前言
办公室里很多喜欢Hu歌的小姑娘,听说他结婚了,而且孩子都生了,都非常惊讶。
就是我也是今天才知道的,哈哈哈哈(交通闭塞了些)😂😂。
所有文章完整的素材+源码都在👇👇
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。

不过,现在的年轻姑娘们追星都很理性了,虽然爱豆结婚会有些意难平,但更多关注的还是一
个人的演技和人品,对于他是否结婚,是否生孩子,似乎没那么在意了。
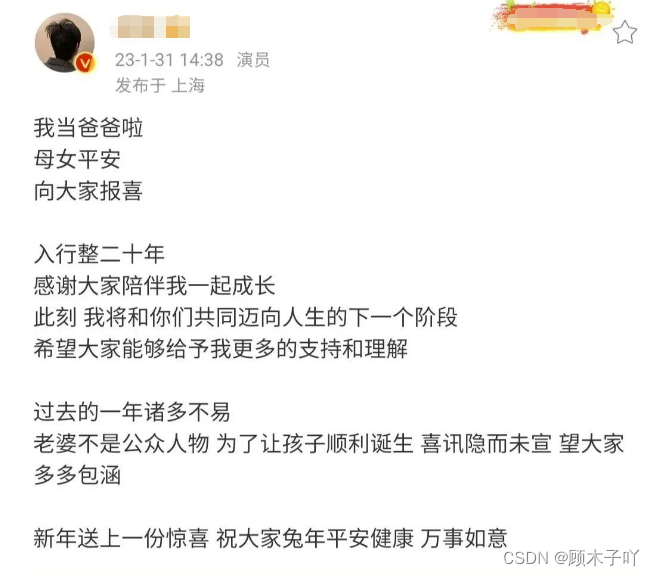
时间过去一个月了,新闻热度已经差不多消退了,让我们看看那些粉丝们的评lun吧。
今天教大家一键采集某星W博粉丝评lun区数据信息,看看大家的祝福吧!
Python爬虫实战-采集W博评lun, 并做数据可视化。 学会爬虫基本流程+W博动态数据抓包+所有的数据提取方式+词云图可视化 (完整的源码跟讲解视频可以滴滴我哈 大部分爬虫的内容是有详细的视频讲解内容的 )
正文
一、环境准备
1)运行环境
开发环境:
python 3.8: 解释器
pycharm: 代码编辑器
requests: 发送请求
parsel: 解析数据 jieba pandas stylecloud部分自带的模块安装Python即可使用。 相对应的安装包/安装教程/激活码/使用教程/学习资
料/工具插件 可以直接找我厚台获取 。
2)模块安装
第三方库的安装方式如下:
一般安装:pip install +模块名
镜像源安装:pip install -i https://pypi.douban.com/simple/+模块名
(还有很多国内镜像源,这里是豆瓣的用习惯了,其他镜像源可以去看下之前文章都有的)模块安装问题可以详细的找我给大家讲一下的哈,之前其实也有的文章写了几个点的。
二、思路讲解
1)爬虫原理:
模拟成 客户端(浏览器/手机) 向 服务器 发送网络请求 。
2)爬虫实现流程:
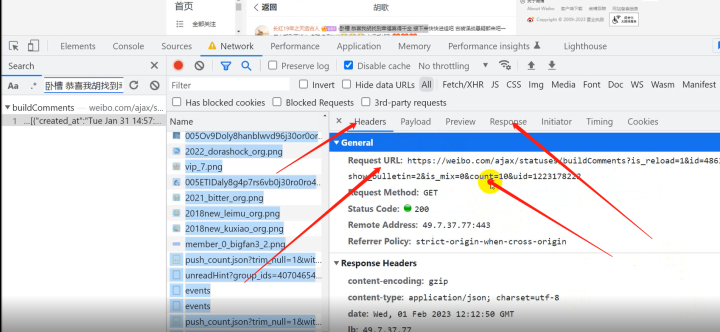
一. 思路分析 找到数据来源 https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4863981833423714&is_show_bulletin=2&is_mix=0&count=10&uid=1223178222 network 记录网页数据 请求 。
二. 实现代码 1. 发送请求 2. 获取数据 3. 解析数据 4. 保存数据。三、步骤流程
1)数据来源
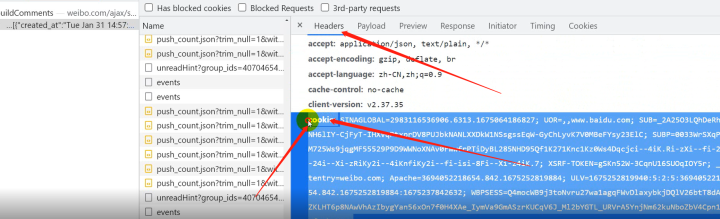
2)用户身份信息(cookie),防盗链(referer),(user-agent)浏览器基本信息都在Headers
下面。
四、代码展示
1)爬虫主程序
import requests # 需要额外安装
import csv
# 半成品 (最基本的架构)
# 分布式
f = open('评论.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.writer(f)
csv_writer.writerow(['id', 'text_raw', 'source', 'like_counts', 'screen_name', 'followers_count'])
# 请求头
headers = {
# 用户身份信息
'cookie': 'SINAGLOBAL=2983116536906.6313.1675064186827; UOR=,,www.baidu.com; SUB=_2A25O3LQhDeRhGeNH6lIY-CjFyT-IHXVqPtxprDV8PUJbkNANLXXDkW1NSsgssEqW-GyChLyvK7V0MBeFYsy23ElC; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWNoXNAv0FwwfrPTiDyBL285NHD95Qf1K271Knc1Kz0Ws4Dqcjci--4iK.Ri-zXi--fi-2Xi-24i--Xi-zRiKy2i--4iKnfiKy2i--fi-isi-8Fi--Xi-z4iK.7; XSRF-TOKEN=gSKn52W-3CqnU16SUOqIOY5r; _s_tentry=weibo.com; Apache=3694052218654.842.1675252819884; ULV=1675252819940:5:2:5:3694052218654.842.1675252819884:1675237842632; WBPSESS=Q4mocWB9j3toNvru27wa1agqFWvDlaxybkjDQlV26btT8dAjnZKLHT6p8NAwVhAzIbygYan56xOn7f0H4XAe_IymVa9GmASzrKUCqV6J_Ml2bYGTL_URVrA5YnjNm62kuNboZbV4Cpn1MZTfoLbEWg==',
# 防盗链
'referer': 'https://weibo.com/1223178222/MqQsvemFc',
# 浏览器基本信息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
next = 'count=10'
while True:
url = f'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4863981833423714&is_show_bulletin=2&is_mix=0&{next}&uid=1223178222'
# 1. 发送请求
response = requests.get(url=url, headers=headers)
# 2. 获取数据
# .text: 获取文本数据
# .json(): json字符串数据
# .content: 获取二进制数据
# 2.1 出现乱码
json_data = response.json()
# 3. 解析数据
# 结构化数据 : json数据{}包裹的格式 转成字典, 使用字典取值 re
# 非结构化数据: 网页源代码 lxml, bs4, parsel, re css/xpath/re
data_list = json_data['data']
max_id = json_data['max_id']
for data in data_list:
text_raw = data['text_raw']
try:
source = data['source']
except:
source = "未知"
id = data['id']
like_counts = data['like_counts']
screen_name = data['user']['screen_name']
followers_count = data['user']['follwers_count']
print(id, text_raw, source, like_counts, screen_name, followers_count)
# 4. 保存数据
csv_writer.writerow([id, text_raw, source, like_counts, screen_name, followers_count])
next = 'max_id='+str(max_id)2)效果展示
爬取信息效果——
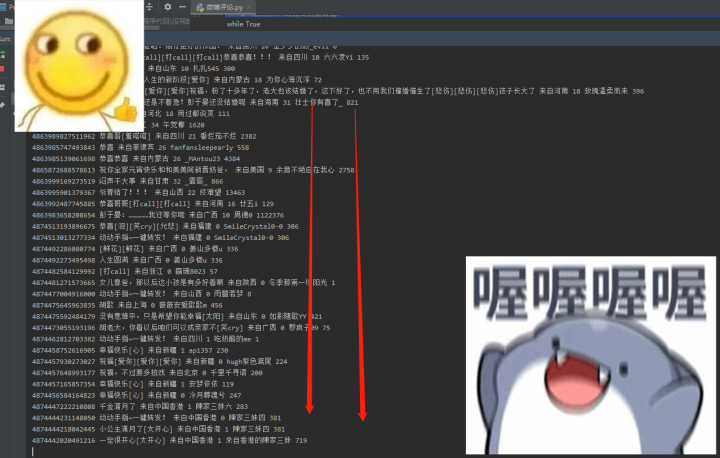
可视化效果——


总结
入行演艺圈二十年,经历了不少坎坷,也创造了许多经典角色。如今,女儿终于平安降
生,实在是人生一大幸事。想我最喜欢的《x剑系列》可是仙侠剧的YYDS啊~
好啦。今天的内容就写到这里结束了,我们下棋不见不散哦~
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
🔨推荐往期文章——
项目0.9 【Python实战】WIFI密码小工具,甩万能钥匙十条街,WIFI任意连哦~(附源码)
项目1.0 【Python实战】再分享一款商品秒杀小工具,我已经把压箱底的宝贝拿出来啦~
项目0.7 【Python爬虫实战】 不生产小说,只做网站的搬运工,太牛逼了~(附源码)
项目0.8 【Python抢票神器】火车票枪票软件到底靠谱吗?实测—终极攻略。
🎁文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)







![[Java·算法·中等]LeetCode215. 数组中的第K个最大元素](https://img-blog.csdnimg.cn/79935be653c64a66a673a381996da929.png)

