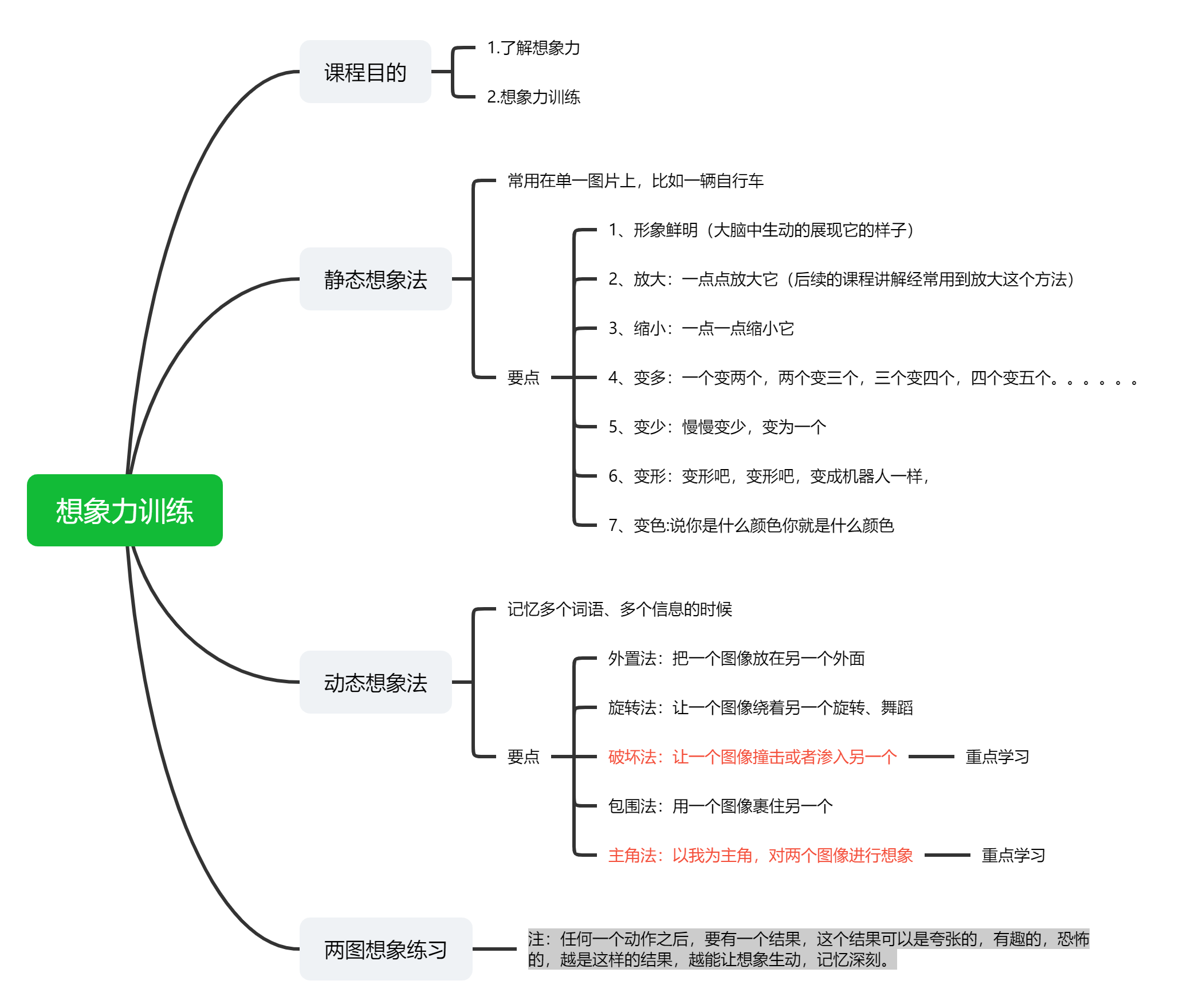
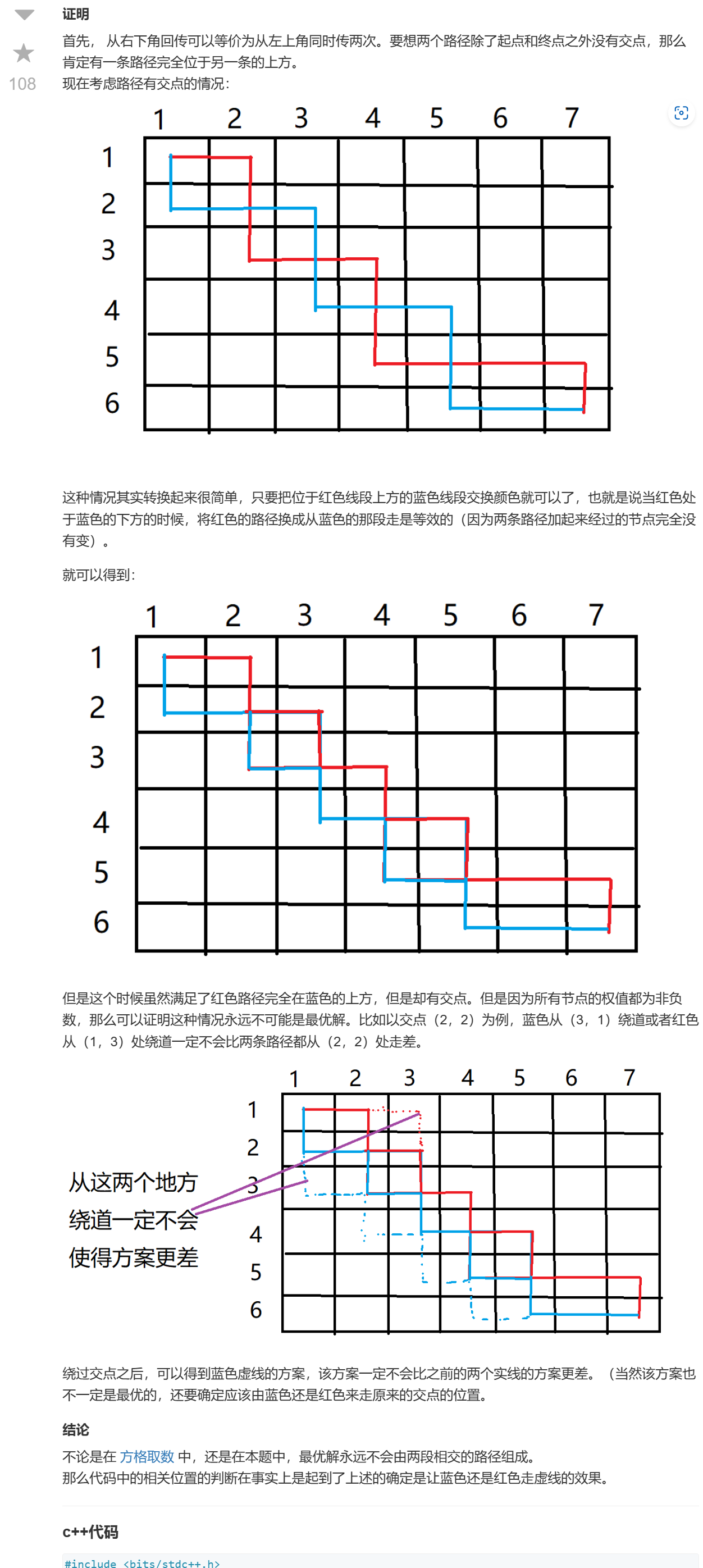
摘要:本文整理自阿里云高级开发工程师 Apache Flink Committer、Flink 1.16 Release Manager 黄兴勃(断尘),在 FFA 2022 核心技术专场的分享。本篇内容主要分为四个部分:
综述
持续领先的流处理
更稳定易用高性能的批处理
蓬勃发展的生态
Tips:点击「阅读原文」查看原文视频&演讲 ppt
01
综述
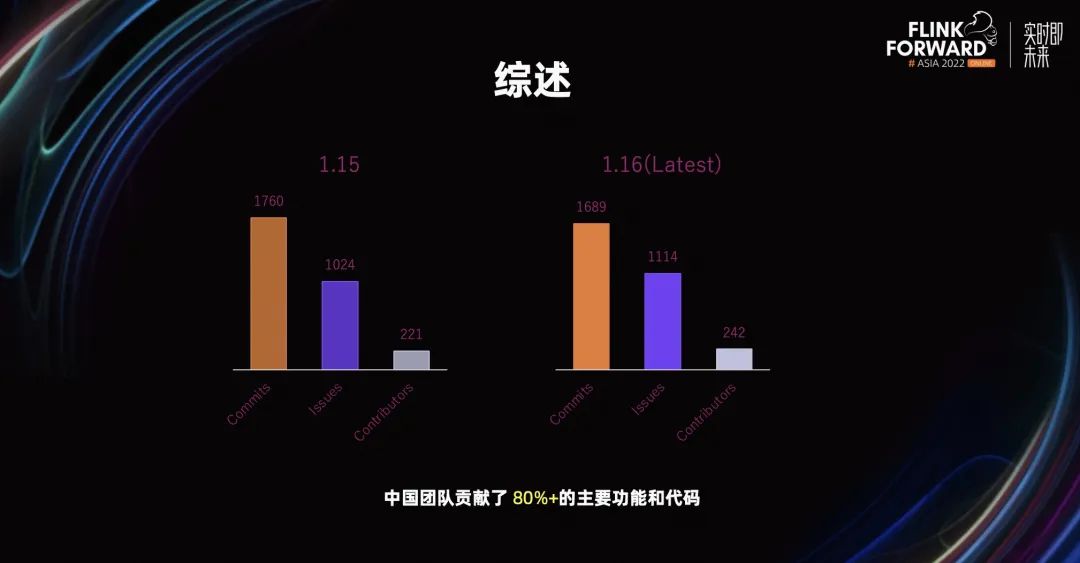
Flink 1.16 同 Flink 1.15 相比,在 Commits、Issues、Contributors 上,保持了较高的水准。最大的不同是,我们在 Flink 1.16 中大部分的功能和代码,主要由中国开发者主导完成。

非常感谢二百四十多位中国 Contributors 对 Flink 1.16 的贡献。接下来,我们详细的看一下 Flink 1.16 在三个方面的改进。
02
持续领先的流处理
Flink 作为流式计算引擎的标准,在 Flink 1.16 的流处理方面,依然做了许多的改进和探索。
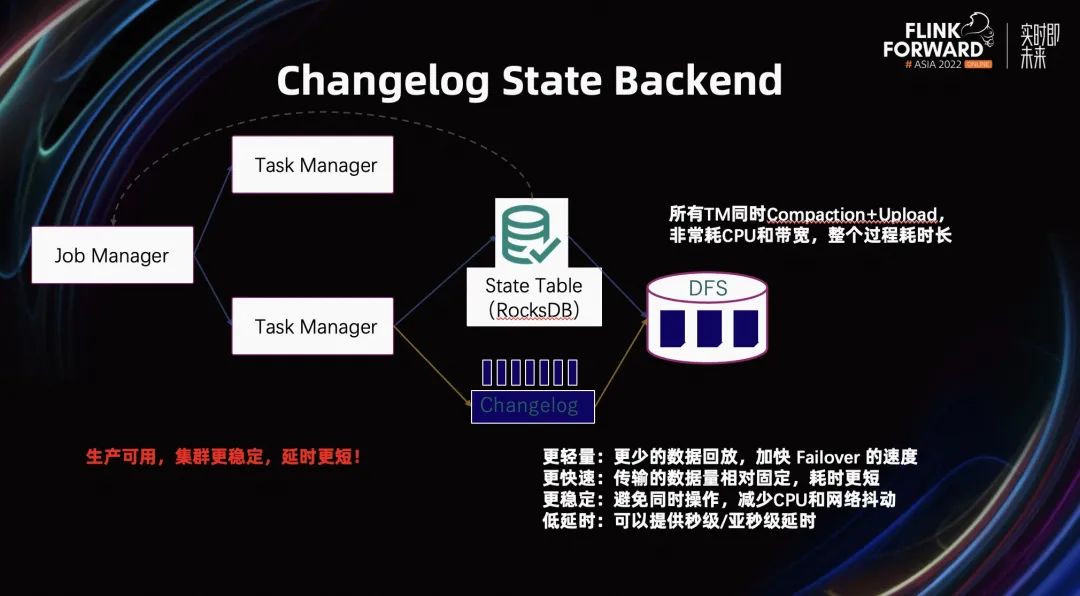
State 是 Flink 中非常重要的概念。有了 State 的存在,才使得 Flink 在流处理上能够保证端到端的 Exactly Once 的语义。State 经过多年的持续发展,在 Flink 1.15 提出了 Changelog State Backend,为了解决 RocksDB 由于 TM 需要同时进行 Compaction 和 Upload,导致它的 CPU 和带宽出现周期性抖动的问题。这部分在引入 Changelog 后得到了解决。
它的基本原理是,当 TM 做 State 操作时,会同时双写。一部分数据会像原来一样,写到原来的本地 State Table 当中。与此同时,会将 State 数据以 Append Only 的形式,写到本地 Changelog 中。Changelog 中的这部分信息,会周期性的上传到远端 DFS。
由于这部分 Changelog 信息相对固定,而且是一种周期定量的形式,所以使得在做 Checkpoint 时,持久化的数据变少,加快了作业 Failover 的速度。其次,因为这份数据相对较少,做 Checkpoint 时的速度会更快。
除此之外,它还改善了 Checkpoint 的问题,解决了 CPU 和带宽抖动的问题。因为它的速度更快,低延时,使得端到端的数据新鲜度更好,保持在分钟级别以内。
这部分功能在 Flink 1.16 实现了全面生产可用,整个集群变得更加稳定。
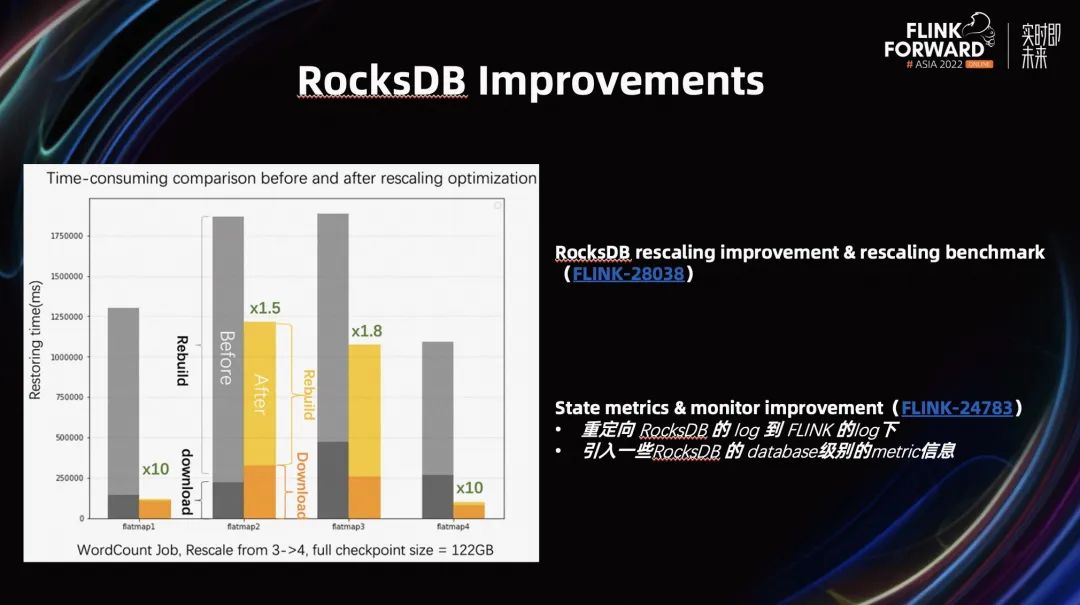
我们在 Flink 1.16 的 RocksDB 上,也做了很多改进,我们引入了 Rescaling Benchmark。可以观测 RocksDB 的 Rescaling 耗时,以及耗时的部分在哪里。
除此之外,我们也在 RocksDB Rescaling 上做了一些改进,大幅提升了 RocksDB Rescaling 的性能。如上图所示,我们能看到在左图中,对于一个 WordCount 作业,提升了 3~4 倍的性能。
除了 RocksDB Rescaling 的改进,我们对现有的 State Metrics 和 Monitor 也进行了改进。我们将原来 RocksDB 的一些 log 信息,重定向到了 Flink log 中。其次,我们将 RocksDB 基于 Database 级别的 Metric 信息引入到了 Flink 系统中。用户可以通过 Flink Metric 系统,查看 RocksDB 的情况。

刚才讲了我们在 Flink 1.16 中,对 State 和 RocksDB 的改进。除此之外,我们在 Checkpoint 上也做了很多改进。
在 Flink 1.11 中,我们引入了 Unaligned Checkpoint,并在 Flink 1.13 实现了生产可用。自此,很多公司开始在他们的生产环境中使用 Unaligned Checkpoint。但在使用过程中,也发现了一些问题。某公司的小伙伴在自己的生产环境中,使用了 Unaligned Checkpoint 后,发现了一些问题,并进行了改进,回馈给了社区。
我们简单看一下 Unaligned Checkpoint 做的一些改进。
第一个是支持透支 buffer。这个功能的引入是为了解决我们 Unaligned Checkpoint 由于 Flink 的执行流程是基于 Mailbox 的处理流程带来的可能的问题。我们知道,做 Checkpoint 的流程是在主线程中进行的,而当主线程在处理 Process Function 逻辑时,Process Function 输出的数据是需要往下游 buffer 输出需要申请一些 output buffer 的。
在上述过程当中,可能出现在反压很严重的情况时,由于难以申请到 buffer,导致主线程卡在了 Process Function 逻辑中。在 Flink 1.16 之前,社区也做了相关的改进:当主线程需要进入 Process Function 逻辑前,需要预先申请 output buffer 里的 buffer。有了这个 buffer 后,它才会进入 Process Function 的逻辑,从而避免卡在里面。
上述方案解决了部分问题,但是仍没有解决其他的一类 Case。如果输入/输出的数据太大,或者 Process Function 是一个 Flatmap Function,需要输出多条数据的情况,一个 buffer 将无法满足,主线程依然会卡死在 Process Function 里。
在 Flink 1.16 中,引入了透支 buffer 的方式。如果 TM 上有额外的一些 buffer 的话,你就可以申请这部分内存。然后,通过透支这部分的 buffer,让主线程不会卡死在 Process Function 中,就能正常跳出 Process Function。主线程就能接收到 Unaligned Checkpoint Barrier。
之前,Unaligned Checkpoint 引入了一个 Timeout Aligned 机制。如果你的 Input Channel 接收到一个 Checkpoint Barrier 时,在指定时间段内没有实现 Barrier 对齐的话,Task 将会切换到 Unaligned Checkpoint。但是如果 Barrier 卡在了 output buffer 里面,下游的 Task 依然是 Aligned Checkpoint。在 Flink 1.16 中,解决了 Barrier 卡在输出队列的情况。
通过以上这两个改进,Unaligned Checkpoint 得到了更大的提升,稳定性也更高。

我们在 Flink 1.16 中,对维表部分的增强。
1. 我们引入了一种缓存机制,提升了维表的查询性能。
2. 我们引入了一种异步查询机制,提升了整个吞吐。
3. 我们引入一种重试机制,主要为了解决维表查询时,遇到的外部系统更新过慢,导致结果不正确,以及稳定性问题。
通过上述改进,我们的维表查询能力得到了极大提升。

在 Flink 1.16 中,我们支持了更多的 DDL。比如 CREATE FUNCTION USING JAR,支持动态加载用户的 JAR,方便平台用户管理用户的 UDF。
其次,我们支持 CREATE TABLE AS SELECT,让用户便捷的通过已有 Table 创建一个新 Table。
最后,ANALYZE TABLE 是 Table 的一种新语法。帮助用户生成更高效的统计信息。这些统计信息会让优化器产生更好的执行图,提升整个作业的性能。

除此之外,我们在流上做了很多优化。这里只列举了几个比较重要的优化。
我们改进了流处理系统中,非确定性问题。这部分非确定性的问题主要包含两部分,一个是维表查询上的非确定性问题,另一个是用户的 UDF 是非确定性的 UDF。
1. 我们在 Flink 1.16 提供了一套非常完备的系统性解决方案。首先,我们能够自动检测 SQL 中,是否有一些非确定性的问题。其次,引擎帮用户解决了维表查询的非确定性问题。最后,提供了一些文档,用户能根据这些文档,更好的发现和解决自己作业中非确定性的问题。
2. 我们终于解决了我们 Protobuf Format 的支持。在 Flink 1.16 中,支持用户使用 PB 格式数据。
3. 我们引入了 RateLimitingStrategy。之前这部分的 Strategy 是定制化,不可配的。在 Flink 1.16 中,我们把它变成可配置。用户能够根据自己的网络堵塞策略,实现自己的一套配置。
03
更稳定易用高性能的批处理
刚才我们聊的都是 Flink 在流处理方面的改进。Flink 不仅是一个流式计算引擎,而且是一个流批一体的计算引擎。所以我们在批处理方面,也做了非常多的工作。Flink 1.16 的目标是,使批处理计算够达到更稳定地应用和高性能。
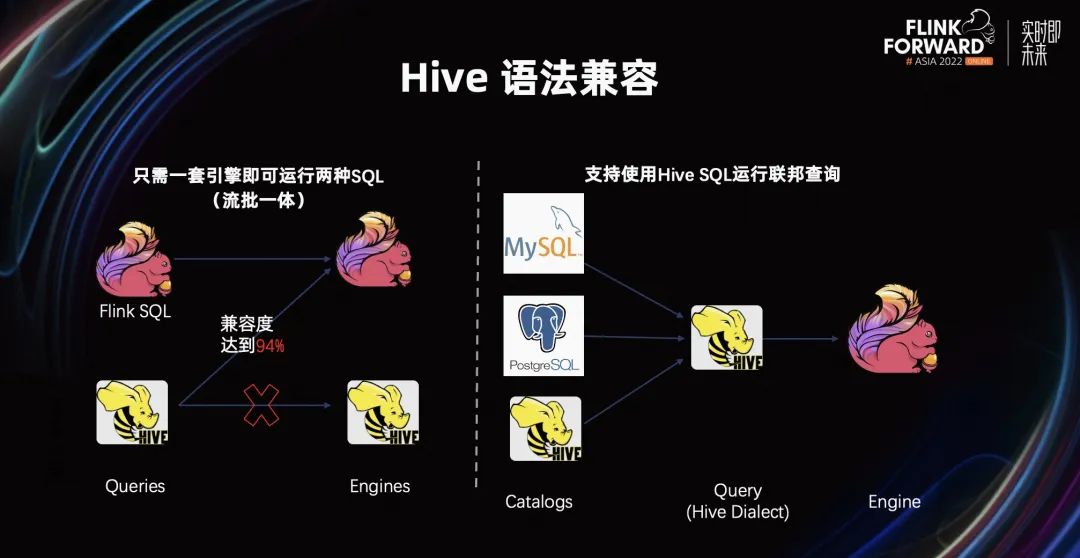
在易用性方面,现有的批生态中,很多用户的作业仍运行在 Hive 生态。在 Flink 1.16 中,我们希望 Hive 的 SQL 能够以非常低价的方式,迁移到 Flink 上。Flink 1.16 的 Hive 生态兼容度达到了 94%。如果扣除掉一些 acid 操作,Hive 生态兼容度达到了 97%。与此同时,配合 Catalog,Hive SQL 在 Flink 引擎上,能够运行联邦查询的能力。
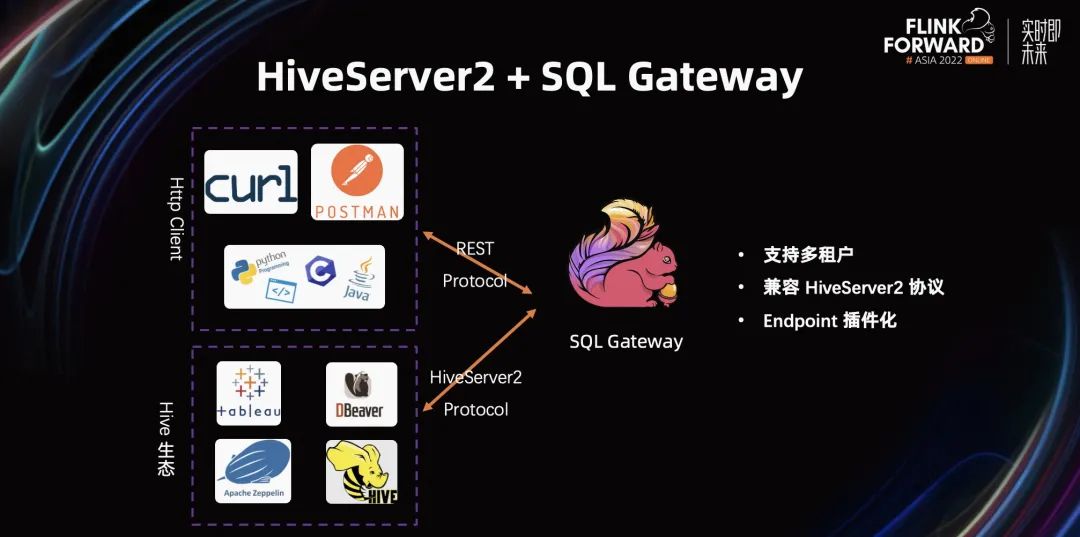
在 Flink 1.16 中,我们还引入了一个非常重要的组件 SQL Gateway。通过 SQL Gateway,以及支持的 HiveServer2,使得 Hive 生态中主流的生态产品可以非常自然的接入 Flink 生态。
在 Flink 1.16 SQL Gateway 中,我们支持多租户,兼容 HiveServer2 协议,以及 HiveServer2 带来的 Hive 生态。有了 HiveServer2 的配合,整个 Hive 生态就能非常便捷的迁移到 Flink 生态上。
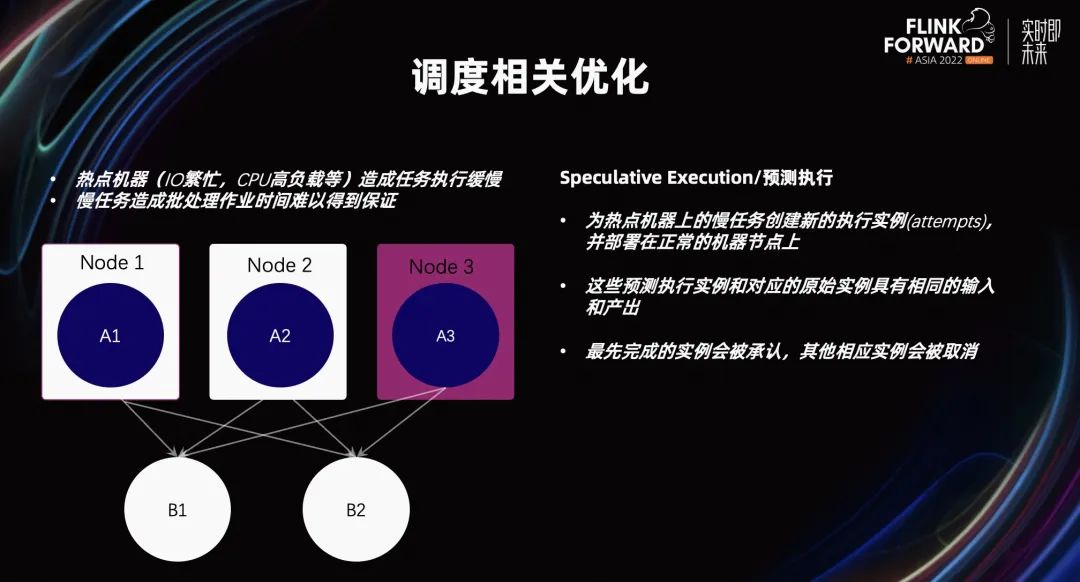
接下来,看看 Flink 引擎本身为批做了哪些优化。首先,讲一讲与调度相关的优化。Flink 批作业经常会遇到这样的问题。由于一些热点机器的 IO 繁忙或 CPU 高负载,导致机器上运行的任务拖累 Flink 批作业端到端的执行时间。
在 Flink 1.16 中,为了解决这个问题,我们引入了 Speculative Execution,一种推测执行的方式。它的基本原理是,在每个阶段,如果我们检测到某一个机器,它是一种热点机器,它上面运行的任务被称为慢任务。所谓慢任务就是,它的慢任务执行时间比同一阶段其他任务的执行时间要长的多,从而把这台机器定义为热点机器。
有了热点机器之后,为了降低整个作业的执行时间。我们希望把热点机器上运行的慢任务,通过一个备份任务,让它能够运行在其他非热点机器上。从而使得整个任务的总执行时间缩短。
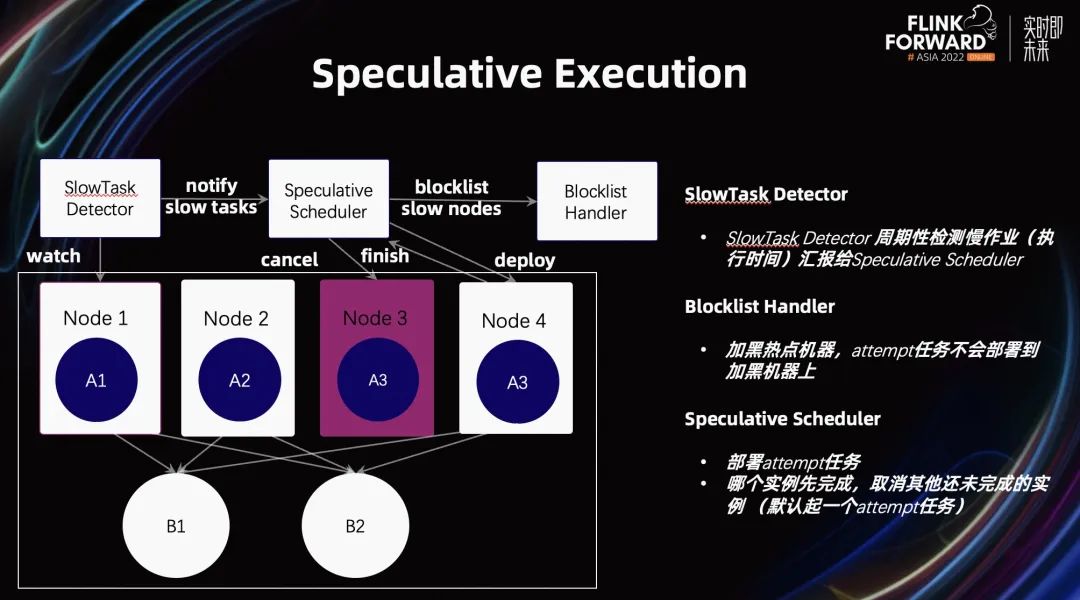
接下来,我们简单看一下它的具体细节。首先,有一个叫 Slow Task Detector 的组件。这个组件会周期性的查看是否有一些慢任务以及慢任务对应的热点机器。
收集到了这些信息后,它会汇报给 Speculative Scheduler。Scheduler 会把这些信息汇报给 Blocklist Handler。然后 Blocklist Handler 会把这些机器加黑。
有了这些加黑机器之后,加黑机器上慢任务的备份任务会被调度到集群当中其他非热点的机器之上,让这些慢任务和备份任务同时运行。谁先完成就承认哪个任务的结果。被承认的那个实例,它的输出也能作为下游算子的输入。没能完成的任务将会被 cancel 掉。
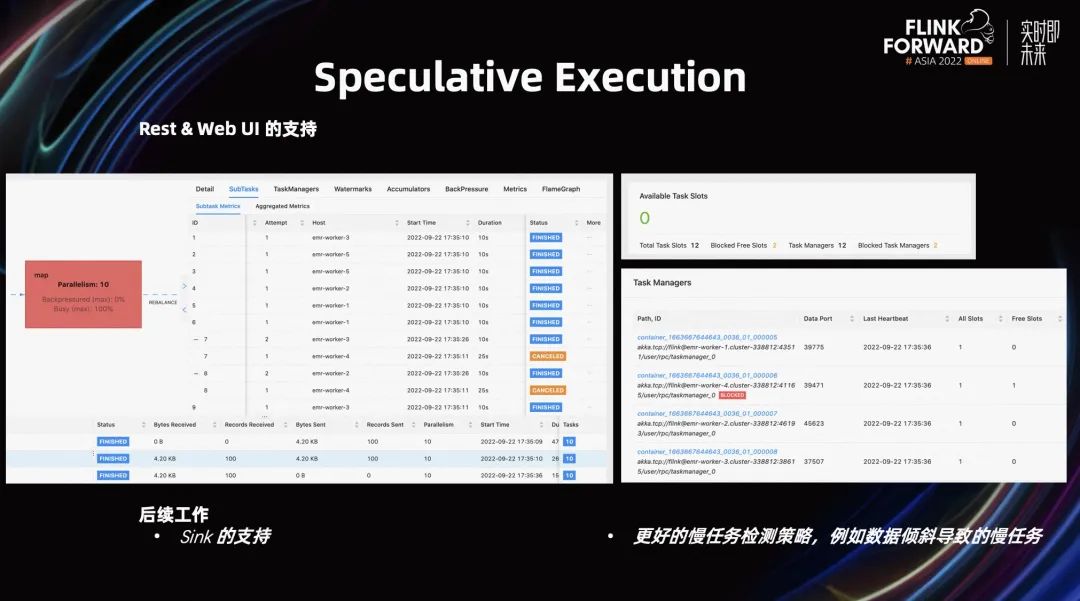
在 Speculative Execution 中,我们也引入了一些 Rest 和 Web UI 的支持。如上左图所示,可以观察到哪些慢任务被取消,哪些是其备份任务。通过右图,可以实时看到哪些 TM 机器被标成了 black 机器。
关于 Speculative Execution 的后续工作,我们当前不支持在 Sink 上的 Speculative Execution。其次,我们现有的检测策略比较粗糙。我们并没有有效的考虑到,由于数据倾斜导致一些慢任务的检测错误。把一些本身是正常的机器,标成了热点机器。这都是我们在 Flink 1.17 之后,需要做的工作。
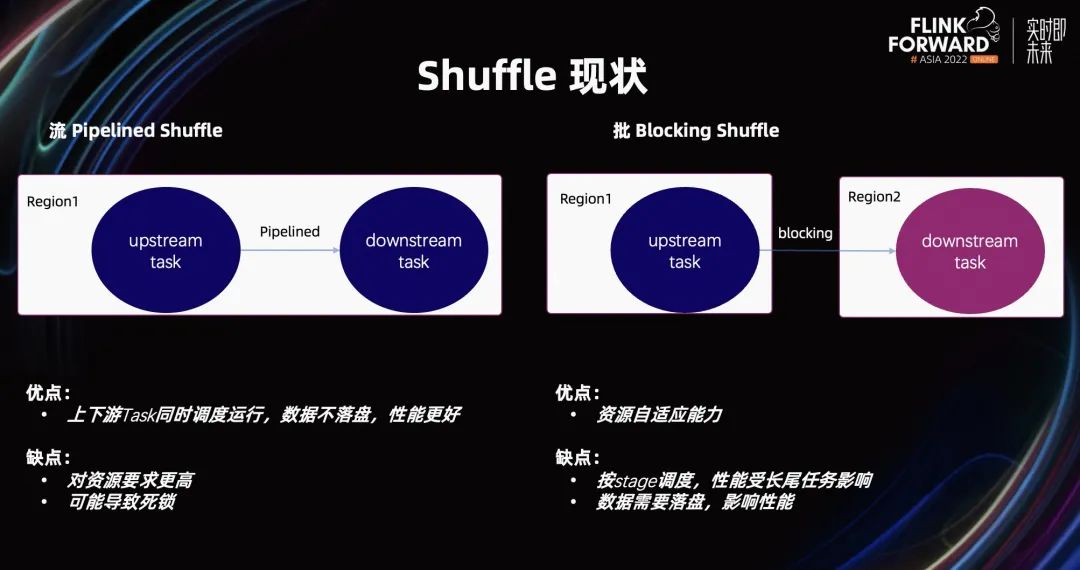
我们在 Shuffle 上做的工作。众所周知,Flink 有两个 Shuffle 策略,一个是 Pipelined Shuffle,另一个是 Blocking Shuffle。
流式 Pipelined Shuffle 的上下游 Task,能够同时调度运行。它的数据传输是一种空对空的传输,数据不落盘,性能更好。但它的缺点是,会占用更多的资源。因为它需要上下游的 Task,同时调度。在一些资源比较紧张的情况下,可能导致作业难以拉起,或者整个作业因为资源索取,造成死锁。
在 Blocking Shuffle 方面,由于它在每个阶段,Task 都会把它的结果写到磁盘里。然后,下游的 Task 再通过磁盘,读取它的数据。这样是好处是,理论上只需要一个 Slot,就能完成整个批作业的运行。但它的缺点也显而易见。因为每个阶段都要把结果数据落盘,下一步还需要读磁盘,所以它的性能较差。
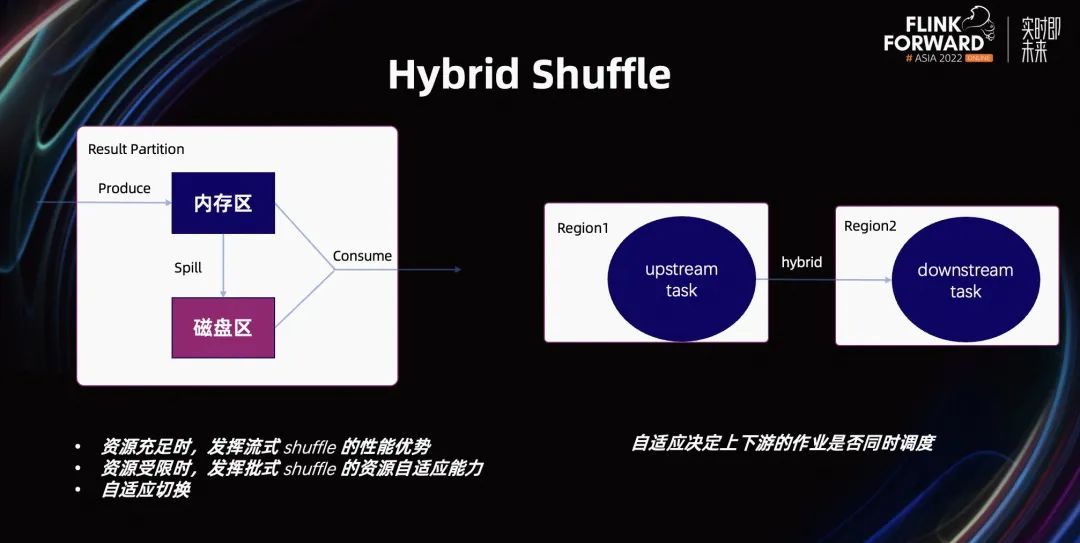
基于这种考虑,我们在 Flink 1.16 提出了一种新的 Shuffle 策略,即 Hybrid Shuffle。其目是同时利用上述两套 Shuffle 的优点。在资源充足时,我们利用 Pipelined Shuffle 的性能优势。在资源不足时,我们利用 Blocking Shuffle 的资源优势。整套 Shuffle 策略是自适应切换的,这是 Hybrid Shuffle 的基本思想。

Hybrid Shuffle 在数据落盘方面,有两套策略。一套是全落盘,另一套是选择性落盘。
选择性落盘的好处是,我们写更少的数据落盘,整个性能相对更高。而全落盘的好处是在 Failover 时的性能会更好。根据用户场景是哪种不同,选择到底用 Hybrid Shuffle 的哪种落盘策略。
在性能方面,Flink 1.16 的 Hybrid Shuffle 相比 Blocking Shufle,TPC-DS 执行时间减少了 7.2%。如果加上广播方面的优化,优化后的 TPC-DS 执行时间比会比 Blocking Shuffle 减少 17%。
关于 Hybrid Shuffle 的后续工作,一个是广播方面的性能优化。另一个是,与 Flink 1.15 提出的 Adaptive Batch Scheduler 适配,以及 Speculative Execution 的适配。

如上图所示,我们在批处理方面还有许多其他优化。我们简单列了一些比较重要的优化。
1. 首先,我们支持了 Dynamic Partition Pruning,即动态分支裁剪。在 1.16 以前的分支裁剪策略都是基于执行图上的静态裁剪。但在批处理上,完全可以利用 Runtime 的一些统计信息,更加高效的进行分支裁剪策略。这套实现让 Flink 1.16 在 TPC-DS 上有 30%的性能提升。
2. 我们引入了 Adaptive Hash Join,一种自适应策略。我们利用 Runtime 的一些统计信息,自适应的将 Hash Join 回退到 Sort Merge Join,提升 Join 的稳定性。
3. 我们在批处理之前的 Blocking Shuffle 上做了一些改进。我们引入了更多的压缩算法(LZO 和 ZSTD)。新的压缩算法是为了解决在数据大小以及 CPU 消耗上的平衡。
4. 我们优化了现有的 Blocking Shuffle 的实现。通过自适应的 buffer 分配,IO 顺序读取,以及 Result Partition 共享,在 TPC-DS 上有 7%的性能提升。
我们在 Batch SQL 上,支持 Join Hints。Join Hints 让用户能手动干预 Join 策略。用户将会知道生成更加高效的执行计划,提升整个作业的性能。
04
蓬勃发展的生态

接下来,介绍一些蓬勃发展的生态产品。如上图所示,PyFlink 是我们生态中非常重要的产品。PyFlink 经过 Flink 1.9 的一路发展到了 Flink 1.16。
1. Python API 的覆盖度达到了 95%以上。一方面,我们优化内置 Window 的支持。在 Flink 1.16 以前,我们在 Flink 1.15 支持了自定义 Window。但对于需要自定义的 Window,用户的实现成本依然较高,难以使用。另一方面,我们在 Flink 1.16 引入了 side output、broadcast state 等支持。
2. PyFlink 支持支持所有的内置 Connector&Format。扩充了 PyFlink 对接各种系统的能力。
3. PyFlink 支持 M1 和 Python 3.9。有了这两部分能力,降低了用户的上手成本。与此同时,Deprecate Python 3.6,将在 Flink 1.17 里移除对 Python3.6 的支持,引入 Python3.10 的支持。
4. PyFlink 搭建了自己的用户网站。提供了各种执行环境下的安装教程,可以在线运行 QuickStart 例子。这些例子直接挂载在在线的 notebook 网站。与此同时,我们总结了许多用户常见的问题答疑,方便新用户上手。同时我们整理了 PyFlink 端到端的场景案例。这些部分内容本质上是为了降低新用户的门槛。
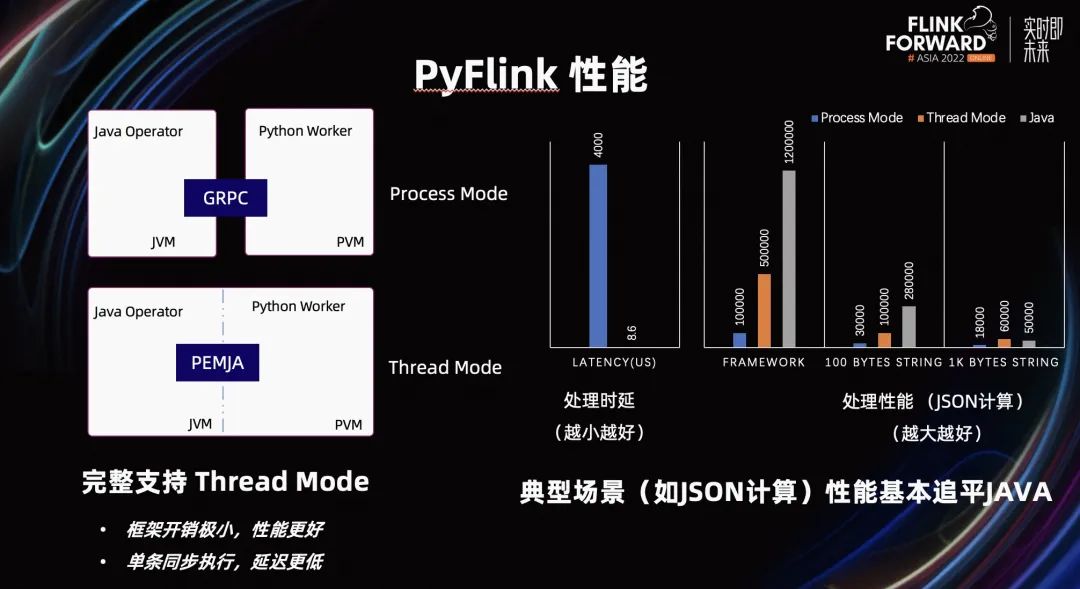
在性能方面,我们在 PyFlink 1.15 时,引入了 Thread Mode。Thread Mode 相对于 Process Mode 最大的不同是,它解决了 Python 进程和 Java 进程间的通信问题。如果是进程间通信,将会有一些序列化/反序列化的开销,而 Thread Mode 将不再有这种问题。
在 Flink 1.16,我们对 Thread Mode 进行了完整的支持。相对于 Process Mode,它的性能会更好,端到端的延迟会更低。
如上图所示,在 JSON 计算的场景下,Thread Mode 的端到端延迟只有 Process Mode 的 1/500。它的性能在通用的典型场景,以及数据比较常见的场景之下,Thread Mode 的性能基本追平了 Java。

由此可见,在 Flink 1.16 中,PyFlink 在功能和性能上,已经达到全面生产可用。除此之外,CEP 也是 Flink 生态中很重要的一部分。我们在 Flink 1.16,对 CEP 的功能进行扩充。
1. 我们在 Batch SQL 上,支持了 CEP 能力。
2. 我们扩充了原有只支持首尾时间间隔的功能,支持了定义事件、事件间隔。

刚才讲的是 Flink 内部重要的生态产品,在 Flink 项目外,我们还有一些重要的生态项目。比如 Flink Table Store、Flink CDC、Flink ML、Feathub。
1. Flink Table Store 配合 Changelog State Backend,实现端到端数据的新鲜度达到分钟级别内。
2. 我们在数据的正确性问题上,做了一些改进。使得 CDC 流进来后做 Join 和聚合会更加流畅。
3. 我们在 DataStream 上支持了 Cache 功能,使 Flink ML 在实现内置算子时,能够得到更高性能。
4. 前一段刚刚开源的 Feathub 项目。Feathub 依赖 PyFlink 作为它的计算引擎底座。随着 PyFlink 性能的提升,Feathub 使用 Python Function 的性能接近 Java Function 的性能,不再有劣势。
更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~
往期精选





▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,查看原文视频&演讲 PPT
点击「阅读原文」,查看原文视频&演讲 PPT



![[Java·算法·中等]LeetCode215. 数组中的第K个最大元素](https://img-blog.csdnimg.cn/79935be653c64a66a673a381996da929.png)





