目录
一、前言
二、论文解读
三、DPN代码复现
四、总结
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊|接辅导、项目定制
● 难度:夯实基础⭐⭐
● 语言:Python3、Pytorch3
● 时间:2月26日-3月3日
🍺要求:
1、对Resnet和Densenet进行总结和探索结合的可能性
2、查阅论文找到结合的点
二、论文解读
论文:DPN(Dual Path Networks)
DPN是在resneXt,denseNet之后,对resnet系列的进一步创新,作者巧妙的将resnet与denseNet相结合,提出了dual path architectures,构造了DPN网络结构。
ResNet和DenseNet是近几年两种比较热门的网络结构,ResNet把输入直接加到(element-wise adding)卷积的输出上,DenseNet则把每一层的输出都拼接(concatenate)到了其后每一层的输入上。在这篇论文中作者用High Order RNN结构(HORNN)把DenseNet和ResNet联系到了一起,证明了DenseNet能从靠前的层级中提取到新的特征,而ResNet本质上是对之前层级中已提取特征的复用。通过把这两种结构的优点结合到一起,就有了最新结构Dual Path Networks(DPN)。
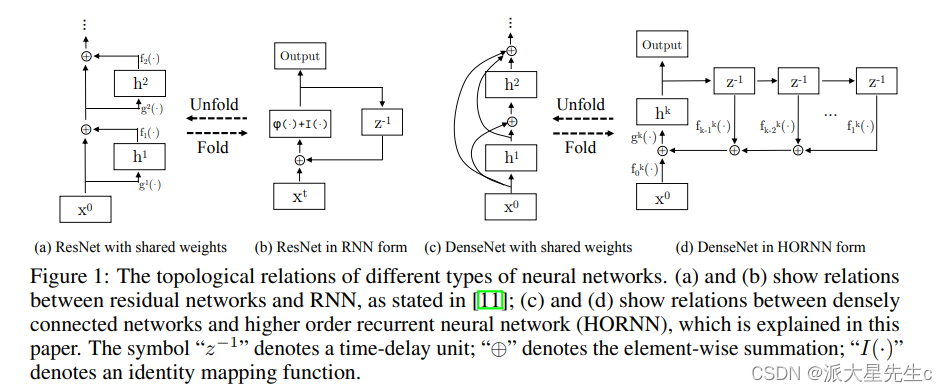
论文第二章、第三章详细介绍了DPN的理论基础,包含有较多的公式,简单而言就是借鉴了:
- resnet特征重用(因为前面特征被sum到了后面层上面)
- denseNet容易发现新特征(将前面特征均进行了concat组合)
Dual Path Architecture(DPA)以ResNet为主要框架,保证了特征的低冗余度,并在其基础上添加了一个非常小的DenseNet分支,用于生成新的特征。DPA的结构可以使用
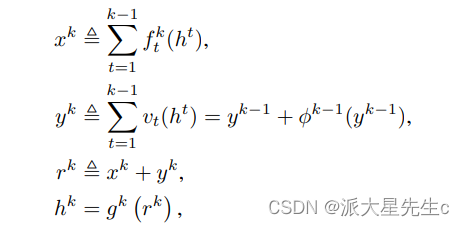
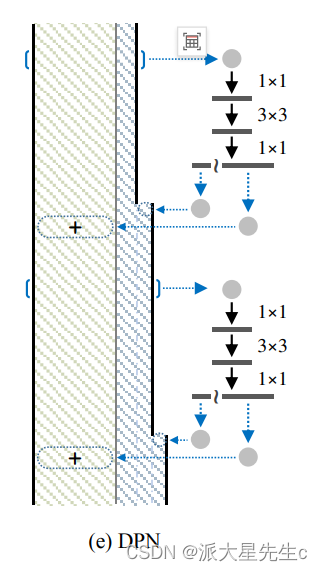
三、DPN代码复现
pytorch实现
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import OrderedDict
__all__ = ['DPN', 'dpn92', 'dpn98', 'dpn131', 'dpn107', 'dpns']
def dpn92(num_classes=1000):
return DPN(num_init_features=64, k_R=96, G=32, k_sec=(3,4,20,3), inc_sec=(16,32,24,128), num_classes=num_classes)
def dpn98(num_classes=1000):
return DPN(num_init_features=96, k_R=160, G=40, k_sec=(3,6,20,3), inc_sec=(16,32,32,128), num_classes=num_classes)
def dpn131(num_classes=1000):
return DPN(num_init_features=128, k_R=160, G=40, k_sec=(4,8,28,3), inc_sec=(16,32,32,128), num_classes=num_classes)
def dpn107(num_classes=1000):
return DPN(num_init_features=128, k_R=200, G=50, k_sec=(4,8,20,3), inc_sec=(20,64,64,128), num_classes=num_classes)
dpns = {
'dpn92': dpn92,
'dpn98': dpn98,
'dpn107': dpn107,
'dpn131': dpn131,
}
class DualPathBlock(nn.Module):
def __init__(self, in_chs, num_1x1_a, num_3x3_b, num_1x1_c, inc, G, _type='normal'):
super(DualPathBlock, self).__init__()
self.num_1x1_c = num_1x1_c
if _type is 'proj':
key_stride = 1
self.has_proj = True
if _type is 'down':
key_stride = 2
self.has_proj = True
if _type is 'normal':
key_stride = 1
self.has_proj = False
if self.has_proj:
self.c1x1_w = self.BN_ReLU_Conv(in_chs=in_chs, out_chs=num_1x1_c+2*inc, kernel_size=1, stride=key_stride)
self.layers = nn.Sequential(OrderedDict([
('c1x1_a', self.BN_ReLU_Conv(in_chs=in_chs, out_chs=num_1x1_a, kernel_size=1, stride=1)),
('c3x3_b', self.BN_ReLU_Conv(in_chs=num_1x1_a, out_chs=num_3x3_b, kernel_size=3, stride=key_stride, padding=1, groups=G)),
('c1x1_c', self.BN_ReLU_Conv(in_chs=num_3x3_b, out_chs=num_1x1_c+inc, kernel_size=1, stride=1)),
]))
def BN_ReLU_Conv(self, in_chs, out_chs, kernel_size, stride, padding=0, groups=1):
return nn.Sequential(OrderedDict([
('norm', nn.BatchNorm2d(in_chs)),
('relu', nn.ReLU(inplace=True)),
('conv', nn.Conv2d(in_chs, out_chs, kernel_size, stride, padding, groups=groups, bias=False)),
]))
def forward(self, x):
data_in = torch.cat(x, dim=1) if isinstance(x, list) else x
if self.has_proj:
data_o = self.c1x1_w(data_in)
data_o1 = data_o[:,:self.num_1x1_c,:,:]
data_o2 = data_o[:,self.num_1x1_c:,:,:]
else:
data_o1 = x[0]
data_o2 = x[1]
out = self.layers(data_in)
summ = data_o1 + out[:,:self.num_1x1_c,:,:]
dense = torch.cat([data_o2, out[:,self.num_1x1_c:,:,:]], dim=1)
return [summ, dense]
class DPN(nn.Module):
def __init__(self, num_init_features=64, k_R=96, G=32,
k_sec=(3, 4, 20, 3), inc_sec=(16,32,24,128), num_classes=1000):
super(DPN, self).__init__()
blocks = OrderedDict()
# conv1
blocks['conv1'] = nn.Sequential(
nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_init_features),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
# conv2
bw = 256
inc = inc_sec[0]
R = int((k_R*bw)/256)
blocks['conv2_1'] = DualPathBlock(num_init_features, R, R, bw, inc, G, 'proj')
in_chs = bw + 3 * inc
for i in range(2, k_sec[0]+1):
blocks['conv2_{}'.format(i)] = DualPathBlock(in_chs, R, R, bw, inc, G, 'normal')
in_chs += inc
# conv3
bw = 512
inc = inc_sec[1]
R = int((k_R*bw)/256)
blocks['conv3_1'] = DualPathBlock(in_chs, R, R, bw, inc, G, 'down')
in_chs = bw + 3 * inc
for i in range(2, k_sec[1]+1):
blocks['conv3_{}'.format(i)] = DualPathBlock(in_chs, R, R, bw, inc, G, 'normal')
in_chs += inc
# conv4
bw = 1024
inc = inc_sec[2]
R = int((k_R*bw)/256)
blocks['conv4_1'] = DualPathBlock(in_chs, R, R, bw, inc, G, 'down')
in_chs = bw + 3 * inc
for i in range(2, k_sec[2]+1):
blocks['conv4_{}'.format(i)] = DualPathBlock(in_chs, R, R, bw, inc, G, 'normal')
in_chs += inc
# conv5
bw = 2048
inc = inc_sec[3]
R = int((k_R*bw)/256)
blocks['conv5_1'] = DualPathBlock(in_chs, R, R, bw, inc, G, 'down')
in_chs = bw + 3 * inc
for i in range(2, k_sec[3]+1):
blocks['conv5_{}'.format(i)] = DualPathBlock(in_chs, R, R, bw, inc, G, 'normal')
in_chs += inc
self.features = nn.Sequential(blocks)
self.classifier = nn.Linear(in_chs, num_classes)
def forward(self, x):
features = torch.cat(self.features(x), dim=1)
out = F.avg_pool2d(features, kernel_size=7).view(features.size(0), -1)
out = self.classifier(out)
return out四、总结
DPN通过一系列非常精彩的推导分析出了ResNet和DenseNet各自的优缺点,通过将卷积网络抽象化为高层的RNN,得出了ResNet低冗余性的优点但是存在特征重用的缺点,也得出了DenseNet可以生成新特征的优点但是冗余度过高的问题,因此提出了结合ResNet和DenseNet的DPN。
DPN的结构并没有太复杂,通过Inception式的结构合并两种或者网络本质上是一种模型集成的方式,而DPN只是采用了ResNet和DenseNet的平均投票的方式仿佛过于简单了。基于模型集成的思想,我们也许可以从下面的几个角度进行进一步的优化:
- 采用更多种类的网络分支,例如加上SENet,NAS等等;
- 采用更好的集成方式,例如加上一个attention为不同的网络结构分支学习不同的权值,因为极有可能不用的网络结构在不同的深度起着不同的作用。