目录
一,问题表现
二、没有技术含量的解决方案
三、本人彻底的解决方案
简要说明
贴代码
思路解析
思路
一,问题表现
示例代码如下:
[Serializable]
public class NodeTest
{
public NodeTest ()
{
new List<NodeTest> ();
}
public string Name { get; set; }
public NodeTest Parent { get; set; }
public List<NodeTest> Children { get; set; }
}
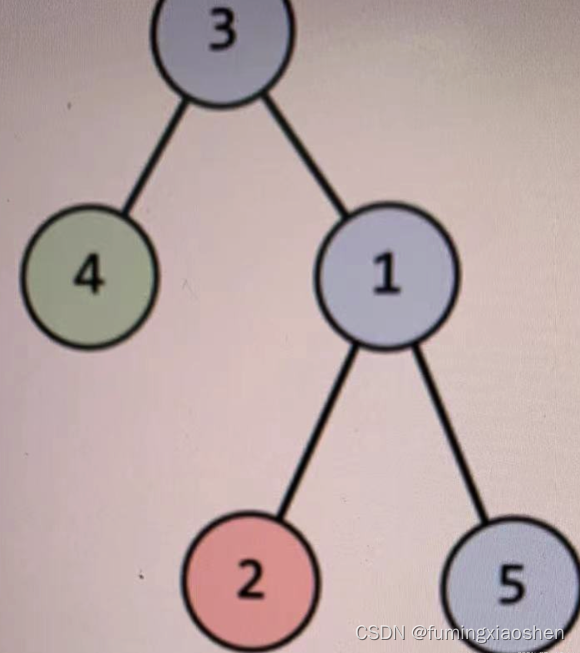
先看错误地方,以上这个类要是序列化就会遇到,"序列化类型 Test.NodeTest 的对象时检测到循环引用。"错误。
二、没有技术含量的解决方案
网上一搜,几乎到处都是这两种解决方案:
- 使用NewtonSoft.Json,然后使用序列方法,加上设置 ReferenceLoopHandling = Newtonsoft.Json.ReferenceLoopHandling.Ignore
- 直接在循环错误属性上加XmlIgnore特性。
NodeTest nd = new NodeTest ();
nd.Name = "root";
NodeTest nd1 = new NodeTest ();
nd1.Name = "child1";
nd1.Parent = nd;
NodeTest nd2 = new NodeTest ();
nd2.Name = "child2";
nd2.Parent = nd;
nd.Children.Add ( nd1 );
nd.Children.Add ( nd2 );上面的实例,采用第一种方法序列化是这结果:

采用第二种是以下结果。
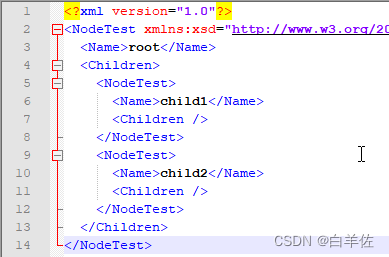
由此可见这两种方法简单,粗暴,没有一点技术含量。这么说是因为,直接忽略了其父子关系。反序列化成对象后Parent属性为空,如果需要逆向查找父对象时,完全行不通。
三、本人彻底的解决方案
-
简要说明
首先将例中NodeTest对象进行改装,让它继承自 IXmlSerializable 接口并实现,为的就是在序列化和反序列化时,可以自由控制以达到序列化时能包含父节点信息。其次是对他的属性Children进行改造,这很重要,如果继续使用List列表,会出现其他问题,这个后续会提到。
-
贴代码
现不废话,贴代码,代码看完,看后文解析,应该很容易明白,NodeTest 类:
[Serializable]
public class NodeTest : IXmlSerializable
{
internal const string ROOT = "NodeTest";
internal const string NAME = "Name";
internal const string PARENT = "Parent";
internal const string ELEMENT_EXISTMARK = "ExistMark";
internal const string ELEMENT_EXIST = "Exist";
internal const string ELEMENT_NOTEXIST = "NotExist";
public NodeTest ()
{
Children = new NodeTestCollection ();
}
public string Name { get; set; }
public NodeTest Parent { get; set; }
[XmlArray ()]
public NodeTestCollection/*List<NodeTest>*/ Children { get; set; }
public System.Xml.Schema.XmlSchema GetSchema ()
{
return null;
}
public static void ResetSerializationStatus ()
{
_dicAllNodes.Clear ();
}
private static Dictionary<string, NodeTest> _dicAllNodes= new Dictionary<string, NodeTest> ();
public void ReadXml ( System.Xml.XmlReader reader )
{
XmlSerializer xmlSer = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTest ) } )[ 0 ];
if ( reader.IsEmptyElement ) return;
while ( reader.NodeType != System.Xml.XmlNodeType.EndElement )
{
reader.ReadStartElement ( ROOT );
reader.ReadStartElement ( NAME );
this.Name = reader.ReadString ();
reader.ReadEndElement ();
reader.MoveToContent ();
string sExistMark = ELEMENT_NOTEXIST;
if ( reader.MoveToAttribute ( ELEMENT_EXISTMARK ) )
{
sExistMark = reader.GetAttribute ( ELEMENT_EXISTMARK );
}
reader.ReadStartElement ( PARENT );
switch ( sExistMark )
{
case ELEMENT_EXIST:
reader.ReadStartElement ( NAME );
Parent = new NodeTest ();
Parent.Name = reader.ReadString ();
reader.ReadEndElement ();
reader.ReadEndElement ();
break;
default:
break;
}
XmlSerializer xmlSer2 = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTestCollection ) } )[ 0 ];
Children = ( NodeTestCollection )xmlSer2.Deserialize ( reader );
if ( Children.Count != 0 )
{
reader.ReadEndElement ();
}
_dicAllNodes.Add ( this.Name, this );
}
for ( int i = 0 ; i < Children.Count ; i++ )
{
var child = Children[ i ];
if ( child.Parent != null )
{
child.Parent = _dicAllNodes[ child.Parent.Name ];
}
}
}
public void WriteXml ( System.Xml.XmlWriter writer )
{
XmlSerializer xmlSer = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTest ) } )[ 0 ];
writer.WriteStartElement ( NAME );
writer.WriteString ( this.Name );
writer.WriteEndElement ();
writer.WriteStartElement ( PARENT );
if ( Parent != null )
{
writer.WriteAttributeString ( ELEMENT_EXISTMARK, ELEMENT_EXIST );
writer.WriteStartElement ( NAME );
writer.WriteString ( Parent.Name );
writer.WriteEndElement ();
}
else
{
writer.WriteAttributeString ( ELEMENT_EXISTMARK, ELEMENT_NOTEXIST );
}
writer.WriteEndElement ();
writer.Flush ();
XmlSerializer xmlSer2 = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTestCollection ) } )[ 0 ];
xmlSer2.Serialize ( writer, this.Children );
writer.Flush ();
writer.Flush ();
}
}
List<NodeTest>改成NodeTestCollection,解决序列化时结构错乱问题(本来打算细说的,算了,懒得打字了,看客自己试试就知道了),此改动,还很利于后续的优化扩展,比如名字索引等,实现如下:
[Serializable]
[XmlRoot(ElementName = "Children" )]
public class NodeTestCollection : IList<NodeTest>, IXmlSerializable
{
private const string ROOT = "Children";
private const string CHILDCOUNT = "ChildCount";
#region 继承实现自IList<NodeTest>
private IList<NodeTest> m_lstNodes = new List<NodeTest> ();
public int IndexOf ( NodeTest item )
{
int iIdx = -1;
for ( int i = 0 ; i < m_lstNodes.Count ; i++ )
{
if ( m_lstNodes[ i ] == item )
{
iIdx = i;
break;
}
}
return iIdx;
}
public void Insert ( int index, NodeTest item )
{
m_lstNodes.Insert ( index, item );
}
[XmlElement ( "NodeTest", Type = typeof ( NodeTest ) )]
public NodeTest this[ int index ]
{
get
{
return m_lstNodes[ index ];
}
set
{
m_lstNodes[ index ] = value;
}
}
public void Add ( NodeTest item )
{
m_lstNodes.Add ( item );
}
public bool Contains ( NodeTest item )
{
return m_lstNodes.Contains ( item );
}
public void CopyTo ( NodeTest[ ] array, int arrayIndex )
{
m_lstNodes.CopyTo ( array, arrayIndex );
}
public bool Remove ( NodeTest item )
{
return m_lstNodes.Remove ( item );
}
IEnumerator<NodeTest> IEnumerable<NodeTest>.GetEnumerator ()
{
return m_lstNodes.GetEnumerator ();
}
public void RemoveAt ( int index )
{
m_lstNodes.RemoveAt ( index );
}
public void Clear ()
{
m_lstNodes.Clear ();
}
public int Count
{
get { return m_lstNodes.Count; }
}
public bool IsReadOnly
{
get { return false; }
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator ()
{
return m_lstNodes.GetEnumerator ();
}
#endregion
public System.Xml.Schema.XmlSchema GetSchema ()
{
return null;
}
public void ReadXml ( System.Xml.XmlReader reader )
{
//if ( reader.IsEmptyElement ) return;
int iChildCount = 0;
if ( reader.MoveToAttribute ( CHILDCOUNT ) ) iChildCount = int.Parse ( reader.GetAttribute ( CHILDCOUNT ) );
reader.ReadStartElement ( ROOT );
if (iChildCount > 0)
{
XmlSerializer xmlSer = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTest ) } )[ 0 ];
for ( int i = 0 ; i < iChildCount ; i++ )
{
var readerSub = reader.ReadSubtree();
this.Add ( ( NodeTest )xmlSer.Deserialize ( readerSub ) );
reader.ReadEndElement ();
}
}
}
public void WriteXml ( System.Xml.XmlWriter writer )
{
int iCnt = this.Count;
writer.WriteAttributeString ( CHILDCOUNT, iCnt.ToString () );
XmlSerializer xmlSer = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTest ) } )[ 0 ];
for ( int i = 0 ; i < iCnt ; i++ )
{
xmlSer.Serialize ( writer, this[ i ] );
}
}
}
-
思路解析
说说思路:改造的地方不多,主要是继承方法的实现上,也就是ReadXml 和WriteXml方法实现上。在实现它们时,采用一点手段,在方法体类对循环引用的对象进行区别处理。
思路
原理很简单,循环引用的地方,在本例中即Parent对象,采用简单存储,存储一个指引信息,这里为图简洁,直接使用Name属性作为指引【后续各位观众具体使用是可以使用唯一标识符进行优化,在此我就不改了】。将所有NodeTest对象信息存为字典,在反序列化时使用指引进行挂接,因为这是class,是引用对象,简单一改,全部挂接完成,挂接处就是For循环处。
此外还有两处XmlAttribute——ExistMark和ChildCount,分别用来辅助Parent存在时检测以及子节点存在检测。
采用这个方法,序列化出来如下图:
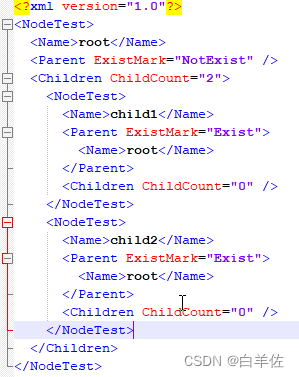
反序列化也成功进行挂接,不信,你试试。
原理就这么简单。
不懂就留言吧。