原创 齐天宇 隐私计算研习社
收录于合集#联邦学习54个

现有的FL方案使用随机的参与者选择来提高选择过程的公平性,但是这会导致资源的低效利用和较低的训练质量。
本文系统地解决了FL中资源效率低效的问题,展示了智能参与者选择和合并来自落后参与者的更新的好处。我们演示了这些因素如何在提高训练后的模型质量的同时提高资源效率。
论文标题:REFL: Resource-Efficient Federated Learning
论文链接:https://mcanini.github.io/papers/refl.eurosys23.pdf
1
Introduction
主要挑战是大量学习者在计算能力和数据分布方面的异质性,这可能会影响训练的效果。
精确度时间是一个重要的指标,它取决于培训的统计效率和系统效率。失败的回合和过度参与的参与者会导致计算的浪费,这在以往的FL方法中大多被忽视了。本文目标是优化FL系统的设计,使其在不同的环境下具有资源与精度之比。这意味着减少了达到目标精度所消耗的计算资源,而不会对精度时间产生重大影响。
本文提出REFL,这是一种在不牺牲统计和系统效率的情况下最大化FL系统资源效率的实用方案。REFL通过将参与者更新的集合从聚合分离到更新的模型中来实现这一点。REFL还智能地在可用的参与者中选择将来最不可能可用的参与者。
贡献:
强调学习者有限能力和可用性的资源利用在FL中的重要性,并提出REFL来智能地选择参与者并有效地利用他们的资源。
提出了陈旧感知聚合和智能参与者选择算法,以提高资源利用率,同时对准确性的时间影响最小。
使用真实世界的FL基准来实现和评估REFL,并将其与最先进的解决方案进行比较。
2
Background
在FL聚合中引入了截止时间。
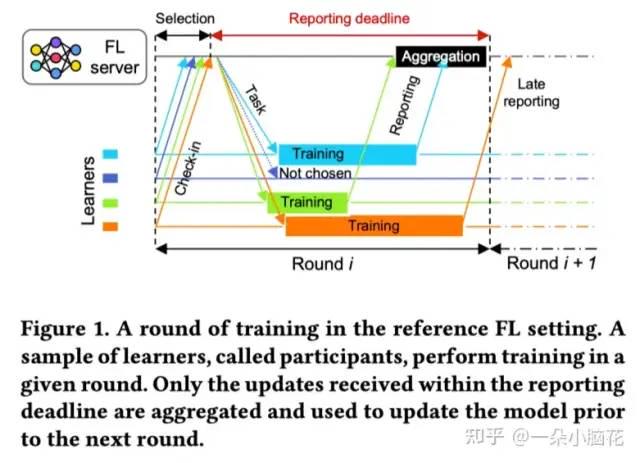
FL的异质性:
数据异质性:Noniid数据;
系统异质性:算力不同;
行为异质性:学员的可获得性因轮次而异;
当前常见的异步算法:
SAFA:落后者参与者的半异步更新;然而,SAFA只允许学习者在有限的陈旧阈值内进行更新;
FiLL支持陈旧度更新,但其协议与FedAvg不兼容;
Oort优先选择学习速度快的学习者来缩短轮次持续时间。
3
The case for REFL
System Efficiency vs. Resource Diversity
当前FL对的设计,要么旨在减少达到准确的时间(系统效率),要么增加学习者池的覆盖率以增强数据分布并公平地分散训练工作量(资源多样性)。但没有考虑学习者的训练成本。
第一个目标导致对某些类别的学习者采取歧视性的做法,要么优先选择计算速度快的学习者,要么优先选择模型更新质量高的学习者(即具有高统计效用的学习者)
第二个目标需要将计算理想地分散到所有可用的学习者上,但代价是可能需要更长的轮次持续时间。
本文的目标是在二者之间取得一种平衡。
Stale Updates & Resource Wastage
SAFA从异步方法中汲取灵感,允许掉队的参与者通过陈旧的更新为全球模型做出贡献。其对所有学员进行培训,并在预设比例的学员返回更新时结束一轮培训。SAFA允许参与者在该轮截止日期后报告,在这种情况下,更新将被缓存并在下一轮中应用。
SAFA+O代表着其预先知道哪些设备会被选择并聚合,可以一定程度减小开销。
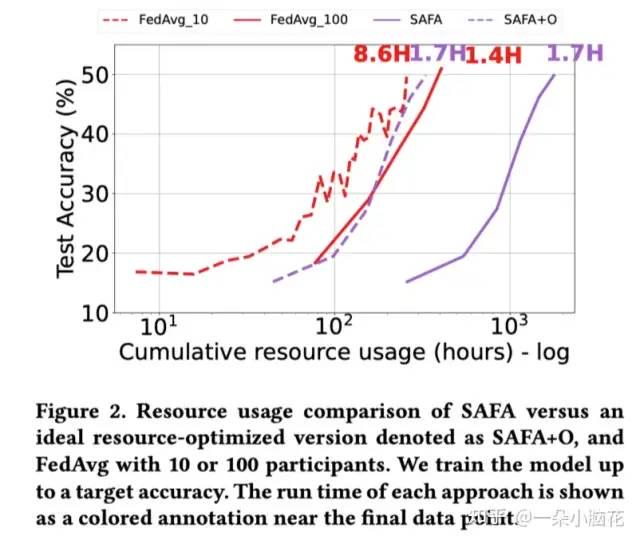
原则上,允许陈旧更新可以减少循环持续时间,获得更好的时间准确性,同时保留掉队者的贡献。然而,主要的挑战是平衡参与者的数量,以避免大量的资源浪费。
Participant Selection & Resource Diversity
Oort是通过改变设备选择策略,尽可能选择易于聚合的快速学习者提升准确率的设备,但减少了数据多样性。
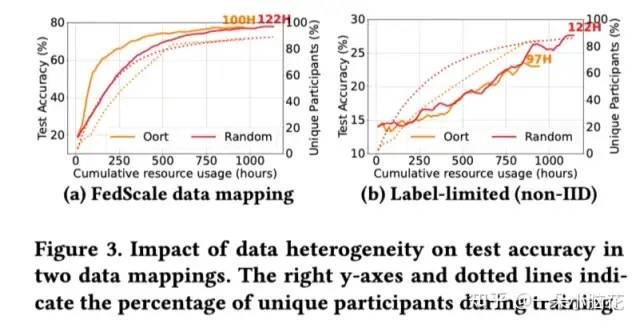
同时还要考虑参与者可用性。每个设备参与者可用的时间长短不一。低可用性学习者可能需要特殊考虑,以增加独特参与者的数量,而不会对总体培训时间产生不利影响。
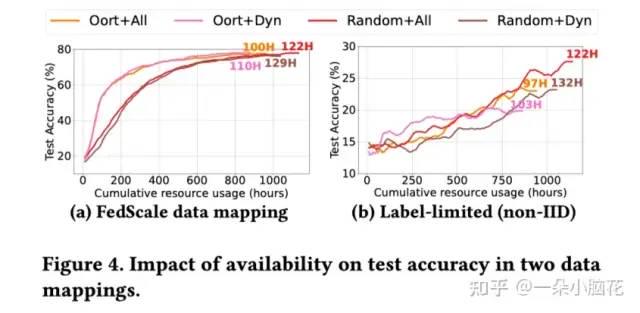
实验结果展示,动态且Noniid的情况下,准确率会下降10%左右。
综上,为了实现更好的模型泛化性能,应该在来自大部分学习者群体的数据样本上联合训练模型。(确保更广泛的学习者覆盖面)
4
REFL design
REFL通过减少延迟参与者的资源浪费和优先考虑可用性降低的参与者来实现这一点。它利用理论支持的方法,根据质量合并陈旧更新。
智能参与者选择(IPS):对提高资源多样性的参与者进行优先排序。
陈旧感知聚合(SAA):在不影响准确性的情况下提高资源效率。

Oort在培训的早期阶段将参与者的选择倾向于更快的学习者,从而错过了有限可用性的学习者,其回合时间是由掉队者决定的。通过允许过时更新。
REFL降低了对落后者的依赖。通过基于估计的可用性对学习者进行优先排序,REFL对更多样化的学习者集合进行采样。
Intelligent Participant Selection (IPS)
IPS增加了资源的多样性,使全球模型能够捕捉广泛分布的学习者数据。此外,它提供了一个可选组件,通过智能地调整每一轮的参与者数量来进一步减少资源浪费。

可用性预测模型:使用现成的时间序列模型来预测学习者的未来可用性。其中是轮次持续时间的平均估计。更新方法为,其中 是上一轮的持续时间。并且其会探测每个当前掉队者,计算其剩余时间 ,将 作为上一轮掉队者中能够完成能够完成训练的集合。所以参与者的数量被调整为
Staleness-Aware Aggregation(SAA)
收敛性分析
从理论上证明了带有陈旧更新的FedAvg算法能够收敛并获得收敛速度。考虑个设备的联合优化问题:
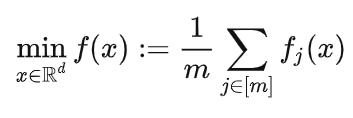
陈旧同步更新算法:

收敛性:

减轻陈旧度的影响(加权平均):

5
Evaluation
用FedSacle实现了FL的集成。
benchmark:
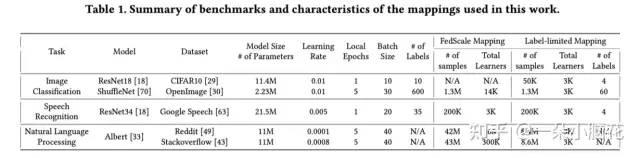
数据异构:1、均衡分布;2、均匀分布;3、Zipf分布

系统性能:从真实数据中测量进行随机分配。
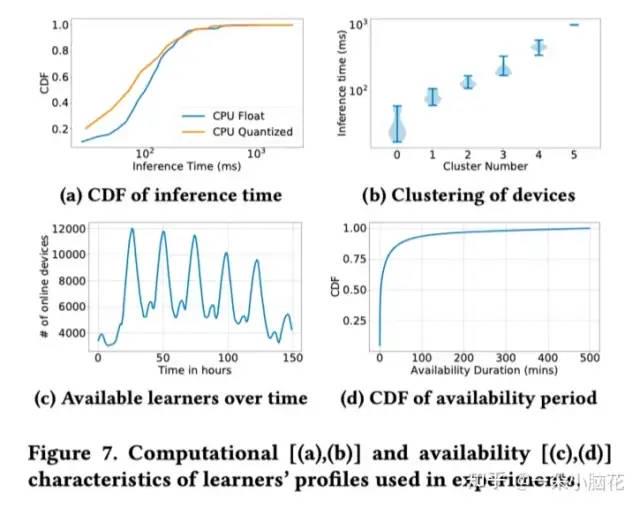
可用性模型:90%的准确率。
6
Result
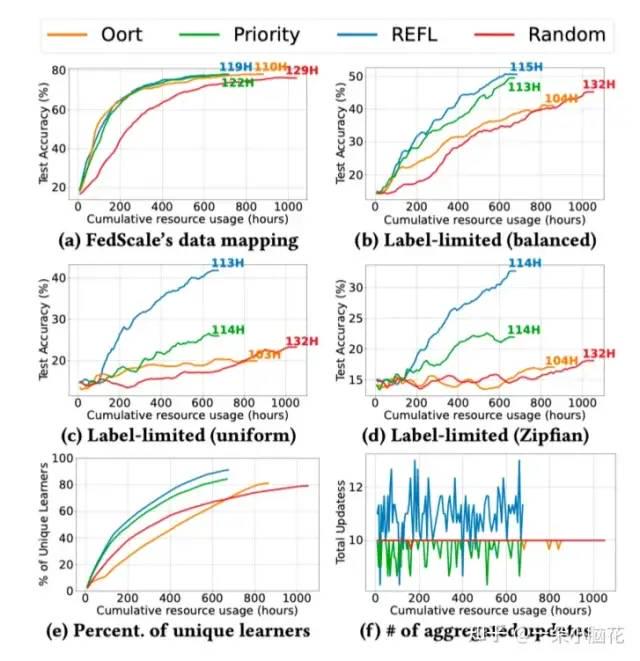
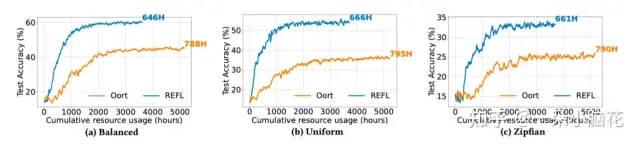
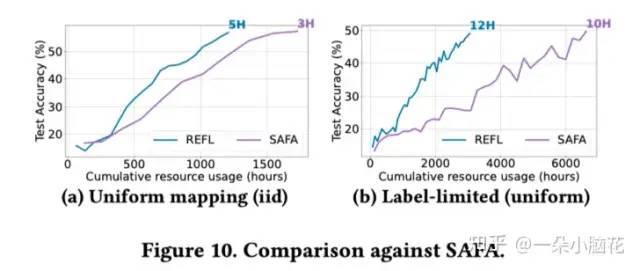
与SAFA相比,REFL耗时基本类似,但资源消耗较少。

加入动态评估时间可用参与者效果会更好。

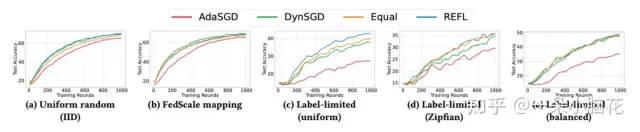
在全部可用的情况下,Oort在iid情况下效果很好,但在Noniid情况下不能选择足够丰富的数据。由于SAA组件的加入,REFL以较低的资源使用获得了良好的模型质量。
大训练参与者情况下的效果:
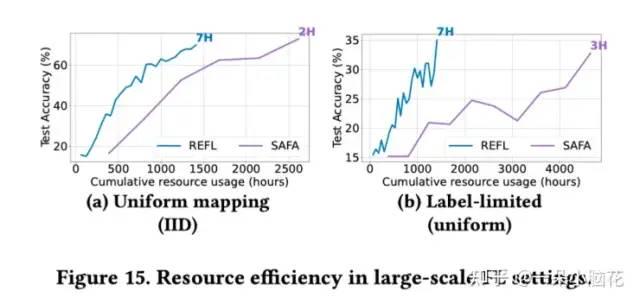
未来硬件进步的影响:

作者简介:齐天宇,北京理工大学自动化学院智能信息与控制研究所研究生。主要研究兴趣包括机器学习、联邦学习、隐私保护。知乎:一朵小脑花。
END

隐私计算研习社
开放隐私计算社区
97篇原创内容
公众号
往期推荐
密码学中常见加密算法的python模块整理
上岸!选择你的隐私计算导师!
联邦学习 (FL) 中常见的3种模型聚合方法的 Tensorflow 代码示例
对于多方安全计算,你是否也有这样的疑惑?

欢迎投稿
邮箱:pet@openmpc.com
参与更多讨论,请添加小编微信加入交流群

分享此内容的人还喜欢
上岸!选择你的隐私计算导师!
隐私计算研习社阅读 996不喜欢
不看的原因确定
内容质量低
不看此公众号

可信区块链隐私计算平台研究与实现
隐私计算研习社阅读 457不喜欢
不看的原因确定
内容质量低
不看此公众号

对于多方安全计算,你是否也有这样的疑惑?
隐私计算研习社阅读 502不喜欢
不看的原因确定
内容质量低
不看此公众号

写下你的留言











![[算法与数据结构]--贪心算法初识](https://img-blog.csdnimg.cn/e48f3734a3d746b3929b4333b7eaebe9.png)