一、移植初体验
1、直接编译三星移植版 uboot 尝试运行
(1) 复制到 linux 的源生目录下,然后解压开。


(2) 检查 Makefile 中的交叉编译工具链。

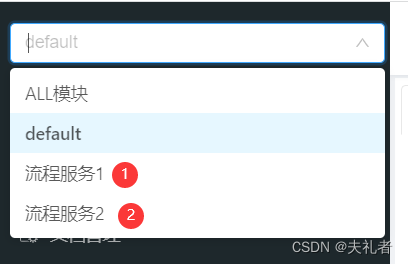
(3) 配置时使用:make smdkv210single_config,对应 include/configs/smdkv210single.h 头文件。
(4) 配置完成后直接 make 编译,编译完成后就进入烧录步骤。
make distclean
make smdkv210single_config
make -j8
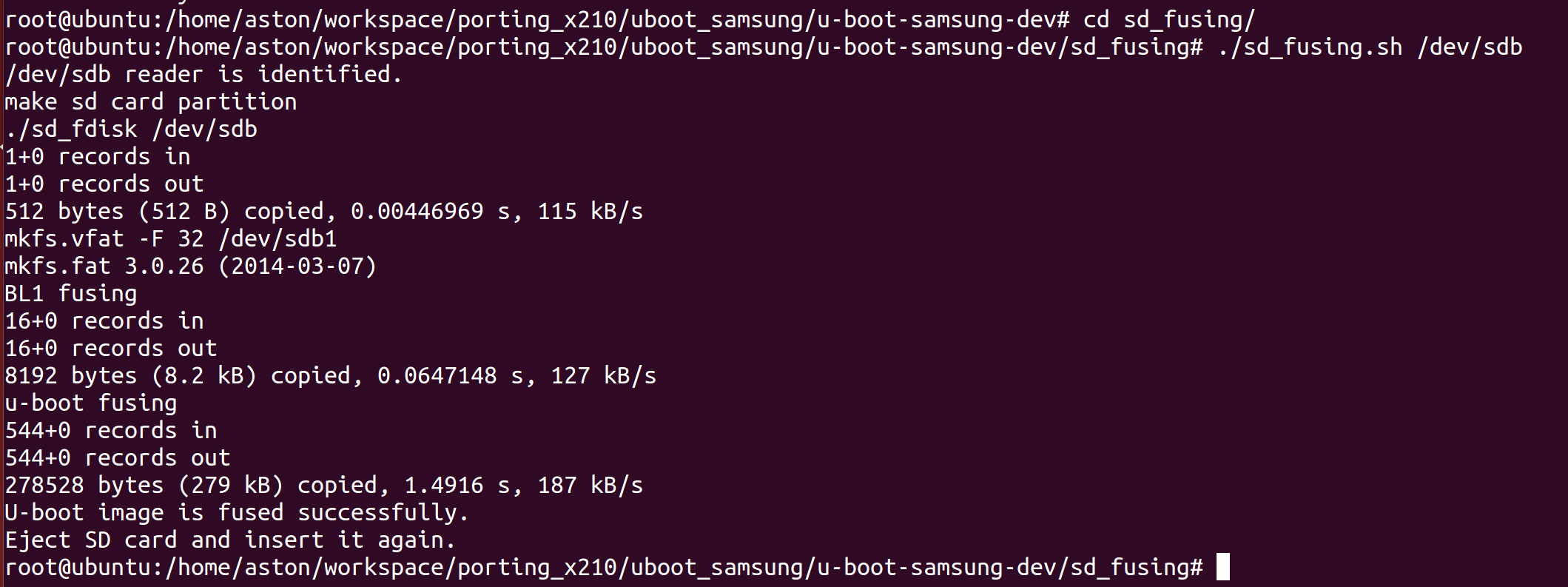
(5) uboot/sd_fusing 目录下有 sd_fusing.sh 脚本,用来烧录。
2、代码分析 & 问题查找
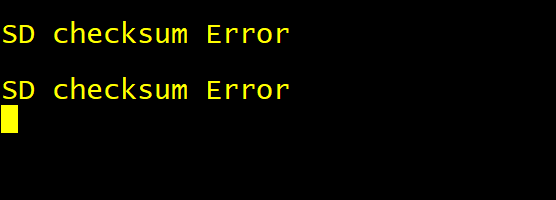

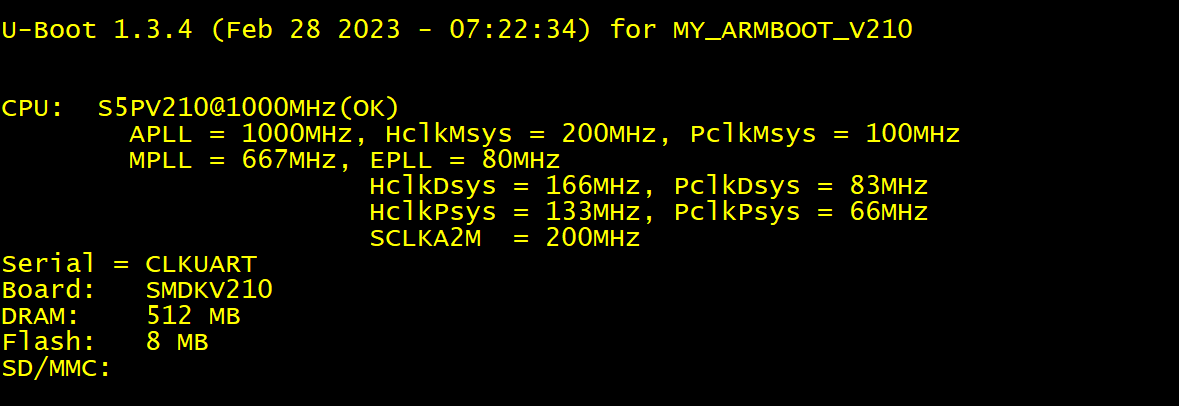
运行结果是:第一,串口无输出;第二,开发板供电锁存成功。
分析运行结果:uboot 中串口最早的输出在 “OK”,在 lowlevel_init.S 中初始化串口时打印出来的;串口无输出 “O” ,说明在打印 “O” 之前代码已经死掉了;开发板供电锁存在 lowlevel_init.S 中,开发板供电锁存成功,说明这个代码之前的部分是没问题的。两个结合起来得到结论:错误在开发板供电锁存代码和串口初始化打印 “O” 代码之间。
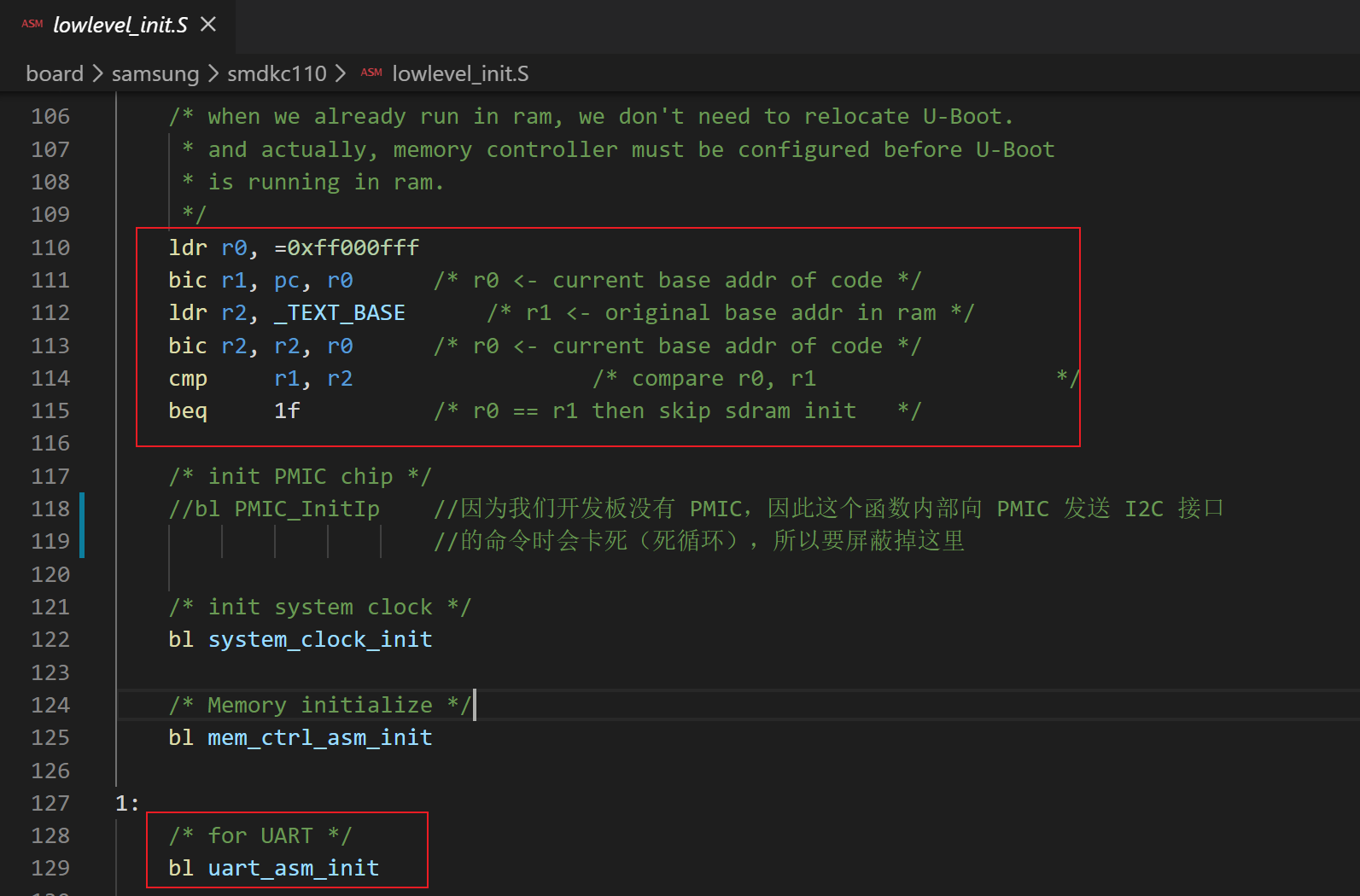
整个程序运行是从 start.S 开始的,看代码也从这里开始。
实际上只要屏蔽掉 bl PMIC_InitIp 这一行代码,然后重新编译,整个 uboot 就启动起来了。但是很多配置信息是有问题的,很多功能应该也是不能用的,都要去一一查验。
make dstclean
make smdkv210single_config
make -j8
cd sd_fusing/
./sd_fusing.sh /dev/sdb

二、时钟和 DDR 的配置移植
1、更改 CONFIG_IDENT_STRING
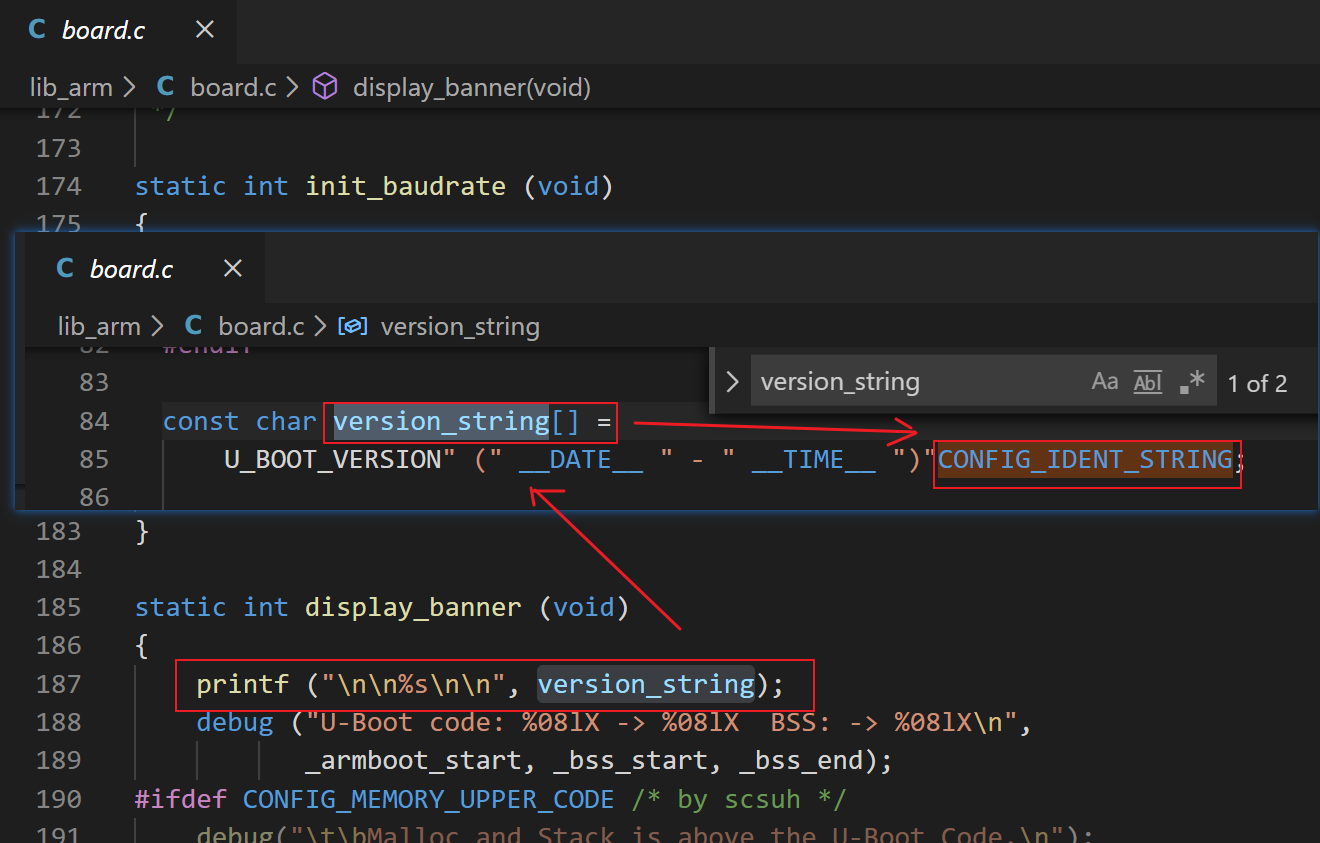
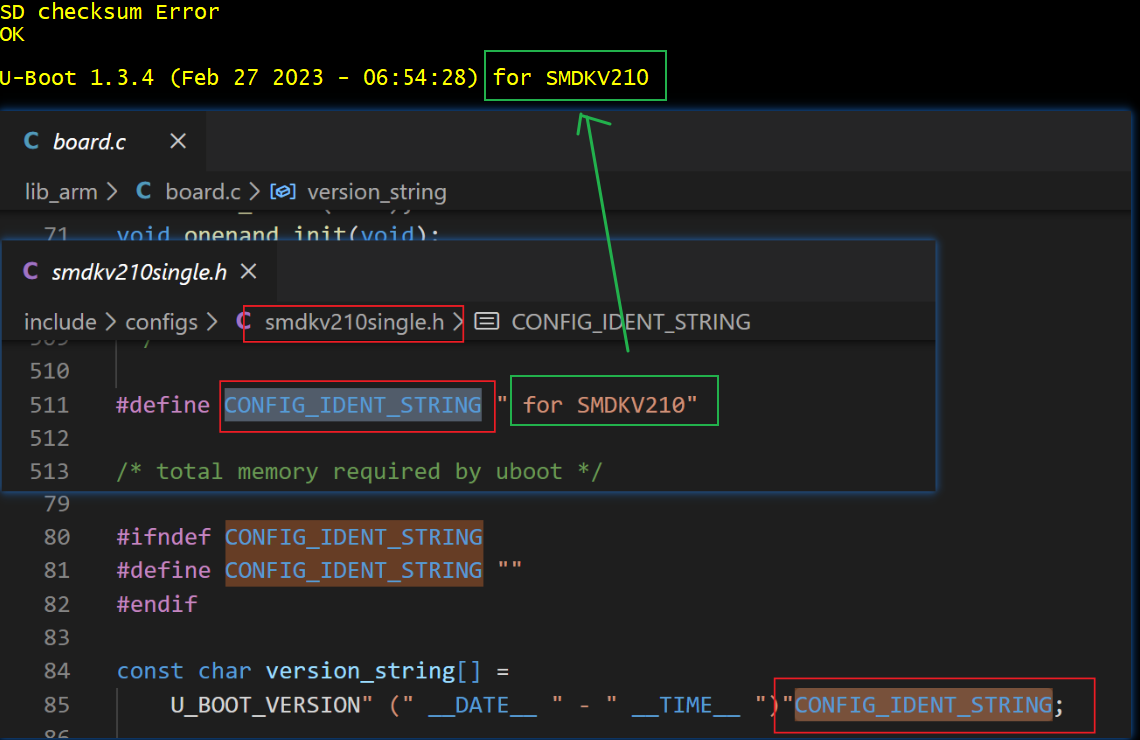
更改 CONFIG_IDENT_STRING 为 " for MY_ARMBOOT_V210",然后同步到 ubuntu 中的一份代码,然后 make distclean; make smdkv210single_config,然后make,然后烧录运行,检查打印出来的 banner 信息是否如我们改动的那样。

2、确认时钟部分的配置
(1) 时钟部分的运行结果本来就是对的,时钟部分的代码在 lowlevel_init.S 中的 bl system_clock_init 调用的这个函数中。函数的代码部分是没任何问题的,根本不需要改动,要改动的是寄存器写入的值,这些值都在配置头文件(smdkv210single.h)中用宏定义定义出来了。如果时钟部分要更改,关键是去更改头文件中的宏定义。
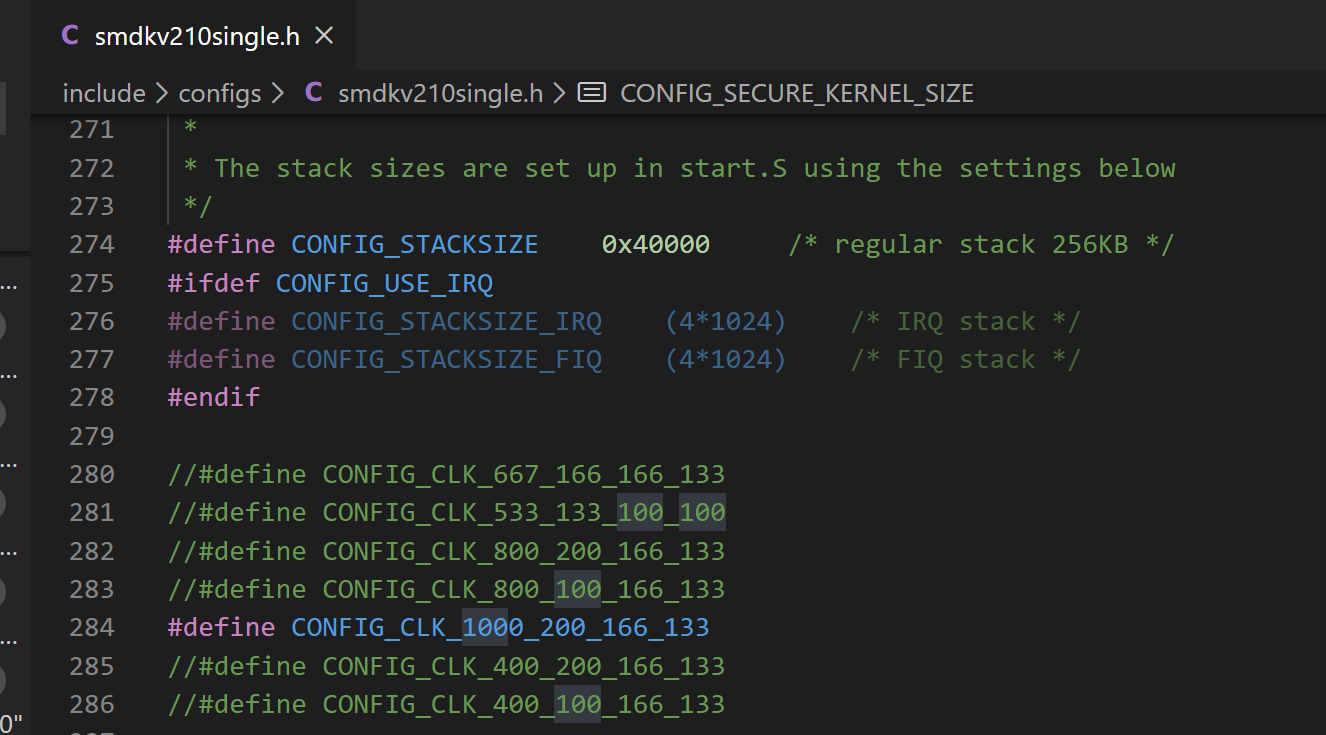
(2) 三星移植时已经把 210 常用的各种时钟配置全都计算好用宏开关来控制了。只要打开相应的宏开关就能将系统配置为各种不同的频率。
3、DDR 配置信息的更改
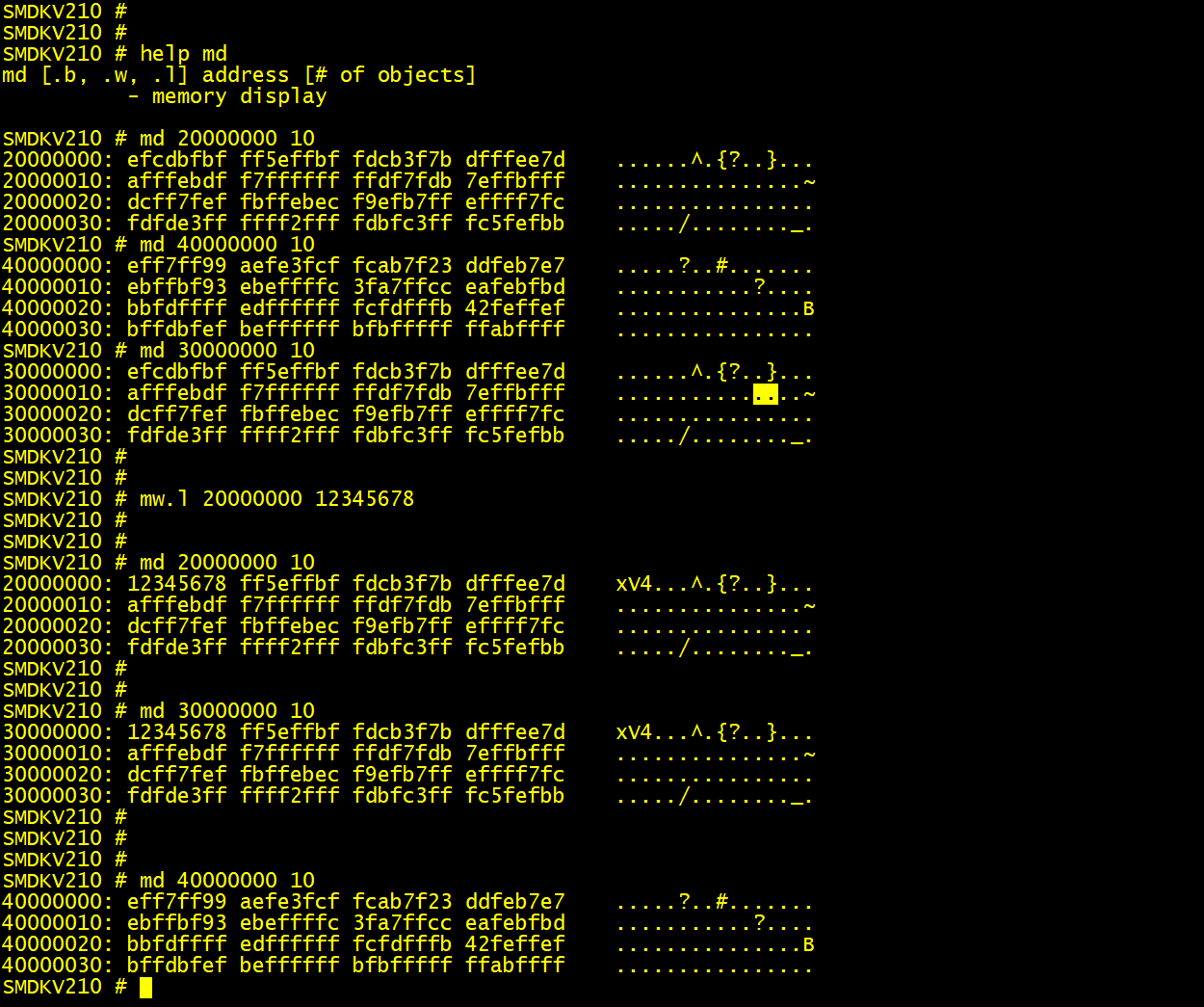
(1) 从运行信息以及 bdinfo 命令看到的结果,显示 DRAM bank0 和 1 的 size 值都设置错了。
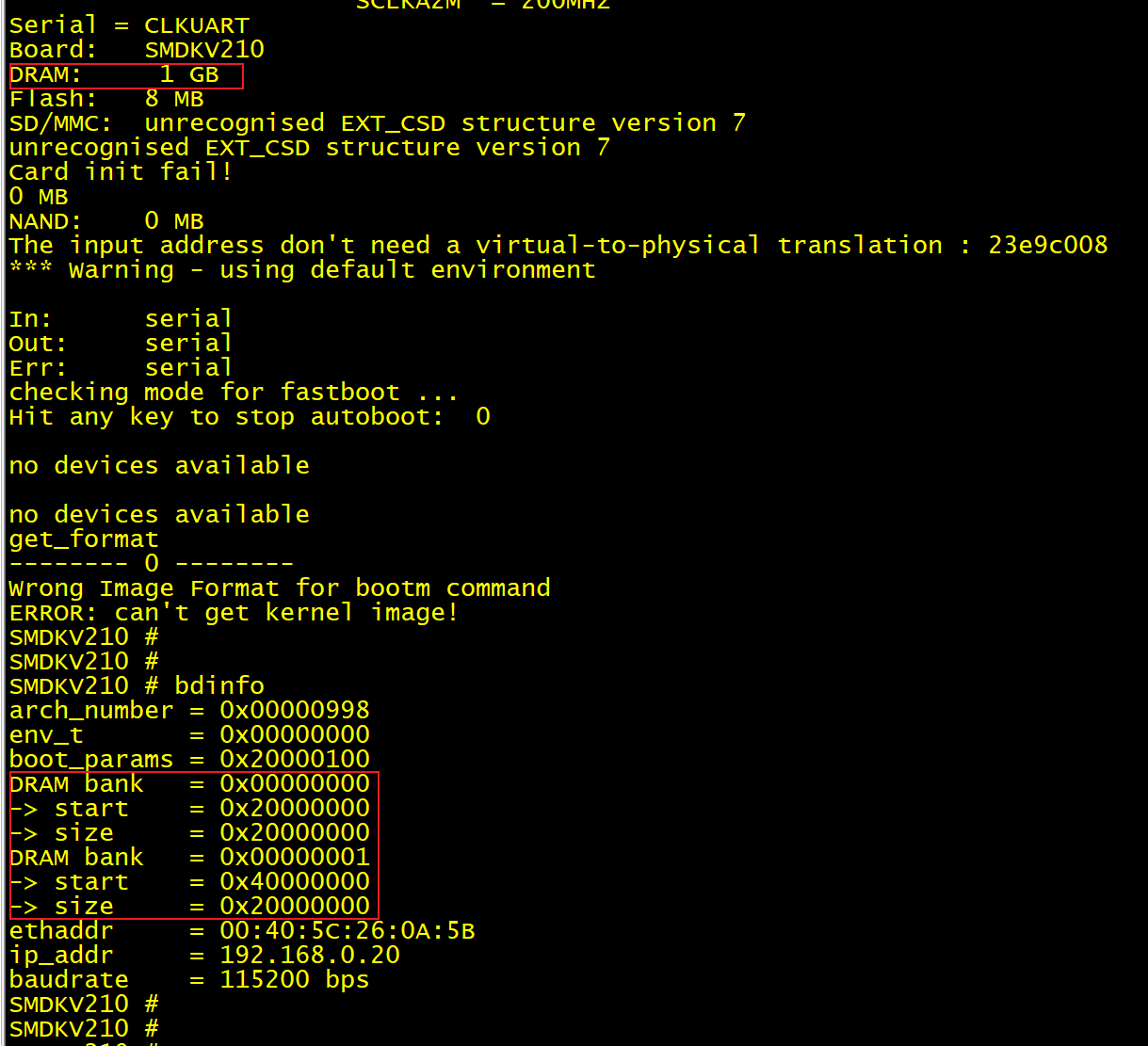
(2) 使用 md 和 mw 命令测试内存,发现 20000000 和 40000000 开头的内存都是可以用的,说明代码中 DDR 初始化部分是正确的,只是 size 错了。
(3) 内存部分配置成:
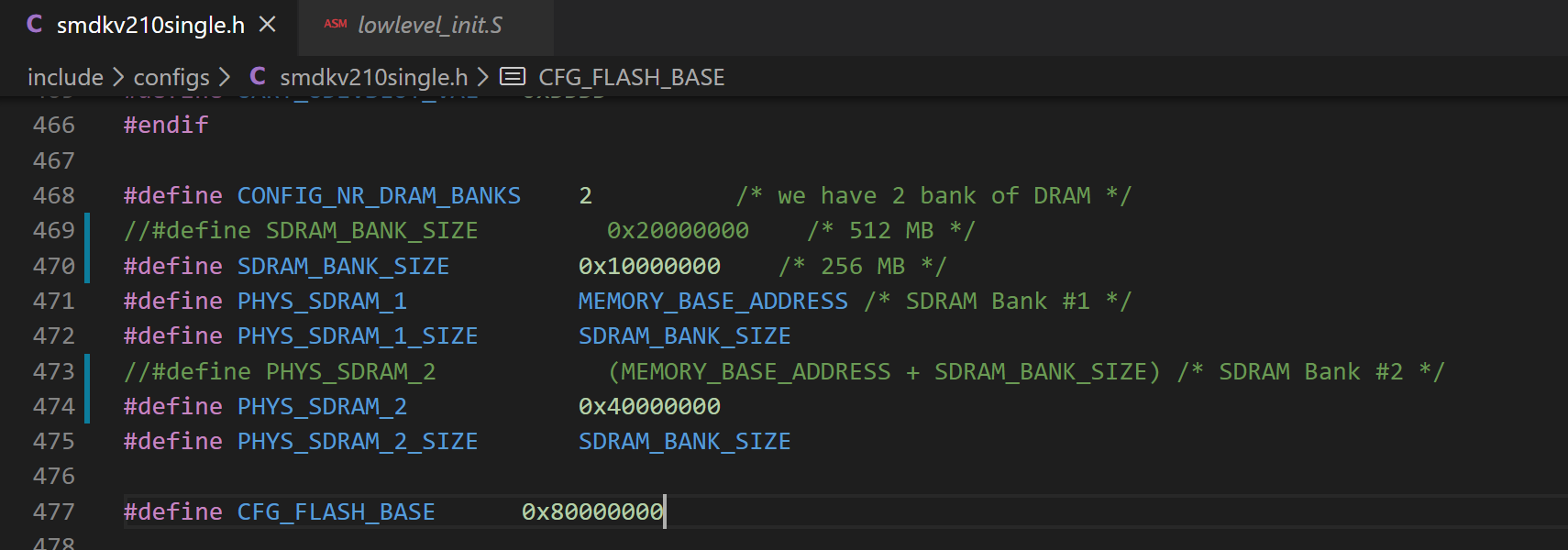
#define CONFIG_NR_DRAM_BANKS 2 /* we have 2 bank of DRAM */
//#define SDRAM_BANK_SIZE 0x20000000 /* 512 MB */
#define SDRAM_BANK_SIZE 0x10000000 /* 256 MB */
#define PHYS_SDRAM_1 MEMORY_BASE_ADDRESS /* SDRAM Bank #1 */
#define PHYS_SDRAM_1_SIZE SDRAM_BANK_SIZE
//#define PHYS_SDRAM_2 (MEMORY_BASE_ADDRESS + SDRAM_BANK_SIZE) /* SDRAM Bank #2 */
#define PHYS_SDRAM_2 0x40000000
#define PHYS_SDRAM_2_SIZE SDRAM_BANK_SIZE
#define CFG_FLASH_BASE 0x80000000
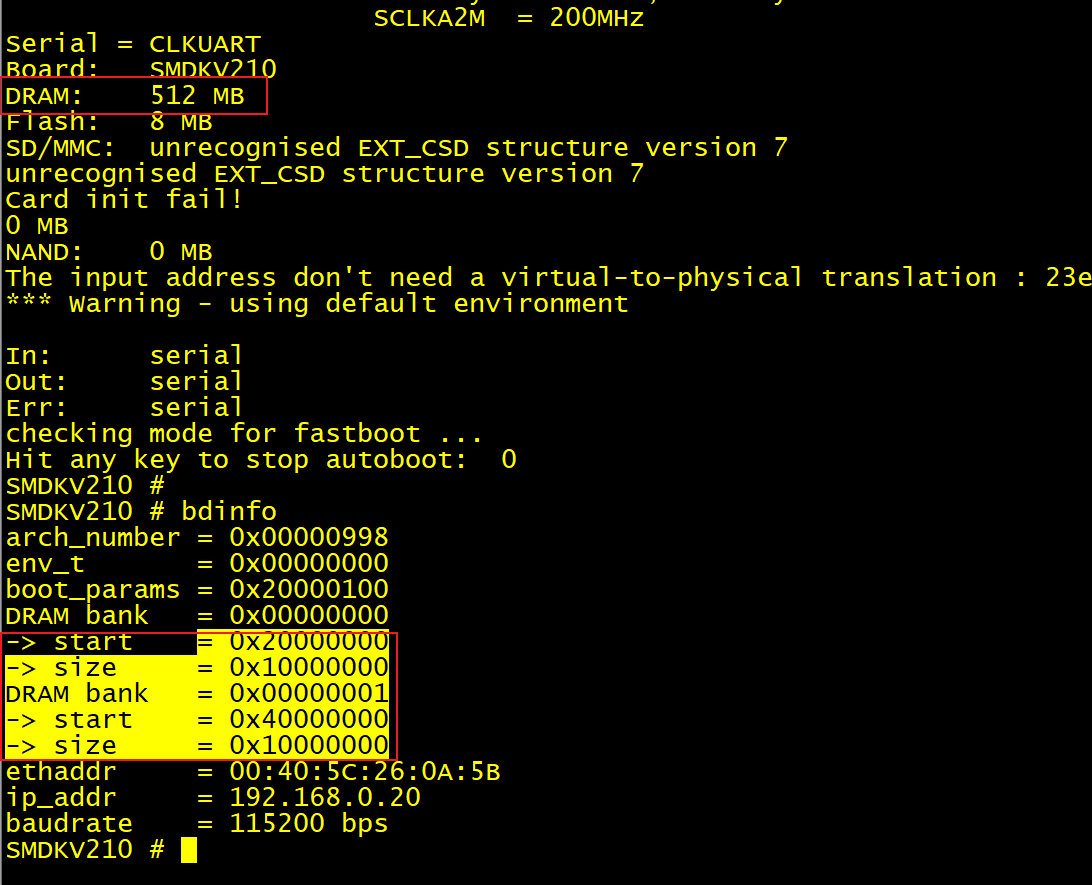
三、DDR地址另外配置
1、目标:将DDR端口0的地址配置为30000000开头
(1) 更改有 2 个目的:第一是让大家体验内存配置的更改过程;第二是 3 开头的地址和DRAM bank1 上 40000000 开头的地址就连起来了。这样我们就得到了地址连续的 512MB 内存,而原来我们得到的 512MB 内存地址是断续的。
2、DDR 初始化参数更改
(1) 根据裸机中讲 DDR 初始化部分的课程,和 uboot 前面分析 uboot 中 DDR 初始化部分的代码的课程,得出结论就是:DDR 的初始化代码部分是在 lowlevel_init.S 中写的,是不用动的。代码部分就是对相应寄存器做相应值的初始化;要动的是值,而 uboot 为了具有可移植性,把值都宏定义在 include/configs/xxx.h 中了。因此我们只需要去这个配置头文件中更改配置值即可。
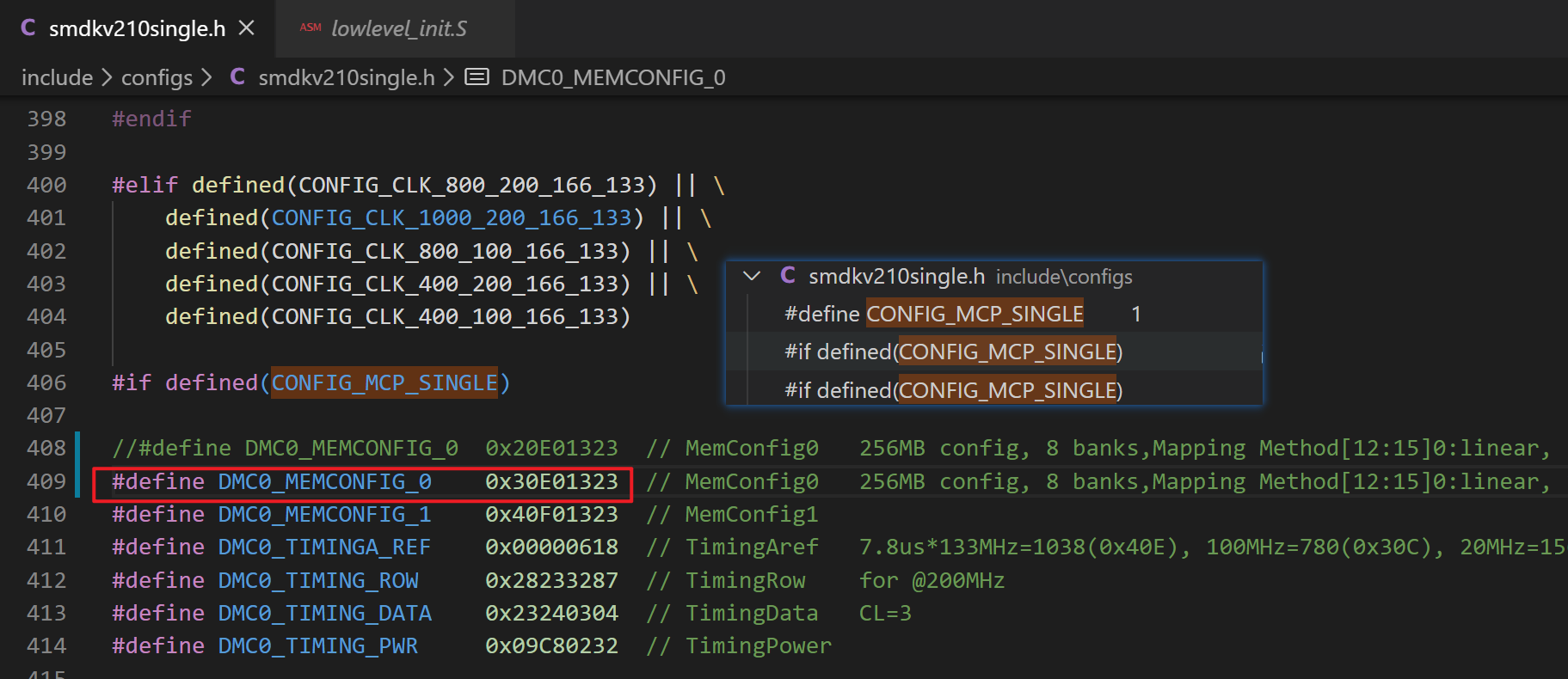
(2) 更改内容是:#define DMC0_MEMCONFIG_0 0x20E01323 改为:
#define DMC0_MEMCONFIG_0 0x30E01323 注意 20 改为 30 了。

3、smdkv210single.h 中相关宏定义修改
(1) 寄存器的值改了后,相当于是硬件配置部分做了更改。但是 uboot 中 DDR 相关的一些软件配置值还没更改,还在原来位置,所以要去更改。
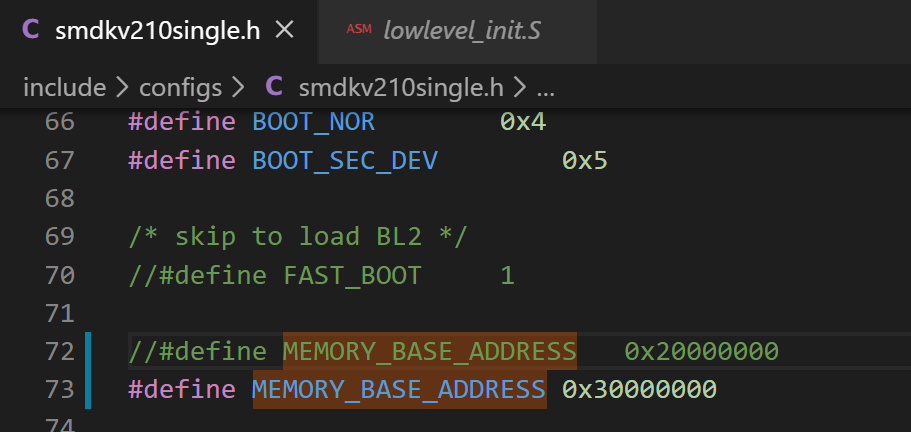
(2) #define MEMORY_BASE_ADDRESS 0x20000000 改为:
#define MEMORY_BASE_ADDRESS 0x30000000。
4、虚拟地址映射表中相应修改
(1) uboot 中开启了 MMU 对内存进行了段式映射,有一张内存映射表。
(2) 经过实际分析,发现这个内存映射只是把 20000000 开始的 256MB 映射到 C0000000 开头的 256MB。我们更改方法是将 2 改成 3.
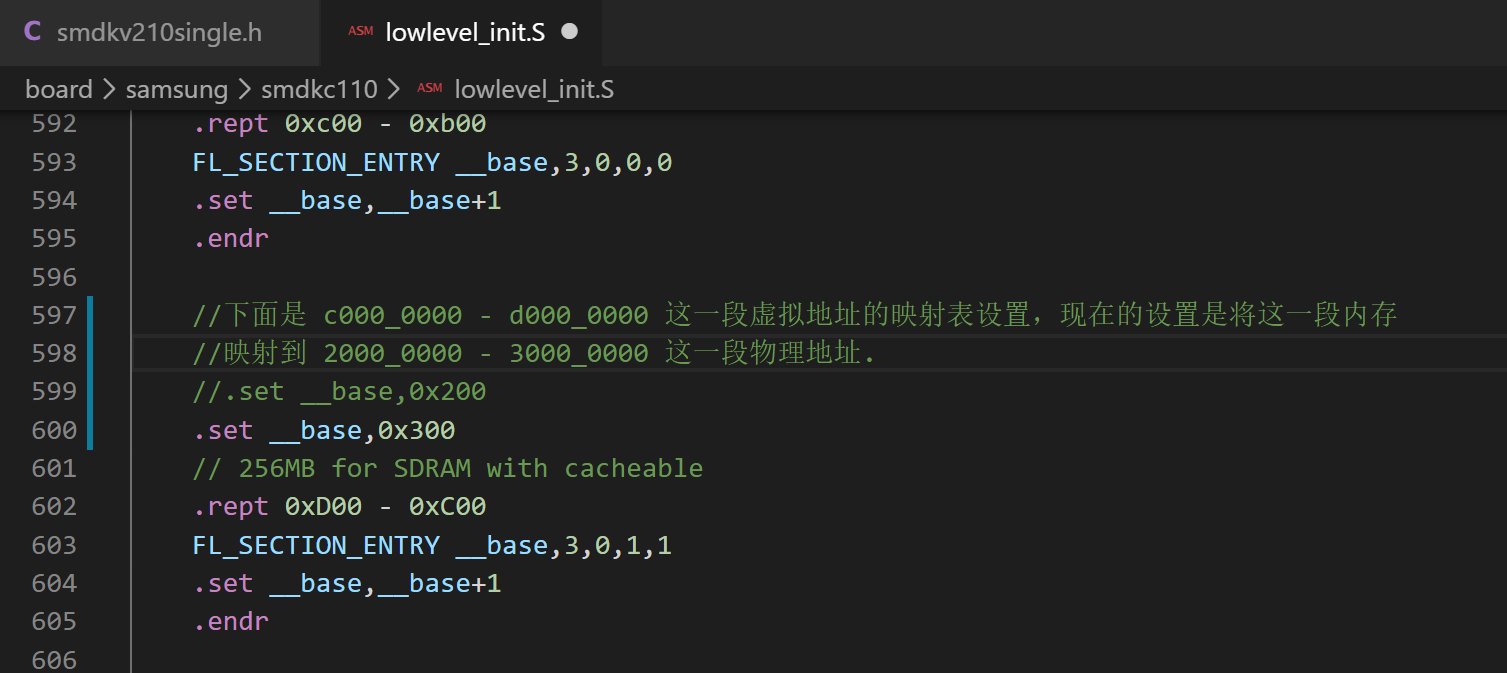
(3) 为了安全起见,再去配置头文件 smdkv210single.h 中查一遍,看看有没有其他的宏定义值和内存配置有关联的。

重新配置编译,烧录运行查看结果,发现还有问题。
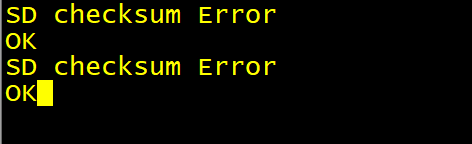
四、DDR 初始化参数更改2
1、修改 DMC0 的配置参数
(1) 修改 DDR 中 DMC0 的 memconfig_0 寄存器的配置值,将
#define DMC0_MEMCONFIG_0 0x30E01323 改为:
#define DMC0_MEMCONFIG_0 0x30F01323
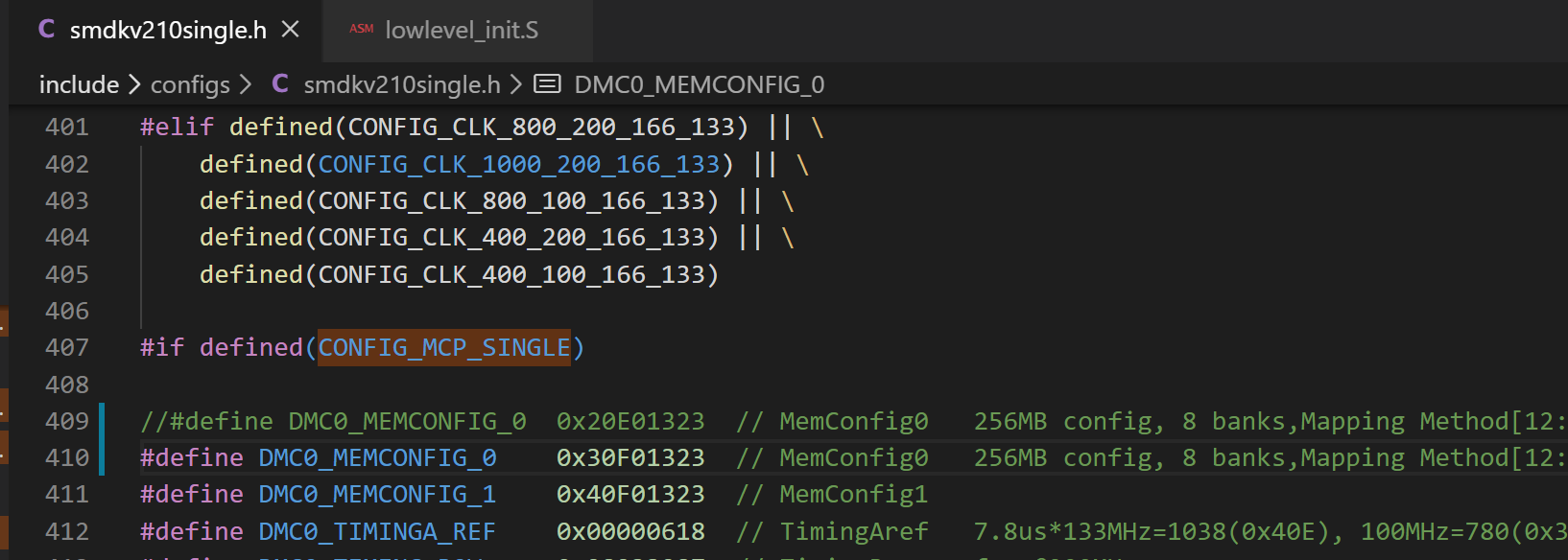
(2) 然后重新同步、编译烧写运行,发现 uboot 第二阶段运行了,但是整个 uboot 还是不成功。
(3) 分析问题,寻找解决方案。分析方法有 2 种:第一种靠经验、靠发现能力、靠直觉去找;第二种就是在整个代码中先基本定位错误地方,然后通过在源代码中添加打印信息来精确定位出错的代码,然后找到精确的出错位置后再去分析错误原因,从而找到解决方案。
2、修改虚拟地址到物理地址的映射函数
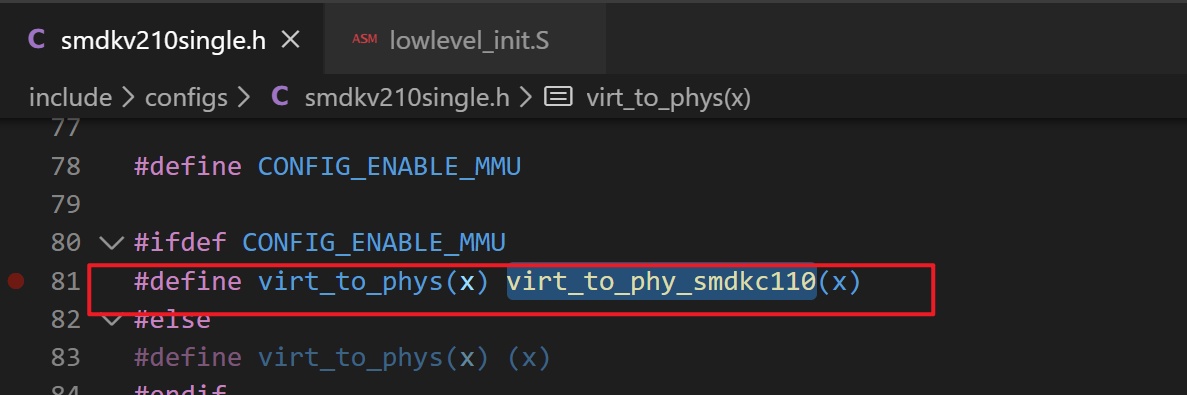
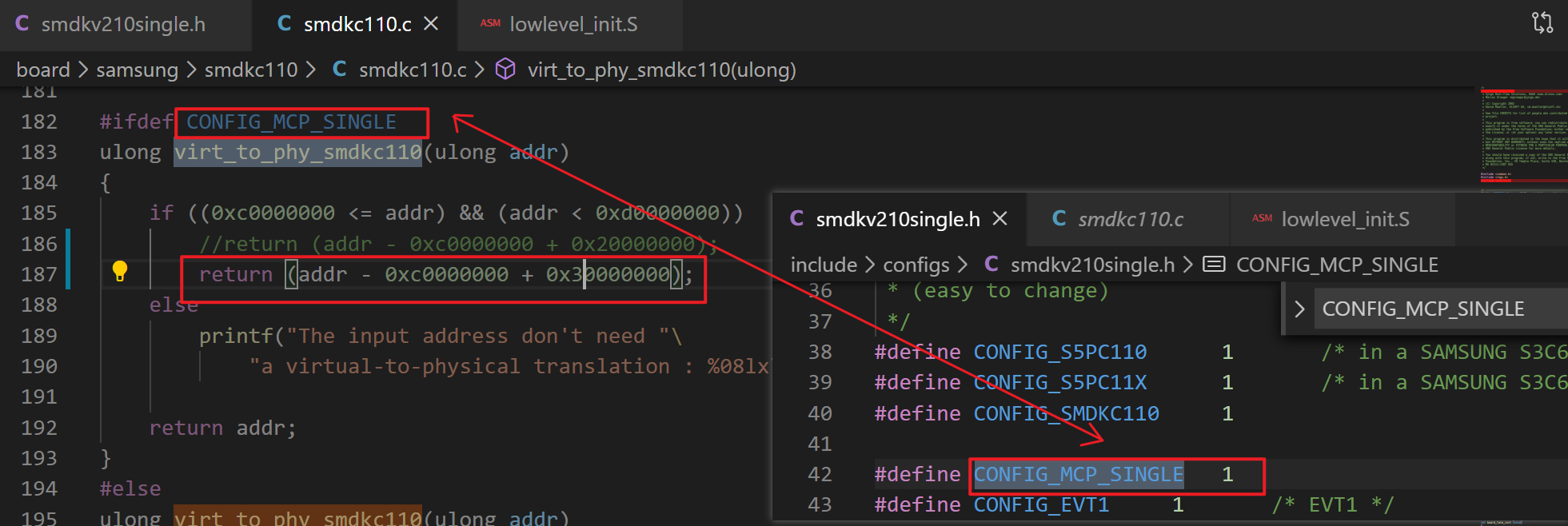
(1) 修改 uboot/board/samsung/smdkc110/smdkc110.c 中的 virt_to_phy_smdkc110,将其中的 20000000 改为 30000000 即可。
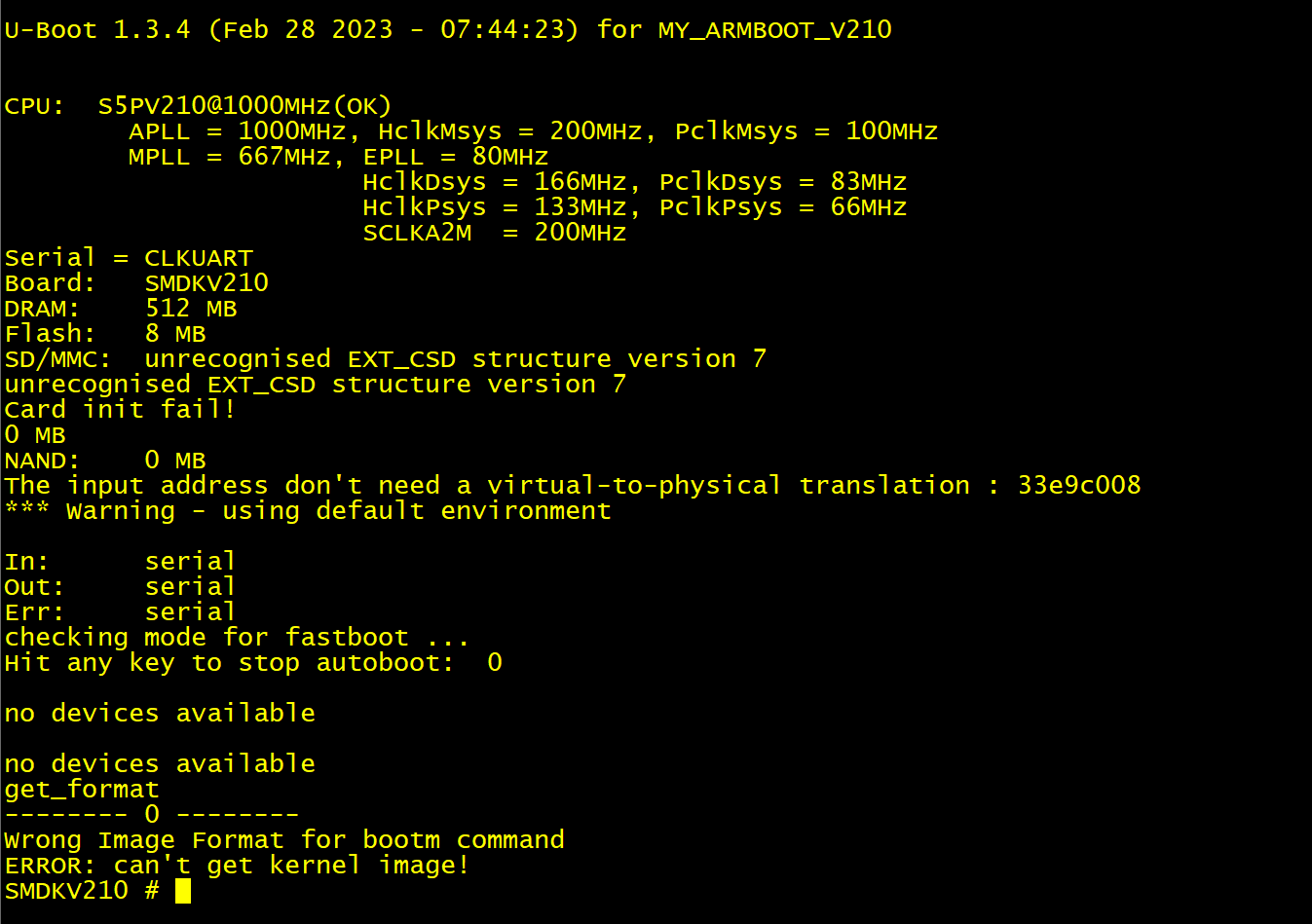
(2) 同步代码,然后重新编译烧录运行。
现象跟三星官方移植的那份源码效果是相同的。
源自朱友鹏老师.