本案例是案例(16)的Scrapy版本
一次运行程序,同时获取内容:获取商店详情、商品问题、商品答案;
效果如下图:
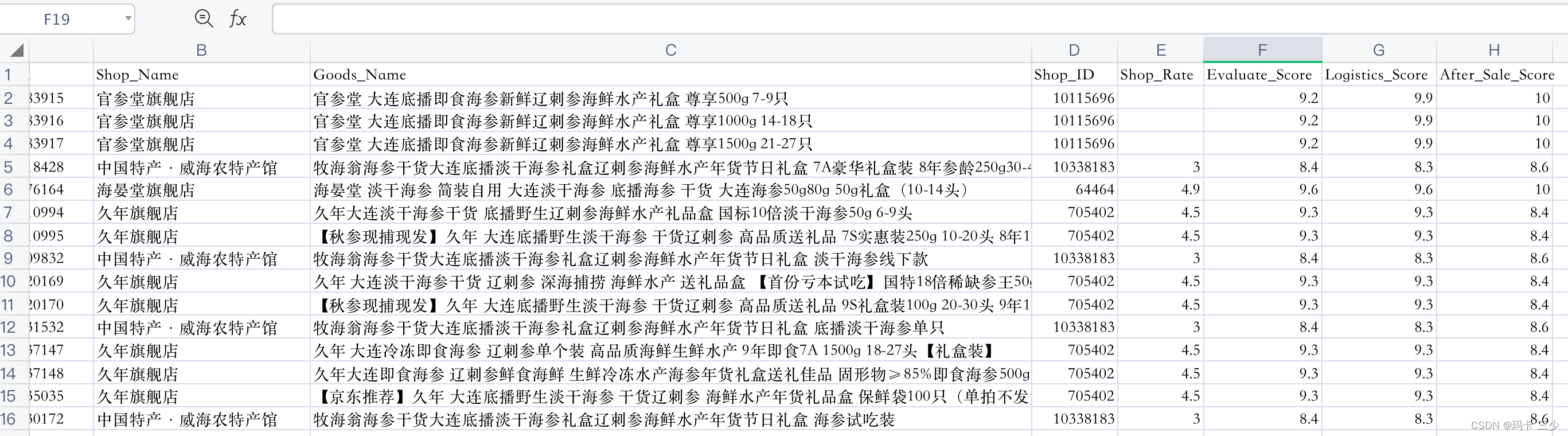
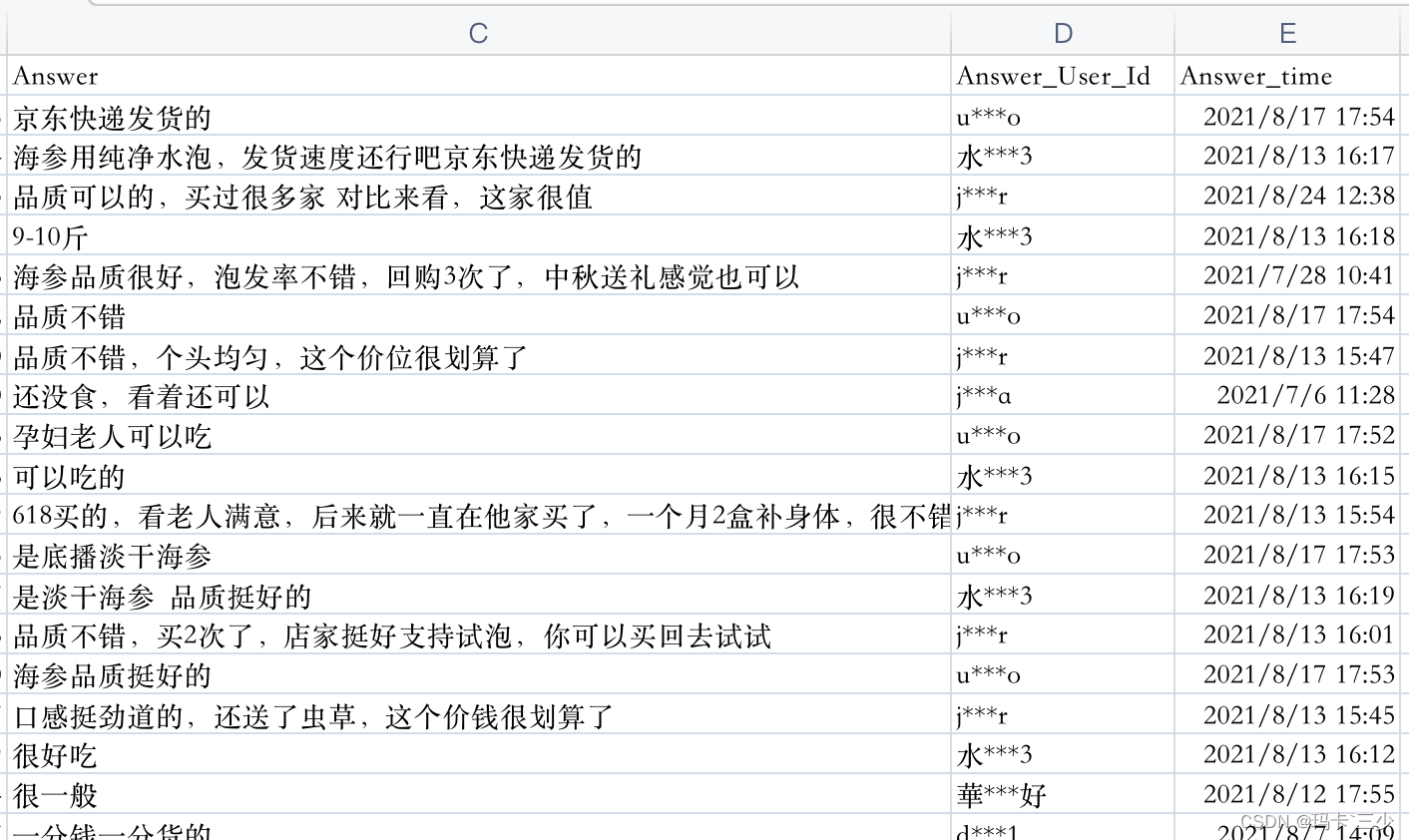
一.Scrapy框架从安装到运行的过程
1.安装scrapy框架
控制台输入:pip3 install scrapy
2.验证安装结果
➜ ~ scrapy -v
Scrapy 2.7.1 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
输入scrapy -v能显示出上面的内容说明安装成功了。
3.新建项目
scrapy startproject jd
4.新建 spider
scrapy genspider jd "jd.com"
注意新建spider时一定要进入到spiders目录下新建哦!
5.运行 spider
scrapy crawl jd_goods
下面会进行以下几步进行分析(下方演示过程全部使用chrome浏览器);
对应接口的分析过程同《案例16》分析过程相同咱就不在重复了啊!
下面来说scrapy配置细节
二.Scrapy配置
新建的scrapy项目都有一个settings.py文件的,这个文件中预留的配置非常多,我的配置如下
# Scrapy settings for jd project
import random
BOT_NAME = 'jd'
SPIDER_MODULES = ['jd.spiders']
NEWSPIDER_MODULE = 'jd.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60",
"Opera/8.0 (Windows NT 5.1; U; en)",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50"
]
USER_AGENT = random.choice(USER_AGENT_LIST)
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 在项处理器(也称为项目管道)中并行处理的并发项目的最大数量(每个响应)。
CONCURRENT_REQUESTS = 16
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 2.3 # "%.1f" % random.random()
RANDOMIZE_DOWNLOAD_DELAY = True
LOG_ENABLED = True
LOG_ENCODING = 'utf-8'
# 日志级别 CRITICAL, ERROR, WARNING, INFO, DEBUG
# LOG_LEVEL = 'ERROR'
# 将由Scrapy下载程序执行的并发(即同时)请求的最大数量。
# CONCURRENT_REQUESTS_PER_DOMAIN = 8
# # 将对任何单个域执行的并发(即同时)请求的最大数量。
# CONCURRENT_REQUESTS_PER_IP = 8
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"authority": "item-soa.jd.com",
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9",
"referer": "https://item.jd.com/",
"sec-fetch-mode": "no-cors",
"sec-fetch-site": "same-site",
}
MEDIA_ALLOW_REDIRECTS = True
HTTPERROR_ALLOWED_CODES = [302, 301, 401, 400]
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'jd.pipelines.ShopInfoPineline': 300,
# 'jd.pipelines.CommentPineline': 300,
'jd.pipelines.QuestionPineline': 300,
'jd.pipelines.AnswerPineline': 300,
}
PROXIES = [
'http://113.124.92.228:17551',
]
# 获取到的数据的存放目录名称
DATA_URI = 'data_file'
# 手动设置每一个id翻页的最大页码,例如限制同一个id翻页请求时控制前50页,此处可设置为50;负数时为不限制最大页码,则此时获取全部翻页数据
MAX_PAGE = 5
三.spider部分相关代码编写
3.1 店铺详情
def parse(self, response):
data = response.json()
p_id = response.meta['p_id']
if data.get("shopInfo") == None:
return
shop = data.get("shopInfo").get("shop")
# 自营店铺貌似也获取不到店铺的评价数据
if shop is None:
# 没有店铺评分的店,测试下来发现是封掉的店
return
shop_item = ShopItem()
shop_item['product_id'] = p_id
shop_item['shop_name'] = shop.get("name", '')
shop_item['goods_name'] = tool.translate_chars(
data.get('wareInfo').get("wname"))
shop_item['shop_id'] = shop.get('shopId', '')
shop_item['shop_rate'] = shop.get('scoreRankRateGrade', '')
shop_item['evaluate_score'] = shop.get('evaluateScore', '')
shop_item['logistics_score'] = shop.get('logisticsScore', '')
shop_item['after_Sale_score'] = shop.get('afterSaleScore', '')
item = {'key': 'shop', 'info': shop_item}
yield item
self.quesiton_params.update({'productId': p_id})
question_url = self.question_base_url + urlencode(self.quesiton_params)
yield Request(get_scraperapi_url(question_url),
cookies=self.cookies,
callback=self.question_parse,
meta={
"p_id": p_id,
'page': 1
})
3.2 商品问题
def question_parse(self, response):
data = response.json()
p_id = response.meta['p_id'] # product_id
page = response.meta['page']
totalPage = math.ceil(data.get("totalItem", 0) / 10)
questionList = data.get('questionList', [])
if page > totalPage:
return
if MAX_PAGE < page and MAX_PAGE > 0:
return
for question in questionList:
question_item = QuestionItem()
q_id = question.get('id')
question_item['product_id'] = p_id # 产品ID
question_item['question_id'] = q_id # 问题ID
question_item['question'] = tool.translate_chars(
question.get('content', '')) # 问题
question_item['question_user_id'] = question.get('userInfo').get(
'nickName', '') # 提问用户昵称
question_item['question_time'] = question.get('created',
'') # 提问日期
item = {'key': 'question', 'info': question_item}
yield item
answerCount = question.get("answerCount", 0)
# 直接保存
if answerCount > 0 and answerCount <= 2:
answerList = question.get('answerList', [])
for answer in answerList:
answer_item = AnswerItem()
answer_item['product_id'] = p_id # 产品ID
answer_item['question_id'] = answer.get('id', '') # 问题ID
answer_item['answer'] = tool.translate_chars(
answer.get('content', '')) # 答
answer_item['answer_name'] = answer.get('userInfo').get(
'nickName', '') # 答问用户id|name
answer_item['answer_time'] = answer.get('created',
'') # 答问日期
item = {'key': 'answer', 'info': answer_item}
yield item
elif answerCount > 2:
self.answer_params.update({'questionId': q_id, 'page': 1})
answer_url = self.answer_base_url + urlencode(
self.answer_params)
yield Request(get_scraperapi_url(answer_url),
callback=self.answer_parse,
meta={
"p_id": p_id,
"q_id": q_id,
'page': 1
})
if page == 1 and page < totalPage:
for k in range(2, totalPage):
if MAX_PAGE < k and MAX_PAGE > 0:
break
self.quesiton_params.update({
'productId': p_id,
'page': k,
})
question_url = self.question_base_url + urlencode(
self.quesiton_params)
yield Request(get_scraperapi_url(question_url),
callback=self.question_parse,
meta={
"p_id": p_id,
'page': k
})
四.pipelines|Item编写
4.1商品详情pipelines
class ShopInfoPineline(object):
def open_spider(self, spider):
# 产品ID 店铺名 商品名 店铺id 店铺星级 商品评价 物流履约 售后服务
if spider.name == 'jd_goods':
self.shop_info_line = "Product_Id,Shop_Name,Goods_Name,Shop_ID,Shop_Rate,Evaluate_Score,Logistics_Score,After_Sale_Score\n"
data_dir = os.path.join(settings.DATA_URI)
#判断文件夹存放的位置是否存在,不存在则新建文件夹
if not os.path.exists(data_dir):
os.makedirs(data_dir)
file_path = data_dir + '/shop.csv'
new_sku_path = data_dir + '/new_sku_id.csv'
self.file = open(file_path, 'w', encoding='utf-8')
self.new_sku_file = open(new_sku_path, 'w', encoding='utf-8')
self.file.write(self.shop_info_line)
def close_spider(self, spider): # 在关闭一个spider的时候自动运行
self.file.close()
self.new_sku_file.close()
def process_item(self, item, spider):
try:
if spider.name == 'jd_goods' and item['key'] == 'shop':
info = item['info']
shop_info_line = '{},{},{},{},{},{},{},{}\n'.format(
info.get('product_id'),
info.get('shop_name', ''),
info.get('goods_name', ''),
info.get('shop_id', ''),
info.get('shop_rate', ''),
info.get('evaluate_score', ''),
info.get('logistics_score', ''),
info.get('after_Sale_score', ''),
)
self.file.write(shop_info_line)
self.new_sku_file.write('{}\n'.format(info.get('product_id')))
except BaseException as e:
print("ShopInfo错误在这里>>>>>>>>>>>>>", e, "<<<<<<<<<<<<<错误在这里")
return item
4.2商品详情的Item
class ShopItem(scrapy.Item):
product_id = scrapy.Field() # 产品ID
shop_name = scrapy.Field() # 店铺名
goods_name = scrapy.Field() # 商品名
shop_id = scrapy.Field() # 店铺id
shop_rate = scrapy.Field() # 店铺星级
evaluate_score = scrapy.Field() # 商品评价
logistics_score = scrapy.Field() # 物流履约
after_Sale_score = scrapy.Field() # 售后服务
五.项目目录结构及结果
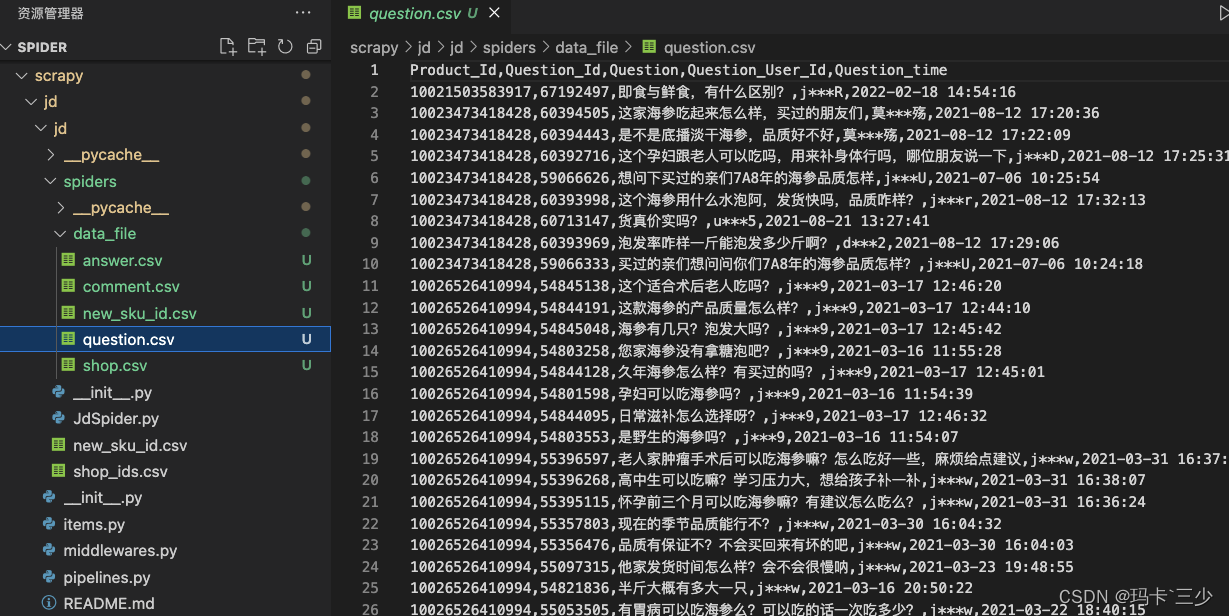
总结:scrapy框架作为一个分布式、多线程框架非常适合爬数据量非常大的网站,整体使用感觉非常不错,配置方便快捷、爬取速度也很快。不过也有缺点,就是容易被识别到,一不小心就被关小黑屋了、、、本案例只是自己纯学习练习使用!源码已同步到知识星 球!
后期会持续分享爬虫案例-100例,不想自己造轮子的同学可加入我的知识星球,有更多技巧、案例注意事项、案例坑点终结、答疑提问特权等你哦!!!
欢迎加入「python、爬虫、逆向Club」知识星球


![[数据结构]:10-二叉排序树(无头结点)(C语言实现)](https://img-blog.csdnimg.cn/66ca6eda1b4348cdbbbbb94a414f6cc5.png)