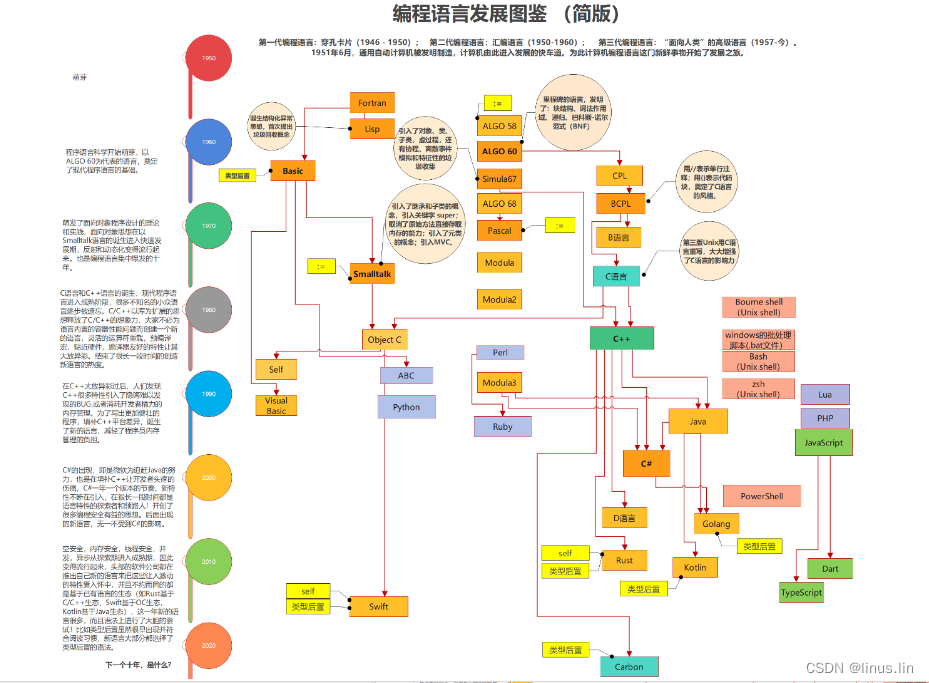
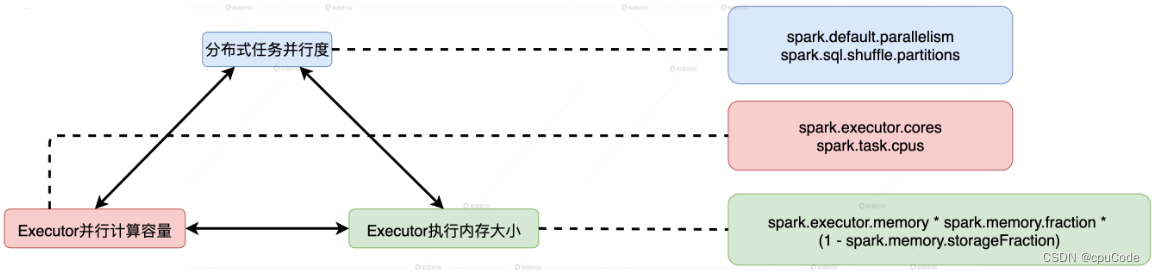
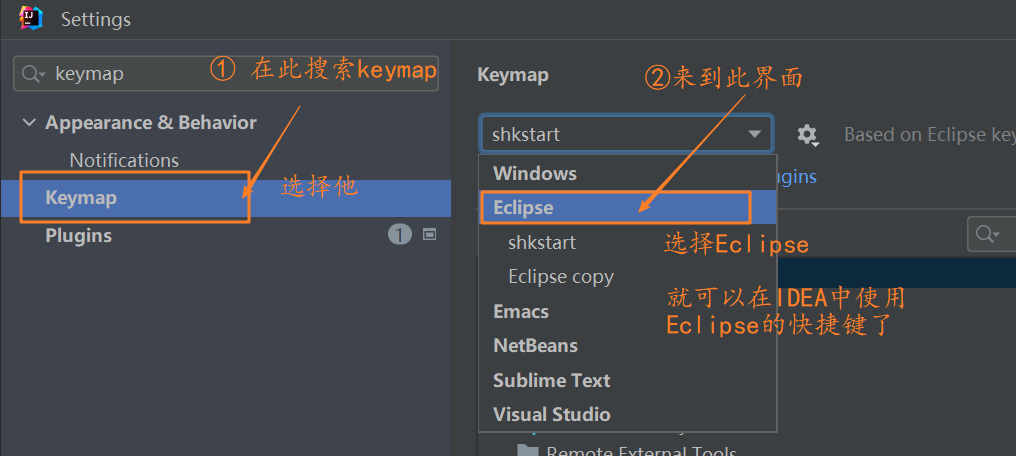
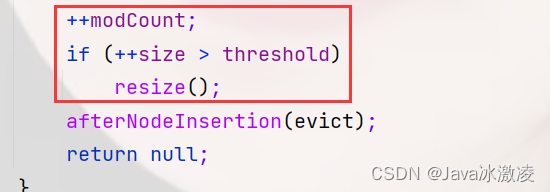
对于开发人员来说,工作都是从评估一个需求开始。我们第一个要解决的问题就是看待需求的视角。视角的不同,得到的设计方案可能是完全不同的。作为一个程序员,不能单单从个人视角来看待问题。而是要尝试从不同角色出发,不停思考。
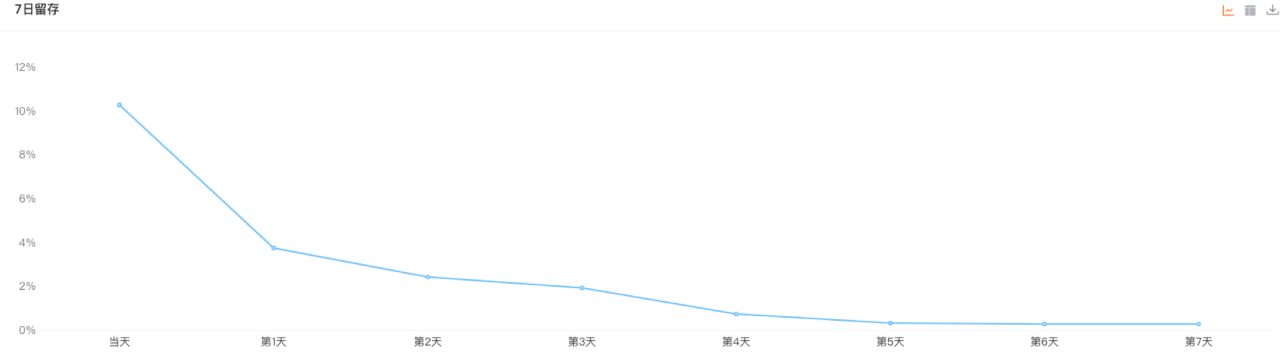
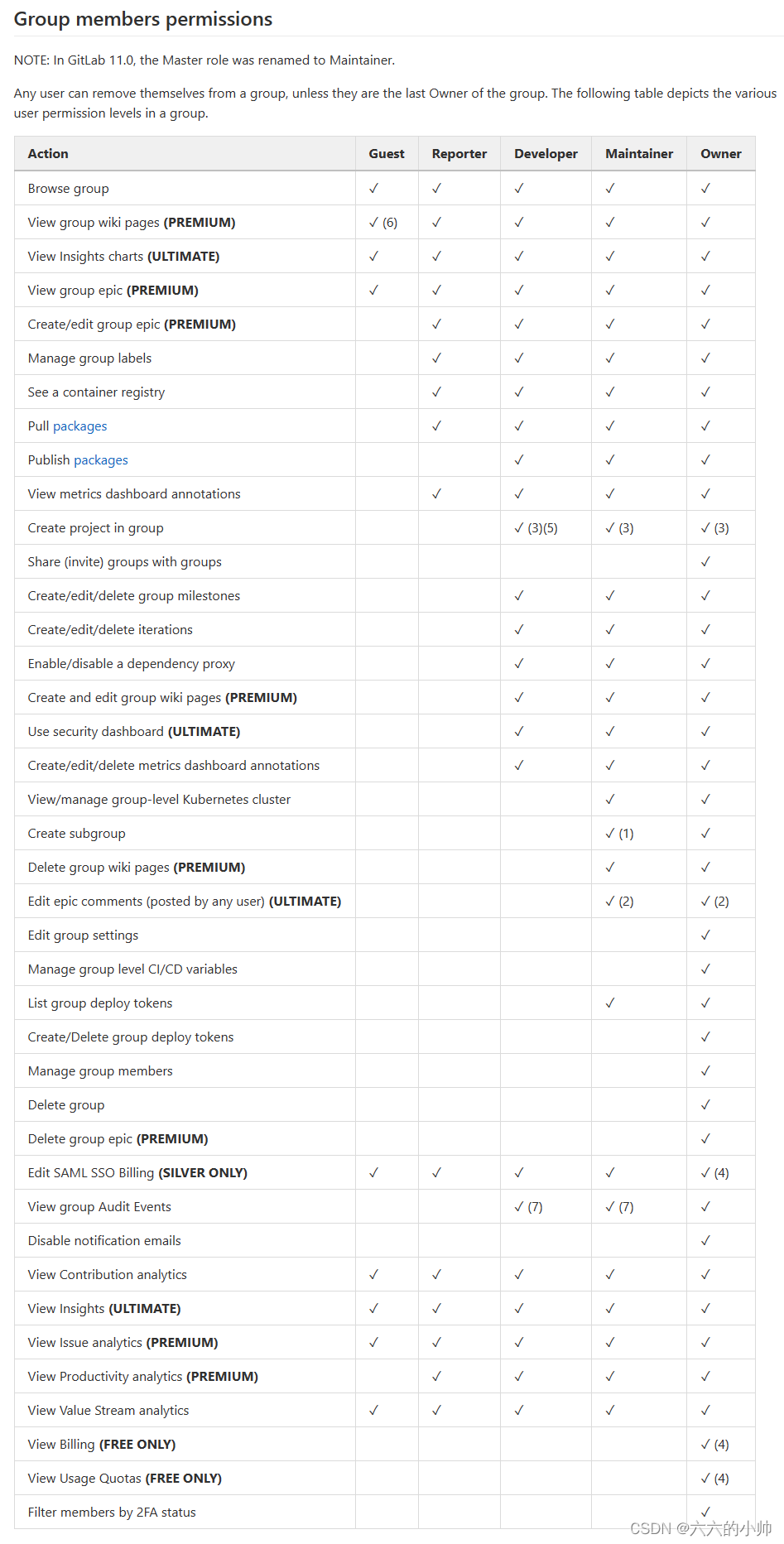
上图是出自一个数据平台7日留存功能。在该原型图中,计算了每天的留存率,并以趋势图的形式呈现出来。常规服务端数据结构定义可能如下:
class RetainRatio {
/**
* 日期
*/
private String day;
/**
* 留存比例
*/
private double ratio;
}RetainRatio代表了留存的数据结构,其中day为日期;ratio为留存率。服务端将数据封装为List<RetainRatio>结构,传递给客户端,由客户端进行展现。
乍看起来没有问题,但是,对于数据平台,可能存在着大量的其他图形分析的需求,如下图是一个行为按日期统计次数的趋势图。
class EventCount {
/**
* 日期
*/
private String day;
/**
*次数
*/
private Integer count;
}很明显,当整个系统中存在着大量画像分析时,将会出现非常多的数据结构定义。我们再来考虑一下,如此多的定义,带来的程序复杂度。
对于服务端开发人员,定义大量数据结构,来承载不同的趋势图结构。
对于客户端开发人员,需要理解不同数据结构,并使用不同的代码来渲染和展现UI效果。
程序设计者往往站在数据结构的角度来看待问题,那么,我们从客户端开发人员的角度进行思考。他们根本不想关注数据结构中的day、ratio、count等。而只关注如何将趋势图展现出来。他们唯一需要的就是横坐标和纵坐标。而具体字段的含义,于客户端代码的编写并没有太大关系。
本着解决一类问题,而不是解决一个问题的思路。我们试着将数据结构定义为如下形式:
public class TrendLine {
/**
* 名称
*/
private String name;
/**
* 曲线上的所有点
*/
private List<TrendPoint> pointList;
}
class TrendPoint {
/**
* 纵坐标的值
*/
private double verticalVal;
/**
* 横坐标的值
*/
private String horizontalVal;
}
TreadLine代表了一条趋势线,趋势线上有若干个点List<TrendPoint>;而每个TrendPoint中含有横坐标(horizontalVal)和纵坐标(verticalVal)。
如此一来,暴露给客户端的数据含义就变为了:线——点——横纵坐标,三个概念。那么整个系统中,所有类似趋势图的图表,均可利用这一结构进行封装。
我们再来看程序的复杂度:
服务端多中数据结构定义统一为一种,在计算时,均向该结构统一。
客户端不再理解具体的业务意义(天、行为、留存率等等),仅仅理解:线——点——坐标三个概念。UI展示时的代码,也只会有一份。
我们可以将这一思路,提升为“视角”这一概念。系统设计者在设计时,需要综合考量各个角色视角所关注的东西。
服务端,关注数据计算。
客户端,关注展示,而并不想关注具体业务是什么——例如本例中的天,次数,留存率,行为等等。
测试端,只关注计算和展示的结果是否正确,更加不会关注具体数据结构如何封装。
换句话说,上游向下游暴露什么数据,直接决定了下游理解的复杂度。上游向下游暴露的信息,在保证足够的情况下,应该是尽量收敛,而非无限扩散的。