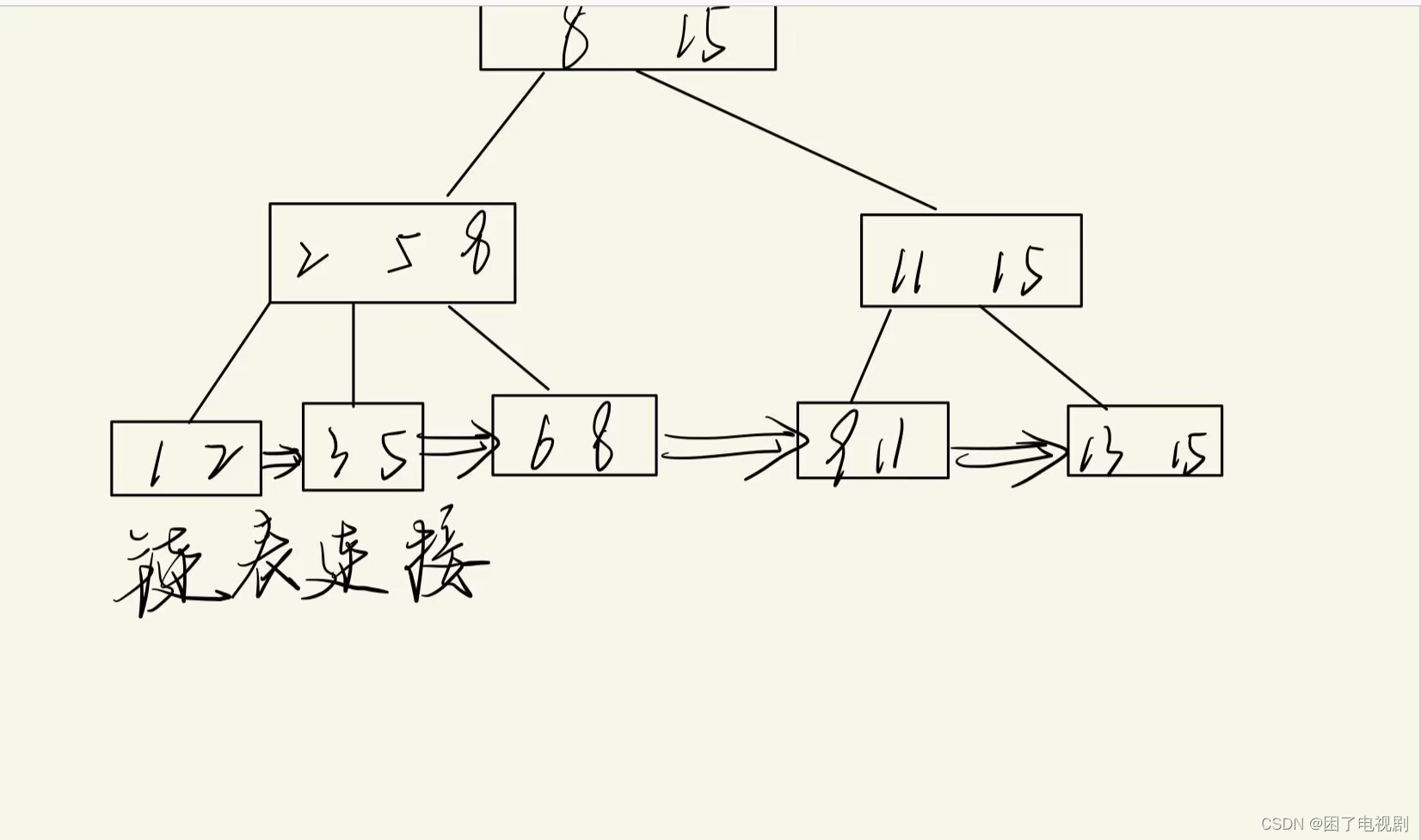
1.信号量机制,读者/写者问题
读者/写者问题分为两种情况:
1.读者和写者互斥,并且不同的读者和写者之间都互斥,一共三个互斥
下面给出伪代码
int m=1;
int mr=1;
int mw=1;
int count=0;
writer()
{
while(1)
{
P(mw);
........
V(mw);
}
}
reader()
{
while(1)
{
p(mr);
if(count==0)
p(mw)
count++;
v(mr)
some thing will be done by reader
p(mr);
count--;
if(count==0)
v(mw)
v(mr)
}
}
但是根据分析,如果一直有源源不断地reader函数被调用,可能会造成writer函数被一直阻塞,以至于饿死。
所以做出如下改进
int m=1;
int mr=1;
int mw=1;
int count=0;
int rw=1;
writer()
{
while(1)
{
P(rw);
P(mw);
some thing will be done by writer
V(mw);
V(rw);
}
}
reader()
{
while(1)
{
P(rw);
P(mr);
if(count==0)
P(mw)
count++;
V(mr)
some thing will be done by reader
P(mr);
count--;
if(count==0)
V(mw);
V(mr);
V(rw);
}
}
2.读者和写者互斥,但是允许最多R个读者同时读取文件
这里我喜欢用信号集来实现也就是用上了Swait和Ssignal。
Swait(P,T,D)当且仅当信号量P的值大于T时分配给此进程D个资源
Ssignal(P,D)给P释放D个资源
给出伪代码如下,这里用SP和SV代表上述的两个函数
int r=R,w=1;
int rw=1;
reader()
{
while(1)
{
SP(r,1,1);
SP(rw,1,0);
..........;
SV(r,1);
}
}
writer()
{
while(1)
{
SP(rw,1,1;r,R,0)
........;
SV(rw,1);
}
}
2.信号量机制,哲学家就餐问题
哲学家就餐问题根据不同的解决算法思路,可以有不同的程序,但是本质上都是考察了对一个进程需要同时两个信号量的情况。
3.操作系统特点:并发性,异步行,共享性,虚拟性的例题
这里主要是想搞一下并发性的例题
4.调度的三个层次
1.作业调度:从外存向内存调入,也就是新创建了一个进程
2.内存调度:从外存向内存调回,把挂起的进程调回等待态
3.进程调度:从内存向CPU调,把此进程的优先级调高
5.调度的算法
1.FCFS,先来先服务(不抢占)
适用情况:作业与进程调度
优缺点:
优点:算法实现简单
缺点:对长作业有利,对短作业不利
2.SJF(不抢占)
算法规则:短作业优先
适用情况:用于作业调度和进程调度
优缺点:
优点:拥有最短的平均等待时间和平均周转时间
缺点:1.必须先知道作业的运行时间 2.对长作业不利,可能会长时间得不到CPU 3.没有考虑作业的紧迫程度之分
3.优先级算法
算法规则:基于作业的紧迫程度,由外部赋予的进程优先级来调度。
适用情况:作业调度和进程调度,也可用于I/O调度
类型:抢占式(可抢占优先级调度算法)和非抢占式(非抢占优先级调度算法)
优先级的类型:
静态优先级:创建进程时确定,在整个运行期间不变
动态优先级:创建进程时先确定一个优先级,然后动态的调整优先级
优缺点:
优点:用于优先级区分紧急程度,运用于实时的OS
缺点:可能导致优先级低的进程总是拿不到CPU
4.时间片轮转算法(抢占)
算法规则:公平的,轮流的为各个进程分配时间片,如果一个时间片结束了进程尚未完成则抢占他的CPU
适用情况:进程调度
优缺点:
优点:公平,响应快,用于分时操作系统
缺点:不能区分任务的紧急程度,需要进程切换,消耗较大。
5.高响应比的优先算法(不抢占)
算法规则:在每次调度前先计算各个作业或者进程的响应比,响应比做高的作业或者进程获得服务
响应比=(等待时间+要求服务时间)/要求服务时间
=响应时间/要求服务时间
适用情况:作业调度和进程调度
优缺点:
优点:总和考虑了等待时间和运行时间,较好的实现了折中,不会出现饥饿现象。
缺点:每次调度前都要计算响应比,会增加系统的开销。
6.多级反馈队列调度算法(抢占)
算法规则:
1.设置多个就绪队列,各级队列优先级从高到低,时间片从小到大。每个队列的时间片是固定的,如果某个进程在响应的时间片内没能结束作业,那么则调入下一级队列中等待。
2.每个队列默认采用FCFS的调度算法,也可根据别的算法来执行
3.按照队列优先级调度,只有当1到i-1队列均空时,才会调度第i队列中的进程
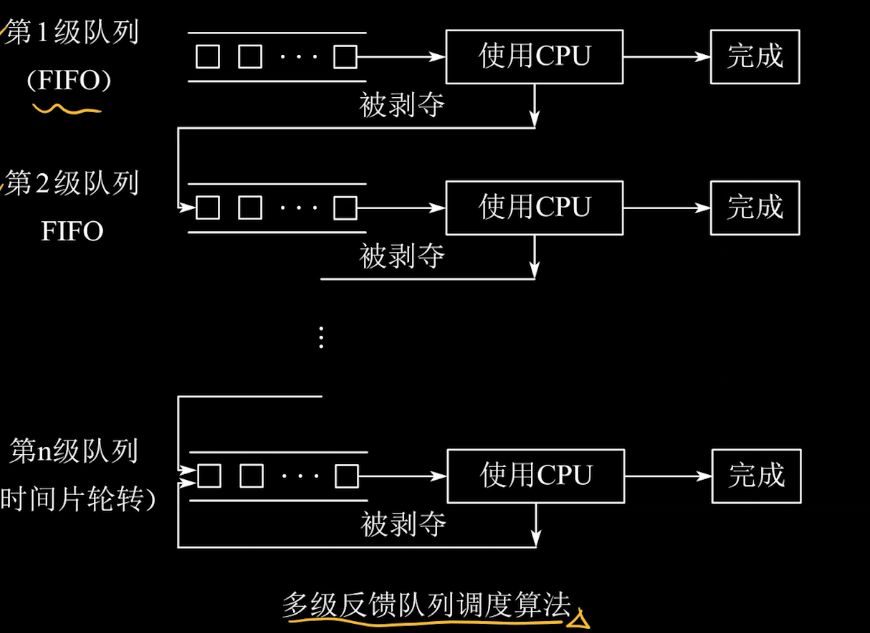
使用情况:进程调度
优缺点:
优点:用优先级区分了紧急程度,用于实时OS
缺点:可能造成饥饿
可能引起调度的原因:
1.进程运行结束
2.进入阻塞状态
3.时间片用完
4.有更高优先级的进程进入就绪队列
6.死锁,死锁的预防,避免,检测,处理
1.基本概念
死锁:各个进程相互等待对方的资源,各个进程都阻塞,无法向前推进。
死锁的处理一是不允许死锁发生,分为静态策略(预防死锁)和动态策略(避免死锁),处理二是允许死锁发生,但是会检测出死锁状况然后采用策略解除
死锁与饥饿的区别:死锁是两个及以上的进程一直处于阻塞态,饥饿是一个进程一直处于就绪态
2.产生死锁的必要条件
!死锁产生的原因根本上就是资源竞争和推进顺序不合理
互斥条件:对必须互斥实用的资源的争抢才会导致死锁
请求和保持条件:进程已经有一个资源保持,但又提出了新的资源请求并且此资源被其他进程占有,此时请求被阻塞并且对已有资源保持不放。
循环等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源被下一个进程请求
不可抢占条件:进程在未使用完之前,不能由其他进程强行的剥夺,只能主动释放
3.预防死锁
破坏四个死锁条件中的一个或几个
破坏互斥条件:如把互斥资源改造成共享资源,SPOOLing技术可以把互斥设备从逻辑上变成共享设备
缺点:不是所有资源都可以共享,很多情况下无法破坏互斥条件
破坏不可抢占条件:当某个进程请求新资源得不到满足,立即释放其所保持的所有资源
缺点:
1.实现较为复杂2.
破坏请求和保持条件:在运行前一次请求所有资源,一旦投入运行,资源不可剥夺也不请求其他资源
缺点:可能会造成资源浪费,资源利用率低,情况重复出现会导致进程饥饿
破坏循环等待条件:对系统资源线性排序,规定每个进程必须按顺序请求资源且一次申请完毕所有资源
缺点:

4.避免死锁:
安全状态:可以找到一个安全序列,使得系统按照这种序列分配资源,则每个进程都能顺利完成,只要能找出一个安全序列系统就是安全状态。
安全状态变成了不安全状态:分配了某资源后,系统不存在安全序列了,有些进程可能无法顺利进行下去
银行家算法(重点)
核心思想:系统提出资源申请时,先预判是否会进入不安全状态,如果会,则拒绝此请求,让此进程阻塞。
银行家算法步骤如下
Max矩阵:每个进程最大需要的资源数
Allocation:当前进程已有资源数
Need:当前进程所需资源数,MAX-ALLOCATION=NEED
Available:当前系统可用资源
request:申请,代表某一进程对某个资源的请求数量

第四步的安全性算法也就是按照安全序列的要求来寻找的。
安全性算法步骤如下


5.死锁的检测与解除
死锁定理:某时刻的资源分配图不可简化则判断为死锁
简化:1.找到不孤立也不阻塞的进程点,去掉和他相连的所有边。2.把释放了资源就能让别人不阻塞的阻塞点也消去和其连的所有边,如果最后整个图没有边了,那么这个图就是可简化的
1.死锁检测算法
资源分配图:两种节点(进程节点,资源节点)两种边(资源分配边,资源请求边)
2.死锁解除算法
资源剥夺法:将死锁进程的资源剥夺分配给其他进程
撤销进程法:强制撤销死锁进程
进程回退法:让一个或者多个进程回退到可以避免死锁的地步
6.内存管理
内存管理的定义:操作系统对内存的划分和动态分配就是内存管理的概念。
内部碎片:以分配出去但是没被利用的内存空间
外部碎片:由于过小而无法分配的内存空闲区域
1.内存管理的功能
内存空间的分配和回收:OS完成对贮存的分配和回收
地址转换:逻辑地址转换为物理地址
内存空间的扩充:利用虚拟存储计数从逻辑上扩充内存
存储保护:保证各道作业在各自的存储空间内运行,互不干扰
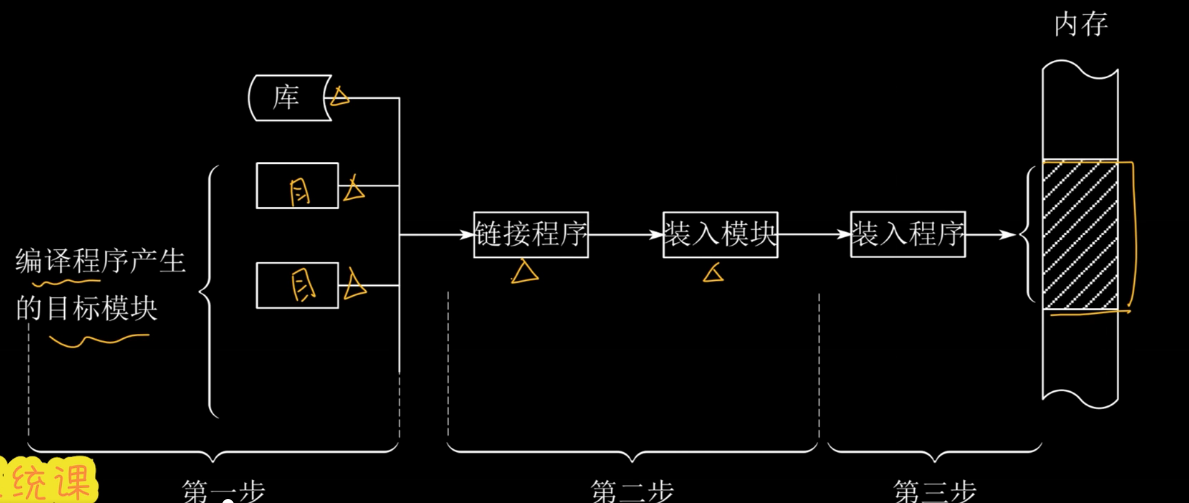
2.程序的装入与链接
编译:由编译程序将用户源代码编译为若干目标模块
链接:由链接程序将编译后的一组目标模块和所需的库函数链接,形成完整的装入模块(形成逻辑地址)
装入:装入程序把装入模块装入内存运行(形成物理地址)
图解如下:
3.程序链接的方式
静态链接:运行前就把目标模块和所需的库函数链接成一个可执行程序
装入时动态链接:编译后所得的一组目标模块在装入时,边装入边链接
运行时动态链接:在运行过程中,需要某些模块就链接
4.装入内存的方式
绝对装入:只适用于单道环境,编译时就知道程序程序装入的具体内存地址
可重定位装入:多个目标模块的起始地址为0,装入时采用程序内相对地址进行地址的动态变换,一次性完成,运行时不允许更改。
动态运行时装入:装入内存后不立即地址变换,而是等到程序运行时才进行的,需要重定位寄存器的支持。
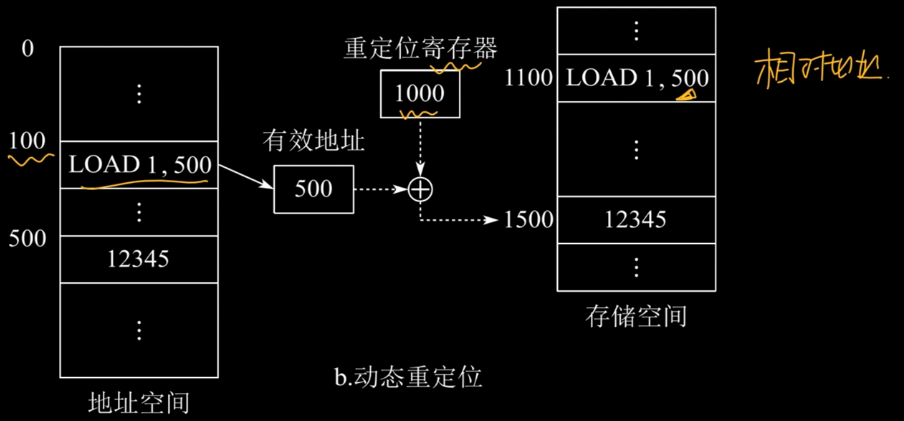
5.覆盖与交换
覆盖技术:将程序分为多个段,常用的段常驻内存,不常用的段需要时调入内存。
也就是说,我们把内存分为固定区和覆盖区,将必须的模块放在固定区,把其他的模块对应到不同的覆盖区上。如下图所示,BC不可同时
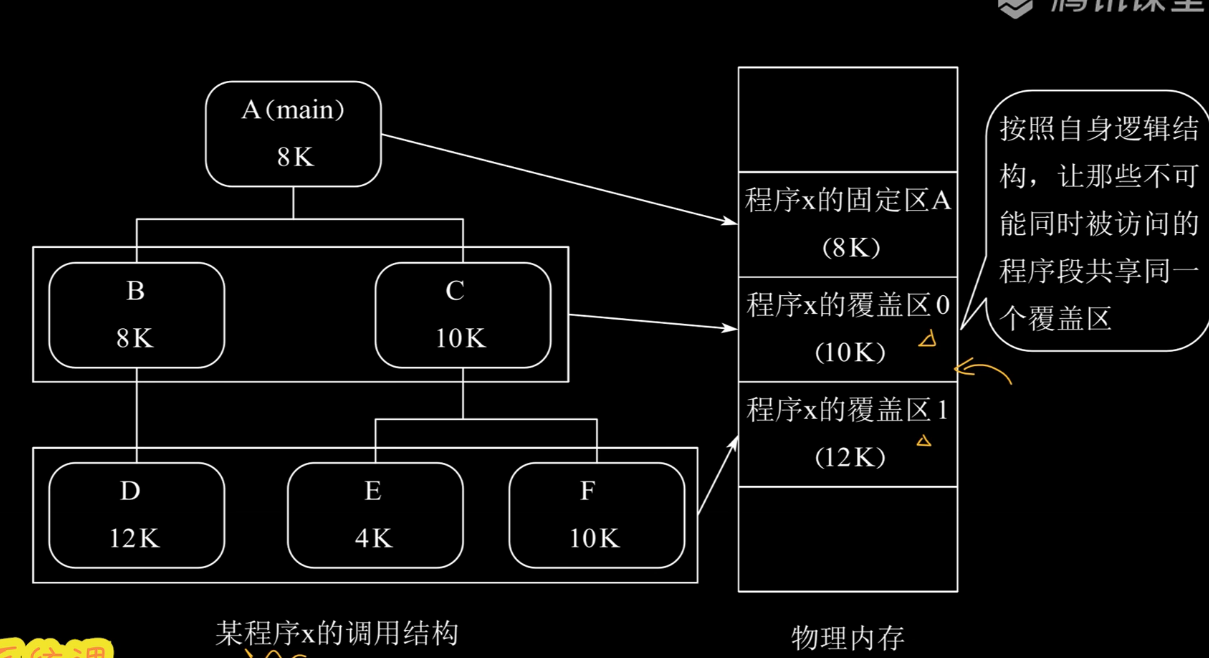
对换技术:把处于等待状态的进程或者被CPU剥夺运行权限的进程从内存移动到外存,称为换出,把准备好竞争CPU的进程从外存移动到内存则为换入。
暂时换出外存等待的进程状态为挂起态,挂起态又可细分为(就绪挂起和阻塞挂起)
交换技术通常把磁盘空间分为文件区和对换区。
文件区:主要用于存放文件,追求存储空间的利用率,因此对文件空间的管理采用离散分配的方式。
对换区:主要用于存放被换出的进程数据,由于对换区的速度影响到整体速度,所以对换区追求换入换出速度,采用连续分配方式。
对换通常发生的时机:在许多程序运行且内存不足时执行,系统负有降低则暂停
对换可以优先换出:阻塞进程,优先级较低进程
6.连续分配管理方式
- 单一连续分配
此方式下,内存分为:系统区和用户区。
系统区:低地址部分,用于存放操作系统
用户区:用于存放用户进程相关数据(用户区只能有一个用户程序,独占整个空间)
优点:实现简单,无外部碎片,可以采用覆盖技术拓展内存,不一定需要采取内存保护
缺点:只能用于单用户,单任务的操作系统,有内部碎片,存储器利用率极低。
- 固定分区分配
最简单的多道程序存储管理方式,将用户内存空间划分为若干个固定大小的区域,每个分区装入一道作业。
大小相等分配方式:将整个用户区分成同一大小
大小不等分配方式:将整个用户区分为不同大小,更为灵活。

优点:简单,无外部碎片
缺点:程序过大时无分区满足要求,需要采用其他覆盖技术会降低性能,有内部碎片,内存利用率低
- 动态分区分配
不预先划分分区,而是在进程装入内存时,根据进程的大小动态的建立分区 ,无论是分区的大小还是数目都可变
通常有两种方式:空闲分区表,空闲分区链
空闲分区表:每个空闲分区对应一个表项,包含分区号,分区大小等
空闲分区链:每个分区的其实部分和末尾部分分别设置前向指针和后向指正。
7.动态分区的分配算法
1.首次适应算法FF
以地址递增形成次序链接,分配内存时顺序查找,找到大小满足的第一个分区
优点:算法开销小,回收分区后不需要重新排序
缺点:低地址部分有很多碎片
2.最佳适应算法BF
以容量递增的方式形成分区链,每次找到第一个能满足要求的空闲分区
注意!每次分完后,空闲分区的大小会改变,这时候我们要求重新排序。
优点:保留大分区给大进程使用
缺点:会产生很多外部碎片
3.最坏适应算法WF
以容量递减次序形成分区链,每次找到第一个能满足要求的空闲分区
优点:可以减少难以利用的碎片
缺点:不利于大进程使用,会造成后续大进程到达时无内存分区可用。
4.临近适应算法 NF
按照地址增加形成分区链,每次查找时,从上次查找结束的位置继续查找。
优点:算法开销小
缺点:会缺少大分区给大进程使用
8.分页存储管理方式
基本概念
页面和页框,页表,页表项,页号等等
页(页面):将用户进程的地址空间分为与页框大小相等的一个个区域,也就是把进程分成了好多页面
页框(物理块):将内存空间分成一个个大小相等的分区(页框号或物理块号从0开始)
页表:记录每个作业各页映射到哪个物理块,形成的页面映射表,简称页表。
页表项长度:页表的列长度,页号数量
页号:页表中每一行都有一个号,就是页号了
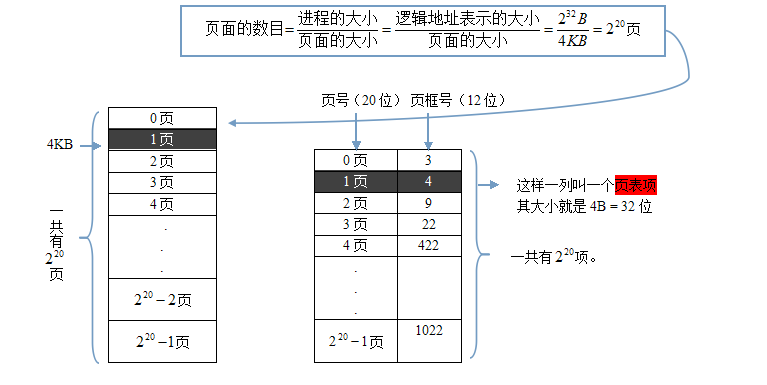
问题:如何运行一个作业?
连续方式下
PCB记录内存首地址,根据该地址顺序取指令执行即可。
离散方式下
页表记录作业的各页分别占用了内存的哪些块; pcb则记录页表在内存的地址——进程构造时伴随着构造页表,该核心信息也要放在内存中供访问;
地址结构
可见下图,大小为232的地址分为页号和页内偏移量两个部分。页内偏移量位数和页面大小挂钩

问题:连续方式下,每条指令用基地址+偏移量即可找到其物理存放的地址。离散方式呢?
离散方式下地址映射(地址计算)的过程
若要执行某作业的一条指令,其相对地址是24B (设10B一页,页表如右表),其物理地址到底是多少呢?
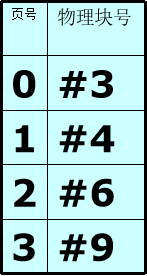
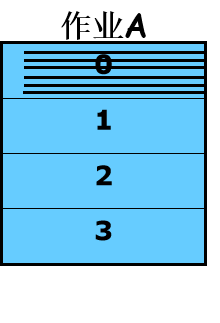
第一步:计算页号,页号=逻辑地址/页面长度 24/10取整得2号页面
第二步:计算偏移量,偏移量=逻辑地址%页面长度 得4B
第三步:查页表找页面对应的块(2号页保存在6号物理块)
第四步:找物理块6,向下偏移4B。
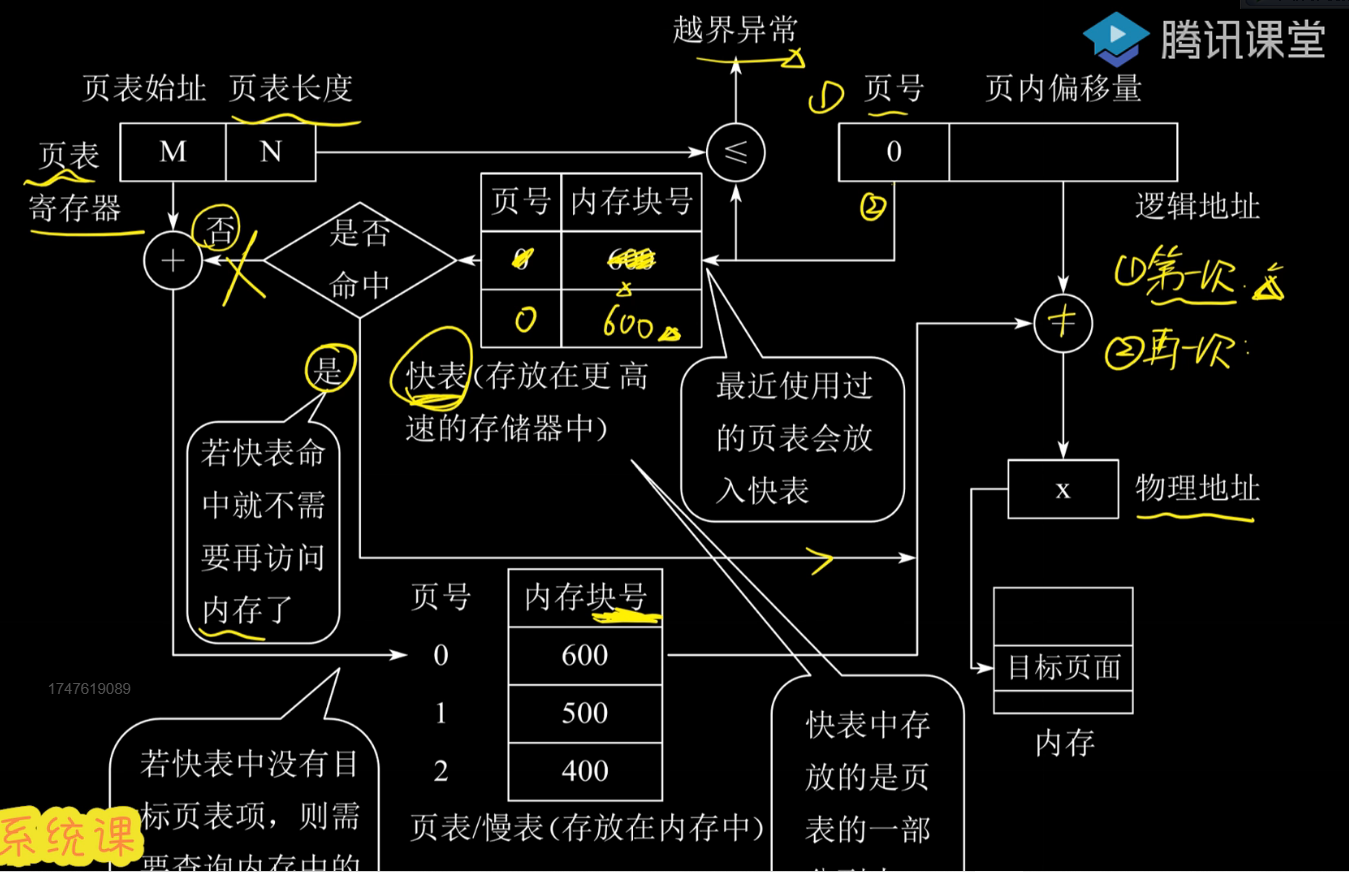
地址变换机构
借助页表来实现把逻辑地址转换为物理地址
实现原理如下图
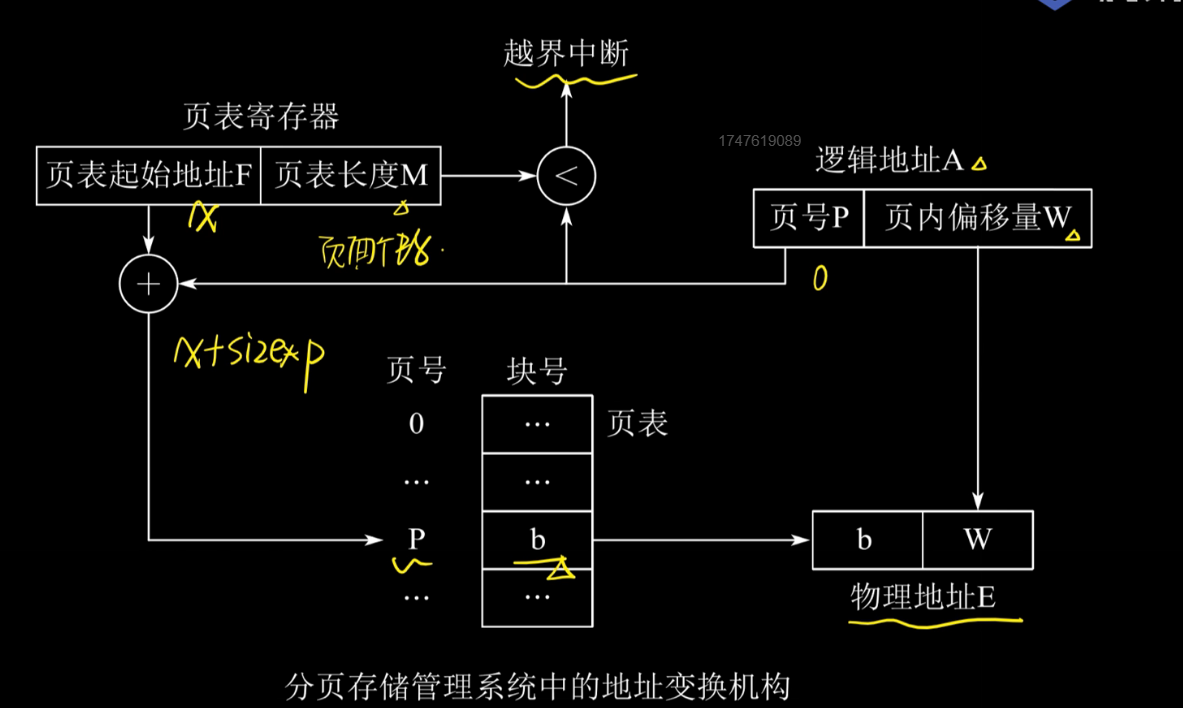
变换过程计算举例:设页面大小为L,逻辑地址A到物理地址E的变换过程如下
第一步:计算页号P和页内偏移量W
第二步:比较P和页表长度M,如果P>M则越界中断,否则继续执行
第三部:页表中页号P的页表项地址=页表起始地址F+页号P*页表项长度,取出页表项内容为b(物理块号),
第四步:计算E=b*L+W,访问物理地址为E的内存
具有快表的地址变换机构
快表:就是在上述过程的第三步找到了物理块号之后放在了chach里,以后第三步的时候就在快表中先找找
二级页表
逻辑地址改变为:(一级页号,二级页号,页内偏移量)
其实这个也简单,就是觉得一个页表太长了,我就把页表再分成好几块,然后把每一块的内存块号记住生成一个顶级页表,找的时候就先根据顶级页表找二级页表所在的内存块号,然后根据二级页表地址找到最终的内存块号,最终访问地址还是=b*L+W
例题
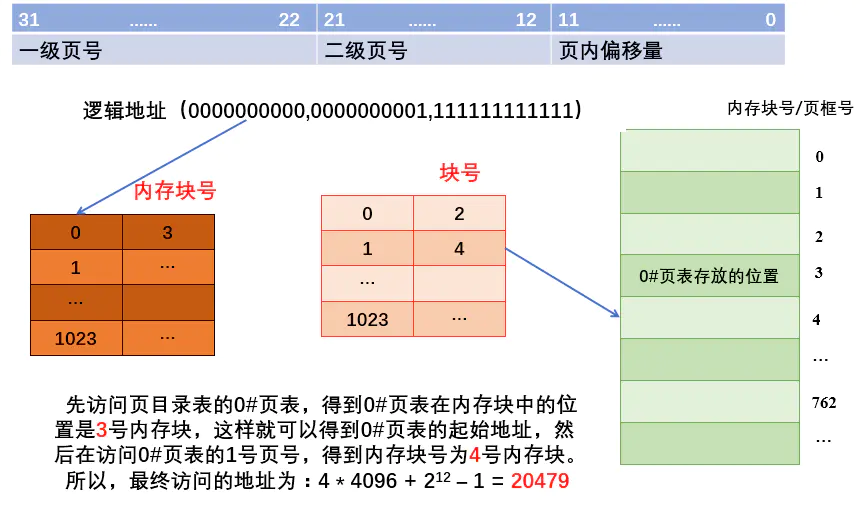
注意,二级页表的思想可以用在多级页表上,具体需要多少级,相关的是页面大小和页表项长度 级数=页表项长度/页面大小(向上取整)
9.分段存储管理方式
作业分成若干段,各段可离散放入内存,段内仍连续存放。
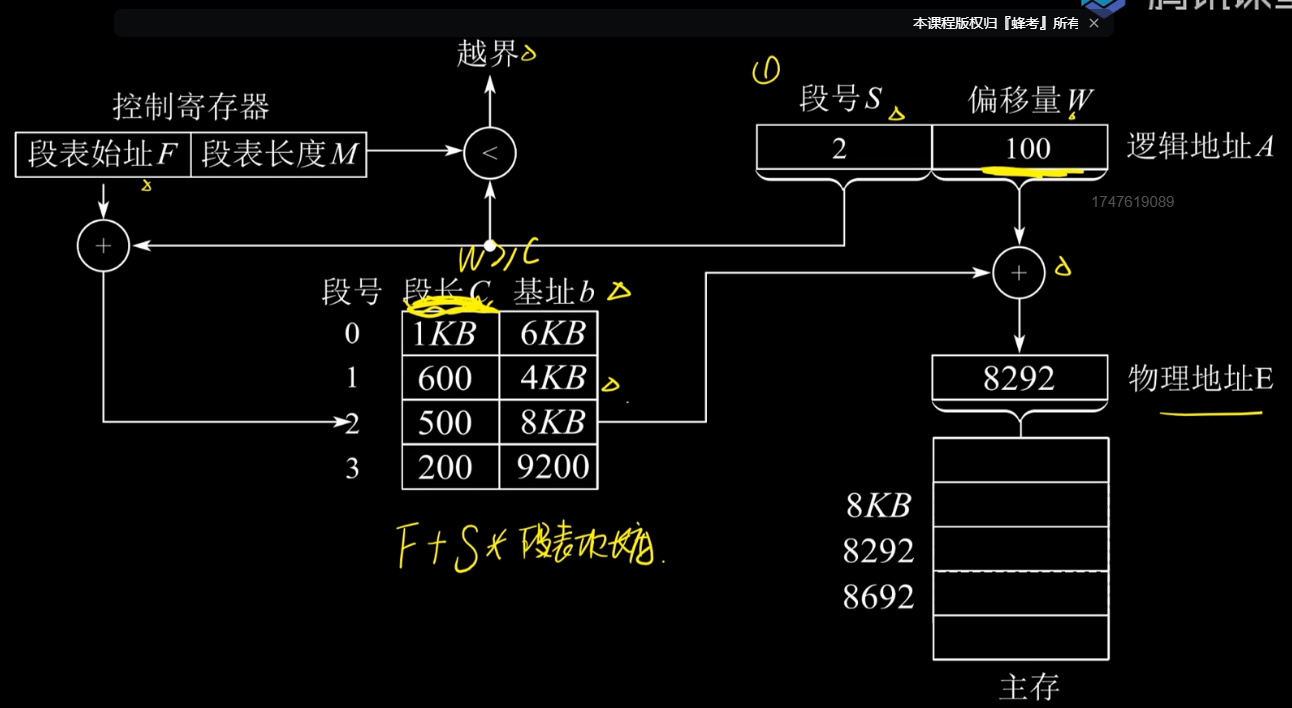
逻辑地址结构与段的概念

如上图所写
段号:每个进程可以被分成216段
段内偏移量:段的最大长度为216
段表的一行:对应了进程的一段,记录此段在内存中的基址和长度。如下图所示
 段表项长度:基址位数+段长位数
段表项长度:基址位数+段长位数
!区别与页表项的长度=页号位数
物理地址=基址+段长
地址变换机构
10.段页式存储管理方式
基本原理
将用户程序分成若干段,并为每个段赋予一个段名。
把每个段分成若干页
地址结构包括段号、段内页号和页内地址三部分

11.关于三种离散式内存管理方式的对比与分析
从存储的角度来看,分段和分页的离散形式是不同的,分页是将整个进程的若干块给离散的分布在了内存中,这种块的大小成为页面大小,通常是受制于页框大小的。而分段则是先将进程给分了好多段,然后每一段再按照内存连续分配管理方式来分配。段页式显然是针对大程序的,我们需要先将其分段然后再分页。
从访存的角度来看,再从访存的角度来看,分段和分页都是两次访存,段页式由于要先根据段号访问段表,再根据页号访问页表,然后根据具体的物理地址去访问物理地址,需要三次访存。
从装入内存的角度来看,目前的管理都存在一次性装入的特点,也就是说内存的空间还是有较大的压力,而对于一些长时间CPU不需要的页我们完全可以将其先置换到外存,需要时再将其调入。这就是接下来虚拟内存管理需要解决的问题:页面置换,页面调入。实现基于内存分页式管理方式的请求分页式管理方式
7.虚拟内存管理
虚拟内存的最大容量:地址结构来决定
虚拟内存的实际容量:内存+外存容量之和
1.虚拟存储器的三个特征
- 多次性:作业可以分多次装入内存
- 对换性:作业运行时无需常驻内存,可以换进换出
- 虚拟性:从逻辑上拓展了内存容量,使用户看到的内存容量远大于实际内存容量
2.虚拟内存技术的实现
- 请求分页式管理方式
请求分页系统建立在分页存储管理系统之上,为了支持虚拟存储器功能添加了请求调页和页面置换功能
注:请求调页是指在进程运行时发现要用的页面不在内存里,从外存调入的过程。页面置换是发现内存空间不够用后,把暂时不用的页面置换出去的功能
页表项的区别

缺页中断机构
请求分页系统当前要访问的页不在内存里,那么就发出一个缺页中断,然后将所缺的页调入内存,此时缺页的进程处于阻塞态。调入后如果有空闲内存快则装入,否则就淘汰某页(如果此淘汰页被修改过,需要将其放入外存)
3.页面置换算法
最佳置换算法 OPT
算法思想:选择以后永不使用或者较长时间不再访问的页面置换,保证最低缺页率
如图:
前三步发生中断,但是并未发生置换,从第4步开始,2想要调入,发现7应该换出,第5步发现0就在内存里,所以无操作。以此类推
总共发生9次缺页中断和6次页面置换
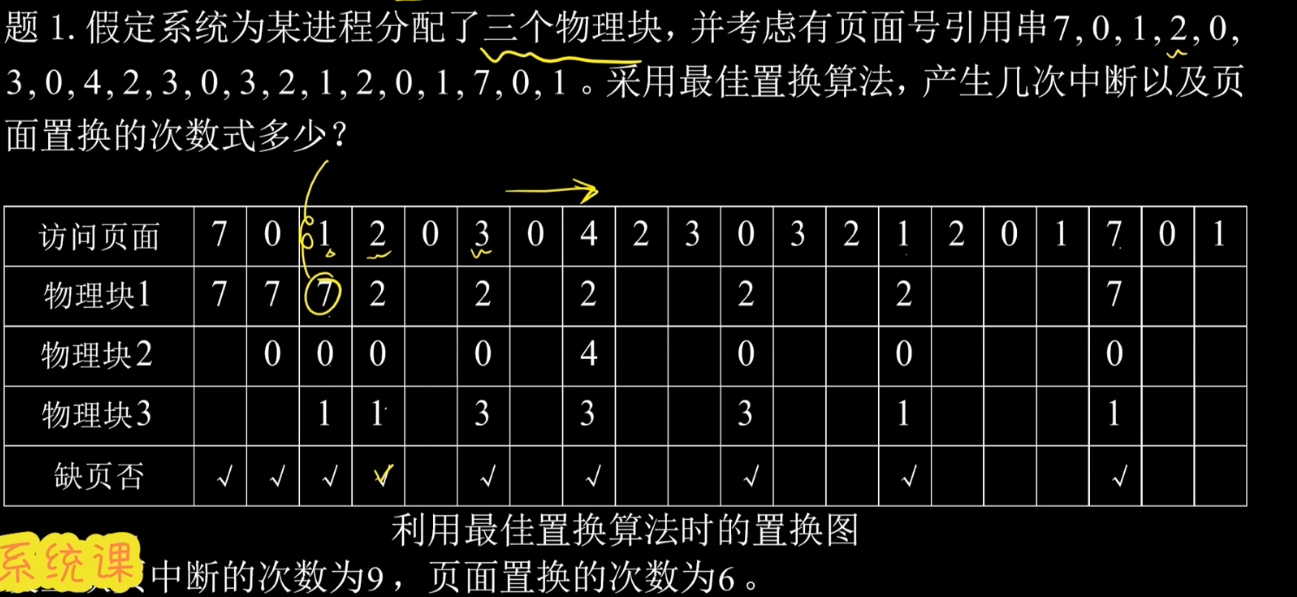
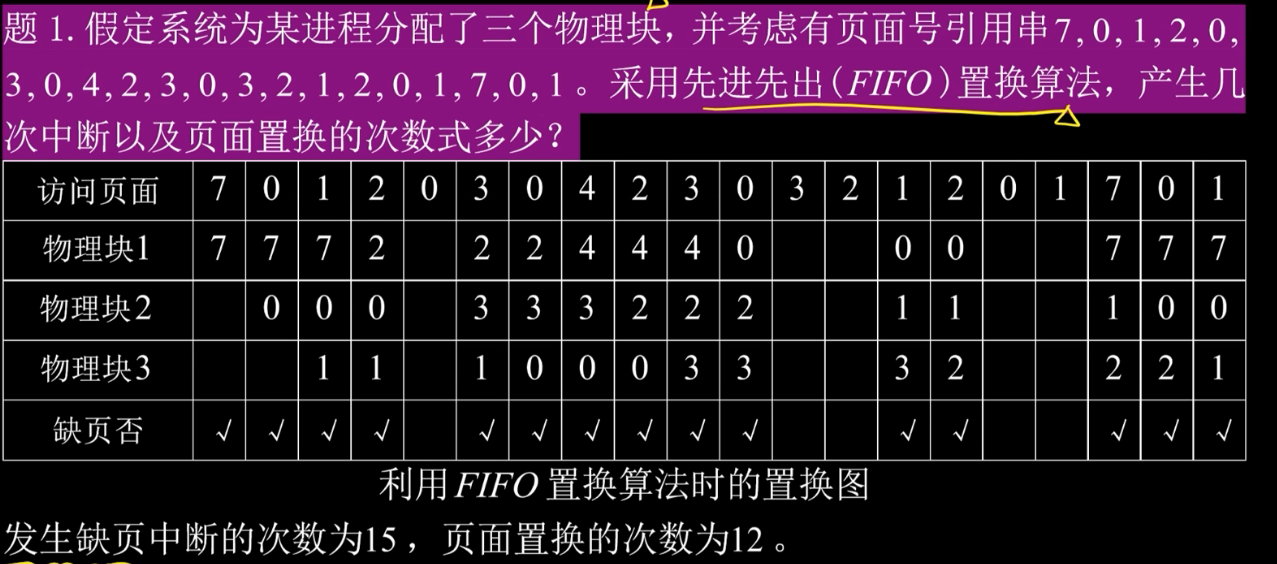
先进先出置换算法FIFO
算法思想:将当前物理块中,驻留最久的换走
但是会发生belady异常:物理块多了反而中断增加了
最近最久未使用置换算法LRU
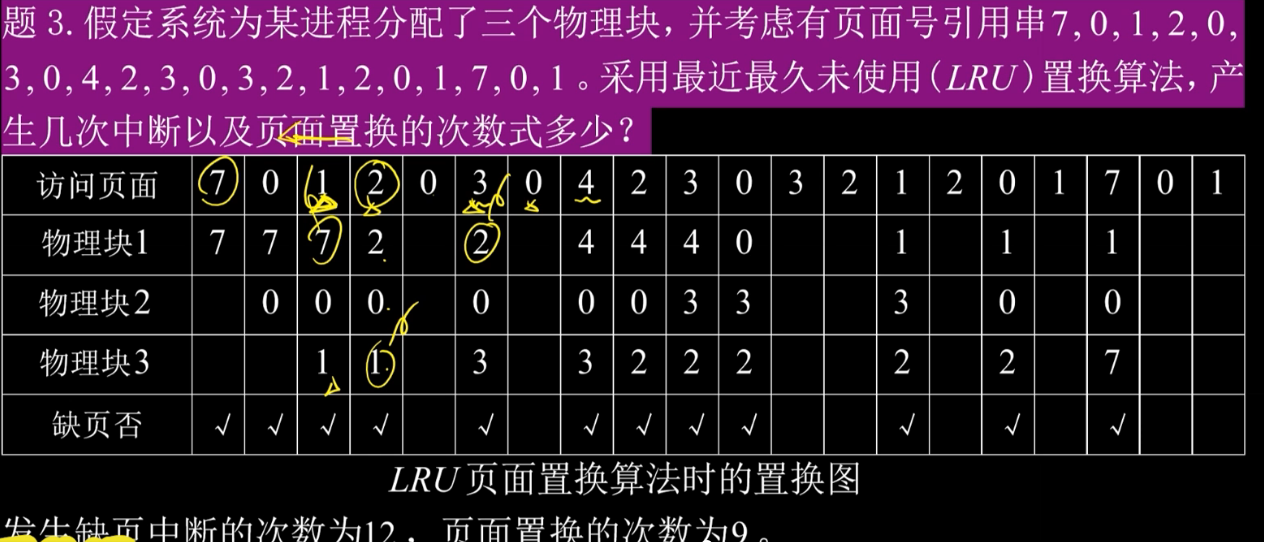
算法思想:注意和FIFO区分,这个看的是当前块里谁最后一次被使用的时间最久远谁就被换出,而不是谁先进来谁换出。
时钟置换算法
当内存中无对应数据时访问位为0即可置换之后再变换访问位,访问位为1不置换仍然变换访问位然后指针下移。当内存中有对应数据时,访问位变换,指针下移。
每访问一次,无论是否发生置换,访问位都要变换。
可以参考下图

参考博客
4.页面分配策略
1.驻留集(给进程分配的物理块的集合)大小
驻留集小,导致缺页,系统处理缺页使得系统开销增大,驻留集大,导致多道程序并发性下降,资源利用率降低。
策略如下
- 固定分配局部置换:为每个进程分配一定运行期间不可改变的物理块
- 可变分配全局置换:为每个进程分配一定物理块,同时操作系统自身也持有一个空闲物理块队列
- 可变分配局部置换:为每个进程分配一定物理块,发生缺页时可以从分配的物理块选出一页换出
2.调入页面的时机
1.预调页策略:一次调入若干相邻的页
2.请求调页策略:在缺页时发出请求,由系统将所需页面调入
3.从何处调入页面
三种情况
1.系统拥有足够的对换区空间:可以全部从对换区调入所需页面,提高调页速度
2.系统缺少足够的对换区空间:不会被修改的文件从文件区调入,换出时不必重写到磁盘,以后再用的时候直接再从文件区调入,对于可能被修改的部分,从对换区调入。
3.UNIX方式:与进程有关的文件放在文件区。凡是未运行的页面都从文件区调入,曾经运行过的但是又被换出的页面从对换区调入。
4.抖动
抖动:页面置换过程中,刚换出的页面又换入主存,刚换入的又马上换出,这种频繁的调度行为叫做抖动。
原因:频繁访问的页面数目高于可用的物理块数目
5.工作集
某段时间间隔内,工作进程访问的页面的集合。
一般来说,驻留集不得小于工作集,否则会发生抖动。
8.文件管理
文件:以计算机硬盘为载体存储在计算机上的信息集合,是IO的基本单位
1.文件的逻辑结构
逻辑结构:从用户观点看到的文件的组织方式
物理结构:从实现观点看到的文件的存储组织形式
这里逻辑结构可以分为无结构文件和有结构文件
无结构文件(流式文件):字节为单位,利用读写指针依次访问。系统对该类文件不需格式处理。
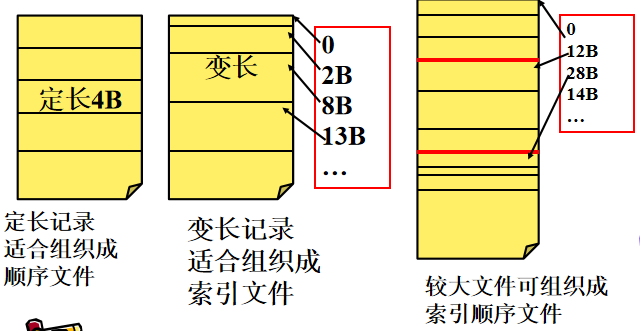
有结构文件(记录式文件):按照记录的组织形式可以分为顺序文件,索引文件,索引顺序文件。按照记录方式又可分为定长记录和变长记录。
顺序文件:系统需按该类型记录“长度”,通常定长。如下为两种记录的排列方式
串结构:按记录形成的时间顺序串行排序。记录顺序与关键字无关;从头检索,顺序查找要找的记录,定长的计算相对快。
顺序结构:按关键字排序。可用折半查找、插值查找、跳步查找等算法提高效率
索引文件:建立一张索引表,加快索引速度,索引表本身是定长记录的顺序文件
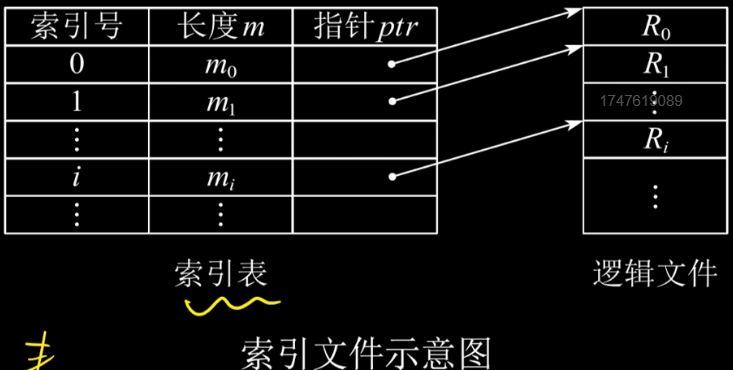
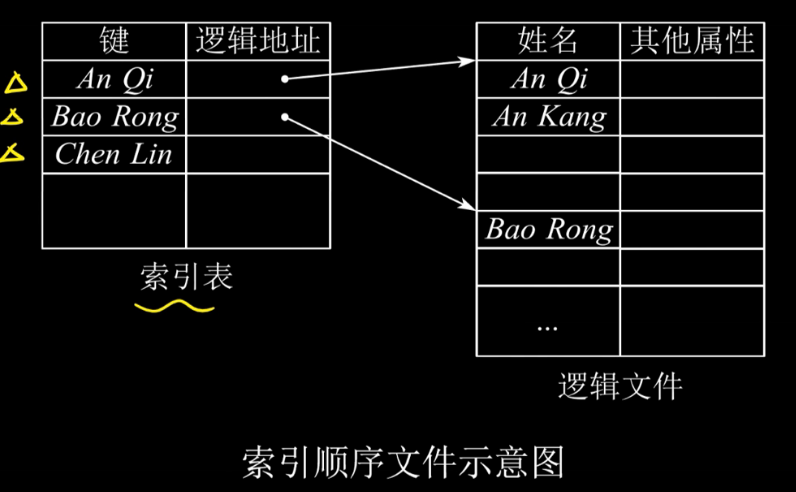
索引顺序文件:建索引表,记录每组记录的第一个记录位置。值得注意的是,这里的索引不再是对应了一个记录,而是对应了一组记录,也就是把顺序文件的一组记录看成一个记录,然后利用索引文件的方式为多个顺序文件建立索引表。
例题

学过算法竞赛的同学都知道分块这个东西,其实这个就是用的分块的思想。他把总共的10000个数据按照根号分块,每块100个,块内再自治来提高效率。
那么显然这题就是100/2+100/2=100。至于那个5000,他的意思是10000个记录在不分块的情况下查找一条记录的期望查找次数是5000.
2.文件目录
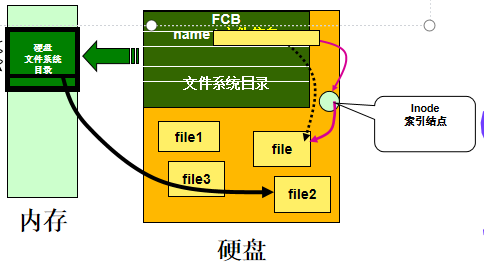
文件放在外存,文件信息形成FCB,FCB的集合构成目录
- 文件控制块FCB:用于存放控制文件所需的各种信息(基本信息,存取控制信息),来实现按名存取
而FCB的有序集合就是文件目录,一个FCB就是一个文件目录项。
索引结点:将文件名、文件具体信息分开,使文件描述信息单独形成一个索引结点。
1.按名检索时,名字不符的话其他信息并不需要读取,所以FCB中许多信息不需要全调入内存。
2.为了减小FCB,将文件的详细信息放入索引结点,FCB中记录文件名和inode地址。目录小了,调入内存占空就少,检索也快了。
目录结构
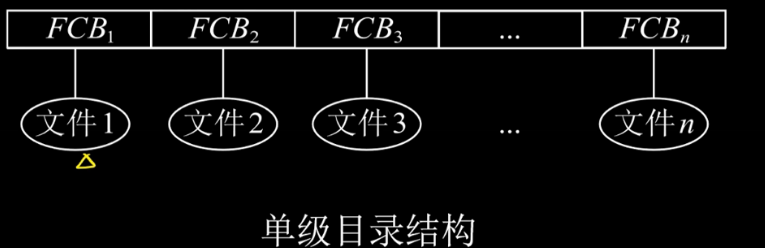
- 单级目录结构:整个文件系统只建立一张目录表,每个文件站一个目录项
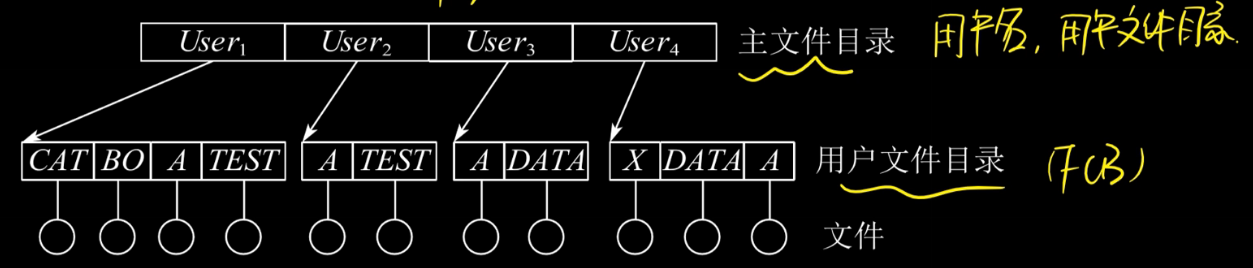
2.两集目录结构:文件目录分为文件目录和用户文件目录两级。
多用户操作系统下适用,但是不灵活。
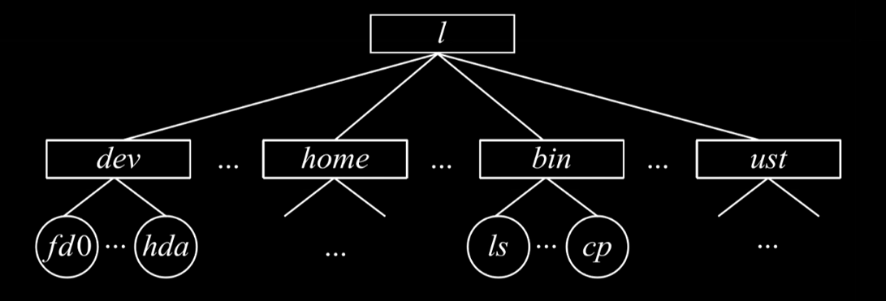
3.多级目录结构
从根节点出发到相应的节点,组成的路径就是文件的绝对路径。
3.文件共享
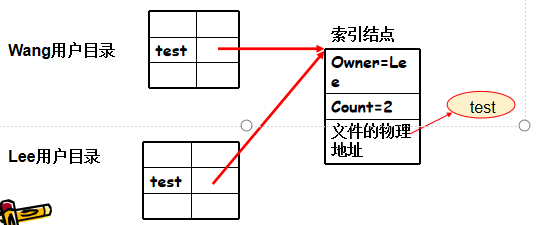
1.基于索引节点的共享凡是(硬链接)
一个用户修改指针指向地址里的内容,指针不变,其他用户通过指针总能感知索引结点中的最新内容
索引结点中增加count计数
主人不能删除文件,否则使得共享用户指针悬空
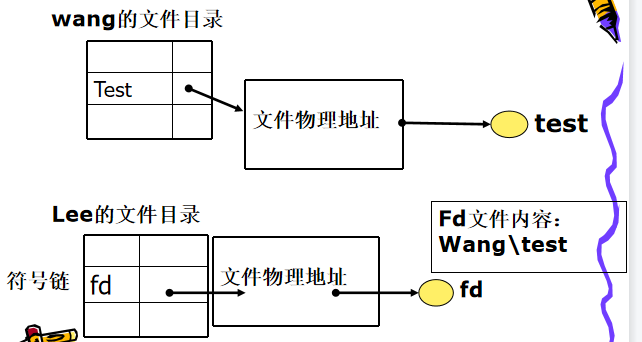
2.基于符号链的共享方式
创建一个link类型的文件:“文件名+共享文件路径”(类似快捷方式)
文件主人删除文件,共享者只会出现找不到文件错误。不会发生共享文件删除后出现悬空指针的情况。
4.文件保护
三种保护方式


5.文件的物理结构
1. 连续分配
为每一个文件分配一组相邻的盘块。
一个文件的目录条目包括开始块地址和所分配区域的长度
若文件长问n块,而且从位置b开始,那么文件就占有b,,b+n这些块。
优点:顺序访问容易,读写速度快
缺点:1.会产生外存碎片。可紧凑法弥补,但需要额外的空间,和内存紧凑相比更花时间。
2.创建文件时要给出文件大小;存储空间利用率不高,不利于文件的动态增加和修改;
2.链接分配
采用离散分配,可以为每一个文件分配一组不相邻的盘块。分为隐式链接和显示链接
优点:1.离散分配,消除外部碎片,提高利用率 2.同时适用于文件的动态增长;修改容易
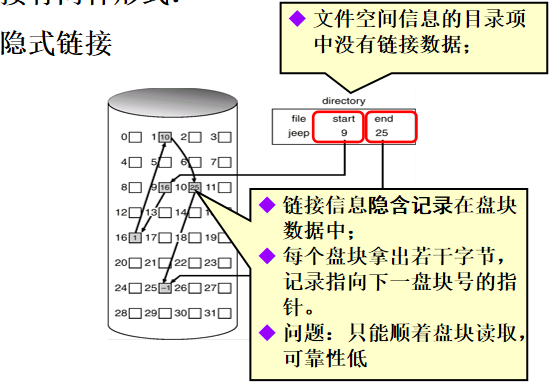
隐式链接
FCB里只有起始块和初始块,没有链接数据,链接数据隐含在各个盘块里。
文件空间信息的目录项中没有链接数据;
链接信息隐含记录在盘块数据中;
每个盘块拿出若干字节,记录指向下一盘块号的指针。
问题:只能顺着盘块读取,可靠性低
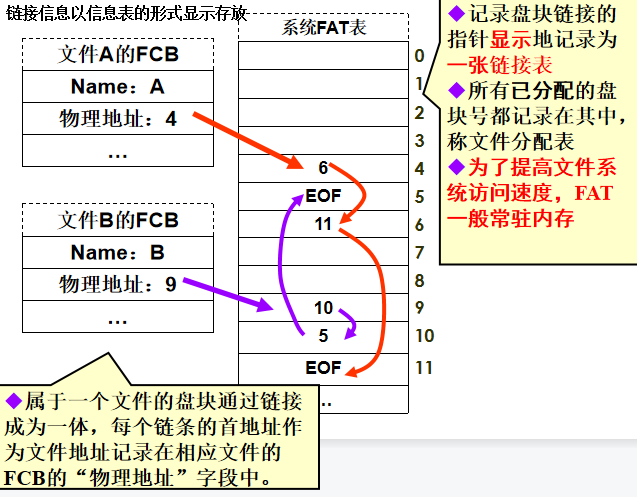
显式链接(FAT)
链接信息以信息表的形式显示存放。
记录盘块链接的指针显示地记录为一张链接表
所有已分配的盘块号都记录在其中,称文件分配表
为了提高文件系统访问速度,FAT一般常驻内存
FAT表的相关计算
一个1.2M的磁盘,盘块512B大小;若文件系统采用FAT格式,则FAT表大小如何?
表项个数 = 盘块个数
= 容量 / 盘块大小 = 1.2 * 220 / 29 = 1.2 *211 个
表项大小,决定于盘块数量编号需要的位数=12 位;
FAT表大小 = 表项个数 * 表项大小
= 1.2 *211 * 12 bit
= 1.2 *211 * 1.5B = 3.6KB
索引分配
系统运行时只涉及部分文件,FAT表无需全部调入内存
也就是把FAT表拆开了,每个文件都有一个索引表。
每个文件单独建索引表(物理盘块索引),记录所有分配给它的盘块号;
建立文件时,便分配一定的外存空间用于存放文件盘块索引表信息;
链接方案
如果一个索引表太大了,那么就可以将多个索引表链接起来。
多级索引
若文件较大,存放索引表也需要多个盘块(索引盘块)。
索引盘块亦需要按顺序管理起来
若索引盘块数量较少用指针链接的方式即可;
若索引盘块较多,需对索引盘块也采用索引方式管理,形成多级索引。
例题:计算文件最大程度
现有磁盘,磁盘块大小为1kb,一个索引表项4B,如果要将一个大小为64MB的文件用索引方式存储,那么请问需要几级索引?
显然,一个索引表项指向一个磁盘块就是1KB,那么现在有216个1KB需要存放,1KB的空间又能存28个索引表项,所以一共需要28个索引表。这样我们建立两级索引即可
混合组织索引
多种索引方式相结合。包含两种方式。
例题:

磁盘块有540K个,可以用220长度的二进制串来代表表项,一个表项就是2.5B,2.5*540K=1350kb

1.显然,一个数据块可以表示1024个地址,那么直接用所有地址数*4kb就行了
(10+1024+10242+10243)*4KB=
2.显然就是2GB+索引表项喽。
2GB/4KB=219块,也就是需要这些地址。
如果题目没有说明磁盘地址的话,我们将选用19位二进制数作为地址表示
然后就是看用几级了,一级表示210个,二级可以表示220个,所以用一个二级的就行了。
所以1个二级间接索引+【((512*1024个地址)-10个地址-1024个地址)/一个块里能容纳的地址数】
6.文件存储空间的管理
1.文件存储器空间的划分与初始化
划分:将物理磁盘划分为多个文件卷
初始化:将各个文件卷划分为目录区,文件区
目录区:存放FCB,用于磁盘存储空间管理信息
文件区:存放文件数据
2.存储空间管理
空闲表法
建立一个表,把所有空闲的盘块记录上去
与内存的动态分配类似,同样可采用首次适应算法、循环首次适应算法等。
回收主要解决对数据结构的数据修改。

如果此时有个请求3个块的文件,那么根据首次适应法的话就可以用序号1,把2 3 4分给他,然后修改第一个空闲盘块号为5,空闲盘块数为1。
空闲链表法
将所有空闲盘区拉成一条空闲链
分配:系统从链首依次摘下适当数目的空闲盘块分配给用户。
回收:系统将回收的盘块依次插入空闲盘块链的末尾。
这个链表法链接的单元有盘块,也有盘区,是盘区时注意考虑相邻区域合并问题
位示图法——位示图(重点)
值为0表示对应的盘块空闲,为1表示已分配。有的系统则相反。
磁盘上的所有盘块都有一个二进制位与之对应,这样由所有盘块所对应的位构成一个集合,称为位示图。
(字号i,位号j)
盘块号=字号*字长+位号
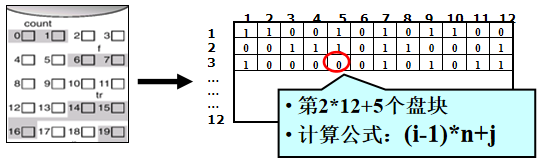
分配:将所找到的一个或一组二进制位为0的,转换成与之对应的盘块号。进行分配操作
回收:将回收盘块的盘块号转换成位示图中的行号和列号
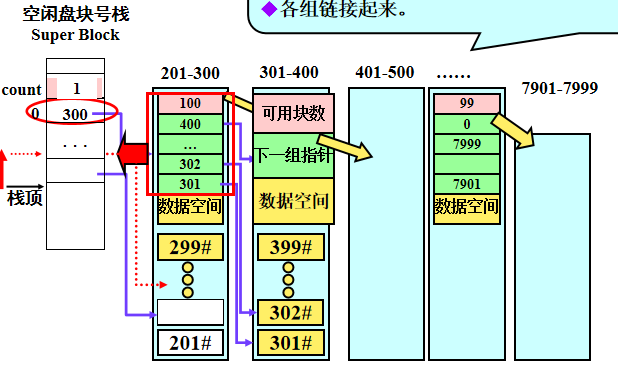
成组链接法
所有盘块按规定大小划分为组;
组间建立链接;
组内的盘块借助一个系统栈可快速处理,且支持离散分配回收。
9.磁盘的组织与管理
1.基本知识
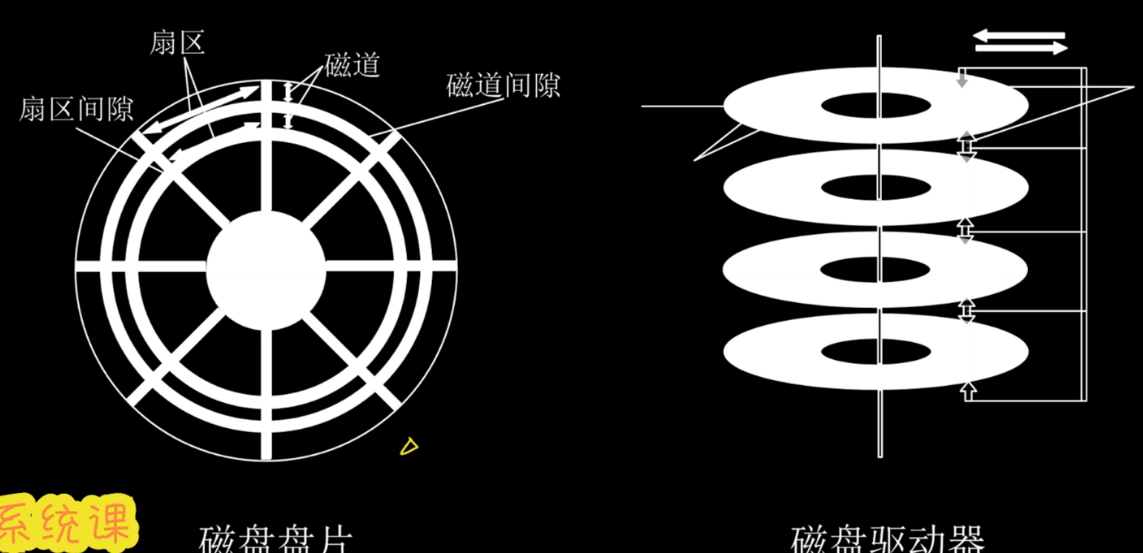
磁道:盘面上一圈圈的同心圆
扇区:整个盘面被分为好几个扇区,是可寻址的最小存储单元
柱面:所有盘面上位置相同的磁道形成柱面
磁盘地址:柱面号,盘面号,扇区号**(重点)**
注:1.扇区按照固定圆心角划分,密度从最外道向内道增加,存储能力受制于最内道的最大记录密度。
2.寻址的顺序是:磁道,盘面,扇区
读写操作通过马达来带动磁头来完成,磁头只能向内或者向外移动。磁头的移动是同一的
磁盘初始化
物理格式化:磁盘的各个磁道划分为删去,课分为头,数据,尾三个部分,然后将磁盘分区,每个分区由若干磁道组成
逻辑格式化:创建文件系统,将管理存储空间的数据结构引入(位示图等)
2.磁盘调度算法
一读磁盘的操作时间=寻道时间+延迟时间+传输时间
寻道时间=跨越一条磁道的时间x跨越磁道数+磁臂启动时间
延迟时间=1/(2转速)
传输时间=读写文件大小/(转速一个磁道的容量)注意,磁道容量和读写文件大小的单位应该已知
对于寻道时间,有以下算法
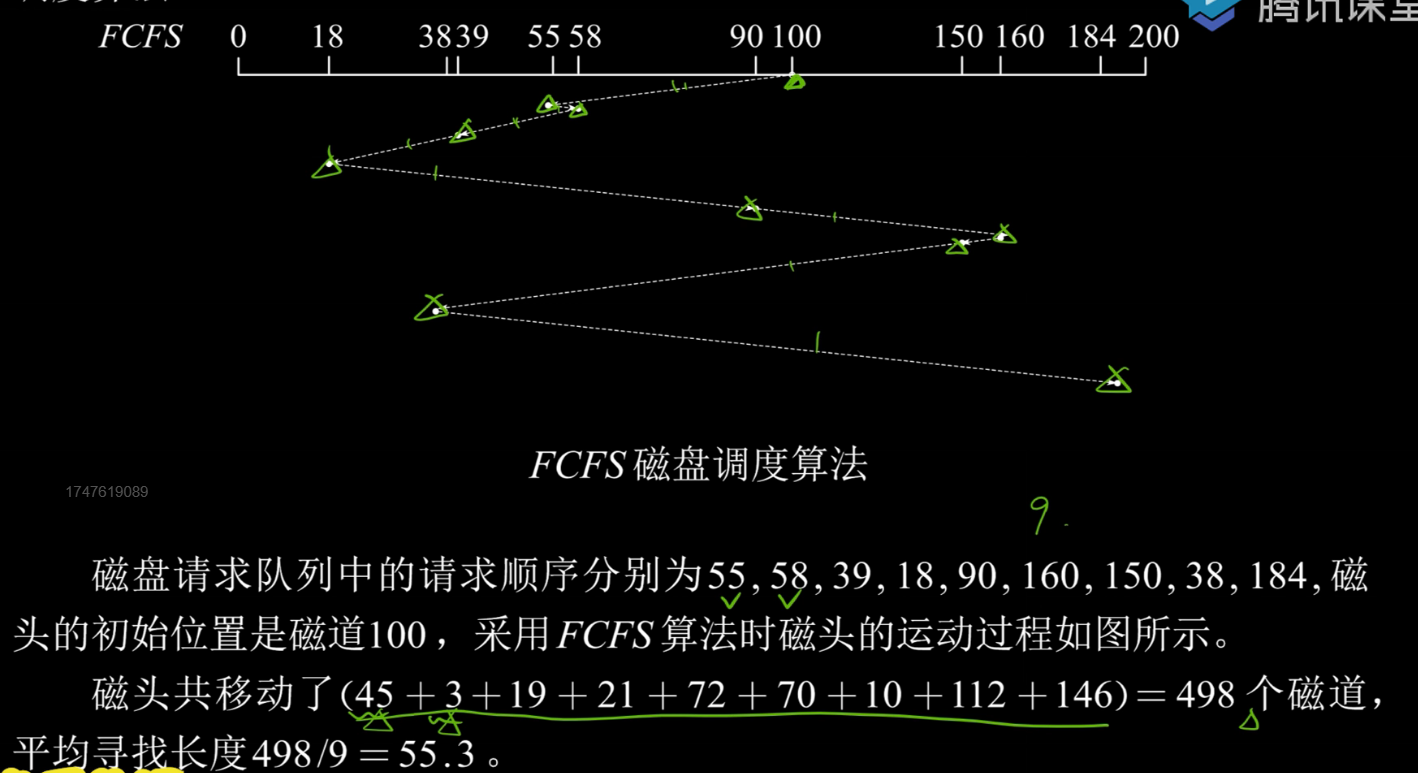
1.先来先服务FCFS
根据进程请求访问磁盘的先后顺序来调度
2.最短寻找时间优先 SSTF
找与当前磁头位置距离最近的位置去调度。

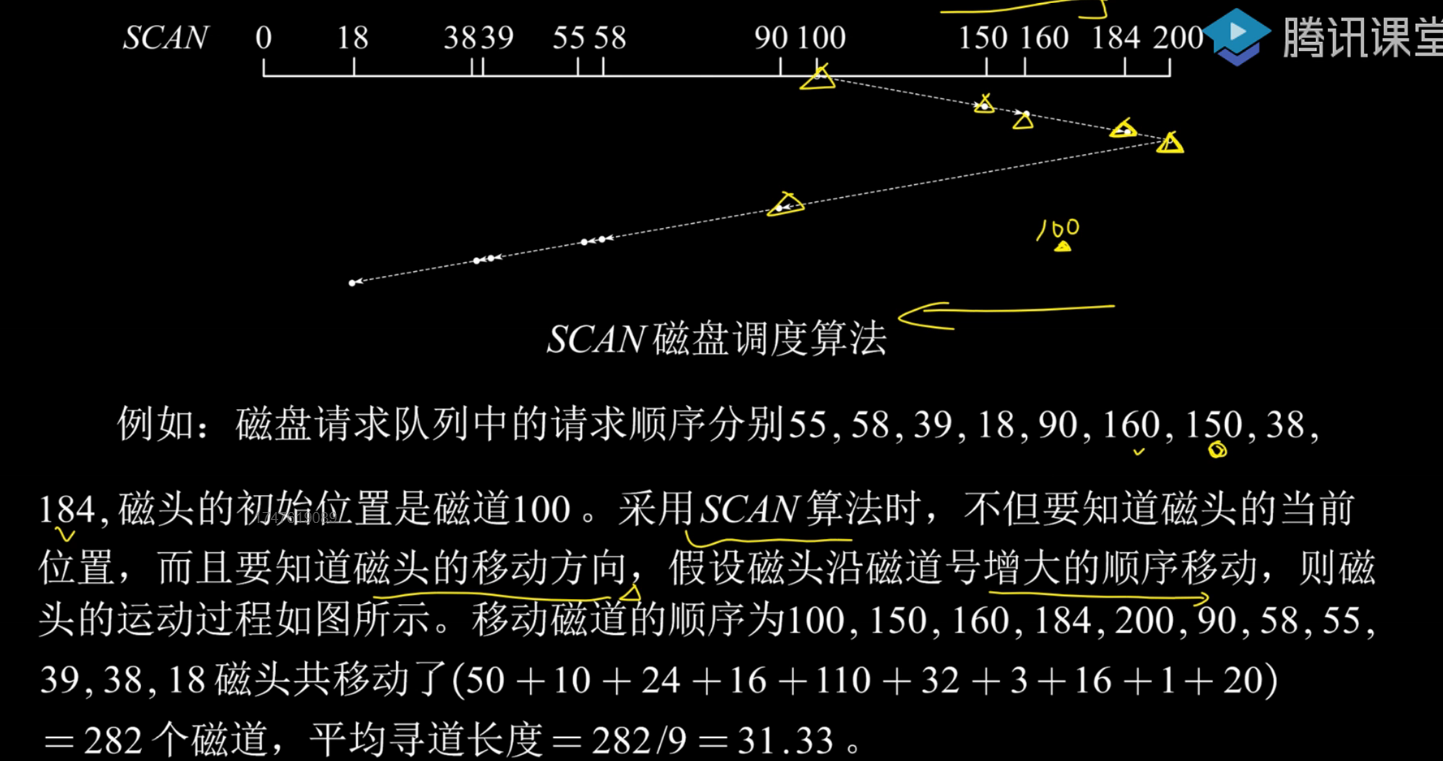
3.扫描算法
规定了磁道移动顺序,每次移动都会一直向外或内移动,直到最外侧或者最内侧后再改变方向。
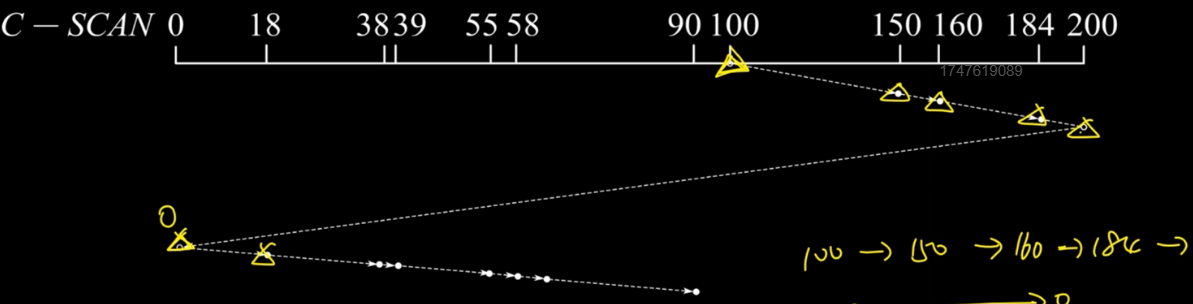
4.循环扫描算法
规定磁头单向移动,当碰壁之后立即回到起始端,比如,我们规定他只能向外侧移动,当碰壁后,它立即回到最内侧而且不去相应任何请求。

10.IO设备管理
1.基本知识
IO设备分为:人机交互外部设备(键盘鼠标显示器,低速设备),存储设备(高速设备),网络通信设备(中速设备)。
按照信息交换单位可分为:块设备(存取以数据块为单位,速率高,可寻址)。字符设备(存取以字节为单位,速率低,不可寻址,通常使用I/O中断来进行存储)
下面为IO系统的模型
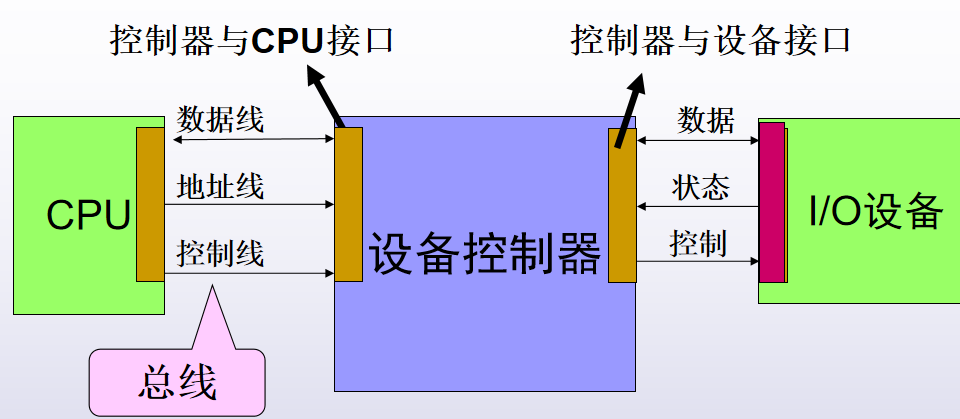
IO设备模型
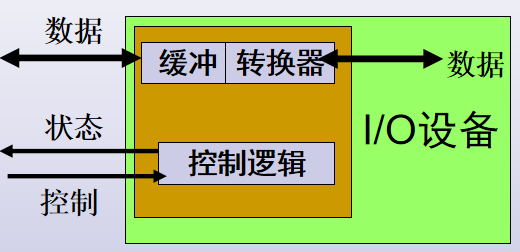
设备控制器模型
主要功能:
1.接收和识别CPU命令(控制寄存器:存放命令和参数)
2.标识和报告设备的状态(状态寄存器)
3.数据交换(数据寄存器)
4.地址识别(控制器识别设备地址、寄存器地址。地址译码器)
5.数据缓冲(协调I/O与CPU的速度差距)
6.差错控制
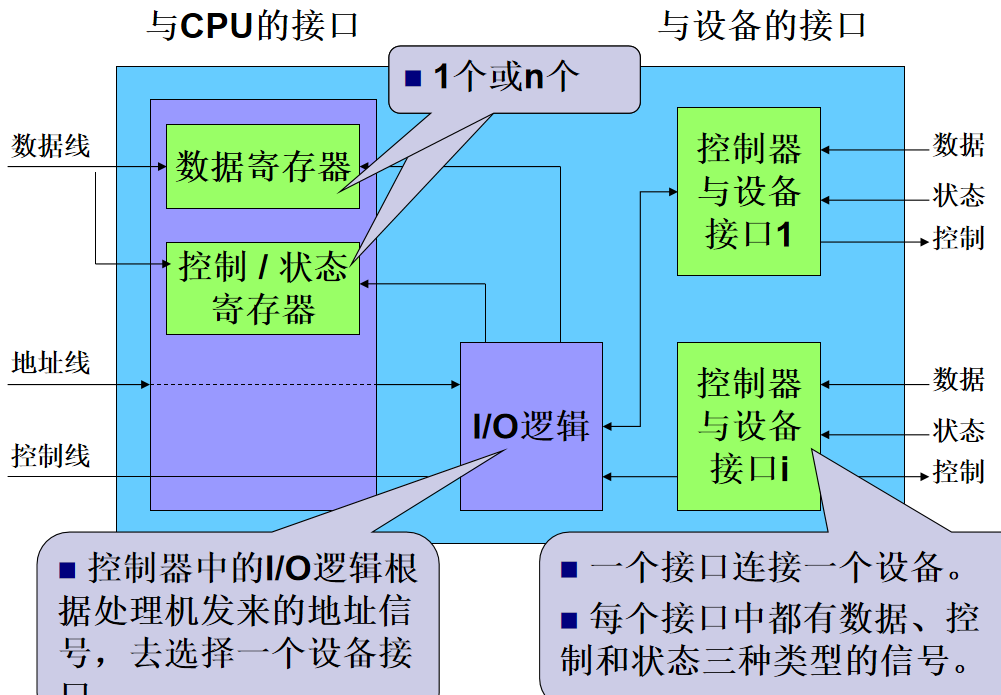
2.I/O设备的层次结构
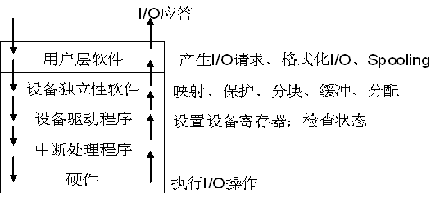
用户层软件
实现与用户交互的接口,用户可直接调用在用户层提供的、与I/O操作有关的库函数,对设备进行操作。
设备独立软件(和硬件无关的操作,在这里就结束了)
用于实现用户程序与设备驱动器的统一接口、设备命名、设备的保护以及设备的分配与释放等,同时为设备管理和数据传送提供必要的存储空间。
设备驱动程序
与硬件直接相关,用于具体实现系统对设备发出的操作指令,驱动I/O设备工作的驱动程序。
中断处理程序
用于保存被中断进程的CPU环境,转入相应的中断处理程序进行处理,处理完后再恢复被中断进程的现场后,返回到被中断进程。
3.I/O设备的控制方式(重点)
- 程序直接控制方式(轮询方式)
第一步:CPU向控制器发送一条I/O指令;启动输入设备输入数据;设备控制器中把状态寄存器busy=1。
第二步:然后不断测试标志。为1:表示输入机尚未输完一个字,CPU继续对该标志测试;直到为0:数据已输入控制器数据寄存器中。
第三步:CPU取控制器中的数据送入内存单元,完成一个字的I/O
- 中断驱动I/O方式
允许IO设备主动打断CPU的运行并且请求服务。
在原本的轮询方式中我们总是去检查IO设备输入完了没,由于IO设备速度低,CPU速度高,CPU等待IO设备就会造成大量资源的浪费,所以我们这里当某个进程要启动IO设备的时候,
1.先由CPU给相应设备控制器发一个IO指令,然后就去忙其他的
2.等到IO弄好了设备控制前再对CPU来一个中断指令
3.然后CPU开始检查数据有没有错,没错就从设备控制器的寄存器里拿走数据
最大优点:允许了CPU和IO设备并行工作
- 直接存储器存取(DMA方式)
基本单位是数据块
DMA控制器内部构造
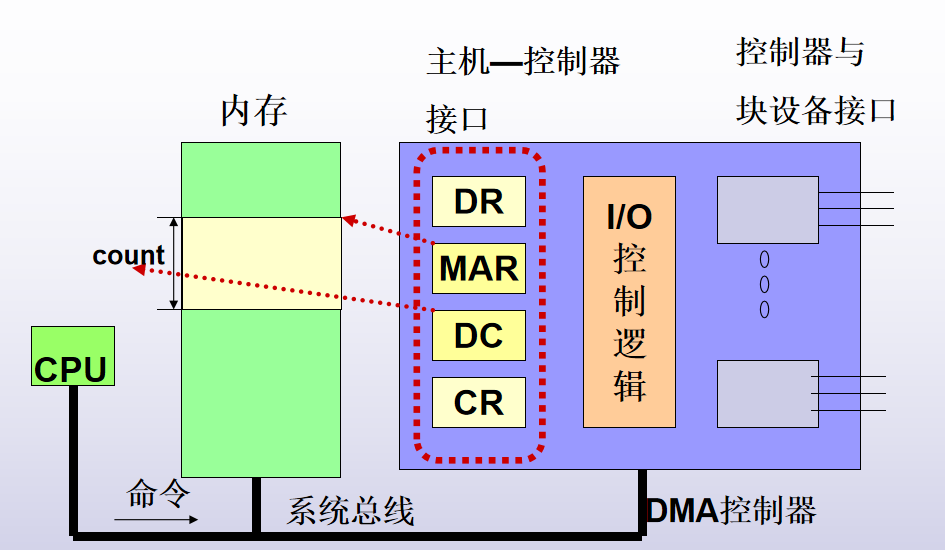
DR:数据寄存器
MAR:内存地址寄存器
CR:命令寄存器
DC:数据计数器
1.CPU给IO设备读指令,该命令被送到命令寄存器CR中,同时发送读入的地址到MAR,要读数据字数送入DC
2.DMA控制器的IO控制逻辑开始将磁头放到相应位置
3.启动DMA控制器开始传送数据,读入第一个数据到DR中,然后传到MAR地址,接着MAR+1,DC-1,直到DC为0,输入结束
- I/O通道控制方式
CPU只需发一条I/O指令,给出通道程序的首地址及要访问设备即可。 CPU、通道和I/O设备三者的并行操作,提高整系统资源利用率。
注意通道是一个硬件。
三种方式对比:
从数据传送单位来说,程序直接控制和终端方式都是以字为基本单位,而DMA时以数据块为基本单位,
从cpu的干预程度来说,CPU在四种方式的干预程度越来越低
4.缓冲区
1.引入缓冲区的主要原因:
缓和CPU与I/O设备间速度不匹配的矛盾。
缓冲区数据成批传入内存,也可进一步减少对CPU的中断频率
最终目的:提高CPU和I/O设备的并行性。
2.使用缓冲区的方式:
1)单缓冲、多缓冲
2)循环缓冲
3)缓冲池(Buffer Pool)
单缓冲(Single Buffer)
每当用户进程发出一I/O请求时,OS在主存中为之分配一个缓冲区。CPU和外设轮流使用,一方处理完后等待对方处理。
双缓冲
进一步加快输入和输出速度,提高设备利用率制,也称缓冲对换
输入:数据送入第一缓冲区,装满后转向第二缓冲区。
读出:OS从第一缓冲区中移出数据,送入用户进程,再由CPU对数据进行计算。
两个缓冲区,CPU和外设不再针对一块交替
可能实现连续处理无需等待对方。前提是CPU和外设对一块数据的处理速度相近。而如下图情况CPU仍需等待慢速设备。

循环缓冲(circular buffer)
多个缓冲区。大小相同,三种类型:
预备装输入数据的空缓冲区R
装满数据的缓冲区G
计算进程正在使用的现行工作缓冲区C
多个指针。
指示正在使用的缓冲区C的指针Current
指示计算进程下一个可取的缓冲区G的指针Nextg
指示输入进程下次可放的缓冲区R的指针Nexti
缓冲池(Buffer Pool)
缓冲池,至少应含有下列三种类型的缓冲区:
空缓冲区;
装满输入数据的缓冲区;
装满输出数据的缓冲区;
为方便管理,将上述类型相同的缓冲区连成队列
空缓冲区队列(所有进程都可用)
输入队列(n个进程有各自的队列)
输出队列(n个进程有各自的队列)
5.设备分配中的虚拟技术— SPOOLing技术
对于cpu,多道程序技术将一台物理CPU虚拟为多台逻辑CPU,实现多个用户共享一台主机
而对于外围设备,专门利用程序模拟脱机I/O的外围机,完成设备I/O操作,称这种联机情况下实现的同时外围操作为SPOOLing 技术。
SPOOling技术可将一台物理I/O设备虚拟为多台逻辑I/O设备,允许多个用户共享一台物理I/O设备。
SPOOLing系统的组成
1.输入井和输出井:磁盘上开辟两大存储空间。输入井模拟脱机输入的磁盘设备,输出井模拟脱机输出时的磁盘。
2.输入缓冲区和输出缓冲区:为缓解速度矛盾,内存中开辟两大缓冲空间,输入缓冲区暂存输入设备送来的数据,再送给输入井;输出缓冲区暂存输出井送来的数据,再送输出设备。
3.输入进程和输出进程。
用一进程模拟脱机输入时外围设备控制器的功能,把低速输入设备上的数据传送到高速磁盘上;
用另一进程模拟脱机输出时外围设备控制器的功能,把数据从磁盘上传送到低速输出设备上。
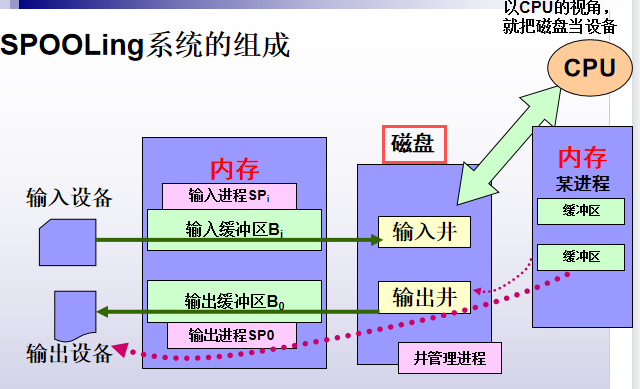
SPOOLing技术的使用:
当用户进程请求打印输出时,SPOOLing系统同意为它打印输出,但并不真正立即把打印机分配给用户进程,而只为它做两件事:
①由输出进程在输出井中为之请求一个空闲磁盘块区,并将要打印的数据送入其中.
②输出进程再为用户进程申请一张空白的用户请求打印表,并将用户的打印要求填入其中,再将该表挂在请求打印队列上.
SPOOLing系统的特点
1.提高了I/O的速度。利用输入输出井模拟成脱机输入输出,缓和了CPU和I/O设备速度不匹配的矛盾。
2.将独占设备改造为共享设备。并没有为进程分配设备,而是为进程分配一存储区和建立一张I/O请求表。
3.最终,实现了虚拟设备功能。多个进程可“同时”使用一台独占设备。