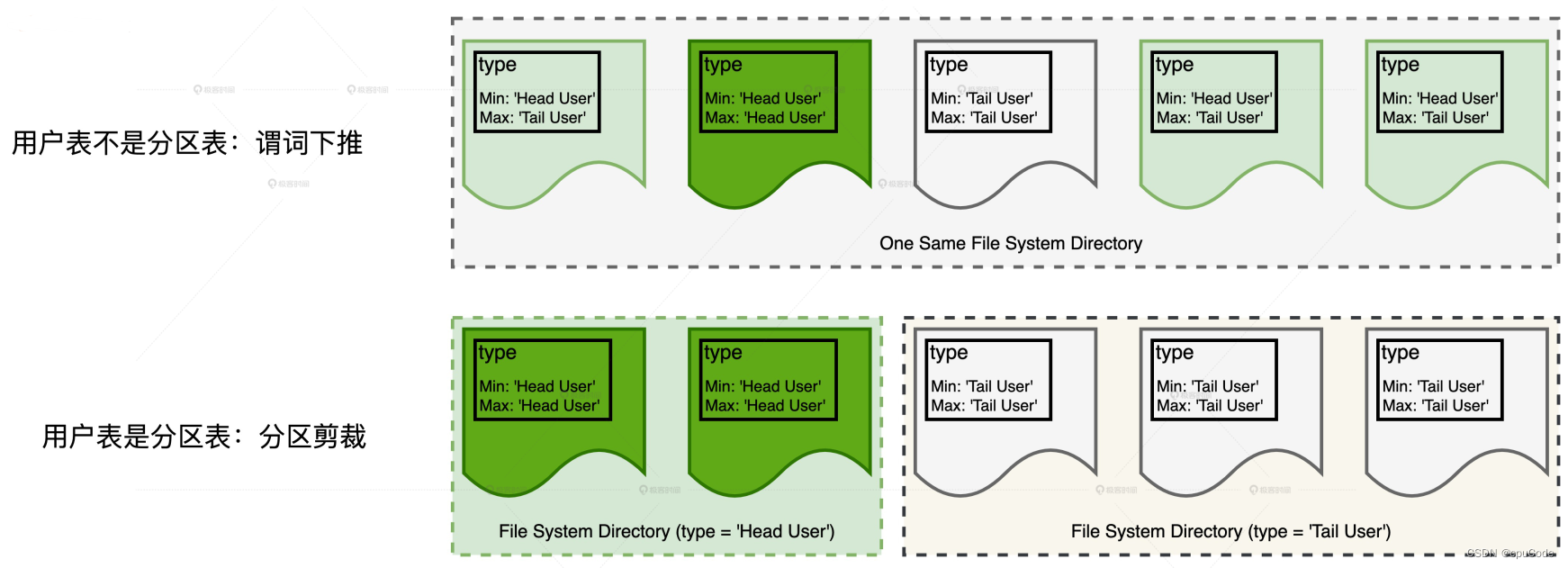
分区剪裁 :谓词下推的特例
- 在分区表中下推谓词,以文件系统目录为单位对数据集进行过滤
分区表的存储方式:在文件系统中创建单独的子目录来存储相应的数据分片
- 例子:用户表是分区表,当 type 字段作为分区键,就以 type 值创建子目录
谓词下推/分区剪裁:
- 不分区时,数据分片都在同个目录下,只能通过 Parquet 在注脚 (Footer) 中 type 字段的统计值,利用谓词下推,减少扫描的数据分片
- 分区时,分区字段 type 值在不同的子目录,利用分区剪裁,跳过子目录的扫描,从而提升 I/O 效率
动态分区剪裁
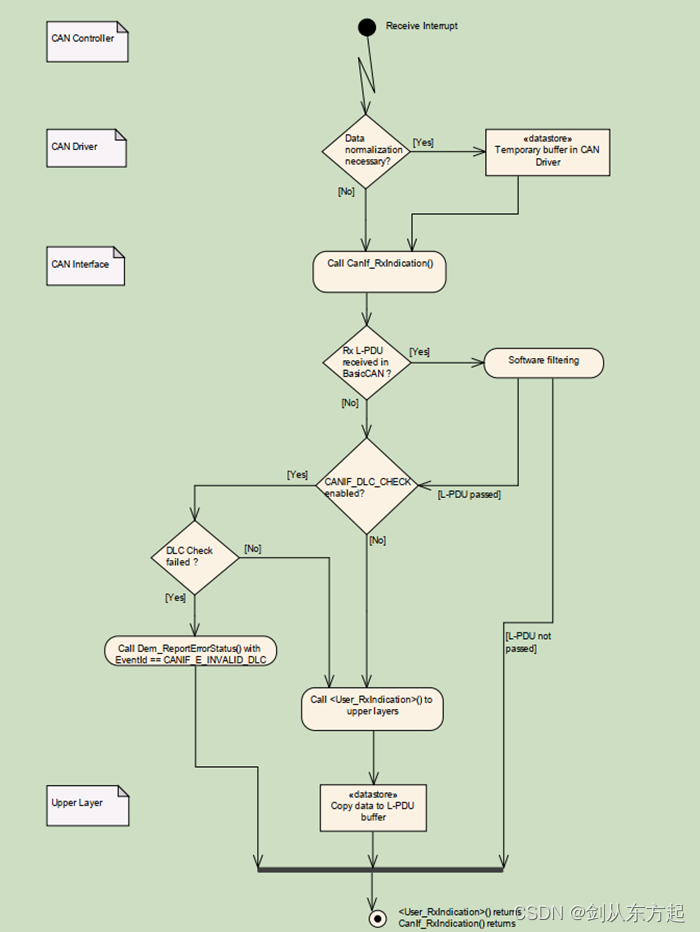
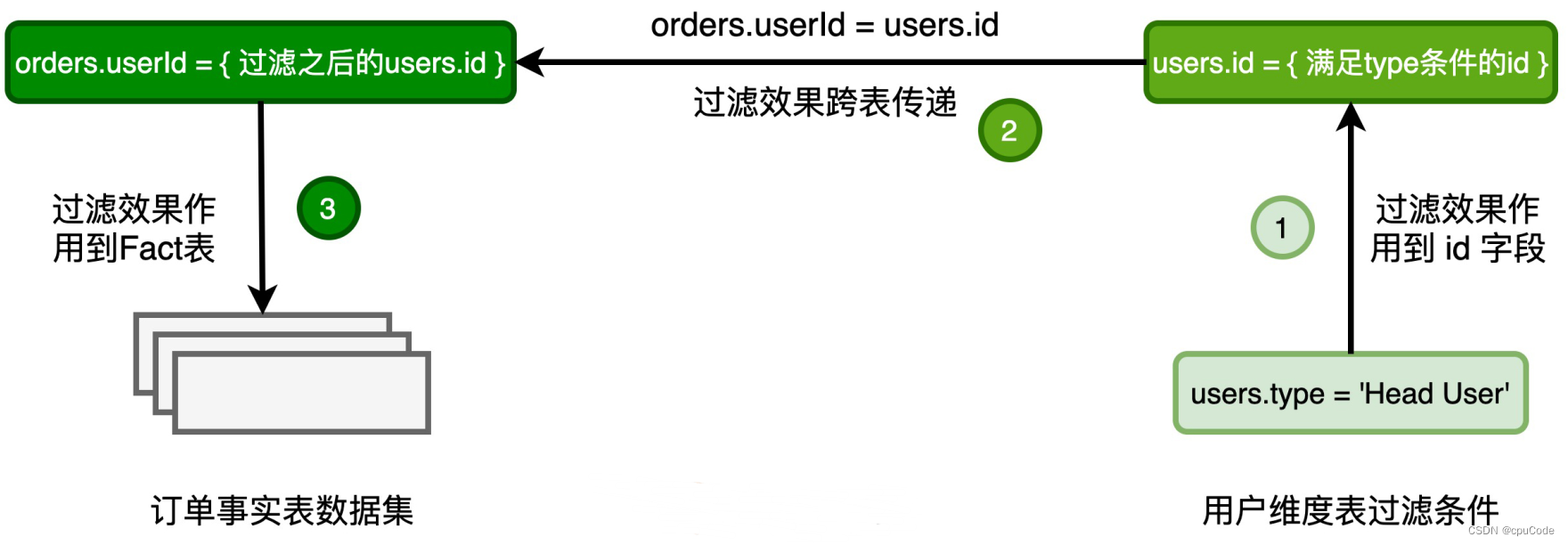
DPP 实现逻辑 :
- 对维度表进行
users.type = 'Head User'条件过滤,再对维度表进行过滤列 id - 根据关联关系
orders.userId = users.id,把维度表 id 传到事实表的 userId 中 - 根据 userId 对事实表过滤,减少数据扫描量,提升 I/O 效率
利用 DPP 的条件:
- 事实表必须是分区表,且分区字段 (可多个) 必须包含 Join Key
- 只支持等值 Joins,不支持大于、小于不等值关联
- 维度表过滤后的数据集 ,要小于广播阈值