一个不知名大学生,江湖人称菜狗
original author: Jacky Li
Email : 3435673055@qq.comTime of completion:2023.3.5
Last edited: 2023.3.5导读
本文使用SPANNER方式实现对中医药进行实体识别,采用focal loss 进行优化。
本文章作用防止安静在以后的生活中遇到病不去看病导致的身体难受,可以利用该系统对中药进行辨认识别,帮助安静快速病好!
目录
实验目的
模型架构部分
模型训练优化部分
不同方案测试集F1值比较(部分)
作者有言

知识图谱是近年来知识管理和知识服务领域中出现的一项新兴技术,它为中医临床知识的关联、整合与分析提供了理想的技术手段。我们基于中医医案等临床知识源,初步建立了由疾病、证候、症状、方剂、中药等核心概念所构成的中医临床知识图谱,以促进中医临床知识的互融互通,揭示中医方证的相关关系,辅助中医临床研究和临床决策。
中医药学是一门古老的医学,历代医家在数千年的实践中积累了丰富的临床经验,形成了完整的知识体系,产生了海量的临床文献。近年来,国家对中医药事业大力扶持,中医药领域的临床实践和临床研究都取得了长足的发展。中医临床方法在国际社会得到广泛认可,传播到183个国家和地区。
利用信息技术手段开展中医临床知识的管理和服务是一项开创性的探索,在临床上具有极大的应用价值。近年来,知识图谱(Knowledge Graph)成为知识管理领域中的一项新兴技术,因其简单易学、可扩展性强、支持智能应用等优点而得到广泛应用。它有助于实现临床指南、中医医案以及方剂知识等各类知识的关联与整合,挖掘整理中医临证经验与学术思想,实现智能化、个性化的中医药知识服务,因此在中医临床领域具有广阔的应用前景。
实验目的
任务目的是从中医药期刊文献的题目和摘要中识别中医药相关实体,实体类型具体包括:中医诊断、西医诊断、中医证候、临床表现、中医治则、方剂、中药、其他治疗等
提供的训练数据为BIO格式,如:
现 O
头 O
昏 O
口 B-临床表现
苦 I-临床表现
训练集、验证集和测试集同分布,长度范围为[0,150],数据平均长度约37
各标签数量分布非常不均匀,出现最多的的实体是临床表现、西医诊断、中药, 中医诊断、中医治则、其他治疗实体较少,可以考虑补充有相关实体的数据集
模型架构部分
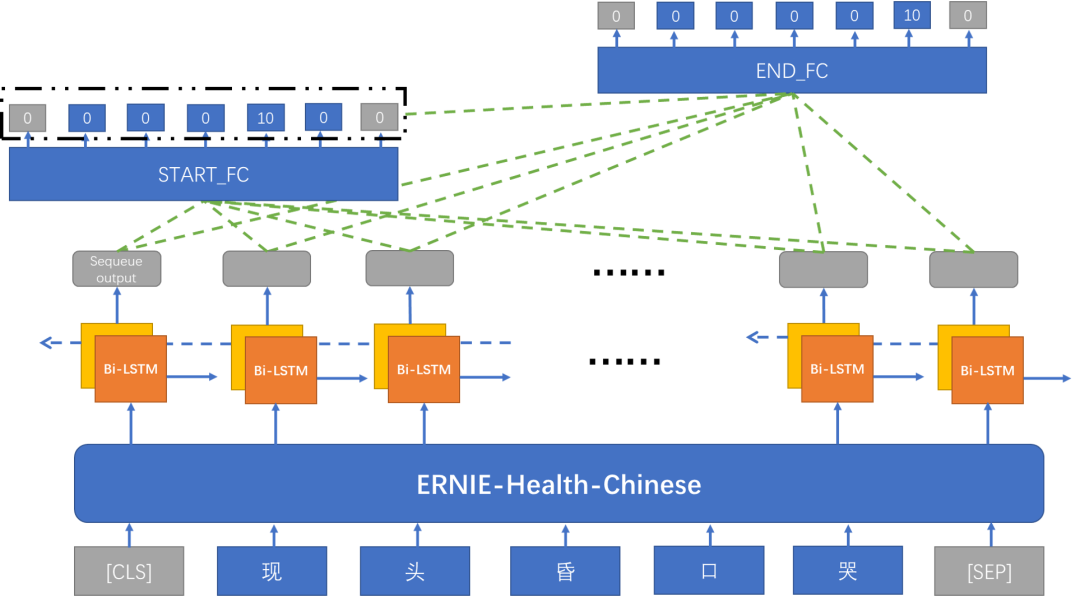
三层架构,底层句子表示层,采用ernie-health-chinese百度开源医疗预训练语言模型进行句子向量表示;第二层LSTM层,将第一层输出作为Bi-LSTM层输入让模型学习前后依赖信息;第三层SPAN预测,将第二层LSTM输出(只取序列输出)放到全连接层1预测实体头,输出shape为[batch_size , seq_len , num_labels],然后实体头预测结果和第二层LSTM输出(只取序列输出,输入shape[batch_size , seq_len , hidden_size * 2+1])放到全连接层2预测实体尾。
模型训练优化部分
根据数据探索性分析,损失函数采用多分类的focal loss(label smooth好像也行但没有实现),降低模型对预测实体标签类别有不同倾向,减少标签分类数量不平衡的影响,提高模型泛化性;fgm/pgd强化训练,训练更平稳,减少模型过拟合情况。优化器采用adamW。
Focal loss是最初由何恺明提出的,最初用于图像领域解决数据不平衡造成的模型性能问题。
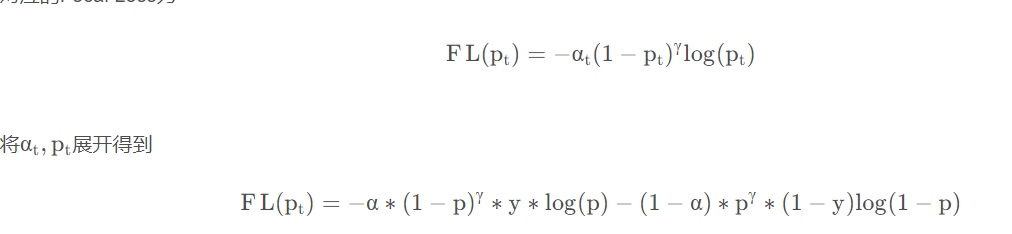
不同方案测试集F1值比较(部分)
| 方案(不包括对抗训练和数据集修正) | 测试集F1值 |
|---|---|
| BERT+LSTM+CRF(baseline) | 0.73919 |
| Ernie-health-ch+Bi-LSTM+CRF(BIO) | 0.78621 |
| Ernie-health-ch+MLP(SPAN) | 0.80161 |
| Nezha-wwm-large-chinese+Bi-LSTM+SPAN_predict(focal loss) | 0.80034 |
| Ernie-health-ch+Bi-LSTM+SPAN_predict(focal loss) | 0.81412 |
对抗训练FMG/PGD提升1个点左右,数据集修正(补充漏标为主)提升3-4个点
作者有言
如果需要代码,请私聊博主,博主看见回。
如果感觉博主讲的对您有用,请点个关注支持一下吧,将会对此类问题持续更新……