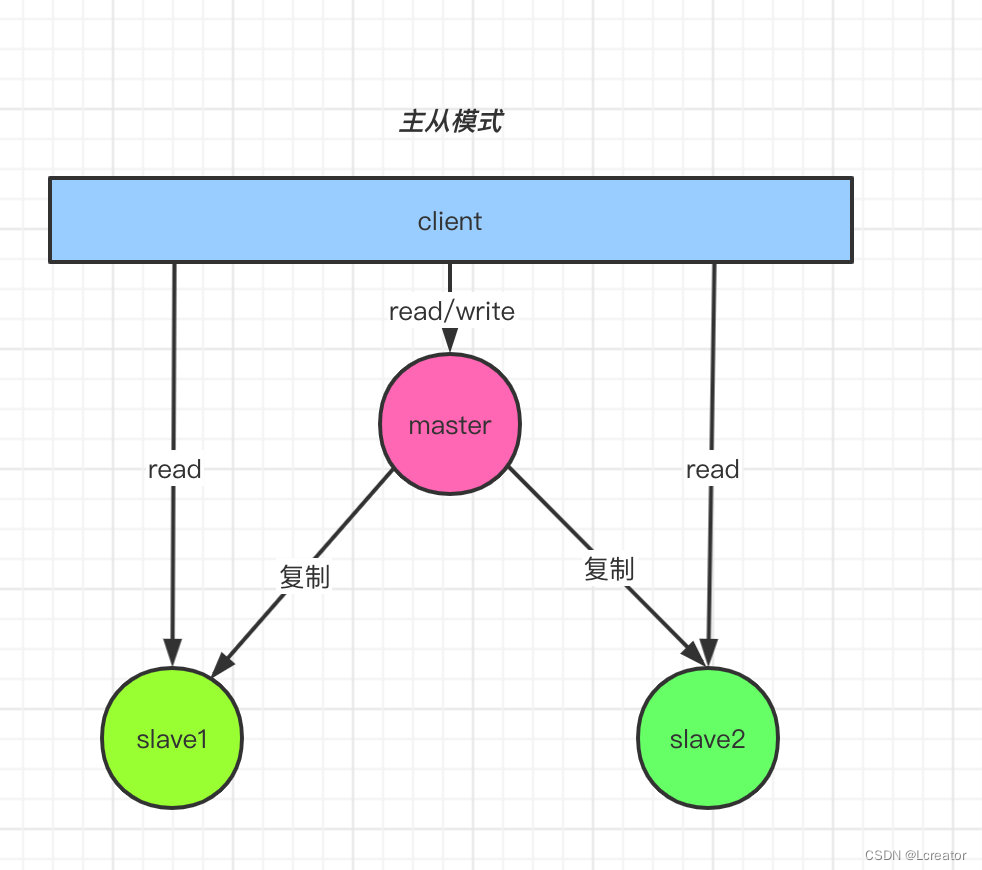
主从复制模式
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。
前者称为主节点(master),后者成为从节点(slave);数据的复制是单向,主要是由主节点到从节点。一个master挂载多个slave节点,当master服务宕机,会在多个slave节点中选举产生一个新的master节点,从而保证服务的高可用性。
主从模式配置很简单,只需要在从节点配置主节点的ip和端口即可
slaveof <masterip> <masterport>
# 例如
# slaveof 192.168.1.214 6379
启动主从节点的所有服务,查看日志即刻看到主从节点之间的服务连接。
从上面很容易就想到一个问题,既然主从复制,意味着master和slave的数据一样,存在数据冗余的问题。
在程序设计上,为了高可用性和高性能,是允许有冗余存在的,但是可以避免宕机影响用户体验。
优点:
- 一旦主节点宕机,从节点作为主节点的备份可以随时代替主节点的工作
- 扩展主节点的读能力,分担主节点的读压力
- 高可用基石:除了上述作用以外,主从复制还是哨兵模式和集群模式能够实施的基础,因此说主从复制是Redis高可用的基石。
缺点: - 一旦主节点宕机,从节点晋升成主节点,同时需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工干预。
- 主节点的读写能力和存储能力受到单机的限制
主从模式的工作机制

当开启主从模式的时候,他的具体工作机制如下:
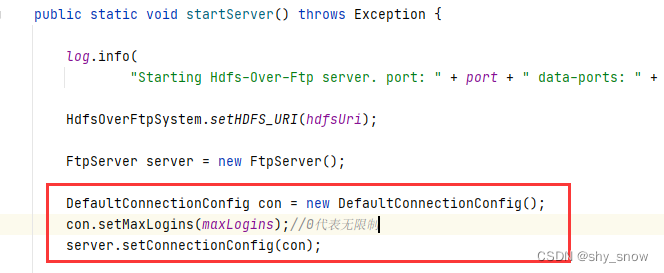
- 当slave启动后会向master发送SYNC命令,master节后到从数据库的命令后通过bgsave保存快照(「RDB持久化」),并且期间的执行的些命令会被缓存起来。
- 然后master会将保存的快照发送给slave,并且继续缓存期间的写命令。
- slave收到主数据库发送过来的快照就会加载到自己的数据库中。
- 最后master讲缓存的命令同步给slave,slave收到命令后执行一遍,这样master与slave数据就保持一致了。
docker构建Redis主从复制模式
创建主从模式
打开一个命令窗口,在其中运行如下命令创建一个名为redis-master的Redis容器。端口为6379
docker run -itd --name redis-master -p 6379:6379 redis:latest

创建第一个从服务器
新建一个命令窗口,在其中运行如下命令创建一个名为redis-slave1的容器,它的端口是6380.这里是在一台电脑上运行,所以用端口号来区别一台主Redis容器和另外两台从Redis容器。在真实项目里,多台Redis会部署在不同的服务器上,所以可以都用6379端口。
docker run -itd --name redis-slave1 -p 6380:6380 redis:latest

创建第二个从服务器
新建一个命令窗口,在其中运行如下命令创建一个名为redis-slave2的容器
docker run -itd --name redis-slave2 -p 6381:6381 redis:latest

查看redis-master容器信息
回到包含redis-master容器的命令窗口,在其中运行docker inspect redis-master命令查看redis-master容器的信息,在其中能通过IPAddress项看到该容器的IP地址,这里是172.17.0.2。在真实项目里,Redis服务器所在的IP地址是固定的,而通过Docker容器启动的Redis服务器的IP地址是动态的,所以这里要用上述命来获取IP地址。
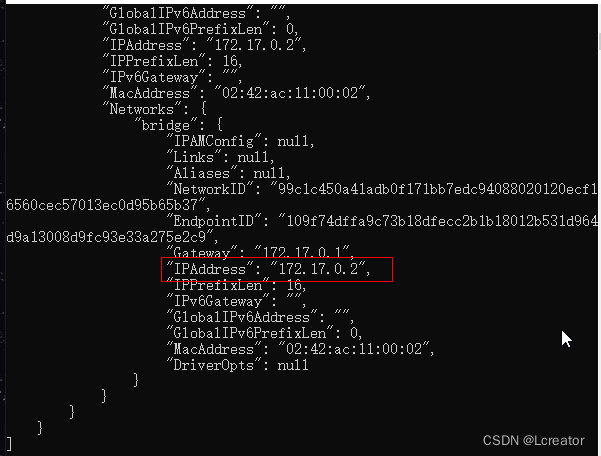
主从复制配置
运行docker exec -it redis-slave1 /bin/bash进入redis-slave1容器,并使用redis-cli进入redis客户端,在redis客户端里运行如下的slaveof命令,指定当前Redis服务器为从服务器。该命令的格式是slaveof ip port,这里指向172.17.0.2:6379所在的主服务器。


同样,在redis-slave2容器的命令窗口里运行如下的slaveof命令,指定当前Redis服务器为从服务器

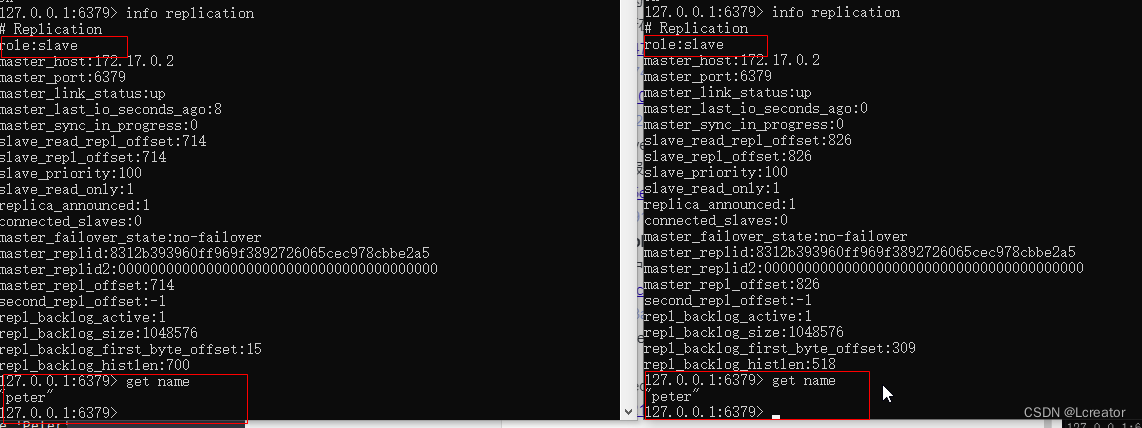
通过info replication命令查看主从配置信息
redis-master容器中:
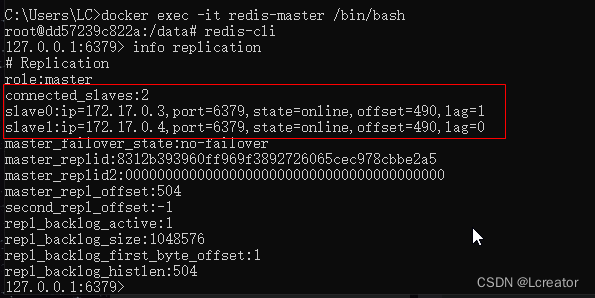
从上面可以看到role为master,连接配置的从服务器有2台,分别是redis-slave1和redis-slave2
在redis-slave1和redis-slave中,可以看到主服务器的ip和它的连接状态
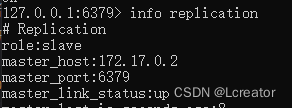
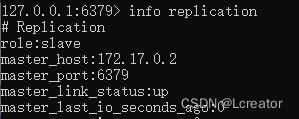
主从复制测试
在redis-master中设置个值set name ‘Peter’,再到从服务器上查看是否复制成功。
redis-master

主从复制常见问题
数据复制的延迟
读写分离时,master会异步将数据复制到slave,如果这时slave发生阻塞,则会延迟master数据的写命令,造成数据不一致的情况
解决方法:可以对slave的偏移量进行监控,如果发现某台slave的偏移量有问题,则将数据读取操作切换到master,但本身这个监控开销比较高,所以关于这个问题,大部分的情况是可以直接使用而不去考虑的。
规避全量复制
redis复制有全量复制和部分复制两种,而全量复制的开销是很大的,下面有几种出现全量复制的情况,可以尽量去规避全量复制。
- 第一次全量复制
当我们一台slave第一次挂到master上时,是不可避免要进行一次全量复制的,那么,我们如何去降低开销呢?
方案1:小主节点,例如我们将redis分成2G一个节点,这样一来,会加速RDB的生成和同步,同时可以降低我们fork子进程的开销(master会fork一个子进程来生成同步需要的RDB文件,而fork是要拷贝内存块的,如果主节点内存太大,fork的开销就大)
方案2:既然第一次不可以避免,那我们可以选在集群低峰的时间(凌晨)进行slave的挂载。 - 节点RunID不匹配
例如我们主节点重启(RunID发生变化),对于slave来说,它会保存之前master节点的RunID,如果它发现了此时master的RunID发生变化,那它会认为这是master过来的数据可能是不安全的,就会采取一次全量复制
解决办法:对于这类问题,我们只有是做一些故障转移的手段,例如master发生故障宕机了,我们选举一台slave晋升为master(哨兵或集群) - 复制积压缓冲区不足
master生成RDB同步到slave,slave加载RDB这段时间里,master的所有写命令都会保存到一个复制缓冲队列里(如果主从直接网络抖动,进行部分复制也是走这个逻辑),待slave加载完RDB后,拿offset的值到这个队列里判断,如果在这个队列中,则把这个队列从offset到末尾全部同步过来,这个队列的默认值为1M。而如果发现offset不在这个队列,就会产生全量复制。
解决办法:增大复制缓冲的设置rel_backlog_size默认1M,我们可以设置大一些,从而来加大我们offset的命中率。这个值,我们可以假设,一般我们网络故障时间一般是分钟级别,那我们可以根据我们当前的QPS来算一下每分钟可以写入多少字节,再乘以我们可能发生故障的分钟就可以得到我们这个理想的值。
5.规避复制风暴
什么是复制风暴?举例:我们master重启,其master下的所有slave检测到RunID发生变化,导致所有从节点向主节点做全量复制。尽量redis对这个问题做了优化,即只生成一份RDB文件,但需要多次传输,仍然开销很大
(1)单主节点复制风暴:主节点重启,多从节点全量复制
解决:更换复制拓扑如下图
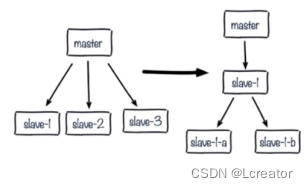
a.我们将原来master与slave中间加一个或多个slave,再在slave上加若干个slave,这样可以分担所有slave对master复制的压力。(这种架构还是有问题:读写分离的时候,slave1也发生了故障,怎么去处理?)
b.如果只是实现高可用,而不做读写分离,那当master宕机,直接晋升一台slave即可。
(2)单机器复制风暴:机器宕机后的大量全量复制,如下图:
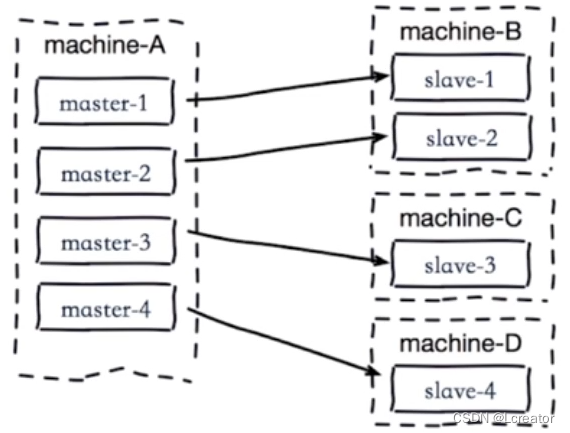
当machine-A这个机器宕机重启,会导致该机器所有master下的所有slave同时产生复制
解决:
1.主节点分散多机器(将master分散到不同机器上部署)
2.还有我们可以采用高可用手段(slave晋升master)就不会有类似问题了。