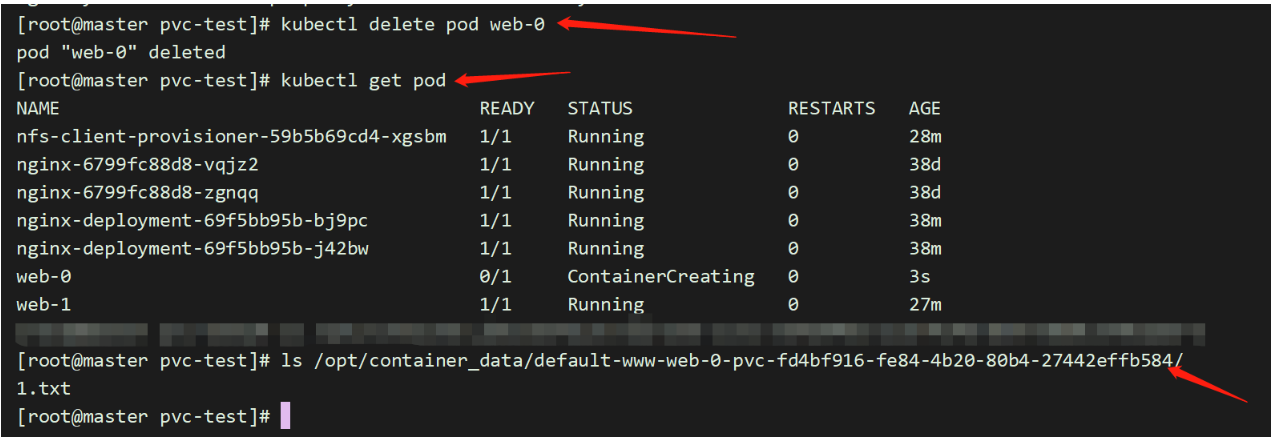
一、背景
为了节约资源,MySQL会对建立的连接进行监控,当某些连接处于不活跃状态的时间超过一个阈值时,则关闭它们。
用户可以执行show variables like '%wait_timeout%';来查看这个阈值:

可以看到,在默认的情况下,这个阈值是28800秒,即,如果一个连接处于不活跃的时间超过8小时,则该连接不再可用。
下面给出一个具体的例子。
1、为了能够快速验证,首先使用set global wait_timeout=10;语句将该阈值设置为10。
设置成功后需要通过
show global variables like '%wait_timeout%';进行查看。为什么要加global?可以参考这里。
2、执行以下验证代码:
from sqlalchemy import create_engine, text
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/platform')
sql = "select 1+1;"
with engine.connect() as conn:
res = conn.execute(text(sql))
print(res.fetchone()[0])
打印结果2。
3、等待超过10秒钟后,再次执行上述代码中的with:部分,则会得到如下错误:
sqlalchemy.exc.OperationalError: (pymysql.err.OperationalError) (2013, 'Lost connection to MySQL server during query')
即无法连接到MySQL服务器。
二、问题
设想这样一个场景:通过flask启动了一个REST服务,该服务需要访问数据库,且每天被定时请求一次(除此之外无请求)。
按照上一节的讨论,由于两次请求间隔(24小时)超过了关闭阈值(8小时),因此在下一次发送请求时,会报出Lost connection的错误。
三、解决方案
一个可选的解决方案是,增加
wait_timeout的值,使之超过24小时。但这样很可能导致数据库中存在大量的处于sleep状态的进程,从而造成资源的浪费。这里不考虑此种方案。
既然是连接失效,那么一种比较直观的解决方案就是在每次使用连接进行数据库操作前,先检验一下连接是否有效。有效就直接使用;无效则重新连接。
SQLAlchemy提供了基于上述思路的解决方案——指定pool_pre_ping参数:
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/platform', pool_pre_ping=True)
这样定义engine之后,再执行上面的验证例子可以发现,即使两次执行with:的间隔超过了阈值,仍可以执行成功。
四、更深入的分析
4.1 Engine与连接池
本系列的第一篇中说“可以将Engine对象视为连接池”,但严格来讲这是不正确的。要正确理解它们之间的关系,需要借助下面这张结构图:

最右侧是数据库,SQLAlchemy通过第三方的DBAPI与之进行连接——在上面的例子中,这个DBPAI是PyMySQL。而上述Engine对象则是通过Pool和Dialect来与DBPAI进行交互。
先说Dialect,这个单词的字面意思是“方言”,在这里可以引申为不同的数据库类型。在上面定义engine的url中的mysql实际上就告诉SQLAlchemy要初始化一个支持连接MySQL的Dialect类。
当使用create_engine函数创建Engine对象时,默认使用QueuePool来创建连接池,用户可以指定poolclass参数来选择不同的Pool。当调用Engine的connect()方法时,就会从连接池中获取一个连接对象来执行操作。
4.2 pool_pre_ping的限制
仔细分析不难看出,第三部分提供的方案是有弊端的。在使用从连接池获取的连接进行实际工作前,都需要向数据库服务器发送ping命令,这无疑会增加开销。
所谓的“发送ping命令”是一个概括的说法,有可能是通过连接向服务器发送了
select 1;等简单的命令。
另外,如果服务器出现了性能瓶颈,可能导致ping命令迟迟得不到有效的相应,从而影响程序性能。
因为上述原因,pool_pre_ping方法被称为是“悲观的”。
4.3 乐观方法
上述悲观方法是被动式的——要等到连接不可用了之后,才能通过ping命令检测到。而乐观方法则是主动式的:通过在调用create_engine时设置pool_recycle参数来指定连接持续时间。这个参数的作用是,在达到pool_recycle的时间限制后,连接池将所有的连接回收,并重新进行连接。这样就保证了连接的有效性。
与悲观方法相比,乐观方法减轻了服务器的负担。
4.4 连接池
直观地查看一下连接池的作用:
# 代码由chatGPT生成
from sqlalchemy import create_engine, text
import concurrent.futures
import threading
# 创建连接池引擎
# 这里限制了池中连接的数量为3,且不允许自动增加连接的数量
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test', pool_size=3, max_overflow=0)
# 定义并发函数
# 为了能从数据库服务器查看连接的执行情况,执行了一个休眠命令
def run_query(query_num):
print('线程:', threading.current_thread().native_id, '正在执行...')
with engine.connect() as conn:
ret = conn.execute(text(f'select sleep({query_num})'))
print('线程:', threading.current_thread().native_id, '执行完成')
return ret.one()[0]
# 使用多线程并发执行查询
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
# 线程池中共有10个线程
futures = []
for i in range(10):
futures.append(executor.submit(run_query, 5))
for future in concurrent.futures.as_completed(futures):
print(future.result())
执行上述代码,首先在控制台上打印出类似如下的内容:
线程: 517317 正在执行...
线程: 517318 正在执行...
线程: 517319 正在执行...
线程: 517321 正在执行...
线程: 517322 正在执行...
线程: 517320 正在执行...
线程: 517323 正在执行...
线程: 517325 正在执行...
线程: 517326 正在执行...
线程: 517324 正在执行...
这说明,10个线程已经开始执行。但由于连接池中只有3个连接,此时通过show processlist可以看到有三个连接在执行操作:

结合控制台打印的输出,当有线程执行完成时,数据库中对应连接的Time字段又从0开始计时,这说明改连接被复用了。
当所有的线程执行完成后,上述三个连接消失。
![[vue]vue3.x 组合式API不同写法](https://img-blog.csdnimg.cn/f2427de30d9e4ff6a73423d5b04ac997.png)