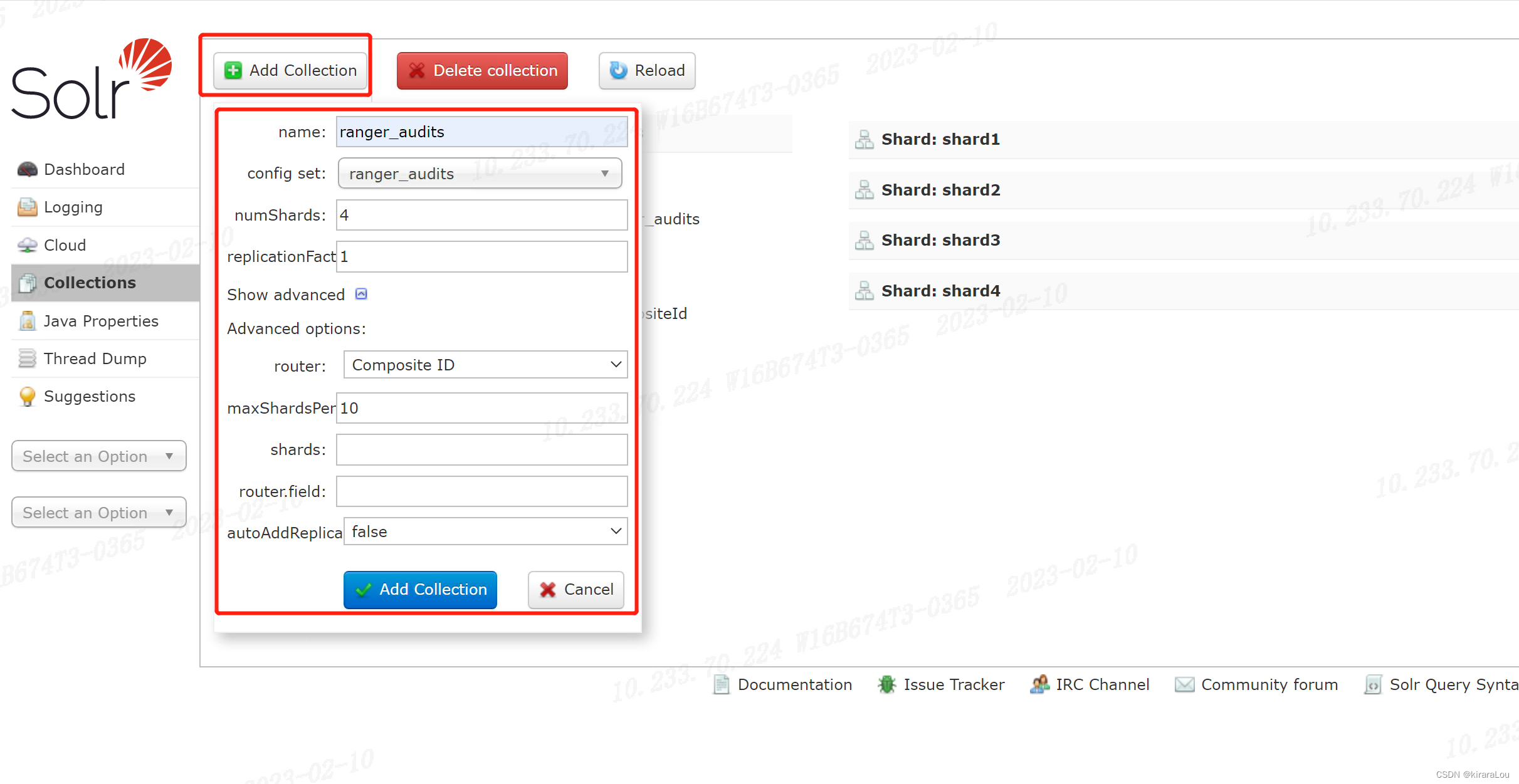
Spark SQL优化机制
- Spark SQL
- Catalyst 优化器
- 逻辑优化
- 物理优化
- Tungsten
- Unsafe Row
- WSCG
RDD 缺点 : RDD的算子都是高阶函数 ,Spark Core 不知函数内的操作,只能闭包形式发给 Executors, 无法优化
DataFrame 不同点:
- 数据的表示形式 :有数据模式(Data Schema)的结构化数据
- 开发算子 :一套 DSL算子(Domain Specific Language)
Spark 能用 DataFrame ,基于启发式的规则或策略,动态的运行时信息,去优化 DataFrame 的计算过程
Spark SQL
- Spark Core :特指 Spark 底层执行引擎(Execution Engine),包括:调度系统、存储系统、内存管理、Shuffle 管理
- Spark SQL :基于 Spark Core 上,有一层独立的优化引 (Optimization Engine)
Spark Core/Spark SQL关系:
- Spark SQL 优化后的代码,交给 Spark Core 执行
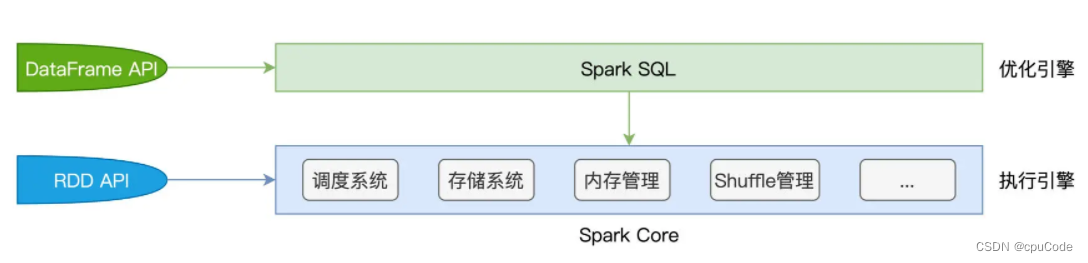
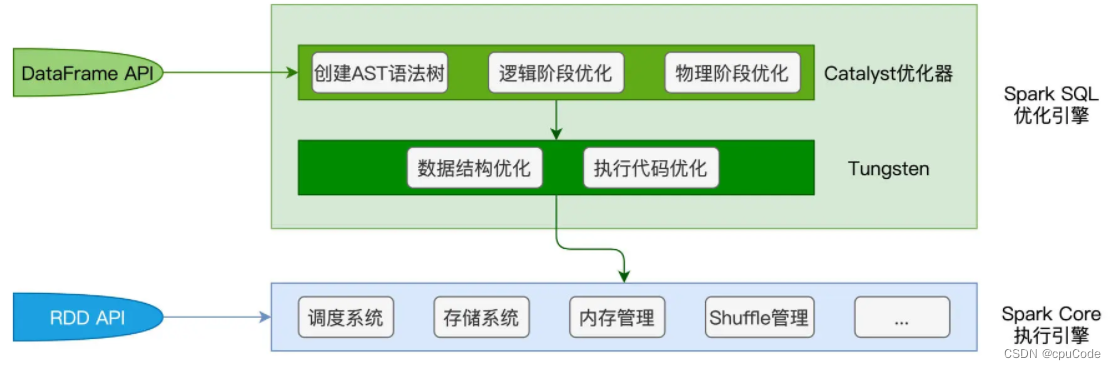
Spark SQL 的两个核心组件:Catalyst 优化器 /Tungsten
- Catalyst 优化器:负责创建并优化执行计划,有 3 个功能模块:创建语法树并生成执行计划、逻辑阶段优化、物理阶段优化
- Tungsten :负责优化数据结果与可执行代码 ,衔接 Catalyst 执行计划与底层的 Spark Core 执行引擎
Catalyst 优化器
Catalyst 优化器的作用:在逻辑优化阶段,基于启发式的规则和策略调整、优化执行计划,为物理优化阶段提升性能奠定基础
逻辑优化
Catalyst 的优化过程 : 先用第三方的 SQL 解析器 ANTLR 生成抽象语法树(AST,AbstractSyntax Tree)
AST 的两个基本元素构成
- 节点:各式各样的操作算子,如 : select、filter、agg
- 边 : 记录了数据表的 Schema 信息 ,如 : 字段名、字段类型
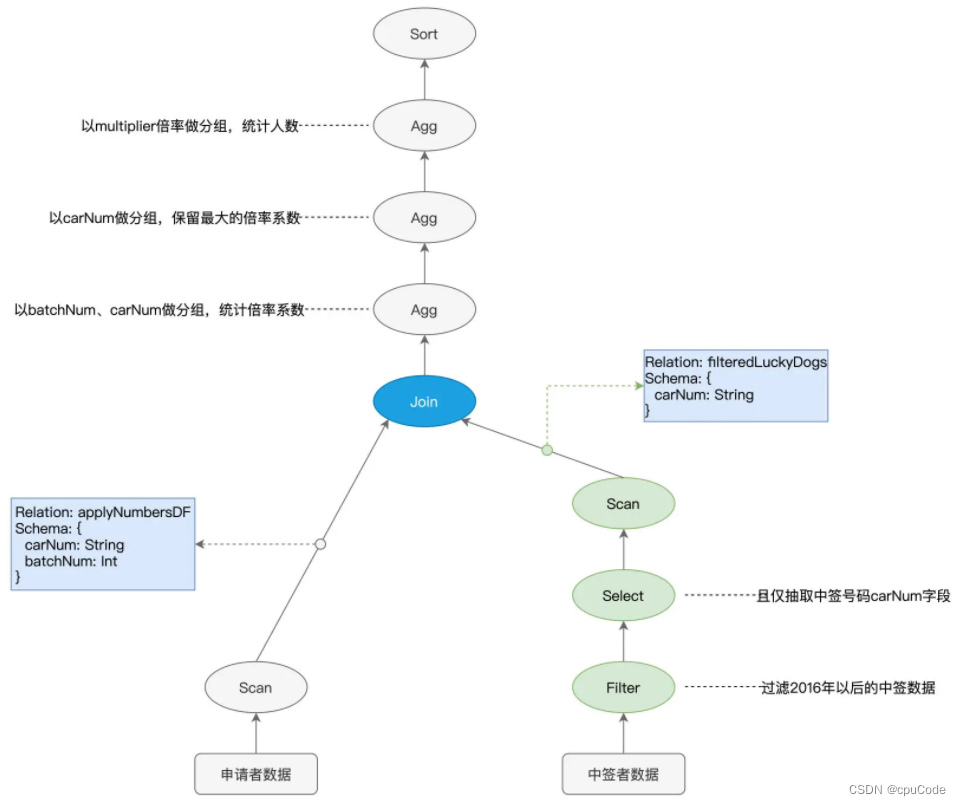
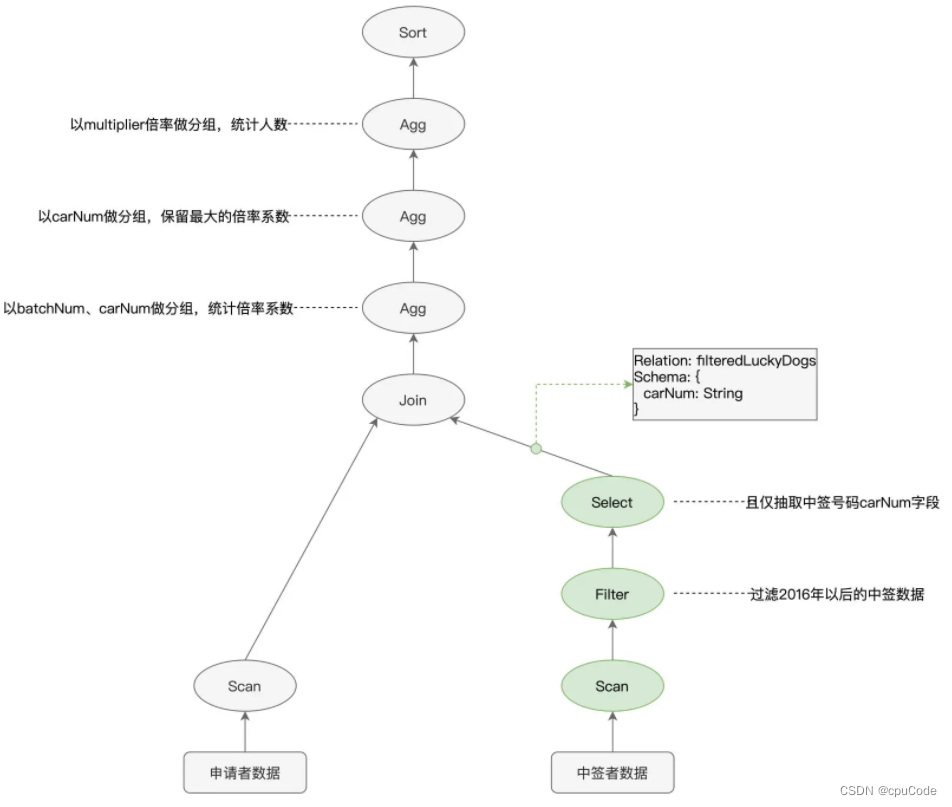
AST 语法树/执行计划(Execution Plan ) :
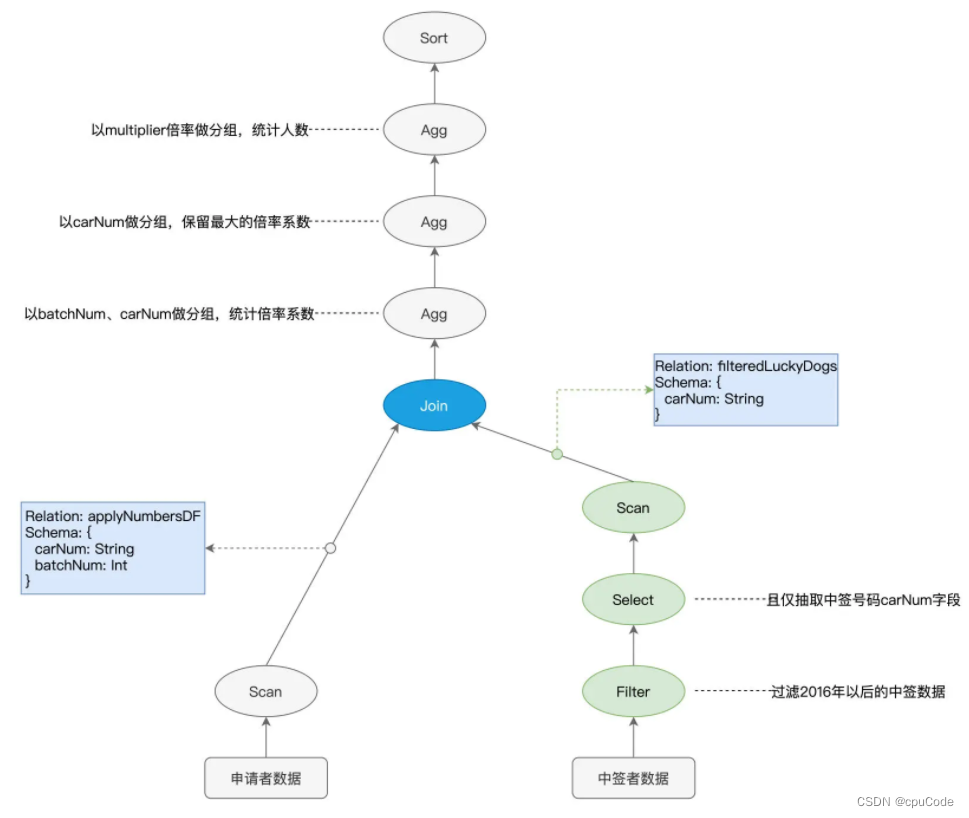
Parquet 格式在文件层面支持两项特性 :
- 谓词下推、列剪枝 :都是启发式的规则或策略
- 谓词下推 (Predicates Pushdown) :
batchNum >= 201601的过滤条件,在扫描过程时,只读取那些满足条件的数据文件 - 列剪枝 (Columns Pruning):Parquet 是列存 (Columns Store) 数据结构,只取某个字段名的数据文件时,就会剪掉其他数据文件的过程
Spark 只扫描绿色部分 :

逻辑优化的执行计划 :
- 执行顺序 :
Scan > Filter > Select变成Filter > Select > Scan
物理优化
Catalyst 的优化阶段差异:
- 逻辑阶段 :依赖先验的启发式经验 , 基于经验优化
- 物理阶段:依赖各式各样的统计信息,如:数据表尺寸、是否启用数据缓存、Shuffle 中间文件, 基于数据优化
Join 节点物理阶段优化:
- 采用哪种实现机制实现关联:嵌套循环连接(NLJ,Nested Loop Join)、排序归并连接(Sort Merge Join)、哈希连接(Hash Join)
- 采用哪种数据分发实现关联:Shuffle Join 和 Broadcast Join
- 根据两张表的存储大小,决定采用 :运行稳定但性能略差的 Shuffle Sort Merge Join 或 执行性能更佳的 Broadcast Hash Join
Tungsten
基于Catalyst ,Tungsten 在数据结构/执行代码进行进一步的优化
- 数据结构优化: Unsafe Row 的设计与实现
- 执行代码优化:全阶段代码生成(WSCG,Whole Stage Code Generation)
Unsafe Row
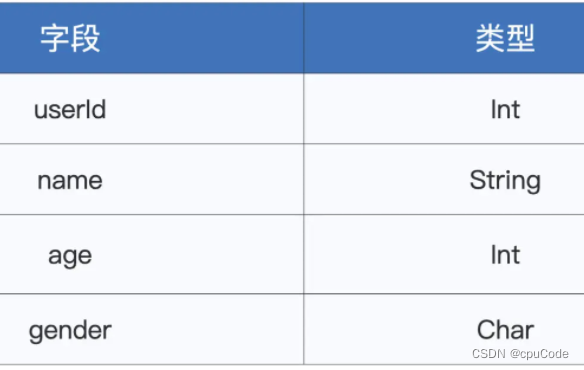
Spark SQL 默认采用 org.apache.spark.sql.Row 对象对每条数据进行封装和存储,Java Object 会有大量的存储开销
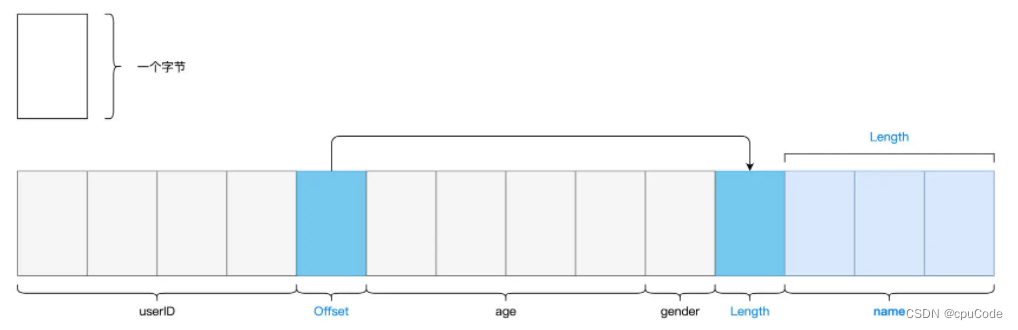
Unsafe Row 是二进制数据结构,以字节数组的格式存储每条数据,能减少存储开销
采用默认的 Row存储:
- 每条记录需要消耗至少 60 个字节
采用 Tungsten Unsafe Row 存储:
- 每条数据记录仅需消耗十几个字节
WSCG
WSCG:全阶段代码生成
- 全阶段:调度系统中的 Stage
- 代码生成:运行时,把链式调用的算子合成一份代码。如:把
Filter、Select、Scan合成一个函数
绿色节点属于同一个 Stage :