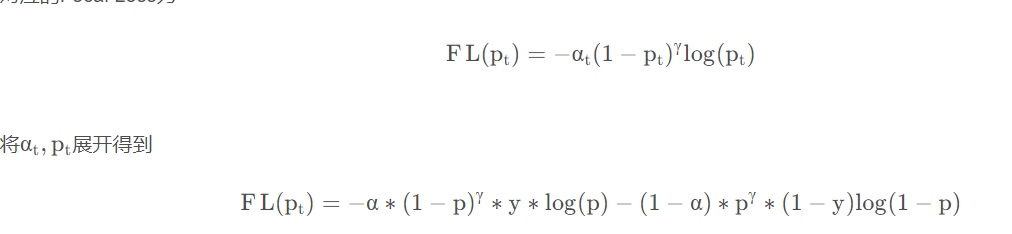目录
1.AXI总线介绍(读2写3)
1.1流量控制
1.2 AXI signals 信号线
1.3重点信号线的介绍
1.4原子操作——让读改写一套操作 永远是一个master对一个slave
1.5AXI BURST Boundary——一个burst不能跨4k boundary,master要保证
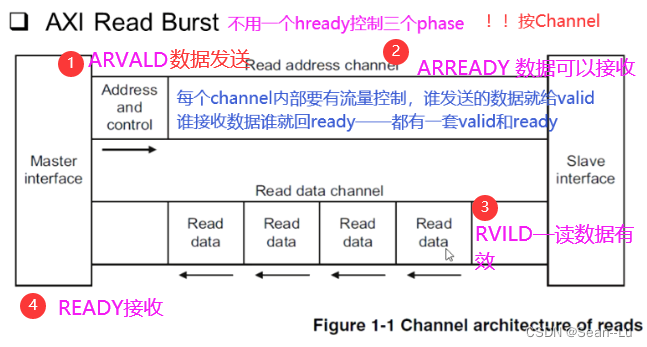
1.6读/写通道是独立的,但读/写操作的内部的2/3个通道内部呢?——读/写操作通道的时序关系
2.AXI的高级特性
2.1为什么AXI能够提高传输效率—CMD Outstanding
2.2 AXI OUT-of-Order —— 因为有WID,请求顺序和回的数据顺序可以不一致
2.3 unaligned Transfers 不对齐的传输
2.4 IP使用的实例
2.5 AXI系统示例
3. AHB/AXI总线对比
4. BUS Arbiter/ BUS Matrix/ BUS NOC
5.AXI效率提升
5.1 效率/latency
5.2AXI的IP设计的考量
6.其他片上总线
1.AXI总线介绍(读2写3)
读——AXI使用基于VALID READY的握手机制数据传输协议,传输源端使用VALID表明地址/控制信号、数据是有效的,目的端使用READY表明自己能够接受信息。
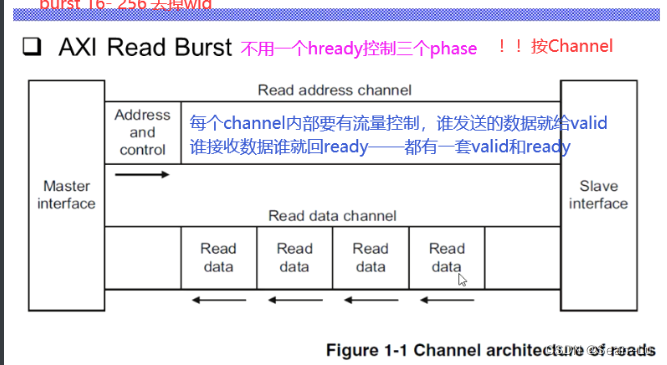
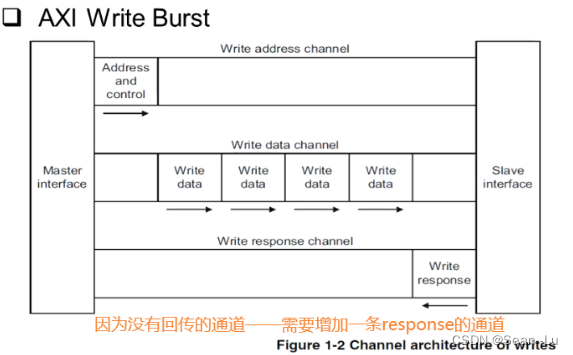
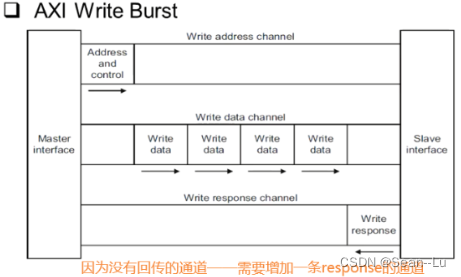
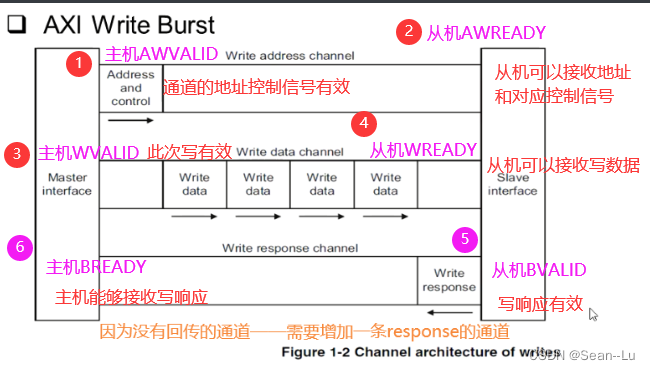
读也存在response——因为会有数据的返回——所以会把response信号绑定在读出的数据中传回 写——因为没有回传的通道——需要增加一条response的通道
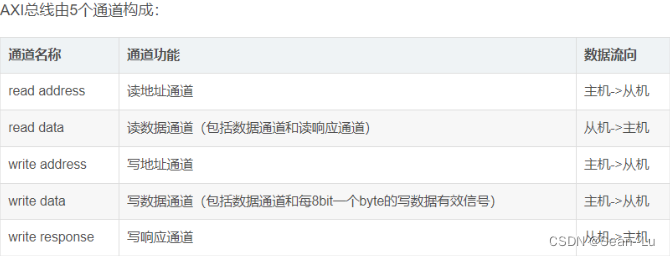

1.1流量控制
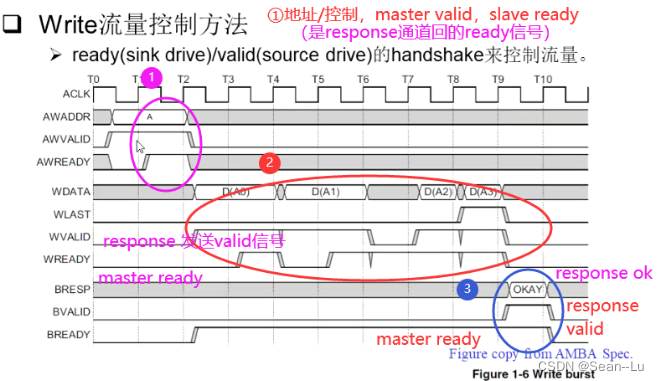
读就是——address channel 配合 data channel ! slave 的ready/valid信号,反馈给master,让master知道传输是否成功。
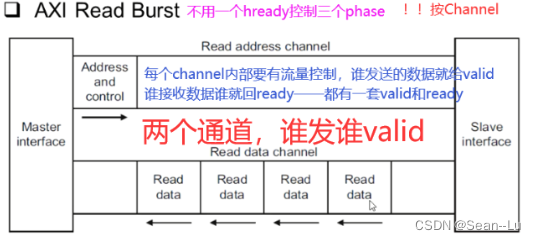

写——三个channel配合
1.2 AXI signals 信号线
1.写 控制/地址通道 信号——理解看中文的!


2.写 数据通道 信号

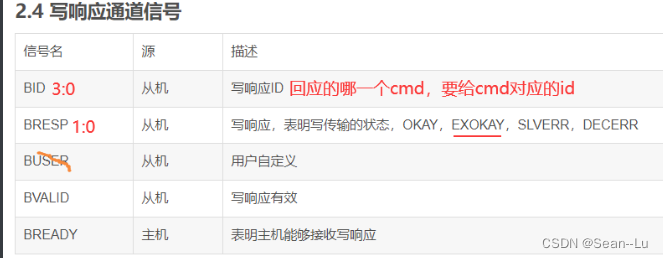
3.写 响应通道 信号
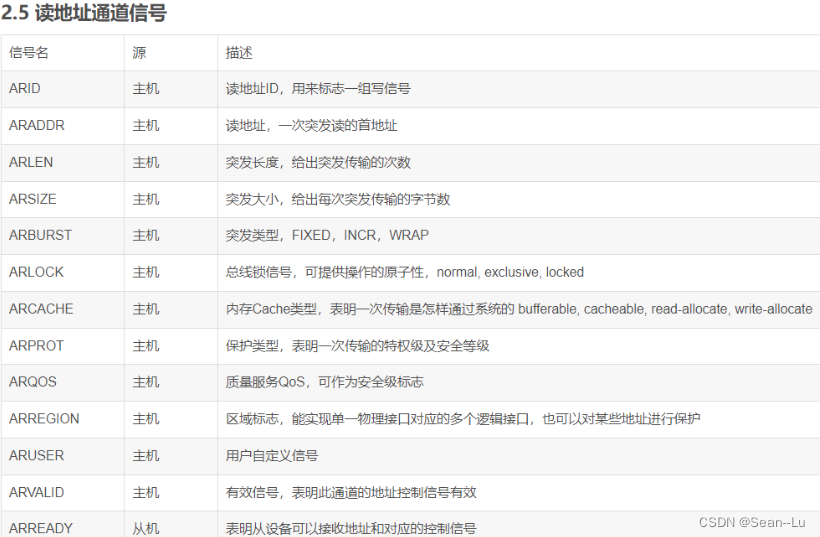
4.读的信号——http://t.csdn.cn/YFrfr——地址通道/数据通道


1.3重点信号线的介绍
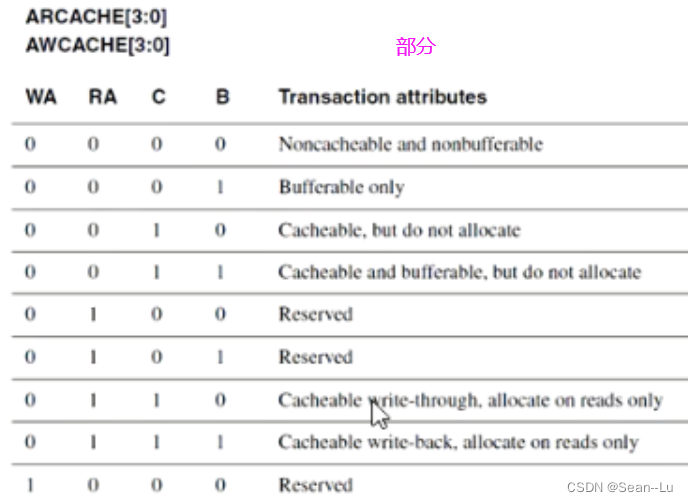
1.Buffer/Cache
cacheable ——进不进cache、bufferable——进不进buffer...


reserved 说明功能有冲突,所以不能用——比如你要allocate,就必须要cache了或buffer了,否则没办法读/写!
2.BRESP[1:0]——写响应
![]()
比如没有这个地址——可以返回decerror 给 master。slave——slave的错误

1.4原子操作——让读改写一套操作 永远是一个master对一个slave
原子操作:一份资源,两份进程需要访问这个资源——其中一个进程先访问-如地址A——判断资源还有没有——有,进行操作read—modify——write——将A地址的有修改,写回去为A没有资源了——等到一个进程用完了——才会再把A中标志位改为资源“有” 所以共享的资源——在系统的某一个地址里面就会存储信息——表明这个资源还存在几份——这样就能保证数据的读改写都是一个进程操作的

Semaphore详解

bus为了支持软件进程的行为——因此定义了两种行为:Locked access 和 Exclusive access ①Locked access——锁定的进程完成了读改写整个流程(lock write - modify - unlock write)——进程才会把bus占有释放掉——别的进程才能抢到锁 ②Exclusive access——不锁死总线——把read-modify-write这个流程的保证工作交给slave——而不是锁死总线——如果slave 在Exclusive状态下,又有别的master想操作slvae,回复rsponse一个操作不成功!
当地址还没有被锁定——地址就会回复exclusive ok——exclusive操作成功! 但是当master访问,A地址已经被上一个slave锁定的时候——此时slave回复ok——表明失败了

比喻总结:两人之间不允许第三者插足——不然都不知道孩子是谁的。为了保证整个读改写操作都是master A操作的,有两种方案——①Locked access的方式,直接锁定总线 ②Exclusive access的方式,让slave访问标志位判断是否已经被占用了,如果是——返回ok表明已经被Exclusive access
read——读
![]()
1.5AXI BURST Boundary——一个burst不能跨4k boundary,master要保证

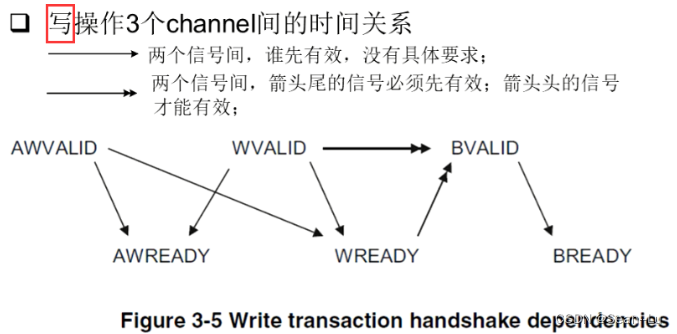
1.6读/写通道是独立的,但读/写操作的内部的2/3个通道内部呢?——读/写操作通道的时序关系
读存在的顺序—ARVALID、ARREADY 均有效—— RVALID才能有效
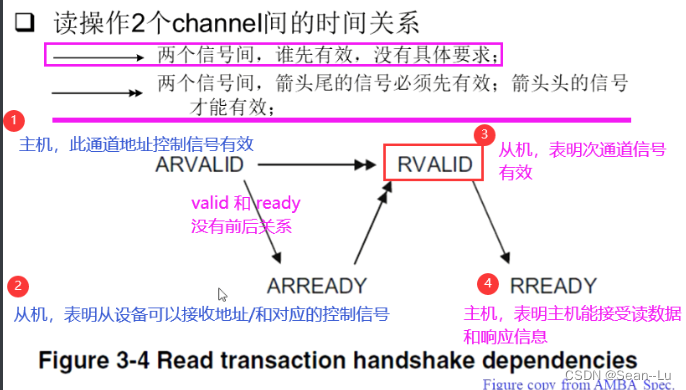
写存在的顺序—data必须写完——才能回BVALID——写响应有效信号 W的 Address channel 和 W的 data channel 是没有关系的——即写数据的地址通道和数据通道之间完全没有关系! 实际应用中还是会先发地址——再发数据
2.AXI的高级特性
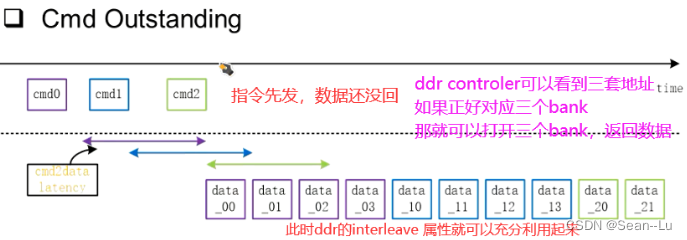
2.1为什么AXI能够提高传输效率—CMD Outstanding
如果只是顺序的指令,那效率是无法提升的
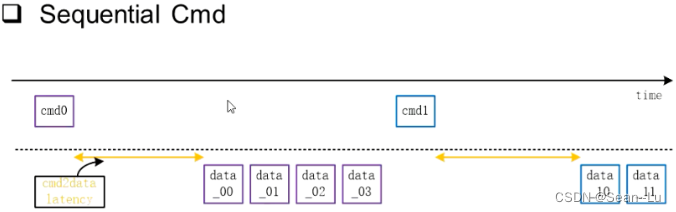
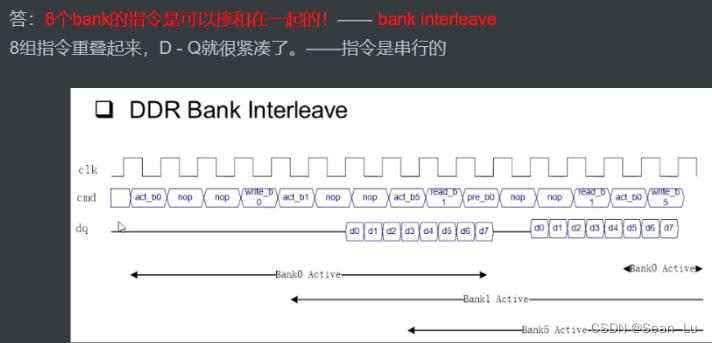
之前学过——DDR是存在bank interleave的!而AXI是能够配合上的——cmd outstanding
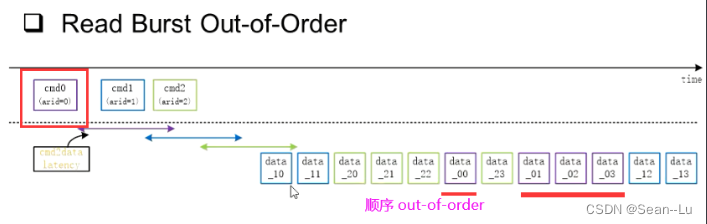
2.2 AXI OUT-of-Order —— 因为有WID,请求顺序和回的数据顺序可以不一致
如果ARID(master 发出来的信号)不同——可以不按顺序回数据——因为回数据的时候有RID(是和ARID对应的!)


2.3 unaligned Transfers 不对齐的传输

2.4 IP使用的实例
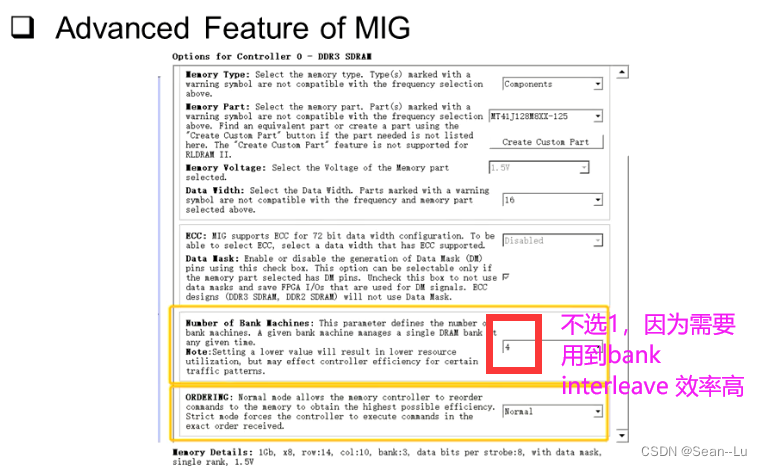
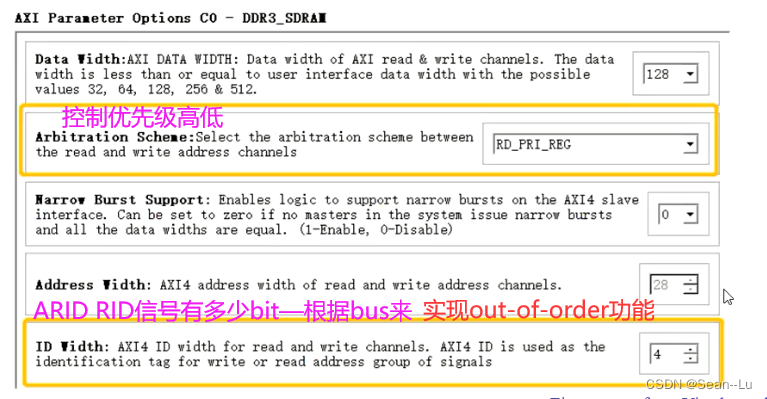
高地址map为row,所以user过来的地址即使在一个row,经过map也可以放到不同的bank,效率提升—— 多使用bank interleave——提升bus效率
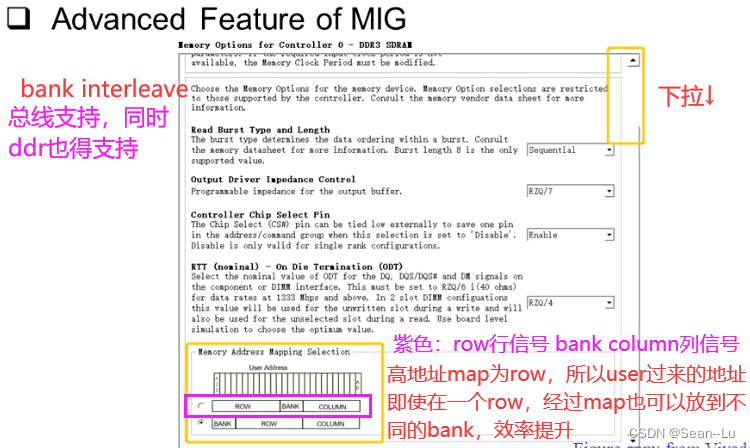
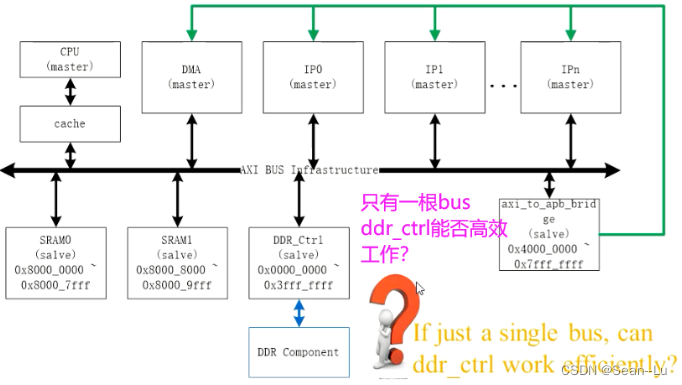
2.5 AXI系统示例
虽然只有一组 读/写 通道,因为可以使用 2.1的CMD Outstanding,这时 读/写 就能看到一堆的控制信号,就能够实现ddr 的 bank interleave —— 意思是,ddr可以同时使用上他的多个bank 读写数据——既然一根AXI bus在通道上就可以发送 许多 连续的读写信号—— ddr就能够配合着进行bank interleave 准备许多的数据
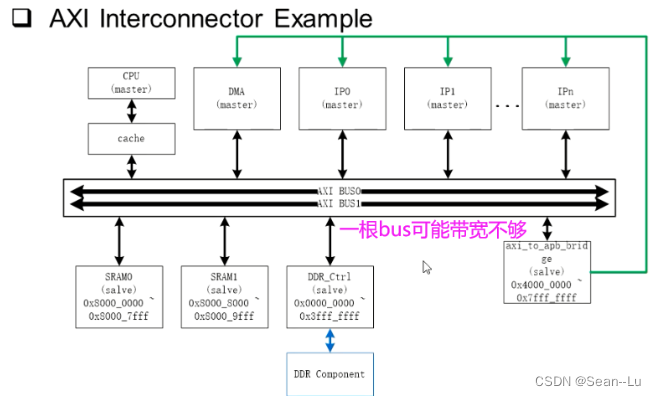
3. AHB/AXI总线对比

①传输效率——AXI可能效率更高
②接口复杂度——AXI可能信号线更多,AHB信号线少一点——所以AXI的gate count接口数量会更大一点——但是对使用者来说——AXI的控制应该是更简单的,更不容易出bug——因为他的操作就是靠valid-ready的hand shank实现
③接口逻辑的频率——理论上AXI更高——order没有严格顺序要求(out of order)——假如timing不过,可以很容易的加寄存器,延迟几拍传输地址/控制信号过来没有关系——但AHB的一个burst中的地址信号需要是连续的——因此AXI很好做pipeline设计,可以做到更高的速度
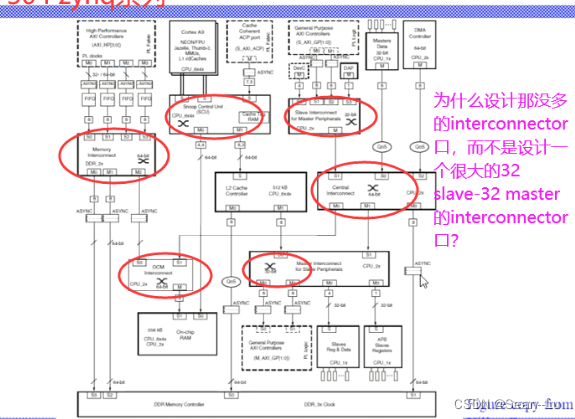
4. BUS Arbiter/ BUS Matrix/ BUS NOC
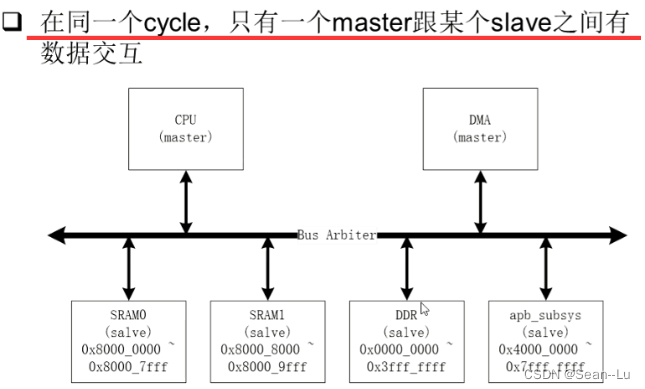
总线上有多通道
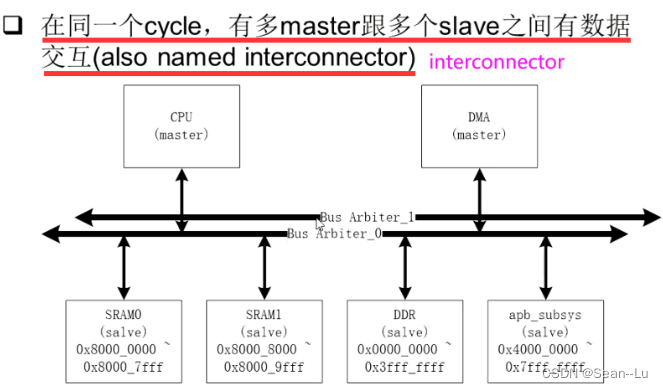
AXI NOC Components

举例——两省之间修高速公路,不会只修一条多车道的公路——是做很多的高速公路网络串起来的——mater分布的位置不同、网络拆开效率才会高、速率不会有瓶颈
5.AXI效率提升
5.1 效率/latency


burst-length不是越长越好——有可能导致real-time的设备死机!



5.2AXI的IP设计的考量




6.其他片上总线