关于缓存的理解
为系统引入缓存的理由
通常情况,在我们面临系统的基础设施,例如数据库无法处理量级的请求时候,总是会下意识的使用缓存,这次我们以设计的角度思考,在为你的系统引入缓存之前,它是否真的需要缓存呢?
在软件开发中,引入缓存的负面作用要明显大于硬件的缓存。
主要有这样几个原因:
从开发角度来说,引入缓存会提高系统的复杂度,因为你要考虑缓存的失效、更新、一致性等问题(硬件缓存也有这些问题,只是不需要由你来考虑,主流的 ISA 也都没有提供任何直接操作缓存的指令);
从运维角度来说,缓存会掩盖掉一些缺陷,让问题在更久的时间以后,出现在距离发生现场更远的位置上;
从安全角度来说,缓存可能泄漏某些保密数据,这也是容易受到攻击的薄弱点。那么,冒着前面提到的这种种风险,你还是想要给系统引入缓存,是为了什么呢?其实无外乎有两种理由。
第一种,为了缓解 CPU 压力而做缓存。
比如说,把方法运行结果存储起来、把原本要实时计算的内容提前算好、把一些公用的数据进行复用,等等,这些引入缓存的做法,都可以节省 CPU 算力,顺带提升响应性能。
第二种,为了缓解 I/O 压力而做缓存。
比如说,通过引入缓存,把原本对网络、磁盘等较慢介质的读写访问,变为对内存等较快介质的访问;把原本对单点部件(如数据库)的读写访问,变为对可扩缩部件(如缓存中间件)的访问,等等,也顺带提升了响应性能。这里请你注意,缓存虽然是典型的以空间换时间来提升性能的手段,但它的出发点是缓解 CPU 和 I/O 资源在峰值流量下的压力,“顺带”而非“专门”地提升响应性能。
所以我的言外之意就是,如果你可以通过增强 CPU、I/O 本身的性能(比如扩展服务器的数量)来满足需要的话,那升级硬件往往是更好的解决方案。即使需要你掏腰包多花一点儿钱,那通常也比引入缓存带来的风险更低。
缓存属性
其实,不少软件系统最初的缓存功能,都是以 HashMap 或者 ConcurrentHashMap 为起点开始的演进的。当我们在开发中发现,系统中某些资源的构建成本比较高,而这些资源又有被重复使用的可能性,那很自然就会产生“循环再利用”的想法,把它们放到 Map 容器中,下次需要时取出重用,避免重新构建。这种原始朴素的复用就是最基本的缓存了。
不过,一旦我们专门把“缓存”看作是一项技术基础设施,一旦它有了通用、高效、可统计、可管理等方面的需求,那么我们需要考虑的因素就会变得复杂起来了。通常我们在设计或者选择缓存时,至少需要考虑以下四个维度的属性:
- 吞吐量:缓存的吞吐量使用 OPS 值(每秒操作数,Operations per Second,ops/s)来衡量,它反映了对缓存进行并发读、写操作的效率,即缓存本身的工作效率高低。
- 命中率:缓存的命中率即成功从缓存中返回结果次数与总请求次数的比值,它反映了引入缓存的价值高低,命中率越低,引入缓存的收益越小,价值越低。
- 扩展功能:缓存除了基本读写功能外,还提供了一些额外的管理功能,比如最大容量、失效时间、失效事件、命中率统计,等等。
- 分布式支持:缓存可以分为“进程内缓存”和“分布式缓存”两大类,前者只为节点本身提供服务,无网络访问操作,速度快但缓存的数据不能在各个服务节点中共享。后者则相反。
在我们就先来探讨下前三个属性(下一篇我们会重点讨论分布式缓存)。
吞吐量
缓存的吞吐量只在并发场景中才有统计的意义,因为不考虑并发的话,即使是最原始的、以 HashMap 实现的缓存,访问效率也已经是常量时间复杂度,即 O(1)。
但 HashMap 并不是线程安全的容器,并发场景我们可以改用 ConcurrentHashMap 来实现,这相当于给 Map 的访问分段加锁(从 JDK 8 起已取消分段加锁,改为 CAS+Synchronized 锁单个元素)。
而无论采用怎样的实现方法,线程安全措施都会带来一定的吞吐量损失。
设计缓存的思路是**“尽可能避免数据竞争”是最关键的。因为无论我们如何实现同步,都不会比直接不需要同步更快。**
缓存中最主要的数据竞争来源于读取数据的同时,也会伴随着对数据状态的写入操作,而写入数据的同时,也会伴随着数据状态的读取操作。
针对前面所讲的伴随读写操作而来的状态维护,我们可以选择两种处理思路。
一种是以 Guava Cache 为代表的同步处理机制。即在访问数据时一并完成缓存淘汰、统计、失效等状态变更操作,通过分段加锁等优化手段来尽量减少数据竞争。(关于Guava的操作我之前有博客写过)
另一种是以 Caffeine 为代表的异步日志提交机制。这种机制参考了经典的数据库设计理论,它把对数据的读、写过程看作是日志(即对数据的操作指令)的提交过程。
命中率与淘汰策略
受硬件约束,缓存肯定不可能无限大,这是一种以空间换时间的策略,需要在消耗空间与节约时间之间取得平衡,这就要求缓存必须能够自动、或者由人工淘汰掉缓存中的低价值数据。有以下几种思路。
**第一种:FIFO(First In First Out)**即优先淘汰最早进入被缓存的数据。
FIFO 的实现十分简单,但一般来说,它并不是优秀的淘汰策略,因为越是频繁被用到的数据,往往越会早早地被存入缓存之中。所以如果采用这种淘汰策略,很可能会大幅降低缓存的命中率。
**第二种:LRU(Least Recent Used)**即优先淘汰最久未被使用访问过的数据。LRU 通常会采用 HashMap 加 LinkedList 的双重结构(如 LinkedHashMap)来实现。也就是,它以 HashMap 来提供访问接口,保证常量时间复杂度的读取性能;以 LinkedList 的链表元素顺序来表示数据的时间顺序,在每次缓存命中时,把返回对象调整到 LinkedList 开头,每次缓存淘汰时从链表末端开始清理数据。
**第三种:LFU(Least Frequently Used)**即优先淘汰最不经常使用的数据。LFU 会给每个数据添加一个访问计数器,每访问一次就加 1,当需要淘汰数据的时候,就清理计数器数值最小的那批数据。LFU 可以解决前面 LRU 中,热点数据间隔一段时间不访问就被淘汰的问题,但同时它又引入了两个新的问题。
第一个问题是需要对每个缓存的数据专门去维护一个计数器,每次访问都要更新,在前面讲“吞吐量”的时候,我也解释了这样做会带来高昂的维护开销;
第二个问题是不便于处理随时间变化的热度变化,比如某个曾经频繁访问的数据现在不需要了,它也很难自动被清理出缓存。
针对以上两个问题,学术界提供了 TinyLFU 和 W-TinyLFU 算法,都带来了优化效果。有兴趣可以下去了解一下。
扩展功能
一般来说,一套标准的 Map 接口就可以满足缓存访问的基本需要,不过在“访问”之外,专业的缓存往往还会提供很多额外的功能。
加载器
许多缓存都有“CacheLoader”之类的设计,加载器可以让缓存从只能被动存储外部放入的数据,变为能够主动通过加载器去加载指定 Key 值的数据,加载器也是实现自动刷新功能的基础前提。Guava就用到了这个。
淘汰策略
有的缓存淘汰策略是固定的,也有一些缓存可以支持用户根据自己的需要,来选择不同的淘汰策略。
失效策略
失效策略就是要求缓存的数据在一定时间后自动失效(移除出缓存)或者自动刷新(使用加载器重新加载)。
事件通知
缓存可能会提供一些事件监听器,让你在数据状态变动(如失效、刷新、移除)时进行一些额外操作。有的缓存还提供了对缓存数据本身的监视能力(Watch 功能)。
并发级别
对于通过分段加锁来实现的缓存(以 Guava Cache 为代表),往往会提供并发级别的设置。这里你可以简单地理解为,缓存内部是使用多个 Map 来分段存储数据的,并发级别就用于计算出使用 Map 的数量。如果这个参数设置过大,会引入更多的 Map,你需要额外维护这些 Map 而导致更大的时间和空间上的开销;而如果设置过小,又会导致在访问时产生线程阻塞,因为多个线程更新同一个 ConcurrentMap 的同一个值时会产生锁竞争。
容量控制
缓存通常都支持指定初始容量和最大容量。设定初始容量的目的是减少扩容频率,这与 Map 接口本身的初始容量含义是一致的;而最大容量类似于控制 Java 堆的 -Xmx 参数,当缓存接近最大容量时,会自动清理掉低价值的数据。
引用方式
Java 语言支持将数据设置为软引用或者弱引用,而提供引用方式的设置,就是为了将缓存与 Java 虚拟机的垃圾收集机制联系起来。
统计信息
缓存框架会提供诸如缓存命中率、平均加载时间、自动回收计数等统计信息。
持久化
也就是支持将缓存的内容存储到数据库或者磁盘中。进程内缓存提供持久化功能的作用不是太大,但分布式缓存大多都会考虑提供持久化功能。
小结
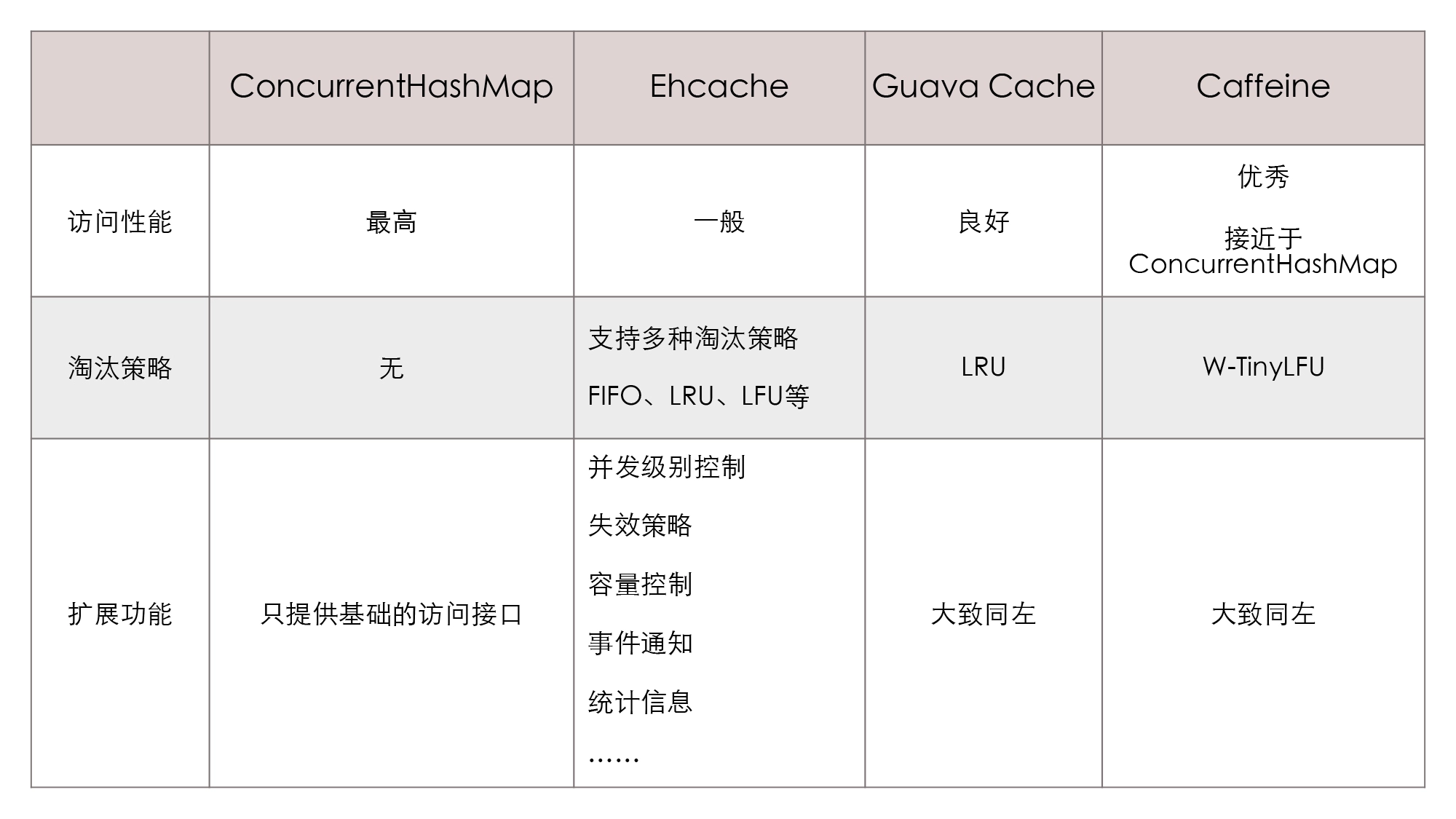
表格里的四类就基本囊括了目前主流的进程内缓存方案。希望通过这节课的学习,你能够掌握服务端缓存的原理,能够独立分析各种缓存框架所提供的功能属性,明白它们有什么影响,有什么收益和代价。
简单说一下使用缓存弊端,也欢迎大家互动补充。
1、空间换时间,无限制的缓存策略可能导致内存溢出
2、缓存的预加载、过期失效、击穿、穿透、雪崩等问题
3、既然是缓存,必然是有时效性的问题,就会出现不一致的问题
4、增加系统复杂度,耦合代码,出问题难以排查。