说明
不可不读书
先从经典的一些超简单信号开始
使用移动平均指标SMA(算术)

给出了信号的产生方法,还有一些测算结果,反正看起来都是盈利的
首先使用离线方法实验一组结果,然后就使用ADBS来进行类似的处理。
内容
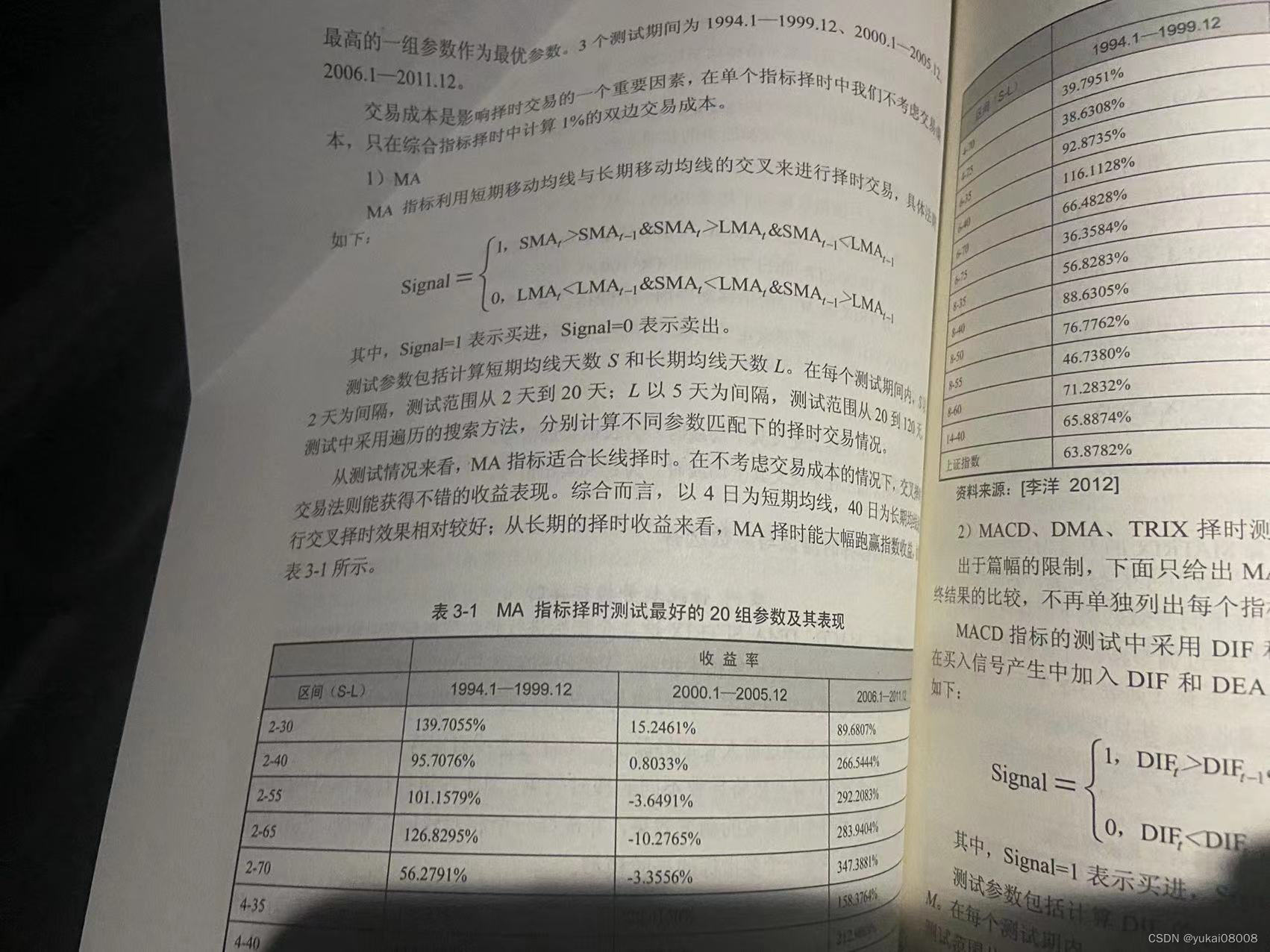
1 原理分析
买入信号:当短线向上穿越长线,且短信增长时,买入;
卖出信号:当短线下穿长线,且长线下跌时,卖出;
因为已经使用T周期进行了平滑,所以短线和长线一般都比较平稳,所以在制作信号时,只用了本时刻t 和上一时刻 t-1两个时刻的数据进行比较。
短线上其实只有一个判断;短线上穿则需要两组,即短线在上一时刻处于长线下方,在当前时刻已处于长线上方。
2 离线计算
基于之前整理好的数据进行计算
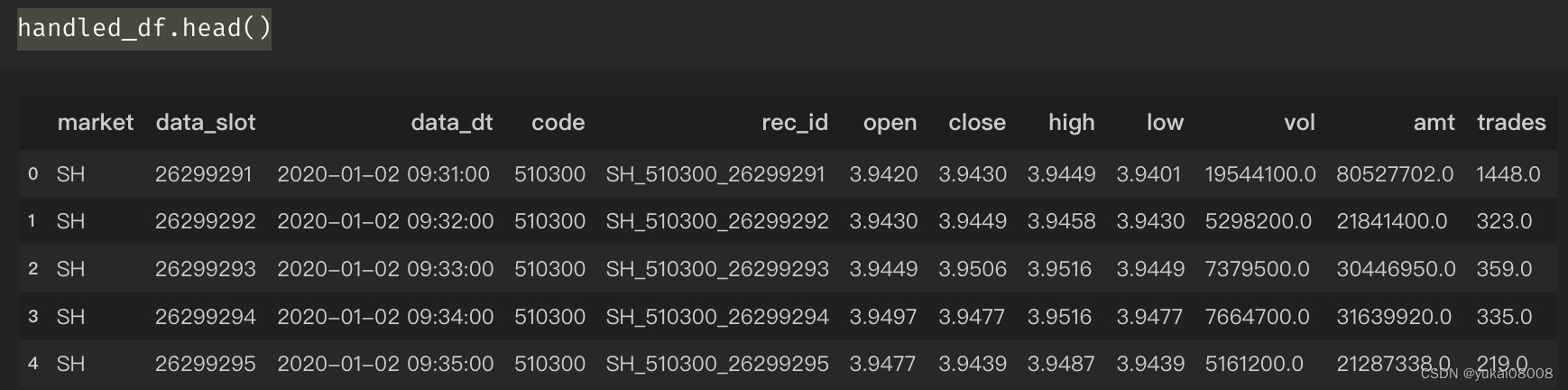
需要计算的指标很简单,我按照几个周期来算。计算均值,然后把上一个均值挪到当前时刻。
handled_df['close_T_mean_24000'] = handled_df['close'].rolling(24000).mean()
handled_df['close_T_mean_12000'] = handled_df['close'].rolling(12000).mean()
handled_df['close_T_mean_1200'] = handled_df['close'].rolling(1200).mean()
handled_df['close_T_mean_600'] = handled_df['close'].rolling(600).mean()
handled_df['close_T_mean_2400'] = handled_df['close'].rolling(2400).mean()
signal_df = handled_df[['data_slot','close', 'close_T_mean_1200','close_T_mean_24000','close_T_mean_12000',
'close_T_mean_600', 'close_T_mean_2400']]
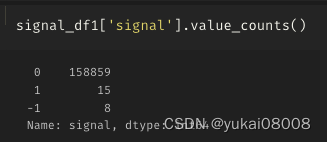
signal_df1 = signal_df.dropna()
signal_df1['last_close_T_mean_600'] = signal_df1['close_T_mean_600'].shift(1)
signal_df1['last_close_T_mean_1200'] = signal_df1['close_T_mean_1200'].shift(1)
signal_df1['last_close_T_mean_2400'] = signal_df1['close_T_mean_2400'].shift(1)
signal_df1['last_close_T_mean_24000'] = signal_df1['close_T_mean_24000'].shift(1)
signal_df1['last_close_T_mean_12000'] = signal_df1['close_T_mean_12000'].shift(1)

按书上说的,生成信号
# short_t = 'close_T_mean_600'
short_t = 'close_T_mean_1200'
# short_t = 'close_T_mean_2400'
# long_t = 'close_T_mean_24000'
long_t = 'close_T_mean_12000'
# long_t = 'close_T_mean_2400'
last_short_t = 'last_%s' % short_t
last_long_t = 'last_%s' % long_t
buy_signal = (signal_df1[short_t] >signal_df1[last_short_t] ) & \
(signal_df1[short_t] >signal_df1[long_t] ) & \
(signal_df1[last_short_t] < signal_df1[last_long_t] )
sell_signal = (signal_df1[long_t] <signal_df1[last_long_t] ) & \
(signal_df1[short_t] <signal_df1[long_t] ) & \
(signal_df1[last_short_t] > signal_df1[last_long_t] )
signal_df1['signal'] = 0
signal_df1['signal'] += buy_signal * 1
signal_df1['signal'] += sell_signal * -1
同时抽取数据里的数据进行比对是一致的:

一开始不知道发生了什么,字段都变成字符型了,把他们变回去。
mongo的管道转整型和转浮点分别是toInt、toDouble
for varname in ['close','high','low','open','trades','vol']:
command_dict = {'%s' % varname :{'$exists': True, '$type': 'string'}}
command_list = [{'$set':{'%s' % varname : { '$toDouble': '$%s' % varname }}}]
res = the_collection.update_many(command_dict, command_list)
print(res.acknowledged)
这种变量的弱管辖方式有时候也算是mongo相较于mysql的弱点吧。
3 离线测试
然后开始简单的测试.
short_t = 'close_T_mean_600'
# short_t = 'close_T_mean_1200'
# short_t = 'close_T_mean_2400'
long_t = 'close_T_mean_2400'
# long_t = 'close_T_mean_24000'
# long_t = 'close_T_mean_12000'
last_short_t = 'last_%s' % short_t
last_long_t = 'last_%s' % long_t
buy_signal = (signal_df1[short_t] >signal_df1[last_short_t] ) & \
(signal_df1[short_t] >signal_df1[long_t] ) & \
(signal_df1[last_short_t] < signal_df1[last_long_t] )
sell_signal = (signal_df1[long_t] <signal_df1[last_long_t] ) & \
(signal_df1[short_t] <signal_df1[long_t] ) & \
(signal_df1[last_short_t] > signal_df1[last_long_t] )
signal_df1['signal'] = 0
signal_df1['signal'] += buy_signal * 1
signal_df1['signal'] += sell_signal * -1
总体来说还是… 有点问题的,哈哈
- 1 方法似乎有点用
- 2 方法似乎有点呆
总结:尽信书,不如无书
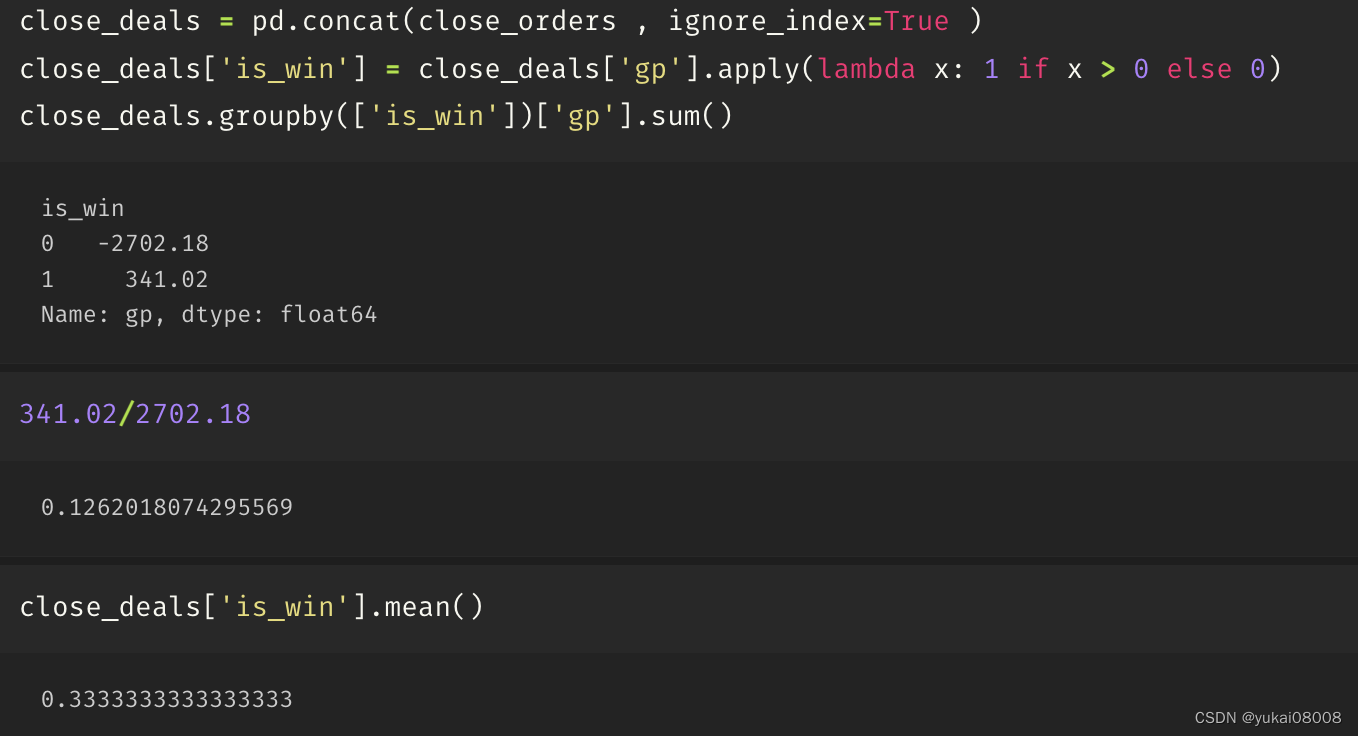
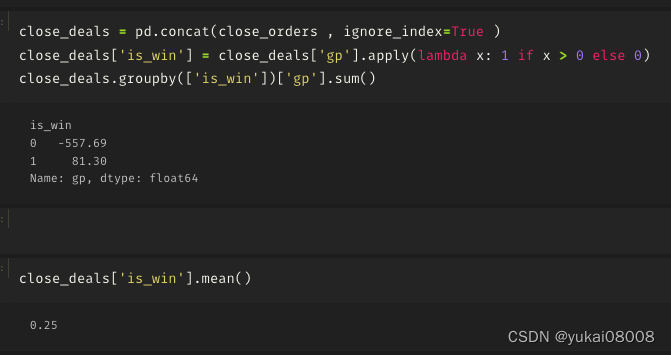
测试采用简单规则:当每次产生买入信号时,购买最大不超过5000块的股票;当产生卖出信号时,将所有的库存清仓。
以下罗列了一下结果(数据是从2020-01-02~2023-2-24,2年多的数据,烧掉前面24000分钟,大约也有接近2年)
模拟交易部分的代码
signal_list = list(signal_df1['signal'])
data_slot_list = list(signal_df1['data_slot'])
price_list = list(signal_df1['close'])
amt = 5000
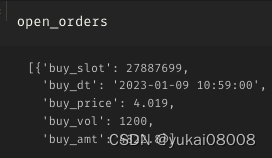
open_orders = []
close_orders = []
for i in range(len(signal_list)):
signal = signal_list[i]
data_slot = data_slot_list[i]
price = price_list[i]
if signal > 0 :
buy_vol = int(amt / (price * 100)) * 100
order_dict = {}
order_dict['buy_slot'] = data_slot
order_dict['buy_dt'] = slot_ord2str(data_slot)
order_dict['buy_price'] = price
order_dict['buy_vol'] = buy_vol
order_dict['buy_amt'] = buy_vol * price
open_orders.append(order_dict)
if signal <0:
if len(open_orders):
tem_df = pd.DataFrame(open_orders)
tem_df['sell_slot'] = data_slot
tem_df['sell_price'] = price
tem_df['sell_vol'] = tem_df['buy_vol']
tem_df['sell_amt'] = tem_df['sell_price'] * tem_df['sell_vol']
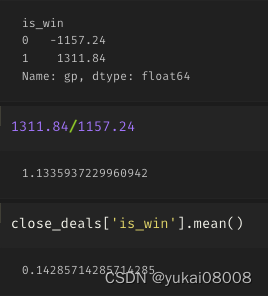
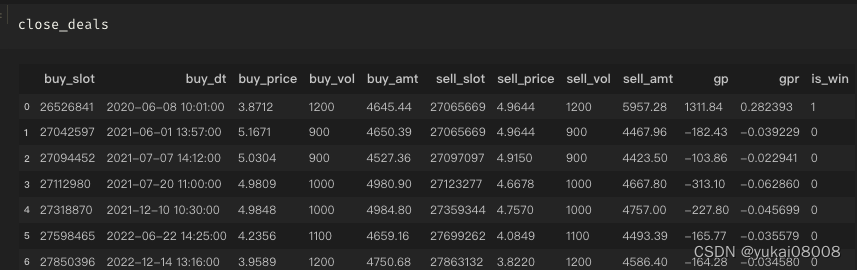
tem_df['gp'] = tem_df['sell_amt'] - tem_df['buy_amt']
tem_df['gpr'] = tem_df['gp'] / tem_df['buy_amt']
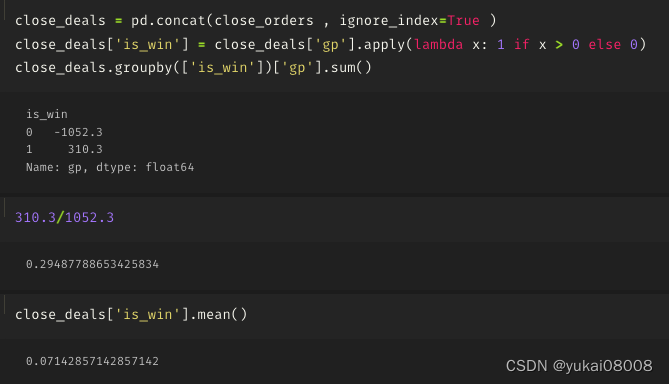
close_orders.append(tem_df)
open_orders = []
3.1 S600-L2400
交易机会,不算很多
模拟结束时,订单全部关闭
盈亏比不及格,胜率低
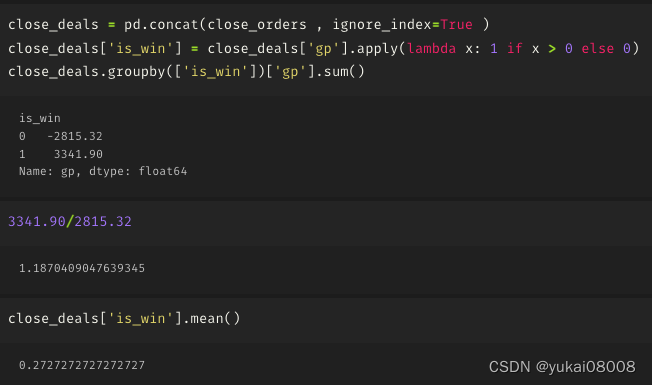
整体交易风格是小输大赢,一个月交易一两次的样子
3.2 S600-L12000
交易次数更少
有一个单子没close…(看起来是赚钱的)
亏钱的
3.3 S600-L24000
将长周期再拉长一点
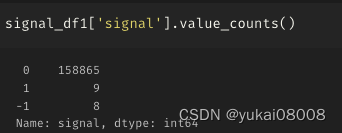
亏
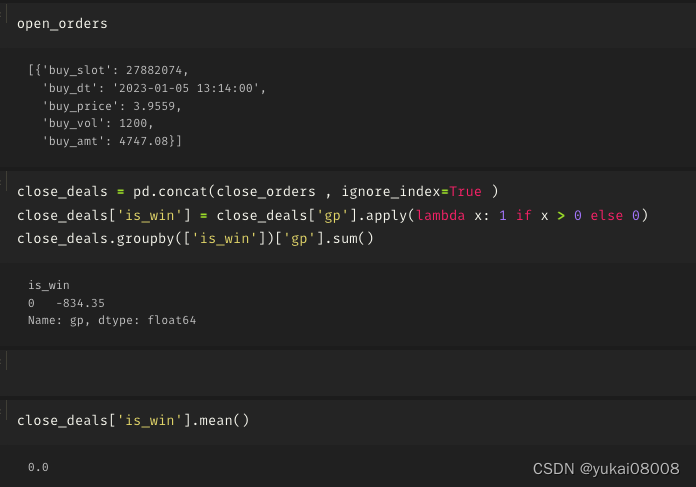
3.4 S1200-L2400
这是长短周期比较接近的
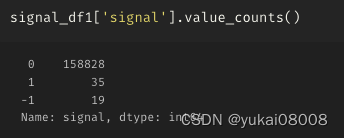
1个订单没有关闭
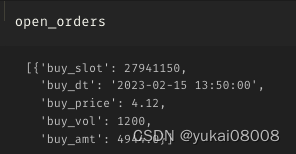
亏
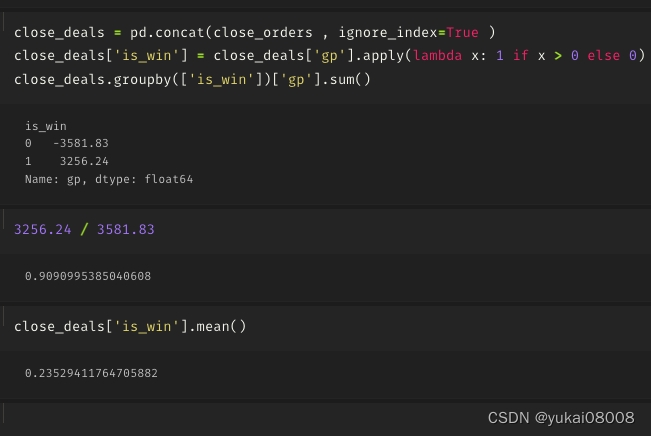
3.5 S1200-L12000
开的单子很少
两个单子没关
不赢不输
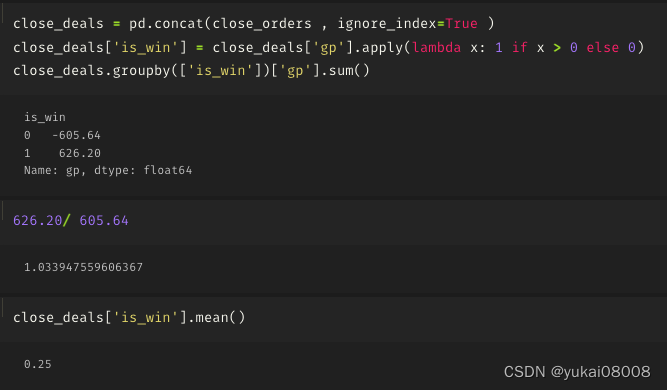
3.6 S1200-L24000
单子少
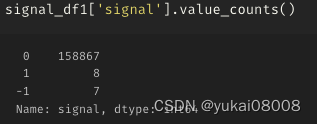
有一个没关
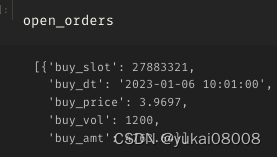
惊人的亏
除了亏还是亏
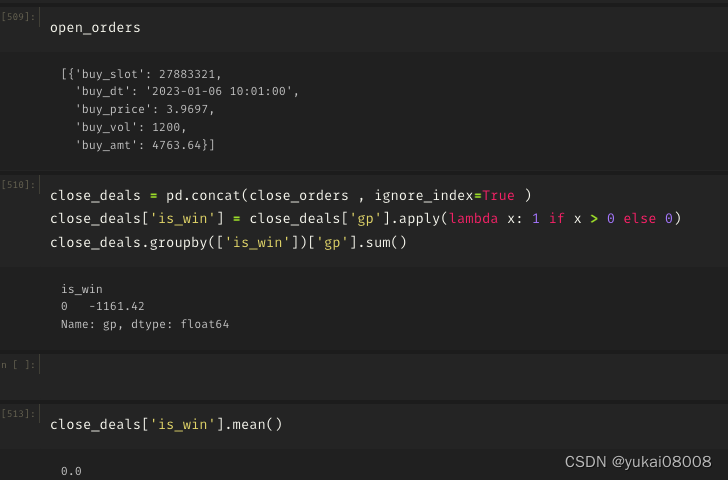
结论:长短周期的搭配是很戏剧的,一个错误的配方可能全毁(这种方法可靠吗?)
3.7 S2400-L12000
机会少
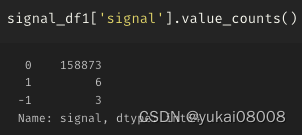
不关单
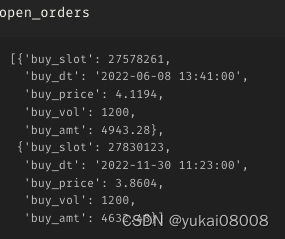
不赚钱
3.8 S2400-L24000
机会少
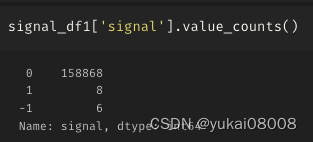
不关单
不怎么赚
就抓住了一次机会
3.9 思考
我所希望的信号策略,不仅是能够产生一个可以盈利的交易基础,更是一种稳定,可控的方法。从上面的实验可以看出来,整个过程很像炼金配方,我觉得这个是存在问题的。
从本质上说,趋势策略相较于动量策略的交易次数肯定会偏低,但是也不应该这么低;而任何一套信号,还应该有一种自收敛的倾向,而不是机械犯错,缓慢纠偏,甚至不纠偏。
这两年的市场事实上是一个很好的市场,可以检验模型在下滑过程中的表现。
怎么办?
有错当然要改,我觉得从整体的思想上是可取的(这是可以拯救的基础)。我甚至把长短周期倒过来试了下,发现完全无法产生卖出信号。
- 1 通过平滑,构造一个平滑的价格曲线
- 2 当短期趋势上升,且突破长趋势线买入
- 3 当长趋势下跌,且短线向下突破卖出
5天线对应1200分钟,10天线就是2400分钟。以S=1200,L=4800来看,最近还是能获得一次收益(当然不是最大收益)
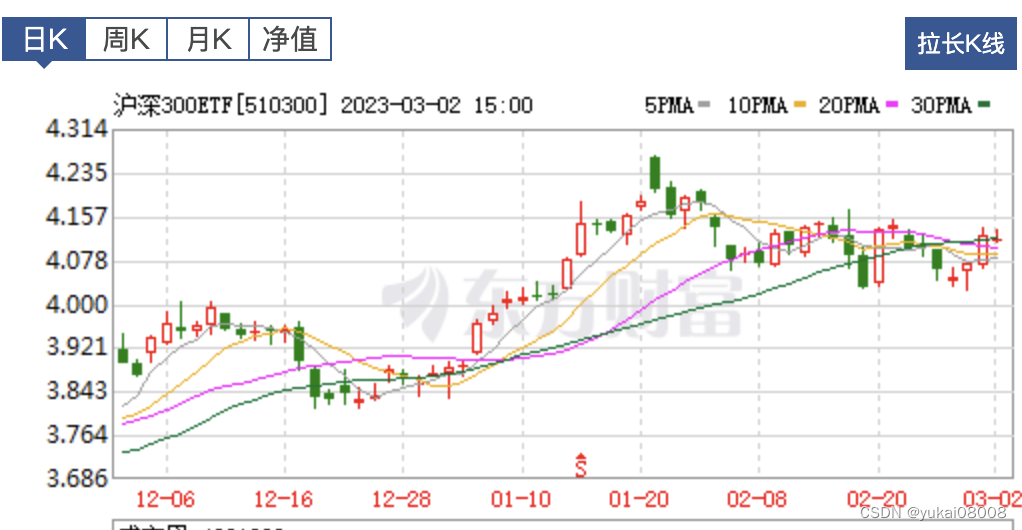
为什么之前的信号是 SMA > LMA?
因为从视觉上最为明显,但是为什么非得是以这个为界限呢?因为这种视觉法,0和1很容易说清楚,但是这种离散化的方法牺牲了大量的信息。我可以用一种连续的方法来替代这种方法吗?
从趋势上来看,如果将曲线进行斜率拟合,那么在上升和下降的区间就可以进行交易。
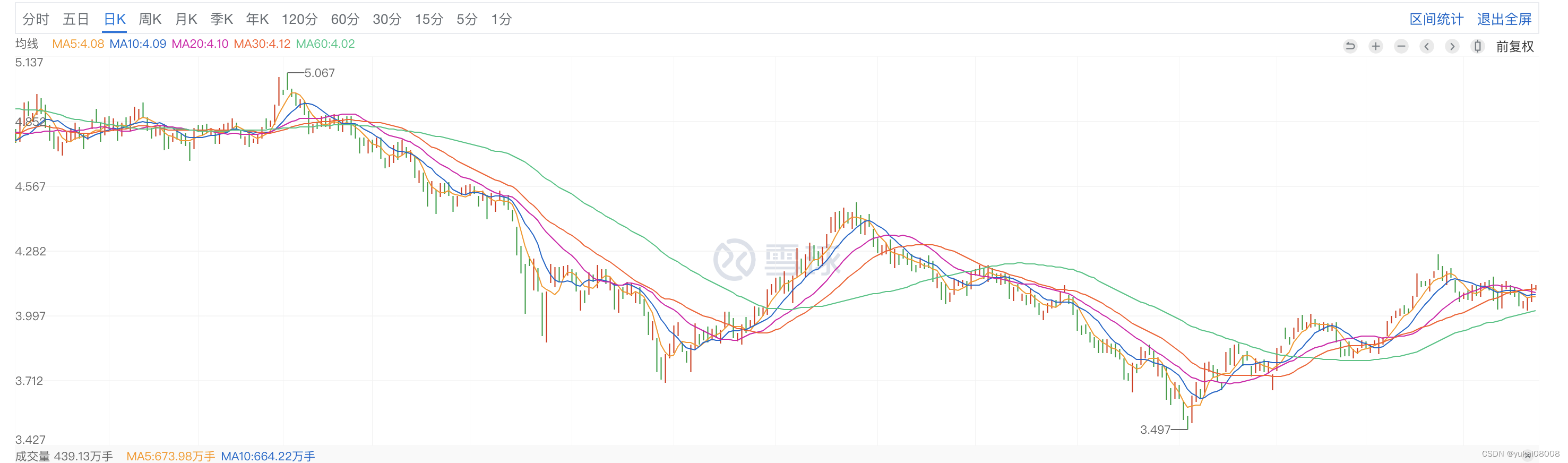
蓝色是10天平均,也就是2400分钟线,我觉得在这个周期上看是比较合适的,能给我提供相对多的交易机会。绿线太慢,周期太长了。
LMA-K: 提供一个交易的保护,在斜率由正向加速减缓,或者为负时清仓,不交易。当负斜率减缓准备,为正时可以交易。
SMA-K: 尽可能的交易,最终时机的把握由SMA-K发出,我觉得600分钟线(甚至更短的)是可以接受的。
斜率:因为MA已经做了平滑,所以当前点减去前一个点就是一个斜率。
如果说斜率是一阶导,那么斜率的变化就是二阶导。如果斜率为正且比上一个斜率更小,说明斜率在衰减,也就是趋势在衰减。理论上,0的时候是顶峰,实际上,可以提前一点行动(将斜率的衰减比去价格)
一阶导:总体上还是符合预期的,长周期的K边的比较慢,一个长周期过程中有若干个短周期
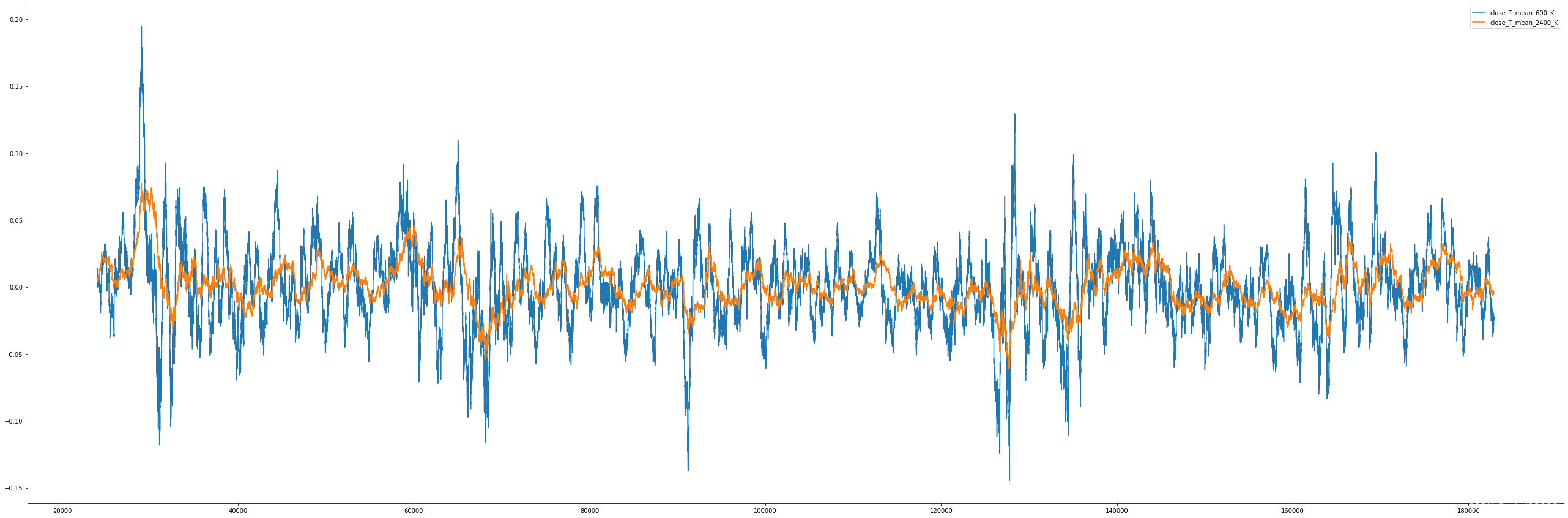
二阶导:
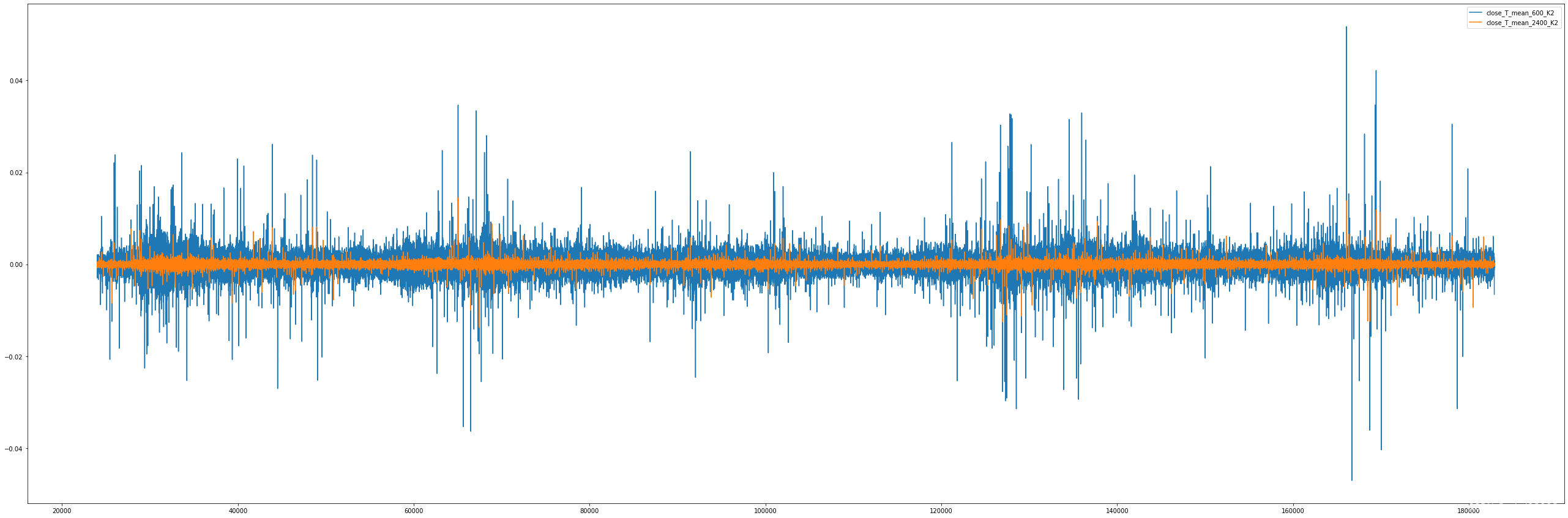
理论上可行,但是按分钟作为周期,抖动太快了
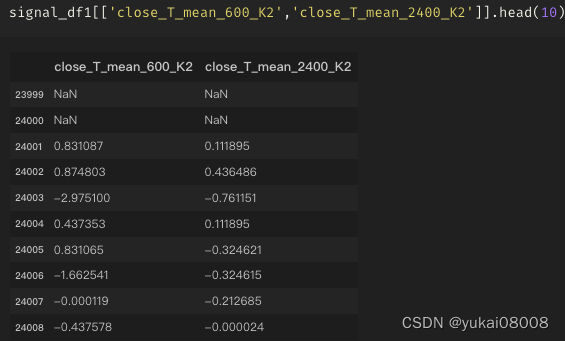
所以,看来周期不能按分钟来滚动叠加
大概上面传统的测试失败,也是因为在分钟级的方式下叠加,很多错误噪声信号。按日k的数据来看,本质上是对一组240分钟进行统计,那样会消弭很多噪声,同时也会滤除很多有益信息。
基于分钟级的分析时,要增加这一层的过滤。所以,我不能用分钟减分钟来获取斜率,而是要拟合一串数字的斜率。
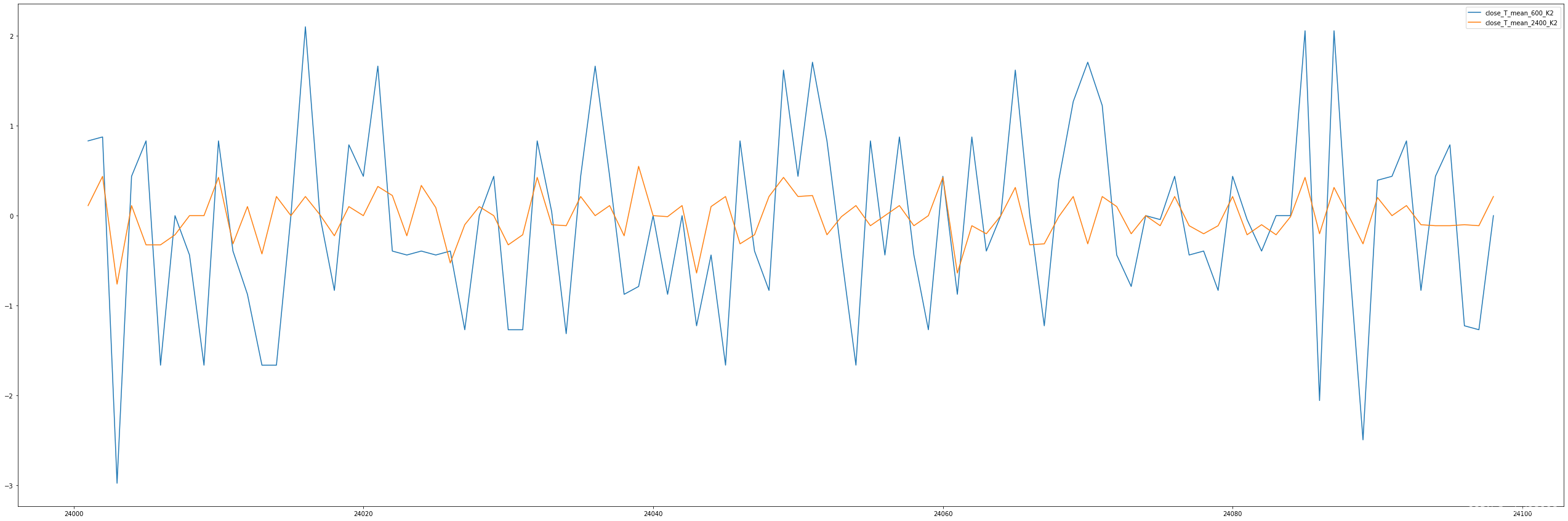
看起来是可以构成理想中的信号源的,橙色是长线,变化缓慢,用来提供短效交易的基础。
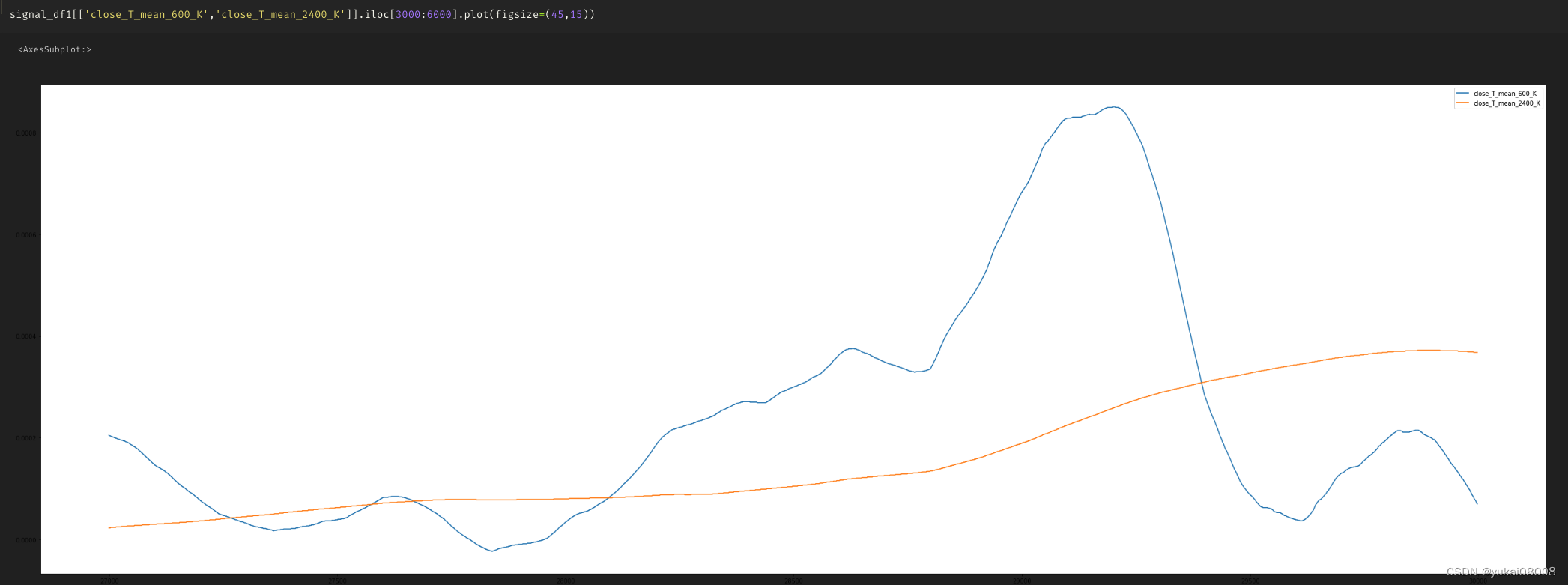
这是二阶信号
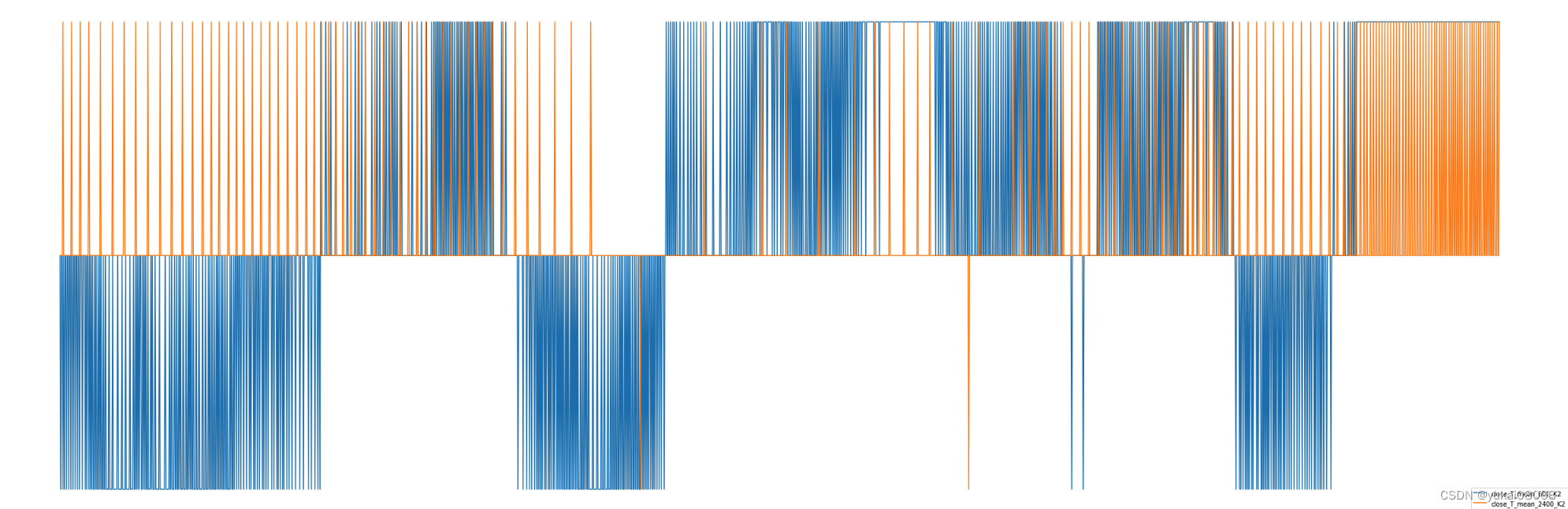
仍然会有一些毛刺,所以在使用信号时可以采用冷静时间的方法过滤(相当于三阶信号)
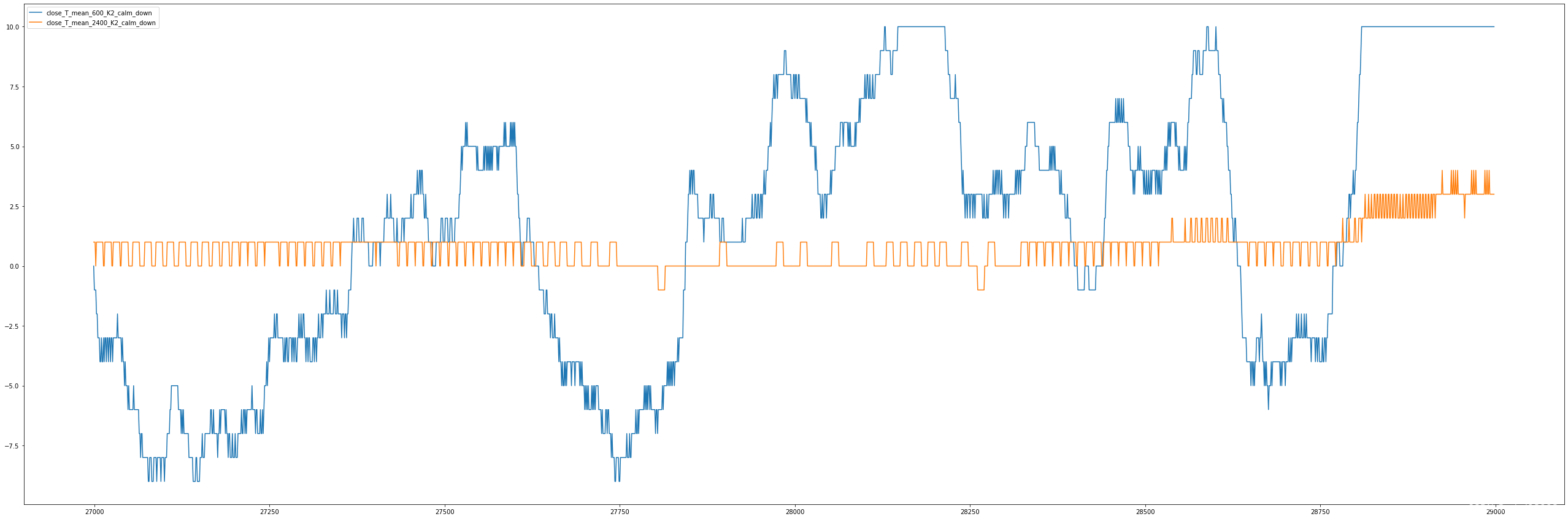
对应的价格曲线,仅以此段为例,短线在底部开始爬升时给出一段足够长的买入信号(如果采用更短的冷静时间可以更早买入);然后长线一直很平稳,仅出现过两次下翻(1),剩余都是0,1,甚至2,3等。

开始计算
signal_df1['close_T_mean_600_K'] = signal_df1['close'].rolling(600).apply(cal_K)
signal_df1['close_T_mean_2400_K'] = signal_df1['close'].rolling(2400).apply(cal_K)
# 为简便起见,暂时也不分辨斜率的强弱
signal_df1['close_T_mean_600_K2'] = signal_df1['close_T_mean_600_K'].diff().apply(lambda x: 1 if x > 0 else - 1 if x < 0 else x)
signal_df1['close_T_mean_2400_K2'] = signal_df1['close_T_mean_2400_K'].diff().apply(lambda x: 1 if x > 0 else - 1 if x < 0 else x)
# 冷静二阶导
signal_df1['close_T_mean_600_K2_calm_down'] = signal_df1['close_T_mean_600_K2'].rolling(10).sum()
signal_df1['close_T_mean_2400_K2_calm_down'] = signal_df1['close_T_mean_2400_K2'].rolling(10).sum()
冷静后的二阶导就可以作为交易的原始信号了(冷静的时间也是其中一个参数)
从短期交易信号来看
sma_signal_list = list(signal_df1['close_T_mean_600_K2_calm_down'])
pd.Series(sma_signal_list).value_counts()
10.0 15294
-10.0 13627
-2.0 9497
-1.0 9380
0.0 9369
1.0 9184
-3.0 8920
2.0 8784
-4.0 8377
3.0 7665
-5.0 6889
4.0 6489
-6.0 6116
5.0 5888
-7.0 5388
6.0 4813
9.0 4594
7.0 4583
8.0 4577
-8.0 4571
-9.0 4268
dtype: int64
从长期交易信号来看
lma_signal_list = list(signal_df1['close_T_mean_2400_K2_calm_down'])
pd.Series(lma_signal_list).value_counts()
0.0 58604
1.0 38034
-1.0 35347
-2.0 10308
2.0 9749
3.0 1926
-3.0 1598
-4.0 399
-5.0 260
4.0 160
-6.0 88
dtype: int64
看起来SMA会呈现比LMA更剧烈的变化,比较符合预期
以下进行简单交易回测。具体的规则是:
- 1 sma信号达到非常显著(过去10个周期连续显示买入)以及lma信号不为负时允许买入
- 2 sma信号相当于采取了10分钟冷静时间
- 3 如果有240分钟内未关闭的订单,即使达到买入条件也不允许买入(冷却时间)
# pd.Series(sma_signal_list).describe()
data_slot_list = list(signal_df1['data_slot'])
price_list = list(signal_df1['close'])
amt = 5000
open_orders = []
close_orders = []
for i in tqdm.tqdm(range(len(sma_signal_list))):
sma_signal = sma_signal_list[i]
lma_signal = lma_signal_list[i]
price = price_list[i]
data_slot = data_slot_list[i]
sma_thres_signal = sma_signal >=10
lma_thres_signal = lma_signal >=0
if len(open_orders):
last_buy_slot = pd.DataFrame(open_orders)['buy_slot'].max()
else:
last_buy_slot = 0
cool_down_slot = last_buy_slot +240
sma_sell_signal = sma_signal < 0
lma_sell_signal = lma_signal < 0
if sma_thres_signal and lma_thres_signal and (data_slot >=cool_down_slot):
# print('buy')
buy_vol = int(amt / (price * 100)) * 100
order_dict = {}
order_dict['buy_slot'] = data_slot
order_dict['buy_dt'] = slot_ord2str(data_slot)
order_dict['buy_price'] = price
order_dict['buy_vol'] = buy_vol
order_dict['buy_amt'] = buy_vol * price
open_orders.append(order_dict)
if sma_sell_signal and lma_sell_signal:
if len(open_orders):
tem_df = pd.DataFrame(open_orders)
tem_df['sell_slot'] = data_slot
tem_df['sell_price'] = price
tem_df['sell_vol'] = tem_df['buy_vol']
tem_df['sell_amt'] = tem_df['sell_price'] * tem_df['sell_vol']
tem_df['gp'] = tem_df['sell_amt'] - tem_df['buy_amt']
tem_df['gpr'] = tem_df['gp'] / tem_df['buy_amt']
close_orders.append(tem_df)
open_orders = []
运行结束后,没有打开的订单
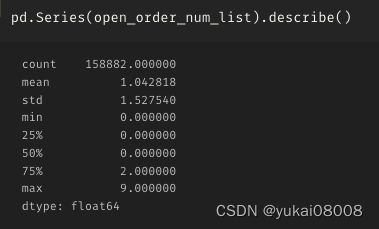
总体来说,这样简单的控制也不会产生大量的敞口:75分位数是2个同时打开的订单(¥10,000),最高的时候有9个(¥45,000)。平均下来,大体上还是可以以¥5,000的(长期)资金占用作为估计的。
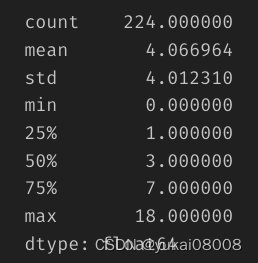
交易时间不是很长,大部分一周之内关闭
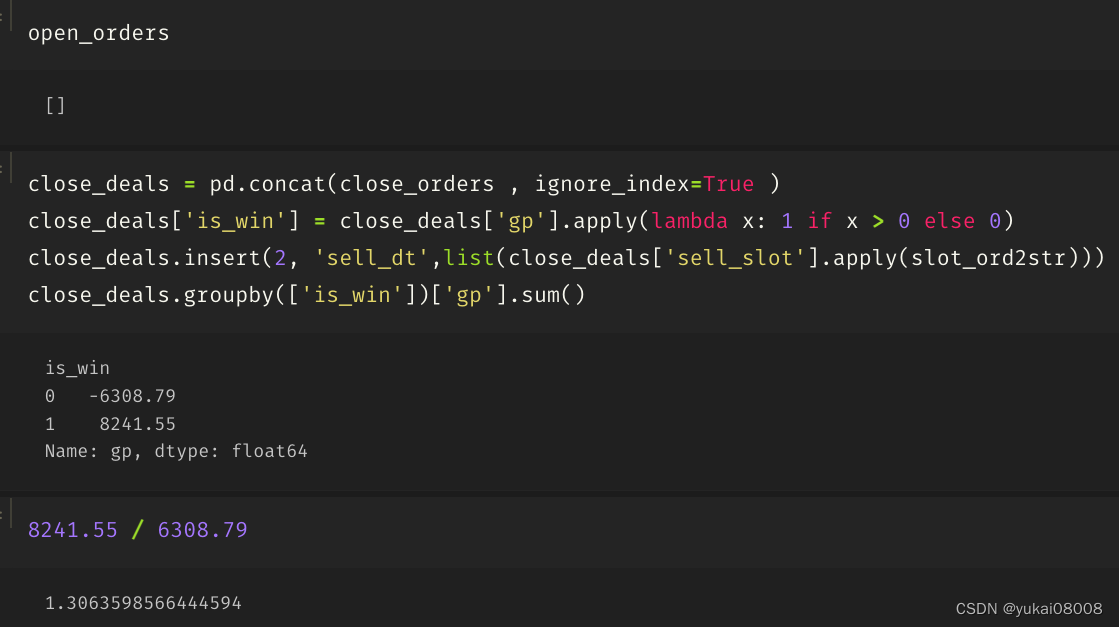
要考虑到这个是初级信号,盈亏比还是不错的,并且这个盈亏比既有统计量上的支持(订单数量),产生的利润金额也足够。
以两年估算,5000本金为例的话大约是年化17%的利润
((1932.7599999999993 + 5000)/5000)**(1/2)
1.1775194265913407
因为其中可能需要更多的临时资金,不妨以10000本金作为一个保守估计
((1932.7599999999993 + 10000)/10000)**(1/2)
1.0923717316005572
所以粗略的,我们可以认为这个原始信号可以产生年化 9%~17%的利润。
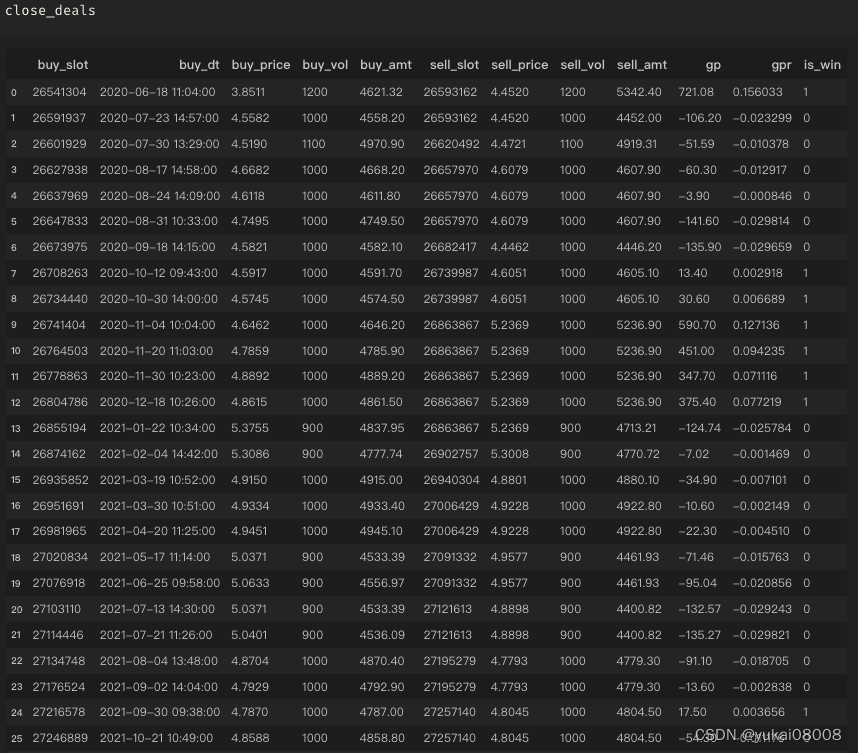
以下是具体的订单明细,可以看看
part1
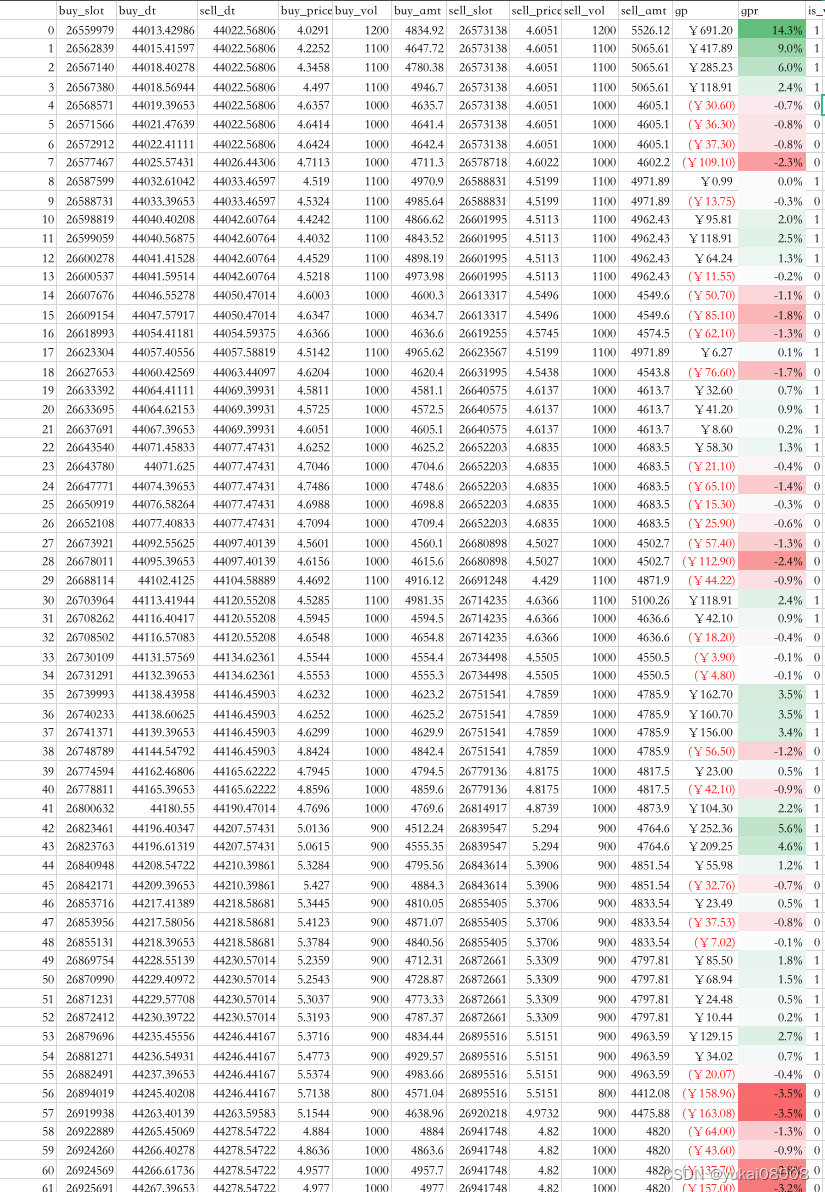
part2
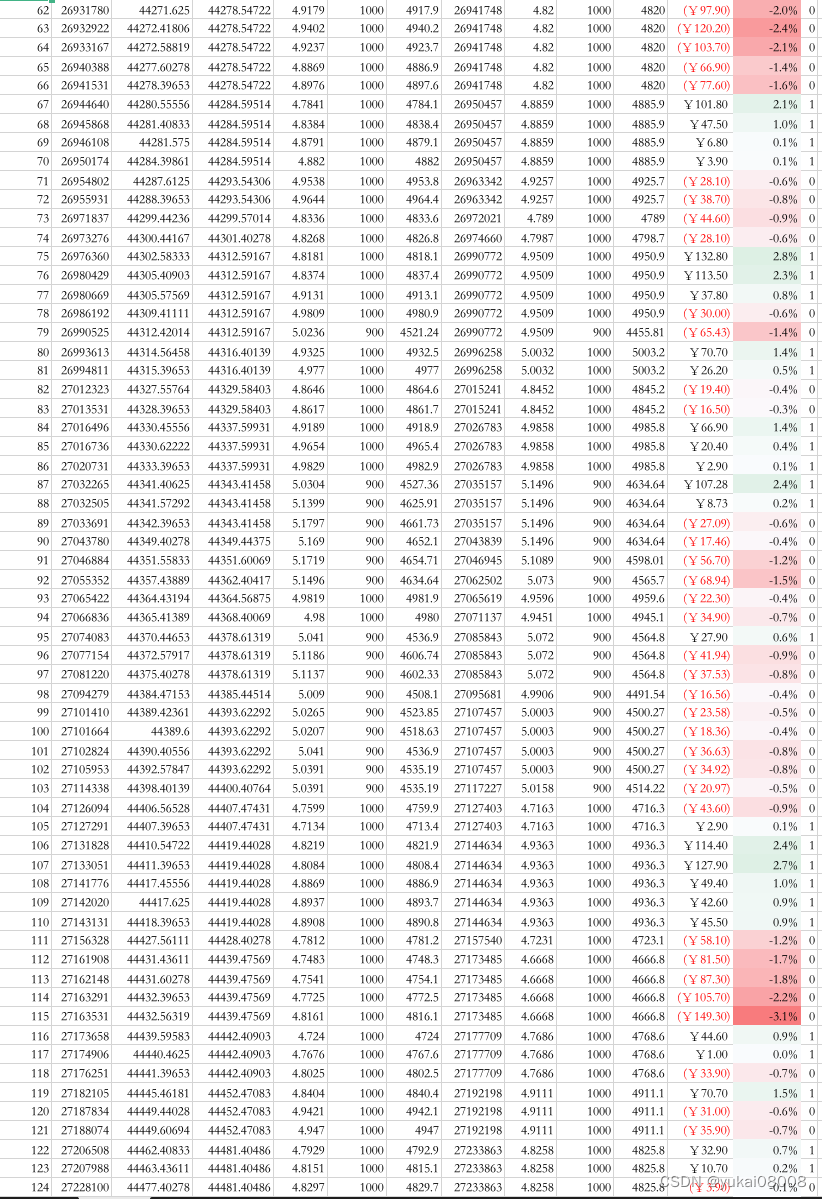
part3
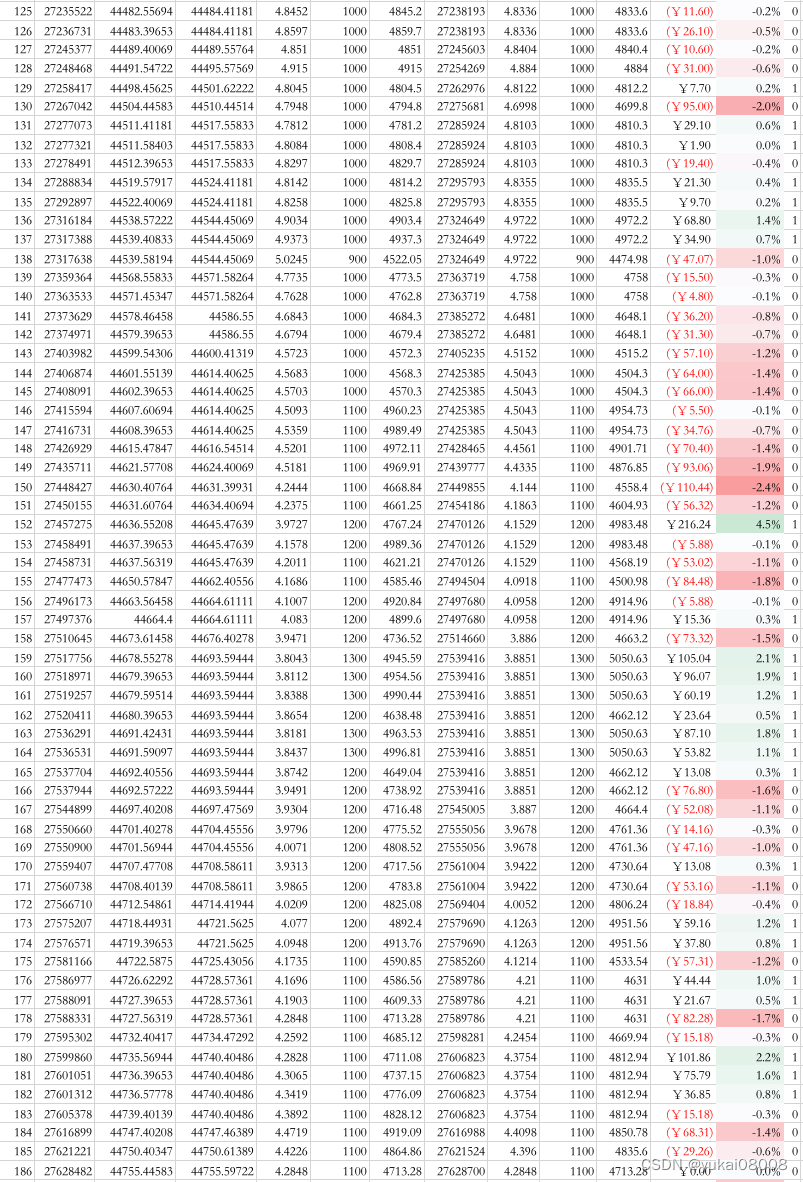
part4
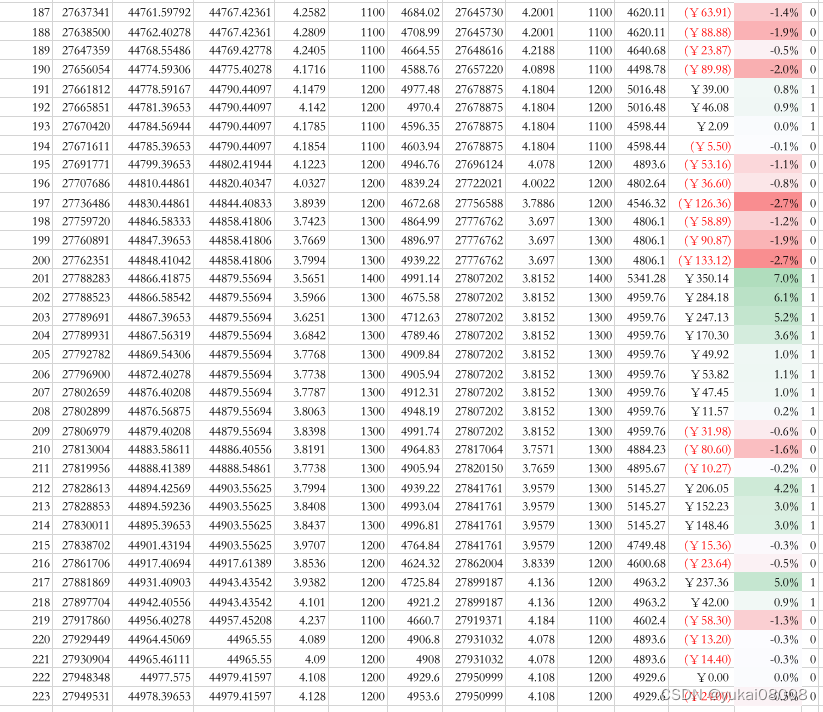
总的看起来是比较理想的:
- 1 输赢比较均匀的分布在整个时间段(说明并无大的结构偏好)
- 2 赢的次数 plus 幅度是明显好于输的
我还试着在几个不同的参数下控制模拟,无论如何,盈亏比总是在1.1以上的,所以也不存在「炼金术的秘方」风险,可以用统计进行解释和控制。
考虑到决策的二次增强,我觉得做到年化15%以上应该是可以的。
4 总结
基于趋势法,可以获得一组稳定的信号源,并获得期望的效果。
接下来对信号方法进行描述,抽象,然后将其部署在ADBS上
- 1 总结信号源的方法(从推理上验证方法的可靠性)
- 2 为Step2创建新的ADBS
- 3 将计算部署到ADBS上