目录
一. 语义分割
二. 数据集
三. 数据增强
图像数据处理步骤
CT图像增强方法 :windowing方法
直方图均衡化
获取掩膜图像深度
在肿瘤CT图中提取肿瘤
保存肿瘤数据
四. 数据加载
数据批处理
编辑编辑
数据集加载
五. UNet神经网络模型搭建
单张图片预测图
一. 语义分割
第三代图像分割:语义分割
图像分割(Image Segmentation)是计算机视觉领域中的一项重要基础技术。图像分割是将数字图像细分为多个图像子区域的过程,通过简化或改变图像的表示形式,让图像能够更加容易被理解。更简单地说,图像分割就是为数字图像中的每一个像素附加标签,使得具有相同标签的像素具有某种共同的视觉特性。
医学图像的模态(格式)更加多样化,如X-ray、CT、MRI以及超声等等,当然也包括一些常见的RGB图像(如眼底视网膜图像)。不同模态图像反应的信息侧重点是不一样的。比如X-ray观察骨骼更清晰,CT可以反应组织和器官出血,MRI适合观察软组织。而且不同型号的成像设备得到的成像结果有一定差异。
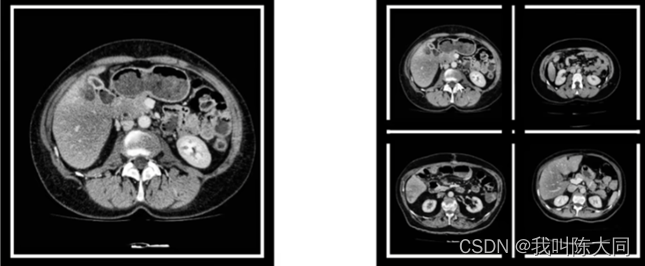
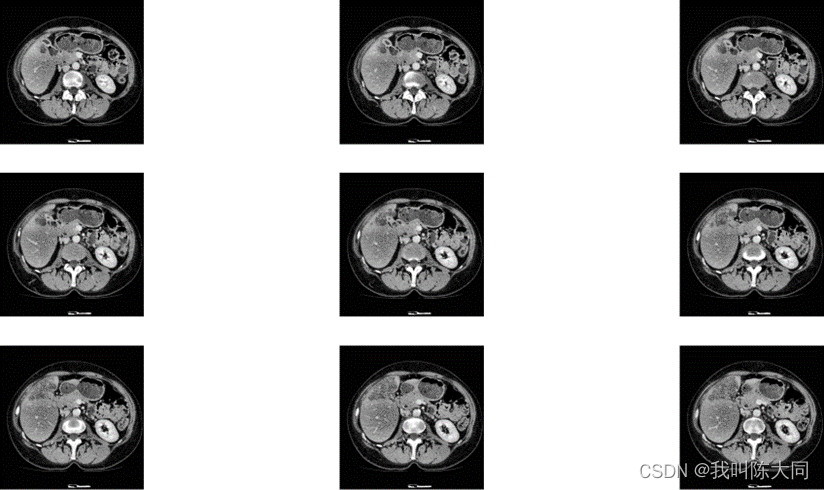
一图为一肝脏CT图像切片可视化结果,已经过预处理转化为灰度图像,组织与器官之间的分界线比较模糊。
二图为不同个体的肝脏CT图像,差异巨大,这给肝脏组织提取带来了很大的困难。
二. 数据集
3D-IRCADb (3D Image Reconstruction for Comparison of Algorithm Database,用于算法数据库比较的三维图像重建),数据库由75%病例中10名女性和10名男性肝脏肿瘤患者的CT扫描组成,每个文件夹对应不同的病人,提供了有关图像的信息,如肝脏大小(宽度、深度、高度)或根据Couninurd分割的肿瘤位置。它还表明,由于与邻近器官的接触、肝脏的非典型形状或密度,甚至图像中的伪影,肝脏分割可能会遇到重大困难。
链接:https://pan.baidu.com/s/1P76AF-wvrFjElc6tR82tRA
提取码:5el7
三. 数据增强
图像数据处理步骤
1.数据加载
2.CT图像增强
3.直方图均衡化增强
4.获取肿瘤对应CT图、肝脏肿瘤掩模图
5.保存图像
DICOM数据读取
使用pydicom库读取文件,pydicom.dcmread函数读取文件,对文件排序,pixel_array属性提取图像像素信息,展示图片:
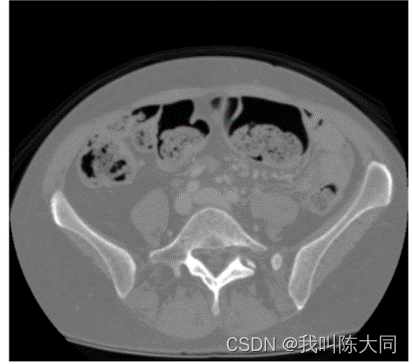
批量数据读取
# 批量读取数据
img_slices = [pydicom.dcmread(os.path.join(data_path, file_name)) for file_name in os.listdir(data_path)]
os.listdir(data_path)
# 排序,避免CT图乱序
img_slices.sort(key=lambda x:x.InstanceNumber) # 顺序属性
img_array = np.array([i.pixel_array for i in img_slices]) # 提取像素值
CT图像增强方法 :windowing方法
CT图像的范围很大导致了对比度很差,需要针对具体的器官进行处理。
CT值的物理意义就是CT射线照了你的身体,辐射经过你的身体时的辐射强度的衰减程度。
CT 的特点是能够分辨人体组织密度的轻微差别,所采用的标准是根据各种组织对x线的线性吸收系数(μ值)来决定的。
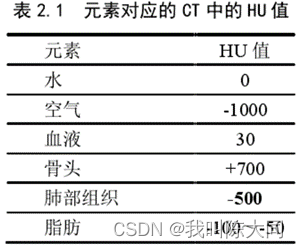
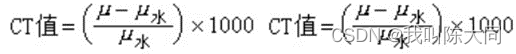
根据Hu(CT)值来筛选我们想要的部位的图片,其他部位全部抹黑或者抹白,目的是为了增加图像对比度。使用windowing方法。观察的CT值范围:窗宽。观察的中心CT值即为窗位,然后对肿瘤部分进行二值化处理。
def windowing(img, window_width, window_center):
# params:需要增强的图片, 窗口宽度, 窗中心 通过窗口最小值来线性移动窗口增强
min_windows = float(window_center)-0.5*float(window_width)
new_img = (img-min_windows)/float(window_width)
new_img[new_img<0] = 0 # 二值化处理 抹白
new_img[new_img>1] = 1 # 抹黑
return (new_img * 255).astype('uint8') # 把数据整理成标准图像格式
img_ct = windowing(img_array, 500, 150)
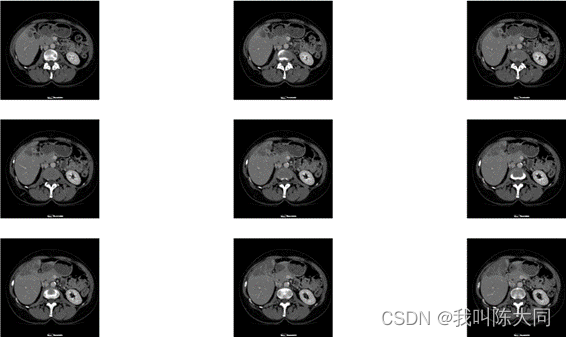
直方图均衡化
直方图均衡化函数:把整个图像分成许多小块(比如按10*10作为一个小块),对每个小块进行均衡化。主要对于图像直方图不是那么单一的(比如存在多峰情况)图像比较实用。0pencv中将这种方法为:cv2.createCLAHE()
def clahe_equalized(imgs):
# 输入imgs的形状必须是3维
assert (len(imgs.shape) == 3)
# 定义均衡化函数
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
# 新数组存放均衡化后的数据
img_res = np.zeros_like(imgs)
for i in range(len(imgs)):
img_res[i,:,:] = clahe.apply(np.array(imgs[i,:,:], dtype=np.uint8))
return img_res/255
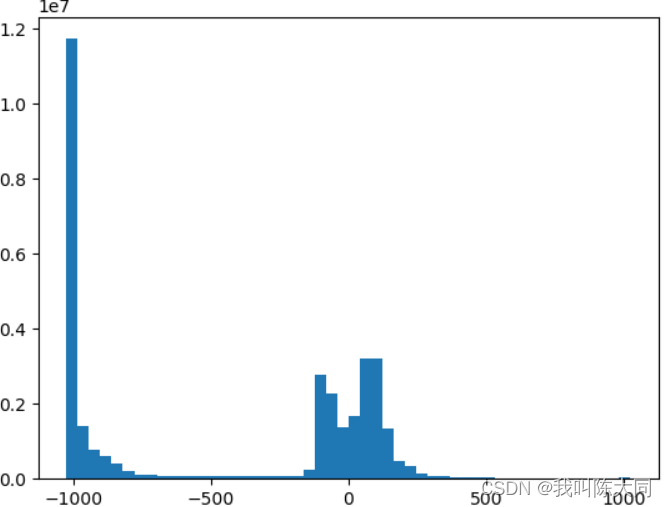
plt.hist(img_array.reshape(-1,),bins=50) # 降成一维,分成50分
获取掩膜图像深度
为加快训练速度,自定义函数实现提取肝脏肿瘤对应的CT图像(处理后)和对应的掩模图,并分别保存到不同的文件夹中,分别作为模型的输入与输出。读取肿瘤CT图:
tumor_slice = [pydicom.dcmread(os.path.join(data_path_mask, file_name)) for file_name in os.listdir(data_path_mask)]
#避免CT图乱序,顺序属性
tumor_slice.sort(key=lambda x: x.InstanceNumber)
#提取像素值
tumor_array = np.array([i.pixel_array for i in tumor_slice])
print(tumor_array.shape) # (129, 512, 512)
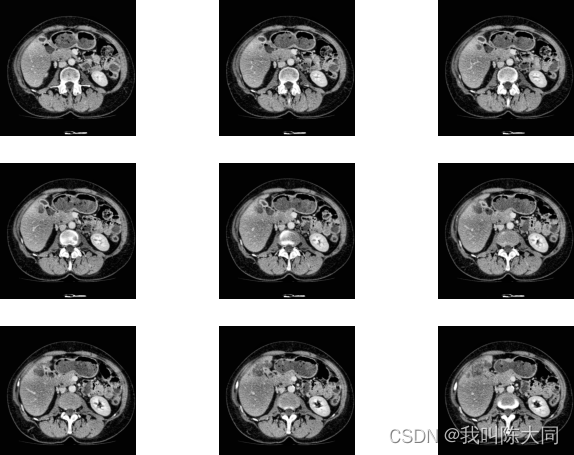
 白色部分为肿瘤掩模图,黑色部分对应的像素数组全为0。
白色部分为肿瘤掩模图,黑色部分对应的像素数组全为0。
在肿瘤CT图中提取肿瘤
index = [i.sum() > 0 for i in tumor_array] # 提取含肿瘤部分
# print(len(index)) # = tumor_array.shape[0] 129
# 提取掩模图的肿瘤部分
img_tumor = tumor_array[index]
# 对增强后的CT图提取肿瘤部分
img_patient = img_clahe[index]

保存肿瘤数据
# 设置保存文件路径
patient_save_path = r'E:/datasets/liver/tmp/patient/'
tumor_save_path = r'E:/datasets/liver/tmp/tumor/'
for path in [patient_save_path, tumor_save_path]:
if os.path.exists(path): # 判断文件夹是否存在
shutil.rmtree(path) # 清空
os.mkdir(path)
# 保留一个肿瘤的数据
# plt.imsave(os.path.join(patient_save_path, '0.jpg'), img_patient[0],cmap='gray')
for i in range(len(img_patient)):
plt.imsave(os.path.join(patient_save_path, f'{i}.jpg'), img_patient[i], cmap='gray')
plt.imsave(os.path.join(tumor_save_path, f'{i}.jpg'), img_tumor[i], cmap='gray')四. 数据加载
数据批处理
取3dircadb1文件夹中数据作为实验对象,取前1-10个病人的数据作为训练样本,10-20个病人的数据作为测试样本。
- 1.读取CT图图像片段
- 2.提取像素值
- 3.CT图增强、均衡化
- 4.处理肿瘤掩模图
- 5.对每个病人的肿瘤图进行排序,提取肿瘤片段像素值
- 6.提取肿瘤肿瘤部分像素编号
- 7.找到CT图中对应位置
- 8.保存所有肿瘤数据
def processImage(start, end):
for num in range(start, end):
print('正在处理第%d号病人' % num)
data_path = fr'G:/dataPack/基于深度学习的肝脏肿瘤图像分割/3dircadb1/3dircadb1.{num}/PATIENT_DICOM'
# 读取CT图图像片段
image_slices = [pydicom.dcmread(os.path.join(data_path, file_name)) for file_name in os.listdir(data_path)]
os.listdir(data_path)
image_slices.sort(key=lambda x: x.InstanceNumber) # 排序
# 提取像素值
image_array = np.array([i.pixel_array for i in image_slices])
# CT图增强-windowing
img_ct = windowing(image_array, 250, 0)
# 直方图均衡化
img_clahe = clahe_equalized(img_ct)
# 肿瘤掩模图处理
livertumor_path = fr'G:/dataPack/基于深度学习的肝脏肿瘤图像分割/3dircadb1/3dircadb1.{num}/MASKS_DICOM'
tumor_paths = [os.path.join(livertumor_path, i) for i in os.listdir(livertumor_path) if 'livertumor' in i]
# 重新排序
tumor_paths.sort()
# 提取所有肿瘤数据
j = 0
for tumor_path in tumor_paths:
print("正在处理第%d个肿瘤" % j)
tumor_slices = [pydicom.dcmread(os.path.join(tumor_path, file_name)) for file_name in
os.listdir(tumor_path)]
# 重新对肿瘤片段图排序
tumor_slices.sort(key=lambda x: x.InstanceNumber)
# 提取像素值
tumor_array = np.array([i.pixel_array for i in tumor_slices])
# 没有肿瘤的掩模图全为黑色,对应像素全为0
index = [i.sum() > 0 for i in tumor_array] # 提取肿瘤部分编号
img_tumor = tumor_array[index]
# 对增强后的CT图提取肿瘤
img_patient = img_clahe[index]
# 保存所有肿瘤数据
for i in range(len(img_patient)):
plt.imsave(os.path.join(patient_save_path, f'{num}_{j}_{i}.jpg'), img_patient[i], cmap='gray') # 保存CT图
plt.imsave(os.path.join(tumor_save_path, f'{num}_{j}_{i}.jpg'), img_tumor[i], cmap='gray') # 保存肿瘤掩模图
j += 1
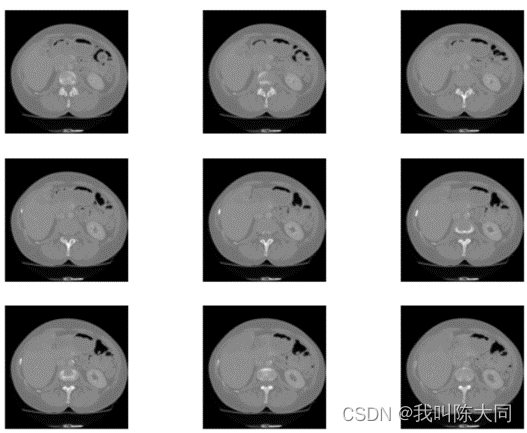
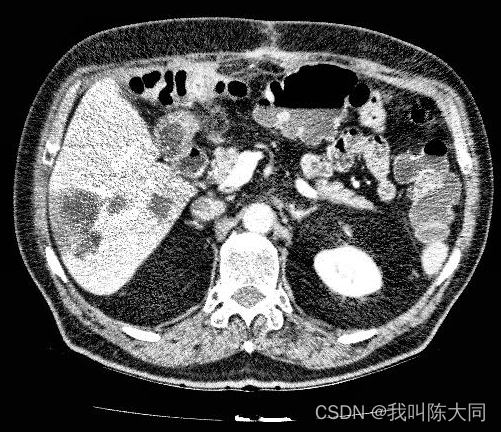
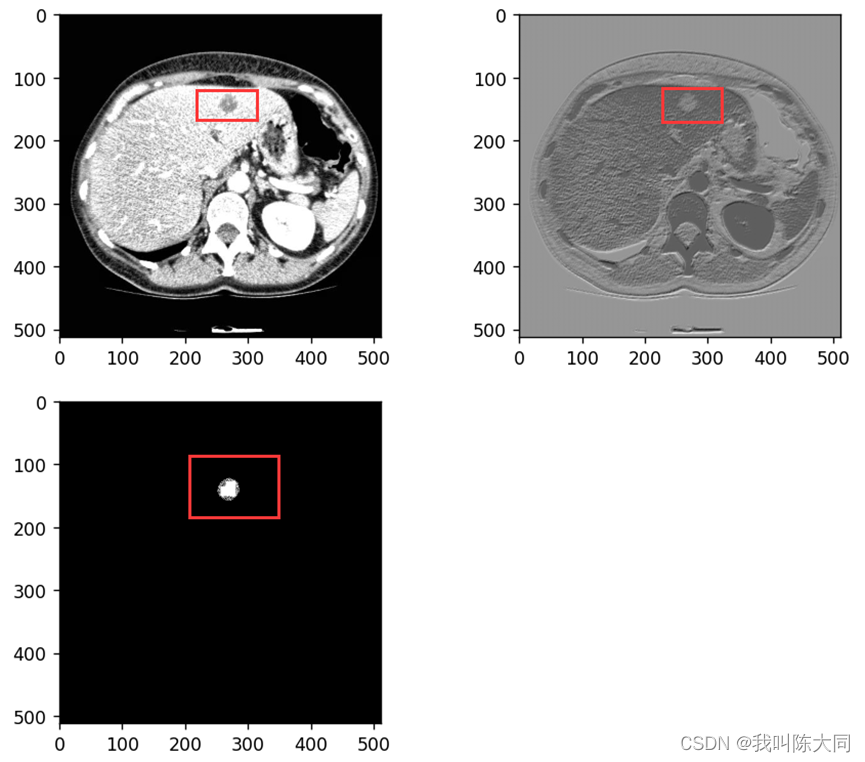
return img_patient, img_tumor处理后保存的CT增强图像与肿瘤掩模图

数据集加载
定义Dataset数据加载器,对样本中每个图片进行进一步处理,转成np数组并转换维度方便UNet网络训练,通过Dataloader中定义batch_size设置每批数据大小为2(从计算角度来提高训练效率)
transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor()
])首先读取本地文件,设置训练集与测试集文件路径,通过torch.squeeze(anno_tensor).type(torch.long)将肿瘤图转化为单通道数组
并对肿瘤图进行二值化处理
# 读取之前保存的处理后的病人CT图片与肿瘤图片
train_img_patient, train_img_tumor = processImage(1, 5)
test_img_patient, test_img_tumor = processImage(5, 7)
patient_images = glob.glob(r'E:\\datasets\liver\tmp\patient\*.jpg')
tumor_images = glob.glob(r'E:\\datasets\liver\tmp\tumor\*.jpg')
train_images = [p for p in patient_images if '1_' in p]
train_labels = [p for p in tumor_images if '1_' in p]
test_images = [p for p in patient_images if '2_' in p]
test_labels = [p for p in tumor_images if '2_' in p]
train_images = np.array(train_images)
train_labels = np.array(train_labels)
test_images = np.array(test_images)
test_labels = np.array(test_labels)
# img = Image.open(train_images[1])
# plt.imshow(img)
# plt.show()
class Portrait_dataset(data.Dataset):
def __init__(self, img_paths, anno_paths):
self.imgs = img_paths
self.annos = anno_paths
def __getitem__(self, index):
img = self.imgs[index]
anno = self.annos[index]
pil_img = Image.open(img)
img_tensor = transform(pil_img)
pil_anno = Image.open(anno)
anno_tensor = transform(pil_anno)
# 由于蒙版图都是黑白图,会产生channel为1的维度。经过转换后,256x256x1,这个1并不是我们需要的。
anno_tensor = torch.squeeze(anno_tensor).type(torch.long)
anno_tensor[anno_tensor > 0] = 1 # 语义分割。二分类。
return img_tensor, anno_tensor
def __len__(self):
return len(self.imgs)
BATCH_SIZE = 2
train_set = Portrait_dataset(train_images, train_labels)
test_set = Portrait_dataset(test_images, test_labels)
train_dataloader = data.DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = data.DataLoader(test_set, batch_size=BATCH_SIZE)
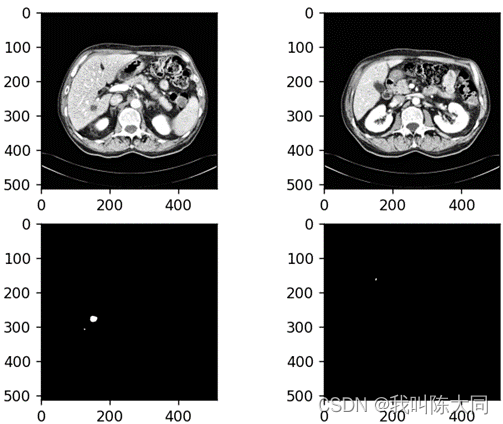
img_batch, anno_batch = next(iter(train_dataloader))通过DataSet读取数据集,在通过DataLoader设置批处理图片数量=2(提高计算效率)
随机选取病人CT图和肿瘤图展示:
五. UNet神经网络模型搭建
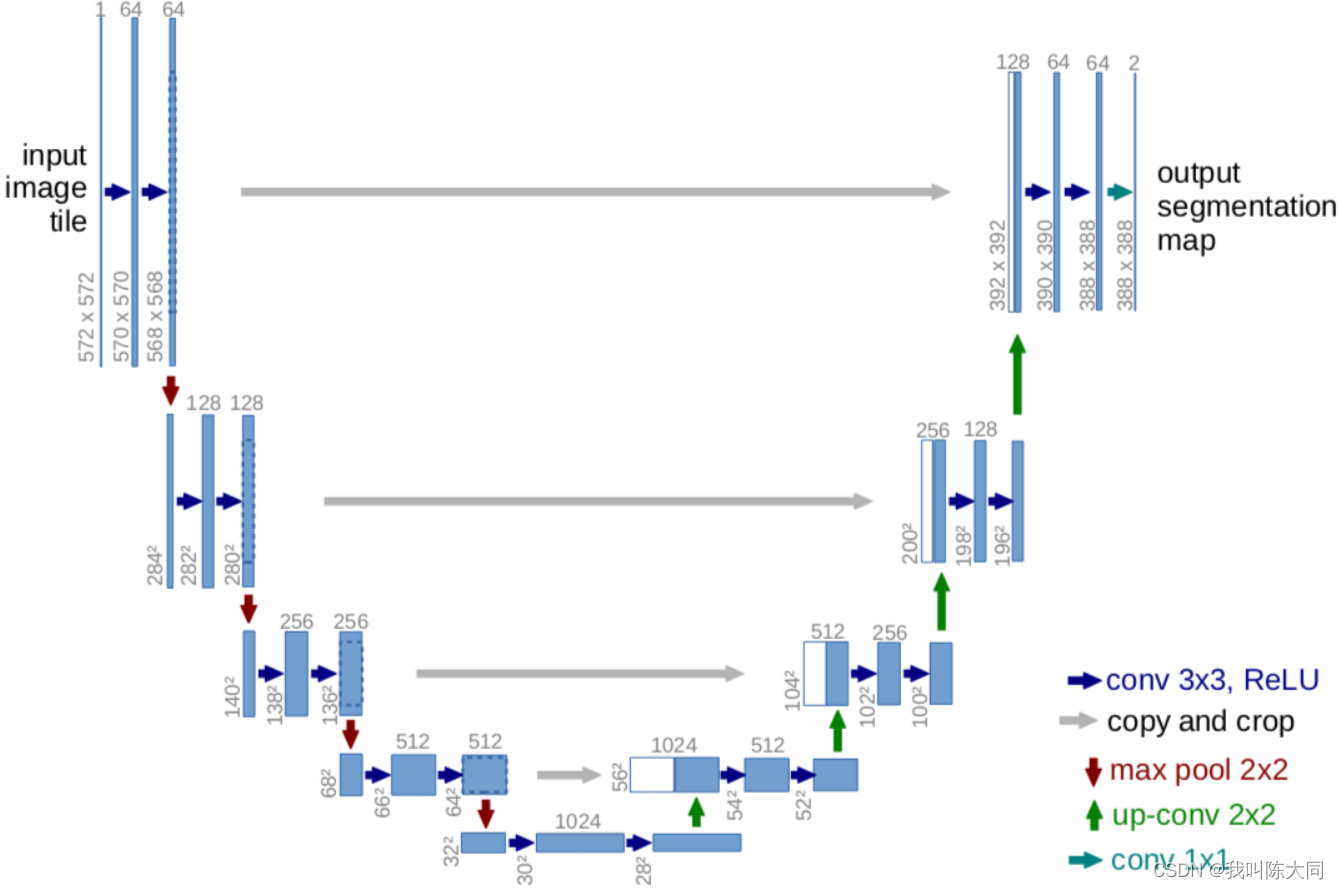
Unet网络结构是对称的,蓝/白色框表示 feature map;蓝色箭头表示 3x3 卷积,用于特征提取;灰色箭头表示 skip-connection,用于特征融合;红色箭头表示池化 pooling,用于降低维度;绿色箭头表示上采样 upsample,用于恢复维度;青色箭头表示 1x1 卷积,用于输出结果。
class downSample(nn.Module):
def __init__(self, in_channels, out_channels):
super(downSample, self).__init__()
# 两层*(卷积+激活)
self.conv_relu = nn.Sequential(
# padding=1,希望图像经过卷积之后大小不变
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
# 下采样(池化)
self.pool = nn.MaxPool2d(kernel_size=2)
def forward(self, x, is_pool=True):
if is_pool:
x = self.pool(x)
print("downSample forward x.shape",x.shape)
x = self.conv_relu(x)
print("downSample forward after conv_relu(x) x.shape",x.shape)
return x
# 上采样模型。卷积、卷积、上采样(反卷积实现上采样)
class upSample(nn.Module):
def __init__(self, channels):
# 两层*(卷积层+激活层)
super(upSample, self).__init__()
self.conv_relu = nn.Sequential(
nn.Conv2d(2 * channels, channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channels, channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
# 上采样激活层(ConvTransposed)将输出层的channel变成原来的一半
self.upConv_relu = nn.Sequential(
nn.ConvTranspose2d(channels, channels // 2,
kernel_size=3, stride=2,
padding=1, output_padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
print("upSample - forward x.shape",x.shape)
x = self.conv_relu(x)
x = self.upConv_relu(x)
return x
# 创建Unet。要初始化上、下采样层,还有其他的一些层
class Unet(nn.Module):
def __init__(self):
super(Unet, self).__init__()
self.down1 = downSample(3, 64)
self.down2 = downSample(64, 128)
self.down3 = downSample(128, 256)
self.down4 = downSample(256, 512)
self.down5 = downSample(512, 1024)
self.up = nn.Sequential(
nn.ConvTranspose2d(1024, 512,
kernel_size=3,
stride=2,
padding=1,
output_padding=1),
nn.ReLU(inplace=True)
)
self.up1 = upSample(512)
self.up2 = upSample(256)
self.up3 = upSample(128)
self.conv_2 = downSample(128, 64) # 最后两层卷积
self.last = nn.Conv2d(64, 2, kernel_size=1) # 输出层为2分类
def forward(self, x):
x1 = self.down1(x, is_pool=False)
x2 = self.down2(x1)
x3 = self.down3(x2)
x4 = self.down4(x3) # ([512, 64, 64])
print("x4.shape",x4.shape) # x4.shape torch.Size([512, 64, 64])
x5 = self.down5(x4)
print("x5.shape",x5.shape) # x5.shape torch.Size([1024, 32, 32])
x6 = self.up(x5)
print("x6.shape",x6.shape) # x6.shape torch.Size([512, 64, 64])
# 将下采用过程x4的输出与上采样过程x5的输出做一个合并
x6 = torch.cat([x4, x6], dim=0) # dim=0
print("x6.shape",x6.shape) # x6.shape torch.Size([512, 128, 64])
x7 = self.up1(x6)
x7 = torch.cat([x3, x7], dim=0)
x8 = self.up2(x7)
x8 = torch.cat([x2, x8], dim=0)
x9 = self.up3(x8)
x9 = torch.cat([x1, x9], dim=0)
x10 = self.conv_2(x9, is_pool=False)
result = self.last(x10)
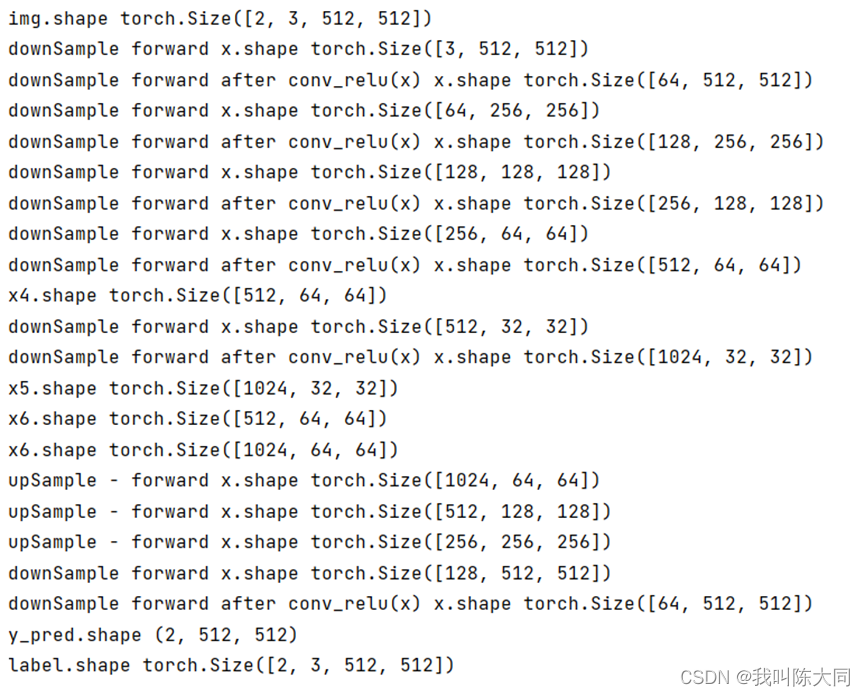
return result神经网络中图像shape变化图:
单张图片预测图





![[数据结构]:09-二分查找(顺序表指针实现形式)(C语言实现)](https://img-blog.csdnimg.cn/4da1fbe0a8354b3592515519f873c81d.png)