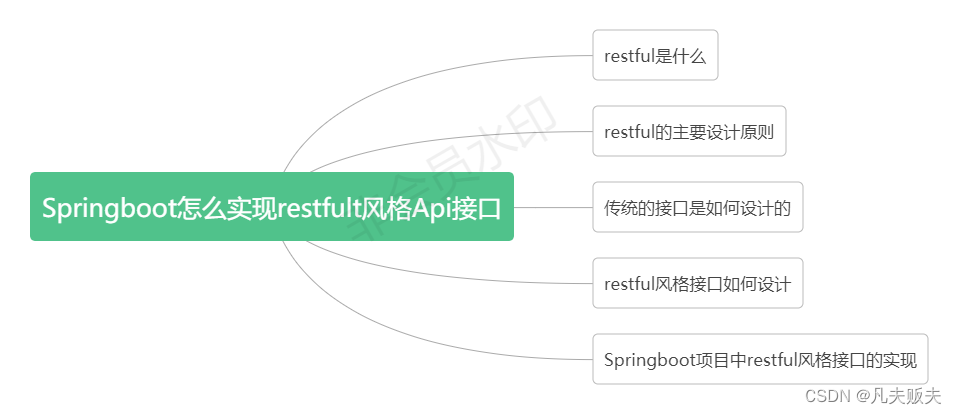
大数据开发的工作内容与流程
- 离线数据仓库开发
- 实时流处理开发
离线数据仓库开发
我们之后在做开发的时候,可能是选择某几个组件来使用。比如做数仓开发,可能就是用sqoop把数据抽到hdfs里,用spark或者mapreduce对这部分数据做一个清洗。
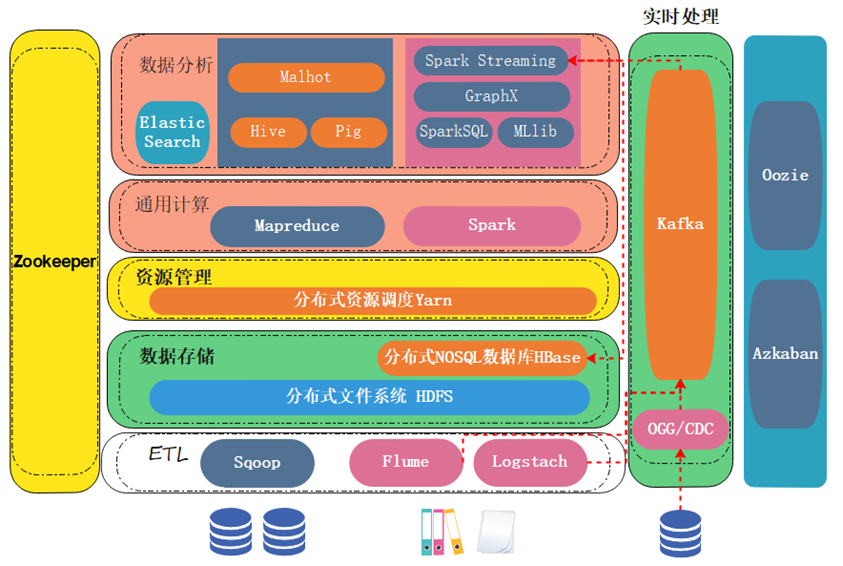
清洗的结果,一般会放到Hive里面。一般开源场景中,Hive是做数仓选型比较多的一个组件,或者放到Spark生态圈的spark sql中。
那之后的话,在hive或者spark sql中可以直接写Sql,来完成对数据的处理即可。
当然的话中间这些个任务的调度,我们可能会选用oozie或者azkaban等任务流调度引擎来完成。
这是数仓的基本架构流程。
实时流处理开发
对于流处理来说的话,可以用flume或者logstach去监控一些非结构化、半结构化数据;像用cdc、ogg这样的一个技术,会监控数据库的日志。这样的话,非结构化、半结构化、结构化数据都可以进行实时采集,把这些个数据实时地抽取到kafka里面进行一个缓存。
然后由流(处理)引擎,比如说spark生态圈的spark streaming,当然还有比较新的像flink这些产品进行一个实时处理。大家可能在这里编写流处理任务会比较多。
数据进行处理以后,可以把这个结果保存到hbase里面,或者存储到elasticsearch里面。
因为这两个的话,它对于小文件来说不是那么敏感。hbase的话,它底层有一个处理小文件的机制;而elasticsearch,它本身文件就不存在hdfs里,它文件直接存在磁盘本地,所以的话它对小文件更不敏感。
因为实时产生的结果,会生成较多小文件,这里是在选型的时候需要注意的。
所以的话流处理一般是用这几个组件比较多。
当然很多时候,在生产中的选型比较复杂,而且会有MPP与大数据产品一起使用的场景,但整体的流程不变,只是各阶段的产品有所替换。后续也会为大家对比分析各主流选型的使用场景与工作流程。
OK,那大数据开发的基本工作内容与流程就给大家讲到这里,谢谢大家!B站配套视频传送:大数据开发的工作内容与流程

![buu [MRCTF2020]Easy_RSA 1](https://img-blog.csdnimg.cn/6b0afa050c8d4d88b10665d683946b44.png)