文章目录
- 1. 基础
- 2. 用户访问
- 3. Pytorch环境的问题
- 4. 显卡调度问题
- 方法一:在shell命令前强制指定显卡
- 方法二:在代码中强制指定显卡
- 5. 各种各样的小BUG
- 5.1 Liunx创建新用户登录异常:/usr/bin/xauth: error/timeout in locking authority file /home/user/.Xauthority
- 5.2 服务器更换了地方连不上网,只有IPV6地址,ping不通
实验室刚到一台Dell服务器主机,里面配置一张RTX 4090和RTX 3090显卡,弄了好久终于能成功运行PyTorch深度学习模型,现在将过程描述如下:
1. 基础
首先是系统,选择的是Ubantu 18.02版本,这个直接下载安装就不说了,直接下一步下一步,没什么问题
然后是显卡驱动,这个由于我们的主机是4090,所以下载的最新的显卡驱动525
下载后出现第一个坑:如果你和我们一样,有两张不平衡的显卡,那么下载显卡驱动极有可能会下载的低等级的那个驱动,导致开机异常,表现为开不了机,屏幕一直闪
解决方法:只留高的显卡,我们只留了4090,然后成功可以开机,安装好4090的驱动后,再将3090插入,依然可以启动
解决完举动之后,安装conda和CUDA,conda没什么好说的,直接anaconda3官网下载安装,至于CUDA,这里我们选择的是最新的CUDA 12.0,在官网搜索下载即可,下载安装后需要更新bashrc文件:
使用vim ~/.bashrc打开文件,没有vim就按照提示安装vim或使用gedit。随后在文件底部添加:
export PATH="/usr/local/anaconda3/bin:$PATH"
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda12.0/lib64
export PATH=$PATH:/usr/local/cuda-12.0/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-12.0
第一句是conda的命令,后三句是cuda的命令,记得改成自己的相应路径
2. 用户访问
首先需要将该主机设置为可以用ssh访问的状态,这个自行百度即可,但千万注意端口号的修改,我们当时就是因为端口号没有修改成可用状态搁置了很久。
设置完后创建用户,这里出现第二个坑,创建用户后出现无法登陆的BUG,经检查后发现是useradd -d命令没有生成对应的目录导致无法登陆,解决方法是在后面加上一句-m,但加上-m后会出现第三个坑,登陆后没有用户名,只有一个$,解决方法是在useradd 后面加上 -s /bin/bash,最后使用的添加用户的命令为:
useradd 用户名 -d /home/user_1/用户名 -m -s /bin/bash
随后设置相应的密码:
passwd 用户名
创建用户后登录,需要设置bashrc文件以运行显卡
输入代码
vim ~/.bashrc
在尾部添加代码:
export PATH="/usr/local/anaconda3/bin:$PATH"
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.0/lib64
export PATH=$PATH:/usr/local/cuda-12.0/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-12.0
更新bashrc:
source ~/.bashrc
初始化conda:
conda init
如果提示没有conda就关闭连接重新ssh接入,再输入
再次连接ssh即可使用conda
3. Pytorch环境的问题
这个是最麻烦的,你或许尝试过conda,尝试过pip,尝试过反复复制Pytorch官网的下载命令,但最后总得到 torch.cuda.is_available()的结果为False
那么这个时候就不要妄想通过PyTorch官网的命令来安好了,什么去掉-c之类的,多半是没有用的,解决办法就是去PyTorch官网去找自己的whl文件下载来安装。具体如下:
首先看到pip命令下面的下载链接:
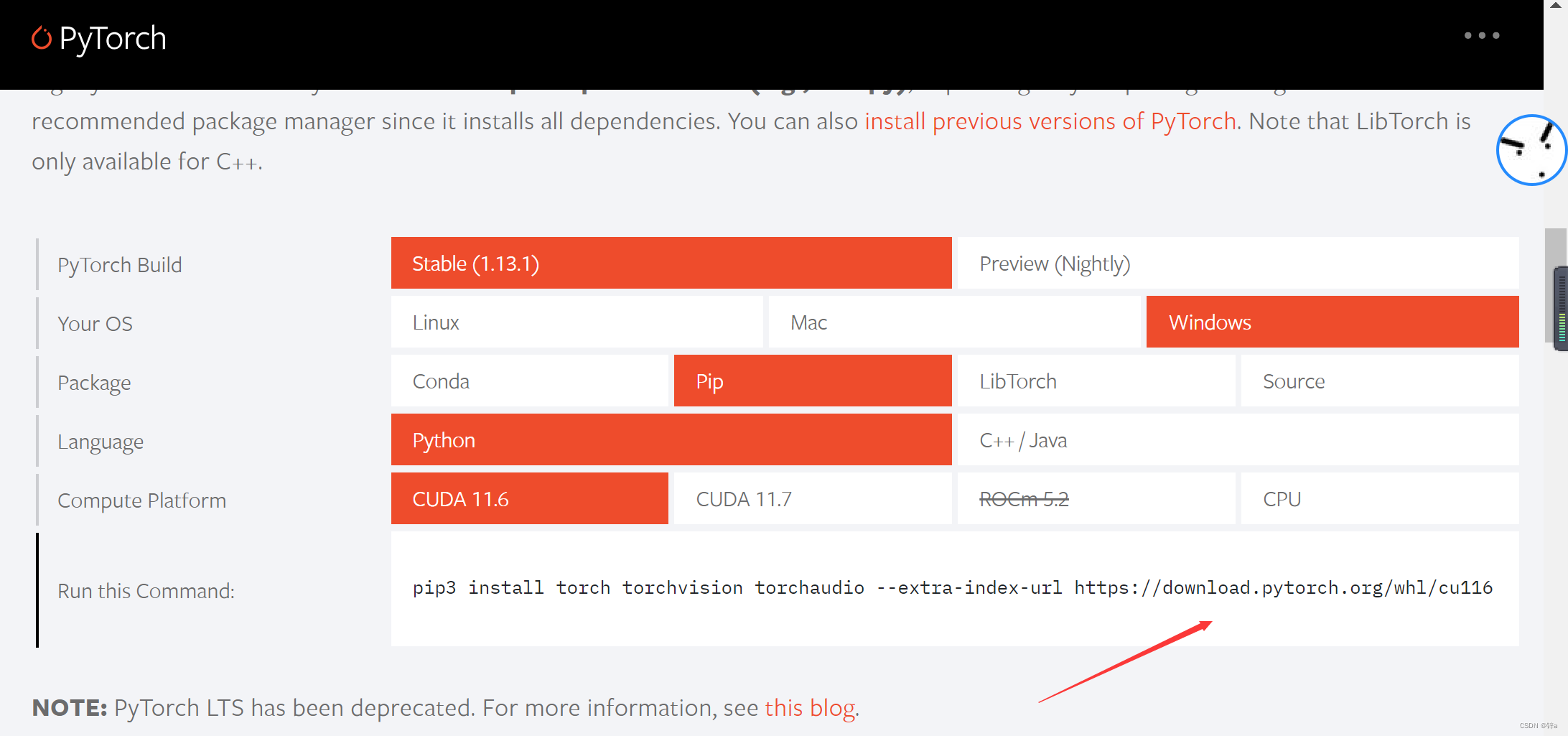
点进去之后会有下载选项,一般需要下载以下三个依赖包:

这里以PyTorch为例子,点进去之后选择想要的版本,cp指的是python版本,cu指的是cuda版本,一定不能下错,这里以python3.7,cuda11.7为例:
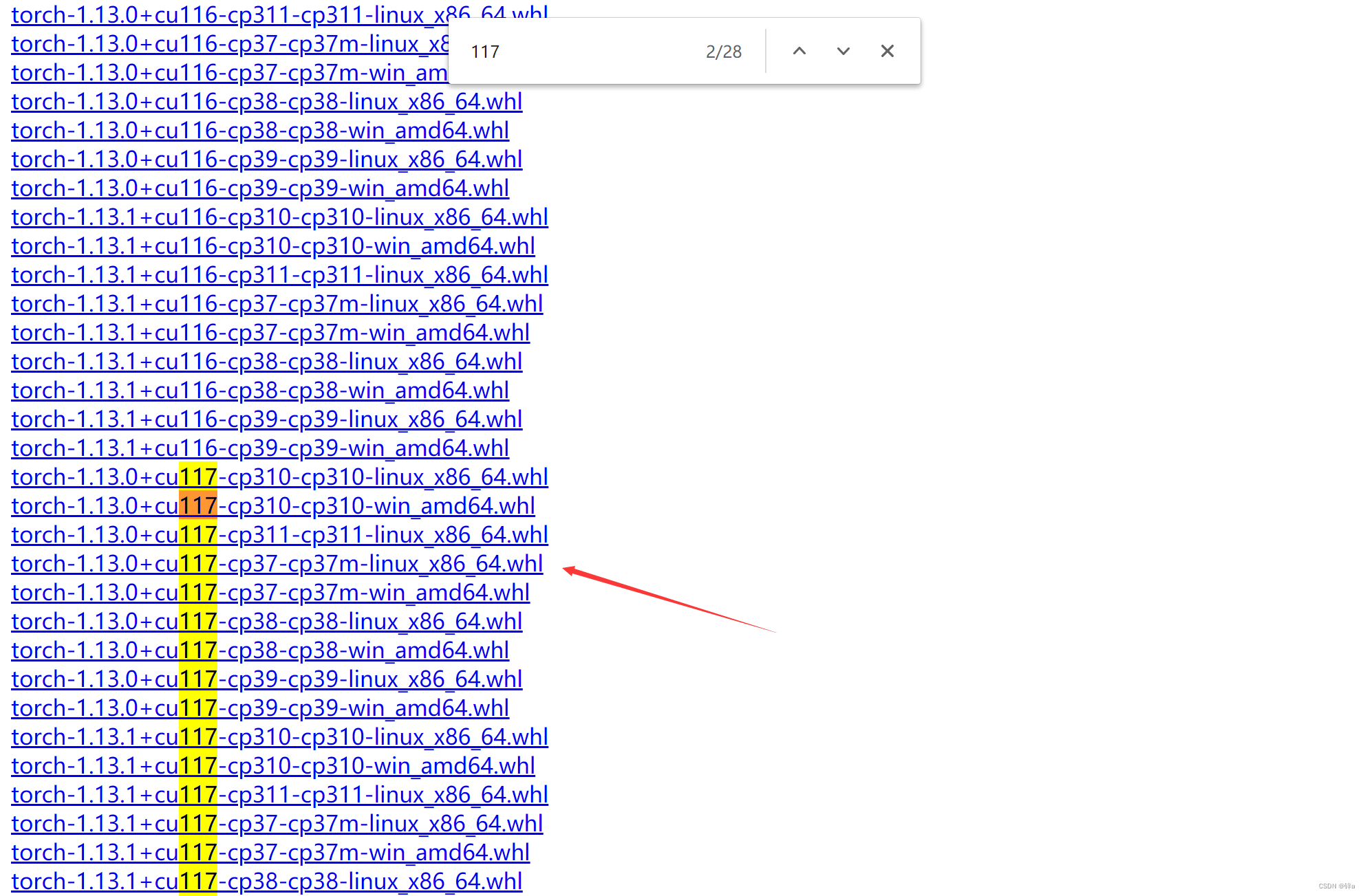
下载后通过winscp传输到服务器中,或者使用U盘传送到服务器中,使用pip install xx.whl安装即可
如果出现报错那么极有可能是:1,python版本问题,下载的时候看仔细;2,文件传输损坏了,重新下载即可。
最后记得验证一下 torch.cuda.is_available(),如果为False则继续重复上述步骤
4. 显卡调度问题
由于我们的服务器配置的显卡型号不一致,使用过程会出现很多问题,显卡不一致不支持双卡并行
我们的是一块4090和一块30-90,尤其是使用4090显卡,若不强制指定会导致3090显卡莫名占用显存,需要设定环境变量,具体如下:
使用4090显卡运行程序示例:
方法一:在shell命令前强制指定显卡
CUDA_VISIBLE_DEVICES="0" python main.py
方法二:在代码中强制指定显卡
在主程序中加入如下代码:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
然后直接运行:python main.py即可
如需使用另一块3090显卡则将 “0”改为 “1”
显卡型号不一致极有可能和我们这个情况一样
若运行中出现如下警告:
`UserWarning:
There is an imbalance between your GPUs. You may want to exclude GPU 1 which
has less than 75% of the memory or cores of GPU 0. You can do so by setting
the device_ids argument to DataParallel, or by setting the CUDA_VISIBLE_DEVICES
environment variable.
warnings.warn(imbalance_warn.format(device_ids[min_pos], device_ids[max_pos]))`
说明显卡没有配置正确,需要ctrl+c停止代码后指定显卡
建议运行代码后,使用 nvidia-smi检查一下显存,如果两张显卡显存同时升高,则显卡指定有误,需要重新指定
5. 各种各样的小BUG
5.1 Liunx创建新用户登录异常:/usr/bin/xauth: error/timeout in locking authority file /home/user/.Xauthority
先使用su创建文件
sudo mkdir /home/user_1/用户名
赋予权限:
chown 用户名:用户名 -R /home/user_1/用户名
usermod -s /bin/bash 用户名
重置bashrc:
cp /etc/skel/.bashrc ~/
重新添加bashrc文件中的conda等环境变量
5.2 服务器更换了地方连不上网,只有IPV6地址,ping不通
解决方法:
首先进入以太网端口,手动设置IPV4的IP地址,这里因人而异,自行咨询网络管理员吧
然后进入etc/network文件(此时应使用su账号)
cd /etc/network
使用vim打开 interfaces文件
vim interfaces
在文件尾端添加你手动输入的IP地址,网关,子网掩码等:
iface 你的网口名称(ipconfig可以看到,一般是enp0) inet static
address 你的IP地址
gatway 你的网关
netmask 你的子网掩码
然后更新网络即可:
service network-manager restart
先写到这里,后续有什么BUG继续更新