1 概述
树(Tree)是n(n >= 0)个结点的有限集。n = 0时称为空树。在任意一棵非空树中:
(1) 有且仅有一个特定的称为根(root)的结点;
(2) 当n > 1时,其余结点可分为m(m > 0)个互不相交的有限集T1、T2、…、Tm,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
2 结点分类
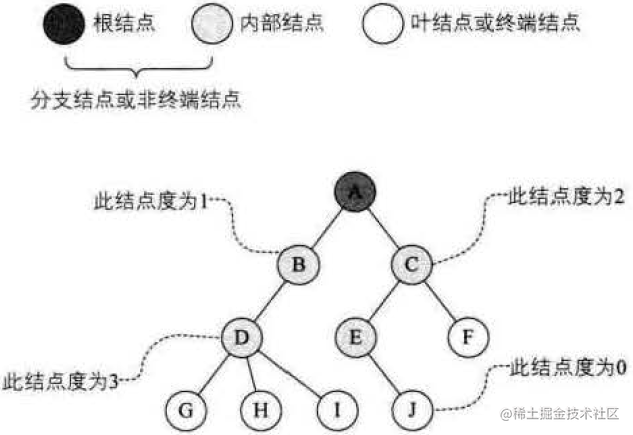
树的结点包含一个数据元素及若干指向其子树的分支。结点拥有的子树数称为结点的度(Degree)。度为0的结点称为叶结点(Leaf)或终端结点;度不为0的结点称为非终端结点或分支结点。除根结点之外,分支结点也称为内部结点。树的度是树内各结点的度的最大值。
3 结点间关系
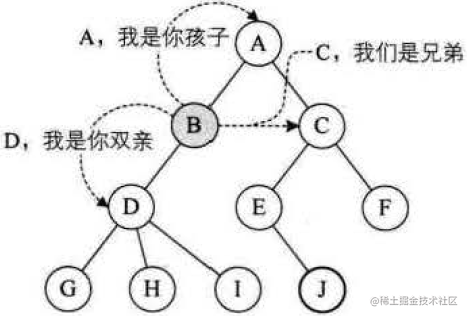
结点的子树的根称为该结点的孩子(Child),相应地,该结点称为孩子的双亲(Parent)。同一个双亲的孩子之间互称兄弟(Sibling),结点的祖先是从根到该结点所经分支上的所有结点。以某结点为根的子树中的任一结点都称为该结点的子孙。
4 树的其他相关概念
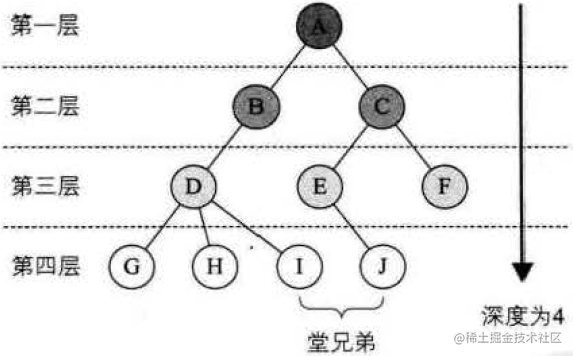
结点的层次(Level)从根开始定义起,根为第一层,根的孩子为第二层。其双亲在同一层的结点互为堂兄弟。树中结点的最大层次称为树的深度(Depth)或高度。
如果将树中结点的各子树看成从左至右是有次序的,不能互换的,则称该树为有序树,否则称为无序树。森林(Forest)是m(m >= 0)棵互不相交的树的集合。对树中每个结点而言,其子树的集合即为森林。
5 抽象数据类型

6 树的存储结构
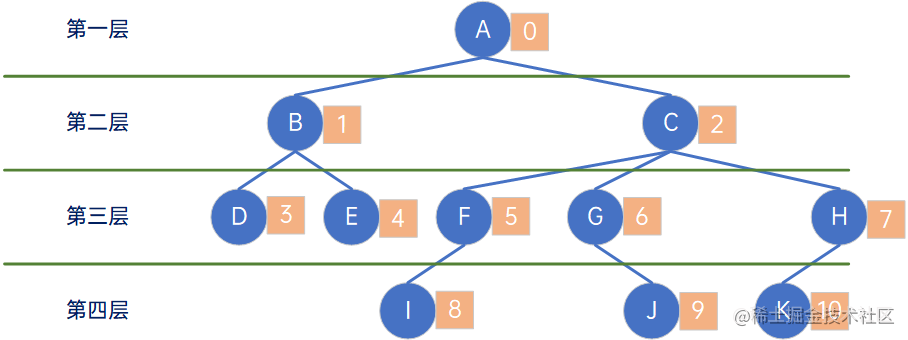
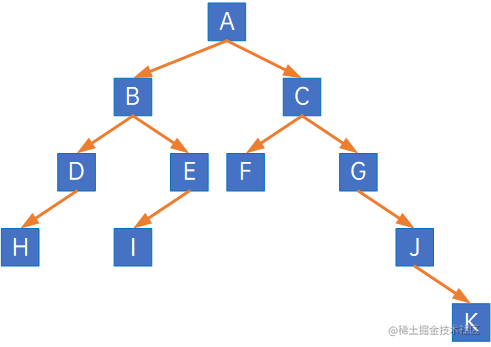
首先,需要知道,在一棵树中,每个结点都是有编号的,从第一层开始依次从左向右、从上向下,从0开始计算编号,如下图所示:
6.1 双亲表示法
在结点中定义一个指针,指向其Parent(双亲)结点的存储结构,称为双亲表示法。
/**
* 双亲表示法结点
*
* @author Korbin
* @date 2023-01-18 11:11:13
**/
@Data
public class ParentTreeNode<T> {
/**
* 数据元素
**/
private T data;
/**
* 双亲指针
**/
private int parent;
}
没有双亲的结点,即根结点,其双亲指针指向-1。
双亲表示法中,树结构会定义结点数组,以及根结点位置、总结点数等信息:
/**
* 树的双亲表示法
*
* @author Korbin
* @date 2023-01-18 10:21:28
**/
public class ParentTree<T> {
/**
* 结点
**/
private ParentTreeNode<T> nodes;
/**
* 最大结点数量
**/
private int maxSize;
/**
* 根结点指针
**/
private int root;
/**
* 结点数量
**/
private int length;
}
对于如下一棵树,按照双亲表示法,可得到其data和parent信息:
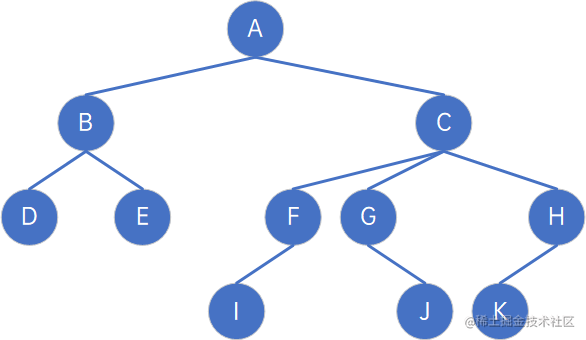
| 下标 | data | parent |
|---|---|---|
| 0 | A | -1 |
| 1 | B | 0 |
| 2 | C | 0 |
| 3 | D | 1 |
| 4 | E | 1 |
| 5 | F | 2 |
| 6 | G | 2 |
| 7 | H | 2 |
| 8 | I | 5 |
| 9 | J | 6 |
| 10 | K | 7 |
这样的存储结构,我们可以根据结点的parent指针很容易找到它的双亲结点,所用的时间复杂度为O(1),直到parent为-1时,表示找到了树结点的根。
可如果我们要知道结点的孩子是什么,那就只能遍历树了。这种情况下,可以考虑增加一个域,表示最左边的孩子位置,也叫长子域,对于没有孩子的结点,这个长子域就设置为-1,那么树的结点信息就变成了:
| 下标 | data | parent | firstChild |
|---|---|---|---|
| 0 | A | -1 | 1 |
| 1 | B | 0 | 3 |
| 2 | C | 0 | 5 |
| 3 | D | 1 | -1 |
| 4 | E | 1 | -1 |
| 5 | F | 2 | 8 |
| 6 | G | 2 | 9 |
| 7 | H | 2 | 10 |
| 8 | I | 5 | -1 |
| 9 | J | 6 | -1 |
| 10 | K | 7 | -1 |
当然,也可以按需要,添加其他域,比如添加右兄弟域来体现兄弟关系等。
6.2 孩子表示法
孩子表示法,即把每个结点的孩子结点排列起来,以单链表作存储结构,则n个结点有n个孩子链表,如果是叶子结点则此单链表为空,然后n个头指针又组成一个线性表,采用顺序存储结构,存放进一个一维数组中。
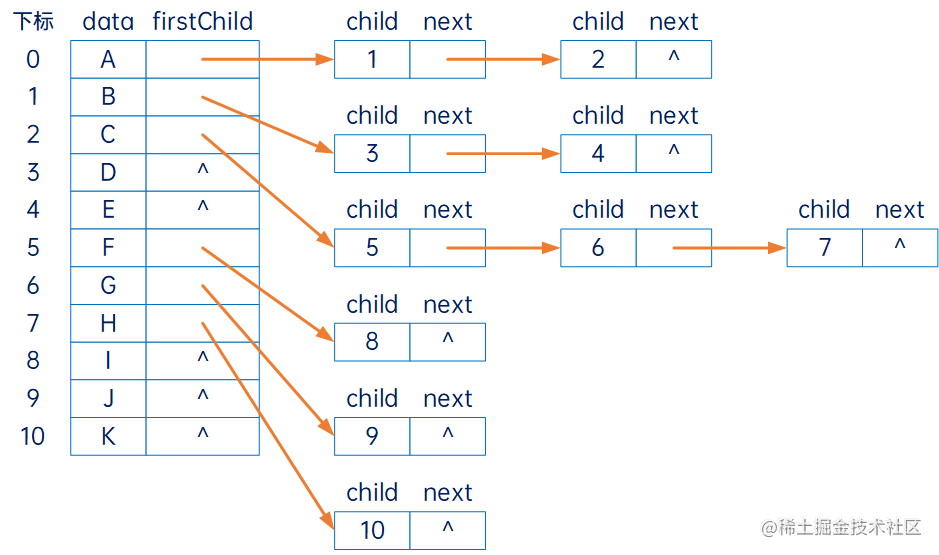
为此,设计两种结点结构,一个是孩子链表的孩子结点:

其中child是数据域,用来存储某个结点在表头数组中的下标,next是指针域,用来存储指向下一个孩子结点的指针。
另一个是表头数组的表头结点,如下所示:

其中data是数据域,存储某结点的数据信息,firstChild是头指针域,存储该结点的孩子链表的头指针。
同样,如果为了提高查询某结点的双亲时,可以在这个结构中,添加双亲指针,类似:
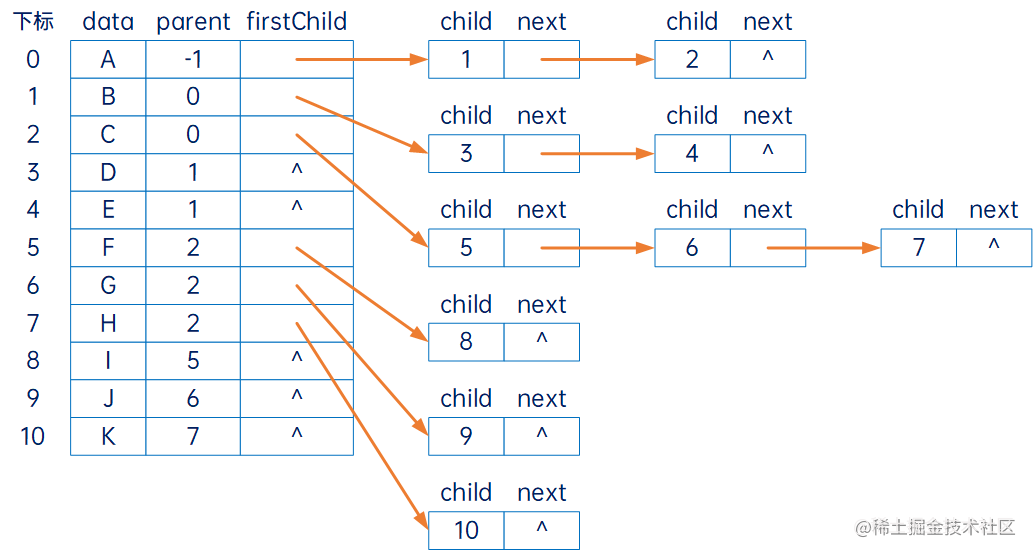
这种结构叫双亲孩子表示法。
6.3 孩子兄弟表示法
任意一棵树,它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的,因此我们设置两个指针,分别指向该结点的长子和右兄弟:

对于下面的树来说,结构变更为:
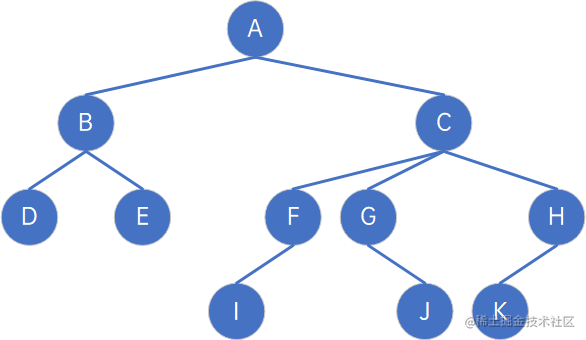
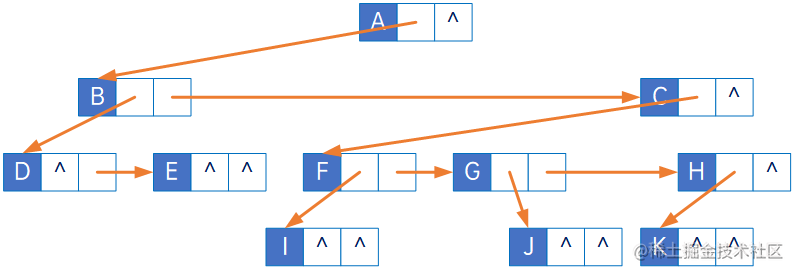
这种表示法,给查找某个结点的某个孩子带来了方便,只需要通过firstChild找到此结点的长子,然后再通过长子结点的rightSib,找到它的二弟,接着一直下去,直到找到具体的孩子。
实际上,这种处理方式,直接把一棵复杂的树,变更成了一棵二叉树:
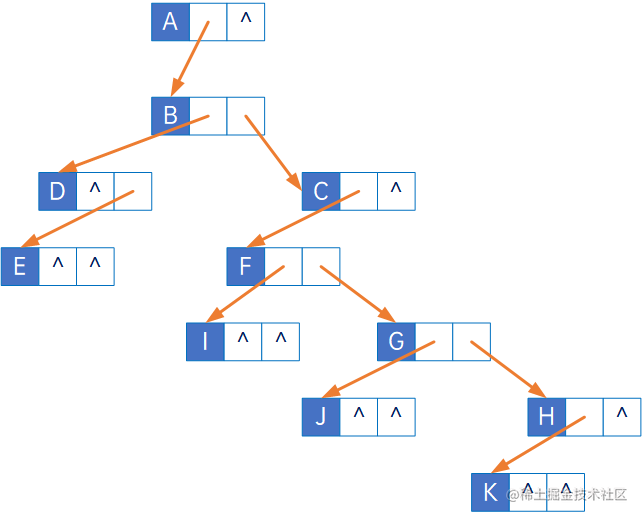
7 二叉树
7.1 概述
二叉树(Binary Tree)是n(n >= 0)个结点的有限集合,该集合或者为空集(称为空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树的二叉树组成。
二叉树的特点:
(1) 每个结点最多有两棵子树,所以二叉树中不存在度大于2的结点;
(2) 左子树与右子树是有顺序的,次序不能任意颠倒;
(3) 即使树中某结点只有一棵子树,也要区分它是左子树还是右子树;
二叉树具有五种形态:
(1) 空二叉树;
(2) 只有一个根结点;
(3) 根结点只有左子树;
(4) 根结点只有右子树;
(5) 根结点既有左子树也有右子树;
7.2 特殊二叉树
(1) 斜树:所有的结点都只有左子树的二叉树叫左斜树,所有结点都只有右子树的二叉树叫右斜树,两者统称斜树。线性表结构就可以理解为是树的一种极其特殊的表现形式;
如下为左斜树:
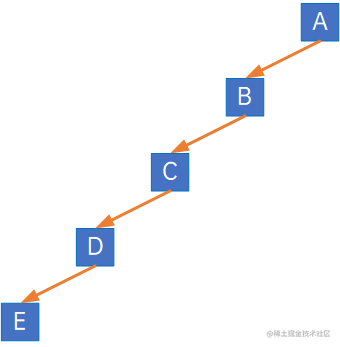
如下为右斜树:
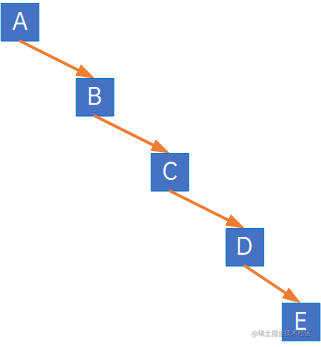
(2) 满二叉树:在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树:
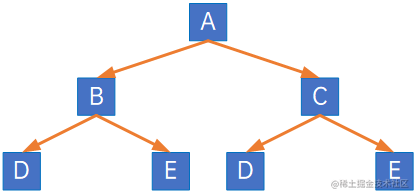
单是每个结点都存在左右子树,不能算是满二叉树,还必须所有的叶子都在同一层上,这就做到了整棵树的平衡,因此满二叉树的特点有:
1) 叶子只能出现在最下一层,出现在其他层就不可能达到平衡;
2) 非叶子结点的度一定是2;
3) 在同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多;
(3) 完全二叉树:对一棵具有n个结点的二叉树按层序编号,如果编号为i(1 <= i <= n)的结点与同样深度的满二叉树中编号为i的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树。
满二叉树是完全二叉树,但完全二叉树不是满二叉树。
上文讲过树的编号,如下:
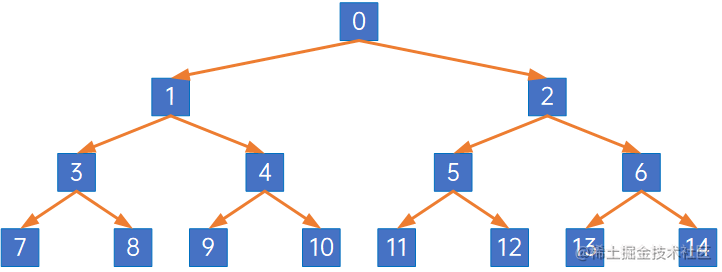
这是一棵满二叉树,如果去掉其中一些节点:
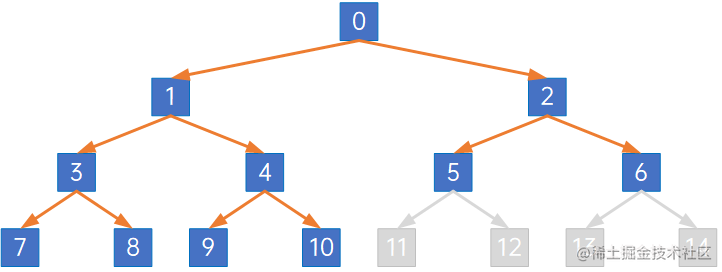
其他结点的编号与满二叉树相同,那这可以称为一棵完全二叉树。
而如果是以下情况:
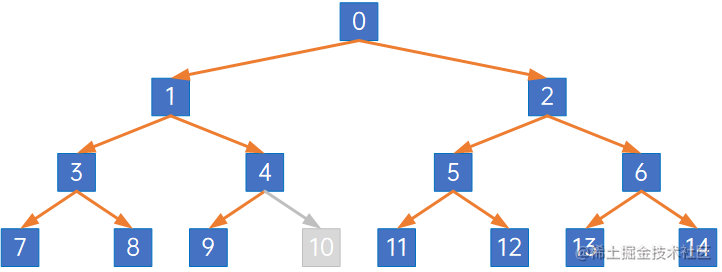
编号为10的结点被删除了,其后的11、12、13、14结点的编号都变小了,不再与满二叉树相同,则此树不再是完全二叉树。
由此可见,将满二叉树从编号最大的结点,依次从右向左,从下向上删除,无论删除多少结点,都是完全二叉树,否则不是完全二叉树。
因此完全二叉树有以下特点:
1) 叶子结点只能出现在最下两层;
2) 最下层的叶子一定集中在左部连续位置;
3) 倒数二层,若有叶子结点,一定都在右部连续位置;
4) 如果结点度为1,则该结点只有左孩子;
5) 同样结点数的二叉树,完全二叉树的深度最小;
7.3 二叉树的性质
性质一:在二叉树的第i层上至多有2i-1个结点(i >= 1)。
性质二:深度为k的二叉树至多有2k - 1个结点(k >= 1)。
性质三:对任何一棵二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0 = n2 + 1。
性质四:具有n个结点的完全二叉树的深度为(int)(log2n) + 1。
性质五:如果对一棵有n个结点的完全二叉树(其深度为(int)(log2n) + 1)的结点按层序编号(从第1层到第(int)(log2n) + 1层,每层从左到右),对任一结点i(1 <= i <= n)有:
(1) 如果i = 1,则结点i是二叉树的根,无双亲;如果i > 1,则其双亲是结点(int)(i / 2);
(2) 如果2i > n,则结点i无左孩子(结点i为叶子结点);否则其左孩子是结点2i;
(3) 如果2i + 1 > n,则结点i无右孩子;否则其右孩子是结点2i + 1;
7.4 二叉树的顺序存储结构
二叉树的顺序存储结构,就是用一维数组来存储二叉树的结点,并且存储的位置,也就是数组的下标要能体现结点之间的逻辑关系,比如双亲与孩子的关系,左右兄弟的关系,如果出现无左孩子或右孩子时,则空置一个数组元素位,如:
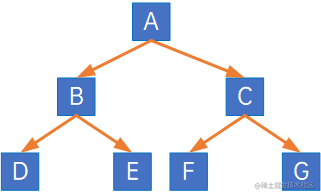
表示为:

假设数组为array,根据上文描述的二叉树特性,可知,array[0]为根结点,因为数组的下标是从0开始的,所以实际上,这是树上的第1个元素,那么,array[0]的左子结点是第2 * 1个元素,其右结点是2 * 1 + 1个元素,即左结点是array[1],右结点是array[2]。同理,根据特性还可知,下标为5,即第6个元素存储的结点的父结点是第6/2个结点,即下标为2(数组的下标减1,即6/2 - 1)的结点。
当然,这样计算过于复杂了,如果完全按数组的下标计算的话,应是:
(1) 下标为i的结点的左子结点的下标为2 * i + 1,右子结点的下标为2 * i + 2;
(2) 下标为i的结点的双亲结点下标为(int)((i - 1) / 2);
继续看,下面二叉树:
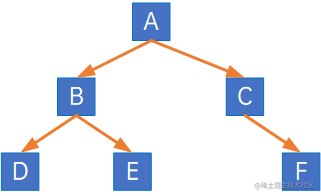
注意,结点C没有左子结点,此时,在进行顺序存储时,C的左子结点位置应存储一个空值:

而如下树:
存储结构则为:

可见,在使用数组对二叉树进行存储时,数组每个元素应存储的结点,是按完全二叉树设计的,但凡完全二叉树中有一个结点不存在时,此结点对应的数组位置应存储一个空值。
这种存储结构,只有在针对完全二叉树时,才不会浪费空间,否则都会造成一定的空间浪费。
7.5 二叉树的链式存储结构
既然顺序存储适用性不强,我们就要考虑链式存储结构,二叉树每个结点最多有两个孩子,所以为它设计一个数据域和两个指针域即可,这样的链表叫做二叉链表。如果添加一个指向其双亲的指针域,则称为三叉链表。
import lombok.Data;
import java.util.UUID;
/**
* 二叉树结点
*
* @author Korbin
* @date 2023-01-18 17:46:55
**/
@Data
public class BinaryTreeNode<T> {
/**
* 数据域
**/
private T data;
/**
* id,用于判断是否相等时使用
**/
private String id = UUID.randomUUID().toString();
/**
* 左子结点
**/
private BinaryTreeNode<T> leftChild;
/**
* 右子结点
**/
private BinaryTreeNode<T> rightChild;
/**
* 判断节点是否相等
*
* @param node 待判断的结点
* @return 相等返回true,否则返回false
* @author Korbin
* @date 2023-01-19 17:22:46
**/
public boolean equals(BinaryTreeNode<T> node) {
return node.getData().equals(data) && node.getId().equals(id);
}
}
7.5.1 创建树
首先将树中所有叶子结点,我没有左孩子或右孩子的结点,使用一个虚拟结点替换,如原始结点为:
添加扩展结点后:
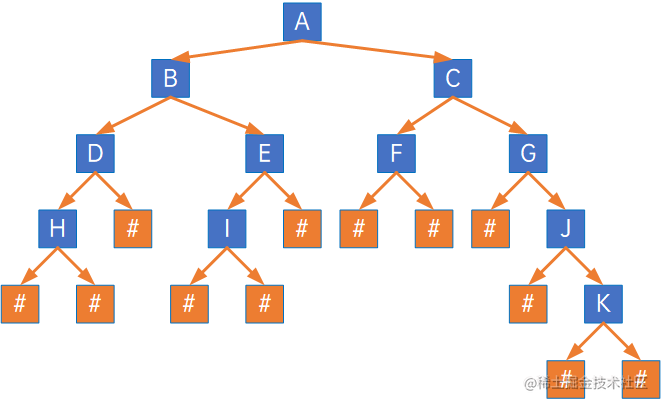
添加扩展结点后的树,称为扩展二叉树,然后使用前序遍历法把这些结点存储进一个线性表中,并使用一个指针指向已处理过的结点:

然后使用递归的方式创建树:top一个个往下探,不是“#”则递归往下设置。
/**
* 创建树
*
* @param definition 树定义
* @return 树上的节点
* @author Korbin
* @date 2023-01-19 12:01:50
**/
public BinaryTreeNode<T> create(BinaryTreeDefinition<T> definition) {
if (null == definition) {
return null;
}
int index = definition.getTop();
BinaryTreeNode<T>[] nodes = definition.getNodes();
int length = nodes.length;
if (index >= length) {
// 不存在结点
return null;
}
BinaryTreeNode<T> node = nodes[index];
if (index == 0) {
root = node;
}
int leftChildIndex = index + 1;
if (leftChildIndex < length) {
definition.setTop(index + 1);
if (!nodes[leftChildIndex].getData().equals("#")) {
// 有左孩子
BinaryTreeNode<T> leftChild = create(definition);
node.setLeftChild(leftChild);
}
}
index = definition.getTop();
if (index >= length) {
// 不存在结点
return null;
}
int rightChildIndex = index + 1;
if (rightChildIndex < length) {
definition.setTop(index + 1);
if (!nodes[rightChildIndex].getData().equals("#")) {
// 有右孩子
BinaryTreeNode<T> rightChild = create(definition);
node.setRightChild(rightChild);
}
}
return node;
}
7.5.2 获取二叉树的深度
使用递归的方式,一层一层往下迭代树,若有左结点或右结点,则深度加1:
/**
* 获得树的深度
*
* @return 树的深度
* @author Korbin
* @date 2023-01-18 18:10:21
**/
public int depth() {
if (null == root) {
return 0;
}
return depth(root) + 1;
}
/**
* 获得树的深度
*
* @param node 结点
* @return 树的深度
* @author Korbin
* @date 2023-01-18 18:10:21
**/
public int depth(BinaryTreeNode<T> node) {
if (null == node) {
return 0;
}
BinaryTreeNode<T> leftChild = node.getLeftChild();
BinaryTreeNode<T> rightChild = node.getRightChild();
int leftDepth = 0;
if (null != leftChild) {
leftDepth++;
leftDepth += depth(leftChild);
}
int rightDepth = 0;
if (null != rightChild) {
rightDepth++;
rightDepth += depth(rightChild);
}
return Math.max(leftDepth, rightDepth);
}
7.5.3 在树中找到指定结点
使用递归的方式,一层一层往下探查,直到找到结点:
/**
* 在树中找到指定结点
*
* @param node 指定结点
* @param treeRoot 根结点
* @return 找到的结点,找不到时返回null
* @author Korbin
* @date 2023-01-19 17:25:51
**/
public BinaryTreeNode<T> findNode(BinaryTreeNode<T> node, BinaryTreeNode<T> treeRoot) {
if (null == treeRoot) {
return null;
}
if (treeRoot.equals(node)) {
return treeRoot;
}
BinaryTreeNode<T> leftTree = treeRoot.getLeftChild();
if (null != leftTree) {
BinaryTreeNode<T> tmp = findNode(node, leftTree);
if (null != tmp) {
return tmp;
}
}
BinaryTreeNode<T> rightTree = treeRoot.getRightChild();
if (null != rightTree) {
return findNode(node, rightTree);
}
return null;
}
7.5.4 设置指定结点的值
先找到结点,再设置结点的值即可:
/**
* 设置树中节点的值为value
*
* @param node 待设置的结点
* @param value 待设置的值
* @author Korbin
* @date 2023-01-18 18:15:14
**/
public void assign(BinaryTreeNode<T> node, T value) {
BinaryTreeNode<T> treeNode = findNode(node, root);
if (null != treeNode) {
treeNode.setData(value);
}
}
7.5.5 获得结点的双亲
与在树中查找指定结点类似,递归往下查找,若查找到该结点,则返回该结点的父结点:
/**
* 获得树中结点的双亲,若为根节点则返回null
*
* @param node 指定结点
* @return 指定结点的双亲
* @author Korbin
* @date 2023-01-18 18:15:36
**/
public BinaryTreeNode<T> parent(BinaryTreeNode<T> node) {
if (null == node || root.equals(node)) {
return null;
}
return parent(root, node);
}
/**
* 获得树中结点的双亲,若为根节点则返回null
*
* @param node 指定结点
* @param rootNode 根结点
* @return 指定结点的双亲
* @author Korbin
* @date 2023-01-18 18:15:36
**/
public BinaryTreeNode<T> parent(BinaryTreeNode<T> rootNode, BinaryTreeNode<T> node) {
if (null == node || rootNode.equals(node)) {
return null;
}
BinaryTreeNode<T> result = null;
BinaryTreeNode<T> leftChild = rootNode.getLeftChild();
if (null != leftChild) {
if (leftChild.equals(node)) {
return rootNode;
} else {
result = parent(leftChild, node);
}
}
if (null == result) {
BinaryTreeNode<T> rightChild = rootNode.getRightChild();
if (null != rightChild) {
if (rightChild.equals(node)) {
return rootNode;
} else {
result = parent(rightChild, node);
}
}
}
return result;
}
7.5.6 获得结点的右兄弟
先获得双亲结点,然后获得右孩子:
/**
* 获得树中结点的右兄弟,若无右兄弟则返回空
*
* @param node 指定结点
* @return 指定结点的右兄弟
* @author Korbin
* @date 2023-01-18 18:15:54
**/
public BinaryTreeNode<T> rightSibling(BinaryTreeNode<T> node) {
if (null == node) {
return null;
}
BinaryTreeNode<T> parent = parent(node);
if (null == parent) {
return null;
}
BinaryTreeNode<T> rightChild = parent.getRightChild();
if (node.equals(rightChild)) {
return null;
} else {
return rightChild;
}
}
7.5.7 为结点添加子结点
先找到结点,再设置即可:
/**
* 在树中结点上,添加一个非空树为其左子树或右子树
*
* @param node 指定结点
* @param left 是否左子树,true为左子树,false为右子树
* @param childTree 待添加的树
* @author Korbin
* @date 2023-01-18 18:16:13
**/
public void insert(BinaryTreeNode<T> node, boolean left, BinaryTreeNode<T> childTree) {
BinaryTreeNode<T> treeNode = findNode(node, root);
if (null != treeNode) {
if (left) {
treeNode.setLeftChild(childTree);
} else {
treeNode.setRightChild(childTree);
}
}
}
7.5.8 删除结点的子结点
找到结点,再设置子结点即可:
/**
* 删除树中结点的左子树或右子树
*
* @param node 指定结点
* @param left 是否左子树,true为左子树,false为右子树
* @author Korbin
* @date 2023-01-18 18:16:37
**/
public void delete(BinaryTreeNode<T> node, boolean left) {
if (null == node || null == root) {
return;
}
BinaryTreeNode<T> treeNode = findNode(node, root);
if (null != treeNode) {
if (left) {
treeNode.setLeftChild(null);
} else {
treeNode.setRightChild(null);
}
}
}
7.5.9 前序遍历
若二叉树为空,则返回空,否则先访问根结点,再访问左孩子,再访问右孩子,遵循根结点->左孩子->右孩子逻辑,即从左到右根在前:
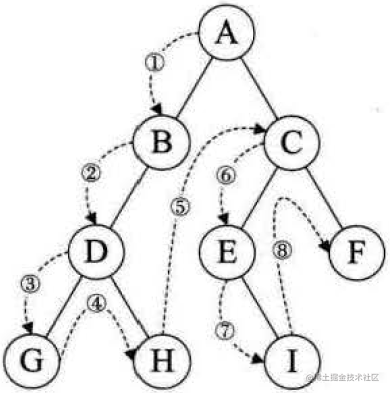
/**
* 前序遍历
*
* @return 遍历结果
* @author Korbin
* @date 2023-01-18 18:21:11
**/
public List<BinaryTreeNode<T>> preOrderTraverse() {
if (null == root) {
return null;
}
return preOrderTraverse(root);
}
/**
* 前缀遍历查找结点
*
* @param rootNode 根结点
* @return 前缀遍历结果
* @author Korbin
* @date 2023-01-19 18:04:46
**/
public List<BinaryTreeNode<T>> preOrderTraverse(BinaryTreeNode<T> rootNode) {
if (null == rootNode) {
return null;
}
List<BinaryTreeNode<T>> list = new ArrayList<>();
list.add(rootNode);
BinaryTreeNode<T> leftChild = rootNode.getLeftChild();
if (null != leftChild) {
list.addAll(preOrderTraverse(leftChild));
}
BinaryTreeNode<T> rightChild = rootNode.getRightChild();
if (null != rightChild) {
list.addAll(preOrderTraverse(rightChild));
}
return list;
}
7.5.10 中序遍历
遍历过程为左孩子->根结点->右孩子,即从左到右根在中间:
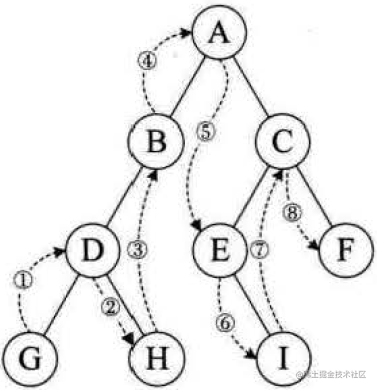
/**
* 中序遍历
*
* @return 遍历结果
* @author Korbin
* @date 2023-01-18 18:21:11
**/
public List<BinaryTreeNode<T>> inOrderTraverse() {
if (null == root) {
return null;
}
return inOrderTraverse(root);
}
/**
* 中序遍历
*
* @param rootNode 根结点
* @return 遍历结果
* @author Korbin
* @date 2023-01-18 18:21:11
**/
public List<BinaryTreeNode<T>> inOrderTraverse(BinaryTreeNode<T> rootNode) {
if (null == rootNode) {
return null;
}
List<BinaryTreeNode<T>> list = new ArrayList<>();
BinaryTreeNode<T> leftChild = rootNode.getLeftChild();
if (null != leftChild) {
list.addAll(inOrderTraverse(leftChild));
}
list.add(rootNode);
BinaryTreeNode<T> rightChild = rootNode.getRightChild();
if (null != rightChild) {
list.addAll(inOrderTraverse(rightChild));
}
return list;
}
7.5.11 后序遍历
顺序为左孩子->右孩子->根结点,即从左到右根在后:
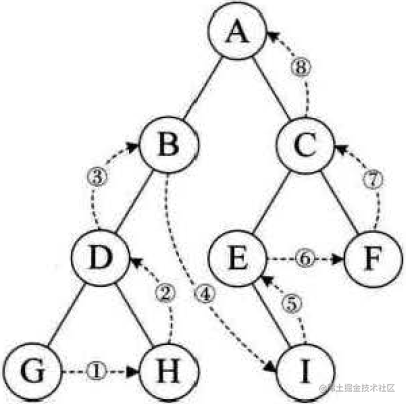
/**
* 后序遍历
*
* @return 遍历结果
* @author Korbin
* @date 2023-01-18 18:21:11
**/
public List<BinaryTreeNode<T>> postOrderTraverse() {
return postOrderTraverse(root);
}
/**
* 后序遍历
*
* @param rootNode 根结点
* @return 遍历结果
* @author Korbin
* @date 2023-01-20 09:19:10
**/
public List<BinaryTreeNode<T>> postOrderTraverse(BinaryTreeNode<T> rootNode) {
if (null == rootNode) {
return null;
}
List<BinaryTreeNode<T>> list = new ArrayList<>();
BinaryTreeNode<T> leftChild = rootNode.getLeftChild();
if (null != leftChild) {
list.addAll(postOrderTraverse(leftChild));
}
BinaryTreeNode<T> rightChild = rootNode.getRightChild();
if (null != rightChild) {
list.addAll(postOrderTraverse(rightChild));
}
list.add(rootNode);
return list;
}
7.5.12 层序遍历
从第一层开始,一层层往下,从左至右遍历:
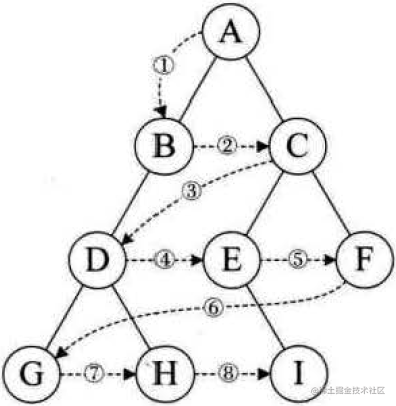
代码实现时,需要使用队列的概念:
(1) 把头结点进栈;
(2) 迭代队列,先将头结点出队,设为X,然后查看X是否有左孩子,有则入队;然后查看X是否有右孩子,有则入队;
(3) 然后继续迭代队列,依照(2)的逻辑持续迭代。
/**
* 层序遍历
*
* @return 遍历结果
* @author Korbin
* @date 2023-01-18 18:21:11
**/
public List<BinaryTreeNode<T>> levelOrderTraverse() {
if (null == root) {
return null;
}
List<BinaryTreeNode<T>> list = new ArrayList<>();
LinkQueue<BinaryTreeNode<T>> queue = new LinkQueue<>();
queue.init();
LinkListNode<BinaryTreeNode<T>> rootNode = new LinkListNode<>();
rootNode.setData(root);
queue.insert(rootNode);
while (!queue.isEmpty()) {
LinkListNode<BinaryTreeNode<T>> element = queue.delete();
BinaryTreeNode<T> node = element.getData();
list.add(node);
BinaryTreeNode<T> leftChild = node.getLeftChild();
if (null != leftChild) {
LinkListNode<BinaryTreeNode<T>> leftNode = new LinkListNode<>();
leftNode.setData(leftChild);
queue.insert(leftNode);
}
BinaryTreeNode<T> rightChild = node.getRightChild();
if (null != rightChild) {
LinkListNode<BinaryTreeNode<T>> rightNode = new LinkListNode<>();
rightNode.setData(rightChild);
queue.insert(rightNode);
}
}
return list;
}
7.5.13 完整代码
import java.util.ArrayList;
import java.util.List;
/**
* 二叉树
*
* @author Korbin
* @date 2023-01-18 17:49:04
**/
public class BinaryTree<T> {
/**
* 根结点
**/
private BinaryTreeNode<T> root;
/**
* 设置树中节点的值为value
*
* @param node 待设置的结点
* @param value 待设置的值
* @author Korbin
* @date 2023-01-18 18:15:14
**/
public void assign(BinaryTreeNode<T> node, T value) {
BinaryTreeNode<T> treeNode = findNode(node, root);
if (null != treeNode) {
treeNode.setData(value);
}
}
/**
* 创建树
*
* @param definition 树定义
* @return 树上的节点
* @author Korbin
* @date 2023-01-19 12:01:50
**/
public BinaryTreeNode<T> create(BinaryTreeDefinition<T> definition) {
if (null == definition) {
return null;
}
int index = definition.getTop();
BinaryTreeNode<T>[] nodes = definition.getNodes();
int length = nodes.length;
if (index >= length) {
// 不存在结点
return null;
}
BinaryTreeNode<T> node = nodes[index];
if (index == 0) {
root = node;
}
int leftChildIndex = index + 1;
if (leftChildIndex < length) {
definition.setTop(index + 1);
if (!nodes[leftChildIndex].getData().equals("#")) {
// 有左孩子
BinaryTreeNode<T> leftChild = create(definition);
node.setLeftChild(leftChild);
}
}
index = definition.getTop();
if (index >= length) {
// 不存在结点
return null;
}
int rightChildIndex = index + 1;
if (rightChildIndex < length) {
definition.setTop(index + 1);
if (!nodes[rightChildIndex].getData().equals("#")) {
// 有右孩子
BinaryTreeNode<T> rightChild = create(definition);
node.setRightChild(rightChild);
}
}
return node;
}
/**
* 删除树中结点的左子树或右子树
*
* @param node 指定结点
* @param left 是否左子树,true为左子树,false为右子树
* @author Korbin
* @date 2023-01-18 18:16:37
**/
public void delete(BinaryTreeNode<T> node, boolean left) {
if (null == node || null == root) {
return;
}
BinaryTreeNode<T> treeNode = findNode(node, root);
if (null != treeNode) {
if (left) {
treeNode.setLeftChild(null);
} else {
treeNode.setRightChild(null);
}
}
}
/**
* 获得树的深度
*
* @return 树的深度
* @author Korbin
* @date 2023-01-18 18:10:21
**/
public int depth() {
if (null == root) {
return 0;
}
return depth(root) + 1;
}
/**
* 获得树的深度
*
* @param node 结点
* @return 树的深度
* @author Korbin
* @date 2023-01-18 18:10:21
**/
public int depth(BinaryTreeNode<T> node) {
if (null == node) {
return 0;
}
BinaryTreeNode<T> leftChild = node.getLeftChild();
BinaryTreeNode<T> rightChild = node.getRightChild();
int leftDepth = 0;
if (null != leftChild) {
leftDepth++;
leftDepth += depth(leftChild);
}
int rightDepth = 0;
if (null != rightChild) {
rightDepth++;
rightDepth += depth(rightChild);
}
return Math.max(leftDepth, rightDepth);
}
/**
* 在树中找到指定结点
*
* @param node 指定结点
* @param treeRoot 根结点
* @return 找到的结点,找不到时返回null
* @author Korbin
* @date 2023-01-19 17:25:51
**/
public BinaryTreeNode<T> findNode(BinaryTreeNode<T> node, BinaryTreeNode<T> treeRoot) {
if (null == treeRoot) {
return null;
}
if (treeRoot.equals(node)) {
return treeRoot;
}
BinaryTreeNode<T> leftTree = treeRoot.getLeftChild();
if (null != leftTree) {
BinaryTreeNode<T> tmp = findNode(node, leftTree);
if (null != tmp) {
return tmp;
}
}
BinaryTreeNode<T> rightTree = treeRoot.getRightChild();
if (null != rightTree) {
return findNode(node, rightTree);
}
return null;
}
/**
* 中序遍历
*
* @return 遍历结果
* @author Korbin
* @date 2023-01-18 18:21:11
**/
public List<BinaryTreeNode<T>> inOrderTraverse() {
if (null == root) {
return null;
}
return inOrderTraverse(root);
}
/**
* 中序遍历
*
* @param rootNode 根结点
* @return 遍历结果
* @author Korbin
* @date 2023-01-18 18:21:11
**/
public List<BinaryTreeNode<T>> inOrderTraverse(BinaryTreeNode<T> rootNode) {
if (null == rootNode) {
return null;
}
List<BinaryTreeNode<T>> list = new ArrayList<>();
BinaryTreeNode<T> leftChild = rootNode.getLeftChild();
if (null != leftChild) {
list.addAll(inOrderTraverse(leftChild));
}
list.add(rootNode);
BinaryTreeNode<T> rightChild = rootNode.getRightChild();
if (null != rightChild) {
list.addAll(inOrderTraverse(rightChild));
}
return list;
}
/**
* 初始化
*
* @author Korbin
* @date 2023-01-19 11:08:29
**/
public void init() {
root = new BinaryTreeNode<>();
}
/**
* 在树中结点上,添加一个非空树为其左子树或右子树
*
* @param node 指定结点
* @param left 是否左子树,true为左子树,false为右子树
* @param childTree 待添加的树
* @author Korbin
* @date 2023-01-18 18:16:13
**/
public void insert(BinaryTreeNode<T> node, boolean left, BinaryTreeNode<T> childTree) {
BinaryTreeNode<T> treeNode = findNode(node, root);
if (null != treeNode) {
if (left) {
treeNode.setLeftChild(childTree);
} else {
treeNode.setRightChild(childTree);
}
}
}
/**
* 层序遍历
*
* @return 遍历结果
* @author Korbin
* @date 2023-01-18 18:21:11
**/
public List<BinaryTreeNode<T>> levelOrderTraverse() {
if (null == root) {
return null;
}
List<BinaryTreeNode<T>> list = new ArrayList<>();
LinkQueue<BinaryTreeNode<T>> queue = new LinkQueue<>();
queue.init();
LinkListNode<BinaryTreeNode<T>> rootNode = new LinkListNode<>();
rootNode.setData(root);
queue.insert(rootNode);
while (!queue.isEmpty()) {
LinkListNode<BinaryTreeNode<T>> element = queue.delete();
BinaryTreeNode<T> node = element.getData();
list.add(node);
BinaryTreeNode<T> leftChild = node.getLeftChild();
if (null != leftChild) {
LinkListNode<BinaryTreeNode<T>> leftNode = new LinkListNode<>();
leftNode.setData(leftChild);
queue.insert(leftNode);
}
BinaryTreeNode<T> rightChild = node.getRightChild();
if (null != rightChild) {
LinkListNode<BinaryTreeNode<T>> rightNode = new LinkListNode<>();
rightNode.setData(rightChild);
queue.insert(rightNode);
}
}
return list;
}
/**
* 获得树中结点的双亲,若为根节点则返回null
*
* @param node 指定结点
* @return 指定结点的双亲
* @author Korbin
* @date 2023-01-18 18:15:36
**/
public BinaryTreeNode<T> parent(BinaryTreeNode<T> node) {
if (null == node || root.equals(node)) {
return null;
}
return parent(root, node);
}
/**
* 获得树中结点的双亲,若为根节点则返回null
*
* @param node 指定结点
* @param rootNode 根结点
* @return 指定结点的双亲
* @author Korbin
* @date 2023-01-18 18:15:36
**/
public BinaryTreeNode<T> parent(BinaryTreeNode<T> rootNode, BinaryTreeNode<T> node) {
if (null == node || rootNode.equals(node)) {
return null;
}
BinaryTreeNode<T> result = null;
BinaryTreeNode<T> leftChild = rootNode.getLeftChild();
if (null != leftChild) {
if (leftChild.equals(node)) {
return rootNode;
} else {
result = parent(leftChild, node);
}
}
if (null == result) {
BinaryTreeNode<T> rightChild = rootNode.getRightChild();
if (null != rightChild) {
if (rightChild.equals(node)) {
return rootNode;
} else {
result = parent(rightChild, node);
}
}
}
return result;
}
/**
* 后序遍历
*
* @return 遍历结果
* @author Korbin
* @date 2023-01-18 18:21:11
**/
public List<BinaryTreeNode<T>> postOrderTraverse() {
return postOrderTraverse(root);
}
/**
* 后序遍历
*
* @param rootNode 根结点
* @return 遍历结果
* @author Korbin
* @date 2023-01-20 09:19:10
**/
public List<BinaryTreeNode<T>> postOrderTraverse(BinaryTreeNode<T> rootNode) {
if (null == rootNode) {
return null;
}
List<BinaryTreeNode<T>> list = new ArrayList<>();
BinaryTreeNode<T> leftChild = rootNode.getLeftChild();
if (null != leftChild) {
list.addAll(postOrderTraverse(leftChild));
}
BinaryTreeNode<T> rightChild = rootNode.getRightChild();
if (null != rightChild) {
list.addAll(postOrderTraverse(rightChild));
}
list.add(rootNode);
return list;
}
/**
* 前序遍历
*
* @return 遍历结果
* @author Korbin
* @date 2023-01-18 18:21:11
**/
public List<BinaryTreeNode<T>> preOrderTraverse() {
if (null == root) {
return null;
}
return preOrderTraverse(root);
}
/**
* 前缀遍历查找结点
*
* @param rootNode 根结点
* @return 前缀遍历结果
* @author Korbin
* @date 2023-01-19 18:04:46
**/
public List<BinaryTreeNode<T>> preOrderTraverse(BinaryTreeNode<T> rootNode) {
if (null == rootNode) {
return null;
}
List<BinaryTreeNode<T>> list = new ArrayList<>();
list.add(rootNode);
BinaryTreeNode<T> leftChild = rootNode.getLeftChild();
if (null != leftChild) {
list.addAll(preOrderTraverse(leftChild));
}
BinaryTreeNode<T> rightChild = rootNode.getRightChild();
if (null != rightChild) {
list.addAll(preOrderTraverse(rightChild));
}
return list;
}
/**
* 获得树中结点的右兄弟,若无右兄弟则返回空
*
* @param node 指定结点
* @return 指定结点的右兄弟
* @author Korbin
* @date 2023-01-18 18:15:54
**/
public BinaryTreeNode<T> rightSibling(BinaryTreeNode<T> node) {
if (null == node) {
return null;
}
BinaryTreeNode<T> parent = parent(node);
if (null == parent) {
return null;
}
BinaryTreeNode<T> rightChild = parent.getRightChild();
if (node.equals(rightChild)) {
return null;
} else {
return rightChild;
}
}
/**
* 根结点
*
* @return 返回根结点
**/
public BinaryTreeNode<T> root() {
return root;
}
@Override
public String toString() {
return value(root);
}
/**
* 获取结点的值,包括该结点的子树的值
*
* @param node 待获取值的结点
* @return 结点的值
* @author Korbin
* @date 2023-01-19 12:06:01
**/
public String value(BinaryTreeNode<T> node) {
if (null == node) {
return null;
}
StringBuilder builder = new StringBuilder();
builder.append(node.getData());
BinaryTreeNode<T> leftChild = node.getLeftChild();
BinaryTreeNode<T> rightChild = node.getRightChild();
if (null != leftChild) {
builder.append(value(leftChild));
}
if (null != rightChild) {
builder.append(value(rightChild));
}
return builder.toString();
}
}
7.6 线索二叉树
为树的结点添加两个指针,并对leftChild和rightChild做一些改变:
(1) 如果结点有左孩子,则leftChild指向左孩子,添加指针leftTag,设值为0;
(2) 如果结果没有左孩子,则leftChild指向前驱结点,设置leftTag为1;
(3) 如果结点有右孩子,则rightChild指向右孩子,添加指针rightTag,设值为0;
(4) 如果结点没有右孩子,则rightChild指向后继结点,设置rightTag为1;
这种指向前驱和后继的指针称为线索,加上线索的二叉链表称为线索链表,相应的二叉树称为线索二叉树,线索二叉树可以避免大量的leftChild和rightChild指向Null,浪费空间。
对于二叉树以某种次序遍历使其变为线索二叉树的过程称为线索化。
以下是前序遍历线索化的结果:
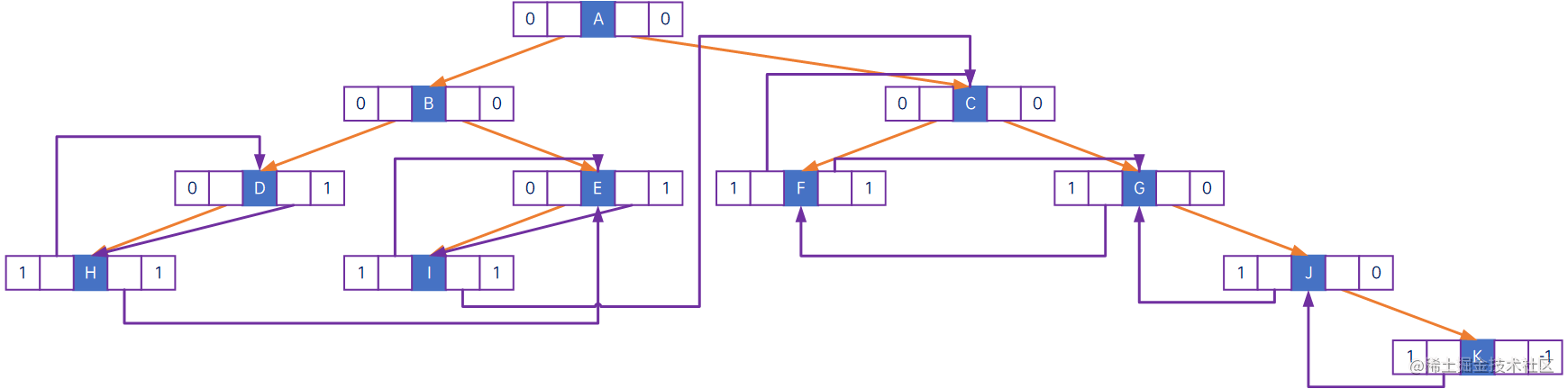
以下是中序遍历线索化的结果:
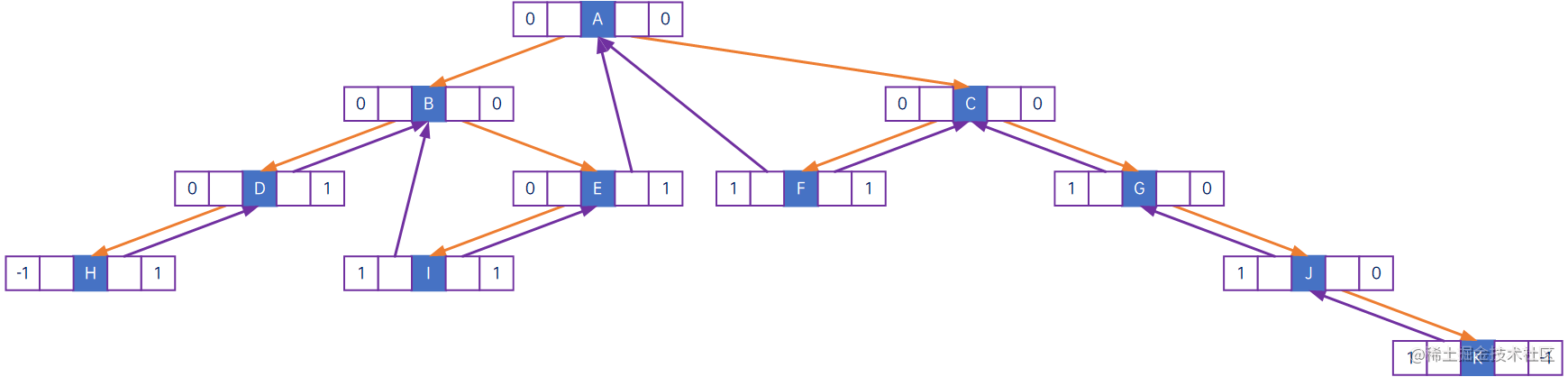
在代码实现过程中,按照线索化的逻辑,对于有左孩子和右孩子的结点,不需要做特殊处理,对于没有左孩子的结点,则要找到其前驱结点,对于没有右孩子的结点,则要找到其后继结点。
无论是什么遍历法,都是从前向后遍历,因此前驱结点很容易就能找到,但是后继结点不太好找,因为还没有遍历到,这时我们换个思路:线索化某结点时,不处理其rightChild,而是将其作为指针传到下一个结点,当遍历下一个结点时,再来处理本结点。
前序遍历线索化的代码实现如下:
/**
* 前缀线索化
*
* @author Korbin
* @date 2023-01-28 15:48:08
**/
public void preOrderThread() {
preOrderThread(root, null);
}
/**
* 前序遍历线索化
*
* @param node 结点
* @param preNode 前驱结点
* @return 前驱结点
* @author Korbin
* @date 2023-01-30 09:26:41
**/
public ThreadBinaryTreeNode<T> preOrderThread(ThreadBinaryTreeNode<T> node, ThreadBinaryTreeNode<T> preNode) {
if (null != node) {
// 设置前驱结点的后继为自己
if (null != preNode) {
ThreadBinaryTreeNode<T> preRightChild = (preNode.getRightTag() == 0) ? preNode.getRightChild() : null;
if (null == preRightChild) {
preNode.setRightChild(node);
preNode.setRightTag(1);
}
}
ThreadBinaryTreeNode<T> leftChild = (node.getLeftTag() == 0) ? node.getLeftChild() : null;
if (null == leftChild) {
// 先处理自己
// 没有左孩子时,前驱就是preNode
if (null != preNode) {
node.setLeftChild(preNode);
node.setLeftTag(1);
}
// 把自己设置为前驱结点,以便在无右孩子时的后继结点使用
preNode = node;
} else {
// 再处理左孩子
// 递归处理左孩子,左孩子的前驱就是自己
// 把自己设置为前驱结点
preNode = node;
preNode = preOrderThread(leftChild, preNode);
}
// 再处理右结点
ThreadBinaryTreeNode<T> rightChild = (node.getRightTag() == 0) ? node.getRightChild() : null;
if (null != rightChild) {
// 递归处理右孩子
preNode = preOrderThread(rightChild, preNode);
}
return preNode;
}
return null;
}
中序遍历线索化的代码实现如下:
/**
* 中序遍历线索化
*
* @author Korbin
* @date 2023-01-29 20:10:57
**/
public void inOrderThread() {
LinkList<ThreadBinaryTreeNode<T>> linkList = new LinkList<>();
linkList.init();
inOrderThread(root, null);
}
/**
* 中序遍历线索化
*
* @param node 结点
* @param preNode 前驱结点
* @return 前驱结点
* @author Korbin
* @date 2023-01-29 20:10:26
**/
public ThreadBinaryTreeNode<T> inOrderThread(ThreadBinaryTreeNode<T> node, ThreadBinaryTreeNode<T> preNode) {
if (null != node) {
// 先处理左孩子
ThreadBinaryTreeNode<T> leftChild = node.getLeftChild();
if (null != leftChild) {
// 有左孩子时
// 递归处理左孩子
// 左孩子的前驱仍为传入的preNode
preNode = inOrderThread(leftChild, preNode);
}
// 再处理自己
// 先设置本结点的前驱结点的后继结点为本结点
if (null != preNode) {
ThreadBinaryTreeNode<T> preRight = (preNode.getRightTag() == 0) ? preNode.getRightChild() : null;
if (null == preRight) {
preNode.setRightChild(node);
preNode.setRightTag(1);
}
}
// 自己的前驱即为左孩子处理的结果
if (null != preNode) {
if (null == leftChild) {
node.setLeftChild(preNode);
node.setLeftTag(1);
}
}
// 然后把自己变为前驱
preNode = node;
// 再处理右孩子
ThreadBinaryTreeNode<T> rightChild = node.getRightChild();
if (null != rightChild) {
// 有右孩子时
// 递归处理右孩子
preNode = inOrderThread(rightChild, preNode);
}
return preNode;
}
return null;
}
线索二叉树由于存储了结点的前驱和后继,因此在需要经常遍历或查找结点时,需要某种遍历序列中的前驱和后继时,线索二叉树的效率会更高。
7.7 树、森林与二叉树的转换
前文中讲述了树的定义和存储,对于树来说,在满足树的条件下可以是任意形状,一个结点可以有任意多个孩子,处理起来相对复杂,而二叉树的处理则相对简单,因此才有了将树转化成二叉树的研究。
7.7.1 树转换为二叉树
将树转换为二叉树的步骤如下:
(1) 加线,在所有兄弟结点之间加一条线;
(2) 去线,对树中每个结点,只保留它与第一个孩子结点的连线,删除它与其他孩子结点之间的连线;
(3) 层次调整,以树的根结点为轴心,将整棵树顺时针旋转一定角度,使之结构层次分明,注意第一个孩子是二叉树结点的左孩子,兄弟转过来的孩子是结点的右孩子;
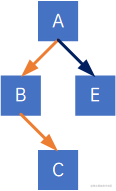
例如如下树:
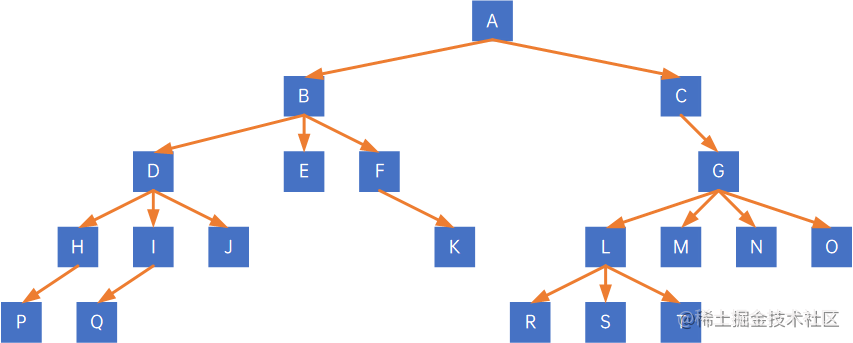
第一步,加线,在所有兄弟结点之间加一条线,注意,同一个双亲之间的结点才需要加连线:
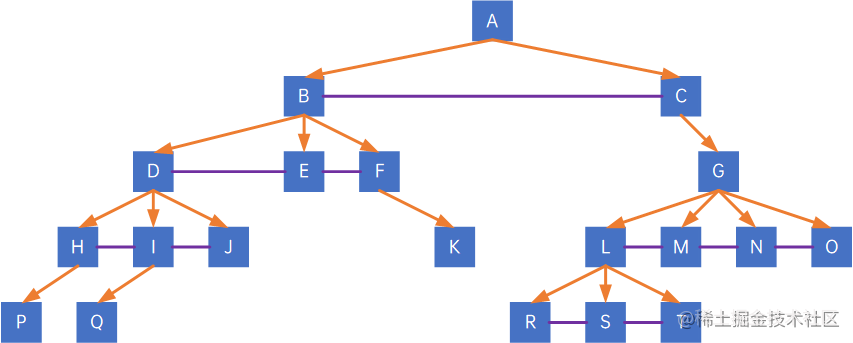
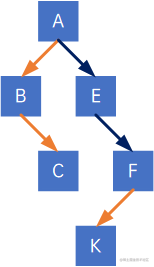
第二步,去线,去除除长子外其他孩子的连线:
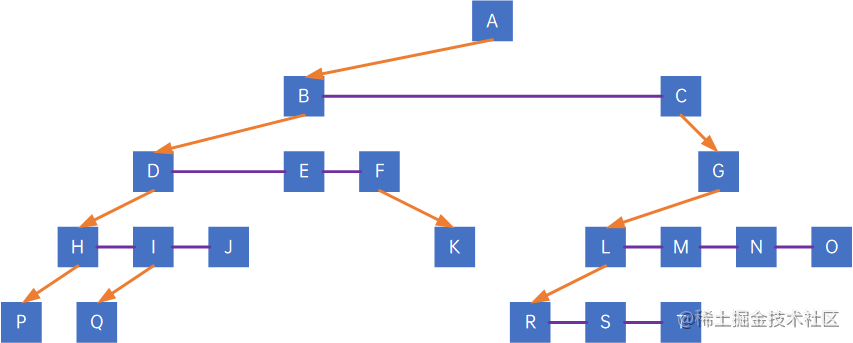
第三步,层次调整,再旋转,注意,第一个孩子是二叉树的左孩子(无论在原树中是什么孩子),兄弟转过来的孩子是结点的右孩子,如果把上图进行拉扯,那规则是——橙色一定是左孩子,紫色一定是右孩子:
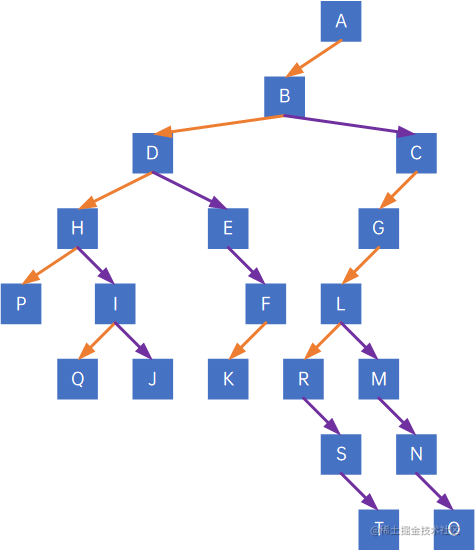
7.7.2 森林转换为二叉树
森林是由若干棵树组成的,所以完全可以理解为,森林中的每一棵树都是兄弟,可以按照兄弟的处理办法来操作,步骤如下:
(1) 把每棵树转换为二叉树;
(2) 第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树作的根结点作为前一棵二叉树的根结点的右孩子,用线连起来,得到最终二叉树;
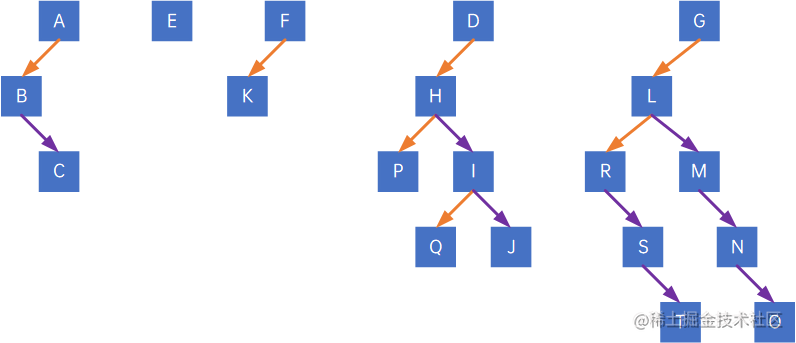
假设有以下几棵树:

第一步,把所有树转化为二叉树:
第二步,保持第一棵二叉树不动,把第二棵二叉树的根结点作为第一棵二叉树根结点的右孩子:
然后把第三棵二叉树作为第二棵二叉树根结点的右孩子:
依次处理,得到最终结果:
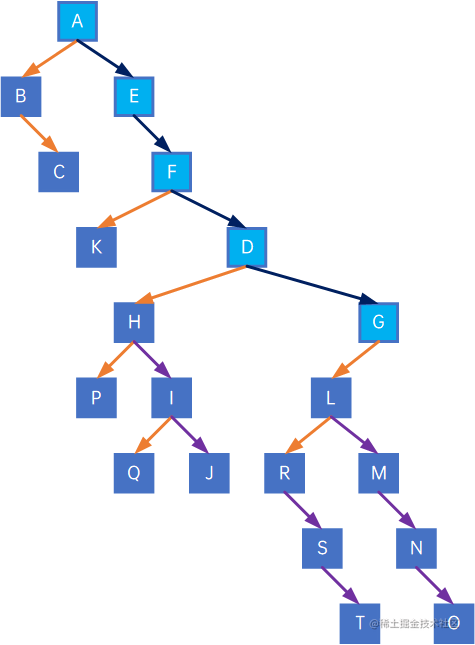
7.7.3 二叉树转换为树
按如下步骤操作:
(1) 加线,若某个结点的左孩子结点存在,则将这个结点与这个结点的左孩子的的右孩子结点、右孩子的右孩子结点、右孩子的右孩子的右孩子结点…全部用线连起来;
(2) 删除原二叉树中所有结点与其右孩子结点的连线;
(3) 调整层次;
假设有以下二叉树:
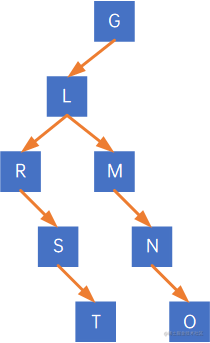
从根结点开始,先看G,发现其有左孩子L,因此把G与L的右孩子M、M的右孩子N、N的右孩子O连在一起:
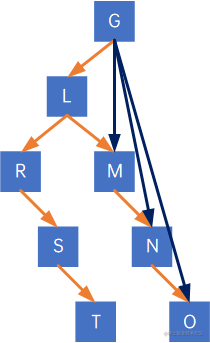
再来看L,其有左孩子R,因此把L与R的右孩子S、S的右孩子T边在一起:
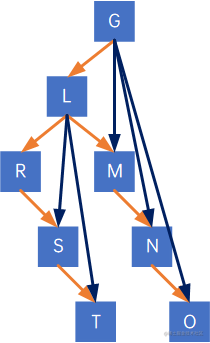
再看R,没有左孩子,跳过,M、S、N、T、O都没有左孩子,全部跳过。
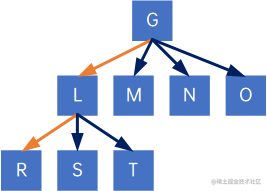
删除所有结点与其右孩子结点的连线:
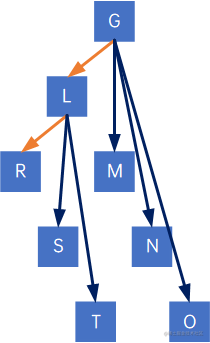
拉直,得到一棵二叉树:
7.7.4 二叉树转换为森林
按如下步骤操作:
(1) 查看二叉树的根结点,若有右孩子存在,则把与右孩子结点的连线删除,得到两棵分离的二叉树;再看第二棵二叉树的根结点,若有右孩子,则把右孩子连线删除,得到三棵二叉树;再看第三棵二叉树的根结点,若有右孩子,则把右孩子连线删除,得到四棵二叉树…依此类推,得到多棵分离的二叉树;
(2) 将每棵分离后的二叉树转换为树;
例如有以下二叉树:
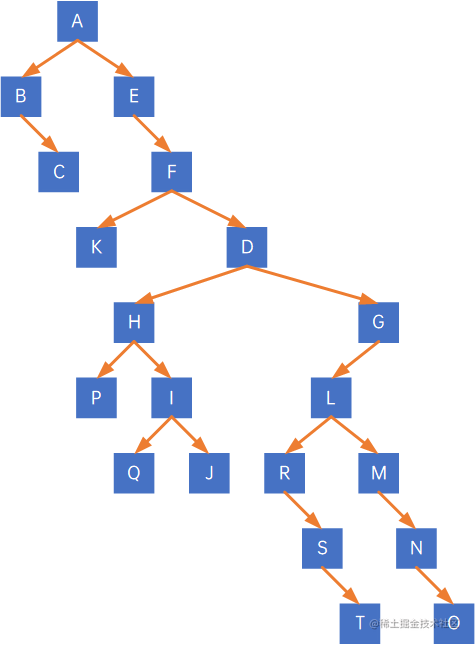
先看根结点A,其有右孩子,因此把与右孩子的连线删除,得到两棵二叉树:
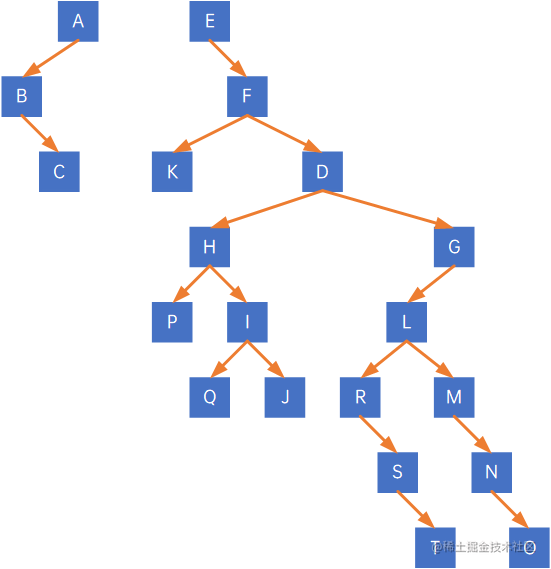
再看第二棵二叉树的根结点E,其有右孩子,因此把与右孩子的连线删除,得到三棵二叉树:
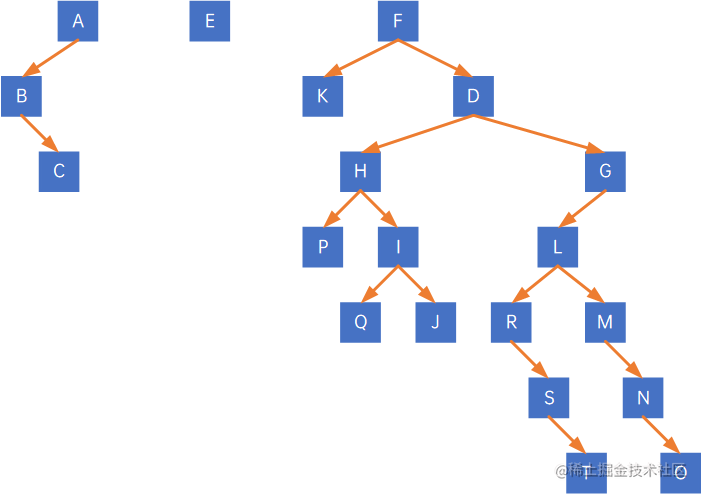
依此类推,得到最终分离的二叉树:
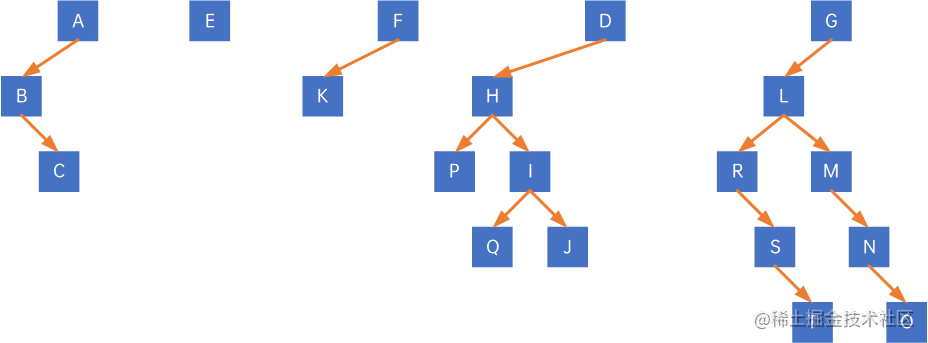
接着,按照7.7.3的方法,把所有二叉树转换为树,得到一片森林:
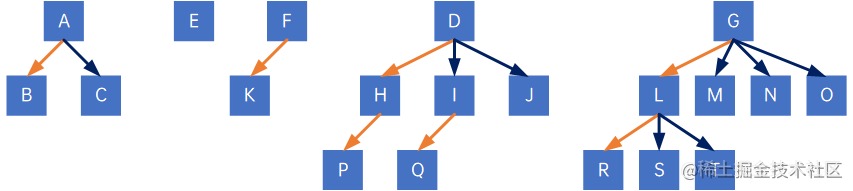
7.7.5 树的遍历
树的遍历有两种方式,一种是先根遍历,一种是后根遍历,实际上与二叉树的前序遍历(根->左->右,若只有一个孩子时默认为左孩子)和后序遍历(左->右->根,若只有一个孩子时默认为左孩子)类似。
如以下树:
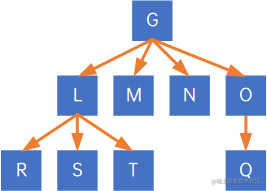
先根遍历(前序遍历)结果为GLRSTMNOQ,后根遍历(后序遍历)结果为RSTLMNQOG。
我们把这棵树转化为二叉树,如下:
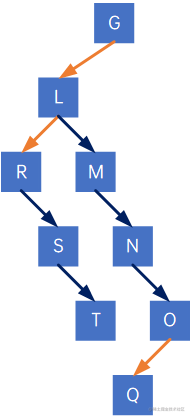
对它进行前序遍历,结果为GLRSTMNOQ,与树的先根遍历结果相同;对它进行中序遍历,结果为RSTLMNQOG,与树的后根遍历结果相同。
因此结论是:
(1) 树的先根遍历,即对树做前序遍历,只有一个孩子的结点默认该孩子为左孩子;
(2) 树的后根遍历,即对树做后序遍历,只有一个孩子的结点默认该孩子为左孩子;
(3) 树的先根遍历,与其转化为二叉树后的前序遍历结果相同;树的后根遍历,与其转化为二叉树后的中序遍历结果相同;
7.7.6 森林的遍历
森林的遍历也分为两种方式:
(1) 前序遍历,从第一棵树开始,使用先根遍历,再串起来,实际上与二叉树的前序遍历相同(根->左->右,若只有一个孩子时默认为左孩子);
(2) 后序遍历,从第一棵树开始,使用后根遍历,再串起来;
如以下森林:
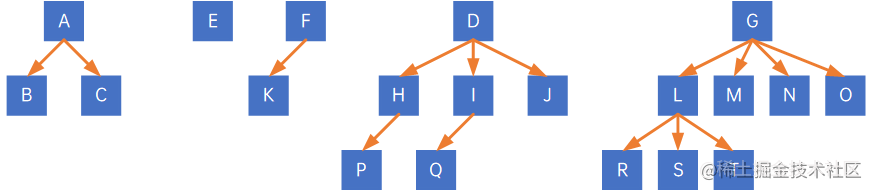
前序遍历结果为ABCEFKDHPIQJGLRSTMNO,后序遍历结果为BCAEKFPHQIJDRSTLMNOG。
把此树转化为一棵二叉树,如下:
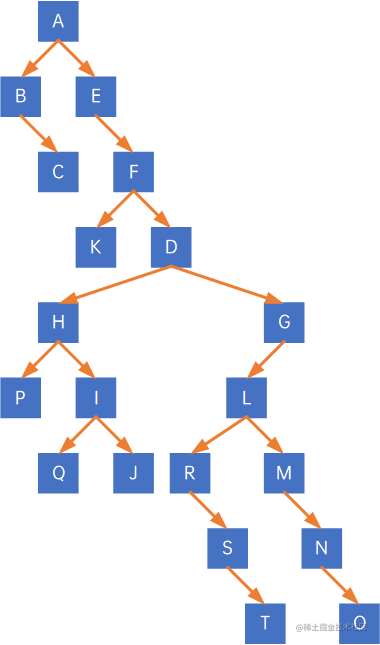
对其进行前序遍历,结果为ABCEFKDHPIQJGLRSTMNO,与森林的前序遍历结果相同;对其进行中序遍历,结果为BCAEKFPHQIJDRSTLMNOG,与森林的后序遍历结果相同。
因此有结论:
(1) 森林的前序遍历,是从第一棵树开始,使用先根遍历(根->左->右)方法遍历后,再串起来;
(2) 森林的后序遍历,是从第一棵树开始,使用后根遍历(左->右->根)方法遍历后,再串起来;
(3) 森林的前序遍历,与其转化为二叉树后的前序遍历结果相同;
(4) 森林的后序遍历,与其转化为二叉树后的中序遍历结果相同;
7.7 赫夫曼树
赫夫曼编码,是最基本的压缩编码方法。赫夫曼编码基于赫夫曼树,赫夫曼树是由赫夫曼(David Huffman,或称哈夫曼)于1952年发明赫夫曼编码时使用的特殊的树。
7.7.1 路径长度和带权路径长度
从根结点到某结点之间的线的数量称为路径长度,所有结点的路径长度之和为树的路径长度。
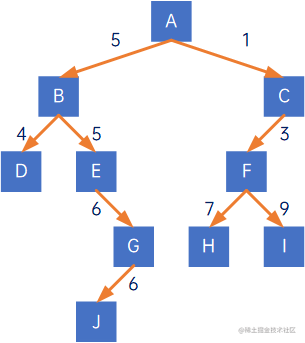
如下二叉树:
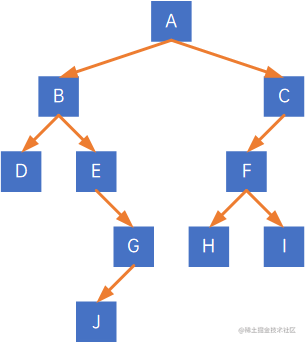
以J结点为例,A结点作为根结点,要走到J结点,需要走四条线,因此J结点的路径长度为4:
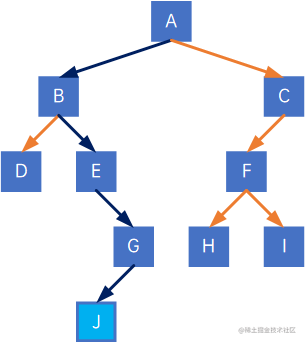
各结点的路径长度为:
(1) A结点为根结点,其路径长度为0;
(2) A结点要到B结点,只有需要走一条线,因此B结点的路径长度为1;
(3) A结点要到C结点,只有需要走一条线,因此C结点的路径长度为1;
(4) A结点要到D结点,要走两条线,因此D结点的路径长度为2;
(5) A结点要到E结点,要走两条线,因此E结点的路径长度为2;
(6) A结点要到F结点,要走两条线,因此F结点的路径长度为2;
(7) A结点要到G结点,要走三条线,因此G结点的路径长度为3;
(8) A结点要到H结点,要走三条线,因此H结点的路径长度为3;
(9) A结点要到I结点,要走三条线,因此I结点的路径长度为3;
(10) A结点要到J结点,要走四条线,因此J结点的路径长度为4;
因此,此二叉树的路径长度为1+1+2+2+2+3+3+3+4=21。
若二叉树的每一个结点都有一个权值,这棵二叉树称为带权二叉树,如下所示:
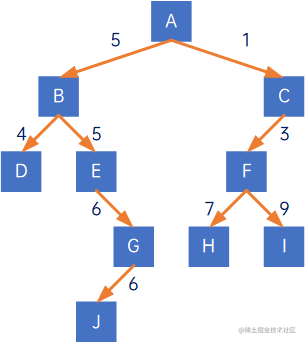
带权二叉树的结点的路径长度称为带权路径长度,带权路径长度为路径长度乘以权值,如上图中,结点J的路径长度为4,权值为6,因此结点J的带权路径长度为4*6=24。
相应的,二叉树的带权路径长度为所有结点的带权路径长度之和,因此此二叉树的带权路径长度为:
15+11+24+25+23+36+37+39+4*6=120。
带权路径长度也称为WPL。
7.7.2 定义
假设有n个权值{w1、w2、w3…wn},构造一棵有n个结点的二叉树,每个叶子结点带权wk,每个叶子的路径长度为lk,则构建出的WPL,即带权路径长度最小的二叉树,称为赫夫曼树,也称最优二叉树。
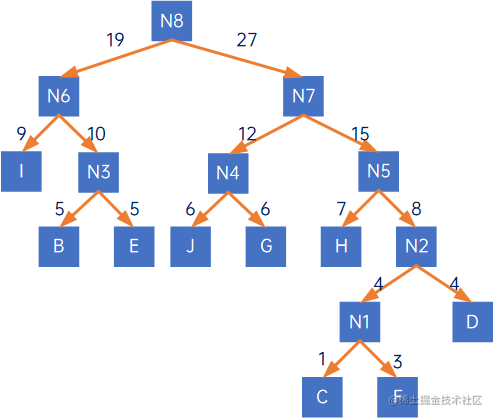
构造赫夫曼二叉树的步骤,以以上树为例,为:
(1) 把所有带权结点及其权值放到一个集合中,即FX={B-5, C-1, D-4, E-5, F-3, G-6, H-7, I-9, J-6};
(2) 先建一个只有根结点N1的树,然后令FX中,权值最小的结点为N1的左结点,权值第二小的结点为N1的右结点,如下所示:
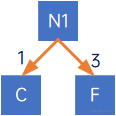
(3) 使结点N1的权值为其左右结点权值之和,即1+3=4,把FX中的C和F,取出,并放入N1,此时FX={N1-4, B-5, D-4, E-5, G-6, H-7, I-9, J-6};
(4) 再建一个只有根结点N2的树,然后令FX中,权值最小的结点为N2的左结点,权值第二小的结点为N2的右结点,如下所示:
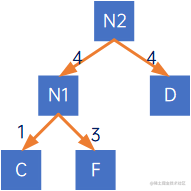
(5) 调整FX,令N2的权值为其左右结点权值之和,并替换原FX中的N1和D,得到新的FX={N2-8, B-5, E-5, G-6, H-7, I-9, J-6};
(6) 重复以上步骤,直到FX中没有结点,得到以下二叉树:
(7) 把临时加的结点,即N1、N2…的权值去掉,得到赫夫曼树:
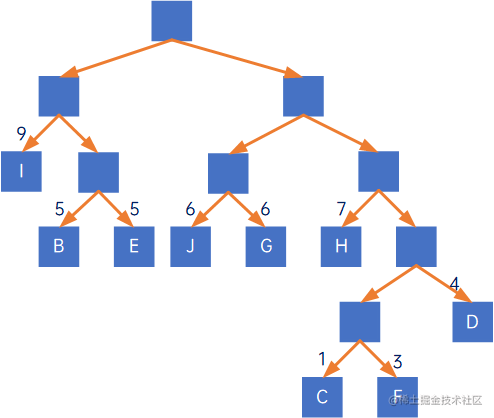
此时,树的带权路径长度为151。
这里出现问题:为什么比上文用到的二叉树:
的带权路径长度长呢?难道构造出来的不是赫夫曼树?
原因是因为,赫夫曼树的主要应用场景,是“不同判断逻辑使用不同处理方式”,也即,上图只是用来说明什么是路径长度,什么是带权路径长度,如果要适用“不同判断逻辑使用不同处理方式”,上图应变更成:
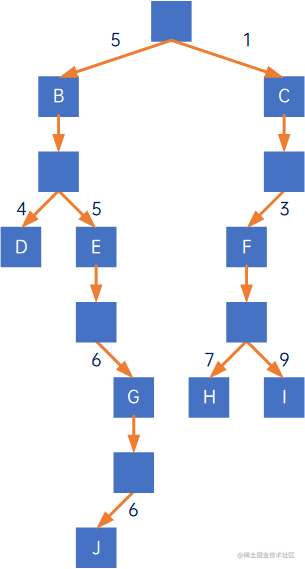
其带权路径长度是194。
7.7.3 赫夫曼编码
赫夫曼研究这种最优树的目的是为了解决当年远距离通信(主要是电报)的数据传输的最优化问题。
比如我们有一段文字内容为“BADCADFEED”要网络传输给别人,显然用二进制的数字(0和1)来表示是很自然的想法,这段文字有ABCDEF六个字母,转化为二进制是:
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 二进制 | 000 | 001 | 010 | 011 | 100 | 101 |
于是传输的数据变为“001000011010000011101100100011”,对方接收时,可以按每三位分一份来进行解析。
如果一篇文章很长的话,这样的二进制数据将会非常长,但实际上,无论是中文还是英文的文章,字母和汉字出现的频率是不同的,我们可以按照频率,进行赫夫曼树进行规划。
如字符串“BADCADFEED”,我们计算出每个字母出现的比例,再把比例乘以100,得到每个字母出现的权值:A-20、B-10、C-10、D-30、E-20、F-10,按照赫夫曼树构造方法,构造出如下赫夫曼树:
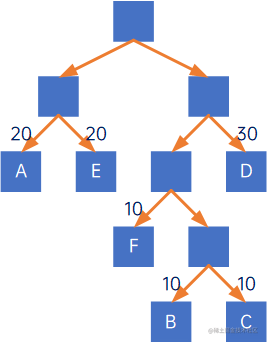
我们将赫夫曼树的权值左分支改为0,右分支改为1:
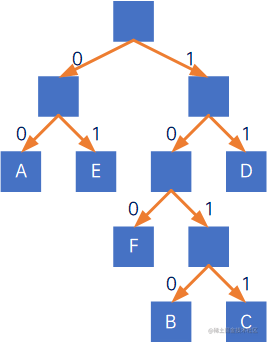
然后我们将这六个字母从树根到叶子所经过路径的0或1来编码,得到新的编码:
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 编码 | 00 | 1010 | 1011 | 11 | 01 | 100 |
那么,传输的数据就产生变化了,以下是赫夫曼优化后前后的数据编码:
| 二进制串 | 字符长度 | |
| 优化前 | 001000011010000011101100100011 | 30 |
| 优化后 | 1010001110110011100010111 | 25 |
也就是说,我们传输的数据被压缩了,节约了大约17%的存储或传输成本,随着字符的增加和多字符权重的不同,这种压缩会更加显出其优势。
将字符按出现频率作为权值构建赫夫曼树,然后设置赫夫曼树的左分支权值为0,右分支权值为1,从根结点到子结点所经过的路径分支组成0和1的序列为子结点的编码,这就是所谓的“赫夫曼编码”。
在生成赫夫曼编码时,应注意,任一字符的编码不能是另一个字符的编码的前缀,例如,若有字符的编码是1010,则其他字符的编码不能是1、10、101,当然也不可能会是1010。
7.7.4 赫夫曼编码数据的解码
在进行赫夫曼编码数据的解码时,直接比对编码表即可,例如以上数据“1010001110110011100010111”,其编码表是:
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 编码 | 00 | 1010 | 1011 | 11 | 01 | 100 |
从数据的第一个数值开始,取出来与编码表相比较,即如下过程:
(1) 取出1,无对应字符,继续;
(2) 取出10,无对应字符,继续;
(3) 取出101,无对应字符,继续;
(4) 取出1010,对应字符B,数据变更为“001110110011100010111”;
(5) 继续,取出0,无对应字符,取出00,对应字符A,数据变更为“1110110011100010111”;
(6) 继续,取出1,无对应字符,取出11,对应字符D,数据变更为“10110011100010111”;
(7) 继续,取出1,无对应字符,取出10,无对应字符,取出101,无对应字符,取出1011,对应字符C,数据变更为“0011100010111”;
(8) 继续,取出0,无对应字符,取出00,对应字符A,数据变更为“11100010111”;
(9) 取出1,无对应字符,取出11,对应字符D,数据变更为“100010111”;
(10) 取出1,无对应字符,取出10,无对应字符,取出100,对应字符F,数据变更为“010111”;
(11) 取出0,无对应字符,取出01,对应字符E,数据变更为“0111”;
(12) 取出0,无对应字符,取出01,对应字符E,数据变更为“11”;
(13) 取出1,无对应字符,取出11,对应字符D,数据已解码完成;
(14) 得到最终结果“BADCADFEED”;
注:本文为程 杰老师《大话数据结构》的读书笔记,其中一些示例和代码是笔者阅读后自行编制的。