吃不了自律的苦,又接受不了平庸的罪。想让自己变好,但又想舒服些。
你啊你……要么就不要去想,想了又不去做,犹犹豫豫,徘徊不前,患得患失…

文章目录
- 一、四种构造函数
- 1.vector的框架和无参构造
- 2.构造函数调用不明确(调用函数时的匹配优先度所造成的问题)
- 二、vector的拷贝构造和赋值重载
- 三、迭代器失效(异地扩容引起的野指针问题)
- 1.insert异地扩容导致的迭代器失效
- 2.vs和g++对于erase后迭代器是否失效的处理手段(一个极端,一个温和)
- 四、vector的更深层次的拷贝
- 1.memcpy逐字节拷贝造成的浅拷贝问题
- 2.其他方便使用的小接口
一、四种构造函数
1.vector的框架和无参构造
1.
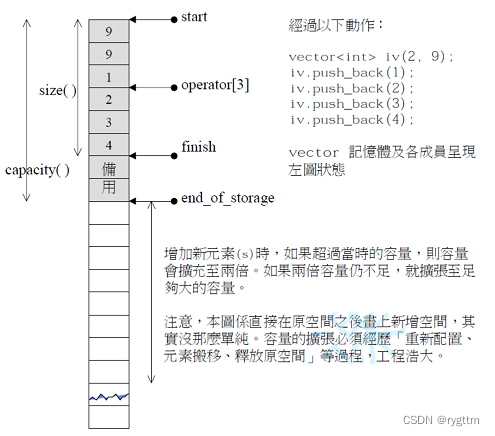
下面是vector的框架,其中成员变量分别为指向当前使用空间首部分的_start指针和最后一个元素的下一个位置的_finish指针,以及指向可用空间末尾的下一个位置的_end_of_storage指针,并且对于vector来说,由于它的底层是由顺序表实现的,所以它的迭代器就是原生态指针T*,我们定义了const和非const的迭代器,便于const和非const对象的迭代器的调用。
下面是SGI版本的stl_vector.h的源码实现,我们模拟实现的就是SGI版本的源码。

namespace wyn
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
……
……
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
}
2.
无参的构造函数,我们利用初始化列表来进行初始化。用nullptr初始化比较好,因为nullptr的free或delete都不会出错。
vector()
:_start(nullptr)
,_finish(nullptr)
,_end_of_storage(nullptr)
{}
2.构造函数调用不明确(调用函数时的匹配优先度所造成的问题)
1.
除无参构造外,常用的构造还有迭代器区间作为参数的构造函数。这里的迭代器需要用函数模板来实现,因为构造vector所用的迭代器不一定只是vector类型的,还有可能是string类型,所以这里的迭代器形参需用模板来实现。

template<class InputIterator>
vector(InputIterator first, InputIterator last)
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
while (first < last)
{
push_back(*first);
first++;
}
}
2.
另一种构造是用n个value值来进行构造,value既有可能是内置类型,也有可能是自定义类型,所以如果用引用作参数的话,需要用const引用,也就是常引用来作参数,否则无法接收内置类型的实参。

3.
在实现完n个value构造的构造函数之后,如果我们此时用10个int类型的数字1来构造对象v1,实际会报错,报错的原因其实是由于函数的匹配优先级所导致的实参无法正确匹配相应的构造函数。而使用10个char类型的字符A却不会报错,这其实也是由于函数的匹配优先级决定的。
4.
对于size_t和常引用作为参数的构造来说,它的匹配优先级对于10个1实际不是最高的,因为常引用需要进行类模板参数T类型的推导,而10又是整型int,int到size_t还需要进行隐式类型转换,代价有点大。
而对于迭代器区间作为参数的构造来讲,函数模板参数InputIterator只需要进行一次类型推导即可完成匹配,所以用10个1来构造时,实际匹配的构造函数是迭代器区间作为参数的构造函数,而在匹配的构造函数中,对迭代器区间进行了解引用,那就是对常量10进行了解引用,则发生非法的间接寻址。
5.
对于这种问题的解决,可以将size_t换成int类型,或者将10强转为size_t类型,但stl源码的解决方式并非是这样的,而是利用了函数重载来解决了这个问题,多重载了一个类型为int的构造函数。

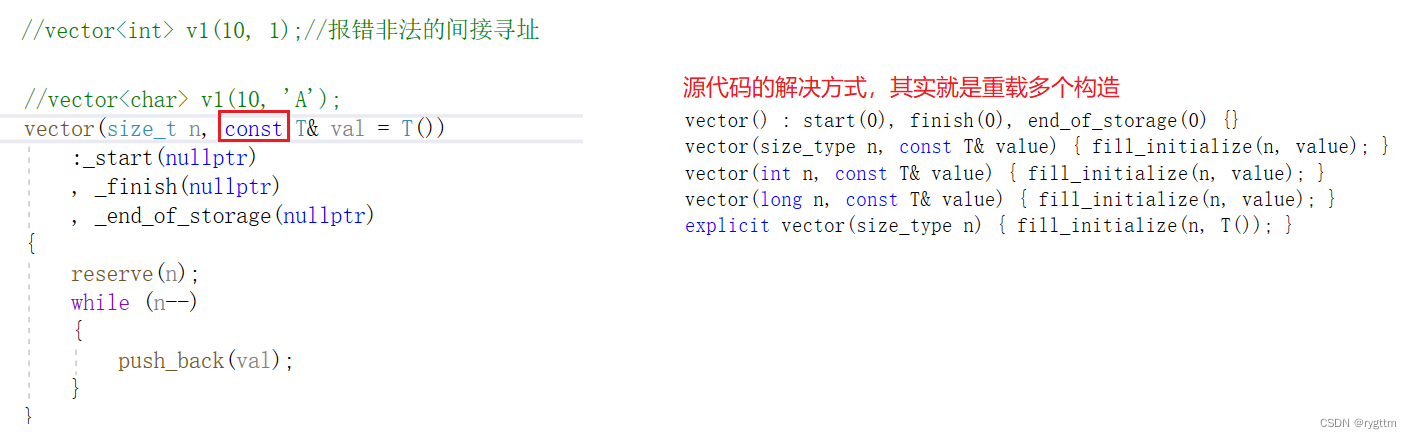
//vector<int> v1(10, 1);
//1.两个都是int,则v1优先匹配的是两个参数均为同类型的模板class InputIterator,不会是下面的构造,因为10需要进行隐式类型转换
//1也需要进行类模板的显示实例化,优先级并没有同类型参数的函数模板高,函数模板只需要一次推导参数类型即可匹配成功。
//2.但是如果匹配了函数模板,则解引用int类型就会发生错误,非法的间接寻址。
//
//vector<char> v1(10, 'A');一个是int一个是char,没有选择,只能选择下面的构造函数进行v1的构造。
//所以可以将构造函数的第一个参数类型改为int,但库在实现的时候,默认用的就是size_t,我们改成int就不太好。
//那该怎么办呢?答案就是看源代码。利用重载构造解决问题。
vector(size_t n, const T& val = T())//引用和指针在赋值时,有可能出现权限问题。这里需要用常量引用,否则无法接收常量值。
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
reserve(n);
while (n--)
{
push_back(val);
}
}
vector(int n, const T& val = T())//引用和指针在赋值时,有可能出现权限问题。这里需要用常量引用,否则无法接收常量值。
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
reserve(n);
while (n--)
{
push_back(val);
}
}
void test_vector8()
{
std::string s("hello world");
vector<int> v(s.begin(), s.end());
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
//vector<int> v1(10, 1);//报错非法的间接寻址
vector<char> v1(10, 'A');//这样的情况都不会出现问题,但是这样的情况,构造函数第二个参数需要加const修饰,以免权限放大
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
//编译错误:注释代码排除寻找出现问题的代码部分
//运行错误:进行调试
}
二、vector的拷贝构造和赋值重载
1.
对于拷贝构造的实现,和string一样,还是有传统写法和利用打工人的现代写法,利用打工人的本质实际就是代码重构。传统写法还分为两种,一种是自己new一个空间然后利用memcpy对数据进行拷贝,另一种就是提前用reserve预留好空间,然后push_back将数据尾插到提前预留的空间当中,但前一种的传统写法实际存在潜在的隐患,如果拷贝的数据类型是自定义类型,那就是浅拷贝,因为memcpy拷贝设计资源申请的类型时,会逐字节进行浅拷贝。所以还是使用现代写法吧。
2.
无论是从代码可读性还是实用性的角度来讲,现代写法都更胜一筹,这里利用形参对象v的迭代器来构造临时对象tmp,然后将对象tmp和* this进行交换,为了防止对象tmp离开函数栈帧销毁时造成野指针的访问问题,所以在调用构造函数时采用了初始化列表的方式将* this的三个成员都初始化为nullptr。
3.
在实现拷贝构造后,实现赋值重载就比较简单了,利用传值拷贝构造的临时对象即可,然后调用swap类成员函数即可完成自定义类型的赋值工作。为了符合连续赋值含义,我们利用引用来作为返回值。
4.利用现代写法的拷贝构造和赋值重载,无论是vector<vector< int >>这样的类型,还是更为复杂的vector类型,都可以完成深层次的拷贝问题,
下面是我陷入的坑,然后想了想又自己跳出来了。
vector& swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_end_of_storage, v._end_of_storage);
return *this;
}
// v2(v1)---v1拷贝构造v2
vector(vector<T>& v)
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
//1.普通的传统写法就是开空间和拷贝数据
//_start = new T[v.capacity()];
//2.进阶的传统写法
reserve(v.capacity());
for (auto& e : v)
//遍历v,将遍历所得的迭代器里面的值依次赋值给e,如果T是自定义类型,这里会发生多次的拷贝构造,所以最好加引用。
{
push_back(e);
}
}
vector(const vector<T>& v)//打工人依旧是带参数的构造函数
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
//string时候的拷贝构造调用的是带参的构造函数,依次来创建出tmp,构造函数就是打工人
vector<T> tmp(v.begin(), v.end());
swap(tmp);//交换的时候就可以体现出拷贝构造函数初始化列表的好处了。
}
// v1 = v2;
// v1 = v1;//极少数情况才会出现自己给自己赋值,况且自己给自己赋值也不报错,所以我们容忍这种情况的出现。
vector<T>& operator=(vector<T> v)//返回引用,符合连续赋值的含义
{
swap(v);
return *this;
}
三、迭代器失效(异地扩容引起的野指针问题)
1.insert异地扩容导致的迭代器失效
1.
迭代器就是粘合容器和算法的粘合剂,它可以让算法不用关心底层数据结构的实现,其底层实际就是一个指针,或是对指针进行封装的产物。
vector的迭代器是一个原生指针的typedef,所以迭代器失效的本质就是指针失效,换句话说就是野指针访问,对指针指向的无效空间进行访问所导致的问题。
2.
在使用insert时,我们需要传某个位置的迭代器,如果在insert中不发生扩容,则这个迭代器在insert之后还是有效的,但只要在insert中发生扩容,则迭代器就会失效,因为reserve进行的是异地扩容,所以原有的迭代器就不能使用,因为原有迭代器指向的是已经释放的旧空间的某个位置,所以如果继续使用,则势必会发生野指针的访问,这正是我们所说的迭代器失效。

3.
如果要解决,方式也很简单,使用insert的返回值即可,它的返回值是指向第一个新插入元素的迭代器。利用insert的返回值就不会发生迭代器失效的问题了。

//迭代器失效:野指针问题
void insert(iterator pos, const T& val)
{
assert(pos >= _start);
assert(pos < _finish);
if (_finish == _end_of_storage)
{
size_t len = pos - _start;//记录一下原空间pos和_start的相对位置。
size_t new_capacity = capacity() == 0 ? 4 : 2 * capacity();
//扩容导致了迭代器pos失效,因为进行了异地扩容,pos位置指向的是已释放空间的迭代器
reserve(new_capacity);
pos = _start + len;
//所以如果发生扩容,则需要更新pos的位置
}
//挪动数据,对于vector来说,就不存在pos等于0时的越界问题,但没有下标的问题,又会产生指针的问题
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = val;
++_finish;
}
void test_vector4()//测试迭代器失效
{
string s;
vector<int> v;
//v.reserve(10);//如果提前开辟好空间,就不会产生迭代器失效的问题。实际就是因为异地扩容导致的迭代器失效
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
vector<int>::iterator it = find(v.begin(), v.end(), 3);
if (it != v.end())
{
v.insert(it, 30);
}
//insert以后,it不能继续使用,因为迭代器可能失效(野指针),虽然在insert内解决了迭代器失效的问题,但那只是修改了内部的pos
//it是外部的,依旧不可以使用,传值传递,外部的问题依旧没有被解决。
(*it)++;//这里一定是一个野指针,因为发生了异地扩容,it指向的是旧空间的位置,但野指针的访问并没有被编译器报错,这很危险。
//所以一定要小心对于野指针的使用,如果it指向的旧空间被分配给某些十分关键的金融数据,则野指针访问会修改这些关键数据,非常危险
//如果野指针的使用影响到其他的进程就完蛋了,公司里出现这样的问题直接废球了。
//1.为什么不用传引用来解决这里的问题呢?因为对于地址这样的常量不能作为变量进行传递,无法从int*转换为int*&
//2.所以在insert之后不要继续使用it,因为他很有可能失效,就算在vs上不失效,但你能保证在其他平台下也不失效吗?比如g++呢?
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}
2.vs和g++对于erase后迭代器是否失效的处理手段(一个极端,一个温和)
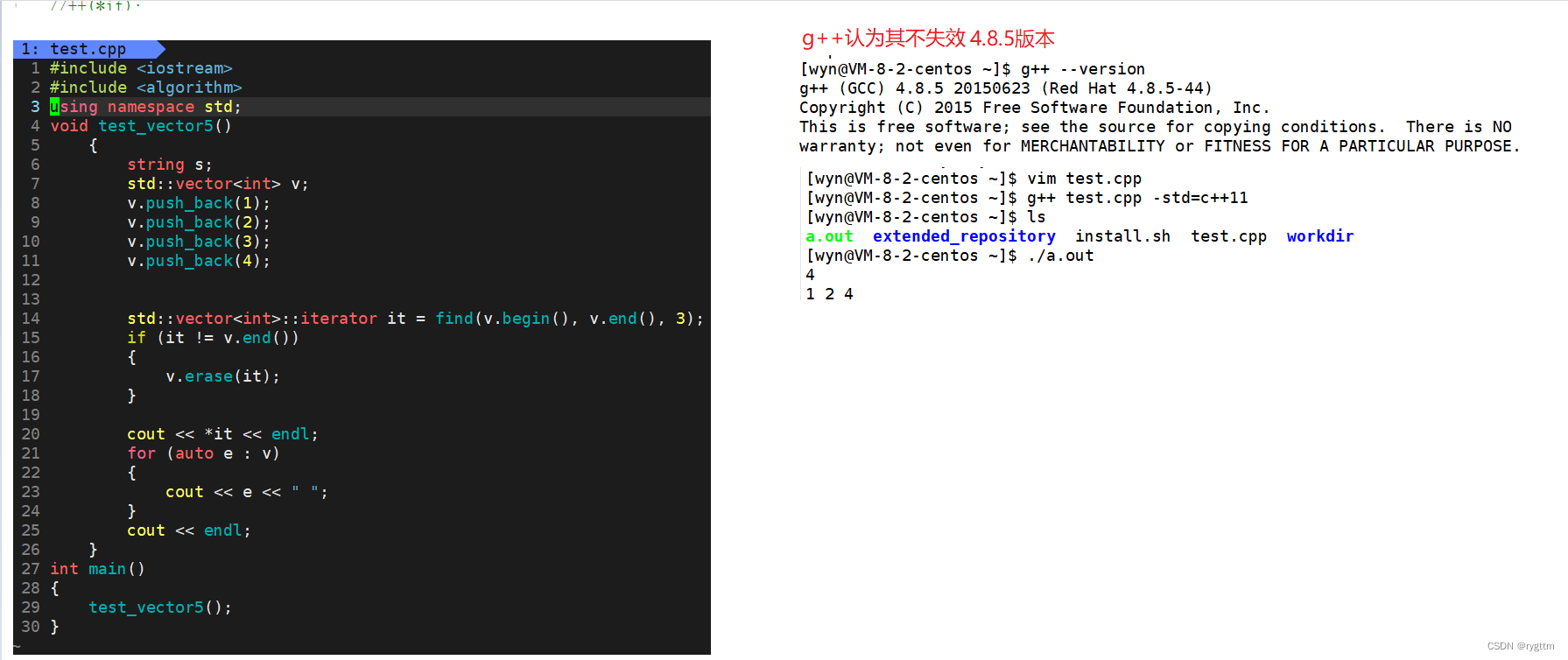
1.
对于vs编译器来说,他是认为erase后迭代器是失效的,在2013的版本下会直接报断言错误,在2022版本下会越界访问,而g++对迭代器失效的检测并不是非常严格,处理也没有vs下极端。

2.
erase删除任意位置代码后,linux下迭代器并没有失效,因为空间还是原来的空间,后序元素往前搬移了,it的位置还是有效的,但是在vs下就会直接报错,所以对于erase之后迭代器是否失效的这一讨论,为了保证程序良好的移植性,我们统一认为erase之后迭代器失效,如果要使用则需要利用erase的返回值来对迭代器重新赋值。

iterator erase(iterator pos)
{
assert(pos >= _start);
assert(pos < _finish);
iterator begin = pos + 1;
while (begin < _finish)
{
*(begin - 1) = *(begin);
begin++;
}
--_finish;
return pos;
}
void test_vector5()//测试迭代器失效
{
std::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
// it是失效还是不失效呢?
std::vector<int>::iterator it = find(v.begin(), v.end(), 3);
if (it != v.end())
{
v.erase(it);
}
//读
cout << *it << endl;//PJ版实现的非常复杂,相对于SGI版本。能够检查出来越界访问
//写
//++(*it);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}
3.
这里在多说一句,在应用场景要求删除所有的偶数情况下,这样的情况稍加更加复杂,如果条件控制不得当,一不小心连g++都有可能会报错,在条件控制这里,我们主要说一下while循环中,if和if else的区别,如果是if条件判断,则后面的it无论什么情况都会++一下,无论是偶数还是奇数,it都会++,这样的控制条件就比较容易出问题。而如果利用if和else来解决的话,则只有在奇数情况下,it才会++,偶数情况下,it不会++。这就是if和if else在用法上的区别。
平常在使用时,要根据具体场景恰当选择这两个分支语句中的哪一个,之前我不知道两者区别的时候,就因为使用的场景不恰当,导致出现了很多的bug。
void test_vector6()//这里我们用自己实现的erase来更新失效之后的迭代器
{
// 要求删除所有的偶数
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(4);
v.push_back(9);
vector<int>::iterator it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
it = v.erase(it);
//所以正确的使用方式就是利用erase的返回值进行迭代器的使用,这样不管你怎么用,迭代器都不会失效。
//因为在erase之后我们统一认为迭代器it失效了,所以需要erase的返回值来更新迭代器,代码在VS和g++下面都可以跑。
}
//it++;//更新迭代器之后,不要继续it++了,因为erase的返回值已经帮你把it挪到下一个元素的位置了,所以你就不要再++了,
else
{
++it;
}
//vs结果还是一样的,erase之后it++,vs认为迭代器失效。所以不要尝试使用erase之后的迭代器。
//统一认为erase之后的迭代器失效。
}
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}
//insert扩容迭代器失效和erase后统一认为迭代器失效。如果想用,那就不要去直接访问迭代器,而是利用返回值更新一下迭代器。
四、vector的更深层次的拷贝
1.memcpy逐字节拷贝造成的浅拷贝问题
1.
在测试接口部分,我们创建了一个vector<vector< int >>类型的数组,数组每个元素是vector< int >类型,由10个数字1组成的vector< int >,在push_back四次之前,程序都不会报错,在第五次的时候,程序就会崩溃。
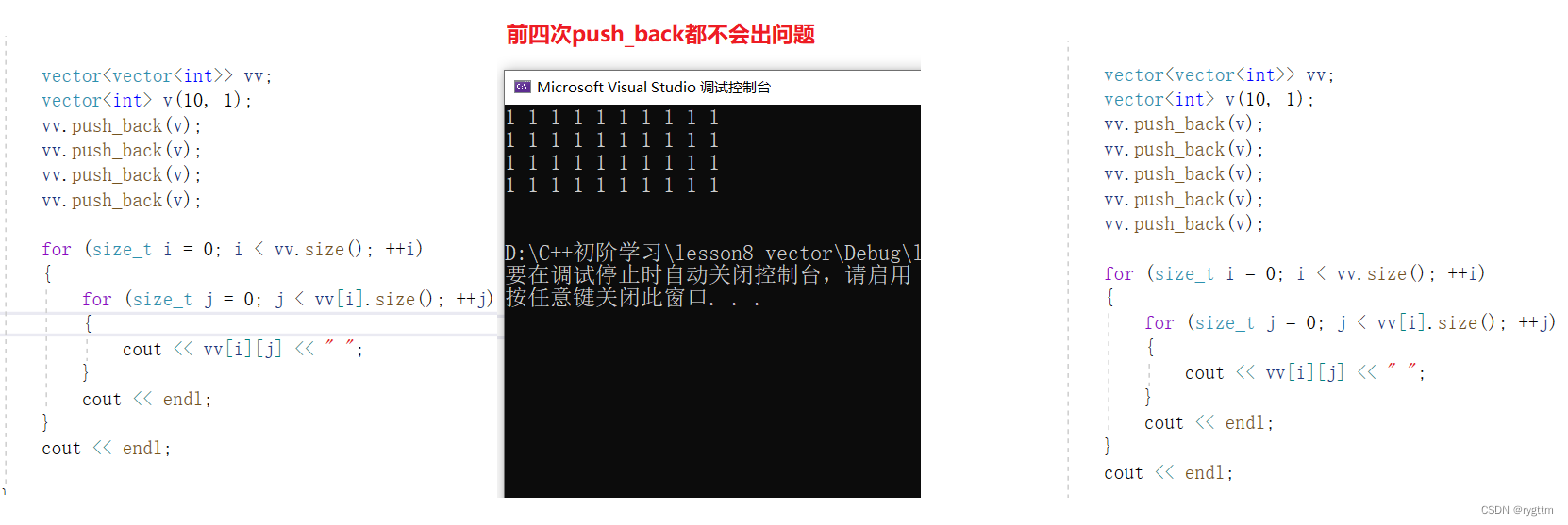
2.
其实是因为在第五次的时候,要调用reserve接口,reserve会进行开空间和数据拷贝的工作,而数据拷贝利用的是memcpy逐字节拷贝的函数,所以一旦拷贝的数据类型是自定义类型,那就是指针的浅拷贝,在临时对象离开函数栈帧销毁tmp对象时,会调用析构函数将指针所指空间销毁,这样一来*this对应的数组里面的每个vector< int >对象的所有指针就都会变为野指针,此时push_back就会对野指针进行访问,自然程序会报错。
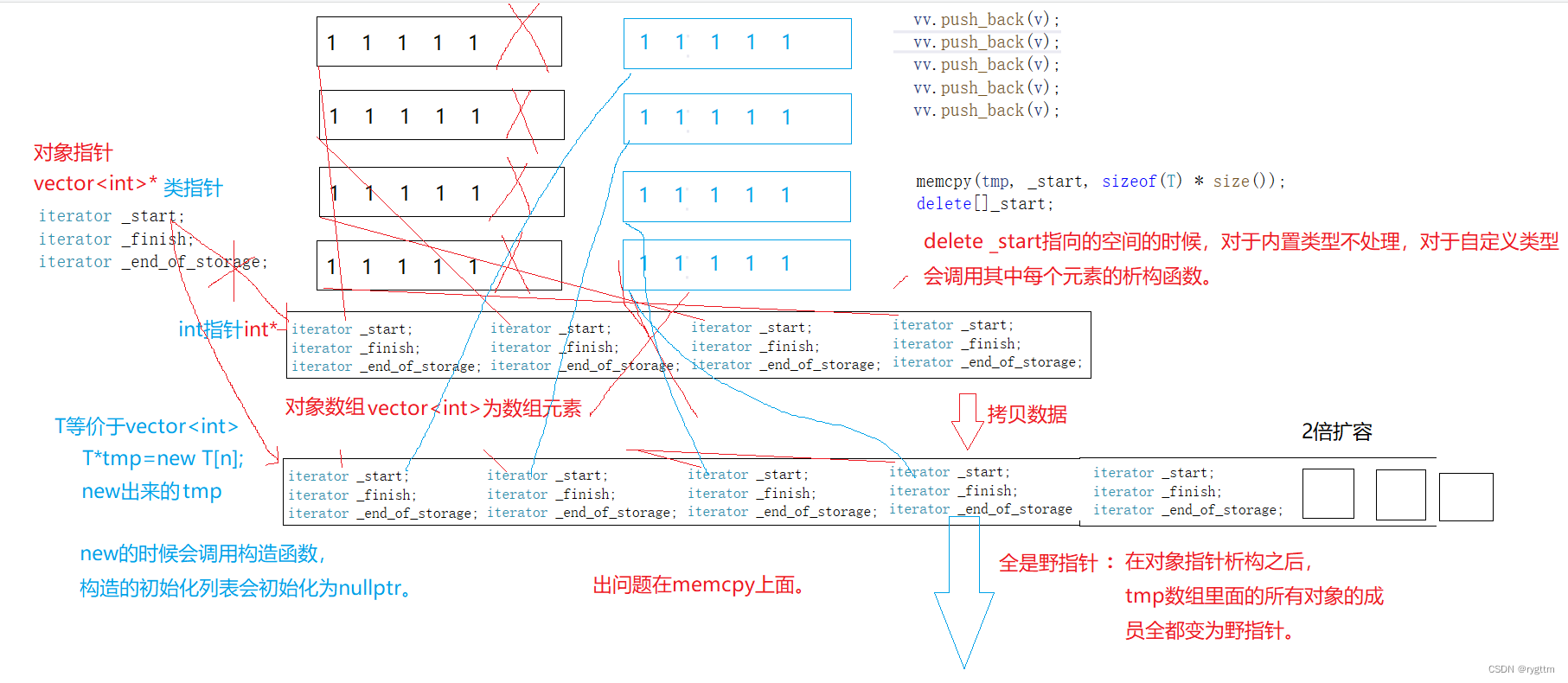
3.
所以如果想要解决,那就不仅仅需要进行vector<vector< int >>类型的数组的深拷贝,数组的元素也需要进行深拷贝,所以就需要深层次的深拷贝,继续利用memcpy当然是不行的,但其实我们可以利用赋值重载来进行解决,赋值重载间接调用拷贝构造,拷贝构造又间接调用迭代器区间作为参数的构造函数,用它当作打工人来帮我们构造一个和拷贝对象一样的对象,最后将被拷贝对象成功创建出来,赋值重载内部只需进行交换二维数组内部的一维数组的三个指针即可。
所以代码重构的思想是非常优雅的,毫不费力地帮我们解决了深层次的深拷贝问题。


~vector()
{
delete[] _start;
_start = _end_of_storage = _finish = nullptr;
}
void reserve(size_t n)
{
if (n > capacity())//只进行扩容
{
size_t oldsize = size();
T* tmp = new T[n];//不需要检查new失败,因为C++new失败直接抛异常
if (_start)//空对象扩容时,_start是nullptr,没必要拷贝数据
{
//memcpy(tmp, _start, sizeof(T) * size());
//如果是自定义类型,则浅拷贝后的同一空间释放两次,势必会造成野指针使用问题的出现
//仅仅只发生vector<int>对象数组的深拷贝是不行的,还需要进行其中每个对象的深拷贝,则需要深层次的深拷贝。
for (size_t i = 0; i < oldsize; ++i)
{
tmp[i] = _start[i];//这里直接调用赋值重载,赋值重载会帮助我们进行对象数组元素的深拷贝
}
delete[]_start;
}
/*_start = tmp;
_finish = _start + size();*///如果是空对象,则_finish没改变为空,而start变为tmp的首元素地址了。
_start = tmp;
_finish = tmp + oldsize;
_end_of_storage = _start + n;
}
}
void resize(size_t n,T val = T())//如果是自定义类型,则将自定义类型的对象先进行初始化,然后在插到vector里面。
{
if (n > capacity())
{
reserve(n);
while (_finish < _start + n)//要小心这里的条件控制,_finish不能等于_start+n,否则发生越界访问。
{
*_finish = val;//如果T是自定义类型,则这里发生赋值重载
++_finish;
}
}
else
{
_finish = _start + n;
}
}
void push_back(const T& x)
{
if (_finish == _end_of_storage)
{
size_t new_capacity = capacity() == 0 ? 4 : 2 * capacity();
reserve(new_capacity);
}
*_finish = x;
++_finish;
}
void test_vector9()//这里涉及很深的深拷贝问题。
{
vector<vector<int>> vv;
vector<int> v(10, 1);
vv.push_back(v);//第一次是开空间,然后存放数据,并不存在拷贝数据的情况。
vv.push_back(v);
vv.push_back(v);
vv.push_back(v);
vv.push_back(v);//这个地方会挂,挂在扩容,问题出在拷贝数据上面。
for (size_t i = 0; i < vv.size(); ++i)
{
for (size_t j = 0; j < vv[i].size(); ++j)
{
cout << vv[i][j] << " ";
}
cout << endl;
}
cout << endl;
vector<vector<int>> vvret = Solution().generate(5);
//非静态成员函数的调用必须与某个特定对象相对。1.搞成静态就可以解决了。2.或者利用匿名对象调用非静态成员函数
//这里出现问题的原因还是因为reserve里的memcpy浅拷贝,因为拷贝构造利用的打工人是迭代器区间为参的构造函数,依旧绕不开
//push_back和reserve,那么一旦出现对象数组的拷贝构造时,reserve里面的memcpy就会造成野指针问题。
for (size_t i = 0; i < vvret.size(); i++)
{
for (size_t j = 0; j < vvret[i].size(); j++)
{
cout << vvret[i][j] << " ";
}
cout << endl;
}
cout << endl;
}
2.其他方便使用的小接口
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin()const
{
return _start;
}
const_iterator end()const
{
return _finish;
}
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];//把_start当成数组玩就行。解引用比较麻烦
}
const T& operator[](size_t pos)const
{
assert(pos < size());
return _start[pos];//把_start当成数组玩就行。解引用比较麻烦
}
size_t size()const//const和非const对象都能调
{
return _finish - _start;
//左闭右开的差正好就是这个区间内的元素个数,[0,10)是正好10个元素,左闭右闭算的是间隔数,如果算元素个数还得+1
}
size_t capacity()const
{
return _end_of_storage - _start;
}
bool empty()const
{
return _start == _finish;
}
void pop_back()
{
assert(!empty());//判断为假就报错。
--_finish;
}


![[Java·算法·中等]LeetCode215. 数组中的第K个最大元素](https://img-blog.csdnimg.cn/79935be653c64a66a673a381996da929.png)