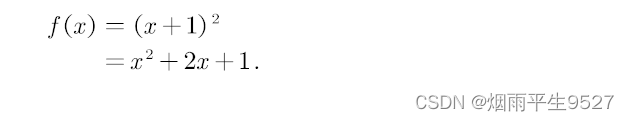EdgeYOLO学习笔记
EdgeYOLO: An Edge-Real-Time Object Detector
Abstract
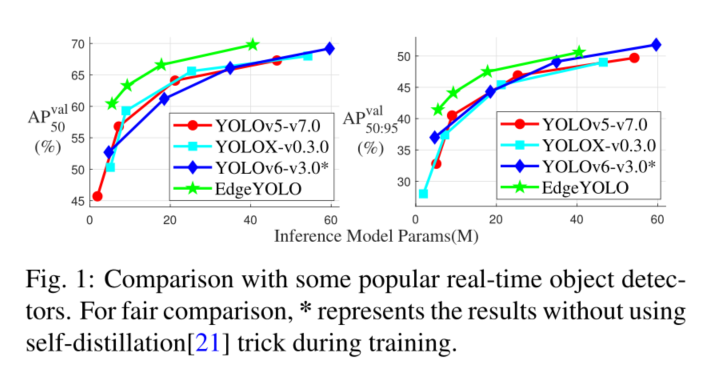
本文基于最先进的YOLO框架,提出了一种高效、低复杂度、无锚的目标检测器,该检测器可以在边缘计算平台上实时实现。为了有效抑制训练过程中的过拟合,我们开发了一种增强的数据增强方法,并设计了混合随机损失函数来提高小目标的检测精度。在FCOS的启发下,提出了一种更轻、更高效的解耦磁头,在不损失精度的情况下提高了推理速度。我们的基线模型在MS COCO2017数据集中可以达到50.6% AP50:95和69.8% AP50的精度,在VisDrone2019-DET数据集中可以达到26.4% AP50:95和44.8% AP50的精度,在Nvidia Jetson AGX Xavier边缘计算设备上可以满足实时(FPS≥30)的要求。如图1所示,我们还为计算能力较低的边缘计算设备设计了更轻、参数更少的模型,也表现出了更好的性能。我们的源代码、超参数和模型权重都可以在https://github.com/LSH9832/edgeyolo上找到。
Key Words: Anchor-free, edge-real-time, object detector, hybrid random loss
1 Introduction
随着计算硬件性能的不断提高,基于深度神经网络的计算机视觉技术在近十年得到了迅速发展,其中目标检测是自主智能系统[1]应用的重要组成部分。目前,主流的目标检测策略有两种。一种是以R-CNN系列[2,5]为代表的两阶段策略,另一种是以YOLO[9-11]为最流行的框架之一的一阶段策略。对于两阶段策略,在第一阶段采用启发式方法或区域建议生成方法获得多个候选盒,然后在第二阶段对这些候选盒进行筛选、分类和回归。单阶段策略以端到端的方式给出结果,其中目标检测问题转化为全局回归问题。全局回归不仅能够同时为多个候选框分配位置和类别,而且能够使模型更清晰地分离对象和背景。
在常见对象检测数据集(如MS COCO2017[3])上,使用两阶段策略的模型比使用一阶段策略的模型表现稍好。然而,由于两阶段框架的内在局限性,它远远不能满足传统计算设备上的实时性要求,在大多数高性能计算平台上也可能面临同样的情况。相比之下,单级目标检测器可以在实时指标和性能之间保持平衡。因此,它们更受到研究人员的关注,YOLO系列算法以高速迭代更新。从YOLOv1到YOLOv3[9-11]的更新主要是对底层框架结构的改进,之后的YOLO主流版本大多侧重于提高精度和推理速度。此外,他们的优化测试平台主要是具有高性能gpu的大型工作站。然而,他们最先进的模型通常在这些边缘计算设备上以令人不满意的低FPS运行。为此,一些研究人员提出了参数更少、结构更轻的网络结构,如MobileNet和ShuffleNet,以取代原有的骨干网,从而在移动设备和边缘设备上获得更好的实时性,但牺牲了一些精度。在本文中,我们的目标是设计一个具有良好精度的对象检测器,可以实时运行在边缘设备上。
本文的主要贡献如下:
i)设计了一种无锚目标检测器,该检测器可在MS COCO2017数据集上实时运行在边缘设备上,AP精度为50.6%;
ii)提出了一种更强大的数据增强方法,进一步保证了训练数据的数量和有效性;
iii)在我们的模型中使用可以重新参数化的结构,以减少推理时间;
iv)设计损失函数以提高对小目标的精度。
2 Related Work
2.1 Anchor-free Object Detector
自YOLOv1问世以来,YOLO系列在实时目标检测领域长期处于领先地位。还有一些其他优秀的检测器,如SSD [4], FCOS[15]等。在测试目标检测任务中的FPS时,以往的研究大多只计算模型推断的时间成本,而一个完整的目标检测任务包含预处理、模型推断和后处理三个部分。由于预处理可以在视频流中完成,因此在计算目标检测的FPS时,需要考虑后处理的时间成本。在高性能GPU工作站或服务器上,预处理和后处理的时间只占很小的比例,而在边缘计算设备上,其延迟时间甚至是其十倍以上。因此,减少后处理计算可以显著提高边缘计算设备的速度。当使用基于锚点的策略时,后处理中的时间延迟几乎与每个网格单元的锚点数量成正比。基于锚的YOLO系列通常为每个网格单元分配3个锚。与基于锚点的检测框架相比,无锚点检测在后处理部分可以节省一半以上的时间
为了保证检测器在边缘计算设备上的实时性,我们选择构建一个基于无锚策略的目标检测器。目前无锚检测器主要有两种类型,一种是基于锚点的检测器,另一种是基于关键点的检测器。在本文中,我们采用了基于锚点的范式。
2.2 Data Augmentation
数据增强是神经网络训练中一个重要的数据处理步骤。合理使用数据增强方法可以有效缓解模型过拟合。对于图像数据集,几何增强(随机裁剪、旋转、镜像、缩放等)和光度增强(HSV和亮度调整)通常应用于单个图像。这些基本增强方法通常用于多图像混合和拼接之前或之后。目前主流的数据增强技术,如Mosaic[18]、Mixup[7]、CopyPaste[17]等,通过不同的方法将多张图片的像素信息放在同一张图片中,丰富图像信息,降低过拟合概率。
如图2(b)所示,我们设计了一种更加灵活和强大的组合增强方法,进一步保证了输入数据的丰富性和有效性。

2.3 Model Reduction
通过模型约简,降低了计算成本,可以有效提高模型推理速度。模型约简方法可分为有损约简和无损约简两类。有损缩减通常通过减少网络层数和信道数来构建更小的网络。无损缩减集成和耦合多个分支模块,通过重新参数化技术[25]构建更精简的等效模块。有损缩减通过牺牲精度来实现更快的速度,并且由于耦合结构容易降低训练效果,一般采用重参数化方法在模型训练完成后进行推理。
本文结合有损约简和无损约简方法,构建了多个不同大小的模型(如图1所示),拟合不同计算能力的边缘器件,加快了模型推断过程。
2.4 Decoupled Regression
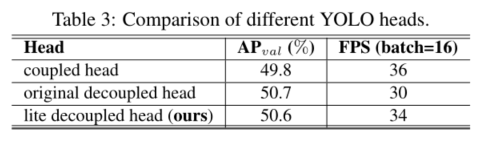
从YOLOv1到YOLOv5[9 - 11,18,19],对于每个不同比例比的特征图,回归获得对象的位置、类别和置信度使用统一的卷积核集。一般来说,不同的任务如果关系密切,则使用相同的卷积核。然而,在数值逻辑中,对象的位置、置信度和类别之间的关系还不够密切。而且,相关实验证明,使用解耦的回归检测头[15,23]与直接统一所有任务的回归检测头相比,可以获得更好的结果,并且可以加速损失收敛。尽管如此,解耦的头部会带来额外的推断成本。作为改进,我们设计了一种更轻的解耦头,同时考虑了模型的推理速度和精度。
2.5 Small Object Detecting Optimization
自目标检测研究开始以来,小目标检测问题一直受到广泛关注。随着物体在图像中的比例减少,用于表达物体的像素信息也会减少。大物体往往比小物体占用几十倍甚至上百倍的信息,小物体的检测精度往往明显低于大物体。而且,这种差距不能通过位图图像的属性来消除。此外,研究人员发现,在训练[14]时,小物体在总损失中所占的比例总是较小。
为了提高小目标的检测效果,以往的研究提出了以下方法:(a)复制小目标,并随机放置在图像的其他位置,以增加数据增强过程中小目标的训练数据样本,称为复制增强[14]。(b)对图像进行缩放和拼接,将原始图像中较大的物体放大为较小的物体。©损失函数通过增加小物体损失的比例[8],使其更加关注小物体。
由于使用方法(a)处理的图像存在尺度不匹配和背景不匹配的问题,我们仅参考方法(b)和方法©来优化训练过程。我们的数据增强中加入了缩放和拼接方法,并重新设计了损失函数,可以有效提高中小目标的检测和模型的整体精度。
3 Approach
3.1 Enhanced-Mosaic & Mixup
许多实时目标检测器在训练过程中使用Mosaic+Mixup策略进行数据增强,可以有效缓解训练过程中的过拟合情况。如图3(a)和(b)所示,有两种常见的组合方法,当数据集中的单幅图像有相对足够的标签时,它们表现良好。由于数据论证中的随机过程,在图3(a)中,当标签空间有响应时,数据加载器可能会提供没有有效对象的图像,这种情况的概率随着每张原始图像中标签数量的减少而增加。
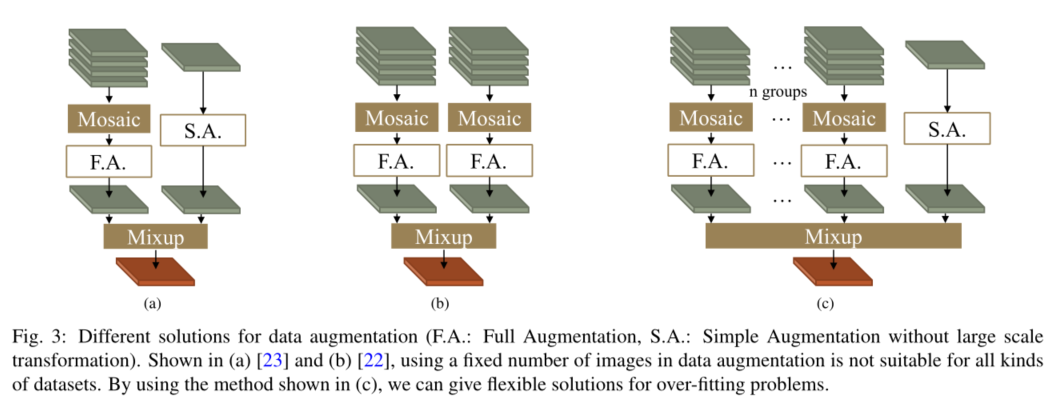
我们设计了如图3©所示的数据增强结构。首先,我们对多组图像使用Mosaic方法,可以根据数据集中单张图片平均标签数量的丰富度来设置组数。然后,利用Mixup方法将最后的简单处理图像与这些经过马赛克处理的图像进行混合。在这些步骤中,我们最后一个图像的原始图像边界在变换后最终输出图像的边界内。这种数据增强方法有效地增加了图像的丰富度以缓解过拟合,并确保输出图像必须包含足够的有效信息。
3.2 Lite-Decoupled Head
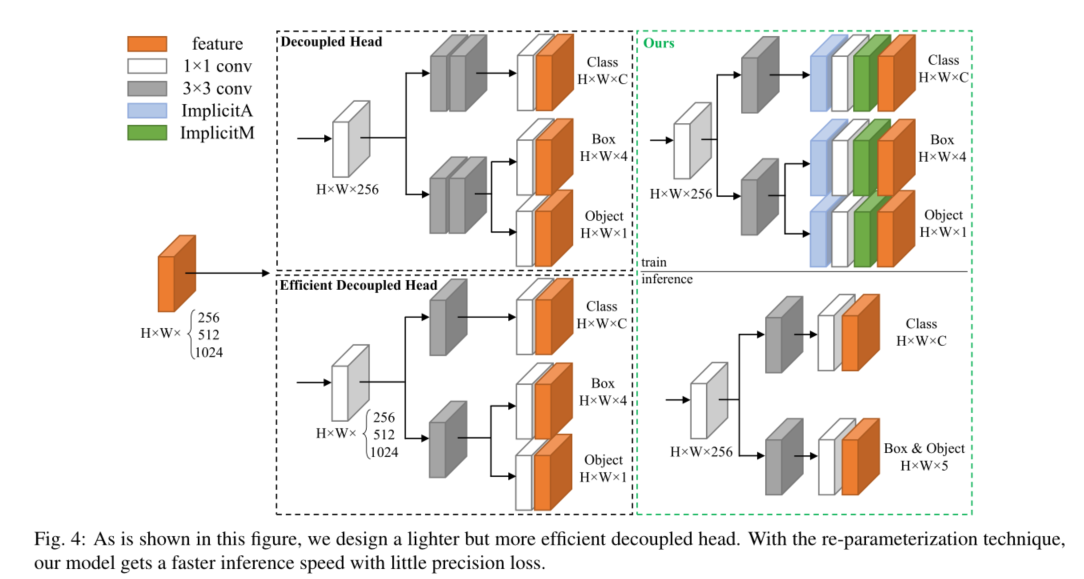
首先在FCOS[15]中提出了图4中的解耦头,然后应用于其他无锚目标探测器,如YOLOX[23]。最后几层采用解耦结构可以加快网络收敛速度,提高回归性能。
由于解耦头采用分支结构,导致额外的推理成本,因此提出了高效解耦头[20],其推理速度更快,将中间3×3卷积层数减少到只有一层,同时保持与输入特征图相同的较大通道数。然而,在我们的实验测试中,这种额外的推断成本随着通道和输入大小的增加而变得更加明显。因此,我们设计了一个更轻的解耦头部,具有更少的通道和卷积层。此外,我们将隐式表示层[24]添加到所有最后的卷积层,以获得更好的回归性能。采用重新参数化的方法,将隐式表示层集成到卷积层中,以降低推理成本。最后的卷积层盒和置信度回归也合并,使模型可以进行推理与高并行计算。
3.3 Staged Loss Function
对于目标检测,损失函数一般可以写成如下形式
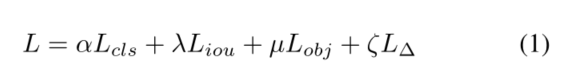
其中 L c l s 、 L i o u 、 L o b j 、 L ∆ L_cls、L_iou、L_obj、L_∆ Lcls、Liou、Lobj、L∆为分类损失、IOU损失、对象损失和调控损失, α 、 λ 、µ、 ζ α、λ、µ、ζ α、λ、µ、ζ为超参数。在实验中,我们将训练过程分为三个阶段。
在第一阶段,我们采用一种最常见的损失函数配置:gIOU损失为IOU损失,分类损失和对象损失为平衡交叉熵损失,调节损失设为零。在最后几个支持数据增强的时代,培训过程进入了第二个阶段。将分类损失和目标损失的损失函数替换为混合随机损失
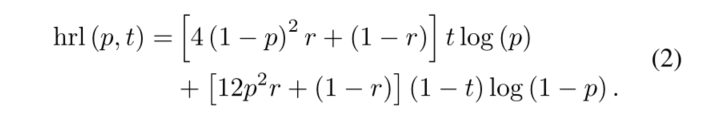
其中p代表预测结果,t代表ground truth, r是0到1之间的随机数。对于一个图像中的所有结果,我们有这个
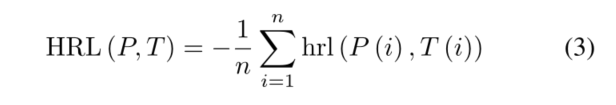
这表明小物体的精度和总精度之间有更好的平衡。第三阶段,我们关闭数据扩充,将L1损耗作为我们的调节损耗,将gIOU损耗替换为cIOU损耗。下一节将介绍更多细节。
4 Experiments
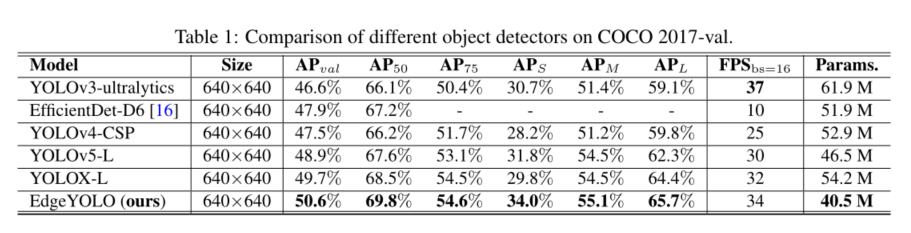
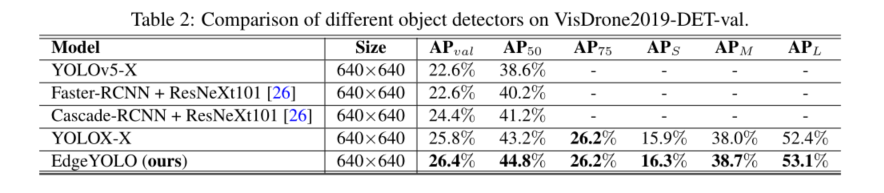



5 Conclusion
我们提出了一种边缘实时无锚的一级检测器EdgeYOLO,其代表性结果如图5和图6所示。实验表明,EdgeYOLO可以在边缘设备上实时高精度运行,对小物体的检测能力得到了进一步提高。由于EdgeYOLO采用无锚结构,降低了设计复杂度和计算复杂度,在边缘设备上的部署更加友好。此外,我们相信该框架可以扩展到其他像素级识别任务,如实例分割。在未来的工作中,我们将进一步提高框架对小目标的检测精度,并对高效优化进行探索。


![论文解析[11] CAT: Cross Attention in Vision Transformer](https://img-blog.csdnimg.cn/5430cf7c7ac040dda1be2310141e623a.png)
![[数据集][VOC][目标检测]河道垃圾水面漂浮物数据集目标检测可用yolo训练-1304张介绍](https://i1.hdslb.com/bfs/archive/5c12f67ab09f89d659e4f816d5cd90be83a7b6ee.jpg@100w_100h_1c.png@57w_57h_1c.png)


![[1.3.3]计算机系统概述——系统调用](https://img-blog.csdnimg.cn/img_convert/caf7058e90fe1b17e2978a4d6c45ec83.png)
![English Learning - L2-4 英音地道语音语调 双元音 [eɪ] [aɪ] [aʊ] [əʊ] [ɔɪ] 2023.03.2 周四](https://img-blog.csdnimg.cn/5f22d48076dd4293b0991e808567e2ad.png)