
Hadoop集群安装配置
当hadoop采用分布式模式部署和运行时,存储采用分布式文件系统HDFS,此时HDFS名称节点和数据节点位于不同的机器上;
数据就可以分布到多个节点,不同的数据节点上的数据计算可以并行执行了,这时候MR才能发挥其本该有的作用;
没那么多机器怎么办~~~~多几个虚拟机不就行了
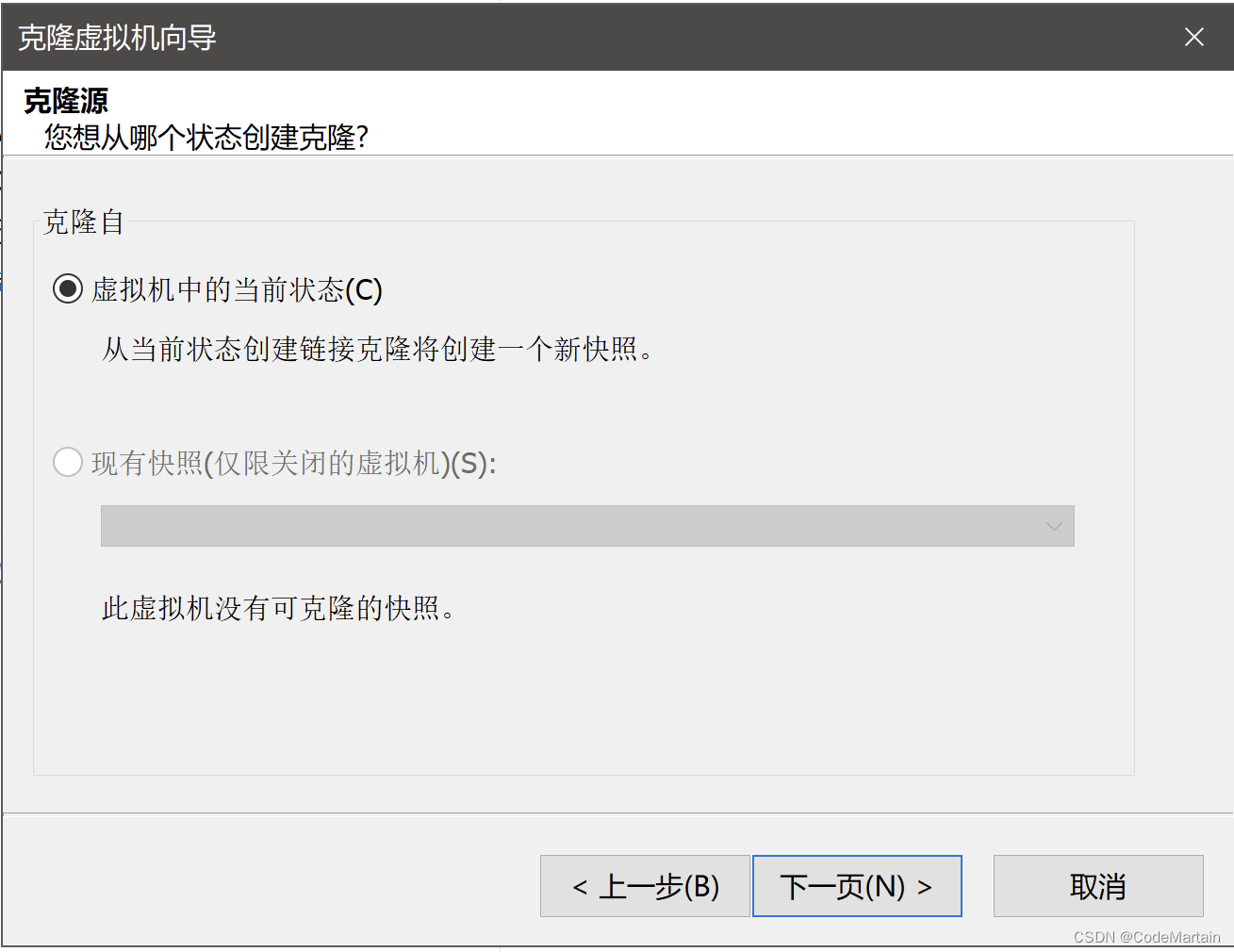
克隆虚拟机
电脑存储不够的可以使用链接克隆的方式
修改虚拟机的网络配置~
以其中一个slave节点为例
- 启动虚拟机
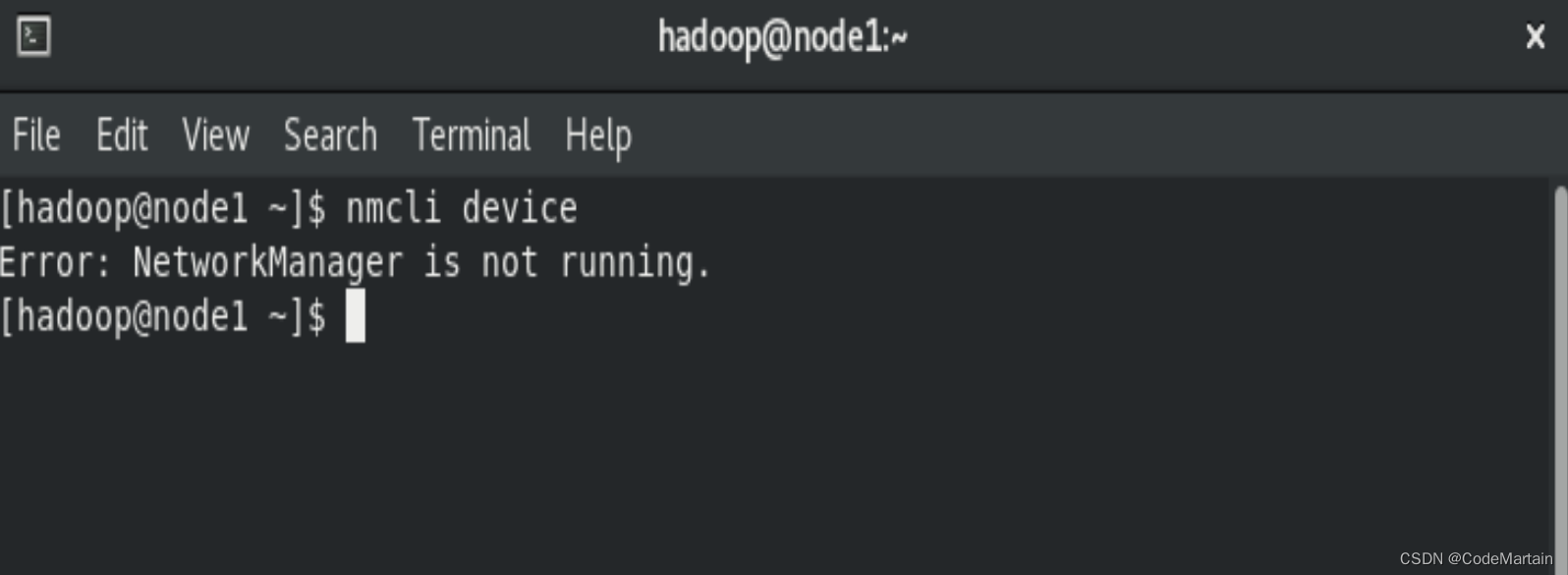
- 关闭网卡服务,然后修改节点的ip
由于本节点启动时默认没有启动网卡,所以就不关闭了,
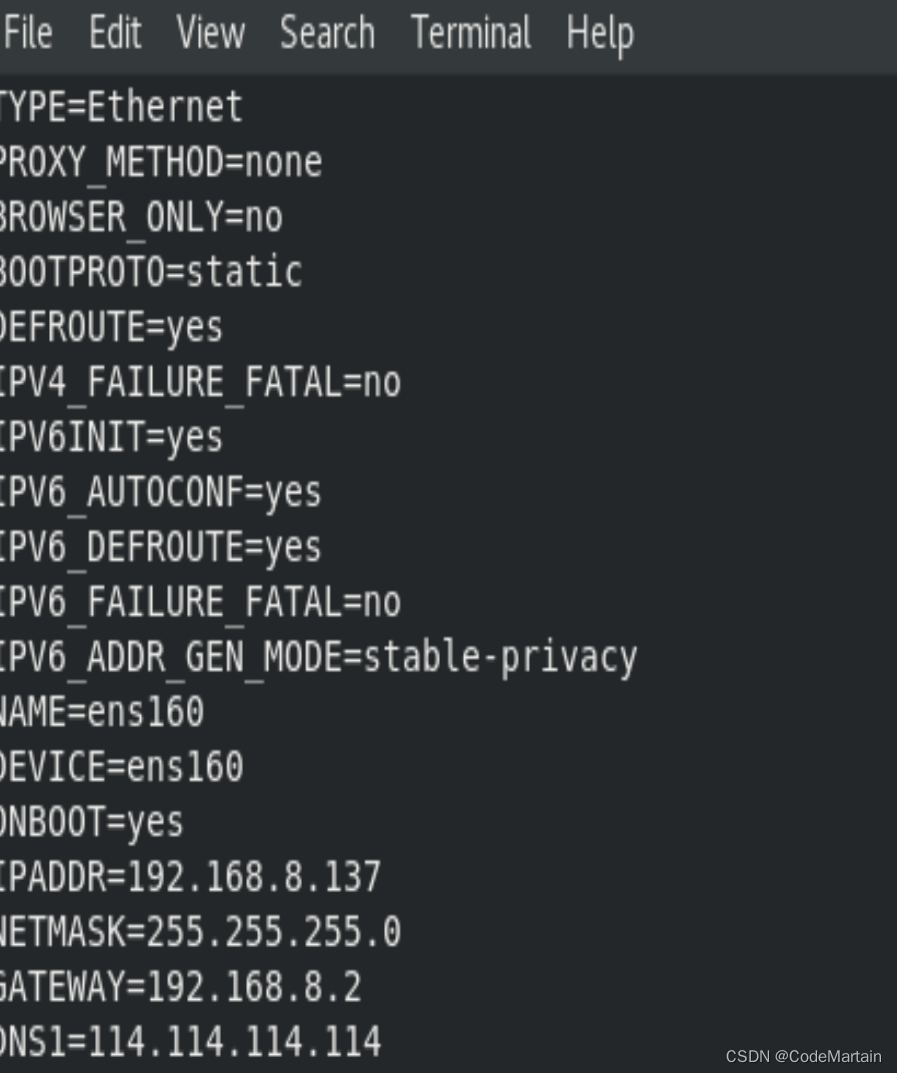
- 修改节点ip为静态IP
vi /etc/sysconfig/network-scripts/ifcfg-ens160
修改成如下地址:
- 设置网卡自动启动后启动网卡
[root@node1 hadoop]# vi /etc/sysconfig/network-scripts/ifcfg-ens160
[root@node1 hadoop]# systemctl enable NetworkManager
Created symlink /etc/systemd/system/multi-user.target.wants/NetworkManager.service → /usr/lib/systemd/system/NetworkManager.service.
Created symlink /etc/systemd/system/dbus-org.freedesktop.nm-dispatcher.service → /usr/lib/systemd/system/NetworkManager-dispatcher.service.
Created symlink /etc/systemd/system/network-online.target.wants/NetworkManager-wait-online.service → /usr/lib/systemd/system/NetworkManager-wait-online.service.
[root@node1 hadoop]# systemctl start NetworkManager
[root@node1 hadoop]#
- ping一下其他节点
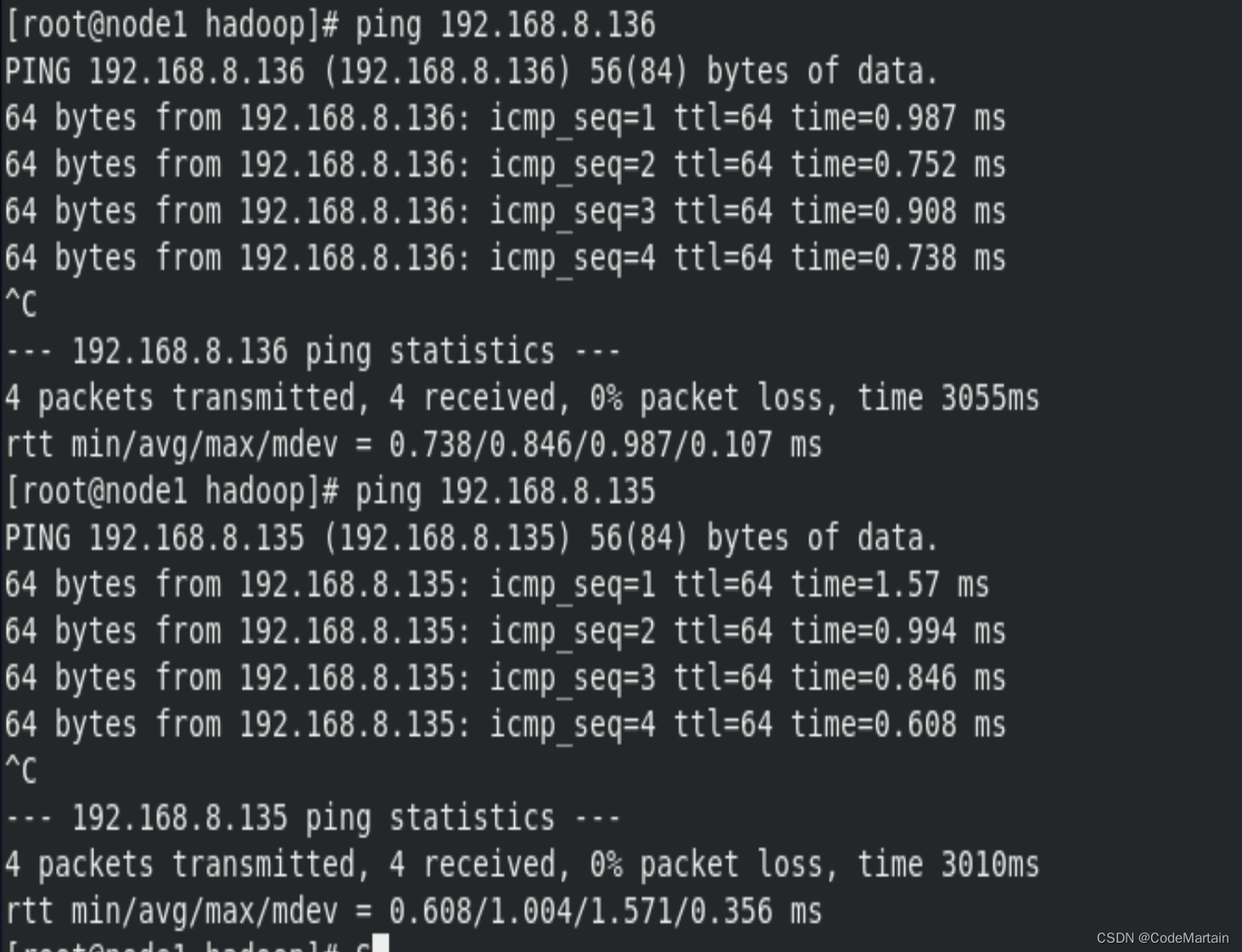 可以正常ping通,我们的机器就准备好了
可以正常ping通,我们的机器就准备好了
为了便于区分节点,我们还需要修改各个节点的主机名
修改之后的具体配置如下
| 节点 | 节点名 | ip |
|---|---|---|
| master | master | 192.168.8.135 |
| slave1 | slave1 | 192.168.8.136 |
| slave2 | slave2 | 192.168.8.137 |
| slave3 | slave3 | 192.168.8.138 |
然后在虚拟机各个节点中添加映射关系
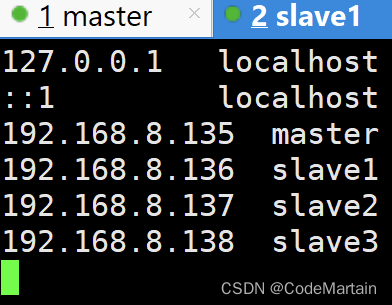
记得修改之后重启虚拟机
之后登录虚拟机就很容易辨认出当前是处于Master节点上进行操作,不会和Slave节点产生混淆。
 重启之后测试一下配置是否成功
重启之后测试一下配置是否成功
- 在master节点上ping一下slave*节点
#ping 3次就停止
ping slave1 -c 3
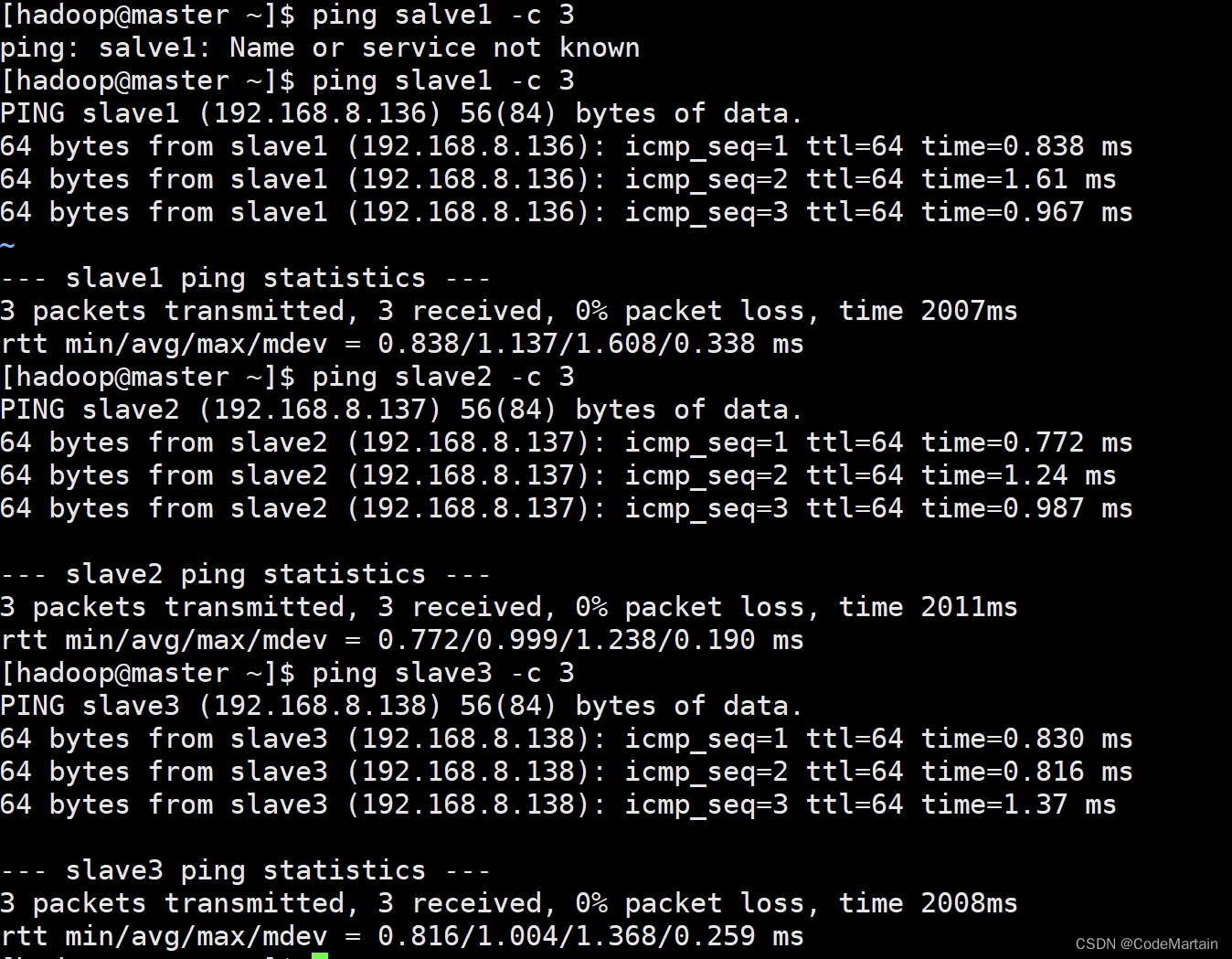 其他的节点自己测试一下就可以,这里不再展示
其他的节点自己测试一下就可以,这里不再展示
如果ping不通:
1,可能你没有重启机器
2,配置的文件内容检查一下










![[1.3_2]计算机系统概述——中断和异常](https://img-blog.csdnimg.cn/d13cbc2731014ff4acd0a40eb10e5841.png)