读流程从头到尾可以分为如下4个步骤:Client-Server读取交互逻辑,Server端Scan框架体系,过滤淘汰不符合查询条件的HFile,从HFile中读取待查找Key。其中Client-Server交互逻辑主要介绍HBase客户端在整个scan请求的过程中是如何与服务器端进行交互的,理解这点对于使用HBase Scan API进行数据读取非常重要。了解Server端Scan框架体系,从宏观上介绍HBase RegionServer如何逐步处理一次scan请求。接下来的小节会对scan流程中的核心步骤进行更加深入的分析。
HBase读数据的流程更加复杂。主要基于两个方面的原因:一是因为HBase一次范围查询可能会涉及多个Region、多块缓存甚至多个数据存储文件;二是因为HBase中更新操作以及删除操作的实现都很简单,更新操作并没有更新原有数据,而是使用时间戳属性实现了多版本;删除操作也并没有真正删除原有数据,只是插入了一条标记为"deleted"标签的数据,而真正的数据删除发生在系统异步执行Major Compact的时候。很显然,这种实现思路大大简化了数据更新、删除流程,但是对于数据读取来说却意味着套上了层层枷锁:读取过程需要根据版本进行过滤,对已经标记删除的数据也要进行过滤。
一、Client-Server读取交互逻辑
Client-Server通用交互逻辑::Client首先会从ZooKeeper中获取元数据hbase:meta表所在的RegionServer,然后根据待读写rowkey发送请求到元数据所在RegionServer,获取数据所在的目标RegionServer和Region(并将这部分元数据信息缓存到本地),最后将请求进行封装发送到目标RegionServer进行处理。
在通用交互逻辑的基础上,数据读取过程中Client与Server的交互有很多需要关注的点。从API的角度看,HBase数据读取可以分为get和scan两类,get请求通常根据给定rowkey查找一行记录,scan请求通常根据给定的startkey和stopkey查找多行满足条件的记录。但从技术实现的角度来看,get请求也是一种scan请求(最简单的scan请求,scan的条数为1)。从这个角度讲,所有读取操作都可以认为是一次scan操作。
注意:
HBase Client端与Server端的scan操作并没有设计为一次RPC请求,这是因为一次大规模的scan操作很有可能就是一次全表扫描,扫描结果非常之大,通过一次RPC将大量扫描结果返回客户端会带来至少两个非常严重的后果:
(1)大量数据传输会导致集群网络带宽等系统资源短时间被大量占用,严重影响集群中其他业务。
(2)客户端很可能因为内存无法缓存这些数据而导致客户端OOM。
实际上HBase会根据设置条件将一次大的scan操作拆分为多个RPC请求,每个RPC请求称为一次next请求,每次只返回规定数量的结果。
scan的客户端示例代码:
public static void scan() {
HTable table=...;
Scan scan=new Scan();
scan.withStartRow(startRow) // 设置检索起始row
.withStopRow(stopRow) // 设置检索结束row
.setFamilyMap(Map<byte[], Set<byte[]> familyMap>) // 设置检索的列簇和对应列簇下的列集合
.setTimeRange(minStamp, maxStamp) // 设置检索TimeRange
.setMaxVersions(maxVersions) // 设置检索的最大版本号
.setFilter(filter) // 设置检索过滤器
...
scan.setMaxResultSize(10000);
scan.setBatch(100);
ResultScanner rs = table.getScanner(scan);
for (Result r : rs) {
for (KeyValue kv : r.raw()) {
......
}
}
}
(1)for(Result r:rs)语句实际等价于Result r=rs.next()。每执行一次next()操作,客户端先会从本地缓存中检查是否有数据,如果有就直接返回给用户,如果没有就发起一次RPC请求到服务器端获取,获取成功之后缓存到本地。
(2)单次RPC请求的数据条数由参数caching设定,默认为Integer.MAX_VALUE。每次RPC请求获取的数据都会缓存到客户端,该值如果设置过大,可能会因为一次获取到的数据量太大导致服务器端/客户端内存OOM;而如果设置太小会导致一次大scan进行太多次RPC,网络成本高。
(3)对于很多特殊业务有可能一张表中设置了大量(几万甚至几十万)的列,这样一行数据的数据量就会非常大,为了防止返回一行数据但数据量很大的情况,客户端可以通过setBatch方法设置一次RPC请求的数据列数量。
(4)客户端还可以通过setMaxResultSize方法设置每次RPC请求返回的数据量大小(不是数据条数),默认是2G。
二、Server端Scan框架体系
一次scan可能会同时扫描一张表的多个Region,对于这种扫描,客户端会根据hbase:meta元数据将扫描的起始区间[startKey,stopKey)进行切分,切分成多个互相独立的查询子区间,每个子区间对应一个Region。比如当前表有3个Region,Region的起始区间分别为:[“a”,“c”),[“c”,“e”),[“e”,“g”),客户端设置scan的扫描区间为[“b”,“f”)。因为扫描区间明显跨越了多个Region,需要进行切分,按照Region区间切分后的子区间为[“b”,“c”),[“c”,“e”),[“e”,“f”)。
HBase中每个Region都是一个独立的存储引擎,因此客户端可以将每个子区间请求分别发送给对应的Region进行处理。下文会聚焦于单个Region处理scan请求的核心流程。
RegionServer接收到客户端的get/scan请求之后做了两件事情:首先构建scanner iterator体系;然后执行next函数获取KeyValue,并对其进行条件过滤。
1,构建Scanner Iterator体系
Scanner的核心体系包括三层Scanner:RegionScanner,StoreScanner,MemStoreScanner和StoreFileScanner。
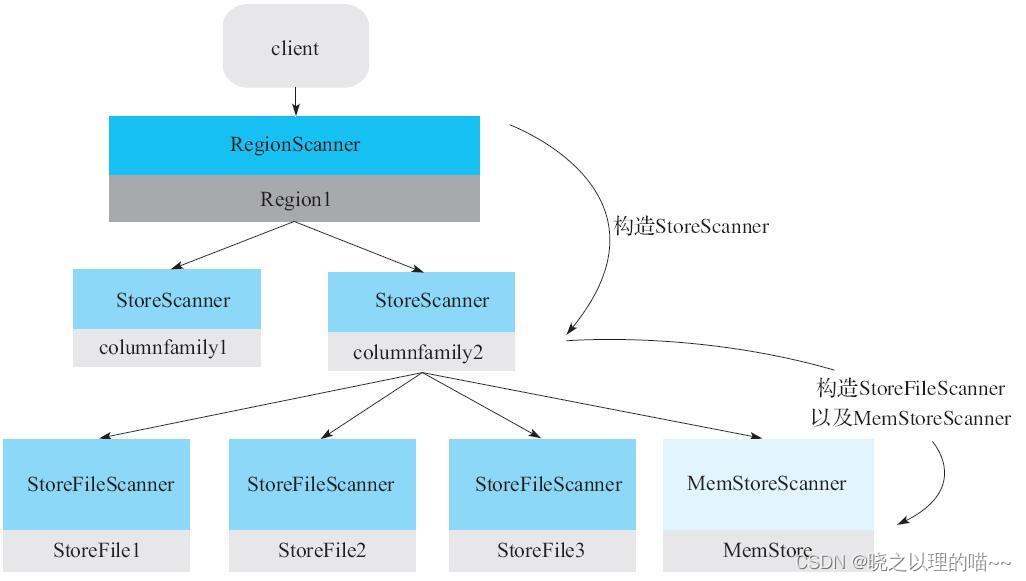
三者是层级的关系:
(1)一个RegionScanner由多个StoreScanner构成。一张表由多少个列簇组成,就有多少个StoreScanner,每个StoreScanner负责对应Store的数据查找。
(2)一个StoreScanner由MemStoreScanner和StoreFileScanner构成。每个Store的数据由内存中的MemStore和磁盘上的StoreFile文件组成。相对应的,StoreScanner会为当前该Store中每个HFile构造一个StoreFileScanner,用于实际执行对应文件的检索。同时,会为对应MemStore构造一个MemStoreScanner,用于执行该Store中MemStore的数据检索。
注意:RegionScanner以及StoreScanner并不负责实际查找操作,它们更多地承担组织调度任务,负责KeyValue最终查找操作的是StoreFileScanner和MemStoreScanner。
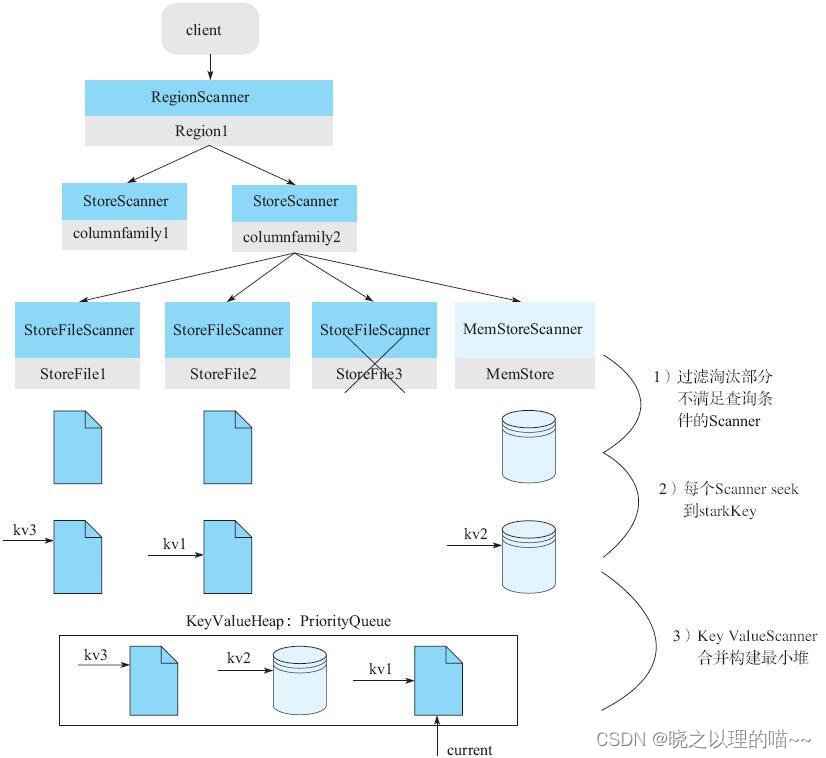
构造好三层Scanner体系之后准备工作并没有完成,还需要以下几个非常核心的关键步骤:
1)过滤淘汰部分不满足查询条件的Scanner。StoreScanner为每一个HFile构造一个对应的StoreFileScanner,需要注意的事实是,并不是每一个HFile都包含用户想要查找的KeyValue,相反,可以通过一些查询条件过滤掉很多肯定不存在待查找KeyValue的HFile。主要过滤策略有:Time Range过滤、Rowkey Range过滤以及布隆过滤器,具体的过滤细节详见6.3.3节。图6-11中StoreFile3检查未通过而被过滤淘汰。
2)每个Scanner seek到startKey。这个步骤在每个HFile文件中(或MemStore)中seek扫描起始点startKey。如果HFile中没有找到starkKey,则seek下一个KeyValue地址。HFile中具体的seek过程比较复杂。
3)KeyValueScanner合并构建最小堆。将该Store中的所有StoreFileScanner和MemStoreScanner合并形成一个heap(最小堆),所谓heap实际上是一个优先级队列。在队列中,按照Scanner排序规则将Scanner seek得到的KeyValue由小到大进行排序。最小堆管理Scanner可以保证取出来的KeyValue都是最小的,这样依次不断地pop就可以由小到大获取目标KeyValue集合,保证有序性。
2,执行next函数获取KeyValue并对其进行条件过滤
经过Scanner体系的构建,KeyValue此时已经可以由小到大依次经过KeyValueScanner获得,但这些KeyValue是否满足用户设定的TimeRange条件、版本号条件以及Filter条件还需要进一步的检查。
检查规则如下:
(1)检查该KeyValue的KeyType是否是Deleted/DeletedColumn/DeleteFamily等,如果是,则直接忽略该列所有其他版本,跳到下列(列簇)。
(2)检查该KeyValue的Timestamp是否在用户设定的Timestamp Range范围,如果不在该范围,忽略。
(3)检查该KeyValue是否满足用户设置的各种filter过滤器,如果不满足,忽略。
(4)检查该KeyValue是否满足用户查询中设定的版本数,比如用户只查询最新版本,则忽略该列的其他版本;反之,如果用户查询所有版本,则还需要查询该cell的其他版本。
三、过滤淘汰不符合查询条件的HFile
过滤StoreFile发生在KeyValueScanner合并构建最小堆,过滤手段主要有三种:根据KeyRange过滤,根据TimeRange过滤,根据布隆过滤器进行过滤。
(1)根据KeyRange过滤:因为StoreFile中所有KeyValue数据都是有序排列的,所以如果待检索row范围[startrow,stoprow]与文件起始key范围[firstkey,lastkey]没有交集,比如stoprow<firstkey或者startrow>lastkey,就可以过滤掉该StoreFile。
(2)根据TimeRange过滤:StoreFile中元数据有一个关于该File的TimeRange属性[miniTimestamp,maxTimestamp],如果待检索的TimeRange与该文件时间范围没有交集,就可以过滤掉该StoreFile;另外,如果该文件所有数据已经过期,也可以过滤淘汰。
(3)根据布隆过滤器进行过滤:StoreFile中布隆过滤器相关Data Block结构在第5章已经做过介绍,系统根据待检索的rowkey获取对应的Bloom Block并加载到内存(通常情况下,热点BloomBlock会常驻内存的),再用hash函数对待检索rowkey进行hash,根据hash后的结果在布隆过滤器数据中进行寻址,即可确定待检索rowkey是否一定不存在于该HFile。
四、从HFile中读取待查找Key

1,根据HFile索引树定位目标Block
HRegionServer打开HFile时会将所有HFile的Trailer部分和Load-on-open部分加载到内存,Load-on-open部分有个非常重要的Block——Root Index Block,即索引树的根节点。
BlockKey是整个Block的第一个rowkey,如Root Index Block中"a",“m”,“o”,"u"都为BlockKey。Block Offset表示该索引节点指向的Block在HFile的偏移量。
HFile索引树索引在数据量不大的时候只有最上面一层,随着数据量增大开始分裂为多层,最多三层。
一次查询的索引过程,基本流程可以表示为:
(1)用户输入rowkey为’fb’,在Root Index Block中通过二分查找定位到’fb’在’a’和’m’之间,因此需要访问索引’a’指向的中间节点。因为Root Index Block常驻内存,所以这个过程很快。
(2)将索引’a’指向的中间节点索引块加载到内存,然后通过二分查找定位到fb在index’d’和’h’之间,接下来访问索引’d’指向的叶子节点。
(3)同理,将索引’d’指向的中间节点索引块加载到内存,通过二分查找定位找到fb在index’f’和’g’之间,最后需要访问索引’f’指向的Data Block节点。
(4)将索引’f’指向的Data Block加载到内存,通过遍历的方式找到对应KeyValue。
上述流程中,Intermediate Index Block、Leaf Index Block以及Data Block都需要加载到内存,所以一次查询的IO正常为3次。但是实际上HBase为Block提供了缓存机制,可以将频繁使用的Block缓存在内存中,以便进一步加快实际读取过程。
2,BlockCache中检索目标Block
BlockCache组件在第5章做过详细介绍,根据内存管理策略的不同经历了LRUBlockCache、SlabCache以及BucketCache等多个方案的发展,在内存管理优化、GC优化方面都有了很大的提升。
但无论哪个方案,从BlockCache中定位待查Block都非常简单。Block缓存到BlockCache之后会构建一个Map,Map的Key是BlockKey,Value是Block在内存中的地址。其中BlockKey由两部分构成——HFile名称以及Block在HFile中的偏移量。BlockKey很显然是全局唯一的。根据BlockKey可以获取该Block在BlockCache中内存位置,然后直接加载出该Block对象。如果在BlockCache中没有找到待查Block,就需要在HDFS文件中查找。
3,HDFS文件中检索目标Block
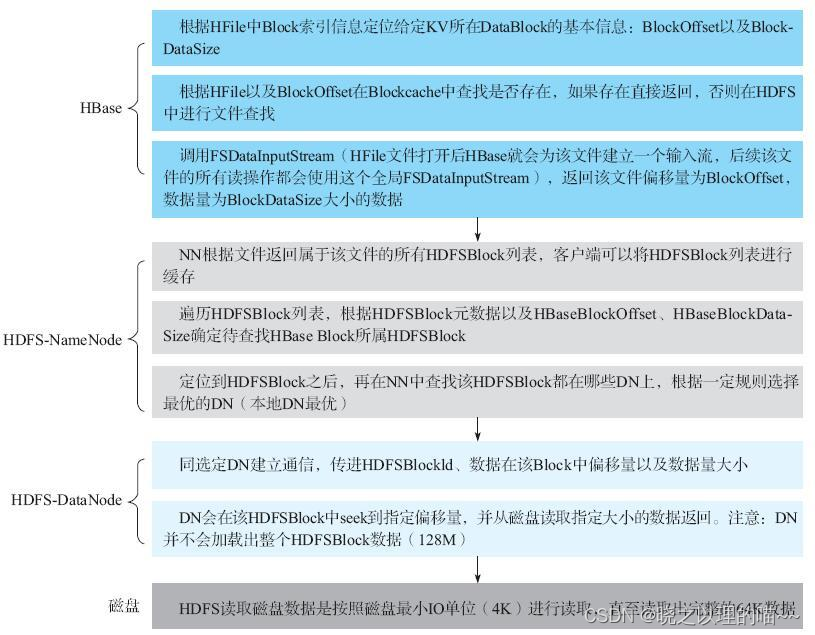
根据文件索引提供的Block Offset以及Block DataSize这两个元素可以在HDFS上读取到对应的Data Block内容(核心代码可以参见HFileBlock.java中内部类FSReaderImpl的readBlockData方法)。这个阶段HBase会下发命令给HDFS,HDFS执行真正的Data Block查找工作。
整个流程涉及4个组件:HBase、NameNode、DataNode以及磁盘。其中HBase模块做的事情上文已经做过了说明,需要特别说明的是FSDataInputStream这个输入流,HBase会在加载HFile的时候为每个HFile新建一个从HDFS读取数据的输入流——FSDataInputStream,之后所有对该HFile的读取操作都会使用这个文件级别的InputStream进行操作。
使用FSDataInputStream读取HFile中的数据块,命令下发到HDFS,首先会联系NameNode组件。NameNode组件会做两件事情:
(1)找到属于这个HFile的所有HDFSBlock列表,确认待查找数据在哪个HDFSBlock上。众所周知,HDFS会将一个给定文件切分为多个大小等于128M的Data Block,NameNode上会存储数据文件与这些HDFSBlock的对应关系。
(2)确认定位到的HDFSBlock在哪些DataNode上,选择一个最优DataNode返回给客户端。HDFS将文件切分成多个HDFSBlock之后,采取一定的策略按照三副本原则将其分布在集群的不同节点,实现数据的高可靠存储。HDFSBlock与DataNode的对应关系存储在NameNode。
NameNode告知HBase可以去特定DataNode上访问特定HDFSBlock,之后,HBase会再联系对应DataNode。DataNode首先找到指定HDFSBlock,seek到指定偏移量,并从磁盘读出指定大小的数据返回。
DataNode读取数据实际上是向磁盘发送读取指令,磁盘接收到读取指令之后会移动磁头到给定位置,读取出完整的64K数据返回。
4,从Block中读取待查找KeyValue
HFile Block由KeyValue(由小到大依次存储)构成,但这些KeyValue并不是固定长度的,只能遍历扫描查找。
文章来源:《HBase原理与实践》 作者:胡争;范欣欣
文章内容仅供学习交流,如有侵犯,联系删除哦!