梗概
本报告主要调研目前主流的机器学习平台,包括但不限于Amazon的Sage maker,Alibaba的PAI,Baidu的PaddlePaddle。对产品的定位、功能、实践、定价四个方面进行详细解析,并通过标杆对比分析提出一套机器学习平台评价体系,旨在给后续机器学习平台需求分析与实际开发提供评估与优化思路。
目录
引入:机器学习平台简介
1.Sage maker
1.1 产品简介
1.2 功能分析
1.3 产品实践
1.3.1 低代码/无代码ML
1.3.2 IDE/Lab
1.3.3 ML的监测、调度与分析
1.4 产品定价
1.5 产品综述
2.PAI
2.1 产品简介
2.2 功能分析
2.3 产品实践
2.3.1 数据准备:PAI-iTAG
2.3.2 模型开发/构建
2.3.3 模型训练:PAI-DLC
2.3.4 模型部署
2.4 产品定价
2.5 产品综述
3.PaddlePaddle
3.1 产品简介
3.2 功能分析
3.3 产品实践
3.3.1 框架使用
3.3.2 工具组件
3.3.3 端到端开发套件
3.3.4 模型库
3.3.5 部署预测:PaddleLite
3.3.6 AI开发平台
3.4 产品综述
4.标杆分析与总结
4.1 标杆分析
4.2 对比分析
引入:机器学习平台简介
随着大数据、人工智能的火热,机器学习任务迅速渗透到各个领域,对于非代码工程师,一个简单易用的可完成机器学习的工具是必要的,对于代码工程师,ML任务尤其DL任务数据与模型大小快速膨胀,需要通过自动化、云端资源等手段来提高效率,处理ML任务,故机器学习平台开始被构建并逐渐火热。
一般来说,一个机器学习平台需要具备数据接入、数据处理、模型构建、训练、验证、部署、监控与结果分析可视化等基本功能,且还要在框架支持度、效率成本协调、技术架构选择等多方面考虑。
1.Sage maker
1.1 产品简介
本节首先对Sage maker进行基本情况的介绍,总结如表1:
表1 Sage maker简介
| 来源(开发商)/ 官网 | Amazon / https://aws.amazon.com/cn/sagemaker/ |
| 产品官方定位 | 通过完全托管的基础设施、工具和工作流程为任何用例构建、训练和部署机器学习 (ML) 模型 |
| 产品与开发文档 | https://aws.amazon.com/cn/sagemaker/resources/ |
在官网中对产品的定位有进行一定描述性的补充,如图1所示:

图1 Sage maker定位补充描述
根据官网描述与调研分析,Sage maker的几大核心竞争优势如下:
Ⅰ、让更多人利用机器学习进行创新
Sage maker根据用户类型开发提供了对应的适应子产品,主要目标人群及子产品总结如表2:
表2 Sage maker子产品及对应目标人群
| 目标人群 | 子产品及简介 |
| 业务分析师(BA) | SageMaker Canvas:提供一个无代码、可视化、点击式的ML预测工具,包含多模型,可与数据科学家协同开发,集成于常见的BI工具中 |
| 数据科学家 | SageMaker Studio:主要从数据角度分析数据科学研究相关问题,提供一个适用于ML生命周期的全集成IDE |
| ML工程师 | SageMaker MLOps:提供一个快速、大规模、高性能的机器学习模型开发与管理平台 |
补充:针对ML初学者,AWS提供了SageMaker Studio Lab进行学习与试验,在不同的子产品中均有详细的产品文档与演示视频教学。
Ⅱ、支持领先的机器学习框架、工具包和编程语言
Sage maker支持大量主流机器学习语言与框架,如图2所示,增加用户的广度与模型的稳定性与可迁移性。

图2 Sage maker框架、工具、语言支持汇总
补充:Sage maker同时集成了多种API,适应多种软件开发工具(Android、JS、iOS等)
Ⅲ、大规模的高性能、低成本ML
Sage maker 建立在 Amazon 二十年来开发现实世界 ML 应用程序的经验之上,这些应用程序包括产品推荐、个性化、智能购物、机器人技术和语音辅助设备,根据官方数据,Sage maker对用户的服务提升如图3所示:

图3 Sage maker对用户的服务提升数据
Ⅳ、客户的优质选择
众多优秀、成功的客户选择使用Sage maker,达成了长期、可持续的合作关系。
Ⅴ、产品文档与日志系统
除了Sage maker的产品文档,Amazon为其相关子产品均建立了详细的文档供学习者与用户使用。此外,官网主页还配备了日志系统,及时发布Sage maker的新功能或优化。
1.2 功能分析
本节主要对Sage maker的功能进行详细的介绍与分析,简介汇总如表3:
表3 Sage maker功能及简介
| 功能 | 简介 |
| 自动模型(超参数)优化 | 按用户指定的ML模型、指标、要搜索的超参数,通过指定的算法与超参数范围在数据集上多次训练来找到模型的最佳版本 |
| Autopilot | 根据用户的数据自动构建、训练和调整最佳 ML 模型,同时保持完全控制和可见性(提供模型与功能排行榜供选择),并支持一键部署模型 |
| Canvas | 无代码的点击式可视化工具,用于ML的预测,支持不同来源的模型与跨工具数据共享 |
| Clarify | 使用各种指标检测和测量潜在偏差,以便他们能够解决潜在偏差并解释模型预测 |
| Data Wrangler | 缩短汇总和准备ML数据的时间,并从单个可视化界面完成数据准备工作流程的每个步骤(包括数据选择、清理、探索和可视化) |
| 调试程序(Debugger) | 通过实时自动捕获训练指标,检测到异常时发送警报来优化 ML 模型,缩短训练故障排除时间 |
| 部署 | 即Sage maker产品本身,通过完全托管的方式帮助模型全流程 |
| 分布式训练库 | 使用分区算法,自动拆分大型深度学习模型和训练数据库,提升了相应流程的速度 |
| Edge Manager | 优化在主流框架中训练的模型,使其轻松部署在任何边缘设备上 |
| 实验 | 一项托管服务,用于大规模跟踪和分析 ML 实验 |
| 特征存放区 | 完全托管式的专用储存库,用于存储、共享、管理ML模型特征 |
| 地理空间ML | 利用地理空间数据(卫星影像、地图和位置数据等)更快地构建、训练和部署 ML 模型 |
| Ground Truth | 识别原始数据,添加信息标记与生成标注合成数据,提高训练集质量 |
| JumpStart | 一个ML中心,用户可以通过点击式调用内置算法完成实际任务 |
| SageMaker for K8 | 简化基于Kubernetes(自动执行容器化应用程序的部署、扩展和管理)的机器学习,提供一个界面管理和调度ML工作流 |
| 模型监控器 | 自动收集并监控模型数据,并内置分析与可视化,在出现不准确数据时提醒用户,始终保持ML模型的准确 |
| 笔记本 | 提供两种云端完全托管式Jupyter Notebook,用于探索数据和构建机器学习模型 |
| 管道 | 专为ML构建的CI/CD服务,大规模创建、自动化和管理端到端 ML 工作流 |
| RStudio | 用于数据科学和机器学习的完全托管的Rstudio IDE |
| 影子测试 | 根据生成模型自动验证新ML模型性能,以防止代价高昂的停机 |
| Studio Lab | 免费的ML学习开发环境 |
| Studio | 适用于机器学习的完全集成的IDE,涵盖ML全生命周期 |
| 训练 | 与部署一致,即产品本身的定位功能 |
补充:除了功能分类,在ML治理上,Sage maker提供了专门的工具——Role Manager和Model Cards,前者便于管理员定义权限,后者简化了模型文档,便于用户捕获、检索、和共享基本模型信息。
根据ML流程总结相关功能如图4所示:
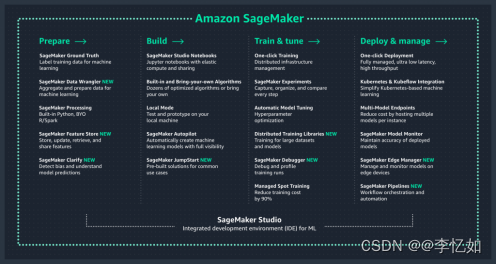
图4 ML流程分类Sage maker功能
在功能简介后,集合相关功能再进行Sage maker竞争优势补充如下:
Ⅰ、ML全流程服务
Sage maker向多种用户提供了包括但不限于模型构建、训练、部署的全流程服务,并在不同阶段均提供了丰富的工具帮助监控与优化,保证了效率的提升与性能的稳定。
Ⅱ、丰富的包容度
除了支持主流的框架、工具、语言外,在多种不同数据和模型的来源与去向的选择上,Sage maker提供了不同功能/工具进行接受、传输与存储,还实现了迁移与部署的易操作性。
Ⅲ、数据与界面的清晰度
在Sage maker多种功能/工具中,均提供了可视化界面,用于直观地输出数据或模型的各种指标对比,在部分功能中,提供了一键式点击交互,内置高效模型帮助用户快速完成实际任务并获取分析结果。
Ⅳ、工作流与资源调度合理
Sage maker大部分功能通过自动化提高用户ML任务的效率,添加了管道合理化工作流,通过子产品工具合理化模型的资源调度,权衡了开销与能耗。
1.3 产品实践
本部分主要进行Sage maker的几个主要功能的实践,并根据过程与结果流程图补充调研分析结果。
Tips:Sage maker大部分功能使用需要AMS账号,故部分过程图来自官网与网络。
1.3.1 低代码/无代码ML
根据表3我们知道,Sega maker提供了Data Wrangler、Autopilot、JumpStart、Canvas四个低代码/无代码ML平台/工具,是对非ML/代码工程师的主力工具,我们首先体验一下。
Ⅰ、Data Wrangler
根据表3,我们知道Data Wrangler可以帮助用户高效完成数据准备的全过程,如图5所示:
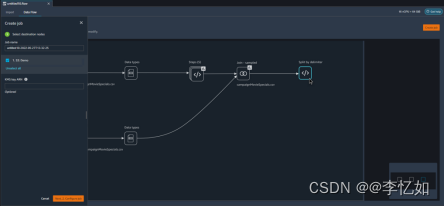
图5 Data Wrangler主界面样例
分析:根据图5,我们可以看到在Data Wrangler中,数据准备的每个步骤可视化为点击事件在单个主界面中,点击不同step可以完成数据的不同操作,主要操作汇总如图6:
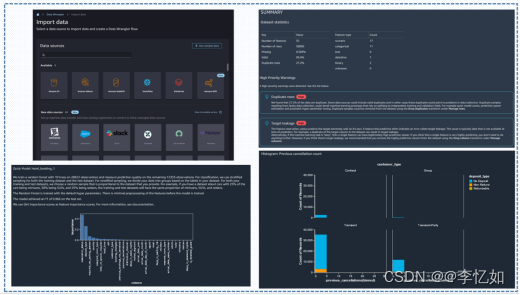
图6 Data Wrangler中对数据的主要操作:左上为数据的查询与选择、右上为数据洞悉与质量分析、左下为数据预测能力分析、右下为数据可视化分析
Ⅱ、Autopilot
根据表3,我们知道Autopilot在数据分析完全可见的情况下可以帮助用户高效完成自动构建、训练和调整最佳 ML 模型的过程,如图7所示:
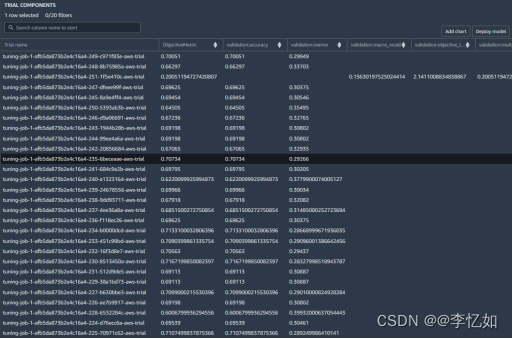
图7 Autopilot模型决策样例
分析:如图7所示,Autopilot针对用户给定数据自动构建、训练多个模型,并给出各种指标,按需求择优选择。
Ⅲ、JumpStart
根据表3,我们知道JumpStrat是一个ML中心,将多种内置算法集合成页面的点击事件,如图8所示。用户根据需求选择实际任务,上传数据并接受返回结果。
图8 JumpStart主界面
Ⅳ、Canvas
根据表3与1.1中官网描述,我们知道Canvas是主要面向BA工作者的无代码、可视化、点击式的ML预测工具,主要功能如图9所示:
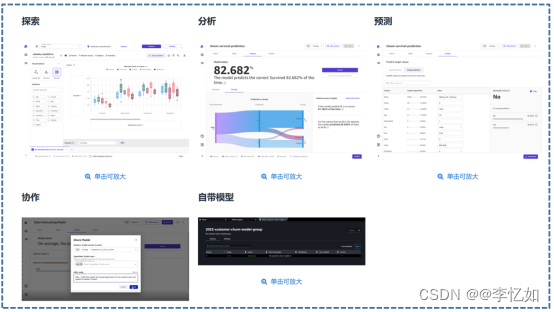
图9 Canvas主要功能
补充:详细教学可见:教程 - 自动创建机器学习模型 - Amazon Web Services
总结:在体验完Sage maker提供的四个低代码/无代码工具后,对Sage maker的核心优势补充如下:
Sage maker不仅服务于多种目标群体,开发的低代码/无代码工具降低了机器学习任务的门槛,大大提高了易用性与用户工作/研究效率。
1.3.2 IDE/Lab
根据表3我们知道,Sage maker提供了Studio、Studio Lab、Rstudio三个集成开发环境,是有一定代码能力的用户的主力工具,我们接下来进行一下实践。
Ⅰ、Rstudio
根据表3,我们知道Rstudio是用于数据科学和机器学习的基于云的、完全托管的Rstudio IDE,在Sage maker上可以动态调度计算资源,统一了R与Python的开发团队。
Ⅱ、Studio Lab
根据表3,我们知道Studio Lab是带有一定资源的免费ML开发环境,并支持一定时间的数据持久化,主界面如图10所示,编程页面样例如图11所示:
图10 Studio Lab主界面

图11 Studio Lab编程界面样例
分析:类似于Google Colab,但Studio Lab更便于非VPN用户访问并跑相关的notebook,且带有一定免费计算资源。
Ⅲ、Studio
根据表3,我们知道Studio是Sage maker中适用于机器学习的完全集成的IDE,涵盖ML全生命周期,搭载Sage maker主要功能。主要功能总结如图12所示:

图12 Studio主要功能汇总:左上为数据的准备、右上为模型的构建、左下为模型训练、右中为模型的部署与管理、右下为数据的偏差检测
分析:Studio是专用于ML的IDE,大量内置热门模型,除了主流代码编写页面还搭载了可视化页面,符合ML任务的待分析性。
补充:Amazon在2022年12月更新了Studio,增加了导航栏,嵌入了Sage maker的一些核心功能,主界面如图13所示:
图13 Studio主界面
总结:在体验完Sage maker提供的三个IDE/Lab后,对Sage maker的核心优势补充如下:
Sage maker提供的开发工具在多团队协同、功能集成度、用户友好度上均有很好的表现。
1.3.3 ML的监测、调度与分析
根据表3我们知道,Sega maker提供了Clarify、Debugger、模型监控器等几种功能帮助用户进行ML任务各阶段的数据、模型的监测、调度与分析,我们进行一下实践。
Ⅰ、Clarify
根据表3,我们知道Clarify使用各种指标检测和测量潜在偏差,以便他们能够解决潜在偏差并解释模型预测,如图14所示:
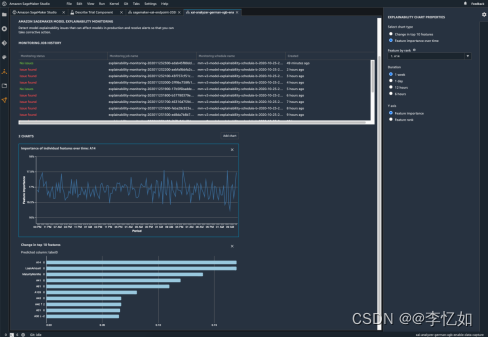
图14 Clarify检测报告界面样例
分析:如图14所示,Clarify可以报告不同特征对模型的贡献,在监测模型行为变化的同时保持其较高的可解释性,并着重检测防止潜在偏差。
Ⅱ、模型监控器
根据表3,我们知道模型监控器可以自动收集并监控模型数据,并内置分析与可视化,在出现不准确数据时提醒用户,始终保持ML模型的准确,如图15所示:
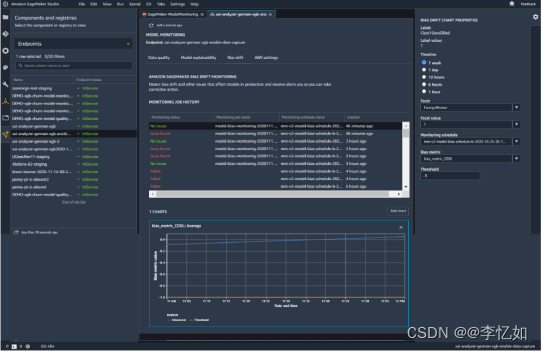
图15 模型监控器页面
补充:实际上模型监控器与Clarify在Sage maker中是集成的,便于用户更高效地监控模型与数据的变化,工具也会自动报告分析结果与警告提醒。
Ⅲ、Debugger
根据表3,我们知道Debugger通过实时自动捕获训练指标,检测到异常时发送警报来优化 ML 模型,缩短训练故障排除时间,如图16所示:
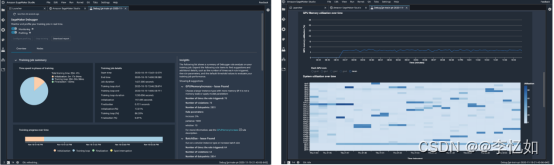
图16 Debugger界面样例
分析:Sage maker中的Debugger与AWS Lambda集成,内置分析与自动监测协同了成本与效率,使用较少资源较高效地在早期发现bug并报告用户。
总结:在体验完Sage maker提供的几个模型/数据监测、调度与分析功能后,对Sage maker的核心优势补充如下:
Sage maker提供的调试与优化工具不仅实现自动化检测、分析与报告,还在资源使用、效率间做了比较好的权衡,且高集成度的合成功能加大了效率的提升度。
至此,Sage maker的主要功能实践分析结束,其他补充在后文对比分析时详述。
1.4 产品定价
Sage maker作为AWS的机器学习产品,予用户予商家定价都是一个重要问题,故在本节做一个产品定价的汇总,Sage maker是按主要功能定价的,详情页如下:Amazon SageMaker 定价,对于明确需求用户,可以采取定价器:AWS Pricing Calculator,同时给出了免费套餐,功能与资源如表4所示:
表4 产品免费套餐内容
| 功能 | 免费套餐前 2 个月的每个月使用情况 |
| Studio笔记本及实例 | Studio 笔记本上的 250 个小时 ml.t3.medium 实例,或者笔记本实例上的 250 个小时 ml.t2 medium 实例或 ml.t3.medium 实例 |
| RStudio | RSession 应用程序上 250 个小时的 ml.t3.medium 实例和 RStudioServerPro 应用程序的免费 ml.t3.medium 实例 |
| Data Wrangler | 25 个小时 ml.m5.4xlarge 实例 |
| 特征存放区 | 1000 万个写单元,1000 万个读单元,25 GB 存储 |
| 培训 | 50 个小时 m4.xlarge 或 m5.xlarge 实例 |
| 实时推理 | 125 个小时 m4.xlarge 或 m5.xlarge 实例 |
| 无服务器推理 | 150000 秒推理持续时间 |
| Canvas | 会话时间为 750 小时/月,每月最多 10 个模型创建请求,每个请求最多 100 万个单元/模型创建请求 |
| 免费套餐前 6 个月的每个月使用情况 | |
| 实验 | 每个月提取 100,000 条指标记录,检索 100 万条指标记录,并存储 100,000 条指标记录 |
1.5 产品综述
在经过前四节的简介、功能分析、实践、定价计算后,在本节对产品做综述如下:
Sage maker是一个面向多用户、支持多框架/工具的ML平台,主要产品为Studio,涵盖ML任务全周期,多功能实现自动化,在成本与效率上也做了较好的平衡。
本次调研对于Sage maker的基本分析到此结束,其他常见问题可见:机器学习 - Amazon SageMaker 常见问题 - Amazon Web Services
2.PAI
2.1 产品简介
本节首先对PAI进行基本情况的介绍,总结如表5,PAI产品架构如图17所示:
表5 PAI简介
| 来源(开发商)/ 官网 | Alibaba / https://www.aliyun.com/product/bigdata/learn |
| 产品官方定位 | PAI(Platform of Artificial Intelligence)是面向开发者和企业的机器学习/深度学习工程平台,提供多种AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力 |
| 产品与开发文档 | https://help.aliyun.com/product/30347.html |

图17 PAI产品架构
根据官网描述与调研分析,PAI的几大核心竞争优势如下:
Ⅰ、简单易用
PAI服务支持单独或组合使用。支持一站式机器学习,其中封装了140+机器学习算法,支持低代码模型训练和一键部署。
Ⅱ、底层支持多种计算框架
⚪ 流式计算框架Flink
⚪ 基于开源版本深度优化的深度学习框架TensorFlow
⚪ 千亿特征样本的大规模并行计算框架Parameter Server
⚪ Spark、PySpark、MapReduce等业内主流开源框架
补充:除了计算框架,PAI同时对接DataWorks,支持SQL、UDF、UDAF、MR等多种数据处理方式,灵活性高。
Ⅲ、高性能、低成本ML
高性能:支持高维稀疏数据场景,支持超大规模样本模型加速训练
低成本:支持CPU/GPU混合调度,云原生弹性伸缩,计费灵活
Ⅳ、丰富的应用场景与插件
PAI提供多场景插件及方案,帮助企业快速构建业务应用。在大模型平台、智能推荐
、用户增长、金融量化科学计算、端侧超分等实际应用场景中都适用且有优秀表现。
Ⅴ、产品文档与日志系统
除了PAI的产品文档,Alibaba为其相关子产品均建立了详细的文档供学习者与用户使用。此外,官网主页还配备了日志系统,及时发布PAI的新功能或优化。此外,在多种应用场景下还有PAI使用的详细指导。
2.2 功能分析
本节主要对PAI的功能进行详细的介绍与分析,根据图17与文档,简介汇总如表6:
表6 PAI功能及简介
| 功能 | 简介 |
| PAI-iTAG | 在数据准备阶段,提供智能化数据标注服务 |
| PAI-Designer | 在模型开发阶段,提供低代码拖拽式可视化建模工具 |
| PAI-DSW | 在模型开发阶段,提供类JupyterLab的交互式建模工具 |
| PAI-DLC | 在模型训练阶段,提供一站式的云原生深度学习训练平台 |
| PAI-EAS | 在模型部署阶段,提供模型在线预测服务(弹性推理) |
| PAI-Blade | 在模型部署阶段,提供推理的通用加速,使其高效到达最优性能 |
| AI资产管理 | 支持用户对模型、数据集、镜像等重要的AI生产资料及开发产出进行全生命周期管理,并利用数据对比分析实现降本增效 |
在功能简介后,集合相关功能再进行PAI竞争优势补充如下:
Ⅰ、ML全流程服务
PAI向用户提供了包括但不限于模型构建、训练、部署的全流程服务,并在不同阶段均提供了低代码/交互式的工具便于不同用户选择,保证了效率的提升。
Ⅱ、相关应用场景实践
在不同功能/工具的介绍中,均有对应的应用场景案例介绍与技术模块分析,并将大部分优质实践收录阿里天池notebook供用户学习与复现。
Ⅲ、数据与界面的清晰度
在PAI几种功能/工具中,均提供了可视化界面,用于直观地输出数据或模型的各种指标对比与当前进度,同时通过数据列表、分析图等多种展示方式降低分析难度。
2.3 产品实践
本部分主要进行PAI的几个主要功能的实践与应用场景的分析,并根据过程与结果流程图补充调研分析结果。
其中PAI提供了一定免费资源与项目供用户体验,详见产品控制台:概览 (aliyun.com)
2.3.1 数据准备:PAI-iTAG
根据表6,我们知道PAI在数据准备阶段给用户提供了PAI-iTAG这一个子产品,接下来进行一定的体验与分析。
PAI-iTAG是PAI下的智能标注平台,有以下几个优势实现智能标注:
①支持图像、文本、视频、音频等多种数据类型的标注以及多模态的混合标注
②与PAI-EAS部署的模型服务打通,提供智能预打标工具和模型在线预标注
③提供标注模板、自定义标注、全外包标注三种标注方式选择
接入流程详见创建数据集:用于数据标注 (aliyun.com),操作界面如图18:

图18 PAI-iTAG操作界面样例
解决方案/应用场景:官网并未明确给出,但在大量ML任务的数据集构建中均适用(数据集需支持iTAG数据标注格式)
2.3.2 模型开发/构建
根据表6,我们知道PAI在模型开发/构建阶段给用户提供了PAI-Designer与PAI-DSW两子产品,接下来进行一定的体验与分析。
Ⅰ、PAI-Designer
根据表6,我们知道PAI-Designer是一个零代码/低代码拖拽式可视化建模工具,类似Sage maker Canvas,有以下几个优势:
①内置丰富的算法组件,涵盖各种机器学习任务
②流批一体化训练,支持离线训练与在线更新
③内置AutoML自动调参引擎,便于用户选择最优模型
④可视化0代码开发,提高非代码从业者的易用性与数据清晰度
解决方案/应用场景:PAI-Desinger在智能推荐、用户增长上提供了解决方案,架构如图19所示,在商品推荐、金融疯狂、文本分类、疾病预测等应用场景下可用。
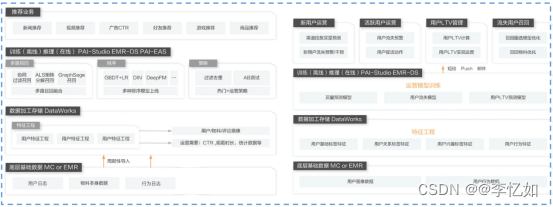
图19 PAI-Designer解决方案架构:左为智能推荐、右为用户增长
产品实践:想使用PAI-Designer,在控制台选择可视化建模创建工作流即可,内置模板页面如图20,以雾霾天气预报为例,实际使用界面如图21,结果可视化如图22所示:
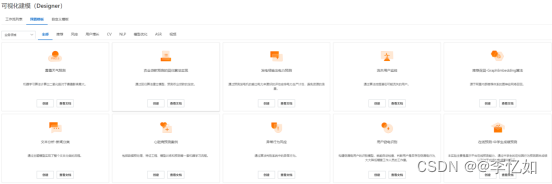
图20 PAI-Designer内置部分模板

图21 PAI-Designer操作页面样例

图22 PAI-Designer结果可视化样例
分析:如图20、21、22所示,针对多种应用场景,PAI-Designer都内置了多种算法与解决方案供内置调用,实际操作通过点击、拖拽等简单操作即可完成ML任务全流程,将结果数据与指标持久化并通过列表、分析图等多种方式可视化帮助用户分析。
Ⅱ、PAI-DSW
根据表6,我们知道PAI-DSW是一个集成JupyterLab、交互式的云端深度学习开发环境,有以下几个优势:
①灵活易用:Notebook交互式云端编程,深度学习网络组件化,支持可视化展现与修改,同时提供组件代码转换
②支持自定义配置:提供阿里深度优化的Tenorflow框架,同时也支持开源框架供用户灵活配置
③全链路ML:用户可以在DSW平台在线完成ML全流程
PAI-DSW在版本上提供个人版(付费)与探索者版(限时免费,资源有限),产品使用流程为:创建实例,资源选择->上传数据,在线开发、调试->运行代码,生成模型->模型在线部署。
解决方案/应用场景:AI企业深度学习解决方案、深度学习算法爱好者、教育与科研领域
产品实践:对于PAI-DSW个人版,在产品控制台付费开启,再按使用流程创建工作流即可。对于PAI-DSW探索者版,可以进入天池Notebook(阿里大数据平台)选择已有项目RUN即可开启实践,或在自己的Lab新建Notebook进行ML任务,详见:天池实验室
在本节以PAI-DSW探索者版为例进行调研,如图23所示:
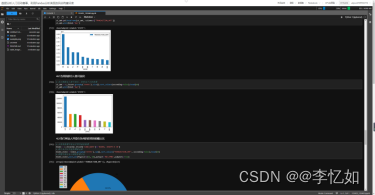
图23 PAI-DSW界面样例
分析:如图23所示,PAI-DSW可以在线利用云端资源,自编代码完成ML任务,在界面直接可视化结果,并在上方给出资源利用情况。
2.3.3 模型训练:PAI-DLC
根据表6,我们知道PAI在模型训练阶段给用户提供了PAI-DLC这一个子产品,接下来进行一定的体验与分析。
PAI-DLC(容器训练)提供一站式的云原生深度学习训练平台,有以下几个优势:
①合理任务管理:支持用户通过不同方式提交任务,且能简单明了地查看任务相关信息
②运行环境自定义:用户可以在多种预设环境与自定义环境中选择
③超大规模分布式任务支持:用户可在DLC上运行过千节点的分布式深度学习任务
产品使用流程与常规云产品类似,分为:选择计算资源->创建DLC工作集群->提交任务并运行。
解决方案/应用场景:数据预处理、离线推理、超大规模分布式训练
产品实践:在产品控制台按需求定义即可,任务定义样例如图24,结果如图25所示:
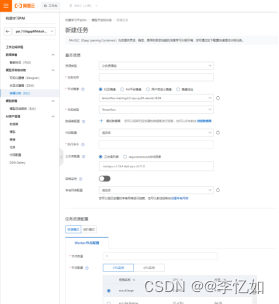
图24 PAI-DLC任务创建与训练样例
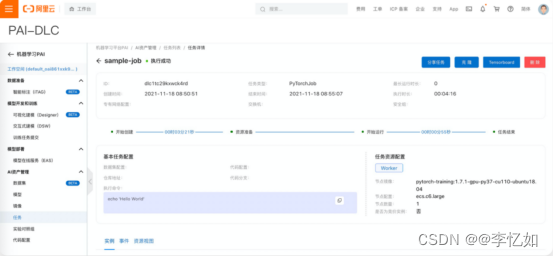
图25 PAI-DLC结果样例
2.3.4 模型部署
根据表6,我们知道PAI在模型部署阶段给用户提供了PAI-EAS与PAI-Blade两子产品,接下来进行一定的体验与分析。
Ⅰ、PAI-EAS
根据表6,我们知道PAI-EAS是PAI平台的模型在线预测服务,有以下几个优势:
①灵活易用:模型部署与服务调用方式灵活,与PAI-Designer、PAI-DSW无缝对接
②异构资源:针对ML、DL模型不同特点,一键部署模型到CPU、GPU
③弹性高可用:高并发高吞吐,服务响应时长短,资源弹性收缩
在产品使用方面,PAI-EAS提供了四种模型部署方式与三种服务调用路径,如图26所示:
图26 PAI-EAS产品使用:左为模型部署方式、右为服务调用路径
解决方案/应用场景:官网并未明确给出,但在大量ML/DL任务的模型部署中均适用。
产品实践:在产品控制台根据需求定义即可,创建部署样例如图27,结果如图28所示:
图27 PAI-EAS部署服务创建
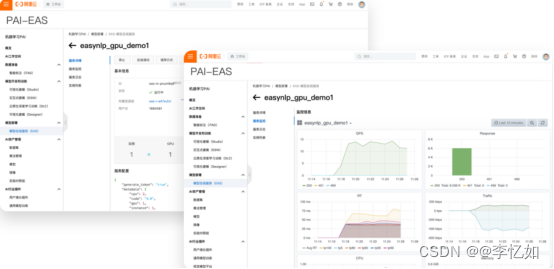
图28 PAI-EAS结果样例
分析:如图27、28所示,PAI-EAS提供用户一个在线的预测工具,提供完整的运维监控体系。
Ⅱ、PAI-Blade
根据表6,我们知道PAI-Blade是一个通用推理加速器,通过模型系统联合优化,有多框架、多设备(GPU、CPU、端)、能力强(支持多种优化技术)、易使用四个特点。技术架构如图29所示:
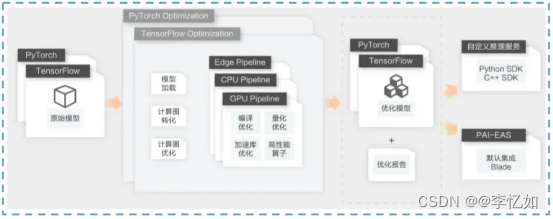
图29 PAI-Blade技术架构
使用步骤:PAI-Blade并不是一个在线服务,而是SDK,安装并使用即可,安装命令根据框架、版本、设备、语言有所不同,详见:模型推理优化Blade (aliyun.com)
2.3.5 数据管理:AI资产管理
在ML/DL任务全流程中,会产生大量数据、模型与指标,如何存储、分析、管理是一个关键问题,根据表6,我们知道PAI在数据管理上给用户提供了AI资产管理这一个子产品,接下来进行一定的体验与分析。
PAI中的AI资产管理为一个在线服务,支持用户对模型、数据集、镜像等重要的AI生产资料及开发产出进行全生命周期管理,如图30所示,详情可见:AI资产管理 (aliyun.com),管理页样例如图31所示:

图30 AI资产管理详细管理部分
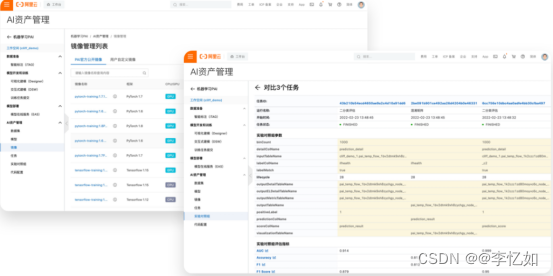
图31 AI资产管理页面样例
分析:如图30、31所示,AI资产管理通过列表形式展示相关信息,同时提供AI资产共享、训练效果横向比对、异常问题回溯等能力,实现AI开发及应用过程的降本增效。
补充:对于PAI,基本使用方式可见工作空间详情,如图32所示:
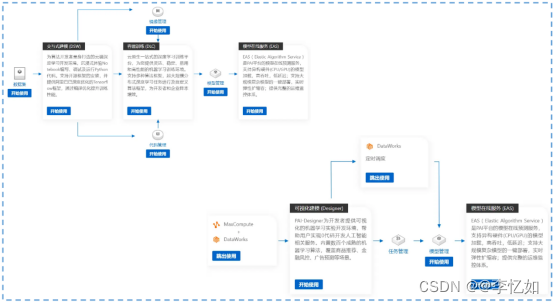
图32 PAI基本使用方式:左为云原生开发场景、右为AI+大数据最佳实践
至此,PAI的主要功能实践分析结束,其他补充在后文对比分析时详述。
2.4 产品定价
PAI作为Alibaba的机器学习产品,予用户予商家定价都是一个重要问题,故在本节做一个产品定价的汇总,PAI是按主要功能定价的,可单产品(子产品组合)或产品组合付费。定价详情页与定价其如下:
https://www.aliyun.com/price/product?spm=5176.14066474.J_7614544130.2.3779426aQRbOQR#/learn/detail/pai
2.5 产品综述
在经过前四节的简介、功能分析、实践、定价计算后,在本节对产品做综述如下:
PAI是一个支持多框架的一站式ML全流程平台,主要服务集中于云端,在大量真实的解决方案/应用场景中验证对效率的提升。
本次调研对于PAI的基本分析到此结束,其他常见问题可见:常见问题 (aliyun.com)
3.PaddlePaddle
3.1 产品简介
本节首先对PaddlePaddle(飞桨)进行基本情况的介绍,总结如表7,主要产品架构如图33所示:
表7 PaddlePaddle简介
| 来源(开发商)/ 官网 | Baidu / https://www.paddlepaddle.org.cn/ |
| 产品官方定位 | PaddlePaddle(飞桨)是一个易用、高效、灵活、可扩展的深度学习框架/平台,致力于让深度学习技术的创新与应用更简单。 |
| 产品与开发文档 | https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/index_cn.html |
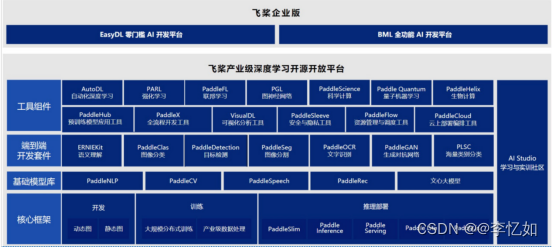
图33 PaddlePaddle主要产品架构
根据官网描述与调研分析,PaddlePaddle的几大核心竞争优势如下:
Ⅰ、丰富的产品/功能支持
在深度学习的不同领域,面向不同机器/模型/用户,PaddlePaddle均有大量相应的子产品/功能支持,提供了针对不同需求的多种选择。
Ⅱ、多语言与多平台
PaddlePaddle支持多种深度学习模型,基于Spark支持C++、Python等编程语言,可应用于分布式计算。同时,支持多端多平台的高性能部署。
Ⅲ、产业级开源模型库
在计算机视觉、自然语言处理、智能语音等不同领域/任务中,PaddlePaddle均提供多种产业级开源模型与端到端开发套件。
Ⅳ、开发便捷的深度学习框架
PaddlePaddle作为一个深度学习框架是高度集成的,基于编程一致的深度学习计算抽象以及对应的前后端设计,拥有易学易用的前端编程界面和统一高效的内部核心架构。除了产品的使用,作为框架可以类似Tensorflow导入IDE完成各种任务。
补充:作为一个深度学习框架,PaddlePaddle支持超大规模深度学习模型训练技术,领先其它框架实现了千亿稀疏特征、万亿参数、数百节点并行训练的能力,解决了超大规模深度学习模型的在线学习和部署难题。
3.2 功能分析
由于PaddlePaddle在DL不同阶段均配备拥有大量的产品链路,如图34所示,故本节不做功能汇总,详见:产品全景_飞桨产品-飞桨PaddlePaddle,在下节对主要/热门产品与功能做一定实践与解析。

图34 PaddlePaddle产品全景
3.3 产品实践
本部分主要进行PaddlePaddle的几个主要功能/产品的实践与应用场景的分析,并根据过程与结果流程图补充调研分析结果。
3.3.1 框架使用
根据3.1我们知道PaddlePaddle的本质定义是一个深度学习框架,所以我们首先先对他在本地IDE的使用进行一定的实践,核心框架详见:GitHub - PaddlePaddle。
首先在官网根据实验机器环境/资源进行安装,结果如图35所示,安装成功后在本地IDE使用方法与其他库/框架类似,使用PaddlePaddle内的模型与函数完成实际任务即可,具体用法详见:API 文档-API文档-PaddlePaddle深度学习平台。以手写数字识别为例,过程与输出结果如图36与37所示:
图35 PaddlePaddle安装结果样例
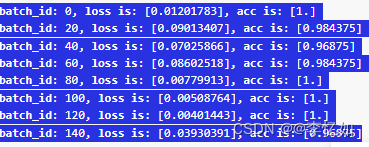
图36 模型训练过程样例
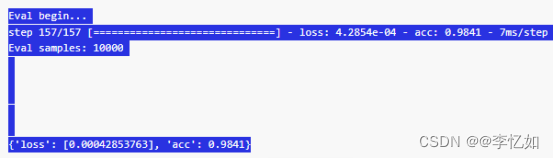
图37 手写数字识别结果样例
3.3.2 工具组件
根据图34,我们知道PaddlePaddle提供了大量工具组件,其中比较主要/热门的是预训练工具:PaddleHub、全流程开发工具:PaddleX、可视化工具:VisualDL、自动化工具:AutoDL,接下来一一介绍与实践。
Ⅰ、预训练工具:PaddleHub
在深度学习模型预训练阶段,PaddlePaddle提供的热门工具——PaddleHub可以便捷地获取PaddlePaddle生态下的预训练模型,完成模型的管理和一键预测。配合使用Fine-tune API,可以基于大规模预训练模型快速完成迁移学习,有以下几个特点:
- 无需数据和训练,一键模型应用
- 一键模型转服务
- 易用的迁移学习
- 丰富的预训练模型与应用场景
一个简单示例如图38所示:
图38 PaddleHub的简单示例
Ⅱ、全流程开发工具:PaddleX
PaddleX是飞桨全流程开发工具,集飞桨核心框架、模型库、工具及组件等深度学习开发所需全部能力于一身。同时提供简明易懂的Python API,及一键下载安装的图形化开发客户端。
在使用上PaddleX集成于客户端,常见应用如图39,其他用法详见:GitHub - PaddlePaddle/PaddleX。

图39 PaddleX主要功能
Ⅲ、可视化工具:VisualDL
VisualDL是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、数据样本、模型结构、PR曲线、ROC曲线、高维数据分布等。帮助用户清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型调优。主要功能展示样例如图40所示:

图40 VisualDL主要功能展示:左上为训练指标、右上为各阶段数据展示、左下为程序图结构、右下为模型训练各层数据统计直方图
Ⅳ、自动化工具:AutoDL
AutoDL为高效地自动搜索构建最佳网络结构的方法,通过增强学习在不断训练过程中得到定制化高质量的模型,实现与使用详见:桨桨/AutoDL (github.com),自动训练核心原理如图41所示:
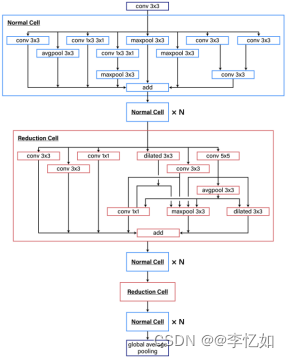
图41 AutoDL自动训练核心原理
3.3.3 端到端开发套件
根据图34,我们知道PaddlePaddle提供了大量工具组件,简单功能介绍如图42,其中比较主要/热门的是PaddleOCR、PaddleDetection,接下来一一介绍与实践。

图42 端到端开发套件简介汇总
Ⅰ、PaddleOCR
PaddleOCR 旨在创建多语言、领先且实用的OCR(主要是内容识别)工具,帮助用户训练更好的模型并将其应用于实践,简单应用如图43所示,用法详见:PaddlePaddle/PaddleOCR。

图43 PaddleOCR简单应用
Ⅱ、PaddleDetection
PaddleDetection是一个目标检测端到端开发套件,帮助开发者实现ML、DL任务的全流程打通,快速进行落地应用,主要应用效果样例如图44所示,用法详见:PaddlePaddle/PaddleDetection。

图44 PaddleDetection主要应用效果样例
补充:PaddlePaddle的端到端开发组件简单体验可以在PaddlePaddle提供的在线平台中。
3.3.4 模型库
根据3.1简介我们知道Paddlepaddle是一个带有大量产业级开源模型的深度学习框架,其中基础模型库简单功能介绍如图45,其中比较主要/热门的是文心大模型,在本小节进行简单介绍与实践。

图45 基础模型库简单功能介绍
文心大模型是PaddlePaddle下的一个热门模型库,同时也是Baidu下的一个大模型应用平台,包含针对多种任务的不同API、开发套件、工具,整体平台架构如图46所示:

图46 文心大模型平台架构
文心模型平台提供多种封装好的在线服务,提高了用户的易用性。以AIGC的应用为例,开放API如下:
⚪ ERNIE 3.0文本理解与创作
⚪ ERNIE-ViLG AI作画
⚪ 文心PLATO 对话生成
基于ERNIE-ViLG AI作画的样例如图47:

图47 文心大模型平台开发服务样例
3.3.5 部署预测:PaddleLite
根据图34,PaddlePaddle在模型部署预测阶段同样提供了多款产品,简单功能介绍如图48所示,其中主要/热门的是PaddleLite,接下来进行简单的介绍与实践。

图48 模型部署预测产品功能简单介绍
Paddle Lite是飞桨基于Paddle Mobile全新升级推出的端侧推理引擎,有以下几个优势:
①全面通用:全面地支持多种硬件、操作系统、训练框架和AI模型
②更优性能:更加优异的性能优化,推理速度优于主流实现
③轻量实用:移动部署,无任何第三方依赖,支持模型深度剪裁
④多应用实践:在多种应用场景下均适用并提出解决方案
Paddle Lite的部署开发流程如图49,技术架构如图50,用法详见:PaddlePaddle/Paddle-Lite,模型效果对比如图51,应用案例详见:PaddlePaddle/Paddle-Lite-Demo。

图49 Paddle Lite部署开发流程
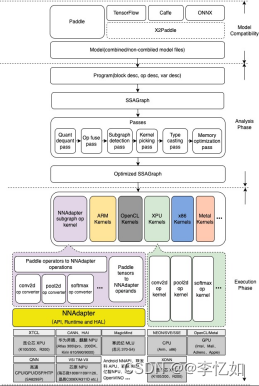
图50 Paddle Lite技术架构
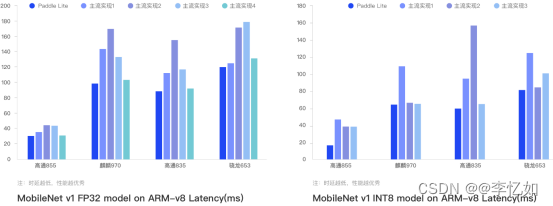
图51 Paddle Lite及主流实现模型效果对比
分析:如图51所示,利用PaddleLite进行模型的部署预测,在不同任务/应用场景中相对其他主流实现方法模型的效果均有提高。
3.3.6 AI开发平台
和其他主流机器学习平台类似,PaddlePaddle同样提供了AI开发平台供用户利用云端资源(含免费算力)在线编程(不同应用场景),包括了EasyDL零门槛AI开发平台、BML全功能AI开发平台、AI Studio 学习与实训社区三个平台,在本小节一一做简介与实践。
Ⅰ、EasyDL
EasyDL是PaddlePaddle下的零门槛AI开发平台,提供了点击式任务供无代码能力用户完成相关任务,主要模型如图52所示,用法详见:EasyDL零门槛AI开发平台。

图52 EasyDL主要模型/应用场景
补充:EasyDL的使用与一般的ML/DL任务保持一致,即数据处理->模型训练->模型校验->模型部署四大流程。
Ⅱ、BML
BML是PaddlePaddle提供的全功能AI开发平台,是EasyDL的相关产品,目标用户是有一定代码能力的用户。平台核心架构如图53所示,用法详见:BML 全功能AI开发平台。

图53 BML核心架构
补充:BML的使用同样与一般的ML/DL任务保持一致,控制台总览样例如图54所示:

图54 BML控制台总览样例
Ⅲ、AI Studio
AI Studio是PaddlePaddle提供的学习与实训社区,提供了免费的算力与不同的项目实例供不同用户学习、研究与讨论。同时提供了类Google Colab的在线编译环境,提高了易用性,界面样例如图55所示:
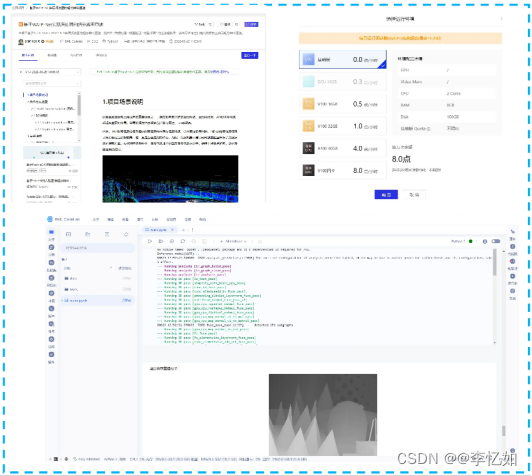
图55 AI Studio界面样例:左上为公开项目详述、右上为环境(免费)算力资源、下为BML CodeLab在线编译器
3.4 产品综述
Tips:PaddlePaddle主要是作为深度学习框架,故本章对定价不做调研。
在经过前三节的简介、功能分析、实践后,在本节对产品做综述如下:
PaddlePaddle是一个带有大量产业级开源模型的深度学习模型,拥有丰富的产品链路与应用场景。
本次调研对于PaddlePaddle的基本分析到此结束,其他常见问题可见:常见问题与解答-使用文档-PaddlePaddle深度学习平台。
4.标杆分析与总结
根据前几章对主流机器学习平台的调研,在本章进行一定的综述与标杆分析,旨在对后续机器学习平台开发与优化提供一定经验与思路。
4.1 标杆分析
根据对主流机器学习平台的调研,在此总结一些机器学习平台的共性优势如表10所示,生成词云如图60所示:
表10 主流机器学习平台共性优势
| 1、高效、自动化的ML全链路服务 优秀的机器学习平台不仅要保证ML全链路服务,还要通过子产品/功能内置常见算法、框架、工具,并通过一定自动化手段帮助用户高效完成相关任务。 |
| 2、便于多种用户使用 优秀的机器学习平台一般带有不同子产品令有无代码基础、各领域的用户都可以完成机器学习任务,且对于流程与结果的界面基本实现可视化,便于分析实验。且均配备完备的文档与日志系统,降低使用门槛。 |
| 3、高性能、低成本的ML 优秀的机器学习平台在高效地完成ML任务的同时,要考虑到计算资源的合理利用、用户成本/实验开销的较小化,提供高性能、低成本的ML。 |
| 4、完备的数据管理、检测、分析 对于ML任务来说,数据与模型的分析是很重要的,而实现高效、清晰完备的数据管理、检测、分析是一个优秀机器学习平台的必选项。在一些主流机器学习平台中(eg.Sage maker)还配备了不同的自动化数据分析工具在ML各生命周期均有服务。 |
| 5、高包容性和多应用场景 优秀的机器学习平台应该是高包容性的,对于数据/模型的由来与去向;框架、语言、工具的选择;任务与用户的选择类型都是如此。且对于每个子产品/功能均有相关的解决方案/应用场景供用户参考与学习。 |
| 6、产品/功能丰富度与完备性 优秀的机器学习平台在兼顾效能的同时要确保产品/功能的丰富度与完备性,包括但不限于适用ML/DL各阶段的功能/工具,且针对不同的细分应用场景有对应的工具,在实现上应提供不同的方案(云端Lab、开源接口、集成IDE),且在每个产品/功能的实现、使用中均有当周期的完备性。 |

图60 主流机器学习平台共性优势
4.2 对比分析
根据标杆分析中主流机器学习平台的共性优势作为评价维度,本节将调研的不同平台进行定性对比分析,如表11所示:
表11 主流机器学习平台对比分析及评价
| Sage maker | PAI | PaddlePaddle | |
| 高效、自动化的ML全链路服务 | 优:在多种功能中强调自动最优化与性能资源协调。 | 优:不同功能中注重效能,通过内置模板模型引擎实现加速。 劣:仅在部分功能中内置了智能模板,自动化程度相对不高。 | 优:在ML全链路中均提供了优质、多选择的服务,利用高性能组件/框架实现高效服务。 |
| 便于多种用户使用 | 优:对不同类型用户开发不同子产品,界面清晰数据可视化。 劣:大部分服务非在线,且对地区、AWS帐号有要求。 | 优:大部分服务集中于云端,内置大量算法与模型供用户调用。 劣:仅提供零门槛/全开发两种套件,没有针对特定行业开发相应子产品。 | 优:在工具方面,基本有Github版与在线版;在平台方面,有零门槛平台与AI全流程开发平台及讨论社区;且PaddlePaddle本身将产品抽象成了框架,有极高易用性。 劣:产品文档的完备性有所欠缺(特性与定位等非技术部分)。 |
| 高性能、低成本的ML | 优:产品开发基于Amazon多年实际ML经验。 劣:免费的平台/算力资源上相对匮乏,在用户成本上较高。 | 优:支持高维稀疏数据场景,支持超大规模样本模型加速训练,支持CPU/GPU混合调度,云原生弹性伸缩,计费灵活。 | 优:在已有框架上做了针对DL任务的优化,在不同阶段也使用了企业级模型与高性能插件加速。 |
| 完备的数据管理、检测、分析 | 优:在ML任务的不同周期均有功能进行监测、调度与分析,并适时发送警报与自动优化。 | 优:将全生命周期数据的存储、分析、管理均集成在了AI资产管理一个功能中,使用方便,数据清晰。 劣:只有基本的数据可视化,缺乏不同周期中对数据、资源的检测、预警与自动优化 | 优:在IDE Terminal对数据进行分析,同时在在线平台中提供数据可视化。 劣:未提供独立的数据管理工具,提高了数据分析的难度。 |
| 高包容性和多应用场景 | 优:多种功能中均支持不同的数据/模型来源与走向,并在不同功能、产品、环境下提供了数据协同。 劣:在功能介绍的真实应用场景与示例介绍不足。 | 优:每个功能中均提供了相应应用场景的解决方案与技术架构供参考。 | 优:针对不同模型/数据提供了不同工具,对于不同工具均提供实例解析与文档,且汇总大量案例于AI在线社区/平台供用户学习与应用。 |
| 产品/功能丰富度与完备性 | 优:有着相对丰富的功能与子产品,在ML/DL的不同阶段均提供了几种功能,也集成在了Studio中,有相对完备性。 | 优:功能高度集成,内置丰富的应用场景与插件,文档系统更新及时,有较好的完备性。 劣:产品/功能抽象度较高,用户选择余地较少,ML/DL每个阶段只有1-2个功能。 | 优:有着非常丰富的产品链路,包含覆盖DL任务的各周期开发工具、端到端开发工具、开源产业模型库、在线带资源编程/服务平台和社区等。 劣:部分工具/产品中更新不及时,文档陈旧,完备性有所不足。 |
根据表11的平台评价对比绘制评价分析图如图61所示:
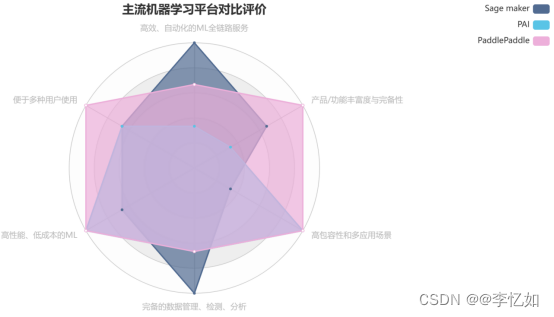
图61 主流机器学习平台评价分析图