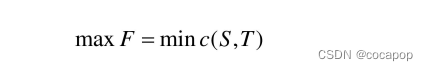文章目录
- 1. Abstract
- 2. Introduction
- 3. Background
- 4. Design Overview
- 5. Program Sampling
- 5.1 Sketch Generation
- 5.2 Random Annotation
- 6. Performance Fine-tuning
- 6.1 Evolutionary Search
- 6.2 Learned Cost Model
- 7. Task Scheduler
- 7.1 Problem Formulation
- 7.2 Optimizing with Gradient Descent
1. Abstract
高性能张量程序是保证深度神经网络有效执行的关键。然而,在各种硬件平台上获得不同算子的性能较好的张量程序是非常具有挑战性的。目前,深度学习系统依赖于硬件供应商提供的内核库(kernel libraries)或各种各样的搜索策略来获取性能较好的张量程序。但这些方法有两个弊端:
(1)需要巨大的工程量来开发平台特定的优化代码;
(2)有限的搜索空间和无效的搜索策略导致很难发现高性能张量程序。
作者基于上述弊端,提出了Ansor,一个用于深度学习应用的张量程序生成框架。对比现有的搜索策略,Ansor有以下特征:
(1)通过从搜索空间的分层表示(hierarchical representation)中采样程序以探索更多的优化组合(optimization combinations);
(2)使用进化搜索(evolutionary search)和学习成本模型(cost model)对采样程序进行微调(fine-tune),以确定最优的程序;
(3)利用任务调度器(task scheduler)来同时优化深度神经网络的多个子图。
作者的实验表明,Ansor能够找到现有最先进(state-of-the-art,SOAT)方法搜索空间之外的高性能程序:是Intel CPU的3.8倍,ARM CPU的2.6倍,NVIDIA GPU的1.7倍。
2. Introduction
深度神经网络(DNN)的低延迟执行在自动驾驶(autonomous driving)、增强现实(augmented reality)、语言翻译(language translation)及其他的AI应用中发挥着至关重要的作用。DNN可以表示为一个有向无环计算图(directed acyclic graph, DAG),结点表示算子(卷积,矩阵乘),有向边表示算子之间的依赖关系。现有的深度学习框架(Tensorflow, PyTorch, MXNet)将DNN中的算子映射为供应商提供的内核库(cuDNN, MKL-DNN)以获取高性能。然而,这些内核库需要巨大的工程量为每个硬件平台和算子进行手动调优,为每个目标加速器产生有效的算子实现所需的大量手工工作限制了新算子和特定加速器的开发和创新。
鉴于DNN性能的重要性,研究者和行业从业者已经转向基于编译器搜索(search-based compilation)来自动生成张量程序,比如张量算子的低级实现。对于一个算子或者多个算子的子图,用户需要用高级声明性语言来定义计算,然后编译器搜索针对不同硬件平台的定制程序。
3. Background
深度学习生态系统正在拥抱快速增长的硬件平台多样性,包括CPU、GPU、FPGA和ASIC。为了在这些平台上部署DNN,需要为DNN中使用的算子提供高性能张量程序,所需的算子集通常包含标准算子(matmul, conv2d)和机器学习研究人员发明的新算子(capsule conv2d, dilated conv2d)。
为了以高效的方式在广泛的硬件平台上提供这些算子的可移植性,多种编译器技术已经出现(TVM, Halide, Tensor Comprehensions)。用户使用高级声明性语言以类似数学表达式的形式定义计算,编译器根据定义生成优化的张量程序。下图显示了TVM张量表达式语言中矩阵乘法的计算定义,用户主要需要定义输入张量的形状,以及如何计算输出张量中的每个元素。

然而,从高级定义自动生成高性能张量程序是极其困难的。根据目标平台的体系结构,编译器需要在一个包含优化组合选择的极其大而复杂的空间中进行搜索(例如,展开结构(tile structure),展开大小(tile size),向量化(vectorization),并行化(parallelization)),寻找高性能的程序需要搜索策略覆盖一个全面的空间,并有效地探索它。

4. Design Overview

Program sampler:Ansor必须解决的一个关键挑战是为给定的计算图生成大的搜索空间。为了覆盖具有各种高级结构和低级细节的各种张量程序,Ansor利用了具有两个级别的搜索空间的分层表示:草图(sketch)和注释(annotation)。Ansor将程序的高级结构定义为草图,并将数十亿个低级选择(例如,平铺大小(tile size)、并行(parallel)、展开注释(unroll annotations))作为注释,这种表示法允许Ansor灵活地枚举高级结构并有效地采样低级细节。
Performance tuner:随机抽样程序的性能不一定好,下一个挑战是对它们进行微调。Ansor采用进化搜索和学习成本模型来迭代地执行微调,在每次迭代中,Ansor使用重新采样的新程序以及以前迭代中的好程序作为初始种群来开始进化搜索。进化搜索通过变异和交叉对程序进行微调,执行乱序重写并解决顺序构造的限制。查询学习到的成本模型比实际测量快几个数量级,因此我们可以在几秒钟内评估数千个程序。
Task scheduler:使用程序采样和性能微调允许Ansor为计算图找到高性能张量程序。直观地说,处理一个完整DNN作为一个单一的计算图,并为其生成一个完整的张量程序,可以潜在地实现最佳性能。然而,这是低效的,因为它必须处理搜索空间不必要的指数爆炸。通常,编译器将DNN的大计算图划分为几个小的子图,由于DNN的逐层(layer-by-layer)构造特性,这种划分对性能的影响可以忽略不计,这就带来了Ansor的最后一个挑战:在为多个子图生成程序时如何分配时间资源?
Ansor中的任务调度器使用基于梯度下降的调度算法将资源分配给更有可能提高端到端DNN性能的子图。
5. Program Sampling
算法探索的搜索空间决定了它能找到的最佳程序。现有方法所考虑的搜索空间受到以下因素的限制:
(1)手动枚举(TVM):通过模板手动枚举所有可能的选择是不切实际的,因此现有的手动模板只能启发式地覆盖有限的搜索空间;
(2)积极的早期剪枝(Halide auto-scheduler):基于评估不完整程序的激进早期修剪阻止搜索算法探索空间中的某些区域。
为了解决(1),作者通过递归应用一组灵活的推导规则来自动扩展搜索空间;
为了避免(2),作者在搜索空间中随机抽样完整的程序。
由于随机抽样给每个被抽样的点机会是相等的,作者提出的搜索算法可以潜在地探索所考虑空间中的每个程序,不依赖于随机抽样来找到最优程序,因为每个抽样程序后来都经过了微调。
在顶层,通过递归地应用一些派生规则来生成草图。在底层,随机地注释这些草图以得到完整的程序。这种表示从数十亿个低级选择中总结了一些基本结构,从而实现了对高级结构的灵活枚举和对低级细节的高效采样。

5.1 Sketch Generation
上图中的第一列显示了两个输入示例。输入有三种等效形式:数学表达式、直接展开循环指标得到的相应naive程序和相应的计算图(DAG)。
在计算机编程领域中,
"naive program"通常是指一种简单或者朴素的程序实现方式。这种程序可能没有考虑所有可能的情况,或者没有利用现有的优化技术。"naive"这个词通常用来描述某些程序员在编写代码时缺乏经验或技术水平较低的情况。在这种情况下,程序员可能会使用一些基本的算法或数据结构,而没有考虑到更复杂或高效的解决方案。这种程序通常会占用大量的计算资源,运行速度较慢。------by ChatGPT
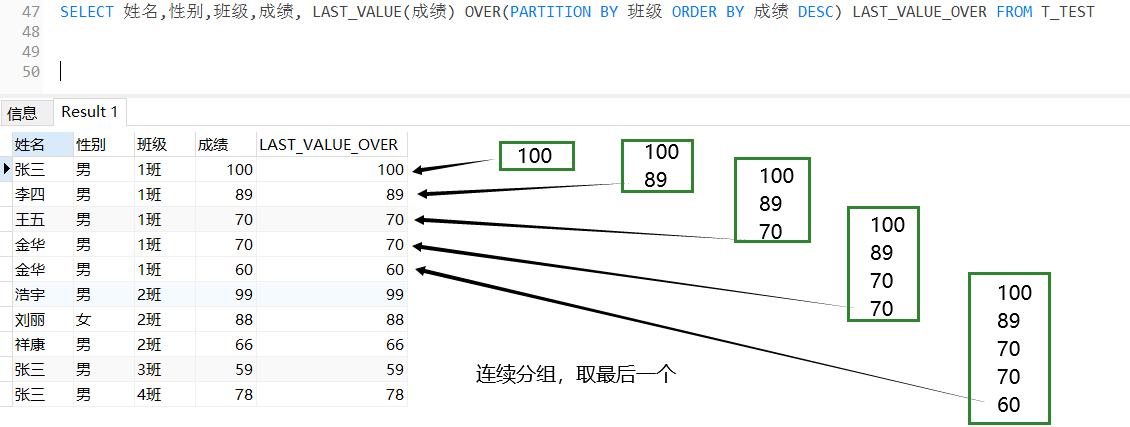
为了给具有多个节点的DAG生成草图,我们以拓扑顺序访问所有节点,并迭代地构建结构。对于计算密集型和有大量数据重用机会的计算节点(conv2d, matmul),我们为它们构建基本的平铺和融合结构作为草图,对于简单的元素节点(ReLU, elementwise add),我们可以安全地内联它们。注意,新节点(缓存节点(caching nodes),布局转换节点(layout transform nodes))也可以在草图生成过程中引入DAG。
作者提出了一种基于派生的枚举(derivation-based enumeration)方法,通过递归应用几个基本规则来生成所有可能的草图。这个过程以DAG作为输入,并返回草图列表。我们定义State
σ
=
(
S
;
i
)
\sigma = (S;i)
σ=(S;i),其中
S
S
S 是DAG当前部分生成的草图,
i
i
i 是当前工作节点的索引,DAG中的节点按照从输出到输入的拓扑顺序进行排序。推导从初始naive程序和最后一个节点开始,或者初始状态
σ
=
(
n
a
i
v
e
p
r
o
g
r
a
m
;
i
n
d
e
x
o
f
t
h
e
l
a
s
t
n
o
d
e
)
\sigma = (naive\ program;\ index\ of\ the\ last\ node)
σ=(naive program; index of the last node),然后我们尝试递归地将所有推导规则应用于这些状态。对于每条规则,如果当前状态满足应用条件,我们应用这条规则
σ
=
(
S
;
i
)
\sigma = (S;i)
σ=(S;i)得到
σ
′
=
(
S
′
;
i
′
)
,
i
′
<
i
\sigma \prime= (S\prime;i\prime),\ i\prime < i
σ′=(S′;i′), i′<i,这样,索引
i
i
i(工作节点)单调地减小,当
i
=
0
i = 0
i=0时,一个状态就变成了终端状态。在枚举过程中,可以对一个状态应用多个规则,从而生成多个后续状态,一个规则还可以生成多个可能的后续状态。因此,我们维护一个队列来存储所有中间状态,当队列为空时,进程结束。所有处于终端状态的
σ
.
S
\sigma .S
σ.S在草图生成结束时形成草图列表。对于典型的子图,草图的数量小于10。
// 递归应用几个基本规则来生成所有可能的sketch
// Derivation rule based enumeration
Array<State> out_states;
while (!pnow->empty()) {
pnext->clear();
for (const State& state : *pnow) {
int stage_id = cur_stage_id_map[state];
// Reaches to the terminal stage
if (stage_id < 0) {
out_states.push_back(state);
continue;
}
// Try all derivation rules
for (const auto& rule : sketch_rules) {
auto cond = rule->MeetCondition(*this, state, stage_id);
if (cond != SketchGenerationRule::ConditionKind::kSkip) {
for (const auto& pair : rule->Apply(*this, state, stage_id)) {
cur_stage_id_map[pair.first] = pair.second;
pnext->push_back(pair.first);
}
// Skip the rest rules
if (cond == SketchGenerationRule::ConditionKind::kApplyAndSkipRest) {
break;
}
}
}
}
std::swap(pnow, pnext);
}
// Conv2d(3, 64, kernel_size=(7, 7), stride=2, padding=1)有3个sketch生成

Derivation rules:上述表格列出了用于CPU的派生规则。作者首先提供所使用谓词的定义,然后描述每个规则的功能,然后对计算定义执行静态分析,以获得这些谓词的值,分析是通过解析数学表达式中的读/写模式自动完成的。我对上述表格进行了整理:
Condition | Description |
|---|---|
| I s S t r i c t I n l i a b l e ( S , i ) IsStrictInliable(S,i) IsStrictInliable(S,i) | 表示
S
S
S中的节点
i
i
i是一个简单的按元素(element-wise)计算的算子,比如element-wise add和ReLU |
| H a s D a t a R e u s e ( S , i ) HasDataReuse(S,i) HasDataReuse(S,i) | 表示
S
S
S中的节点
i
i
i是计算密集型(compute-intensive)算子,并且具有大量的算子内数据重用机会,比如matmul和 conv2d |
| H a s F u s i b l e C o n s u m e r ( S , i ) HasFusibleConsumer(S, i) HasFusibleConsumer(S,i) | 表示
S
S
S中的节点
i
i
i只有一个消费者节点
j
j
j,节点
j
j
j可以融合到节点
i
i
i中,比如matmul + bias_add和conv2d + relu |
| H a s M o r e R e d u c t i o n P a r a l l e l ( S , i ) HasMoreReductionParallel(S, i) HasMoreReductionParallel(S,i) | 表示
S
S
S中的节点
i
i
i在空间维度上并行性很小,但在降维上有足够的并行机会,比如计算矩阵的L2范数,矩乘
C
2
×
2
=
A
2
×
512
⋅
B
512
×
2
C_{2\times2}=A_{2\times512} \cdot B_{512\times2}
C2×2=A2×512⋅B512×2 |
在计算机编程中,
"inline"通常指的是一种编译器优化技术,即在编译代码时将函数调用直接替换为函数体内的代码。这样可以避免函数调用时的额外开销,从而提高代码的执行效率。
在C++中,我们可以使用关键字"inline"来告诉编译器,将某个函数作为inline函数来处理。在C++程序中使用inline函数的好处是可以减少函数调用的开销,从而提高程序的运行效率。此外,使用inline函数还可以减少代码的重复,因为每次调用该函数时都会将函数的代码嵌入到调用位置。
需要注意的是,虽然使用inline函数可以提高程序的性能,但并不是所有函数都适合作为inline函数。一般来说,较小的、频繁调用的函数最适合作为inline函数,而较大的、复杂的函数则不适合作为inline函数。此外,inline函数可能会增加代码的体积,因此需要在代码大小和性能之间进行权衡。------by ChatGPT
Rule 1只是简单地跳过一个节点,如果这个节点不是严格内联的;
Rule 2始终是严格内联节点,由于Rule1和Rule2的条件是互斥的,
i
>
1
i > 1
i>1的状态总是可以满足其中一个条件并继续推导;
Rule 3是为数据可重用节点执行多级平铺。对于CPU,我们使用"SSRSRS"平铺结构,其中"S"代表一个平铺级别的空间循环(space loop),"R"代表一个平铺级别的缩减循环(reduction loop)。例如,在矩乘
C
(
i
,
j
)
=
∑
k
A
[
i
,
k
]
×
B
[
k
,
j
]
C(i,j) = \sum_k A[i,k] \times B[k,j]
C(i,j)=∑kA[i,k]×B[k,j],
i
i
i和
j
j
j是空间环,
k
k
k是缩减环。矩乘的"SSRSRS"平铺结构将原来的3级循环
(
i
,
j
,
k
)
(i,j,k)
(i,j,k)扩展为一个10级循环
(
i
0
,
j
0
,
i
1
,
j
1
,
k
0
,
i
2
,
j
2
,
k
1
,
i
3
,
j
3
)
(i_0,j_0,i_1,j_1,k_0,i_2,j_2,k_1,i_3,j_3)
(i0,j0,i1,j1,k0,i2,j2,k1,i3,j3),虽然没有打乱循环顺序,但这种多级平铺也可以覆盖一些重新排序的情况。例如,上面的10级循环可以专门用于简单的重排序
(
k
0
,
j
2
,
j
3
)
(k_0,j_2,j_3)
(k0,j2,j3)通过设置其他循环的长度为1。"SSRSRS"平铺结构一般用于深度学习中的计算密集型密集算子(matmul, conv2d, conv3d),因为它们都由space loop和reduction loop组成;
Rule 4是执行多级平铺,还融合了可融合的消费者。例如,可以将按元素划分的节点(ReLU,bias_add)融合到平铺节点(conv2d, matmul);
Rule 5是如果当前数据可重用节点没有可融合的消费者,则添加缓存节点。例如,DAG中的最终输出节点没有任何消费者,因此默认情况下它直接将结果写入主存,由于内存访问的高延迟,这是低效的。通过添加一个缓存节点,我们在DAG中引入了一个新的可融合的消费者,然后可以应用Rule 4将这个新添加的缓存节点融合到最终的输出节点中。随着缓存节点的融合,现在最终输出节点将其结果写入缓存块,当块中的所有数据计算完毕时,缓存块将立即写入主存;
Rule 6可以使用rfactor将reduction loop分解为space loop,以带来更多的并行性;
可见Rule 3、Rule 4和Rule 5处理具有数据重用的节点的多级平铺和融合。
对于
GPU,我们使用"SSSRRSRS"平铺结构,前三个空间平铺中的循环分别绑定到BlockIdx,虚拟线程(virtual thread,用于减少bank冲突)和ThreadIdx,并添加了两种草图派生规则,一种是通过插入缓存节点来利用共享内存(类似于Rule 5),另一种用于跨线程减少(类似于Rule 6)。
本小节的开头那张图显示了生成草图的三个示例。草图与TVM中的手动模板不同,因为手动模板同时指定高级结构和低级细节,而草图只定义高级结构。以Input 1为例,DAG中四个节点的排序顺序为
(
A
,
B
,
C
,
D
)
(A,B,C,D)
(A,B,C,D)。为了得到DAG的草图,我们从输出节点
D
(
i
=
4
)
D(i=4)
D(i=4)开始,并逐个对节点应用规则。具体来说,生成的Sketch 1的推导过程为:

对
Input 1的DAG中的是个节点进行理解:A和B为输入数据节点,C为matmul节点,D为输出节点,A,B和D节点应用Rule 1,C节点应用Rule 4。
对于示例Input 2,五个节点的排序顺序为
(
A
,
B
,
C
,
D
,
E
)
(A,B,C,D,E)
(A,B,C,D,E)。类似地,我们从输出节点
E
(
i
=
5
)
E(i = 5)
E(i=5)开始,递归地应用规则,生成Sketch 1的推导过程为:

对
Input 2的DAG中的是个节点进行理解:A和D为输入数据节点,B为max节点,C为xxx节点,E为matmul节点,同时也是输出节点,A,C和D节点应用Rule 1,B节点应用Rule 2,E节点应用Rule 5插入一个缓存节点,然后在应用Rule 4。
同样地,生成Sketch 3的派生过程为:

5.2 Random Annotation
上一小节生成的草图是不完整的程序,因为它们只有平铺结构,没有特定的平铺大小和循环注释(loop annotation),比如并行、展开和向量化。在本小节中,将对草图进行注释,使其成为用于微调和评估的完整程序。
给定一个生成的草图列表,我们随机选择一个草图,随机填充平铺尺寸,并行化一些外部循环,向量化一些内部循环,并展开一些内部循环。我们还随机改变程序中某些节点的计算位置,以对平铺结构进行轻微调整。这里的所有"随机"是指在所有有效值上的均匀分布。如果某些特殊算法需要自定义注释才能有效(例如,特殊展开),允许用户在计算定义中给出简单的提示来调整注释策略。最后,由于改变常数张量的布局可以在编译时间内完成,并且不会带来运行时开销,因此我们根据多级平铺结构重写常数张量的布局,以使它们尽可能地对缓存友好。这种优化是有效的,因为卷积或全连接层的权重张量是推理应用的常数。
随机抽样的例子可以看本小节的开头那张图,抽样程序的循环可能比草图更少,因为长度为1的循环被简化了。
loop annotation是指在循环体中添加特定的标记,以告诉编译器该循环体的性质和特点,帮助编译器更好地优化循环体的执行。这些标记通常是以注释的形式添加在代码中的循环体中。
常见的loop annotation包括:
1.unroll:展开循环,即将循环体中的代码复制多次,减少循环控制语句的开销。
2.vectorize:向量化循环,即将多次执行的相同操作合并为一次操作,以加速循环体的执行。
3.parallelize:并行化循环,即将循环体中的多次迭代分配到不同的处理器核心或线程中执行,以加速循环体的执行。
4.pipeline:将循环体中的多次迭代分成多个阶段,并在不同的处理器核心或线程中同时执行,以加速循环体的执行。
使用loop annotation需要根据具体情况选择适当的标记,并根据硬件设备的特点进行优化。虽然loop annotation可以提高循环体的执行效率,但过多的loop annotation也可能会降低代码的可读性和可维护性。因此,在使用Lloop annotation时需要进行权衡和评估,以确定最佳的优化方案。------by ChatGPT
6. Performance Fine-tuning
程序采样器采样的程序对搜索空间有很好的覆盖,但它们的质量不能保证,这是因为优化选项,比如平铺结构和循环注释,都是随机采样得到的。因此作者引入了性能调优器,它通过进化搜索和学习成本模型对采样程序的性能进行微调。
微调是迭代执行的,在每次迭代中,我们首先使用进化搜索,根据学习成本模型找到一小批有前景的程序,然后在硬件上测量这些程序以得到实际的执行时间成本,最后,利用测量得到的性能数据对成本模型进行重新训练,使其更加准确。
进化搜索使用随机抽样的程序以及之前测量的高质量程序作为初始种群,并应用突变和交叉来生成下一代。学习成本模型用于预测每个程序的适应性(fitness),在我们的例子中,这是一个程序的吞吐量。我们进行固定数量的进化,并选择在搜索过程中发现的最佳程序。我们利用一个学习成本模型,因为成本模型可以相对准确地估计程序的适合性,同时比实际测量快几个数量级。它允许我们在几秒钟内比较搜索空间中的数万个程序,并选择有前景的程序进行实际测量。
6.1 Evolutionary Search
Tile size mutation:该操作扫描程序并随机选择一个平铺循环。对于这个平铺循环,它将一个平铺层的平铺大小除以一个随机因子,然后将这个因子乘到另一个平铺层。由于此操作使平铺大小的乘积等于原始循环长度,因此更改后的程序始终有效。
Parallel mutation:该操作扫描程序并随机选择一个带有parallel注释的循环。对于这个循环,该操作通过融合相邻的循环级别或将其拆分为一个因子来更改并行粒度。
Pragma mutation:程序中的一些优化是由特定于编译器的pragma指定的,该操作扫描程序并随机选择一个pragma。对于这个pragma,该操作将它随机地转换为另一个有效值,例如,我们的底层代码生成器通过提供auto_unroll_max_step=N pragma来支持最大步数的自动展开,我们随机调整数字N。
Computation location:该操作扫描程序并随机选择一个非多层平铺的灵活节点(例如,卷积层中的填充节点)。对于这个节点,操作随机地将其计算位置更改为另一个有效的附加点。
Node-based crossover:在Ansor中,程序的基因就是程序的重写步骤。Ansor生成的每个程序都从最初的简单实现开始重写,在草图生成和随机注释期间,Ansor为每个程序保留了完整的重写历史。我们可以将重写步骤视为程序的基因,因为它们描述了这个程序是如何从初始的原始程序形成的。在此基础上,我们可以将两个现有程序的重写步骤结合起来,生成一个新的程序。然而,任意组合来自两个程序的重写步骤可能会破坏步骤中的依赖关系并创建无效程序。因此,Ansor中交叉操作的粒度基于DAG中的节点,因为跨不同节点的重写步骤通常依赖性较小。Ansor为每个节点随机选择一个父节点,并合并所选节点的重写步骤。当节点之间存在依赖关系时,Ansor试图用简单的启发式分析和调整这些步骤。Ansor进一步验证合并后的程序,以保证功能的正确性。验证很简单,因为Ansor只使用一小部分循环转换重写步骤,底层代码生成器可以通过依赖分析检查正确性。
进化搜索利用突变和交叉,在几轮中重复生成一组新的候选程序,并输出一组分数最高的程序,这些程序将在目标硬件上进行编译和测量,以获得实际的运行时间成本,收集的测量数据用于更新成本模型。通过这种方式,学习到的成本模型的精度逐渐提高,以匹配目标硬件。因此,进化搜索逐渐为目标硬件平台生成更高质量的程序。
与TVM和FlexTensor中的搜索算法只能在固定的类网格参数空间中工作不同,Ansor中的进化操作是专门为张量程序设计的。它们可以应用于一般的张量程序,并且可以处理具有复杂依赖关系的搜索空间。与Halide自动调度器中的展开规则不同,这些操作可以对程序执行乱序修改,解决顺序限制。
6.2 Learned Cost Model
由于我们的目标程序主要是数据并行张量程序,由多个交错循环巢组成,其中几个赋值语句作为最内层语句,因此我们训练成本模型来预测循环巢中最内层非循环语句的得分。对于一个完整的程序,我们对每个最内层的非循环语句进行预测,并将预测结果相加作为得分。我们通过在完整程序的上下文中提取特征来构建最内层非循环语句的特征向量,所提取的特征包括算术特征和内存访问特征。有关特征的介绍参考其他小节。
我们使用加权平方误差作为损失函数,因为我们主要关心从搜索空间中识别性能良好的程序,所以我们更重视运行速度较快的程序。具体来说,在吞吐量为
y
y
y的程序
P
P
P上,模型
f
f
f的损失函数为
l
o
s
s
(
f
,
P
,
y
)
=
w
p
(
∑
s
∈
S
(
P
)
f
(
s
)
−
y
)
2
=
y
(
∑
s
∈
S
(
P
)
f
(
s
)
−
y
)
2
loss(f,P,y) = w_p \big( \sum_{s \in S(P)} f(s) - y \big)^2 \\[5pt] =y \big( \sum_{s \in S(P)} f(s) - y \big)^2
loss(f,P,y)=wp(s∈S(P)∑f(s)−y)2=y(s∈S(P)∑f(s)−y)2 其中
S
(
P
)
S(P)
S(P)是
P
P
P中最内层的非循环语句集合,直接用吞吐量
y
y
y作为权重。
我们训练一个梯度增强决策树(XGBoost)作为底层模型
f
f
f,为来自所有DAG的所有张量程序训练一个模型,并将来自同一DAG的所有程序的吞吐量归一化到[0,1]的范围内。在优化DNN时,测量的程序数量通常小于3万个,在这么小的数据集上训练XGBoost非常快,所以我们每次都训练一个新模型,而不是做增量更新。
7. Task Scheduler
DNN可以划分为许多独立的子图(例如,conv2d + relu),对于某些子图,花时间调优它们并不能显著提高端到端DNN性能,这是由于两个原因:
(1)子图不是性能瓶颈;
(2)调优只会对子图的性能带来极小的改善。
为了避免在调优不重要的子图上浪费时间,Ansor动态地为不同的子图分配不同数量的时间资源。以ResNet-50为例,经过图划分后,它有29个唯一的子图。这些子图中的大多数是具有不同形状配置(input size, kernel size, stride等)的卷积层。我们需要为不同的卷积层生成不同的程序,因为最好的张量程序取决于这些形状配置。实际上,用户的所有应用程序都可能有多个DNN。这就产生了更多的子图以及更多减少总调优时间的机会,因为我们可以在子图之间共享和重用知识,一个子图也可以在一个DNN中或在不同的DNN中出现多次。
我们将任务定义为为子图生成高性能程序而执行的流程,这意味着优化单个DNN需要完成数十个任务(例如,ResNet-50的29个任务)。Ansor的任务调度器以迭代的方式为任务分配时间资源,在每次迭代中,Ansor选择一个任务,为子图生成一批有前景的程序,并在硬件上测量该程序,我们将这样的迭代定义为一个时间资源单位。当我们将一个单位的时间资源分配给一个任务时,该任务就获得了生成和度量新程序的机会,这也意味着找到更好的程序的机会。
7.1 Problem Formulation
当调优一个DNN或一组DNN时,用户可以有各种类型的目标,例如,减少DNN的延迟,满足一组DNN的延迟要求,或者在调优不再显著提高DNN性能时最小化调优时间。因此,我们为用户提供了一组目标函数来表达他们的目标,用户还可以提供自己的目标函数。
假设总共有
n
n
n个任务,设
t
∈
Z
n
t \in \mathcal Z^n
t∈Zn为分配向量,其中
t
i
t_i
ti为花费在任务
i
i
i上的时间单位数,设任务
i
i
i获得的最小子图延迟是分配向量
g
i
(
t
)
g_i(t)
gi(t)的函数,设DNN的端到端代价(cost)是子图
f
(
g
1
(
t
)
,
g
2
(
t
)
,
…
,
g
3
(
t
)
)
f\big( g_1(t), g_2(t), \dots, g_3(t) \big)
f(g1(t),g2(t),…,g3(t))的时延的函数,我们的目标是最小化端到端的成本:
m
i
n
i
m
i
z
e
f
(
g
1
(
t
)
,
g
2
(
t
)
,
…
,
g
3
(
t
)
)
minimize f\big( g_1(t), g_2(t), \dots, g_3(t) \big)
minimizef(g1(t),g2(t),…,g3(t)) 为了最小化单个DNN的端到端时延,我们可以定义
f
(
g
1
,
g
2
,
…
,
g
n
)
=
∑
i
=
1
n
w
i
×
g
i
f\big( g_1, g_2, \dots, g_n \big) = \sum_{i=1}^{n} w_i \times g_i
f(g1,g2,…,gn)=i=1∑nwi×gi 其中
w
i
w_i
wi是任务
i
i
i在DNN中出现的次数。这个公式很简单,因为
f
f
f是端到端DNN时延的近似值。

上述表格显示了用于调优多个DNN的目标函数示例。设
m
m
m为DNN的个数,
S
(
j
)
S(j)
S(j)为属于DNN
j
j
j的任务集。
f
1
f_1
f1将每个DNN的时延加起来,这意味着要优化一次连续运行所有DNN的管道的成本;在
f
2
f_2
f2中,我们将
L
j
L_j
Lj定义为DNN
j
j
j的时延要求,这意味着如果DNN的时延已经满足要求,我们就不希望在其上花费时间;在
f
3
f_3
f3中,我们将
B
j
B_j
Bj定义为DNN
j
j
j的参考时延,因此,我们的目标是使加速的几何平均值相对于给定的参考时延最大化;最后在
f
4
f_4
f4中,我们定义了一个函数
E
S
(
g
i
,
t
)
ES(g_i,t)
ES(gi,t),通过查看任务
i
i
i的时延历史,返回一个提前停止的值,可以达到每个任务提前停止的效果。
7.2 Optimizing with Gradient Descent
为了有效地优化目标函数,作者提出了一种基于梯度下降的调度算法,其思想是,给定当前分配
t
t
t,为了选择任务
i
i
i,近似目标函数的梯度
∂
f
∂
t
i
\frac {\partial f} {\partial t_i}
∂ti∂f,使
i
=
a
r
g
m
a
x
i
∣
∂
f
∂
t
i
∣
i = argmax_i \big| \frac {\partial f} {\partial t_i} \big|
i=argmaxi
∂ti∂f
。我们通过乐观猜测和考虑任务之间的相似性来近似梯度。
梯度近似公式如下:
∂
f
∂
t
i
=
∂
f
∂
g
i
(
α
g
i
(
t
i
)
−
g
i
(
t
i
−
Δ
t
)
Δ
t
+
(
1
−
α
)
(
m
i
n
(
−
g
i
(
t
i
)
t
i
,
β
C
i
m
a
x
k
∈
N
(
i
)
V
k
−
g
i
(
t
i
)
)
)
)
\frac {\partial f} {\partial t_i} = \frac {\partial f} {\partial g_i} \bigg( \alpha \frac {g_i(t_i) - g_i(t_i - \Delta t)} {\Delta t} + \big(1 - \alpha\big)\big(min(-\frac {g_i(t_i)} {t_i}, \beta \frac {C_i} {max_{k\in N(i)} V_k} - g_i(t_i))\big) \bigg)
∂ti∂f=∂gi∂f(αΔtgi(ti)−gi(ti−Δt)+(1−α)(min(−tigi(ti),βmaxk∈N(i)VkCi−gi(ti)))) 其中
Δ
t
\Delta t
Δt是一个很小的后向窗口大小,
g
i
(
t
i
)
g_i(t_i)
gi(ti)和
g
i
(
t
i
−
Δ
t
)
g_i(t_i-\Delta t)
gi(ti−Δt)都是从分配的历史中知道的,
N
(
i
)
N(i)
N(i)是
i
i
i中相似任务的集合,
C
i
C_i
Ci是任务
i
i
i中浮点运算的个数,
V
k
V_k
Vk是在任务
k
k
k中每秒可以完成的浮点运算数,参数
α
\alpha
α和
β
\beta
β控制权重以信任某些预测。
为了运行算法,Ansor从
t
=
0
t = 0
t=0开始,并通过一轮循环(round-robin)来预热(warm-up),以获得初始分配向量
t
=
(
1
,
1
,
…
,
1
)
t=(1,1,\dots,1)
t=(1,1,…,1)。warm-up之后,在每次迭代中,我们计算每个任务的梯度,并选择
a
r
g
m
a
x
i
∣
∂
f
∂
t
i
∣
argmax_i \big| \frac {\partial f} {\partial t_i} \big|
argmaxi
∂ti∂f
,然后我们将资源单元分配给任务
i
i
i,并更新分配向量
t
i
=
t
i
+
1
t_i = t_i +1
ti=ti+1,优化过程将继续进行,直到耗尽时间预算为止。为了鼓励探索,我们采用
ϵ
\epsilon
ϵ贪婪策略(e-greedy),它保留了以概率
ϵ
\epsilon
ϵ来随机选择任务。