文章目录
- 简介
- handler
- 商品分类
- 轮播图
- 品牌和品牌与分类
- oss
- 前端直传
- 库存服务
- 数据不一致
- redis 分布式锁
- 小结
简介
- 开发商品微服务 API 层
- 类似的,将 user-web 目拷贝一份,全局替换掉 user-web
- 修改 config
- 去掉不用的配置
- 更新本地和远程 nacos 配置文件
- 把 proto 文件拷过来再生成一下,全部拷过来也行
- Q:grpc 和 HTTP 调用的优缺点是什么?
- Q:如何将我们的服务改为 HTTP 调用?
- 更新 initialize/router
ApiGroup := Router.Group("/g/v1")- router 目录是单独设置的,方便管理,也需要更新;通过 package 区分各接口,也就是需要在 api 下新建目录(goods/brand/category/banners)
- 修改 global 文件
- 修改 initialize/srv_conn 文件,服务发现并拨号连接 goods_srv
- middlewares 部分是各微服务的共用代码,可以抽出来共用
- 但要有专人维护,并做好版本管理,避免因为改动影响所有微服务
- 或者就放在各微服务,代码虽多但是隔离性好
- 启动项目测试能否注册并发现 goods_srv
- 在 router 中临时配置一个接口
- 使用 yapi 配置商品服务的测试环境,请求我们的接口
- 配置环境别忘了带 token,这个是各服务都要验证的,可以先请求密码登录接口获取一个,过期时间设置长一些
handler
- 开始实现各接口
- 新建 test 目录,为每个接口编写 UT 测试,主要是看响应,先不必 assert
- 商品列表 List
- 获取商品列表需要一些请求参数,前端页面和后端(API)严格遵守文档(在yapi定义)
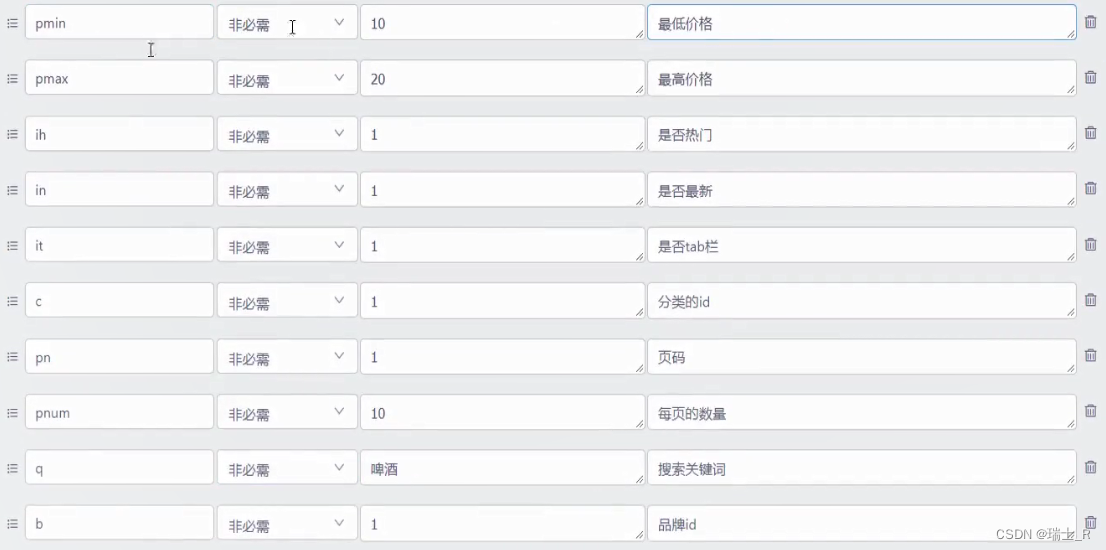
- API 这里获取页面请求参数:
ctx.DefaultQuery(),按照 proto 的定义拼装好向 srv 的请求参数 - 注意检查用户输入,避免后端处理时异常
- 除了在文档中定义请求参数,还要定义返回值
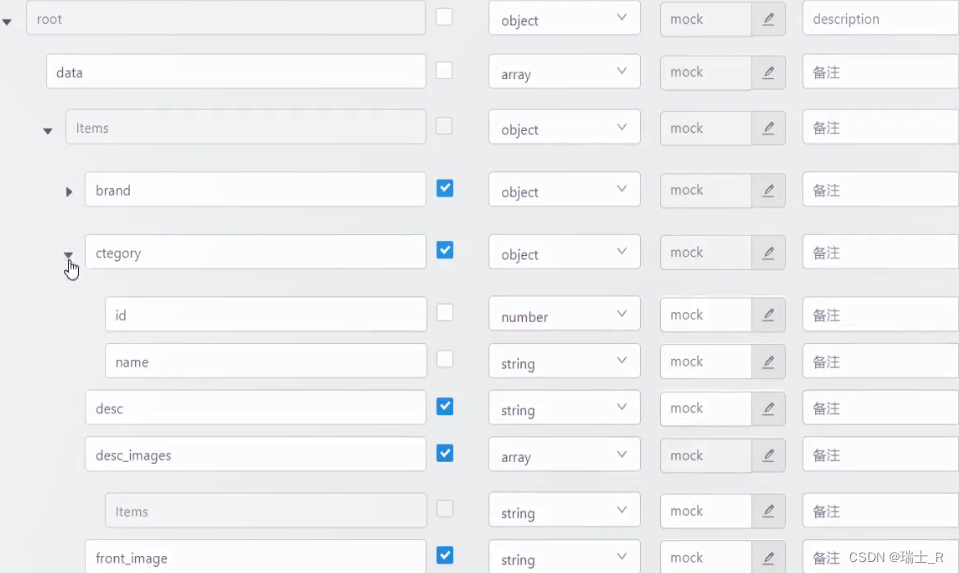
- 注:yapi 是在前端页面和 API 层之间的一个东西,定义的请求参数和返回值都有两用
- 获取商品列表需要一些请求参数,前端页面和后端(API)严格遵守文档(在yapi定义)
- 注册
- 注册中心可能换成别的(etcd/zookeper),所以新建目录 util/register/consul,定义注册逻辑
- 连接 consul 需要 host 和 port,这里采用 go 语言的风格,由于没有构造方法,需要定义结构体并给这它关联函数,然后使用 NewRegistryClient 作为构造函数使用,返回 Registry 实例
type Registry struct { Host string Port int } func NewRegistryClient(host string, port int) RegistryClient { return &Registry{ Host: host, Port: port, } } - 可以用 python 面向对象思想的 class/method/init 理解
- 但这里为了不限制 struct 的名称(不管是哪个 struct),使用 interface 作为返回值类型,表明只要 return 的这个实例实现了接口中规定的这两个方法,是哪个都行
type RegistryClient interface { Register(address string, port int, name string, tags []string, id string) error DeRegister(serviceId string) error } - go 语言中很多源码都用这种鸭子类型,在 proto 文件生成的 go stub 中也可以看到
type GoodsClient interface { //商品接口 GoodsList(ctx context.Context, in *GoodsFilterRequest, opts ...grpc.CallOption) (*GoodsListResponse, error) // .... } type goodsClient struct { cc grpc.ClientConnInterface } func NewGoodsClient(cc grpc.ClientConnInterface) GoodsClient { return &goodsClient{cc} }
- 注销
- 在 main 函数用协程启动服务器,接收中断信号优雅退出
- 新建商品 New
- 定义路由,路由建议分多个 group 管理(商品、品牌、分类,分文件管理);下面这些 API 都是,记得在 router 下定义路由
- 这个接口的基本逻辑是接收 Form 数据,封装数据,转为 struct 实例,再请求后端接口
- 把 yapi 和 proto 文件利用好
- 定义 API 前先明确调用哪个 srv 接口,理清请求参数和响应值是什么
- 商品库存涉及到跨节点分布式事务,重难点,后续补充(TODO=>Done)
- 在分布式应用中,POST 比 GET 复杂得多
- 获取商品详情 Detail
- 使用异步请求所有数据,比如这里的库存,让前端再发一个请求
- 大型网站都这么做,能很好地提升性能
- 删除商品 Delete
- 更新商品信息 Update
- 更新商品状态 UpdateStatus
- 是否为 hot、new 之类的
- 获取商品库存
- 后面我们会做库存微服务,这里先查表
商品分类
- 这部分代码和上面类似,就不赘述了
- 新建分类和更新分类信息需要定义表单
- 在 python 中转换表单数据比较容易,就是一个 json 的 load 和 dump,轻松实现 json 字符串和字典对象之间的切换
- go 里面需要先定义 struct 并带上 tag 才能转成 go 实例;go 的实例也需要通过 map 转成 json 字符串
- 记得定义路由并初始化,我们的接口符合 RESTful 风格
CategoryRouter.GET("", category.List) // 商品类别列表页 CategoryRouter.DELETE("/:id", category.Delete) // 删除分类 CategoryRouter.GET("/:id", category.Detail) // 获取分类详情 CategoryRouter.POST("", category.New) //新建分类 CategoryRouter.PUT("/:id", category.Update) //修改分类信息 - 接口测试返回的数据可以在 yapi 设置返回值时直接导入,它会据此设置返回的字段并推断类型,可能需要微调;预览中看到的是它 mock 出的数据
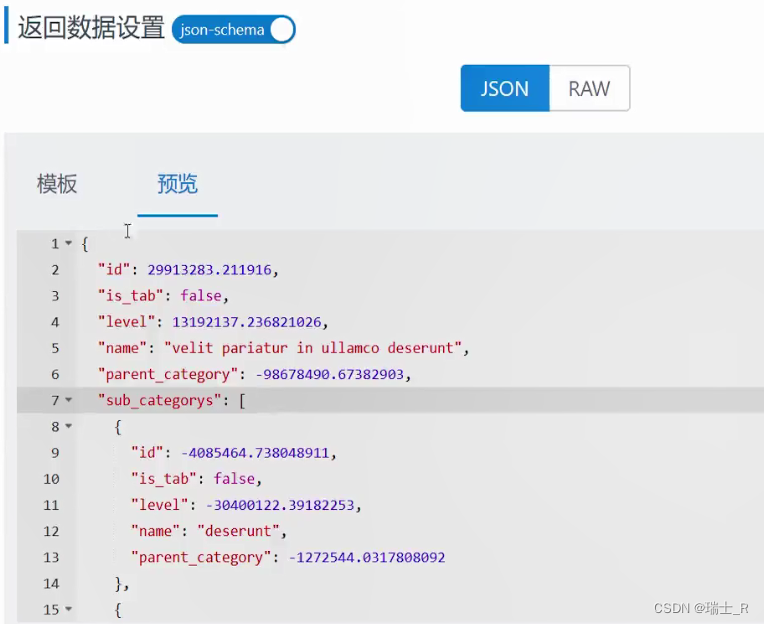
- 删除分类有可以改进的地方(TODO)
- 其子分类也应该逻辑删除
轮播图
- 这里的接口和前面类似,不再赘述
- 再介绍个使用 yapi 的技巧,当我们测试用例太多的时候可以创建测试集合,配置好规则(断言),一键搞定;注意选择测试环境
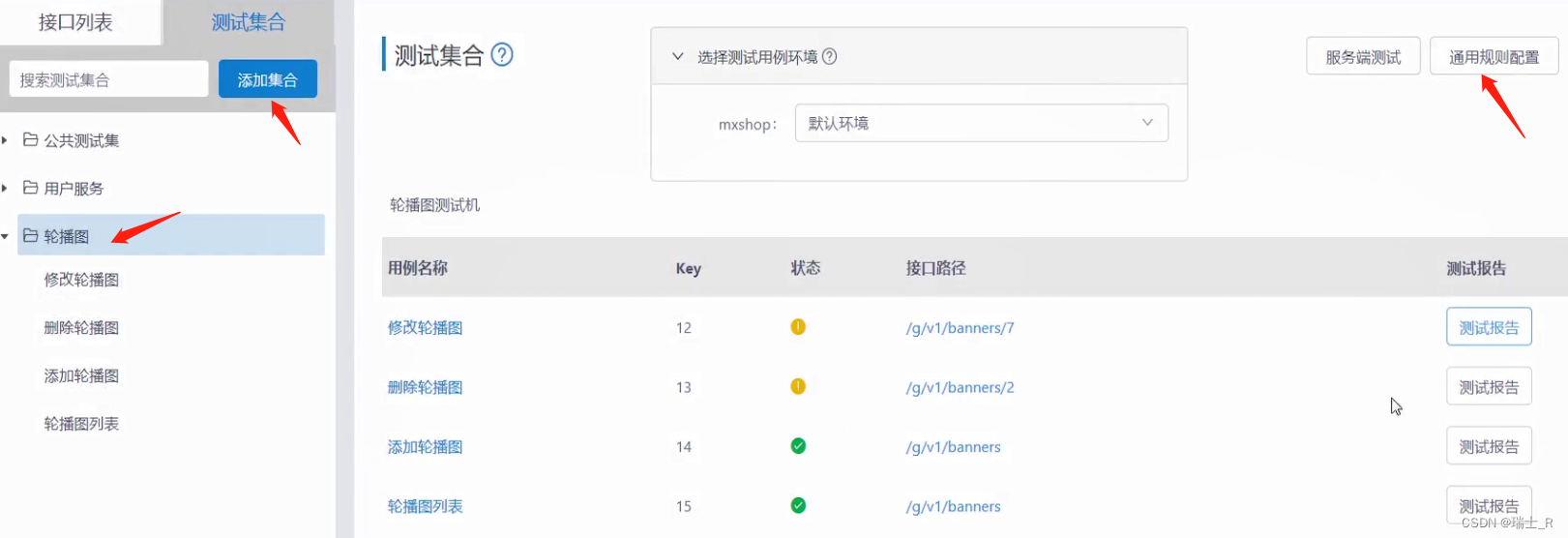
- 当然,自动化测试是个很大的话题,有很多工具可以选择,也有很多种架构可以选择
- 感兴趣的话可以看这个系列的文章了解
品牌和品牌与分类
- 和前面的 API 类似,这里放个获取某分类下所有品牌的接口定义
// 根据某个分类找到所有品牌 func GetCategoryBrandList(ctx *gin.Context) { // 1. 获取请求参数 id := ctx.Param("id") i, err := strconv.ParseInt(id, 10, 32) if err != nil { ctx.Status(http.StatusNotFound) return } // 2. 组装请求参数,请求后端接口 rsp, err := global.GoodsSrvClient.GetCategoryBrandList(context.Background(), &proto.CategoryInfoRequest{ Id: int32(i), }) if err != nil { api.HandleGrpcErrorToHttp(err, ctx) return } // 3. 解析响应数据,返回给前端 // 组成 json 格式 result := make([]interface{}, 0) // 切片 for _, value := range rsp.Data { reMap := make(map[string]interface{}) reMap["id"] = value.Id reMap["name"] = value.Name reMap["logo"] = value.Logo result = append(result, reMap) } ctx.JSON(http.StatusOK, result) } - new 和 make 的区别
oss
- 到这里基本实现了商品服务的 API 层,说明一下,目前还没有和前端页面结合起来,后面接口开发完毕会直接来一套前端源码展示
- 正常的项目开发应该是前端先设计页面给出需求文档
- 因为关系到最底层的数据库设计,牵一发而动全部 API,最好能在一开始处理得当,避免后端加班
- 我们这里旨在学习架构设计和服务开发,所以顺序有些倒置,问题不大
- 但还是有两个坑
- 商品库存如何在分布式集群中同步
- 图片如何存储
- 这里先使用阿里云的对象存储服务(oss)解决图片上传存储的问题
- 分布式服务之间是隔离的,但图片访问或者说文件访问是公共的,这就需要我们有共用的文件服务,但自己开发成本太高,推荐第三方
- 在《Go云存储-四》部分使用过,这里记录一下基本使用流程
- 这个项目就是自己搭建文件服务器,后续会更新出来
- 简而言之就是需要申请阿里云的 oss 服务并创建 Bucket
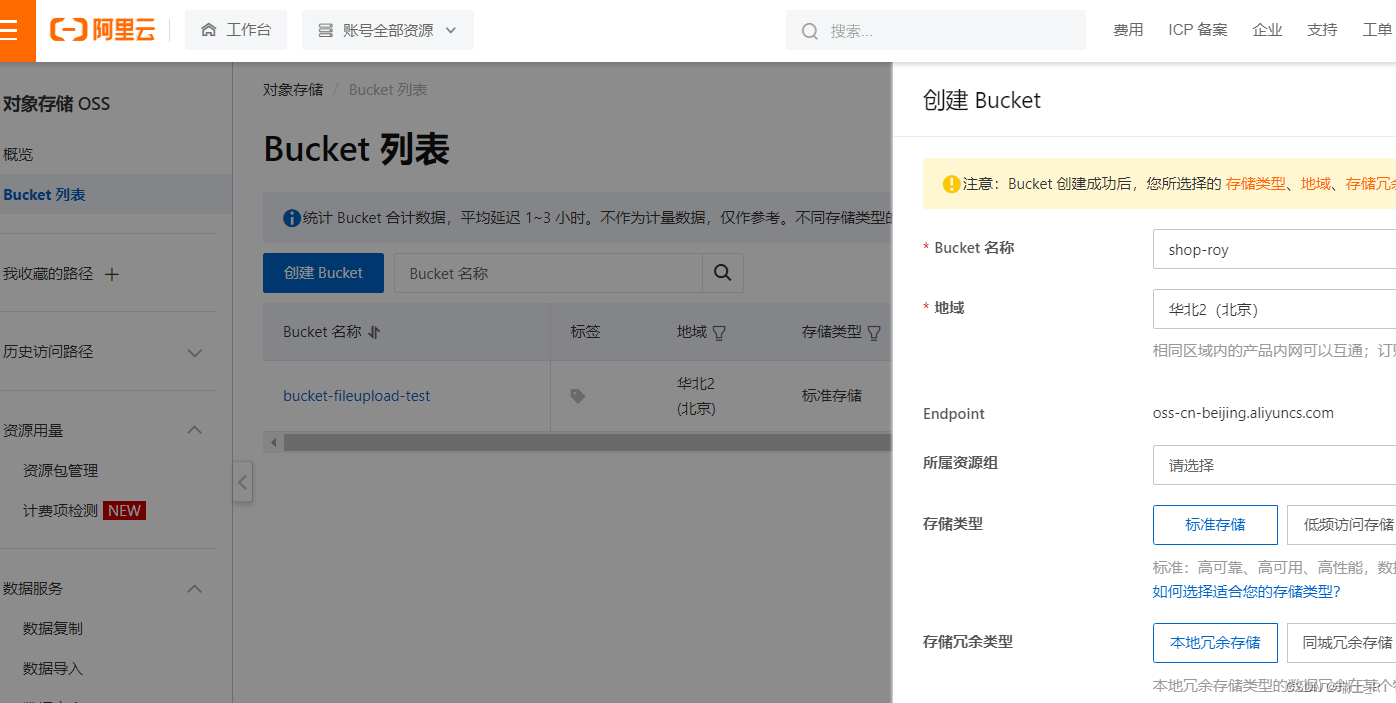
- 需要了解这些概念,记住那个 Endpoint 并创建自己的 AccessKey
- OK,作为开发人员,主要还是了解它提供的 API 了,如果你不想直接用这些接口,它还提供了针对不同语言的 SDK
- 我们用 go 语言的 SDK
- 快速入门,建议创建 RAM 子用户获取你的 KEY;子用户也能登陆页面,子用户的 key 也能用来编程访问
package main import ( "fmt" "github.com/aliyun/aliyun-oss-go-sdk/oss" "os" ) func handleError(err error) { fmt.Println("Error:", err) os.Exit(-1) } func main() { // yourEndpoint填写Bucket对应的Endpoint,以华东1(杭州)为例,填写为https://oss-cn-hangzhou.aliyuncs.com。其它Region请按实际情况填写。 endpoint := "https://oss-cn-beijing.aliyuncs.com" // 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户。 accessKeyId := "LTAI5tAnJCMgDdYKNPKK5AUP" accessKeySecret := "xxx" // yourBucketName填写存储空间名称。 bucketName := "bucket-fileupload-test" // yourObjectName填写Object完整路径,完整路径不包含Bucket名称。 objectName := "files/test.png" // yourLocalFileName填写本地文件的完整路径。 localFileName := "D:\\GoLand\\workspaces\\shop-api\\temp\\oss\\yun.png" // 创建OSSClient实例。 client, err := oss.New(endpoint, accessKeyId, accessKeySecret) if err != nil { handleError(err) } // 获取存储空间。 bucket, err := client.Bucket(bucketName) if err != nil { handleError(err) } // 上传文件。 err = bucket.PutObjectFromFile(objectName, localFileName) if err != nil { handleError(err) } } - 那我们就可以这么用了吗?
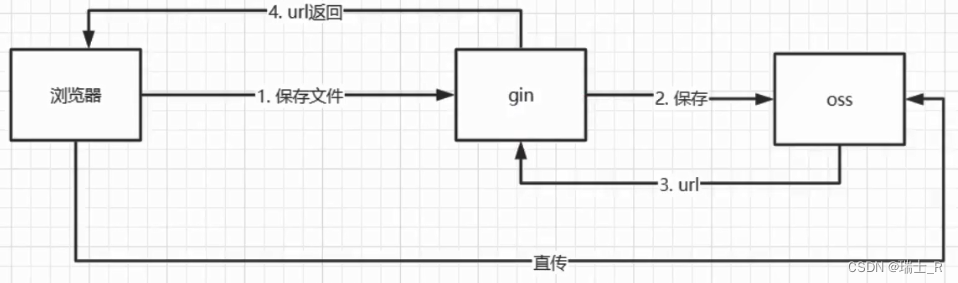
- 什么问题呢?如果用户上传文件较大,gin 这里会成为瓶颈
- 怎么解决呢?阿里云提供了一种方案:客户端直传
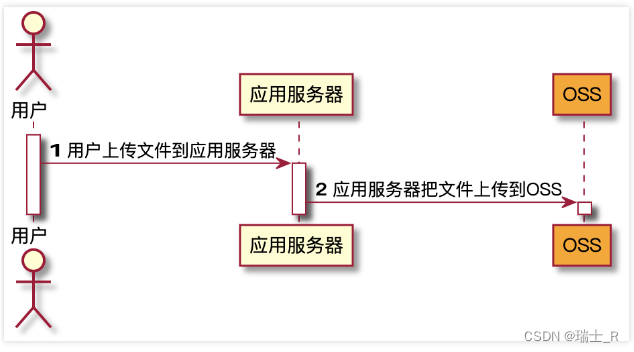
- 但这样做又会有安全问题,浏览器拿着 secret 是件很危险的事,解决方案就是给用户一个签名
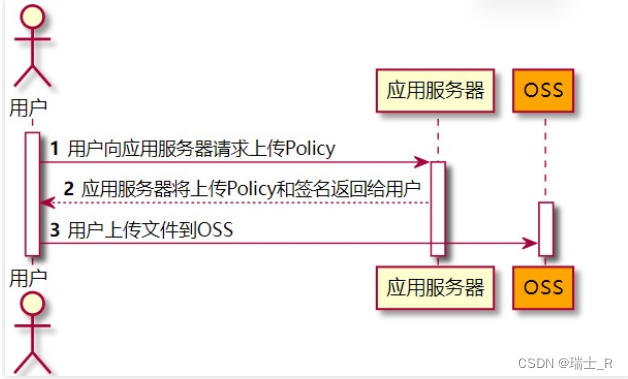
- 使用流程分两种,可以在我标出 4 的地方直接返回给客户端上传状态;如果想指定返回的信息,可以让 oss 回调我们服务器准备的函数,准备好返回给客户端的信息再给 oss,再执行第 6 步
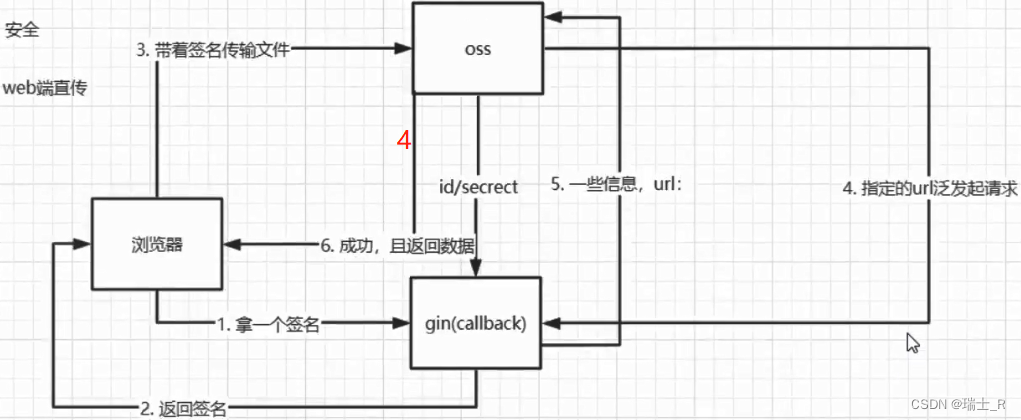
- 快速入门,建议创建 RAM 子用户获取你的 KEY;子用户也能登陆页面,子用户的 key 也能用来编程访问
- 接下来看看具体怎么做
前端直传
- 官方给了详细步骤
- 下载源码,修改相关信息,启动 server
go run appserver.go 127.0.0.1 8888- 访问 http://127.0.0.1:8888/ 会看到返回给前端的信息
{ accessid: "LTAI5tAnJCMgDdYKNPKK5AUP", host: "http://bucket-fileupload-test.oss-cn-hangzhou.aliyuncs.com", expire: 1677897001, signature: "P/C8MKC9vxoJcAOzzKDJVWv8Mf4=", policy: "eyJleHBpcmF0aW9uIjoiMjAyMy0wMy0wNFQwMjozMDowMVoiLCJjb25kaXRpb25zIjpbWyJzdGFydHMtd2l0aCIsIiRrZ", dir: "webfiles/", callback: "eyJjYWxsYmFja1VybCI6Imh0dHA6Ly8xMjcuMC4wLjE6ODg4OCIsImNhbGxiYWNrQm9keSI6ImZpbGVuYW1lPSR7b2JqZWN0fVx1MDAyNnNpemU9JHtzaXplfVx1MDAyNm1pbWVUeXBlPSR7bWltZVR5cGV9XHUwMDI2aGVpZ2h0PSR7aW1hZ2VJbmZvLmhlaWdodH1cdTAwMjZ3aWR0aD0ke2ltYWdlSW5mby53aWR0aH0iLCJjYWxsYmFja0JvZHlUeXBlIjoiYXBwbGljYXRpb24veC13d3ctZm9ybS11cmxlbmNvZGVkIn0=" } - 还没集成到我们的应用服务器,就先用本地回环测试
- 修改前端源码
- 修改
serverUrl - 注释掉 callback,意味着 oss 直接传给服务器 status
new_multipart_params = { 'key' : g_object_name, 'policy': policyBase64, 'OSSAccessKeyId': accessid, 'success_action_status' : '200', //让服务端返回200,不然,默认会返回204 //'callback' : callbackbody, 'signature': signature, }; - OK,现在可以直传文件了

- 修改
- 上述是不配置回调的情况,但如果我们想自定义返回给用户的信息
responseSuccess/responseFailed,就需要再经过我们的服务器 - 但这里个问题,oss 服务器回调我们服务器的函数,也就是请求
callbackUrl需要公网 IP,我们的服务器都在局域网上- 可以买个公网服务器,比如 ECS,通过它请求我们的内网 server
- 或者使用内网穿透服务,原理和自己买公网服务器是一样的
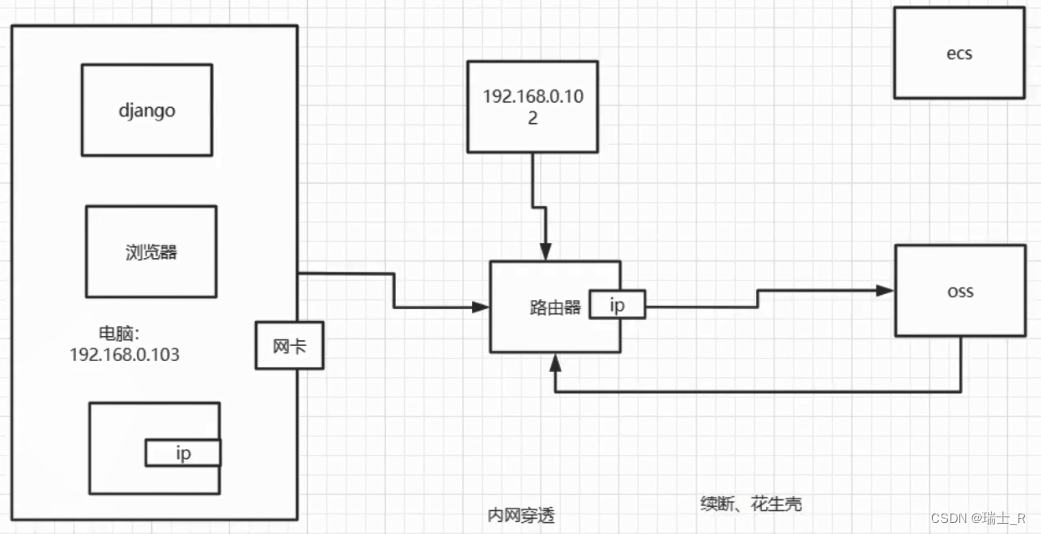
- 就不赘述了,咱们暂且不回调
- 将 oss 直传集成到 gin 微服务中
- 官方的代码是基于 http 写的,这里改写成 oss-web 微服务(gin)
- 结构和前面那些微服务一样,主要代码在 router 和 handler,官方提供的代码封装在 utils
- 记得修改 nacos 的本地和中心配置文件,确保服务正常注册
- 目前,还是现在 static/js/upload.js 设置不回调
- Q&A
- oss-web 不需要考虑分布式存储吗?(TODO)
- 共用阿里的服务器,但是分布在不同机器的多个 oss-web 微服务可能会上传同名文件
库存服务
- 接下来填另一个坑,商品库存服务
- 这个服务的作用和所处的位置如图,只在 srv 层
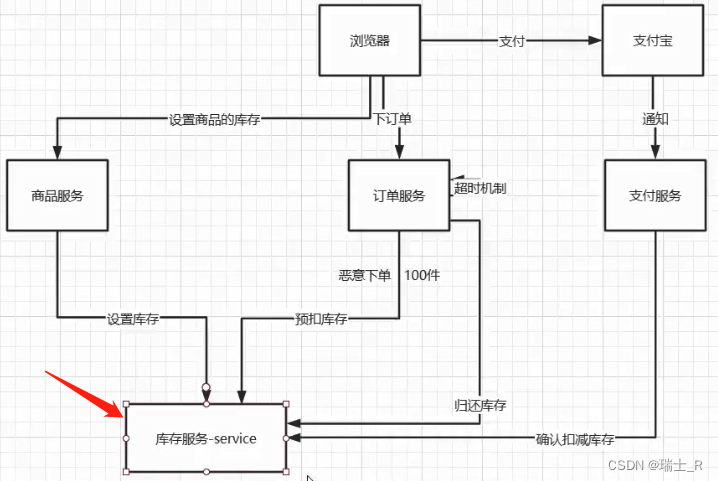
- 表设计
- 将库存单独做成微服务是很有必要的,不仅要对接订单服务和支付服务,商品库存和仓库之间的关系也比较复杂
- 大型的商家可能在不同地方有很多仓库,用户 A 下订单后,哪个仓库有货,安排哪里给用户发货等等都需要考虑;我们这里为了体现核心逻辑,先不扩展(TODO),只完成上图所示的功能;这部分的核心任务是:分布式事务
type Inventory struct{ BaseModel Goods int32 `gorm:"type:int;index"` // 这个其实是商品id,这里直接用 goods Stocks int32 `gorm:"type:int"` Version int32 `gorm:"type:int"` //分布式锁的乐观锁 } - 新建数据库,生成表
- 设计接口
- 就让 srv 层之间相互调用,当然,也有别的方式
- 首先肯定是设置库存
SetInv,给商品服务用 - 查看库存
InvDetail - 预扣减库存
Sell,给订单服务用,也可以批量,因为用户一般会直接从购物车下单多件 - 归还库存
Reback,要针对订单 ID 新设计表(归还这个订单下的所有商品),方便支持事务 - 关注点要聚焦在核心任务上,其他的扩展可以在复盘时逐一实现
- 实现接口
- 先将服务注册的逻辑拿过来
- 这里先实现基础逻辑,再考虑事务
- proto 文件提供了
UnimplementedInventoryServer让我们在编写微服务时具有向前兼容的能力- 向前兼容,可以简单理解成你不实现这个接口也能启动服务
- 重点在实现预扣库存 Sell,使用 gorm 的手动事务
- 后续还会用分布式锁解决数据不一致问题(由于并发导致超卖)
- 还是用数据库本身的加锁功能;注:这和事务不是一回事,锁是保证事务操作无误的前提
- 确认扣减库存呢?支付服务中加个回调
- 库存归还,一般是订单超时归还(15分钟内没付钱),也可能是订单创建失败归还(预扣了)
- 测试
- 注:First finds the first record ordered by primary key,也就是说 First 查询是将查询条件和主键匹配的,但我们的 goodsId 不是主键,所以会造成重复添加的问题,需要用 Where 设置条件
- 为所有商品设置库存,为后续开发做准备
func main() { Init() var i int32 // 商品表 id 从 421 到 840 for i = 421; i<=840; i++ { TestSetInv(i, 100) } }
数据不一致
- 前面预扣库存还有个数据不一致的问题
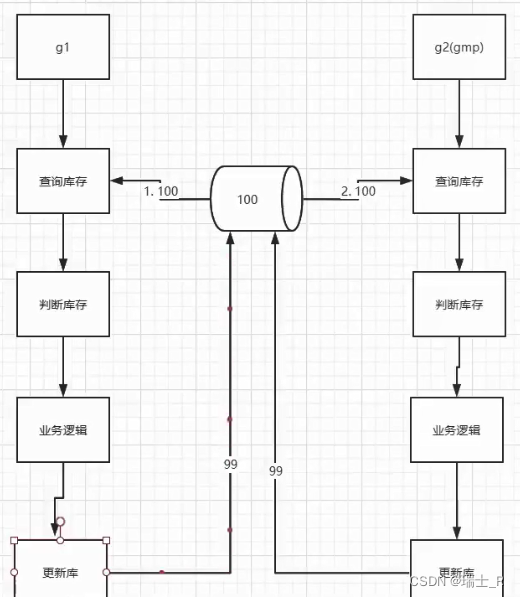
- 可以用代码模拟一下
func main() { Init() var wg sync.WaitGroup wg.Add(20) for i := 0; i < 20; i++ { go TestSell(&wg) } wg.Wait() conn.Close() } - 为了给事务一个正确的起点,需要在查询库存前加锁,提交后释放锁
- 可以使用 go 自带的
sync.Mutex里面的Lock和unLock方法 - 但这会带来严重的性能问题,因为这个锁并不针对数据库,而是这段代码,会锁住其他所有的这个函数的协程,但我们操作的不一定是同一个 goodsId,白白浪费性能;相当于表锁
- 同时,这个锁看起来没有问题,其实不然(什么问题?)
- 可以使用 go 自带的
- 那用什么锁呢?MySQL 提供了一种锁机制
for update(InnoDB引擎)- 当查询的字段建立了索引,那就只会锁住满足条件的数据,也叫行锁
- 若查无此记录,无锁
- 当然,如果没有建立索引,怎么都是表锁
- gorm 也提供了接口
// 直接用 SQL 语句是这样的 // select * from table where xxx for update // mysql 默认自动提交,提交了会释放锁,所以事务在这里起到了两个作用,还有一个就是相当于关闭autocommit // 换句话说就是:在begin与commit之间才生效 tx := global.DB.Begin() tx.Clauses(clause.Locking{Strength: "UPDATE"}) // 后面再跟 Where 即可 - 也叫悲观锁,既然是锁,就会串行,肯定有性能问题
- 当查询的字段建立了索引,那就只会锁住满足条件的数据,也叫行锁
- 基于 MySQL 的乐观锁
- 乐观锁本质上不是一种锁,而是一种分布式情况下数据一致性的解决方案
- 需要我们加一个字段:
version,更新条件中带上 version,如果和一开始查询到的 version 不一致,证明之前查到的数据已经别人被更新了,需要重新查询;如果更新成功则需把 version+1
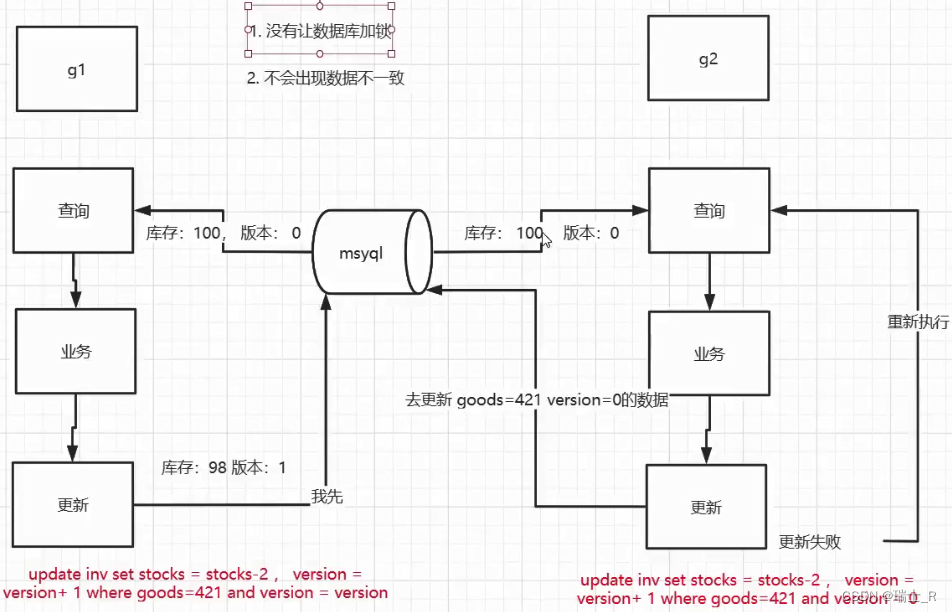
- 在代码中使用乐观锁
for { // 这里有个坑,就是一定要用 Select,不然有零值问题,gorm 会忽略掉不更新,就是说不让你设置为0,库存虽然只剩一件,但是version没问题,全部都能扣减成功!库存始终是1 if result := tx.Model(&model.Inventory{}).Select("Stocks", "Version").Where("goods = ? and version= ?", goodInfo.GoodsId, inv.Version).Updates(model.Inventory{Stocks: inv.Stocks, Version: inv.Version+1}); result.RowsAffected == 0 { zap.S().Info("库存扣减失败") }else{ break } }
- OK,分布式锁的第一种方案就是:基于 MySQL 的乐观锁
redis 分布式锁
- 基于 Redis 实现分布式锁是常见方案,也是这里的第二种方案(推荐)
- 这里有实现此方案的开源项目,使用方法自己看
- 集成到代码
client := goredislib.NewClient(&goredislib.Options{ Addr: fmt.Sprintf("%s:%d", global.ServerConfig.RedisInfo.Host, global.ServerConfig.RedisInfo.Port), }) pool := goredis.NewPool(client) // or, pool := redigo.NewPool(...) rs := redsync.New(pool) // ... mutex := rs.NewMutex(fmt.Sprintf("goods_%d", goodInfo.GoodsId)) // 剩下的就和go自带的mutex类似 - 和 go 不同的是,Save 之后就可以释放锁
mutex.Unlock() - 具体原理
- setnx:原子操作,设置key/value,这个 key 可以是我们的商品 id,value 是唯一的,保证不被其他用户删除
- 当时设置的 value 值是多少只有当时的 g 才能知道
- 删除时会取出 redis 中的值和当前自己保存下来的值对比一下
- 加入超时机制,避免死锁;也需要延时操作,避免活没干完锁丢了
- 产生死锁是因为 redis 服务可能挂掉了,为了获取锁而一直等待
- 使用 redlock 解决 redis 集群 master 可能宕机导致的数据不同步问题
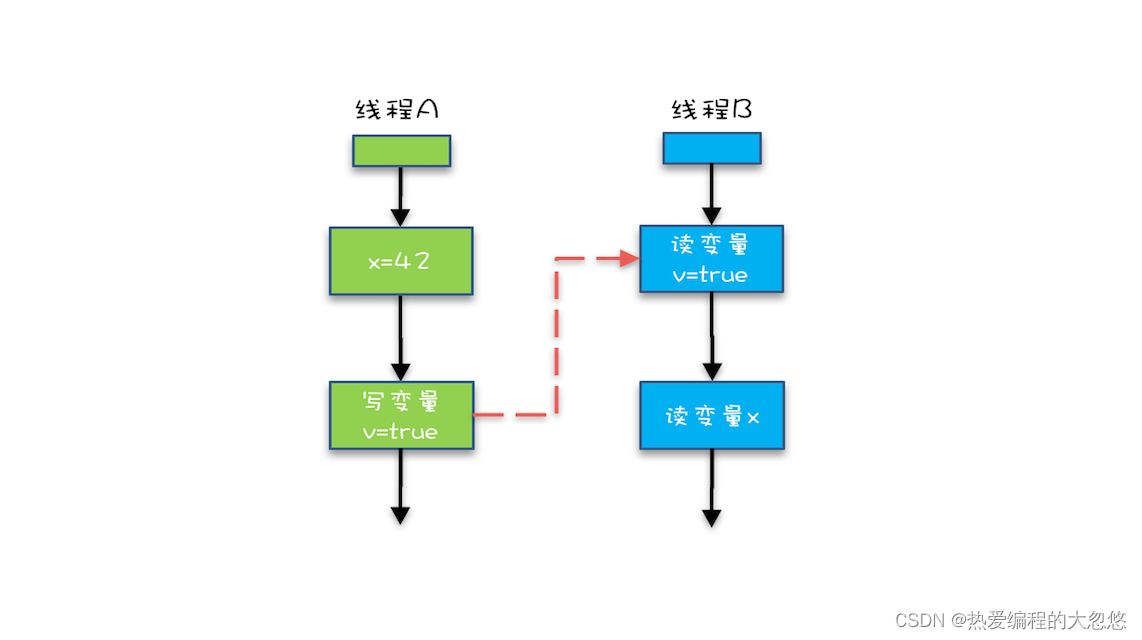
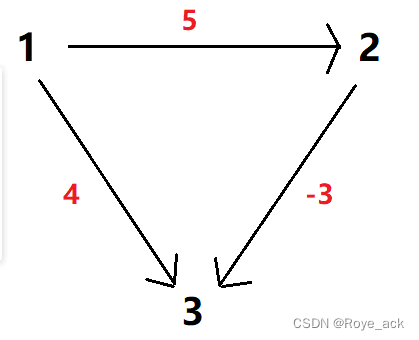
- 这个问题源于下图这种模式:都从 master 获取锁
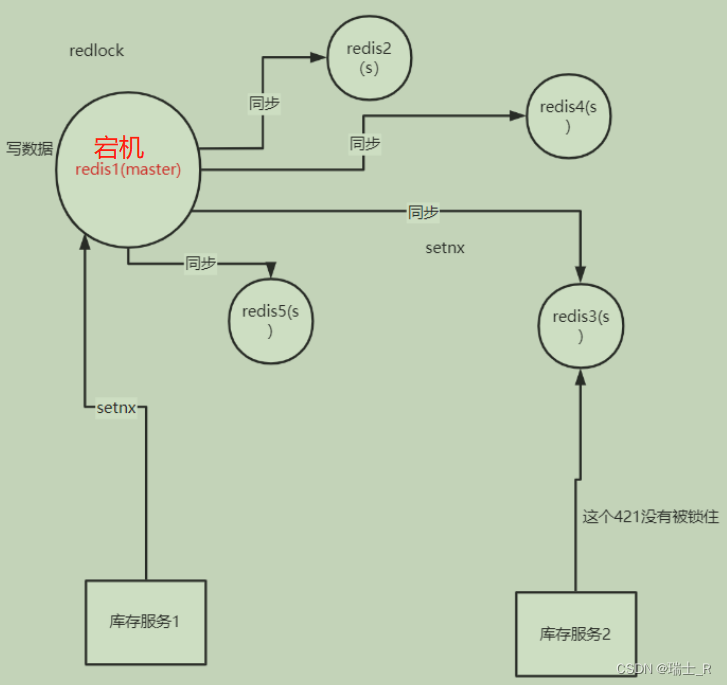
- 所有 redis 机器都视作相同服务器
- client 尝试按照顺序使用相同的 KV 获取所有 redis 的锁
- 机器个数一般为奇数个,获取锁较多的 client 最终获得锁
- 这里还有个时钟漂移问题,需要设置因子考虑漂移时间
- 这个问题源于下图这种模式:都从 master 获取锁
- 建议根据上述逻辑看一遍源码,并不复杂
- setnx:原子操作,设置key/value,这个 key 可以是我们的商品 id,value 是唯一的,保证不被其他用户删除
小结
- 商品微服务到这里基本梳理结束,还差最后一步,将 elasticsearch 集成进去,会在订单微服务完成后一并接入
- 关于多机部署问题会在所有微服务完成后统一梳理
- 各微服务之间代码结构大同小异,web 层在 api 定义主要逻辑,srv 层在 handler 定义主要逻辑



![[YOLO] yolov3、yolov4、yolov5改进](https://img-blog.csdnimg.cn/4fc6b9403e9f495f94d896cc4bf3beba.png)