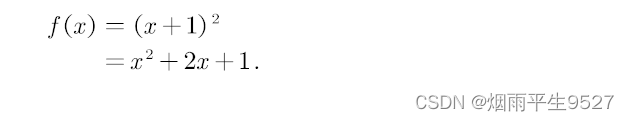发表时间:2021
论文地址:https://arxiv.org/abs/2106.05786v1
文章目录
- 摘要
- 3 方法
- 3.1 总体结构
- 3.1.1 Inner-Patch Self-Attention Block
- 3.1.2 Cross-Patch Self-Attention Block
- 3.1.3 Cross Attention based Transformer
- 结论
摘要
使用图像patch来替换transformer中的word token所需要的计算量是巨大的。
在本论文中,我们在Transformer中提出了一种新的注意机制,称为交叉注意力。在图像patch内部而不是整张图像中捕获局部信息,在单通道特征图中的图像patch之间捕获全局信息。
两个操作都比Transformer中的标准自注意力有更少的计算量。通过在patch内和patch间交替应用注意力,我们实现了交叉注意力以更低的计算代价保持性能,构建了一个称为交叉注意力Transformer(CAT)的分层网络。
3 方法
3.1 总体结构
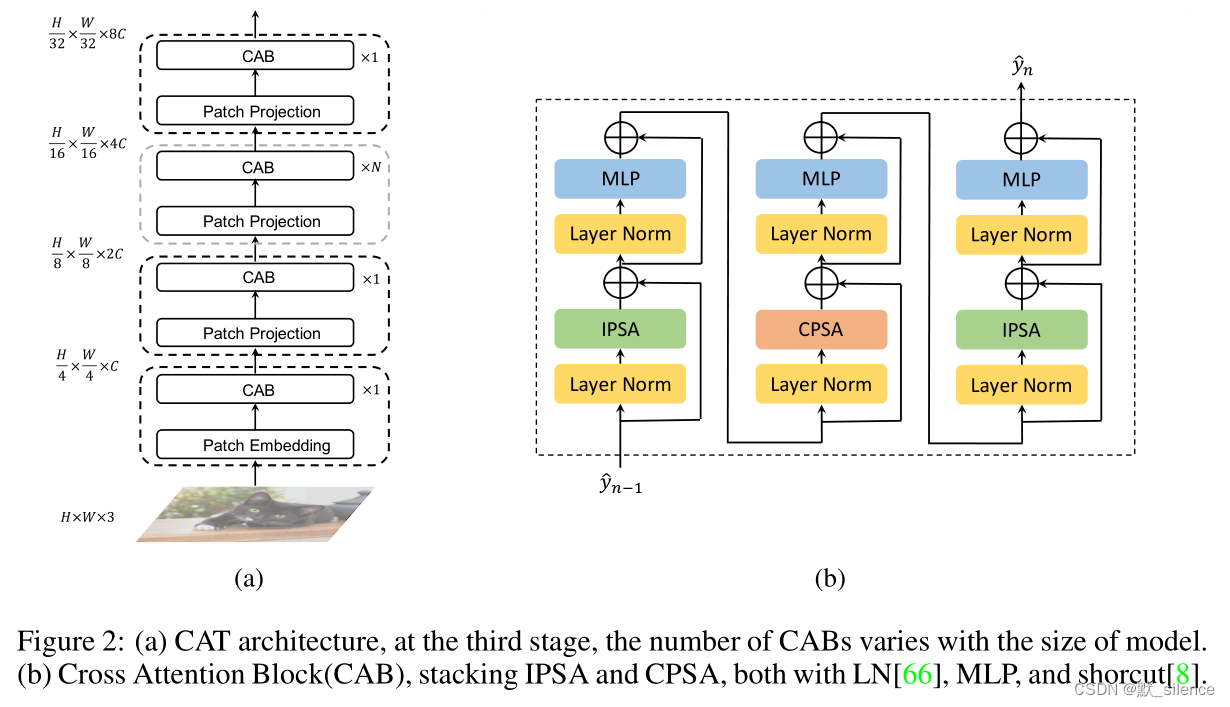
如图2(a),首先在patch嵌入层将输入图像缩小到
H
1
=
H
/
P
,
W
1
=
W
/
P
H_1=H/P,W_1=W/P
H1=H/P,W1=W/P,并将通道数提升到
C
1
C_1
C1。接下来是一些在不同尺度进行特征提取的CAT层。
经过上面的预处理,进入第一个stage。patch数量是 H 1 / N × W 1 / N H_1/N×W_1/N H1/N×W1/N,patch大小为 N × N × C 1 N×N×C_1 N×N×C1。stage1输出的特征图作为 F 1 F_1 F1。
此时进入第二个stage,patch投影层执行空间到更深的操作。在通过下一层的交叉注意力块之后,生成大小为 H 1 / 2 × W 1 / 2 × C 2 H_1/2×W_1/2×C_2 H1/2×W1/2×C2 的 F 2 F_2 F2。经过四个stage之后,可以得到四个不同尺度和维度的特征图。类似于基于卷积的网络,不同粒度的特征图可以用于其他的下游视觉任务。
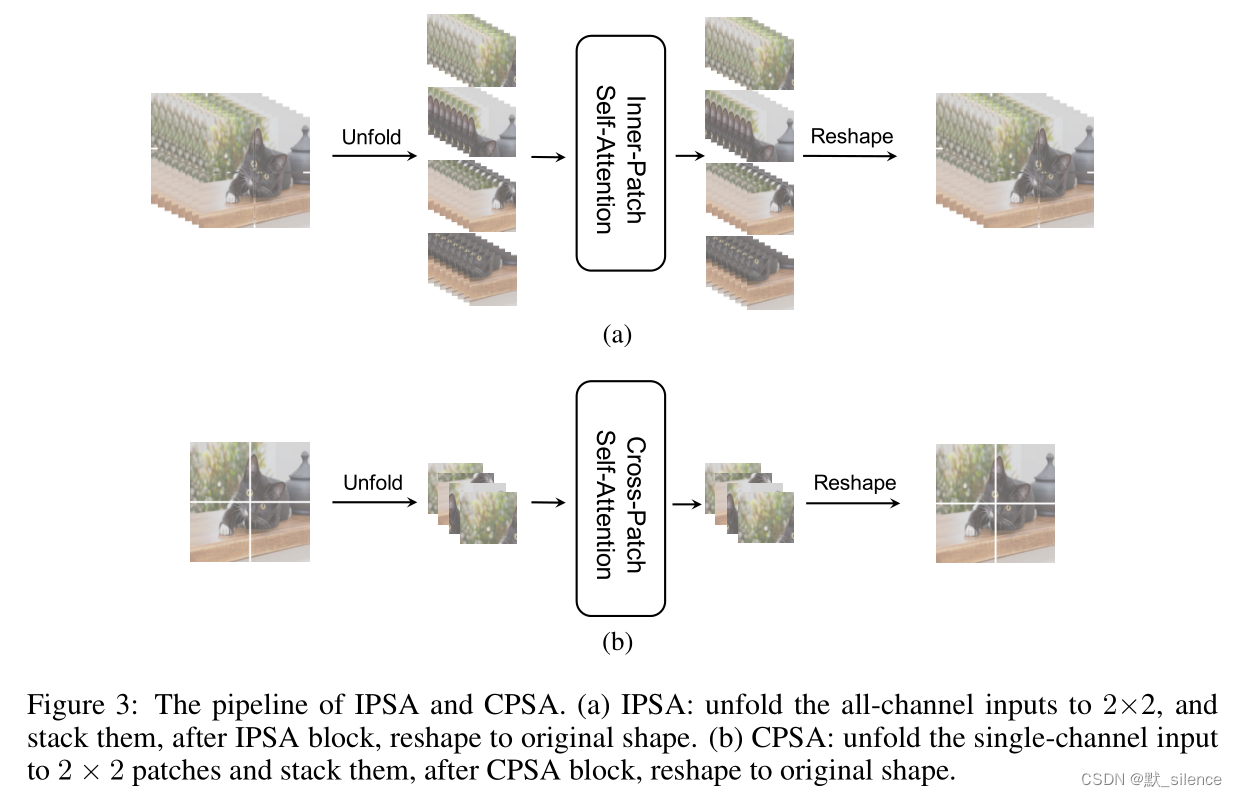
3.1.1 Inner-Patch Self-Attention Block
普通多头注意力的复杂度:
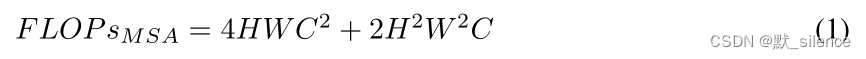
将CNN网络中的局部卷积方法引入Transformer,来对每个patch中的像素进行自注意力,叫作Inner-Patch Self-Attention(IPSA)。
IPSA的复杂度:
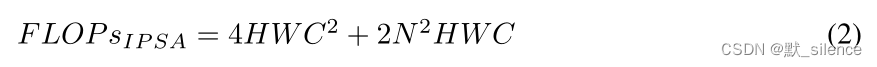
N
N
N 是IPSA中的patch大小
3.1.2 Cross-Patch Self-Attention Block
提出了Cross-Patch Self-Attention Block,分开每个通道特征图,把每个通道划分为 H / N × W / N H/N×W/N H/N×W/N 个patch,在整张特征图中使用自注意力来获取全局信息。
CPSA的复杂度:
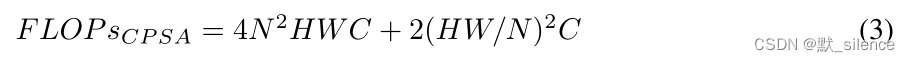
3.1.3 Cross Attention based Transformer
Cross Attention block包括两个IPSA块和一个CPSA块。CAT层由一些CAB组成,网络的每个stage由一些不同数量的层和一个patch嵌入层组成,如图2(a)所示。
CAB的流程:
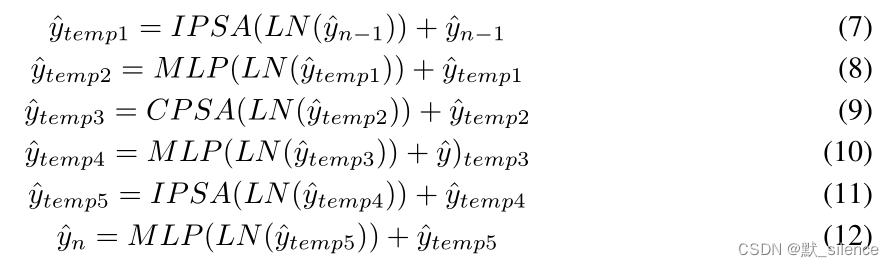
结论
提出的Cross Attention更好的结合了CNN中局部特征和Transformer中全局信息的价值。它可以生成类似于CNN网络的不同尺度的特征,也可以适应不同的输入大小。CAT在一些数据集上取得了sota的表现。关键在于我们轮换使用特征图patch中的注意力和单通道特征图中的注意力来获取局部和全局信息。
![[数据集][VOC][目标检测]河道垃圾水面漂浮物数据集目标检测可用yolo训练-1304张介绍](https://i1.hdslb.com/bfs/archive/5c12f67ab09f89d659e4f816d5cd90be83a7b6ee.jpg@100w_100h_1c.png@57w_57h_1c.png)


![[1.3.3]计算机系统概述——系统调用](https://img-blog.csdnimg.cn/img_convert/caf7058e90fe1b17e2978a4d6c45ec83.png)
![English Learning - L2-4 英音地道语音语调 双元音 [eɪ] [aɪ] [aʊ] [əʊ] [ɔɪ] 2023.03.2 周四](https://img-blog.csdnimg.cn/5f22d48076dd4293b0991e808567e2ad.png)