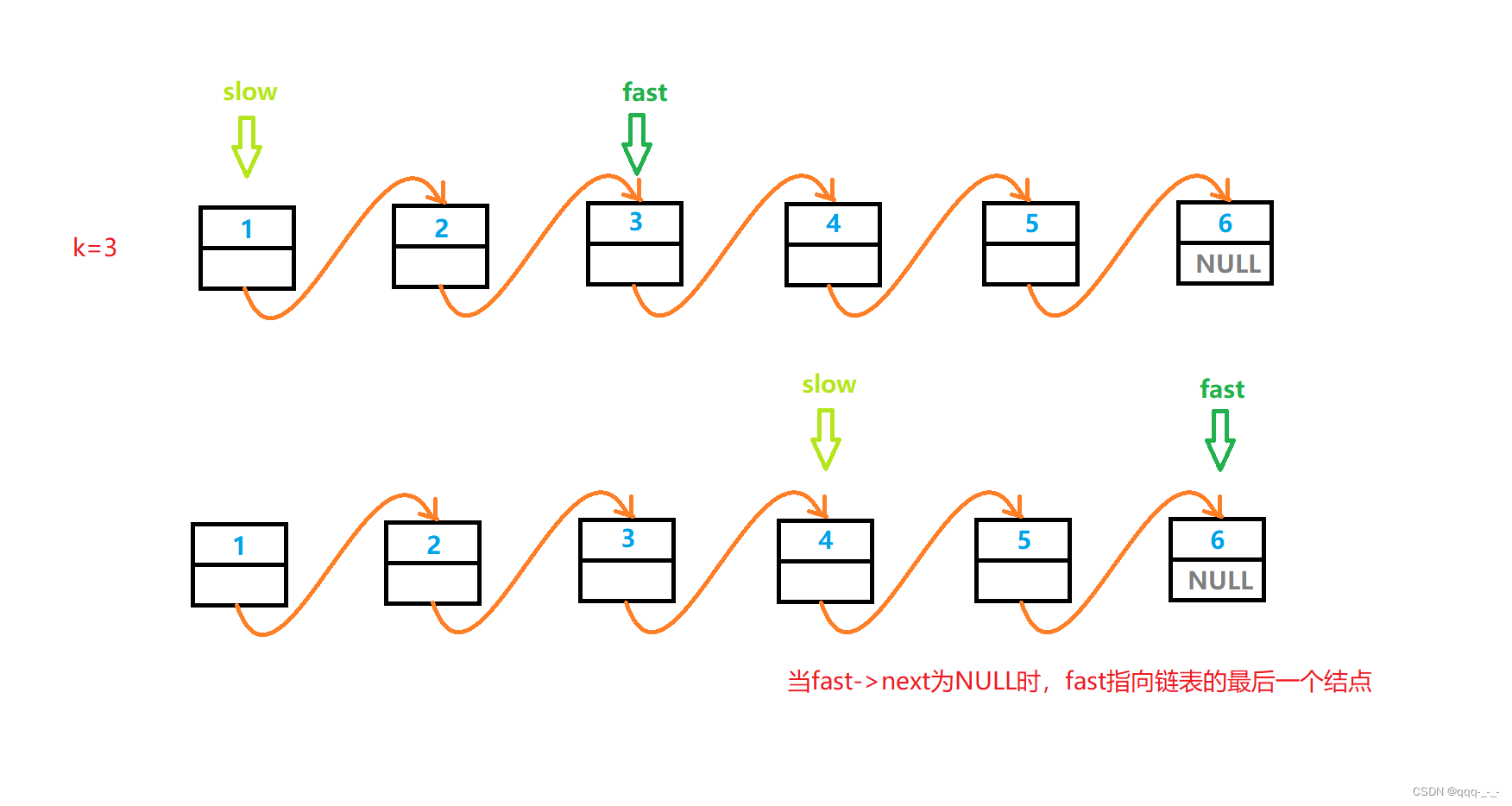
Mysql客户端包括JDBC、 Navicat、sqlyog,只是为了和mysql server建立连接,向mysql server提交sql语句。
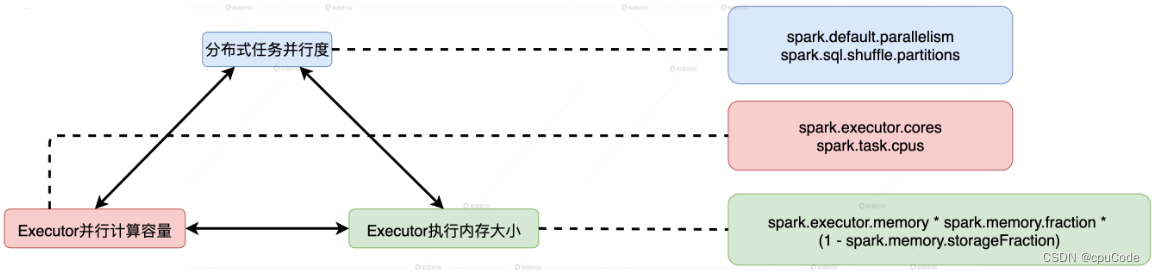
mysql server组件
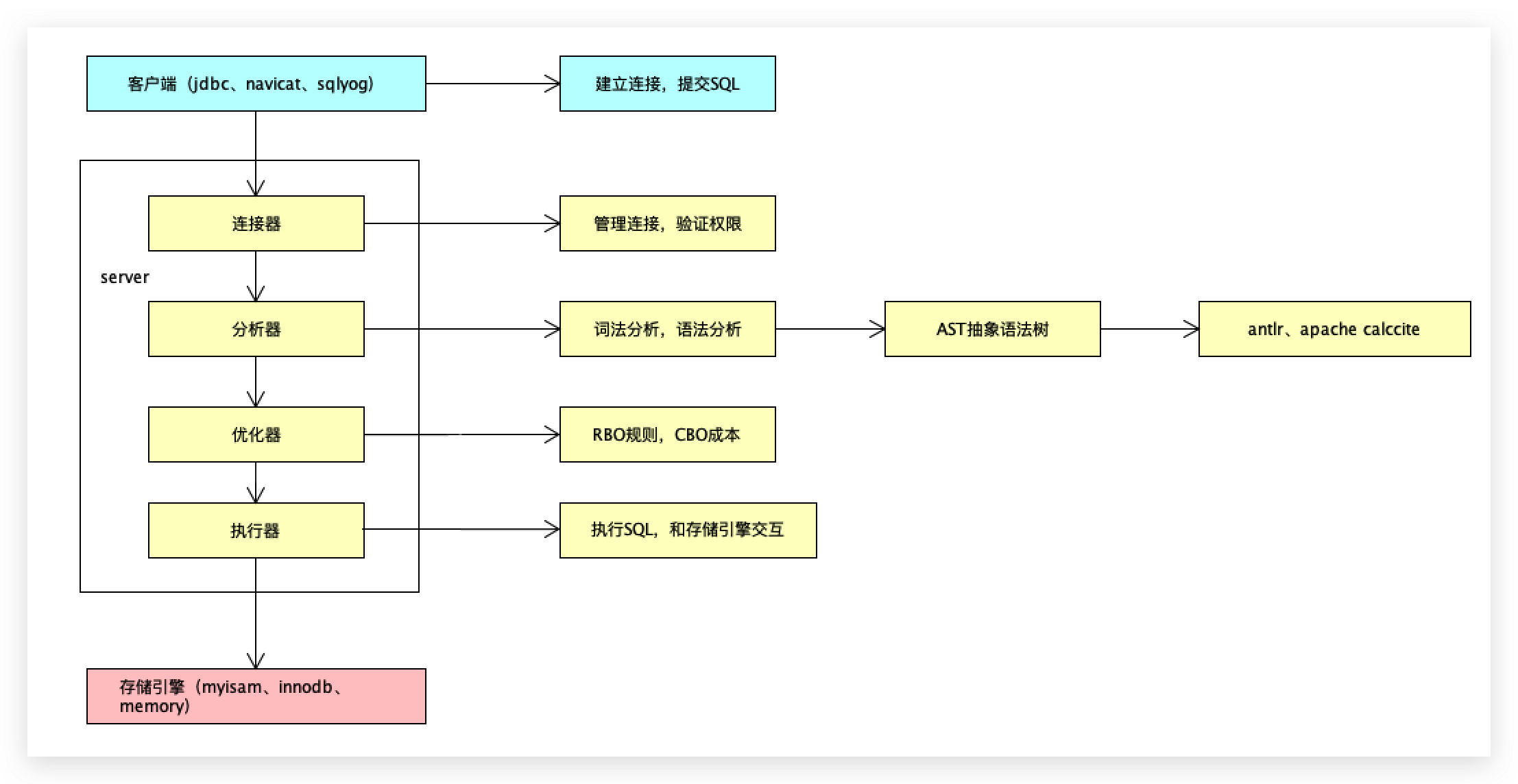
第一部分叫连接器
主要承担的功能叫管理连接和验证权限,每次在进行数据库访问的时候,必然要输入用户名和密码,进行权限的验证之类的。
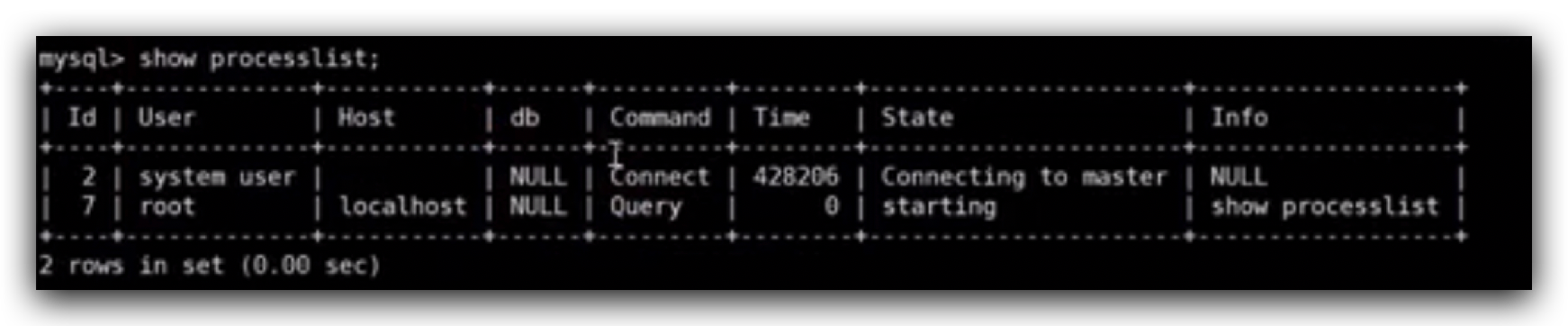
查看当前数据库正在建立的连接有几个:
第二个部分叫分析器
sql语句就是一堆的字符串,server拿到这一系列字符串之后需要对当前字符串进行解析操作;
最终一个sql语句,无论多简单都会转换成一个树形结构(AST 抽象语法树),
这里面会做2个基本操作一个是词法分析一个是语法分析,最终会转换成一个抽象语法树,
sql语句在正常执行的时候都是按照这样一个树形结构来执行的。
一般情况下sql语句在进行语法分析的时候,根据输入自动生成语法树并可视化显示出来。
开源的语法分析器常用的2个组件是Antlr、Apache Calcite,如果公司自研sql中间件,可能会涉及到sql语句解析工作,可以基于这2个组件来实现。

将这个sql语句转换成这样的树形结构,
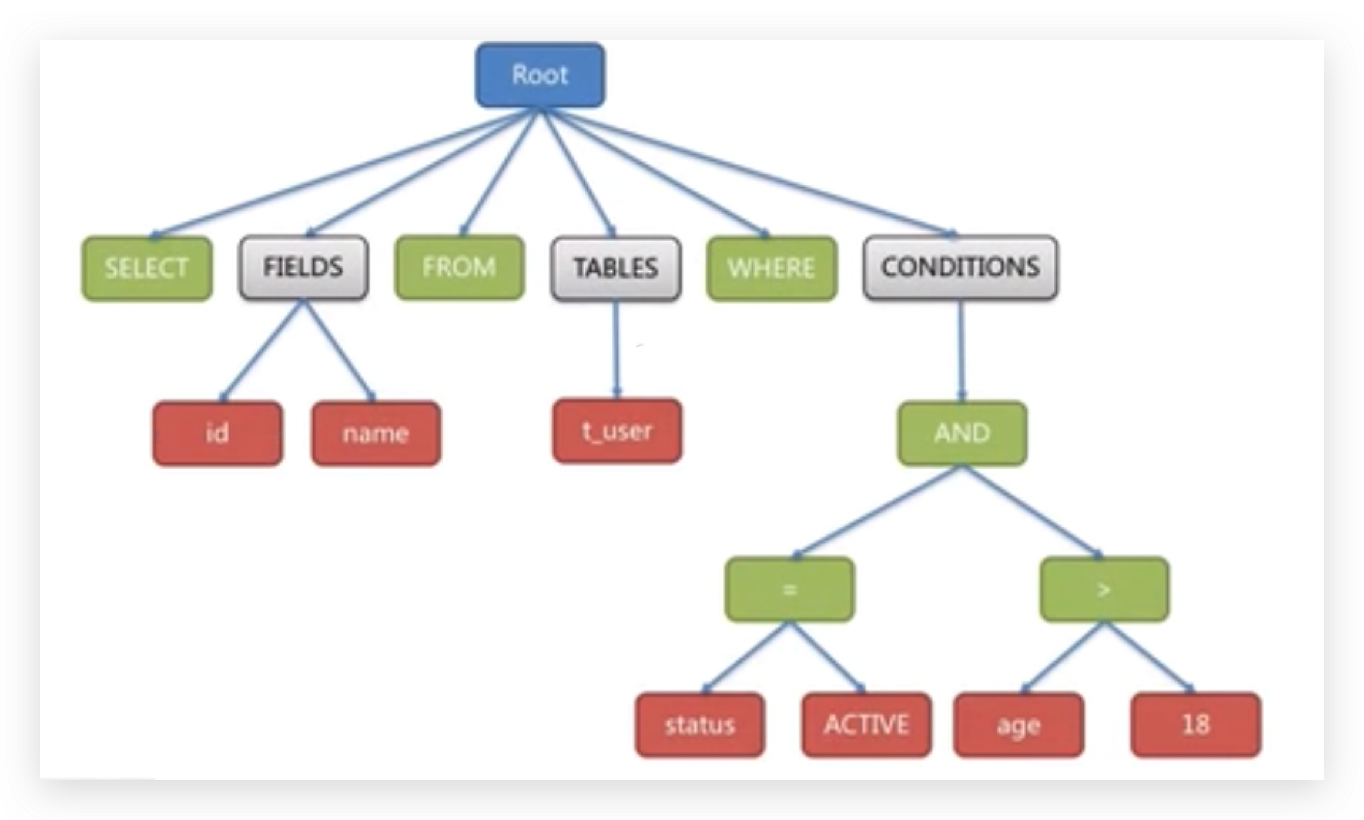
绿色的代表关键字token,按照这样的树形结构来进行具体server的解析工作。
第三部分叫优化器
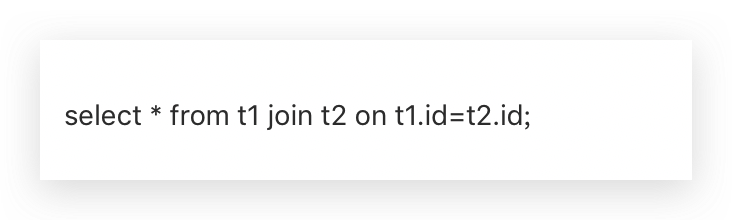
对于这样的sql语句先读取t1表还是先读取t2表,这是优化器来选择的,主要依据于2个标准,第一个标准叫RBO,第二个标准叫CBO;RBO基于规则的优化,CBO是基于成本的优化,现在主流的数据库CBO用的是比较多的,RBO用的比较少。
第四个组件-执行器
执行sql,执行器是需要和存储引擎进行交互的,需要从存储引擎里面把数据查询出来并且返回给客户端,
怎么理解存储引擎
mysql的数据文件存在磁盘,不同的存储引擎在磁盘上的存储形式是不一样的,不同的数据文件在磁盘是不同组织形式,统一的概述叫存储引擎。
Innodb存储引擎文件中有2个同名的文件,frm(表结构相关的元数据信息)和ibd(数据文件和对应的索引文件)。
**MyISAM存储引擎文件中有3个同名的文件,frm(表结构相关的元数据信息)和MYD(数据)和MYI(索引),数据文件和索引文件是分开的。
还包含一个查询缓存组件,8.0以上取消了,因为数据命中率非常低,需要经常的更新里面的数据。
为什么要使用B+树这样的数据结构,自己设计的话,怎么设计?
索引的意义是加快数据访问,提高查询效率,数据存储在磁盘,从磁盘中读取效率很低,特别是在读取大量数据的时候,瓶颈是卡在硬件层面。将电脑机械硬盘换成SSD固态硬盘,速度快,在软件设计的时候可以对io操作进行相关的优化,优化的时候可以考虑2个纬度:
1、尽可能读取少量的数据,减少io量
2、减少io次数
数据是存储在磁盘的,从磁盘读取数据的时候需要涉及到磁体的移动或者说寻址的时间,这都是太浪费时间的,所以能一次性读取就不读取2次。
索引到底要存储什么样的数据?索引的数据格式是什么?
一个非常大的文件里面存储一行一行的数据,如何去定位我想要的数据在哪个位置?并且如何把对应数据位置的数据读取出来?
应该选择什么样的数据格式来存储数据?
在创建索引的时候一定有个key值每次根据key找到了整行的value值,k是字段信息,v是文件名称以及偏移量(可以把当前数据读取出来)以及读取的数据长度,这样的结构会有一个非常大的问题,当数据文件变的越来越大的时候,当前存储索引的文件有可能会变得非常大;数据文件和索引文件的可能会变得非常大,有必要在索引文件的前面再给它建一个索引,不断的在前面加索引,这很明显是不合适的。
OLAP联机分析处理,主要对历史数据进行分析,产生决策,不要求短时间内返回结果,比如数据仓库HIVE,在HIVE中索引确实是这样的方式存在的,但不要求短时间内返回结果;
OLTP联机事务处理,支撑业务系统的需要,在短时间内返回对应的数据结果,比如数据库mysql必须在秒级别和毫秒级别返回数据。
存储k-v格式的数据需要使用什么样的数据结构?
哈希表、二叉树、红黑树、B树、B+树这些数据结构都是存储k-v格式的数据。
把磁盘所有的数据文件全部一口气读取到内存,把所有的索引文件都放入内存,这是不太可能的,所以需要分块读取,分而治之,很多大数据设计都用了这个理念。
哈希表存在什么样的问题

使用哈希表的意义是为了让数据尽可能的散列,因此在使用哈希表的时候要选择合适的哈希算法,避免hash碰撞 和哈希冲突。
如图所示数据不是散列均匀的,数据都集中在1和3号位置;哈希表存储的数据是无序的,当需要进行范围查询的时候只能进行挨个遍历对比,效率极低,哈希表在读取数据的时候不能一块一块去读。
虽然索引没有hash表的数据结构,但是mysql里面有hash索引,mysql中的memory存储引擎支持哈希索引,innodb存储引擎支持自适应hash。
二叉树,BST(binary search tree 二叉搜索树),AVL(平衡二叉查找树),红黑树,这四个的共同点是最多只能有2个分支;BST、AVL、红黑树这3个是有序的,左子树必须小于根节点,右子树必须大于根节点;AVL和红黑树都是平衡的。
三层的树结构,存满之后,最多可以装多少条数据?
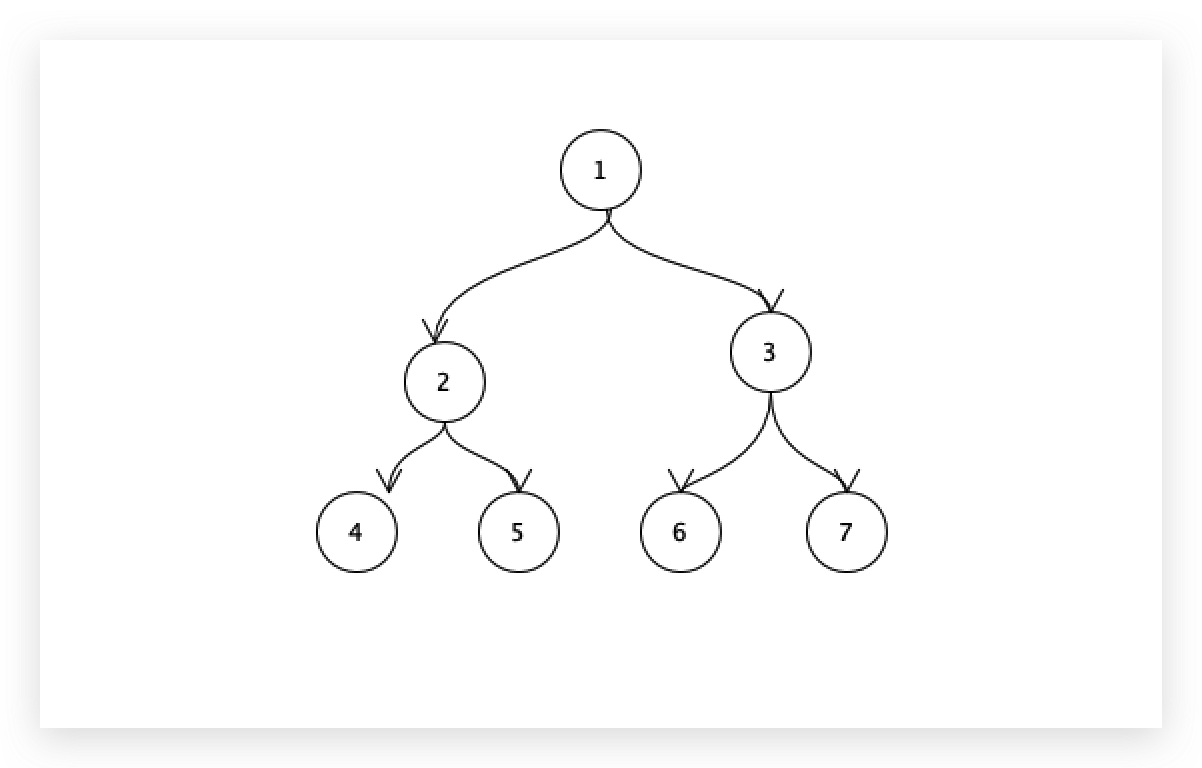
2的3次方-1=7条,
如果想存储更多的数据,只能将树的高度提高,变成四层或五层或更多层,层数变多会有什么影响吗?
io次数会变多,磁盘预读,内存跟磁盘进行数据交互的时候,有一个最基本的逻辑单位称之为页或datapage,页的大小是跟操作系统相关的,一般是4kb或8kb;在进行数据读取的时候,一般操作的是页的整数倍。
当这里有一个页的概念了,内存和磁盘交互的时候是有页了,和刚才说的分而治之关联起来,这里就是天然的分好的块了。
页如果存不满,可以放其他东西吗?
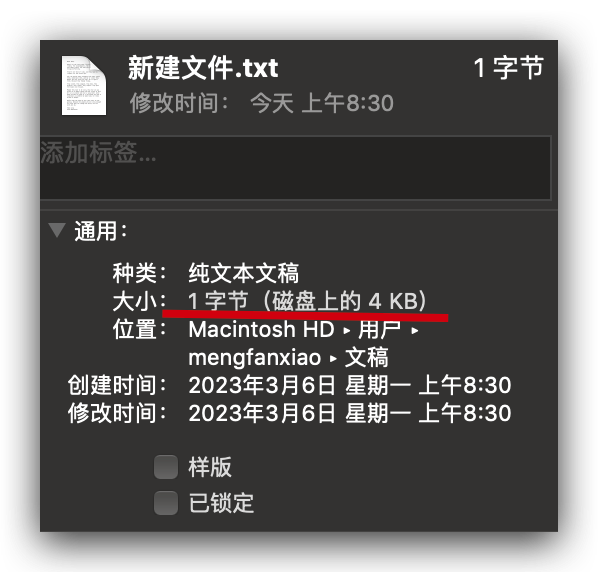
8bit(位)= 1Byte (字节),1024Byte(字节)=1KB,占不满还是占4KB的空间。
每一个节点,如果只能存储一个数据值的话,如果想让它存储更多数据的话,要加层,
每一层或每一个节点里面读取的时候,都是一页一页的,层数加多了,会导致io量变多。
既要尽可能多的存储数据,还要减少io的次数,减少树的高度,如果不能变高,那这个树可以变形吗?如果一个节点放多个值呢?
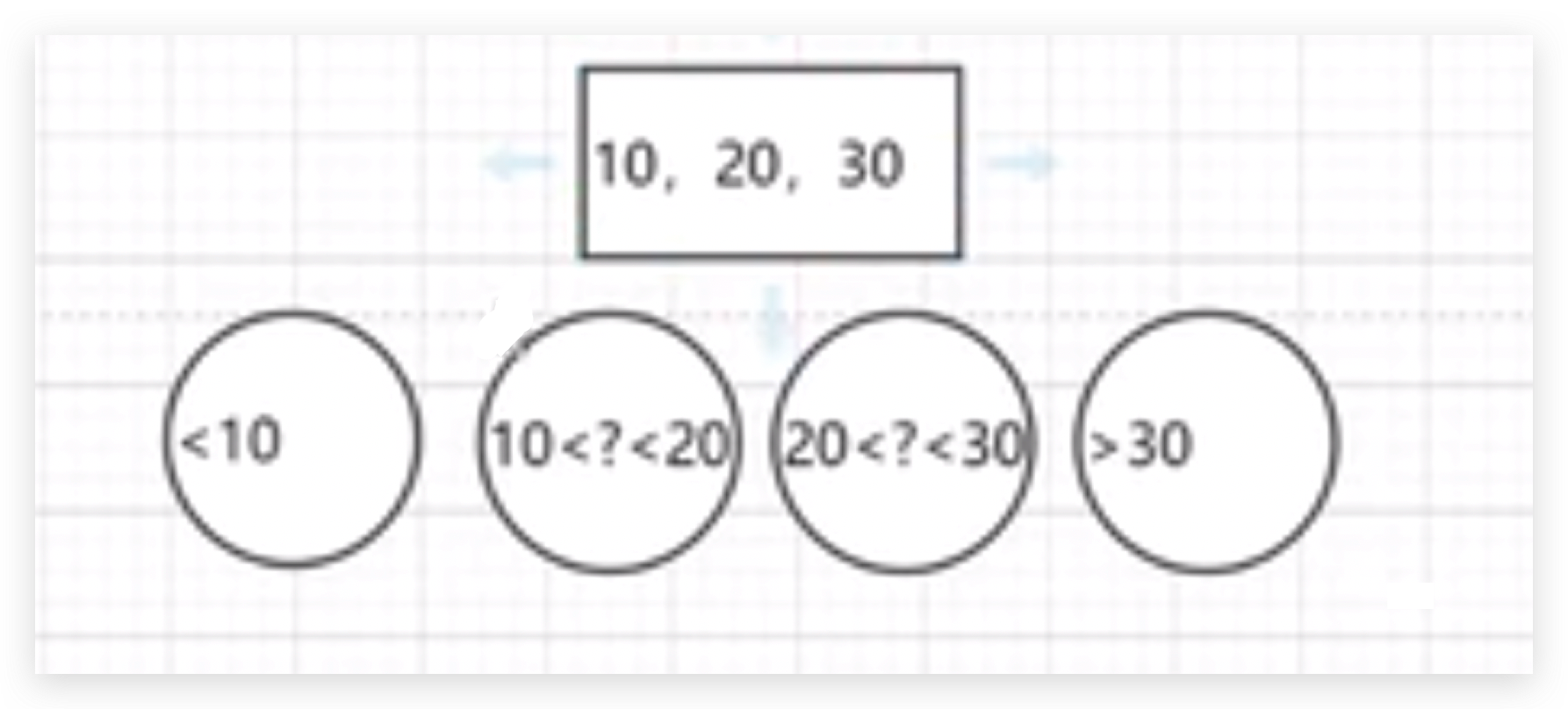
原来是二叉树,让当前这个结构变形为多叉树,当变成多叉树之后,就意味着孩子节点变多了,树变矮了,有序 且平衡,就变成了一个B树了。
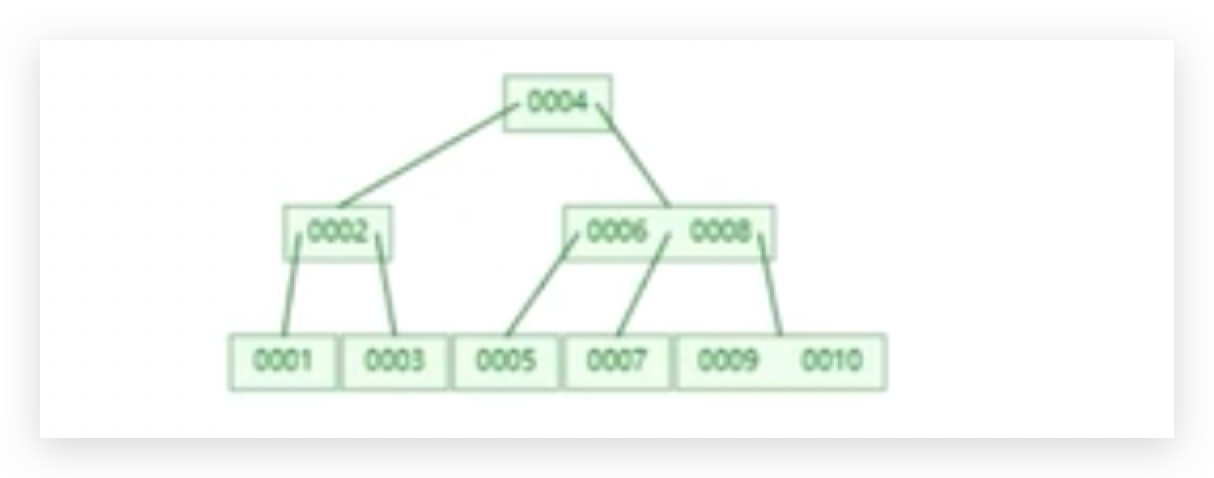
需要把这个B树模型做一个过渡,用来存数据库表和行数据,这个值变成几种类型的数据,首先第一个存放数据的时候key值是要有的,根据key值检索到对应的数据。
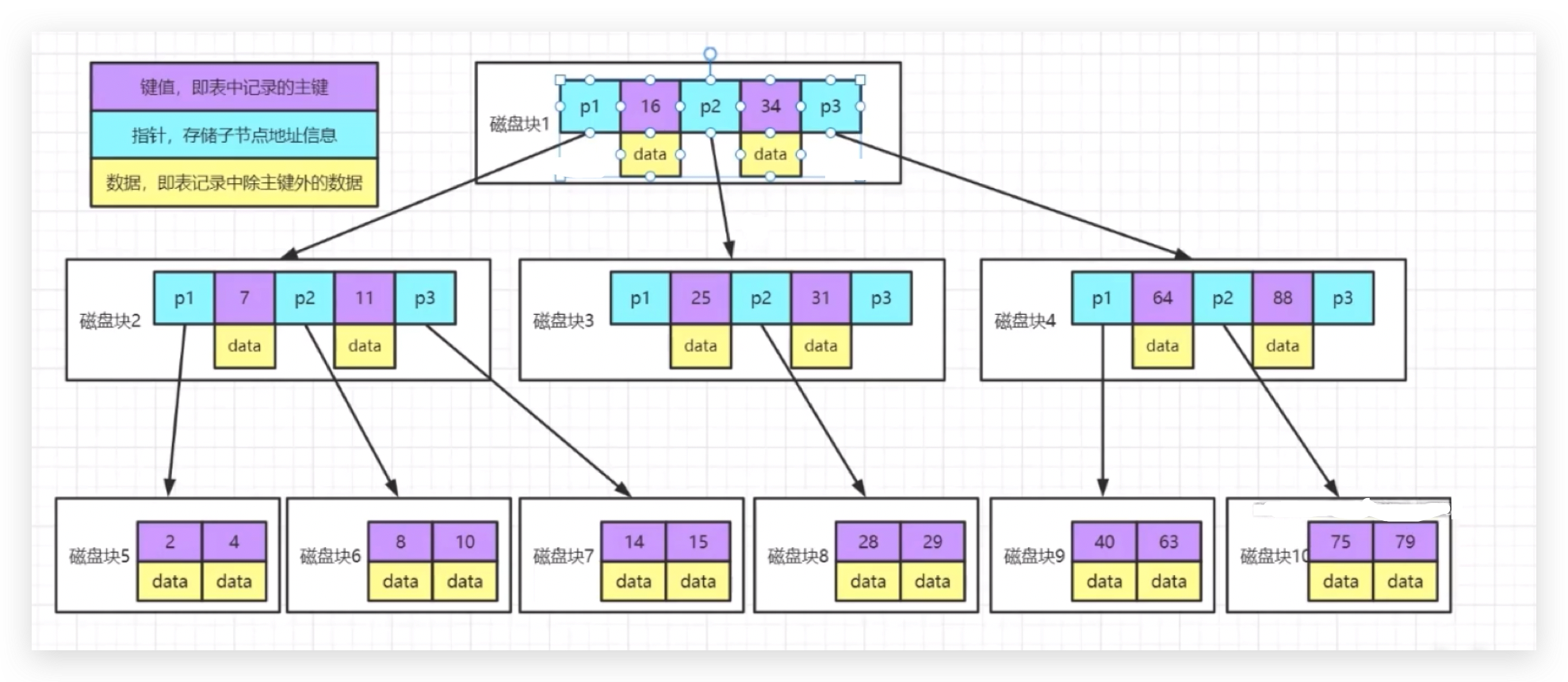
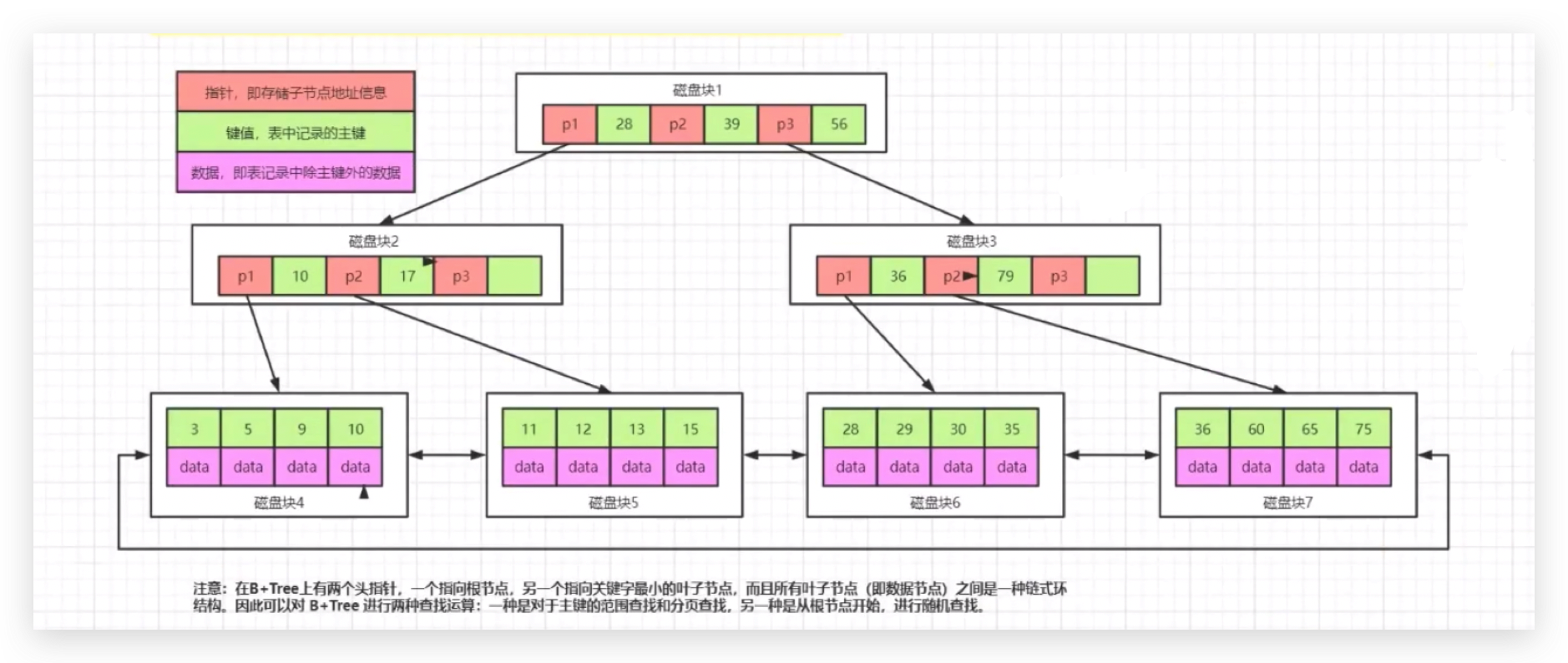
每个方块就代表读取的n个页的信息,每次在进行数据交互的时候读取页的整数倍,每个方块表示读页的整数倍 默认假设16kb,每个磁盘快包含三种类型的数据,16、32表示具体的key值,data表示实际的行数据,p1表示实际的指针。
3层的树,如果要读取28这条数据的话,先读取磁盘块1,把28和36、34对比,正好在中间,沿着p2指针把磁盘块3读取过来,把磁盘块3读取过来之后,再把28和25、31对比,正好在中间,把磁盘块8读取出来,一共读取了3个磁盘块。
在innodb存储引擎里面有一个变量,
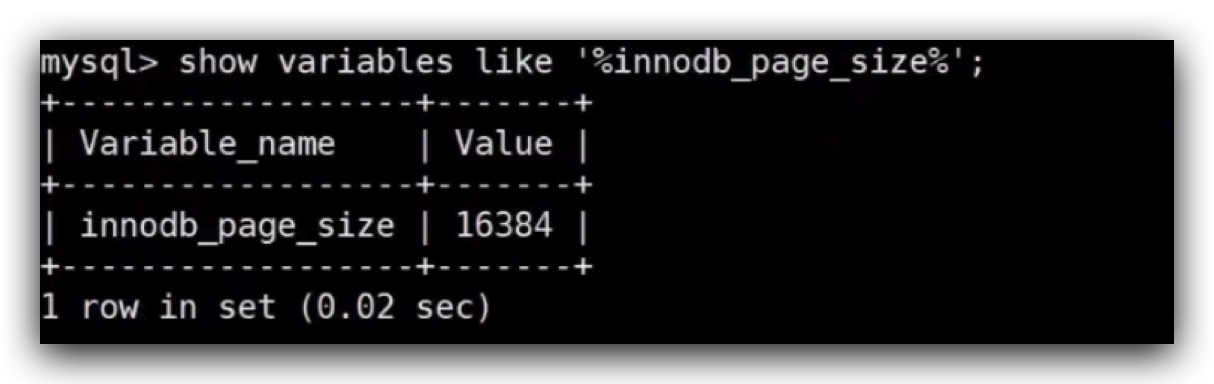
默认读取16kb的数据,每个磁盘块占16k,一共读了48kb的数据,如果这个B树只有3层,存满了之后可以存多少条数据?
假设一个data占1kb,磁盘块1最多能有几个子节点?
最多15个data,16个范围,最多有16个子节点,每层16,三层16 x *16 x *16 = 4096条记录,
为什么三层的B树只能存4000条数据?谁占用了大量的存储空间?
是data,能不能把data去掉?
所以在B树的基础之上有了B+树,
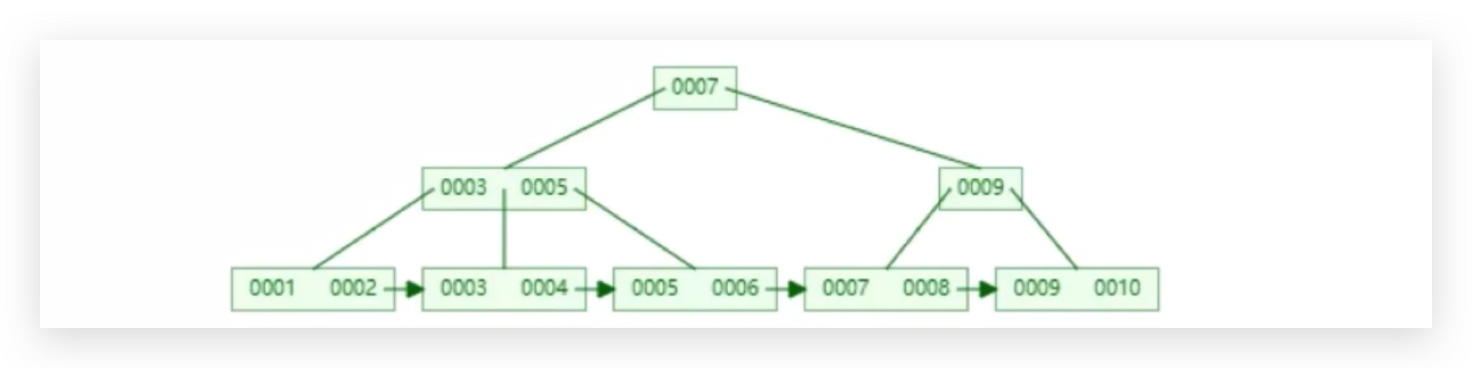
B树数据没有重复的,
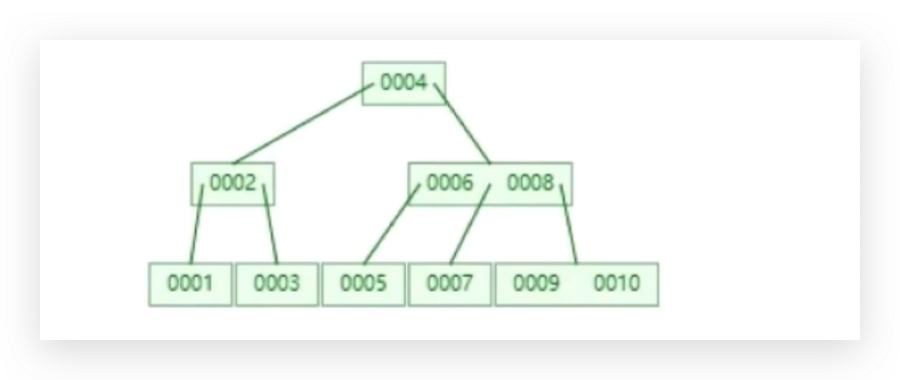
B+树叶子节点包含了全量的数据,非叶子节点包含了部分数据即有一定数据冗余。
所有的data都放到叶子节点里面去了,非叶子节点不存储实际的数据,只有在叶子节点才会存储实际的数据,这样的一个3层B+ Tree,如果存满的话,可以支持多少数据量的存储?
一个磁盘块16kb,读一次,3层,3个磁盘块,比如读取磁盘块1->磁盘块3->磁盘块7,依然读取了48kb的数据,假设磁盘块1中的p1+28占了10个字节,16*1024/10大约1600个子节点,第二层一个磁盘块也是1600个节点,第三层只能存16条,存满的话1600 x 1600 x 16=40960000,千万级别。
B+tree的索引一般是3层,一般情况下3-4层的B+tree足以支撑千万级别的数据量存储,
刚刚计算公式谁占了绝大部分空间?指针的大小是不变的,索引列的值是有可能会变化的,索引影响最大的是key这个值,所以要保证key尽可能小的占用存储空间。
在创建索引的时候,用int类型好?还是varchar类型好?
int占4个字节,但是varchar占用的字节是自己指定的,比如varchar(3),即谁占用的空间小,就用哪个列作为索引。
mysql表创建的时候,主键要不要自增?在满足业务系统支撑的情况下尽可能的自增,这里面会涉及到索引的维护。
假设磁盘块5最多只能放4条记录,
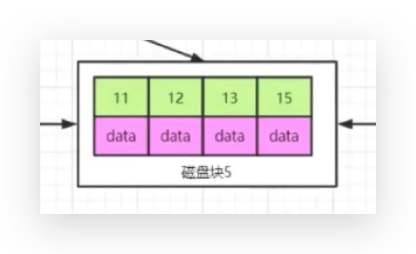
当存满了之后,要插入一条14的记录,底层的叶子节点是有顺序的,所以要把磁盘块5拆分成2个磁盘块,11、12
和13、15,分开之后,上层磁盘块2也需要增加一个指针,如果磁盘块2也满了,也要分裂成两个....
所以在进行数据插入的时候,有可能会影响到上层的新增,就会很麻烦。
而递增后到效果是在后面追加就行了,对上层没有影响,所以在满足业务系统的情况下,尽可能的自增,而分布式环境下可以通过雪花算法自增。