前言
Apache Spark是专门为大规模数据处理而设计的快速通用的计算引擎,Spark拥有Hadoop MapReduce所具有的优点,但不同于Mapreduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好的适用于数据挖掘与机器学习等需要迭代的MapReduce。
Spark是一种与hadoop相似的开源集群计算环境,但是两者之间还存在一些不同之处,Spark启用了内存分布数据集群,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark特点:
1、更快的速度:内存计算下,Spark比Hadoop快100倍
2、易用性:可以使用java、scala、python、R和SQL语言进行spark开发,Spark提供了80多个高级运算符
3、通用性:Spark提供了大量的库,包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。开发者可以在一个应用程序中无缝组合使用这些库
4、多种运行环境:Spark可在Hadoop、Apache Mesos、Kubernetes、standalone或其他云环境上运行
参考链接:https://blog.csdn.net/cuiyaonan2000/article/details/116048663
spark适用场景:
1、spark是基于内存的迭代计算,适合多次操作特定数据集的场合
2、数据量不是特别大,但要求实时统计分析需求
3、不适用异步细粒更新状态的应用,如web服务器存储、增量的web爬虫和索引
spark运行模式:
1、可以运行在一台机器上,称为Local(本地)运行模式
2、可以使用spark自带的资源调度系统,称为Standalone模式
3、可以使用Yarn、Mesos、kubernetes作为底层资源调度系统,称为Spark On Yarn、Spark On Mesos、Spark On K8s
参考链接:https://blog.csdn.net/jiayi_yao/article/details/125545826#t8
一、安装启动
安装spark及其依赖
yum install java-1.8.0-openjdk curl tar python3
mkdir -p /usr/local/spark
cd /usr/local/spark
wget https://mirrors.aliyun.com/apache/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
tar -xvf spark-3.3.2-bin-hadoop3.tgz
- 启动spark-master
cd /usr/local/spark/spark-3.3.2-bin-hadoop3/
[root@bogon spark-3.3.2-bin-hadoop3]# ./sbin/start-master.sh
可以看到类似如下的输出:
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-3.3.2-bin-hadoop3/logs/spark-root-org.apache.spark.deploy.master.Master-1-bogon.out
用tail命令查看执行日志
[root@bogon spark-3.3.2-bin-hadoop3]# tail logs/spark-root-org.apache.spark.deploy.master.Master-1-bogon.out
23/03/06 14:35:44 INFO SecurityManager: Changing modify acls to: root
23/03/06 14:35:44 INFO SecurityManager: Changing view acls groups to:
23/03/06 14:35:44 INFO SecurityManager: Changing modify acls groups to:
23/03/06 14:35:44 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
23/03/06 14:35:45 INFO Utils: Successfully started service 'sparkMaster' on port 7077.
23/03/06 14:35:45 INFO Master: Starting Spark master at spark://bogon:7077
23/03/06 14:35:45 INFO Master: Running Spark version 3.3.2
23/03/06 14:35:45 INFO Utils: Successfully started service 'MasterUI' on port 8080.
23/03/06 14:35:45 INFO MasterWebUI: Bound MasterWebUI to 0.0.0.0, and started at http://bogon:8080
23/03/06 14:35:46 INFO Master: I have been elected leader! New state: ALIVE
- 启动spark-worker
cd /usr/local/spark/spark-3.3.2-bin-hadoop3/
[root@bogon spark-3.3.2-bin-hadoop3]# ./sbin/start-worker.sh spark://bogon:7077
可以看到类似如下的输出:
starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-3.3.2-bin-hadoop3/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bogon.out
用tail命令查看执行日志
[root@bogon spark-3.3.2-bin-hadoop3]# tail logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bogon.out
23/03/06 14:52:17 INFO Worker: Spark home: /usr/local/spark/spark-3.3.2-bin-hadoop3
23/03/06 14:52:17 INFO ResourceUtils: ==============================================================
23/03/06 14:52:17 INFO ResourceUtils: No custom resources configured for spark.worker.
23/03/06 14:52:17 INFO ResourceUtils: ==============================================================
23/03/06 14:52:17 WARN Utils: Service 'WorkerUI' could not bind on port 8081. Attempting port 8082.
23/03/06 14:52:17 INFO Utils: Successfully started service 'WorkerUI' on port 8082.
23/03/06 14:52:17 INFO WorkerWebUI: Bound WorkerWebUI to 0.0.0.0, and started at http://bogon:8082
23/03/06 14:52:17 INFO Worker: Connecting to master bogon:7077...
23/03/06 14:52:17 INFO TransportClientFactory: Successfully created connection to bogon/10.130.0.73:7077 after 85 ms (0 ms spent in bootstraps)
23/03/06 14:52:18 INFO Worker: Successfully registered with master spark://bogon:7077
二、测试
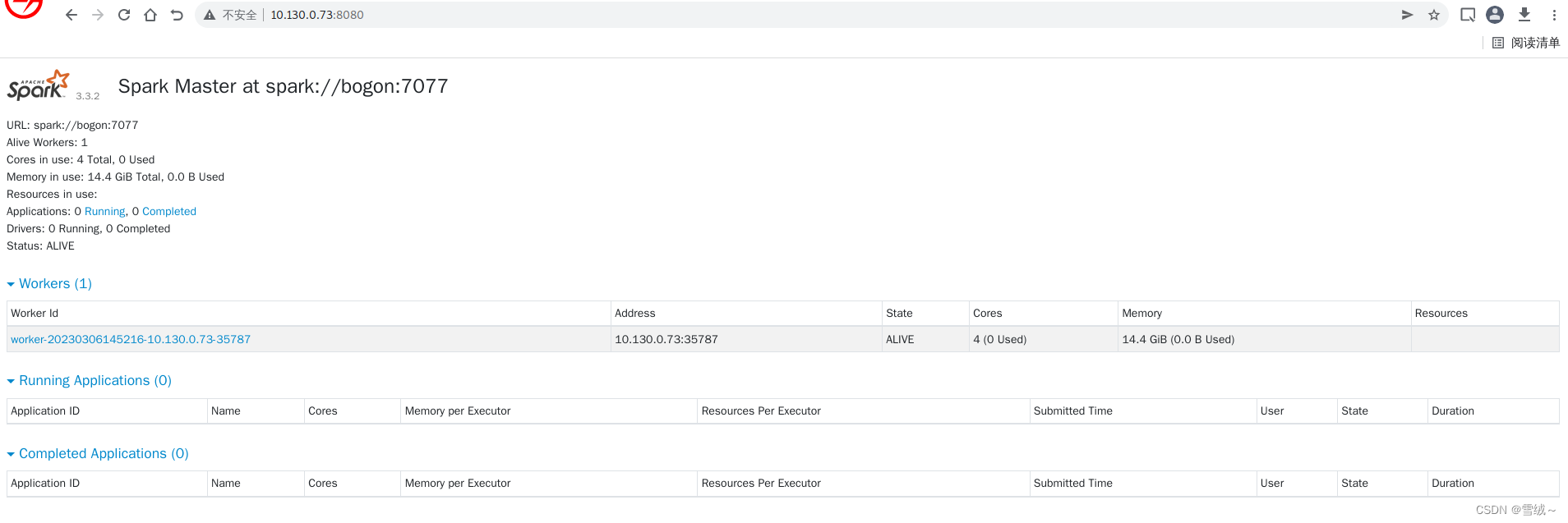
- 通过http://$IP:8080 访问master页面,获取资源消耗等的摘要信息
如果部署成功,我们可以看到类似如下的返回结果
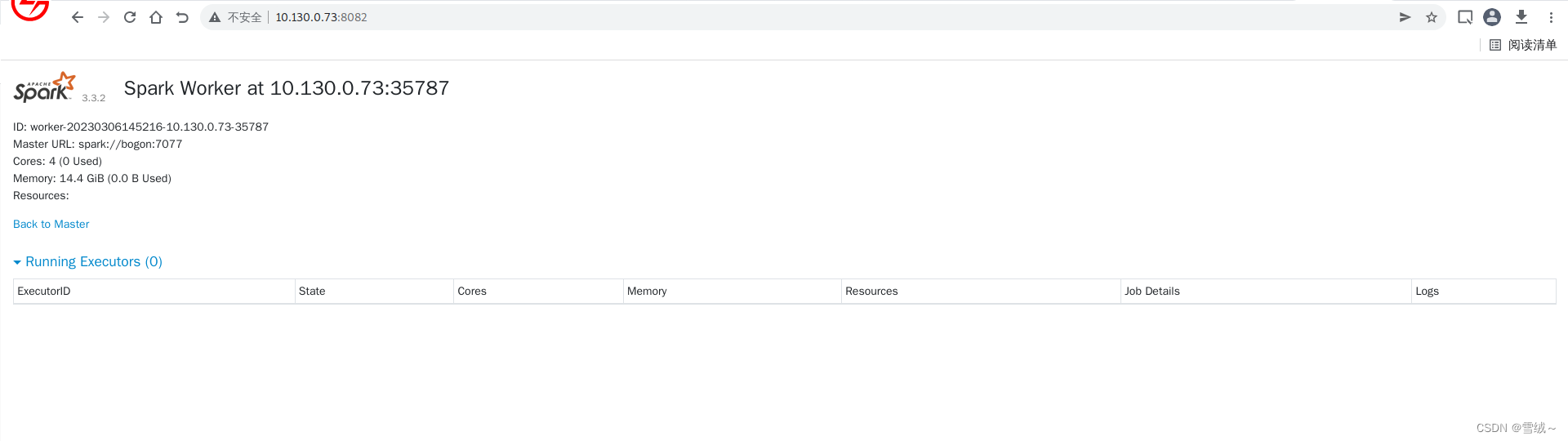
- 也可以通过web浏览器请求对应服务器8082端口(默认8081端口,可通过日志查看具体的端口号),查看worker的基本情况
- 提交测试任务,计算pi,提交命令如下
./bin/spark-submit --master spark://bogon:7077 examples/src/main/python/pi.py 1000
可以看到类似如下的输出:
23/03/06 16:32:55 INFO TaskSetManager: Starting task 999.0 in stage 0.0 (TID 999) (10.130.0.73, executor 0, partition 999, PROCESS_LOCAL, 4437 bytes) taskResourceAssignments Map()
23/03/06 16:32:55 INFO TaskSetManager: Finished task 995.0 in stage 0.0 (TID 995) in 217 ms on 10.130.0.73 (executor 0) (996/1000)
23/03/06 16:32:55 INFO TaskSetManager: Finished task 996.0 in stage 0.0 (TID 996) in 220 ms on 10.130.0.73 (executor 0) (997/1000)
23/03/06 16:32:55 INFO TaskSetManager: Finished task 997.0 in stage 0.0 (TID 997) in 198 ms on 10.130.0.73 (executor 0) (998/1000)
23/03/06 16:32:55 INFO TaskSetManager: Finished task 998.0 in stage 0.0 (TID 998) in 189 ms on 10.130.0.73 (executor 0) (999/1000)
23/03/06 16:32:55 INFO TaskSetManager: Finished task 999.0 in stage 0.0 (TID 999) in 238 ms on 10.130.0.73 (executor 0) (1000/1000)
23/03/06 16:32:55 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
23/03/06 16:32:55 INFO DAGScheduler: ResultStage 0 (reduce at /usr/local/spark/spark-3.3.2-bin-hadoop3/examples/src/main/python/pi.py:42) finished in 64.352 s
23/03/06 16:32:55 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
23/03/06 16:32:55 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
23/03/06 16:32:55 INFO DAGScheduler: Job 0 finished: reduce at /usr/local/spark/spark-3.3.2-bin-hadoop3/examples/src/main/python/pi.py:42, took 64.938378 s
Pi is roughly 3.133640
23/03/06 16:32:55 INFO SparkUI: Stopped Spark web UI at http://bogon:4040
23/03/06 16:32:55 INFO StandaloneSchedulerBackend: Shutting down all executors
23/03/06 16:32:55 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down
23/03/06 16:32:55 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
23/03/06 16:32:55 INFO MemoryStore: MemoryStore cleared
23/03/06 16:32:55 INFO BlockManager: BlockManager stopped
23/03/06 16:32:55 INFO BlockManagerMaster: BlockManagerMaster stopped
23/03/06 16:32:55 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
23/03/06 16:32:55 INFO SparkContext: Successfully stopped SparkContext
23/03/06 16:32:56 INFO ShutdownHookManager: Shutdown hook called
23/03/06 16:32:56 INFO ShutdownHookManager: Deleting directory /tmp/spark-087c8a21-8641-4b20-8b65-be47b77f26c5
23/03/06 16:32:56 INFO ShutdownHookManager: Deleting directory /tmp/spark-24d1bc1a-841a-435e-8263-ad891e2aaa97/pyspark-f67ad2cb-ec86-41eb-ae7c-8fcb46e66827
23/03/06 16:32:56 INFO ShutdownHookManager: Deleting directory /tmp/spark-24d1bc1a-841a-435e-8263-ad891e2aaa97
可以在网页界面看到运行结果
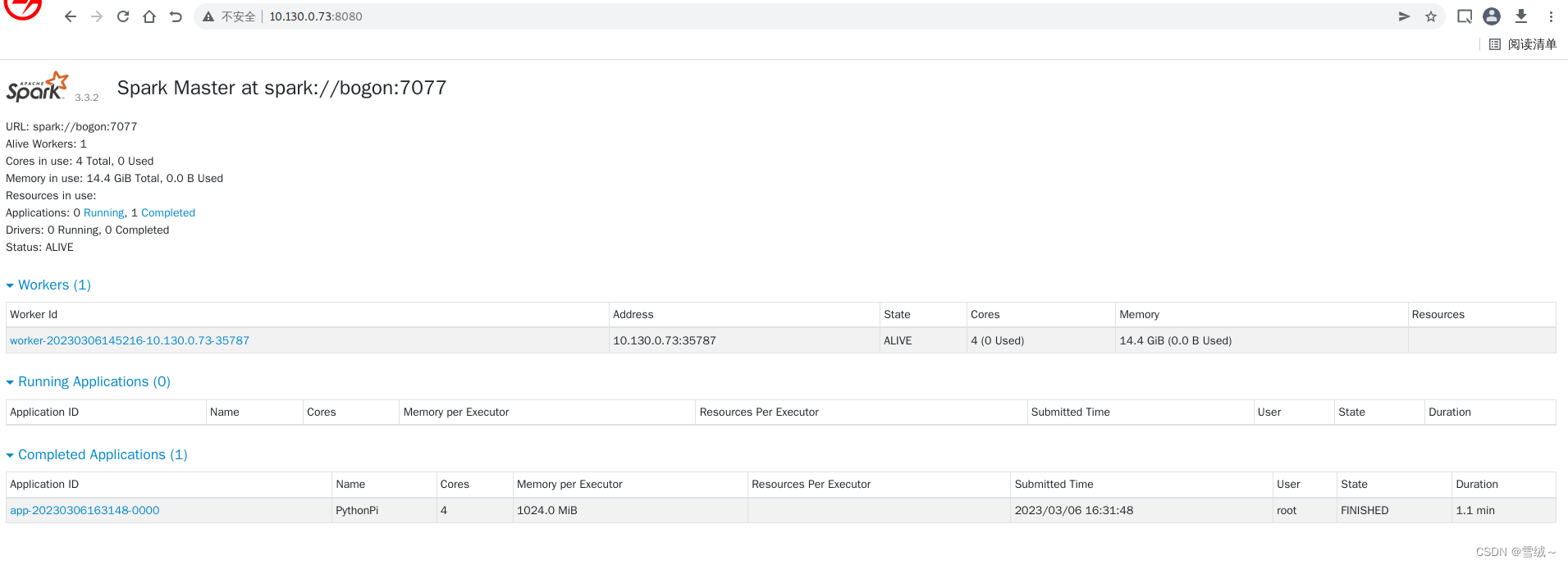
也可以查看执行日志
[root@bogon spark-3.3.2-bin-hadoop3]# tail logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bogon.out
23/03/06 16:31:48 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
23/03/06 16:31:48 INFO ExecutorRunner: Launch command: "/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-8.1.10.lns8.loongarch64/jre/bin/java" "-cp" "/usr/local/spark/spark-3.3.2-bin-hadoop3/conf/:/usr/local/spark/spark-3.3.2-bin-hadoop3/jars/*" "-Xmx1024M" "-Dspark.driver.port=46821" "-XX:+IgnoreUnrecognizedVMOptions" "--add-opens=java.base/java.lang=ALL-UNNAMED" "--add-opens=java.base/java.lang.invoke=ALL-UNNAMED" "--add-opens=java.base/java.lang.reflect=ALL-UNNAMED" "--add-opens=java.base/java.io=ALL-UNNAMED" "--add-opens=java.base/java.net=ALL-UNNAMED" "--add-opens=java.base/java.nio=ALL-UNNAMED" "--add-opens=java.base/java.util=ALL-UNNAMED" "--add-opens=java.base/java.util.concurrent=ALL-UNNAMED" "--add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED" "--add-opens=java.base/sun.nio.ch=ALL-UNNAMED" "--add-opens=java.base/sun.nio.cs=ALL-UNNAMED" "--add-opens=java.base/sun.security.action=ALL-UNNAMED" "--add-opens=java.base/sun.util.calendar=ALL-UNNAMED" "--add-opens=java.security.jgss/sun.security.krb5=ALL-UNNAMED" "org.apache.spark.executor.CoarseGrainedExecutorBackend" "--driver-url" "spark://CoarseGrainedScheduler@bogon:46821" "--executor-id" "0" "--hostname" "10.130.0.73" "--cores" "4" "--app-id" "app-20230306163148-0000" "--worker-url" "spark://Worker@10.130.0.73:35787"
23/03/06 16:32:55 INFO Worker: Asked to kill executor app-20230306163148-0000/0
23/03/06 16:32:55 INFO ExecutorRunner: Runner thread for executor app-20230306163148-0000/0 interrupted
23/03/06 16:32:55 INFO ExecutorRunner: Killing process!
23/03/06 16:32:55 INFO Worker: Executor app-20230306163148-0000/0 finished with state KILLED exitStatus 143
23/03/06 16:32:55 INFO ExternalShuffleBlockResolver: Clean up non-shuffle and non-RDD files associated with the finished executor 0
23/03/06 16:32:55 INFO ExternalShuffleBlockResolver: Executor is not registered (appId=app-20230306163148-0000, execId=0)
23/03/06 16:32:55 INFO Worker: Cleaning up local directories for application app-20230306163148-0000
23/03/06 16:32:55 INFO ExternalShuffleBlockResolver: Application app-20230306163148-0000 removed, cleanupLocalDirs = true
清理环境
./sbin/stop-worker.sh
./sbin/stop-master.sh
rm -rf /usr/local/spark