Spark 磁盘作用
- 磁盘作用
- 性能价值
- 失败重试
- ReuseExchange
Spark 导航
磁盘作用
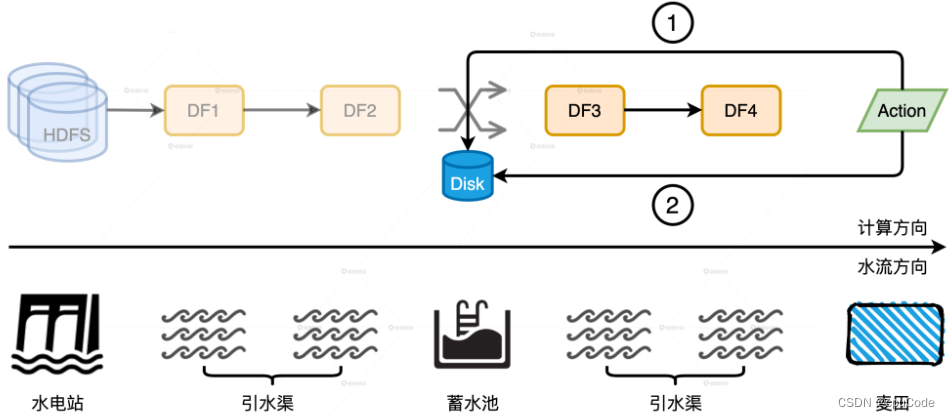
临时文件、中间文件、缓存数据,都会存储到 spark.local.dir 中
- 在 Shuffle Map 时, 当内存空间不足,就会溢出临时文件存储到磁盘上
- 溢出的临时文件一起做归并计算,得到 Shuffle 中间文件存储到磁盘上
- 缓存分布式数据集 : DISK 的存储模式,会把内存中放不下的数据缓存到磁盘
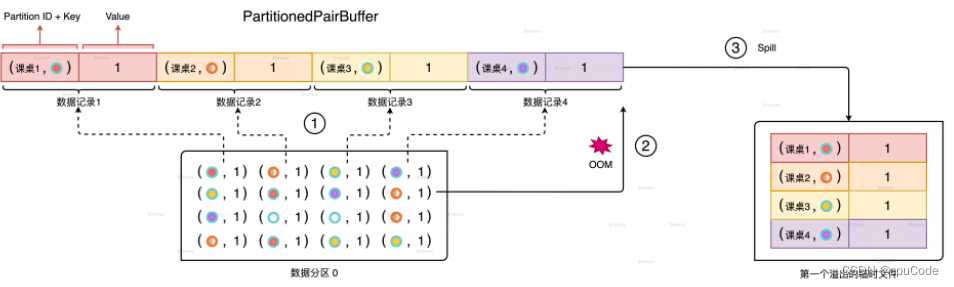
性能价值
spark.local.dir 配置到 SDD 或访问高效的存储系统
磁盘复用 :
- 给执行性能带来更好的提升
- 磁盘复用 : Shuffle Write 产生的中间文件被多次利用
失败重试
一旦某个计算环节出错,就会触发失败重试。失败重试的触发点是距离最新的 Shuffle 的中间文件
当 RDD4 的计算任务失败时,会从 RDD4 向前回溯,回溯到 RDD3 (RDD2 输出的中间文件 ) ,并重新开始计算
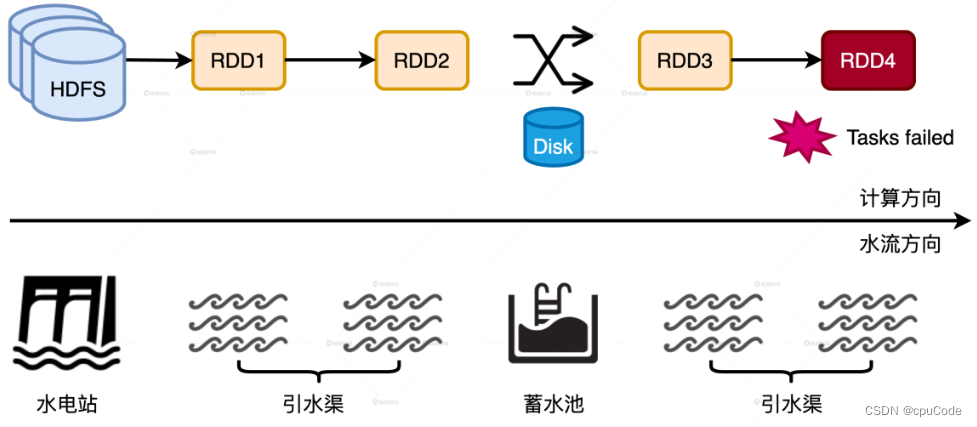
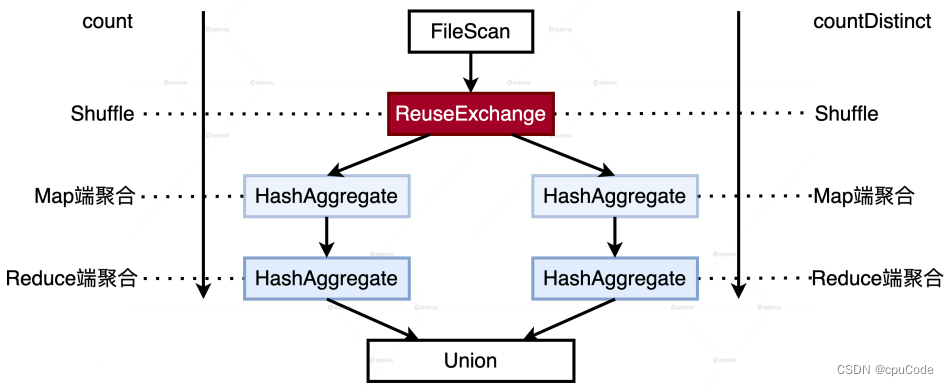
ReuseExchange
ReuseExchange 是 Spark SQL 优化一种 : 相同或相似的物理计划能共享 Shuffle 中间文件
ReuseExchange 机制的触发条件:
- 多个查询所依赖的分区规则要与 Shuffle 中间数据的分区规则保持一致
- 多个查询所涉及的字段(Attributes)要保持一致
统计不同用户的 PV(Page Views,页面浏览量)、UV(Unique Views,网站独立访客),并把两项统计结果合并:
//版本1:分别计算PV、UV,然后合并
// Data schema (userId: String, accessTime: Timestamp, page: String)
val filePath: String = _
val df: DataFrame = spark.read.parquet(filePath)
val dfPV: DataFrame =
df.groupBy("userId").agg(count("page").alias("value"))
val dfUV: DataFrame =
df.groupBy("userId").agg(countDistinct("page").alias("value"))
val resultDF: DataFrame = dfPV.Union(dfUV)
// Result样例
| userId | metrics | value |
| user0 | PV | 25 |
| user0 | UV | 12 |
文件扫描/Shuffle 两次 :
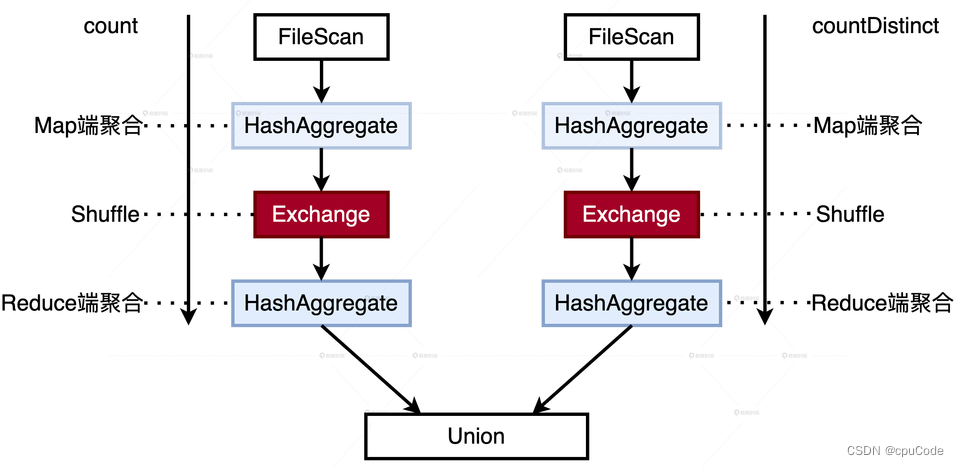
以 userId 为分区 ,调用 repartition :
//版本2:分别计算PV、UV,然后合并
// Data schema (userId: String, accessTime: Timestamp, page: String)
val filePath: String = _
val df: DataFrame =
spark.read.parquet(filePath).repartition($"userId")
val dfPV: DataFrame =
df.groupBy("userId").agg(count("page").alias("value"))
val dfUV: DataFrame =
df.groupBy("userId").agg(countDistinct("page").alias("value"))
val resultDF: DataFrame = dfPV.Union(dfUV)
// Result样例
| userId | metrics | value |
| user0 | PV | 25 |
| user0 | UV | 12 |
ReuseExchange :
- 数据源只需扫描一遍
- Shuffle 也只发生一次