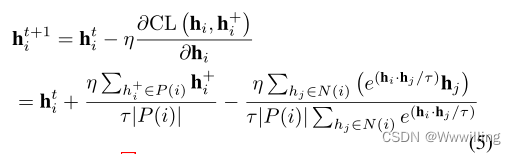决策树(理论)
目录
- 一、何为决策树
- 1、决策树的组成
- 2、决策树的构建
- 二、熵
- 1、熵的作用
- 2、熵的定义
- 3、熵的计算
- 4、条件熵的引入
- 5、条件熵的计算
- 三、划分选择
- 1、信息增益( ID3 算法选用的评估标准)
- 2、信息增益率( C4.5 算法选用的评估标准)
- 3、基尼系数( CART 算法选用的评估标准)
- 4、基尼增益
- 5、基尼增益率
- 四、决策树中的连续值处理
- 五、决策树中的预剪枝处理(正则化)
- 1、限制决策树的深度
- 2、限制决策树中叶子结点的个数
- 3、限制决策树中叶子结点包含的样本个数
- 4、限制决策树的最低信息增益
- 六、决策树中的后剪枝处理
- 七、实战部分
一、何为决策树
决策树(Decision Tree)是一种分类和回归方法,是基于各种情况发生的所需条件构成决策树,以实现期望最大化的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。它的运行机制非常通俗易懂,因此被誉为机器学习中,最“友好”的算法。下面通过一个简单的例子来阐述它的执行流程。假设根据大量数据,含 3 个指标:天气、温度、风速,构建了一棵“可预测学校会不会举办运动会”的决策树(如右图所示)。
接下来,当我们拿到某个数据时,就能做出对应预测:

在对任意数据进行预测时,都需要从决策树的根结点开始,一步步走到叶子结点(执行决策的过程)。如,对上表中的第一条数据( [ 阴天,寒冷,强 ] ):首先从根结点出发,判断“天气”取值,而该数据的“天气”属性取值为“阴天”,从决策树可知,此时可直接输出决策结果为“举行”。这时,无论其他属性取值为什么,都不需要再执行任何决策(类似于“短路”现象)。

1、决策树的组成
决策树由结点和有向边组成。结点有两种类型:内部结点(圆)和叶结点(矩形)。其中,内部结点表示一个特征(属性);叶结点表示一个类别。而有向边则对应其所属内部结点的可选项(属性的取值范围)。

在用决策树进行分类时,首先从根结点出发,对实例在该结点的对应属性进行测试,接着会根据测试结果,将实例分配到其子结点;然后,在子结点继续执行这一流程,如此递归地对实例进行测试并分配,直至到达叶结点;最终,该实例将被分类到叶结点所指示的结果中。
在决策树中,若把每个内部结点视为一个条件,每对结点之间的有向边视为一个选项,则从根结点到叶结点的每一条路径都可以看做是一个规则,而叶结点则对应着在指定规则下的结论。这样的规则具有互斥性和完备性,从根结点到叶结点的每一条路径代表了一类实例,并且这个实例只能在这条路径上。从这个角度来看,决策树相当于是一个 if-then 的规则集合,因此它具
有非常好的可解释性(白盒模型),这也是为什么说它是机器学习算法中最“友好”的一个原因。
2、决策树的构建
前面介绍了决策树的相关概念,接下来讨论如何构建一棵决策树。
决策树的本质是从训练集中归纳出一套分类规则,使其尽量符合以下要求:
- 具有较好的泛化能力;
- 在 1 的基础上尽量不出现过拟合现象。
注意到一件事:当目标数据的特征较多时,构建的具有不同规则的决策树也相当庞大(成长复杂度为 𝑂(𝑛!) )。如当仅考虑 5 个特征时,就能构建出 5×4×3×2×1=120 种。在这么多树中,选择哪一棵才能达到最好的分类效果呢?实际上,这个问题的本质是:应该将样本数据的特征按照怎样的顺序添加到一颗决策树的各级结点中?这便是构建决策树所需要关注的问题核心。
如,在前面的例子中,为什么要先对“天气”进行划分,然后再是“温度”和“风速”呢(下图1)?可不可以先对“风速”进行划分,然后再是“温度”和“天气”呢(下图2)?

一种很直观的思路是:如果按照某个特征对数据进行划分时,它能最大程度地将原本混乱的结果尽可能划分为几个有序的大类,则就应该先以这个特征为决策树中的根结点。接着,不断重复这一过程,直到整棵决策树被构建完成为止。
基于此,引入信息论中的“熵”。
二、熵
1、熵的作用
熵(Entropy)是表示随机变量不确定性的度量。说简单点就是物体内部的混乱程度。比如下边的两幅图中,从 图1 到 图2 表示了熵增的过程。对于决策树的某个结点而言,它在对样本数据进行分类后,我们当然希望分类后的结果能使得整个样本集在各自的类别中尽可能有序,即希望某个特征在被用于分类后,能最大程度地降低样本数据的熵。

现在假设有这样一个待分类数据(如下图所示),若分类器 1 选择特征 𝑥1、分类器 2 选择特征 𝑥2 分别为根构建了一棵决策树,其效果如下:

则根据以上结果,可以很直观地认为,决策树 2 的分类效果优于决策树 1 。从熵的角度看,决策树 2 在通过特征 𝑥2 进行分类后,整个样本被划分为两个分别有序的类簇;而决策树 1 在通过特征 𝑥1 进行分类后,得到的分类结果依然混乱(甚至有熵增的情况),因此这个特征在现阶段被认为是无效特征。
2、熵的定义
故此,可以这样认为:构建决策树的实质是对特征进行层次选择,而衡量特征选择的合理性指标,则是熵。为便于说明,下面先给出熵的定义:设 𝑋 是取值在有限范围内的一个离散随机变量,其概率密度为:
P ( X = x i ) = p i , i = 1 , 2 , … , n P(X=x_i)=p_i \ , \ i=1,2,…,n P(X=xi)=pi , i=1,2,…,n
下图展示了有关 𝑝 𝑖 𝑝_𝑖 pi 与 k k k 的定义(其中,𝑘 是该集合中元素的类别数):

则随机变量 𝑋 的熵定义为
H ( X ) = − ∑ i = 1 k p i log p i H(X)=-\sum_{i=1}^kp_i \ \text{log} \ p_i H(X)=−i=1∑kpi log pi
从该式的定义可以看出,熵仅仅依赖于 𝑋 的分布而与其取值无关,所以也可以将 𝑋 的熵记为 𝐻(𝑝) 。
由于随机变量 𝑋 的概率密度
𝑝
𝑖
∈
[
0
,
1
]
𝑝_𝑖 ∈ [0, 1]
pi∈[0,1] ,因此
log
𝑝
𝑖
∈
(
−
∞
,
0
]
\text{log}\ 𝑝_𝑖 ∈ (−∞, 0]
log pi∈(−∞,0] 。此时,若在
log
𝑝
𝑖
\text{log}\ 𝑝_𝑖
log pi 前加上负号,就有
−
log
𝑝
𝑖
∈
[
0
,
∞
)
-\text{log}\ 𝑝_𝑖 ∈ [0,∞)
−log pi∈[0,∞) 。所以,
H
(
X
)
=
−
∑
i
=
1
k
p
i
log
p
i
∈
[
0
,
∞
)
H(X)=-\sum_{i=1}^kp_i \ \text{log} \ p_i∈ [0,∞)
H(X)=−∑i=1kpi log pi∈[0,∞) 。当某个集合含有多个类别时,此时 𝑘 较大, 𝑝𝑖 的数量过多;且整体的 𝑝𝑖 都会因 𝑘 的过大而普遍较小,从而使得 𝐻(X) 的值过大。这正好符合“熵值越大,事物越混乱”的定义。

3、熵的计算
例如,现在有两个集合:𝐴 = { 1,2 } , 𝐵 = { 1,2,3,4,5,6 } ,若以这两个集合为取值空间,则可分别计算其熵。
对于集合 𝐴 ,先计算其分布列为:

于是可得到其熵为:
H ( X A ) = − ∑ i = 1 2 p i log p i = − ( 1 2 × log 1 2 + 1 2 × log 1 2 ) = − log 1 2 = log 2 ≈ 0.69 \begin{aligned} H(X_A) &= -\sum_{i=1}^2p_i \ \text{log} \ p_i \\ &= -(\frac12× \text{log} \frac12 + \frac12× \text{log} \frac12) = -\text{log} \frac12 \\ &= \text{log} \ 2 \\ &≈ 0.69 \\ \end{aligned} H(XA)=−i=1∑2pi log pi=−(21×log21+21×log21)=−log21=log 2≈0.69
对于集合 𝐵 ,计算其分布列为:

于是可得到其熵为:
H ( X B ) = − ∑ i = 1 6 p i log p i = − ( 1 6 × log 1 6 + 1 6 × log 1 6 + 1 6 × log 1 6 + 1 6 × log 1 6 + 1 6 × log 1 6 + 1 6 × log 1 6 ) = − log 1 2 = log 2 ≈ 0.69 \begin{aligned} H(X_B) &= -\sum_{i=1}^6p_i \ \text{log} \ p_i \\ &= -(\frac16× \text{log} \frac16 + \frac16× \text{log} \frac16 + \frac16× \text{log} \frac16 + \frac16× \text{log} \frac16 + \frac16× \text{log} \frac16 + \frac16× \text{log} \frac16) \\ &= -\text{log} \frac12 \\ &= \text{log} \ 2 \\ &≈ 0.69 \end{aligned} H(XB)=−i=1∑6pi log pi=−(61×log61+61×log61+61×log61+61×log61+61×log61+61×log61)=−log21=log 2≈0.69
结果显示,𝐴 集合的熵值要低一些,从两个集合的内容也能很轻易看出: 𝐴 集合只有两种类别,相对稳定;而 𝐵 集合中的类别过多,显得混乱。从另一个角度看:若视集合 𝐴 为“抛 1 次硬币的结果”;视集合 𝐵 为“掷 1 次骰子的结果”,则显然掷骰子的不确定性比投硬币的不确定性要高。
取极端情况,当集合中仅有一类元素时,如 𝐶 = { 1,1,1,1,1,1 } 时,此时其分布列为:

其熵为:
H ( X B ) = − ∑ i = 1 1 p i log p i = − ( 1 × log 1 ) = 0 \begin{aligned} H(X_B) &= -\sum_{i=1}^1p_i \ \text{log} \ p_i \\ &= -(1 × \text{log} 1) \\ &= 0 \end{aligned} H(XB)=−i=1∑1pi log pi=−(1×log1)=0
取到最小值,即表明当前集合状态不混乱,非常有序。
4、条件熵的引入
根据熵的定义,在构建决策树时我们可采用一种很简单的思路来进行“熵减”:每当要选出一个内部结点时,考虑样本中的所有“尚未被使用”特征,并基于该特征的取值对样本数据进行划分。即有:

对于每个特征,都可以算出“该特征各项取值对运动会举办与否”的影响(而衡量各特征谁最合适的准则,即是熵)。为此,引入条件熵。首先看原始数据集 𝐷 (共14天)的熵,该数据的标签只有两个(“举办”与“不举办”),且各占一半,故可算出该数据集的初始熵为:
H ( X B ) = − ∑ i = 1 2 p i log p i = − ( 1 2 × log 1 2 + 1 2 × log 1 2 ) = − log 1 2 = log 2 ≈ 0.6931 \begin{aligned} H(X_B) &= -\sum_{i=1}^2p_i \ \text{log} \ p_i \\ &= -(\frac12 ×\text{log} \ \frac12 + \frac12 ×\text{log} \ \frac12) \\ &= -\text{log} \ \frac12 \\ &= \text{log} 2 \\ &≈ 0.6931 \end{aligned} H(XB)=−i=1∑2pi log pi=−(21×log 21+21×log 21)=−log 21=log2≈0.6931
对于每个特征,我们逐个分析,先从“天气”开始:

- 天气 = “晴天” 时,归类集合的熵为 H ( X A ) = − ∑ i = 1 2 p i log = − ( 4 8 × log 4 8 + 4 8 × log 4 8 ) = − log 1 2 ≈ 0.6931 H(X_A)=-\sum_{i=1}^2p_i \ \text{log}=-(\frac48 ×\text{log} \ \frac48 + \frac48 ×\text{log} \ \frac48)= -\text{log} \ \frac12≈ 0.6931 H(XA)=−∑i=12pi log=−(84×log 84+84×log 84)=−log 21≈0.6931 ;
- 天气 = “阴天” 时,归类集合的熵为 H ( X B ) = − ∑ i = 1 2 p i log = − ( 1 × log 1 + 0 × log 0 ) = 0 H(X_B)=-\sum_{i=1}^2p_i \ \text{log}=-(1 ×\text{log} \ 1 + 0 ×\text{log} \ 0)= 0 H(XB)=−∑i=12pi log=−(1×log 1+0×log 0)=0;
- 天气 = “雨天” 时,归类集合的熵为 H ( X C ) = − ∑ i = 1 2 p i log = − ( 0 × log 0 + 1 × log 1 ) = 0 H(X_C)=-\sum_{i=1}^2p_i \ \text{log}=-(0 ×\text{log} \ 0 + 1 ×\text{log} \ 1)= 0 H(XC)=−∑i=12pi log=−(0×log 0+1×log 1)=0。
从原始数据表可知,“天气” 特征取值为 “晴天”、“阴天”、“雨天” 的概率分别为 8 14 \frac{8}{14} 148 、 3 14 \frac{3}{14} 143 、 3 14 \frac{3}{14} 143,因此,若以 “天气” 特征为现阶段的内部节点(用于划分的特征),则整个系统的熵值为:
8 14 H ( X A ) + 3 14 H ( X B ) + 3 14 H ( X C ) = 8 14 × 0.6931 + 3 14 × 0 + 3 14 × 0 ≈ 0.3961 \begin{aligned} & \frac{8}{14} H(X_A) + \frac{3}{14} H(X_B) + \frac{3}{14} H(X_C) \\ &= \frac{8}{14} × 0.6931 + \frac{3}{14} × 0 + \frac{3}{14} × 0 \\ &≈ 0.3961 \end{aligned} 148H(XA)+143H(XB)+143H(XC)=148×0.6931+143×0+143×0≈0.3961
5、条件熵的计算
在上面的计算中,我们将“天气”特征展开,以分别求解各取值对应集合的熵。实际上,该式的计算正是在求条件熵。条件熵 𝐻(𝑌 | 𝑋) 表示在已知随机变量 𝑋 的条件下随机变量 𝑌 的不确定性。它的数学定义是:若设随机变量 (𝑋, 𝑌) ,其联合概率密度为
P ( X = x i , Y = y j ) = p i j , i = 1 , 2 , … , n P(X=x_i,Y=y_j)=p_{ij} \ , \ i=1,2,…,n P(X=xi,Y=yj)=pij , i=1,2,…,n
则定义条件熵 𝐻(𝑌 | 𝑋) :在给定 𝑋 的条件下 𝑌 的条件概率分布对 𝑋 的数学期望,即
𝐻 ( 𝑌 ∣ 𝑋 ) = ∑ i = 1 k p i H ( Y ∣ X = x i ) 𝐻(𝑌 | 𝑋)=\sum_{i=1}^k \ p_i \ H(Y|X=x_i) H(Y∣X)=i=1∑k pi H(Y∣X=xi)
其中,
p
i
=
P
(
X
=
x
i
)
,
𝑖
=
1
,
2
,
…
,
𝑘
p_i=P(X=x_i) \ , \ 𝑖 = 1,2, … , 𝑘
pi=P(X=xi) , i=1,2,…,k (表示指定集合中的元素类别) 。
按照这样的定义,可算出其余各特征的条件熵分别为:
特征取 “温度” 时:
H
(
Y
∣
X
温度
)
=
∑
i
=
1
3
p
i
H
(
Y
∣
X
=
x
i
)
=
P
(
X
=
"
炎热
"
)
H
(
Y
∣
X
=
"
炎热
"
)
+
P
(
X
=
"
正常
"
)
H
(
Y
∣
X
=
"
正常
"
)
+
P
(
X
=
"
寒冷
"
)
H
(
Y
∣
X
=
"
寒冷
"
)
=
6
14
×
(
−
(
3
6
log
3
6
+
3
6
log
3
6
)
)
+
4
14
×
(
−
(
2
4
log
2
4
+
2
4
log
2
4
)
)
+
4
14
×
(
−
(
2
4
log
2
4
+
2
4
log
2
4
)
)
≈
0.6931
\begin{aligned} & H(Y|X_{温度}) = \sum_{i=1}^3 \ p_i \ H(Y|X=x_i) \\ & = P(X= {\sf {"}} 炎热 {\sf {"}})H(Y|X= {\sf {"}} 炎热 {\sf {"}} ) + P(X= {\sf {"}} 正常 {\sf {"}})H(Y|X= {\sf {"}} 正常 {\sf {"}} ) + P(X= {\sf {"}} 寒冷 {\sf {"}})H(Y|X= {\sf {"}} 寒冷 {\sf {"}} ) \\ &= \frac{6}{14}× \left( - \left( \frac36 \ \text{log} \ \frac36 + \frac36 \ \text{log} \ \frac36 \right) \right) + \frac{4}{14}× \left( - \left( \frac24 \ \text{log} \ \frac24 + \frac24 \ \text{log} \ \frac24 \right) \right) + \frac{4}{14}× \left( - \left( \frac24 \ \text{log} \ \frac24 + \frac24 \ \text{log} \ \frac24 \right) \right) \\ &≈ 0.6931 \end{aligned}
H(Y∣X温度)=i=1∑3 pi H(Y∣X=xi)=P(X="炎热")H(Y∣X="炎热")+P(X="正常")H(Y∣X="正常")+P(X="寒冷")H(Y∣X="寒冷")=146×(−(63 log 63+63 log 63))+144×(−(42 log 42+42 log 42))+144×(−(42 log 42+42 log 42))≈0.6931
特征取 “风速” 时:
H
(
Y
∣
X
风速
)
=
∑
i
=
1
2
p
i
H
(
Y
∣
X
=
x
i
)
=
P
(
X
=
"
强
"
)
H
(
Y
∣
X
=
"
强
"
)
+
P
(
X
=
"
弱
"
)
H
(
Y
∣
X
=
"
弱
"
)
=
7
14
×
(
−
(
2
7
log
2
7
+
5
7
log
5
7
)
)
+
7
14
×
(
−
(
5
7
log
5
7
+
2
7
log
2
7
)
)
≈
0.5983
\begin{aligned} & H(Y|X_{风速}) = \sum_{i=1}^2 \ p_i \ H(Y|X=x_i) \\ & = P(X= {\sf {"}} 强 {\sf {"}})H(Y|X= {\sf {"}} 强 {\sf {"}} ) + P(X= {\sf {"}} 弱 {\sf {"}})H(Y|X= {\sf {"}} 弱 {\sf {"}} ) \\ &= \frac{7}{14}× \left( - \left( \frac27 \ \text{log} \ \frac27 + \frac57 \ \text{log} \ \frac57 \right) \right) + \frac{7}{14}× \left( - \left( \frac57 \ \text{log} \ \frac57 + \frac27 \ \text{log} \ \frac27 \right) \right) \\ &≈ 0.5983 \end{aligned}
H(Y∣X风速)=i=1∑2 pi H(Y∣X=xi)=P(X="强")H(Y∣X="强")+P(X="弱")H(Y∣X="弱")=147×(−(72 log 72+75 log 75))+147×(−(75 log 75+72 log 72))≈0.5983
特征取 “湿度” 时:
H
(
Y
∣
X
湿度
)
=
∑
i
=
1
3
p
i
H
(
Y
∣
X
=
x
i
)
=
P
(
X
=
"
干燥
"
)
H
(
Y
∣
X
=
"
干燥
"
)
+
P
(
X
=
"
正常
"
)
H
(
Y
∣
X
=
"
正常
"
)
+
P
(
X
=
"
潮湿
"
)
H
(
Y
∣
X
=
"
潮湿
"
)
=
4
14
×
(
−
(
2
4
log
2
4
+
2
4
log
2
4
)
)
+
6
14
×
(
−
(
4
6
log
4
6
+
2
6
log
2
6
)
)
+
4
14
×
(
−
(
1
4
log
1
4
+
3
4
log
3
4
)
)
≈
0.6315
\begin{aligned} & H(Y|X_{湿度}) = \sum_{i=1}^3 \ p_i \ H(Y|X=x_i) \\ & = P(X= {\sf {"}} 干燥 {\sf {"}})H(Y|X= {\sf {"}} 干燥 {\sf {"}} ) + P(X= {\sf {"}} 正常 {\sf {"}})H(Y|X= {\sf {"}} 正常 {\sf {"}} ) + P(X= {\sf {"}} 潮湿 {\sf {"}})H(Y|X= {\sf {"}} 潮湿 {\sf {"}} ) \\ &= \frac{4}{14}× \left( - \left( \frac24 \ \text{log} \ \frac24 + \frac24 \ \text{log} \ \frac24 \right) \right) + \frac{6}{14}× \left( - \left( \frac46 \ \text{log} \ \frac46 + \frac26 \ \text{log} \ \frac26 \right) \right) + \frac{4}{14}× \left( - \left( \frac14 \ \text{log} \ \frac14 + \frac34 \ \text{log} \ \frac34 \right) \right) \\ &≈ 0.6315 \end{aligned}
H(Y∣X湿度)=i=1∑3 pi H(Y∣X=xi)=P(X="干燥")H(Y∣X="干燥")+P(X="正常")H(Y∣X="正常")+P(X="潮湿")H(Y∣X="潮湿")=144×(−(42 log 42+42 log 42))+146×(−(64 log 64+62 log 62))+144×(−(41 log 41+43 log 43))≈0.6315
三、划分选择
从前面的讨论可以知道,决策树学习的关键在于:如何选择最优划分属性。一般而言,随着划分过程的不断进行,我们自然希望决策树各分支结点所包含的样本尽可能属于同一类别,即结点的 “纯度” (purity) 越来越高。下面介绍几类较为主流的评选算法。
1、信息增益( ID3 算法选用的评估标准)
信息增益 𝑔(𝐷, 𝑋) :表示某特征 𝑋 使得数据集 𝐷 的不确定性减少程度,定义为集合 𝐷 的熵与在给定特征 𝑋 的条件下 𝐷 的条件熵 𝐻(𝐷 | 𝑋) 之差,即
g ( D , X ) = H ( D ) − H ( D ∣ X ) g(D,X)=H(D)-H(D|X) g(D,X)=H(D)−H(D∣X)
从该式可以看出,信息增益表达了样本数据在被分类后的专一性。因此,它可以作为选择当前最优特征的一个指标。
根据前面的计算结果,可知集合 𝐷 的熵 𝐻(𝐷) = 0.6931 ,特征 “天气”、“温度”、“风速”、“湿度” 的条件熵分别为 𝐻(𝐷 | 𝑋天气) = 0.3961 、𝐻(𝐷 | 𝑋温度) = 0.6931、𝐻(𝐷 | 𝑋风速) = 0.5983、𝐻(𝐷 | 𝑋湿度) = 0.6315。根据这些数据,可以算出全部特征在被用于分类时,各自的信息增益:
g ( 𝐷 ∣ 𝑋 天气 ) = H ( D ) − H ( D ∣ X 天气 ) = 0.6931 − 0.3961 = 0.2970 g ( 𝐷 ∣ 𝑋 温度 ) = H ( D ) − H ( D ∣ X 温度 ) = 0.6931 − 0.6931 = 0.0000 g ( 𝐷 ∣ 𝑋 风速 ) = H ( D ) − H ( D ∣ X 风速 ) = 0.6931 − 0.5983 = 0.0948 g ( 𝐷 ∣ 𝑋 湿度 ) = H ( D ) − H ( D ∣ X 湿度 ) = 0.6931 − 0.6315 = 0.0616 g(𝐷 | 𝑋_{天气})=H(D)-H(D|X_{天气}) =0.6931-0.3961= 0.2970 \\ g(𝐷 | 𝑋_{温度})=H(D)-H(D|X_{温度}) =0.6931-0.6931= 0.0000 \\ g(𝐷 | 𝑋_{风速})=H(D)-H(D|X_{风速}) =0.6931-0.5983= 0.0948 \\ g(𝐷 | 𝑋_{湿度})=H(D)-H(D|X_{湿度}) =0.6931-0.6315= 0.0616 g(D∣X天气)=H(D)−H(D∣X天气)=0.6931−0.3961=0.2970g(D∣X温度)=H(D)−H(D∣X温度)=0.6931−0.6931=0.0000g(D∣X风速)=H(D)−H(D∣X风速)=0.6931−0.5983=0.0948g(D∣X湿度)=H(D)−H(D∣X湿度)=0.6931−0.6315=0.0616
上面各特征求得的信息增益中,“天气” 特征对应的是最大的。也就是说,如果将 “天气” 作为决策树的第一个划分特征,系统整体的熵值将降低 0.297,是所有备选特征中效果最好的。因此,根据 “学校举办运动会的历史数据” 构建决策树时,根节点最好取 “天气” 特征。
接下来,在 “晴天” 中的数据将按上面的流程继续执行,直到构建好一棵完整的决策树(或达到指定条件)。不过此时,备选特征只剩下 “温度”、“风速” 和 “湿度” 3 项(往后,每当决策树的深度加 1 时,都会减少一个)。
2、信息增益率( C4.5 算法选用的评估标准)
以信息增益作为划分数据集的特征时,其偏向于选择取值较多的特征。比如,当在学校举办运动会的历史数据中加入一个新特征 “编号” 时,该特征将成为最优特征。因为给定 “编号” 就一定知道那天是否举行过运动会,因此 “编号” 的信息增益很高。

按 “编号” 进行划分得到的决策树:

其条件熵:
H ( D ∣ X 编号 ) = ∑ i = 1 14 p i H ( D ∣ X = x i ) = ( 1 14 × ( 1 × log 1 ) + 1 14 × ( 1 × log 1 ) + … + 1 14 × ( 1 × log 1 ) ) = ( 0 + 0 + … + 0 ) = 0 \begin{aligned} &H(D|X_{编号})=\sum_{i=1}^{14} \ p_i \ H(D|X=x_i) \\ &=\left( \frac1{14}×(1× \text{log} \ 1) +\frac1{14}×(1× \text{log} \ 1) + … + \frac1{14}×(1× \text{log} \ 1) \right) \\ &= (0+0+…+0) \\ &= 0 \end{aligned} H(D∣X编号)=i=1∑14 pi H(D∣X=xi)=(141×(1×log 1)+141×(1×log 1)+…+141×(1×log 1))=(0+0+…+0)=0
信息增益:
g ( 𝐷 ∣ 𝑋 编号 ) = H ( D ) − H ( D ∣ X 编号 ) = 0.6931 − 0 = 0.6931 g(𝐷 | 𝑋_{编号})=H(D)-H(D|X_{编号}) =0.6931-0= 0.6931 g(D∣X编号)=H(D)−H(D∣X编号)=0.6931−0=0.6931
但实际我们知道,“编号” 对于类别的划分并没有实际意义。故此,引入信息增益率。
信息增益率 𝑔𝑅(𝐷, 𝑋) 定义为其信息增益 𝑔(𝐷, 𝑋) 与数据集 𝐷 在特征 𝑋 上值的熵 𝐻𝑋(𝐷) 之比,即:
g R ( D , X ) = g ( D , X ) H X ( D ) g_R(D,X)=\frac{g(D,X)}{H_X(D)} gR(D,X)=HX(D)g(D,X)
其中, H X ( D ) = − ∑ i = 1 k ∣ D i ∣ ∣ D ∣ log ∣ D i ∣ ∣ D ∣ H_X(D)=-\sum_{i=1}^k \ \frac{|D_i|}{|D|}\text{log}\frac{|D_i|}{|D|} HX(D)=−∑i=1k ∣D∣∣Di∣log∣D∣∣Di∣ , 𝑘 是特征 𝑋 的取值类别个数。从上式可以看出,信息增益率考虑了特征本身的熵(此时,当某特征取值类别较多时,𝑔𝑅(𝐷, 𝑋) 式中的分母也会增大),从而降低了 “偏向取值较多的特征” 这一影响。根据该式,可得到基于各特征划分的信息增益率如下:
按编号划分: H 编号 ( D ) = − ∑ i = 1 14 ∣ D i ∣ ∣ D ∣ log ∣ D i ∣ ∣ D ∣ = − ∑ i = 1 14 1 14 log 1 14 = log 14 ≈ 2.6390 g R ( D , X 编号 ) = g ( D , X 编号 ) H 编号 ( D ) = 0.6931 2.6390 ≈ 0.2574 按天气划分: H 天气 ( D ) = − ∑ i = 1 3 ∣ D i ∣ ∣ D ∣ log ∣ D i ∣ ∣ D ∣ = − ( 8 14 log 8 14 + 3 14 log 3 14 + 3 14 log 3 14 ) ≈ 0.9800 g R ( D , X 天气 ) = g ( D , X 天气 ) H 天气 ( D ) = 0.2970 0.9800 ≈ 0.3031 按温度划分: H 温度 ( D ) = − ∑ i = 1 3 ∣ D i ∣ ∣ D ∣ log ∣ D i ∣ ∣ D ∣ = − ( 6 14 log 6 14 + 4 14 log 4 14 + 4 14 log 4 14 ) ≈ 1.0790 g R ( D , X 温度 ) = g ( D , X 温度 ) H 温度 ( D ) = 0 1.0790 ≈ 0 按风速划分: H 风速 ( D ) = − ∑ i = 1 2 ∣ D i ∣ ∣ D ∣ log ∣ D i ∣ ∣ D ∣ = − ( 7 14 log 7 14 + 7 14 log 7 14 ) ≈ 0.6931 g R ( D , X 风速 ) = g ( D , X 风速 ) H 风速 ( D ) = 0.0948 0.6931 ≈ 0.1368 按湿度划分: H 湿度 ( D ) = − ∑ i = 1 3 ∣ D i ∣ ∣ D ∣ log ∣ D i ∣ ∣ D ∣ = − ( 4 14 log 4 14 + 6 14 log 6 14 + 4 14 log 4 14 ) ≈ 1.0790 g R ( D , X 湿度 ) = g ( D , X 湿度 ) H 湿度 ( D ) = 0.0616 1.0790 ≈ 0.0571 \begin{aligned} &按编号划分: \\ & H_{编号}(D)=-\sum_{i=1}^{14} \ \frac{|D_i|}{|D|}\text{log}\frac{|D_i|}{|D|}=-\sum_{i=1}^{14} \ \frac{1}{14}\text{log}\frac{1}{14}=\text{log} \ 14≈2.6390 \\ & g_R(D,X_{编号})=\frac{g(D,X_{编号})}{H_{编号}(D)}=\frac{0.6931}{2.6390}≈0.2574 \\ \\ &按天气划分: \\ & H_{天气}(D)=-\sum_{i=1}^{3} \ \frac{|D_i|}{|D|}\text{log}\frac{|D_i|}{|D|}=-\left( \frac{8}{14}\text{log}\frac{8}{14} +\frac{3}{14}\text{log}\frac{3}{14} + \frac{3}{14}\text{log}\frac{3}{14} \right)≈0.9800 \\ & g_R(D,X_{天气})=\frac{g(D,X_{天气})}{H_{天气}(D)}=\frac{0.2970}{0.9800}≈0.3031 \\ \\ &按温度划分: \\ & H_{温度}(D)=-\sum_{i=1}^{3} \ \frac{|D_i|}{|D|}\text{log}\frac{|D_i|}{|D|}=-\left( \frac{6}{14}\text{log}\frac{6}{14} +\frac{4}{14}\text{log}\frac{4}{14} + \frac{4}{14}\text{log}\frac{4}{14} \right)≈1.0790 \\ & g_R(D,X_{温度})=\frac{g(D,X_{温度})}{H_{温度}(D)}=\frac{0}{1.0790}≈0 \\ \\ &按风速划分: \\ & H_{风速}(D)=-\sum_{i=1}^{2} \ \frac{|D_i|}{|D|}\text{log}\frac{|D_i|}{|D|}=-\left( \frac{7}{14}\text{log}\frac{7}{14} +\frac{7}{14}\text{log}\frac{7}{14} \right)≈0.6931 \\ & g_R(D,X_{风速})=\frac{g(D,X_{风速})}{H_{风速}(D)}=\frac{0.0948}{0.6931 }≈0.1368 \\ \\ &按湿度划分: \\ & H_{湿度}(D)=-\sum_{i=1}^{3} \ \frac{|D_i|}{|D|}\text{log}\frac{|D_i|}{|D|}=-\left( \frac{4}{14}\text{log}\frac{4}{14} +\frac{6}{14}\text{log}\frac{6}{14} + \frac{4}{14}\text{log}\frac{4}{14} \right)≈1.0790 \\ & g_R(D,X_{湿度})=\frac{g(D,X_{湿度})}{H_{湿度}(D)}=\frac{0.0616}{1.0790 }≈0.0571 \\ \end{aligned} 按编号划分:H编号(D)=−i=1∑14 ∣D∣∣Di∣log∣D∣∣Di∣=−i=1∑14 141log141=log 14≈2.6390gR(D,X编号)=H编号(D)g(D,X编号)=2.63900.6931≈0.2574按天气划分:H天气(D)=−i=1∑3 ∣D∣∣Di∣log∣D∣∣Di∣=−(148log148+143log143+143log143)≈0.9800gR(D,X天气)=H天气(D)g(D,X天气)=0.98000.2970≈0.3031按温度划分:H温度(D)=−i=1∑3 ∣D∣∣Di∣log∣D∣∣Di∣=−(146log146+144log144+144log144)≈1.0790gR(D,X温度)=H温度(D)g(D,X温度)=1.07900≈0按风速划分:H风速(D)=−i=1∑2 ∣D∣∣Di∣log∣D∣∣Di∣=−(147log147+147log147)≈0.6931gR(D,X风速)=H风速(D)g(D,X风速)=0.69310.0948≈0.1368按湿度划分:H湿度(D)=−i=1∑3 ∣D∣∣Di∣log∣D∣∣Di∣=−(144log144+146log146+144log144)≈1.0790gR(D,X湿度)=H湿度(D)g(D,X湿度)=1.07900.0616≈0.0571
从上面的结果可以看出,信息增益率能明显降低取值较多的特征偏好现象,从而更合理地评估各特征在划分数据集时取得的效果。因此,信息增益率是现阶段用得较多的一种算法。
3、基尼系数( CART 算法选用的评估标准)
从前面的讨论不难看出,无论是 ID3 还是 C4.5 ,都是基于信息论的熵模型出发而得,均涉及了大量对数运算。能不能简化模型同时又不至于完全丢失熵模型的优点呢?分类回归树(Classification and Regression Tree,CART)便是答案,它通过使用基尼系数来代替信息增益率,从而避免复杂的对数运算。基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。注:这一点和信息增益(率)恰好相反。
在分类问题中,假设有 𝑘 个类别,且第 𝑘 个类别的概率为 𝑝𝑘 ,则基尼系数为
G i n i ( p ) = ∑ i = 1 k p i ( 1 − p i ) = 1 − ∑ i = 1 k p i 2 Gini(p)=\sum_{i=1}^k \ p_i(1-p_i)=1-\sum_{i=1}^kp_i^2 Gini(p)=i=1∑k pi(1−pi)=1−i=1∑kpi2
对于给定数据集 𝐷 ,假设有 𝑘 个类别,且第 𝑘 个类别的数量为 𝐶𝑘 ,则该数据集的基尼系数为
G i n i ( D ) = ∑ i = 1 k ∣ C i ∣ ∣ D ∣ ( 1 − ∣ C i ∣ ∣ D ∣ ) = 1 − ∑ i = 1 k ( ∣ C i ∣ ∣ D ∣ ) 2 Gini(D)=\sum_{i=1}^k \ \frac{|C_i|}{|D|} \left(1-\frac{|C_i|}{|D|} \right)=1-\sum_{i=1}^k{\left( \frac{|C_i|}{|D|} \right)}^2 Gini(D)=i=1∑k ∣D∣∣Ci∣(1−∣D∣∣Ci∣)=1−i=1∑k(∣D∣∣Ci∣)2
从上式可以看出,基尼系数表征了样本集合里一个随机样本分类错误的平均概率。例如:

如果数据集 𝐷 根据特征 𝑋 的取值将其划分为 {𝐷1,𝐷2, … ,𝐷m} ,则在特征 𝑋 的条件下,划分后的集合 𝐷 的基尼系数为:
G i n i ( D , X ) = ∑ i = 1 k ∣ C i ∣ ∣ D ∣ G i n i ( D i ) Gini(D,X)=\sum_{i=1}^k \ \frac{|C_i|}{|D|} Gini(D_i) Gini(D,X)=i=1∑k ∣D∣∣Ci∣Gini(Di)
由于基尼系数 𝐺𝑖𝑛𝑖(𝐷) 表示集合 𝐷 的不确定性,则基尼系数 𝐺𝑖𝑛𝑖(𝐷, 𝑋) 表示 “基于指定特征 𝑋 进行划分后,集合 𝐷 的不确定性”。该值越大,就表示数据集 𝐷 的不确定性越大,也就说明以该特征 进行划分越容易分乱。基于前面各特征对数据集的划分,可得到其对应的基尼系数为:
G i n i ( D , X 编号 ) = ∑ i = 1 14 ∣ C i ∣ ∣ D ∣ G i n i ( D i ) = 1 14 ( 1 − 1 2 ) + 1 14 ( 1 − 1 2 ) + … + 1 14 ( 1 − 1 2 ) = 0 G i n i ( D , X 天气 ) = ∑ i = 1 3 ∣ C i ∣ ∣ D ∣ G i n i ( D i ) = 8 14 ( 1 − ( ( 4 8 ) 2 + ( 4 8 ) 2 ) ) + 3 14 ( 1 − ( 3 3 ) 2 ) + 3 14 ( 1 − ( 3 3 ) 2 ) ≈ 0.2857 G i n i ( D , X 温度 ) = ∑ i = 1 3 ∣ C i ∣ ∣ D ∣ G i n i ( D i ) = 6 14 ( 1 − ( ( 3 6 ) 2 + ( 3 6 ) 2 ) ) + 4 14 ( 1 − ( ( 2 4 ) 2 + ( 2 4 ) 2 ) ) + 4 14 ( 1 − ( ( 2 4 ) 2 + ( 2 4 ) 2 ) ) ≈ 0.5000 G i n i ( D , X 风速 ) = ∑ i = 1 2 ∣ C i ∣ ∣ D ∣ G i n i ( D i ) = 7 14 ( 1 − ( ( 2 7 ) 2 + ( 5 7 ) 2 ) ) + 7 14 ( 1 − ( ( 5 7 ) 2 + ( 2 7 ) 2 ) ) ≈ 0.4082 G i n i ( D , X 湿度 ) = ∑ i = 1 3 ∣ C i ∣ ∣ D ∣ G i n i ( D i ) = 4 14 ( 1 − ( ( 2 4 ) 2 + ( 2 4 ) 2 ) ) + 6 14 ( 1 − ( ( 4 6 ) 2 + ( 2 6 ) 2 ) ) + 4 14 ( 1 − ( ( 1 4 ) 2 + ( 3 4 ) 2 ) ) ≈ 0.4405 \begin{aligned} & Gini(D,X_{编号})=\sum_{i=1}^{14} \ \frac{|C_i|}{|D|} Gini(D_i)=\frac{1}{14}(1-1^2)+\frac{1}{14}(1-1^2)+…+\frac{1}{14}(1-1^2)=0 \\ & Gini(D,X_{天气})=\sum_{i=1}^{3} \ \frac{|C_i|}{|D|} Gini(D_i)=\frac{8}{14} \left(1- \left( \left(\frac48 \right)^2 + \left(\frac48 \right)^2 \right) \right) + \frac{3}{14} \left( 1- \left( \frac33 \right)^2 \right) + \frac{3}{14} \left( 1- \left( \frac33 \right)^2 \right)≈0.2857 \\ & Gini(D,X_{温度})=\sum_{i=1}^{3} \ \frac{|C_i|}{|D|} Gini(D_i)=\frac{6}{14} \left(1- \left( \left(\frac36 \right)^2 + \left(\frac36 \right)^2 \right) \right) + \frac{4}{14} \left(1- \left( \left(\frac24 \right)^2 + \left(\frac24 \right)^2 \right) \right) + \frac{4}{14} \left(1- \left( \left(\frac24 \right)^2 + \left(\frac24 \right)^2 \right) \right)≈0.5000 \\ & Gini(D,X_{风速})=\sum_{i=1}^{2} \ \frac{|C_i|}{|D|} Gini(D_i)=\frac{7}{14} \left(1- \left( \left(\frac27 \right)^2 + \left(\frac57 \right)^2 \right) \right) + \frac{7}{14} \left(1- \left( \left(\frac57 \right)^2 + \left(\frac27 \right)^2 \right) \right)≈0.4082 \\ & Gini(D,X_{湿度})=\sum_{i=1}^{3} \ \frac{|C_i|}{|D|} Gini(D_i)=\frac{4}{14} \left(1- \left( \left(\frac24 \right)^2 + \left(\frac24 \right)^2 \right) \right) + \frac{6}{14} \left(1- \left( \left(\frac46 \right)^2 + \left(\frac26 \right)^2 \right) \right) + \frac{4}{14} \left(1- \left( \left(\frac14 \right)^2 + \left(\frac34 \right)^2 \right) \right)≈0.4405 \\ \end{aligned} Gini(D,X编号)=i=1∑14 ∣D∣∣Ci∣Gini(Di)=141(1−12)+141(1−12)+…+141(1−12)=0Gini(D,X天气)=i=1∑3 ∣D∣∣Ci∣Gini(Di)=148(1−((84)2+(84)2))+143(1−(33)2)+143(1−(33)2)≈0.2857Gini(D,X温度)=i=1∑3 ∣D∣∣Ci∣Gini(Di)=146(1−((63)2+(63)2))+144(1−((42)2+(42)2))+144(1−((42)2+(42)2))≈0.5000Gini(D,X风速)=i=1∑2 ∣D∣∣Ci∣Gini(Di)=147(1−((72)2+(75)2))+147(1−((75)2+(72)2))≈0.4082Gini(D,X湿度)=i=1∑3 ∣D∣∣Ci∣Gini(Di)=144(1−((42)2+(42)2))+146(1−((64)2+(62)2))+144(1−((41)2+(43)2))≈0.4405
4、基尼增益
同信息增益一样,如果将数据集 𝐷 的基尼系数减去数据集 𝐷 根据特征 𝑋 进行划分后得到的基尼系数
G ( D , X ) = G i n i ( D ) − G i n i ( D , X ) G(D,X)=Gini(D)-Gini(D,X) G(D,X)=Gini(D)−Gini(D,X)
就得到基尼增益(系数)。显然,采用越好的特征进行划分,得到的基尼增益也越大。基于前面各特征对数据集的划分,可得到其对应的基尼增益。
步骤一:先算出初始数据集合 D 的基尼系数。
G i n i ( D ) = 1 − ∑ i = 1 2 ( ∣ C i ∣ ∣ D ∣ ) 2 = 1 − ( ( 7 14 ) 2 + ( 7 14 ) 2 ) = 0.5000 Gini(D)=1-\sum_{i=1}^2 \left( \frac{|C_i|}{|D|} \right)^2=1- \left( \left(\frac{7}{14} \right)^2 + \left(\frac{7}{14} \right)^2 \right)=0.5000 Gini(D)=1−∑i=12(∣D∣∣Ci∣)2=1−((147)2+(147)2)=0.5000
步骤二:计算基尼系数计算基尼增益率。
G ( D , X 编号 ) = G i n i ( D ) − G i n i ( D , X 编号 ) = 0.5000 − 0 = 0.5000 G ( D , X 天气 ) = G i n i ( D ) − G i n i ( D , X 天气 ) = 0.5000 − 0.2857 = 0.2143 G ( D , X 温度 ) = G i n i ( D ) − G i n i ( D , X 温度 ) = 0.5000 − 0.5000 = 0 G ( D , X 风速 ) = G i n i ( D ) − G i n i ( D , X 风速 ) = 0.5000 − 0.4082 = 0.0918 G ( D , X 湿度 ) = G i n i ( D ) − G i n i ( D , X 湿度 ) = 0.5000 − 0.4405 = 0.0595 \begin{aligned} & G(D,X_{编号})=Gini(D)-Gini(D,X_{编号})=0.5000-0=0.5000 \\ & G(D,X_{天气})=Gini(D)-Gini(D,X_{天气})=0.5000-0.2857=0.2143 \\ & G(D,X_{温度})=Gini(D)-Gini(D,X_{温度})=0.5000-0.5000=0\\ & G(D,X_{风速})=Gini(D)-Gini(D,X_{风速})=0.5000-0.4082=0.0918 \\ & G(D,X_{湿度})=Gini(D)-Gini(D,X_{湿度})=0.5000-0.4405=0.0595 \\ \end{aligned} G(D,X编号)=Gini(D)−Gini(D,X编号)=0.5000−0=0.5000G(D,X天气)=Gini(D)−Gini(D,X天气)=0.5000−0.2857=0.2143G(D,X温度)=Gini(D)−Gini(D,X温度)=0.5000−0.5000=0G(D,X风速)=Gini(D)−Gini(D,X风速)=0.5000−0.4082=0.0918G(D,X湿度)=Gini(D)−Gini(D,X湿度)=0.5000−0.4405=0.0595
可见,基尼增益在处理诸如 “编号” 这一类特征时,仍然会认为其是最优特征(此时,可采取类似信息增益率的方式,选用基尼增益率 )。但对常规特征而言,其评估的合理性还是较优的。
5、基尼增益率
基尼增益率 𝐺𝑅(𝐷, 𝑋) 定义为其尼基增益 𝐺(𝐷, 𝑋) 与数据集 𝐷 在特征 𝑋 上的取值个数之比,即
G R ( D , X ) = G ( D , X ) ∣ D X ∣ G_R(D,X)=\frac{G(D,X)}{|D_X|} GR(D,X)=∣DX∣G(D,X)
容易看出,基尼增益率考虑了特征本身的基尼系数(此时,当某特征取值类别较多时, 𝐺𝑅(𝐷, 𝑋) 式中的分母也会增大),从而降低了 “偏向取值较多的特征” 这一影响。根据该式,可得到基于各特征划分的基尼增益率如下:
G R ( D , X 编号 ) = G ( D , X 编号 ) ∣ D 编号 ∣ = 0.5000 14 ≈ 0.0357 G R ( D , X 天气 ) = G ( D , X 天气 ) ∣ D 天气 ∣ = 0.2143 3 ≈ 0.7143 G R ( D , X 温度 ) = G ( D , X 温度 ) ∣ D 温度 ∣ = 0 3 = 0 G R ( D , X 风速 ) = G ( D , X 风速 ) ∣ D 风速 ∣ = 0.0948 3 ≈ 0.0316 G R ( D , X 湿度 ) = G ( D , X 湿度 ) ∣ D 湿度 ∣ = 0.0616 2 ≈ 0.0308 \begin{aligned} & G_R(D,X_{编号})=\frac{G(D,X_{编号})}{|D_{编号}|}=\frac{0.5000}{14}≈0.0357 \\ & G_R(D,X_{天气})=\frac{G(D,X_{天气})}{|D_{天气}|}=\frac{0.2143}{3}≈0.7143 \\ & G_R(D,X_{温度})=\frac{G(D,X_{温度})}{|D_{温度}|}=\frac{0}{3}=0 \\ & G_R(D,X_{风速})=\frac{G(D,X_{风速})}{|D_{风速}|}=\frac{0.0948}{3}≈0.0316 \\ & G_R(D,X_{湿度})=\frac{G(D,X_{湿度})}{|D_{湿度}|}=\frac{0.0616}{2}≈0.0308 \\ \end{aligned} GR(D,X编号)=∣D编号∣G(D,X编号)=140.5000≈0.0357GR(D,X天气)=∣D天气∣G(D,X天气)=30.2143≈0.7143GR(D,X温度)=∣D温度∣G(D,X温度)=30=0GR(D,X风速)=∣D风速∣G(D,X风速)=30.0948≈0.0316GR(D,X湿度)=∣D湿度∣G(D,X湿度)=20.0616≈0.0308
从上面的结果可以看出,基尼增益率能明显降低取值较多的特征偏好现象,从而更合理地评估各特征在划分数据集时取得的效果。
四、决策树中的连续值处理
在前面的数据集中,各项特征(以及标签)均为离散型数据,但有时处理的数据对象可能会含有连续性数值,为了解决这一问题,我们可以对数据进行离散化处理。此时,可把连续取值的数据值域划分为多个区间,并将每个区间视为该特征的一个取值,如此就完成了从连续性数据到离散性数据的转变。例如,当 “学校举办运动会的历史数据” 为下表时,我们可根据这些数据(并结合相关知识)将温度特征的取值作以下划分:

将 “温度” 属性进行分区处理:

对于一些尚无明确划分标准的特征(如下面是一组无具体含义的数据):
62 , 65 , 72 , 86 , 89 , 96 , 102 , 116 , 118 , 120 , 125 , 169 , 187 , 211 , 218 62,65,72,86,89,96,102,116,118,120,125,169,187,211,218 62,65,72,86,89,96,102,116,118,120,125,169,187,211,218
我们要如何将这些数据进行离散化呢?一种较为直接的方式是:对原数据进行排序,再取任意相邻值的中位点作为划分点,例如:可以 65 和 72 的中位点( φ = a i + a i + 1 2 = 65 + 72 2 = 68.5 \varphi=\frac{a_i+a_{i+1}}{2}=\frac{65+72}{2}=68.5 φ=2ai+ai+1=265+72=68.5)进行划分。对数据进行离散化处理是希望划分之后的数据集更加纯净,所以这里依然可以用信息熵来作为对划分的度量,并选取划分效果最好的点作为划分点。
对于长度为 n n n 的数据,其备选中位点有 n − 1 n-1 n−1 个:
φ = { a i + a i + 1 2 , 1 ≤ i ≤ n − 1 } \varphi=\left\{ \frac{a_i+a_{i+1}}{2} , 1≤i≤n-1 \right\} φ={2ai+ai+1,1≤i≤n−1}
我们需要算出这 n − 1 n-1 n−1 个备选中位点划分出的数据集的信息熵,信息熵最小的就是最优划分点。
在评估决策树执行分类或回归任务的效果时,其方式也有所不同。对于分类任务,可用熵或基尼系数;对于回归任务,则需要用方差来衡量最终落到某个叶子节点中的数值之间的差异(方差越小则说明数据之间的差异越小,越应该被归类到一类)。注:决策树在执行回归任务时,其最终反馈的结果应当取某个叶子结点中所有数的均值。
五、决策树中的预剪枝处理(正则化)
对于决策树而言,当你不断向下划分,以构建一棵足够大的决策树时(直到所有叶子结点熵值均为 0),理论上就能将近乎所有数据全部区分开。所以,决策树的过拟合风险非常大。为此,需要对其进行剪枝处理。
常用的剪枝策略主要有两个:
- 预剪枝;构建决策树的同时进行剪枝处理(更常用);
- 后剪枝:构建决策树后再进行剪枝处理。
预剪枝策略可以通过限制树的深度、叶子结点个数、叶子结点含样本数以及信息增量来完成。
1、限制决策树的深度
下图展示了通过限制树的深度以防止决策树出现过拟合风险的情况。

2、限制决策树中叶子结点的个数
下图展示了通过限制决策树中叶子结点的个数以防止决策树出现过拟合风险的情况。

3、限制决策树中叶子结点包含的样本个数
下图展示了通过限制决策树中叶子结点包含的样本个数以防止决策树出现过拟合风险的情况。

4、限制决策树的最低信息增益
下图展示了通过限制决策树中叶子结点包含的样本个数以防止决策树出现过拟合风险的情况。

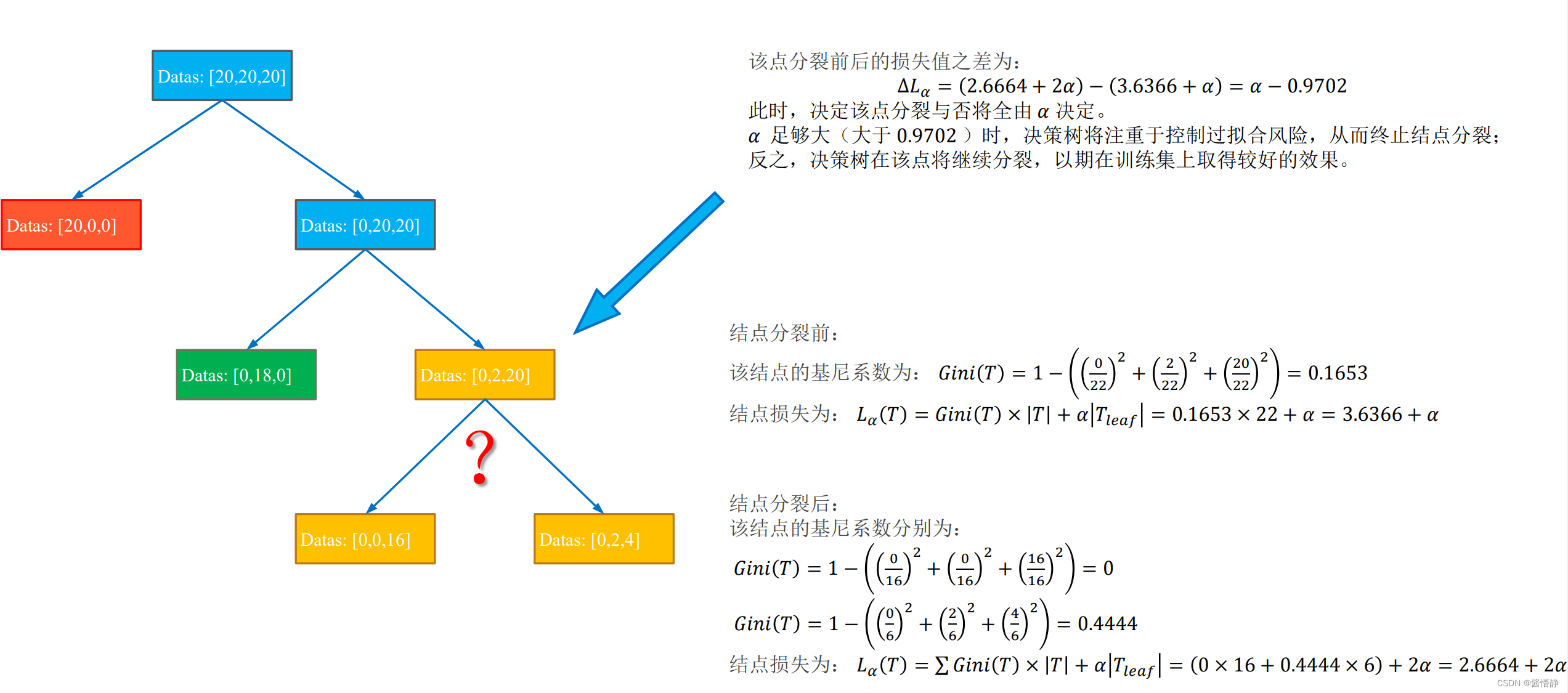
六、决策树中的后剪枝处理
后剪枝的实现依赖如下衡量标准:
L α = G i n i ( T ) × ∣ T ∣ + α ∣ T l e a f ∣ L_\alpha=Gini(T)×|T|+\alpha|T_{leaf}| Lα=Gini(T)×∣T∣+α∣Tleaf∣
其中, 𝐿𝛼(𝑇) 表示最终损失(希望决策树的最终损失越小越好),𝐺𝑖𝑛𝑖(𝑇) 表示当前结点的熵或基尼系数, |𝑇| 表示当前结点包含的数据样本个数, 𝑇𝑙𝑒𝑎𝑓 表示当前结点被划分后产生的叶子结点个数(显然,叶子节点越多损失越大),𝛼 是由用户指定的偏好系数( 𝛼 越大代表我们对 “划分出更多的子结点” 的惩罚越大,即越不偏好于决策树的过分划分,因此有助于控制模型过拟合;反之,𝛼 越小表示我们对 “划分出更多的子结点” 的惩罚越小,即更希望决策树能在训练集上得到较好的结果,而不在意过拟合风险)。
下面以一幅图像来展示后剪枝处理的算法原理:
七、实战部分
博主正在尽力研究中…