- 若文章内容或图片失效,请留言反馈。
- 部分素材来自网络,若不小心影响到您的利益,请联系博主删除。
- 写这篇博客旨在制作笔记,方便个人在线阅览,巩固知识,无其他用途。
学习视频:【黑马 Java 基础教程:Java-Stream 流从入门到精通】
吐槽:基础不牢,地动山摇 (查漏补缺)
【不可变集合】
1.不可变集合概述
不可变集合的特点
- 不可变集合定义完成后不可以修改,或者进行添加、删除的操作
创建不可变集合
- List、Set、Map 接口中都存在静态的 of() 方法,可以获取一个不可变的集合
- 注:这个 of() 方法在 JDK 9 版本才开始提供
三种集合使用 of() 创建不可变集合的细节
- List:List 是有序存储元素的,存储的元素内容是可重复的。可以直接用。
- Set:Set 存储的元素的内容是无序的,也是不可重复的。
- Map:Map 存储的元素是不可重复的,键值对数量最多是 10 个。
如果超过 10 个键值对(也就是超过了 20 个参数),就使用Map.ofEntries()(JDK 9 开始提供该方法)。
也可以使用Map.copyof()(JDK 10 开始提供该方法)来处理上述的情况。
HashMap 可以存储元素内容 null 的 key 和 value,可以有多个值为 null ,但只能有一个键是 null
2.List 方式
2.1.List.of()
创建一个不可变集合
List<String> list = List.of("张三", "李四", "王五", "赵六");
对不可变集合做出修改其内部元素的操作,都会报错:java.lang.UnsupportedOperationException
list.remove("李四");
list.add("孙七");
list.set(0, "陈二");
2.2.遍历 List 集合
此处顺带回顾 List 集合的三种遍历方式
- 增强 for 循环遍历
private static void ergodic_1(List<String> list) {
for (String s : list) {
System.out.print(s + "\t");
}
}
- 迭代器遍历
private static void ergodic_2(List<String> list) {
Iterator<String> listIterator = list.iterator();
while (listIterator.hasNext()) {
String s = listIterator.next();
System.out.print(s + "\t");
}
}
- 普通的 for 循环遍历
private static void ergodic_3(List<String> list) {
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.print(s + "\t");
}
}
使用上面的三种遍历方式,控制台输出信息都是如下所示
张三 李四 王五 赵六
3.Set 方式
3.1.Set.of()
创建不可变集合(Set 中每一个元素都是独一无二的,不可存在重复的元素)
Set<String> set = Set.of("张三", "李四", "王五", "赵六");
修改不可变集合内部元素的操作,都会导致控制台报错:java.lang.UnsupportedOperationException
set.remove("王五");
3.2.遍历 Set 集合
这里顺带回顾一下 Set 集合的遍历方式
- 增强 for 循环遍历
private static void ergodic_1(Set<String> set) {
for (String s : set) {
System.out.print(s + "\t");
}
}
- 迭代器遍历
private static void ergodic_2(Set<String> set) {
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
String next = iterator.next();
System.out.print(next + "\t");
}
}
遍历结果(无序)
赵六 张三 王五 李四
TreeSet 是有序的,是基于 TreeMap 的 NavigableSet 实现的。
可以认为TreeSet 和 TreeMap 都是基于红黑树实现的。
这些元素使用他们的自然排序或者在创建时提供的 Comparator 进行排序,具体取决于使用的构造函数。
4.Map 方式
4.1.Map.of()
修改不可变集合内部的元素,会报错:java.lang.UnsupportedOperationException
public class Immutable_MapDemo {
public static void main(String[] args) {
Map<String, String> map_1 = createMap_1();
map_1.remove("李四");
}
private static Map<String, String> createMap_1() {
return Map.of(
"张三", "北京",
"李四", "上海",
"王五", "广州",
"赵六", "深圳"
);
}
}
4.2.注意细节
- 细节一:Map 里的键是不可重复
- 细节二:Map 里面的 of 方法,参数是有上限的,最多只可传递 20 个参数(即 10 个键值对)
- 细节三:如果我们要传递多个键值对对象,它的数量大于 10 个,可以将键值对视为一个整体传递给 entries
键重复,在主方法中调用下面的方法会抛异常:java.lang.IllegalArgumentException: duplicate key: XXX
private static Map<String, String> createMap_2() {
return Map.of(
"张三", "北京",
"张三", "上海",
"王五", "广州",
"赵六", "深圳"
);
}
Map 里面的 of 方法,参数是有上限的,最多只可传递 10 个键值对
private static Map<String, String> createMap_3() {
return Map.of(
"刘一", "北京", "李二", "上海", "张三", "广州", "赵四", "深圳", "王五", "北京",
"赵六", "上海", "孙七", "广州", "周八", "深圳", "吴九", "北京", "郑十", "上海"
// 再添加一个[键值对],编译器就会报错了
);
}
如果我们要传递多个键值对对象,它的数量大于 10 个,可以将键值对视为一个整体传递给 entries
那么此时我们有这样的一个需求:一个方法可以接受多个键,多个值
解决方案:键和值都是可变参数,泛型方法(在传入的参数类型不确定的情况下)
public static <K, V> void of(K... keys, V... values) { } // 直接报错
然而这样的写法,会报错:Vararg parameter must be the last in the list
对于可变参数而言:在一个方法里,只能有一个形参是可变参数,而且必须写在最后
此时,我们便需要使用方法 Map.ofEntries() 了(JDK 9 开始提供该方法)
4.3.Map.ofEntries()
java/util/Map.offEntries()
@SafeVarargs // 该注解抑制编译器警告
static <K, V> Map<K, V> ofEntries(Map.Entry<? extends K, ? extends V>... entries) {
if (entries.length == 0) {
return ImmutableCollections.emptyMap();
} else if (entries.length == 1) {
return new Map1(entries[0].getKey(), entries[0].getValue());
} else {
Object[] kva = new Object[entries.length << 1];
int a = 0;
Map.Entry[] var3 = entries;
int var4 = entries.length;
for(int var5 = 0; var5 < var4; ++var5) {
Map.Entry<? extends K, ? extends V> entry = var3[var5];
kva[a++] = entry.getKey();
kva[a++] = entry.getValue();
}
return new MapN(kva);
}
}
4.3.1.基本使用
创建一个普通的 map 集合(HashMap)
private static HashMap<String, String> createHashMap() {
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("刘一", "北京");
hashMap.put("李二", "上海");
hashMap.put("张三", "广州");
hashMap.put("赵四", "深圳");
hashMap.put("王五", "天津");
hashMap.put("赵六", "重庆");
hashMap.put("孙七", "成都");
hashMap.put("周八", "贵州");
hashMap.put("吴九", "昆明");
hashMap.put("郑十", "南宁");
hashMap.put("Key_11", "Value_11");
return hashMap;
}
利用上面的数据来创建一个不可变的集合
private static void getImmutable_1() {
HashMap<String, String> hashMap = createHashMap();
Set<Map.Entry<String, String>> entries = hashMap.entrySet();
Map.Entry[] entries_1 = entries.toArray(new Map.Entry[0]);
Map map = Map.ofEntries(entries_1);
Set<Map.Entry<String, String>> entries_tmp = map.entrySet();
for (Map.Entry<String, String> entry : entries_tmp) {
System.out.println(entry); // 正常遍历。此处我就不贴遍历的信息了
}
}
修改不可变集合内部的元素,会报错:java.lang.UnsupportedOperationException
map.put("NewKey", "NewValue");
可以用链式编程的书写方法来简化上面的代码
Map<Object, Object> immutableMap_2 = Map.ofEntries(createHashMap().entrySet().toArray(new Map.Entry[0]));
4.3.2.理解 toArray(new Map.Entry[0])
关于 Map.Entry[] entries_1 = entries.toArray(new Map.Entry[0]); 这行代码我们可以理解为如下的情况
Map.Entry[] entries_a = new Map.Entry[0];
Map.Entry[] entries_b = entries.toArray(entries_a);
- toArray():把 entries 变成一个 object[] 数组
HashMap<String, String> hashMap = createHashMap();
Set<Map.Entry<String, String>> entries = hashMap.entrySet();
Object[] objects = entries.toArray();
我们的需求是获取指定类型的数组,这里我们用不到这个无参方法。
// 遍历对象数组:Object[]
System.out.println("entries.toArray():");
for (Object object : objects) {
System.out.println("\t" + object);
}
- toArray(T[] a):把 entries 变成一个数组,这个数组的类型是可以被指定的
HashMap<String, String> hashMap = createHashMap();
Set<Map.Entry<String, String>> entries = hashMap.entrySet();
Map.Entry[] arrays_a = new Map.Entry[0];
Map.Entry[] arrays_b = entries.toArray(arrays_a);
带参数的这个方法是符合我们的要求的,可以指定数组类型
注意:toArray 方法在底层会比较 [数组的长度] 与 [集合的长度] 二者的大小
[集合的长度] > [数组的长度]:数据在数组中放不下,此时会根据实际数据的个数重新创建数组[集合的长度] <= [数组的长度]:数据在数组中是放得下的,此时不会创建新的数组,直接用
private static void getImmutable_2() {
HashMap<String, String> hashMap = createHashMap();
Set<Map.Entry<String, String>> entries = hashMap.entrySet();
System.out.println("Map.Entry[].size():");
Map.Entry[] arrays1_1 = new Map.Entry[0];
Map.Entry[] arrays1_2 = entries.toArray(arrays1_1);
System.out.println("\t" + "Map.Entry[0].length:" + arrays1_2.length); // 11
Map.Entry[] arrays2_1 = new Map.Entry[20];
Map.Entry[] arrays2_2 = entries.toArray(arrays2_1);
System.out.println("\t" + "Map.Entry[20].length:" + arrays2_2.length); // 20
}
在主方法中调用上方代码块中的方法,运行 IDEA,控制台输出信息如下
Map.Entry[].size():
Map.Entry[0].length:11
Map.Entry[20].length:20
4.3.3.HashMap 注意事项
HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个
private static Map createMap_4() {
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("诸葛亮", "琅琊");
// 下面三个键值对,只会存入一个
hashMap.put("", "");
hashMap.put("", "杭州");
hashMap.put("", "南京");
hashMap.put("司马懿", "河内");
return hashMap;
}
在主方法中调用上方代码块中的方法,并遍历 Map 集合
public static void main(String[] args) {
Map map_4 = createMap_4();
Set<Map.Entry<String, String>> entries = map_4.entrySet();
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry);
}
}
控制台打印信息(显然,HashMap 存储的键值对是无序的,而且只能有一个键为 null 的键值对)
=南京
司马懿=河内
诸葛亮=琅琊
4.4.Map.copyof()
HashMap<String, String> hashMap = createHashMap();
Set<Map.Entry<String, String>> entries_0 = hashMap.entrySet();
Map.Entry[] entries_1 = entries_0.toArray(new Map.Entry[0]);
Map map = Map.ofEntries(entries_1);
简化上方的代码块(链式编程)
HashMap<String, String> hashMap = createHashMap();
Map<Object, Object> entries_2 = Map.ofEntries(hashMap.entrySet().toArray(new Map.Entry[0]));
此时再让我们看看 java/util/Map.copyOf() 中内部的情况,几乎与上方的简化代码如出一辙
static <K, V> Map<K, V> copyOf(Map<? extends K, ? extends V> map) {
return map instanceof AbstractImmutableMap ? map : ofEntries((Map.Entry[])map.entrySet().toArray(new Map.Entry[0]));
}
所以此时我们可以直接用这个 Map.copyOf() 来创建不可变集合(参数超过 20 个)
private static void getImmutable_4() {
HashMap<String, String> hashMap = createHashMap();
Map<String, String> immutableMap = Map.copyOf(hashMap);
}
修改不可变集合内部的元素,会报错:java.lang.UnsupportedOperationException
immutableMap.put("NewKey", "NewValue");
4.5.遍历 Map 集合
这里顺带回顾一下 Map 集合的遍历方式
第一种遍历方式
private static void ergodic_1(Map<String, String> map) {
Set<String> keys = map.keySet();
for (String key : keys) {
String value = map.get(key);
System.out.println(key + ":" + value);
}
}
第二种遍历方式
private static void ergodic_2(Map<String, String> map) {
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + ":" + value);
}
【Stream 流】
1.Stream 概述
- Stream 流的作用:结合了 Lambda 表达式,简化集合、数组的操作
- Stream 流的使用步骤:
- 先得到一条 Stream 流(流水线),并把数据放上去
- 利用 Stream 流中的 API 进行各种操作
- 使用 中间方法 对流水线上的数据进行操作
- 使用 终结方法 对流水线上的数据进行操作
2.获取 Stream 流
| 获取方式 | 方法名 | 说明 |
|---|---|---|
| 单列集合 | default Stream<E> stream() | Collection 中的默认方法 |
| 双列集合 | 无 | 无法直接使用 stream 流 |
| 数组 | public static <T> Stream<T> stream(T[] array) | Arrays 工具类中的静态方法 |
| 一堆零散数据 | public static <T> Stream<T> of(T... values) | Stream 接口中的静态方法 |
2.1.单列集合
创建一个单列集合
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "a", "b", "c", "d", "e");
可以采用内部类的方式来遍历
Stream<String> stream_1 = list.stream();
stream_1.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.print(s);
}
});
使用链式编程的书写方式更符合 Stream 流的思想
list.stream().forEach(s -> System.out.print(s));
还可以进一步简化上面一行的代码
list.stream().forEach(System.out::print);
打印结果
abcde
2.2.双列集合
创建一个双列集合
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("AAA", 111);
hashMap.put("BBB", 222);
hashMap.put("CCC", 333);
hashMap.put("DDD", 444);
hashMap.put("EEE", 555);
第一种遍历方式
hashMap.keySet().stream().forEach(s -> System.out.print(s));
打印结果
ABCDE
第二种遍历方式
hashMap.entrySet().stream().forEach(s-> System.out.println(s));
打印结果
A=111
B=222
C=333
D=444
E=555
2.3.数组
数组是基本数据类型
int[] array = {1, 2, 3, 4, 5, 6, 7, 8, 9};
Arrays.stream(array).forEach(s -> System.out.print(s));
数组是引用数据类型
String[] strings = {"a", "b", "c", "d"};
Arrays.stream(strings).forEach(s -> System.out.print(s));
2.4.一堆零散的数据
可以使用 Stream 流,但必须是同一类型
Stream.of(1, 2, 3, 4, 5).forEach(s -> System.out.println(s));
Stream.of("a", "b", "c", "d", "e").forEach(s -> System.out.println(s));
2.5.注意事项
public class StreamDemo_3S {
public static void main(String[] args) {
int[] ints = {1, 2, 3, 4};
Integer[] integers = {1, 2, 3, 4};
String[] strings = {"a", "b", "c", "d"};
System.out.println("================================");
Stream.of(ints).forEach(s -> System.out.print(s));
System.out.println("\n" + "================================");
Stream.of(integers).forEach(s -> System.out.print(s));
System.out.println("\n" + "================================");
Stream.of(strings).forEach(s -> System.out.print(s));
System.out.println("\n" + "================================");
}
}
输出结果
================================
[I@7ef20235
================================
1234
================================
abcd
================================
java/util/stream/Stream.java
static <T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
Stream 流的接口中的静态方法 of() 的细节:
- 该方法的形参是一个可变参数,可以传递一堆零散的数据,也可以传递数组。
- 数组一定要是引用类型才可以正常输出我们想要的值。
- 如果传递的数据是基本数据类型,则会把整个数组当成一个元素,放到 stream 中
3.Stream 流的中间方法
| 名称 | 说明 |
|---|---|
Stream<T> filter(Predicate<? super T> predicate) | 过滤 |
Stream<T> limit(long maxSize) | 获取前几个元素 |
Stream<T> skip(long n) | 跳过前几个元素 |
Stream<T> disitinct() | 元素去重,依赖(hashCode 和 equals 方法) |
static <T> Stream<T> concat(Stream a, Stream b) | 合并 a 和 b 两个流成为一个流 |
Stream<R> map(Function<T, R> mapper) | 转换流中的数据类型 |
3.1.filter()
Stream<T> filter(Predicate<? super T> predicate); // 对流中的数据进行过滤操作
Predicate<T> 接口中的泛型 T 是在流中,当前接收的数据类型
boolean test(T t);
Predicate 接口中有一个方法:boolean test(T t),其会对给定的参数进行判断,返回一个布尔值
- 若返回值为 true,则表示当前数据留下
- 若返回值为 false,则表示当前数据舍弃不要
创建一个数组
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌", "赵敏", "周芷若", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
为了便于理解,这里先使用内部类的方式对数据过滤
list.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return s.startsWith("张");
}
}).forEach(s -> System.out.println(s));
当然,一般更建议使用 链式编程 + Lambda 的书写方式来写 Stream 流(可以理解为 filter(参数 -> boolean 值))
list.stream().filter(s -> s.startsWith("张")).forEach(s -> System.out.println(s));
控制台打印信息
张无忌
张强
张三丰
张翠山
张良
java/util/function/Predicate.java 源码
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
default Predicate<T> negate() {
return (t) -> !test(t);
}
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
3.2.中间方法注意事项
注意事项
- 中间方法会返回新的 Stream 流,原来的流会被关闭。
这样一来,原来的 Stream 流只能使用一次,故建议使用链式编程 - 修改 Stream 流中的数据,不会影响原来集合或数组中的数据
3.2.1.注意-1
注意-1:中间方法会关闭之前的 Stream 流,返回新的 Stream 流。
创建一个数组
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌", "赵敏", "周芷若", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
创建完数组后,再过滤信息
Stream<String> stream_1 = list.stream().filter(s -> s.startsWith("张"));
Stream<String> stream_2 = stream_1.filter(s -> s.length() == 3);
Stream<String> stream_3 = stream_1.filter(s -> s.length() == 3);
控制台输出信息:显然,报错了(stream has already been operated upon or closed)
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.<init>(AbstractPipeline.java:203)
at java.util.stream.ReferencePipeline.<init>(ReferencePipeline.java:94)
at java.util.stream.ReferencePipeline$StatelessOp.<init>(ReferencePipeline.java:618)
at java.util.stream.ReferencePipeline$2.<init>(ReferencePipeline.java:163)
at java.util.stream.ReferencePipeline.filter(ReferencePipeline.java:162)
at org.example.test1.StreamDemo_6.method_2(StreamDemo_6.java:24)
at org.example.test1.StreamDemo_6.main(StreamDemo_6.java:15)
解决办法便是使用链式编程一步到位。为了便于阅读,一般会折行每行代码
list.stream()
.filter(s -> s.startsWith("张"))
.filter(s -> s.length() == 3)
.forEach(s -> System.out.println(s));
控制台输出信息(张姓,且名字的字数为三)
张无忌
张三丰
张翠山
3.2.2.注意-2
注意-2:修改 Stream 流中的数据,不会影响原来集合或数组中的数据
System.out.println("------------------------------------------------------------------------------------");
list.stream()
.filter(s -> s.startsWith("张"))
.filter(s -> s.length() == 3)
.forEach(s -> System.out.println(s));
System.out.println("------------------------------------------------------------------------------------");
System.out.println(list);
System.out.println("------------------------------------------------------------------------------------");
控制台输出信息(显然,原数组中的信息并没有受到影响)
------------------------------------------------------------------------------------
张无忌
张三丰
张翠山
------------------------------------------------------------------------------------
[张无忌, 赵敏, 周芷若, 张强, 张三丰, 张翠山, 张良, 王二麻子, 谢广坤]
------------------------------------------------------------------------------------
3.3.limit()
Stream<T> limit(long maxSize) // 返回此流中的元素组成的流,截取前指定参数个数的数据
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌", "赵敏", "周芷若", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
list.stream()
.limit(3)
.forEach(s -> System.out.print(s + " "));
控制台输出信息
张无忌 赵敏 周芷若
3.4.skip()
Stream<T> skip(long n) // 跳过指定参数个数的数据,返回由该流的剩余元素组成的流
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌", "赵敏", "周芷若", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
list.stream()
.skip(3)
.forEach(s -> System.out.print(s + " "));
控制台输出信息
张强 张三丰 张翠山 张良 王二麻子 谢广坤
3.5.distinct()
Stream<T> distinct() // 返回由该流的不同元素(根据 Object.equals(Object))组成的流,即去重
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌", "张无忌", "张无忌", "张无忌", "赵敏", "周芷若", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
list.stream().distinct().forEach(s -> System.out.print(s + " "));
输出结果
张无忌 赵敏 周芷若 张强 张三丰 张翠山 张良 王二麻子 谢广坤
3.6.concat()
static <T> Stream<T> concat(Stream a, Stream b) // 合并 a 和 b 两个流成为一个流
ArrayList<String> list_1 = new ArrayList<>();
Collections.addAll(list_1, "张无忌", "张无忌", "张无忌", "张无忌", "赵敏", "周芷若", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
ArrayList<String> list_2 = new ArrayList<>();
Collections.addAll(list_2, "周芷若", "赵敏", "小昭");
Stream.concat(list_1.stream(), list_2.stream()).forEach(s -> System.out.print(s + " "));
控制台输出信息
张无忌 张无忌 张无忌 张无忌 赵敏 周芷若 张强 张三丰 张翠山 张良 王二麻子 谢广坤 周芷若 赵敏 小昭
3.7.map()
Stream<R> map(Function<T, R> mapper) // 转换流中的数据类型,即 T -> R
Function<T, R>中的第一个参数 T:是流中原本的数据类型Function<T, R>中的第二个参数 R:是要转成的类型
R apply(T t);
Function<T, R> 接口中有一个方法:R apply(T t)
R apply(T t)中的形参 t:依次表示流里面的每一个数据R apply(T t)中的返回值:表示转换之后的数据R apply(T t)方法体的作用:接收一个 T 类型的参数,返回一个 R 类型的值
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌-15", "周芷若-14", "赵敏-13", "张强-20", "张三丰-100", "张翠山-40", "张良-35", "王二麻子-37");
需求:只获取里面的年龄,并进行打印
为了便于理解,这里先使用内部类的方式对数据进行操作
list.stream()
// Function<T, R> 中的第一个参数 T:流中原本的数据类型
// Function<T, R> 中的第二个参数 R:要转成的类型
.map(new Function<String, Integer>() {
// apply() 中的形参 s:依次表示流里面的每一个数据
// apply() 中的返回值:表示转换之后的数据
@Override
public Integer apply(String s) {
String[] arrays = s.split("-");
String ageString = arrays[1];
int age = Integer.parseInt(ageString);
return age;
}
}
).forEach(s -> System.out.print(s + " "));
Lambda 表达式方式(可以理解为 map(参数 -> 结果),这个结果可以由逻辑操作得出,比如类型转换)
list.stream()
.map(s -> Integer.parseInt(s.split("-")[1]))
.forEach(s -> System.out.print(s + " "));
控制台输出信息
15 14 13 20 100 40 35 37
java/util/function/Function.java 源码
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
static <T> Function<T, T> identity() {
return t -> t;
}
}
4.Stream 流的终结方法
| 名称 | 说明 |
|---|---|
void forEach(Consumer action) | 遍历 |
long count() | 统计 |
toArray() | 收集流中的数据,放到数组中 |
collect(Collector collector) | 收集流中的数据,放到集合中 |
4.1.forEach()
java/util/stream/Stream.java 中的 forEach 方法
void forEach(Consumer<? super T> var1); // 遍历流中的数据
Consumer<T> 接口中有一个方法:accept(T var1)
void accept(T var1);
Consumer<T>中的泛型:表示流中的数据类型Consumer<T>的accept(T var1)方法的形参 var1:依次表示流里的每一个数据
(类似于for(String s:strings)中的 s)Consumer<T>中的accept(T var1)方法体的作用:对每一个数据的处理操作(比如说:打印操作)
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌", "赵敏", "周芷若", "张强", "张三丰", "张翠山", "张良", "王二麻子", "谢广坤");
为了便于理解,这里先使用内部类的方式对数据进行操作
list.stream().forEach(
new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
}
);
Lambda 表达式方式(可以理解为 forEach(参数 -> void),可以做不返回结果的操作,比如打印操作)
list.stream().forEach(s -> System.out.println(s));
java/util/function/Consumer.java 源码
@FunctionalInterface
public interface Consumer<T> {
void accept(T var1);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (t) -> {
this.accept(t);
after.accept(t);
};
}
}
4.2.count()
long count() // 统计流中的数据的个数
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌-15", "周芷若-14", "赵敏-13", "张强-20", "张三丰-100", "张翠山-40", "张良-35", "王二麻子-37");
long count = list.stream().count();
System.out.println(count); // 输出结果:8
4.3.toArray()
toArray() // 收集流中的数据,放到数组中
Object[] toArray();:返回 Object[] 类型的数组<A> A[] toArray(IntFunction<A[]> generator);:返回指定类型的数组
在带参数的 toArray 方法中,有一个接口:IntFunction<R>
@FunctionalInterface
public interface IntFunction<R> {
R apply(int value);
}
IntFunction<R> 接口中的 R apply(int value); 和 Function<T, R> 接口中的 R apply(T t) 并没有什么区别。
只不过这次的返回类型就是 IntFunction<R> 接口中的唯一一个 R 类型。
- 对于
R apply(int value);这个抽象方法,可以理解为(参数) -> 结果。
说的再具体点的话就是:(参数) -> (一个有返回值的操作)。
结合 <A> A[] toArray(IntFunction<A[]> generator) 来看,即传入数据,对流中的数据逐个操作,并返回指定类型的数组,这个数组的长度也是要和流中的数据的个数相等的。
这么说或许有点小抽象,下面将结合例子具体分析。
创建一个数组
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌-15", "周芷若-14", "赵敏-13", "张强-20", "张三丰-100", "张翠山-40", "张良-35", "王二麻子-37");
Object[] toArray():返回 Object[] 类型的数组
Object[] array_1 = list.stream().toArray();
System.out.println(Arrays.toString(array_1));
<A> A[] toArray(IntFunction<A[]> generator);:返回指定类型的数组
内部类方式使用 toArray 方法
/*
* IntFunction 的泛型:具体类型的数组
*
* * apply() 的形参:流中数据的个数,要和数组的长度保持一致
* * apply() 中的返回值:具体类型的数组
* * apply() 方法体:创建数组
* *
* * toArray() 方法的参数的作用:负责创建一个指定类型的数组
* * toArray() 方法的底层,会依次得到流里面的每一个数据,并且把数据放到数组中
* * toArray() 方法的返回值:是一个装着流里面所有数据的数组
*/
String[] strings = list.stream().toArray(new IntFunction<String[]>() {
@Override
public String[] apply(int value) {
return new String[value];
}
});
System.out.println(Arrays.toString(strings));
Lambda 表达式方式使用 toArray 方法
(可以理解为 toArray(参数 -> 一个返回结果是数组的操作),这个操作是对流中的数据一对一操作的)
String[] strings = list.stream().toArray(value -> new String[value]);
System.out.println(Arrays.toString(strings));
4.4.collect()
java/util/stream/Stream.java 中的 collect() 方法之一
<R, A> R collect(Collector<? super T, A, R> collector);
collect(Collector collector) 中的这个 Collector 也是一个接口
这里贴一下 Collector 接口的内部结构图(JDK 11 版本)
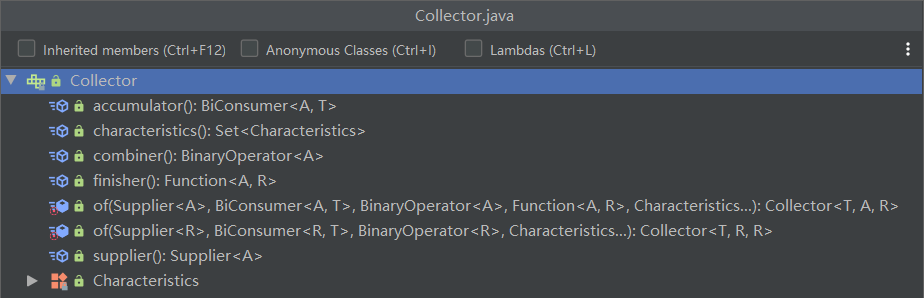
public static<T>Collectors toList():把元素收集到 List 集合中public static<T>Collectors toSet():把元素收集到 Set 集合中public static Collectors toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends K> valueMapper)
把元素收集到 Map 集合中
先创建一个 List 集合
public class StreamDemo_9_2 {
public static void main(String[] args) {
List<String> list = createList();
// collectToList(list);
// collectToSet(list);
// collectToMap_1(list);
// collectToMap_2(list);
}
private static List<String> createList() {
List<String> list = new ArrayList<>();
Collections.addAll(list,
"张无忌1-男-15", "张无忌2-男-15", "周芷若-女-14", "赵敏-女-13", "张强-男-20",
"张三丰-男-100", "张翠山-男-40", "张良-男-35", "王二麻子-男-37", "谢广坤-男-41");
return list;
}
}
4.4.1.toList()
private static void collectToList(List<String> list) {
// 收集 List 集合中的所有男性
List<String> newList = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toList());
System.out.println(newList);
}
4.4.2.toSet()
private static void collectToSet(List<String> list) {
Set<String> newSet = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toSet());
System.out.println(newSet);
}
4.4.3.toMap()
在 Map 集合中,一定指明谁作为键,谁作为值。这里我指定姓名为键,年龄为值
toMap(Function<T, K> keyMapper, Function<T, K> valueMapper)
参数一 keyMapper 表示键的生成规则,参数二 valueMapper 表示值的生成规则
java/util/function/Function.java
public interface Function<T, R> {
R apply(T t); // 这是一个抽象方法,简单描述就是接收 T 类型的数据,返回 R 类型的数据
// 省略
}
toMap(Function<T, K> keyMapper, Function<T, K> valueMapper)- 参数一
Function<? super T, ? extends K> keyMapper- 第一个泛型 T,表示流中的每一个数据的类型
- 第二个泛型 K,表示 Map 集合中的数据类型
R apply(T t)- 形参:表示流里面的每一个数据
- 方法体功能:生成键的代码(
- 返回值:已经生成好的键
- 参数二
Function<? super T, ? extends K> valueMapper- 第一个泛型 T,表示流中的每一个数据的类型
- 第二个泛型 K,表示 Map 集合中的数据类型
R apply(T t)- 形参:表示流里面的每一个数据
- 方法体功能:生成值的代码
- 返回值:已经生成好的值
内部类方式书写 toMap()
private static void collectToMap_1(List<String> list) {
Map<String, Integer> map = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toMap(
new Function<String, String>() {
@Override
public String apply(String s) {
return s.split("-")[0];
}
},
new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s.split("-")[2]);
}
}
));
System.out.println(map);
}
Lambda 方式书写 toMap()
private static void collectToMap_2(List<String> list) {
Map<String, Integer> map = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toMap(
s -> s.split("-")[0],
s -> Integer.parseInt(s.split("-")[2])
));
System.out.println(map);
}
5.总结
Stream 流的作用
- 结合了 Lambda 表达式,简化集合、数组的操作
Stream 的使用步骤
- 获取 Stream 流对象
- 使用中间方法处理数据
- 使用终结方法处理数据
如何获取 Stream 流对象
- 单例集合:Collection 中的默认方法 stream
- 双列集合:不能直接获取
- 数组:Arrays 工具类型中的静态方法 stream
- 一堆零散的数据:Stream 接口中的静态方法 of
常用方法
- 中间方法:filter、limit、skip、distinct、concat、map
- 终结方法:forEach、count、collect
6.练习
6.1.数字过滤
定义一个集合,并添加一些整数:1、2、3、4、5、6、7、8、9、10
过滤奇数,只留下偶数,并且需要将集合保存起来
public class Practice_1 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
Collections.addAll(list, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> collect = list.stream().filter(s -> s % 2 == 0).collect(Collectors.toList());
System.out.println(collect);
}
}
控制台输出信息
[2, 4, 6, 8, 10]
6.2.字符串过滤并收集
创建一个 ArrayList 集合,并添加以下字符串,字符串的前面是姓名,后面是年龄
"zhangsan,23"
"lisi,24"
"wangwu,25"
保留年龄大于等于 24 岁的人,并将结果收集到 Map 集合中,以姓名为键,以年龄为值。
public class Practice_2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "zhangsan,23", "lisi,24", "wangwu,25");
Map<String, Integer> collect = list.stream()
.filter(s -> Integer.parseInt(s.split(",")[1]) >= 24)
.collect(Collectors.toMap(
s -> s.split(",")[0],
s -> Integer.parseInt(s.split(",")[1])
));
System.out.println(collect);
}
}
控制台输出
{lisi=24, wangwu=25}
6.3.自定义对象过滤并收集
现在有两个 ArrayList 集合
- 第一个集合中:存储 6 名男演员的名字和年龄。
- 第二个集合中:存储 6 名女演员的名字和年龄。
要求完成如下的操作
- 男演员只要名字为 3 个字的前两人
- 女演员只要姓杨的,并且不要第一个
- 把过滤后的男演员姓名和女演员姓名合并到一起
- 将上一步的演员信息封装成 Actor 对象
- 将所有的演员对象都保存到 List 集合中。
备注:演员类 Actor,其属性有 name 和 age
Actor 类
public class Actor {
private String name;
private int age;
public Actor() {
}
public Actor(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
测试类
public class Practice_3 {
public static void main(String[] args) {
ArrayList<String> manList = new ArrayList<>();
ArrayList<String> womanList = new ArrayList<>();
Collections.addAll(manList, "蔡坤坤,24", "叶齁贤,23", "刘不甜,22", "吴签,24", "谷嘉,30", "肖梁梁,27");
Collections.addAll(womanList, "赵小颖,35", "杨莹,36", "高元元,43", "张天天,31", "刘诗,35", "杨小幂,33");
// 需求 1:男演员只要名字为 3 个字的前两人
Stream<String> manStream = manList.stream()
.filter(s -> s.split(",")[0].length() == 3)
.limit(2);
// 需求 2:女演员只要姓杨的,并且不要第一个
Stream<String> womanStream = womanList.stream()
.filter(s -> s.split(",")[0].startsWith("杨"))
.skip(1);
// 需求 3:把过滤后的男演员姓名和女演员姓名合并到一起
// 需求 4:将上一步的演员信息封装成 Actor 对象
// 需求 5:将所有的演员对象都保存到 List 集合中
List<Actor> collect = Stream.concat(manStream, womanStream)
.map(s -> new Actor(s.split(",")[0], Integer.parseInt(s.split(",")[1])))
.collect(Collectors.toList());
System.out.println(collect);
}
}
控制台输出信息
[Actor{name='蔡坤坤', age=24}, Actor{name='叶齁贤', age=23}, Actor{name='杨小幂', age=33}]