Linux内核调度策略、优先级、调度类
- 一、Linux 内核支持调度策略
- 二、进程优先级
- 三、公平调度 CFS 与其它调度
- 3.1、调度类
- 3.2、公平调度类 CFS
- 3.3、运行队列
- 3.4、调度进程
- 3.5、调度时机
- 四、RCU机制与内存屏障
一、Linux 内核支持调度策略
- 先进先出调度(SCHED_FIFO),没有时间片。
- 轮流调度(SCHED_RR),有时间片。
- 限期调度策略(SCHED_DEADLINE)。
采用不同的调度策略调度实时进程。
普通进程支持两种调度策略:
- 标准轮流分时(SCHED_NORMAL)和SCHED_BATCH 调度普通的非实时进程。
- 空闲(SCHED_IDLE)则在系统空闲时调用 idle 进程。
二、进程优先级
限期进程的优先级比实时进程高,实时进程的优先级比普通进程高。
限制进程的优先级是-1。 实时进程的实时优先级是 1-99,优先级数值越大,表示优先级 越高。 普通进程的静态优先级是 100-139,优先级数值越小,表示优先 级越高,可通过修改 nice 值改变普通进程的优先级,优先级等于 120 加上 nice 值。
prio是调度优先级,数值越小,优先级越高;多数情况为normal_prio。
| 优先级 | 限期进程 | 普通进程 | 实时进程 |
|---|---|---|---|
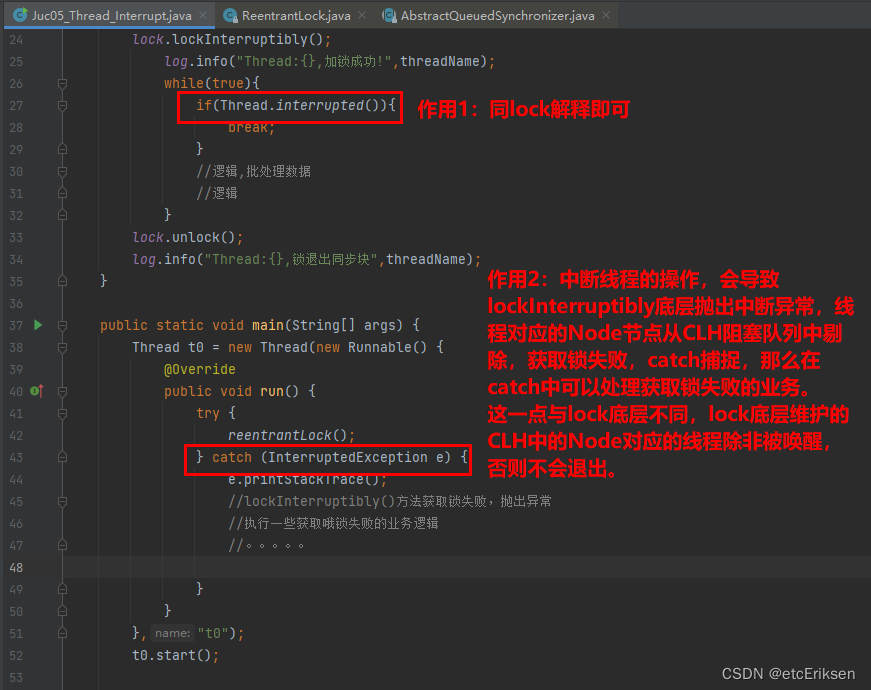
| prio | normal_prio | normal_prio | normal_prio |
| static_prio | 0 | 120 加上 nice 值,数值越小优先级越高。 | 0 |
| normal_prio | -1 | static_prio | 99至rt_priority |
| rt_priority | 0 | 0 | 1至99,数值越大优先级越高 |
在 task_struct 结构体中,4 个成员和优先级有关如下:
// include/linux/sched.h
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
三、公平调度 CFS 与其它调度
3.1、调度类
Linux 内核 sched_class 调度器有五种类型:
- dl_sched_class:限期调度类。
- rt_sched_class:实时调度类。
- stop_sched_class:停机调度类。
- idle_sched_c lass
- fair_sched_class
其中每种调度类都有自己的调度策略。主要是为方便添加新的调度策略 ,Linux 内核抽象一 个调 度类 sched_class。其调试器类型源码如下(kernel/sched/sched.h):
extern const struct sched_class dl_sched_class
extern const struct sched_class rt_sched_class
extern const struct sched_class stop_sched_class
extern const struct sched_class idle_sched_c lass
extern const struct sched_class fair_sched_class
- stop_sched_class调度类可以抢占其他进程,其他进程不能抢占它;停机调度类是指将处理器停下来做更加紧急的工作,只有迁移线程属于停机调度类,每个CPU有一个迁移线程cpu_id。
- dl_sched_class调度类使用红黑树将进程按照绝对截至限期从小到大排序,每次调度的时间选择绝对截止限期最小的进程。
- rt_sched_class将每个调度优先级维护一个队列,通过位图bitmap能够快速查找第一个非空队列;DECLARE_BITMAP(bitmap,MAX_RT_PRIO+1)。
调度类优先级,由高到低进行排列:停机调度类>限期调度类> 实时调度类>公平调度类>空闲调度类。
修改时间片(默认是5ms):/proc/sys/kernel/sched_rt_timeslice_ms
3.2、公平调度类 CFS
公平调度类应用完全公平调度算法,丢掉时间片和固定调度周 期,在此引入虚拟运行时间。vruntime 的计算公式如下:
虚拟运行时间(vruntime)=实际运行时间*nice0 权重值/进程权 重值。
(kernel/sched/core.c)
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
完全公平调度算法使用红黑树将进程按照虚拟运行时间从小到大排序,每次调度的时候选择虚拟运行时间最小的那个进程。
进程时间片=调度周期*进程权重 / 运行队列中全部进程的权重之和。
3.3、运行队列
每个处理器有一个运行队列,结构体是 rq,定义的全局变量如下:
(kernel/sched/core.c)
DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
rq 是描述就绪队列,其设计是为每一个 CPU 就绪队列,本地进程在 本地队列上排序。
3.4、调度进程
主动调度进程的函数是 schedule() ,它会把主要工作委托给 __schedule()去处理。
(kernel/sched/core.c)
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;//获取当前进程
sched_submit_work(tsk);//防止进程睡眠时发送死锁
do {
preempt_disable();//关闭内核抢占
__schedule(false);//执行调度的核心函数处理细节
sched_preempt_enable_no_resched();//开启内核抢占
} while (need_resched());
sched_update_worker(tsk);
}
EXPORT_SYMBOL(schedule);
函数__shcedule 的主要处理过程如下:
- 调用 pick_next_task()以选择下一个进程。
- 调用 context_switch()以切换进程。
/*
* __schedule() is the main scheduler function.
*
* The main means of driving the scheduler and thus entering this function are:
*
* 1. Explicit blocking: mutex, semaphore, waitqueue, etc.
*
* 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return
* paths. For example, see arch/x86/entry_64.S.
*
* To drive preemption between tasks, the scheduler sets the flag in timer
* interrupt handler scheduler_tick().
*
* 3. Wakeups don't really cause entry into schedule(). They add a
* task to the run-queue and that's it.
*
* Now, if the new task added to the run-queue preempts the current
* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets
* called on the nearest possible occasion:
*
* - If the kernel is preemptible (CONFIG_PREEMPTION=y):
*
* - in syscall or exception context, at the next outmost
* preempt_enable(). (this might be as soon as the wake_up()'s
* spin_unlock()!)
*
* - in IRQ context, return from interrupt-handler to
* preemptible context
*
* - If the kernel is not preemptible (CONFIG_PREEMPTION is not set)
* then at the next:
*
* - cond_resched() call
* - explicit schedule() call
* - return from syscall or exception to user-space
* - return from interrupt-handler to user-space
*
* WARNING: must be called with preemption disabled!
*/
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
schedule_debug(prev, preempt);
if (sched_feat(HRTICK))
hrtick_clear(rq);
local_irq_disable();
rcu_note_context_switch(preempt);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*
* The membarrier system call requires a full memory barrier
* after coming from user-space, before storing to rq->curr.
*/
rq_lock(rq, &rf);
smp_mb__after_spinlock();
/* Promote REQ to ACT */
rq->clock_update_flags <<= 1;
update_rq_clock(rq);
switch_count = &prev->nivcsw;
if (!preempt && prev->state) {
if (signal_pending_state(prev->state, prev)) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
if (prev->in_iowait) {
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
}
switch_count = &prev->nvcsw;
}
next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
if (likely(prev != next)) {
rq->nr_switches++;
/*
* RCU users of rcu_dereference(rq->curr) may not see
* changes to task_struct made by pick_next_task().
*/
RCU_INIT_POINTER(rq->curr, next);
/*
* The membarrier system call requires each architecture
* to have a full memory barrier after updating
* rq->curr, before returning to user-space.
*
* Here are the schemes providing that barrier on the
* various architectures:
* - mm ? switch_mm() : mmdrop() for x86, s390, sparc, PowerPC.
* switch_mm() rely on membarrier_arch_switch_mm() on PowerPC.
* - finish_lock_switch() for weakly-ordered
* architectures where spin_unlock is a full barrier,
* - switch_to() for arm64 (weakly-ordered, spin_unlock
* is a RELEASE barrier),
*/
++*switch_count;
trace_sched_switch(preempt, prev, next);
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);
} else {
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unlock_irq(rq, &rf);
}
balance_callback(rq);
}
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
prepare_task_switch(rq, prev, next);
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
/*
* kernel -> kernel lazy + transfer active
* user -> kernel lazy + mmgrab() active
*
* kernel -> user switch + mmdrop() active
* user -> user switch
*/
if (!next->mm) { // to kernel
enter_lazy_tlb(prev->active_mm, next);
next->active_mm = prev->active_mm;
if (prev->mm) // from user
mmgrab(prev->active_mm);
else
prev->active_mm = NULL;
} else { // to user
membarrier_switch_mm(rq, prev->active_mm, next->mm);
/*
* sys_membarrier() requires an smp_mb() between setting
* rq->curr / membarrier_switch_mm() and returning to userspace.
*
* The below provides this either through switch_mm(), or in
* case 'prev->active_mm == next->mm' through
* finish_task_switch()'s mmdrop().
*/
switch_mm_irqs_off(prev->active_mm, next->mm, next);
if (!prev->mm) { // from kernel
/* will mmdrop() in finish_task_switch(). */
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
}
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
prepare_lock_switch(rq, next, rf);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
(1)切 换 用 户 虚 拟 地 址 空 间 , ARM64 架 构 使 用 默 认 的switch_mm_irqs_off,其内核源码定义如下:
// include/linux/mmu_context.h
/* SPDX-License-Identifier: GPL-2.0 */
#ifndef _LINUX_MMU_CONTEXT_H
#define _LINUX_MMU_CONTEXT_H
#include <asm/mmu_context.h>
struct mm_struct;
void use_mm(struct mm_struct *mm);
void unuse_mm(struct mm_struct *mm);
/* Architectures that care about IRQ state in switch_mm can override this. */
#ifndef switch_mm_irqs_off
# define switch_mm_irqs_off switch_mm
#endif
#endif
switch_mm 函数内核源码处理如下:
// arch/arm64/include/asm/mmu_context.h
static inline void __switch_mm(struct mm_struct *next)
{
unsigned int cpu = smp_processor_id();
/*
* init_mm.pgd does not contain any user mappings and it is always
* active for kernel addresses in TTBR1. Just set the reserved TTBR0.
*/
if (next == &init_mm) {
cpu_set_reserved_ttbr0();
return;
}
check_and_switch_context(next, cpu);
}
static inline void
switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
if (prev != next)
__switch_mm(next);
/*
* Update the saved TTBR0_EL1 of the scheduled-in task as the previous
* value may have not been initialised yet (activate_mm caller) or the
* ASID has changed since the last run (following the context switch
* of another thread of the same process).
*/
update_saved_ttbr0(tsk, next);
}
(2)切 换 寄 存 器 , 宏 switch_to 把 这 项 工 作 委 托 给 函 数__switch_to:
// include/asm-generic/switch_to.h
#ifndef __ASM_GENERIC_SWITCH_TO_H
#define __ASM_GENERIC_SWITCH_TO_H
#include <linux/thread_info.h>
/*
* Context switching is now performed out-of-line in switch_to.S
*/
extern struct task_struct *__switch_to(struct task_struct *,
struct task_struct *);
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \
} while (0)
#endif /* __ASM_GENERIC_SWITCH_TO_H */
(arch/arm64/kernel/process.c)
/*
* Thread switching.
*/
__notrace_funcgraph struct task_struct *__switch_to(struct task_struct *prev,
struct task_struct *next)
{
struct task_struct *last;
fpsimd_thread_switch(next);
tls_thread_switch(next);
hw_breakpoint_thread_switch(next);
contextidr_thread_switch(next);
entry_task_switch(next);
uao_thread_switch(next);
ptrauth_thread_switch(next);
ssbs_thread_switch(next);
/*
* Complete any pending TLB or cache maintenance on this CPU in case
* the thread migrates to a different CPU.
* This full barrier is also required by the membarrier system
* call.
*/
dsb(ish);
/* the actual thread switch */
last = cpu_switch_to(prev, next);
return last;
}
3.5、调度时机
调度进程的时机:
- 进程主动调用 schedule()函数。
- 周期性地调度,抢占当前进程,强迫当前进程让出处理器。
- 唤醒进程的时候,被唤醒的进程可能抢占当前进程。
- 创建新进程的时候,新进程可能抢占当前进程。
(1)主动调度 :
进程在用户模式下运行,无法直接调用 schedule()函数,只能通过系统调用进入内核模式,如果系统调用需要等待某个资源,如互斥锁或信号量,就会把进程的状态设置为睡眠状态,然后调用schedule()函数来调度进程。
(2)周期调度 :
周期调度的函数为 scheduler_tick(),调用当前进程所属调度类task_tick()方法。
四、RCU机制与内存屏障
(1)RCU(read-copy update)为 Linux 当中的一种同步机制,则为读/拷贝更新。
- 写者修改对象流程:先复制生成一个副本,然后更新这个副本,最后使用新的对象替换旧的对象,在写者执行复制的时候读者则执行可以读数据。
- 写者删除对象时,必须等待所有访问对象的访问者都访问结束了才能删除对象。等待所有读者访问结束的时间叫做宽期限。
- RCU的读者没有任何的同步开销,不需要获取任何的锁,也不需要执行延迟指令,也不需要执行内存屏障;但是写者的同步开销非常大,需要延迟对象释放时间,复制被修改的对象,写者直接必须使用锁;从某个意义来说也算是RCU的缺点。
(2)内存屏障 :保证内存访问的顺序方法,用来解决编译器编码的时候可能会重新排序汇编指令。
因为为了使编译出来的程序在CPU上运行更快,有时候优化结果可能不符合程序的要求;现在的CPU采用超标量的一个体系结构和lanch技术,能够一个时钟并行执行很多条指令。
- 内存屏障可分为两种类型:编译器内存屏障和 CPU 内存屏障。
- 内核支持三种内存屏障:内存映射I/O写屏障、编译器屏障、处理器屏障。