前言
在可视化图探索工具 NebulaGraph Explorer 3.1.0 版本中加入了图计算工作流功能,针对 NebulaGraph 提供了图计算的能力,同时可以利用工作流的 nGQL 运行能力支持简单的数据读取,过滤及写入等数据处理功能。
本文将简单分享下 NebulaGraph Explorer 中集成图计算的基本实现原理。
整体架构
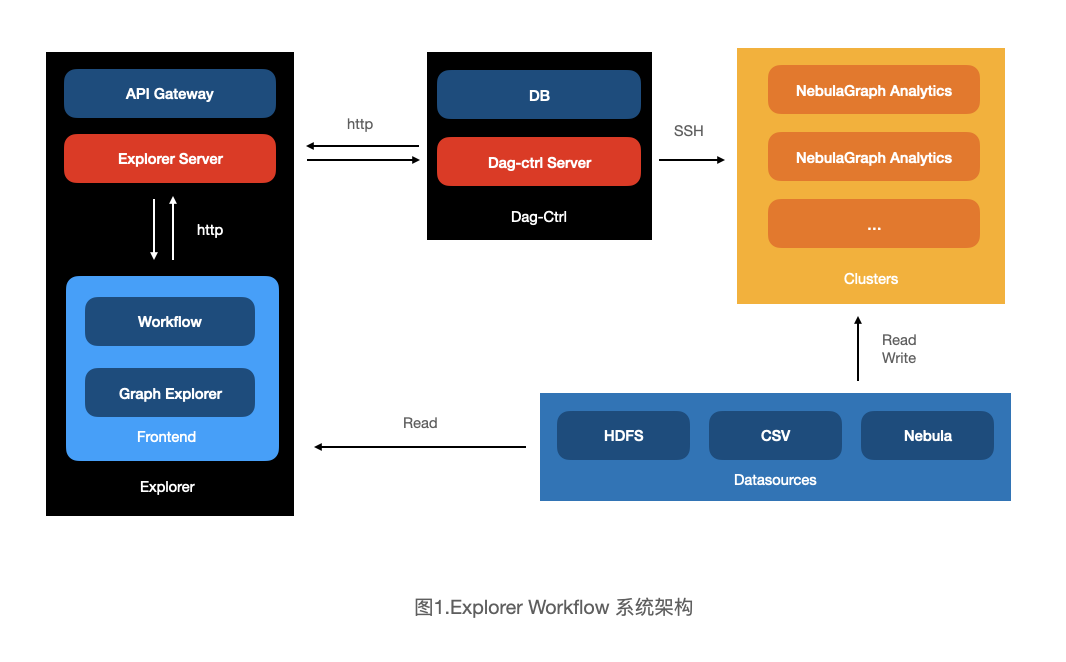
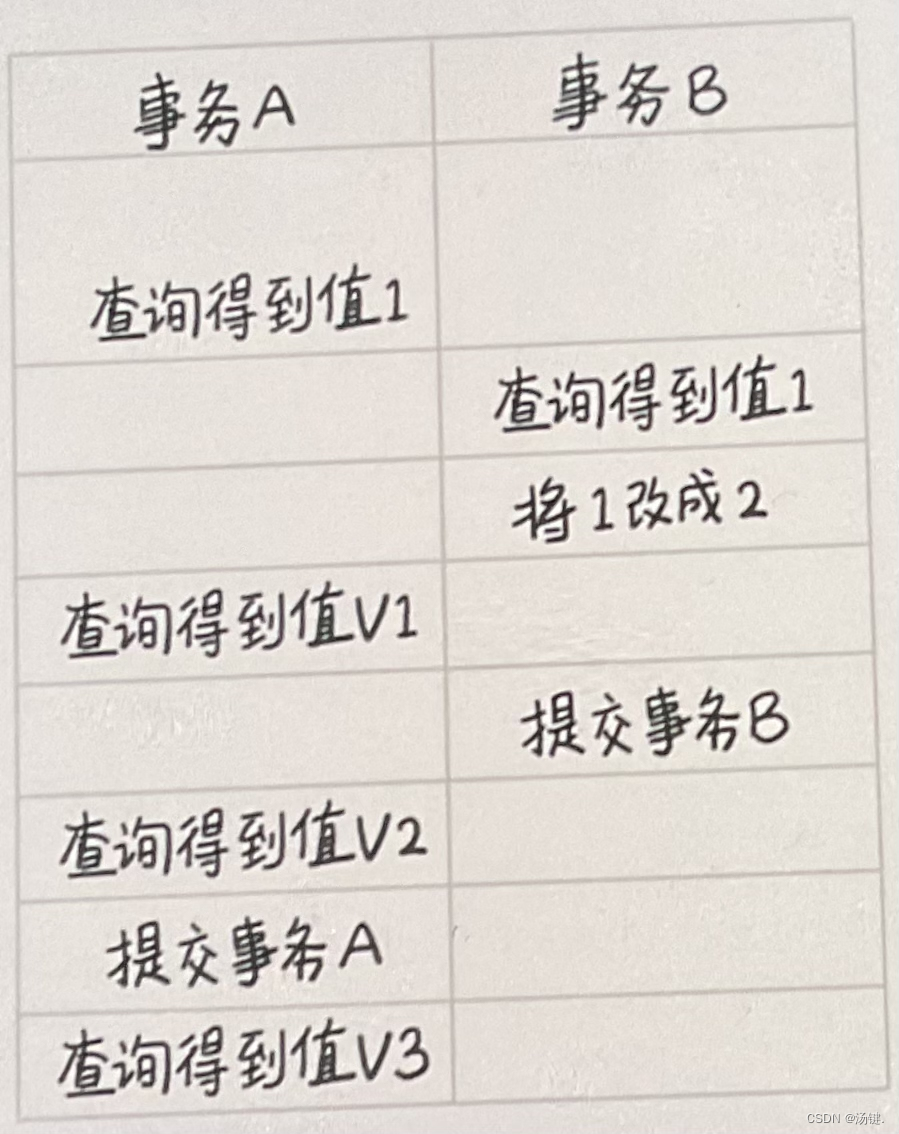
上图 1 描述了 NebulaGraph Explorer Workflow 所涉及的相关系统及调用过程。
其中:
- Explorer:主要负责产出工作流的配置,提供操作工作流的 HTTP API 服务,可视化展示及读取图计算工作流运行结果的能力。
- Dag-Ctrl:主要提供独立解析工作流,下发任务的能力,提供相应的 Job(单次运行的 workflow)和 Task (Job 中的具体任务节点)日志及启停能力,具有独立 web 服务。
- Analytics:提供运行具体任务节点的能力(运行算法,查询,写入等)
- Datasources:目前 Explorer 支持的各类数据源。
前端交互界面
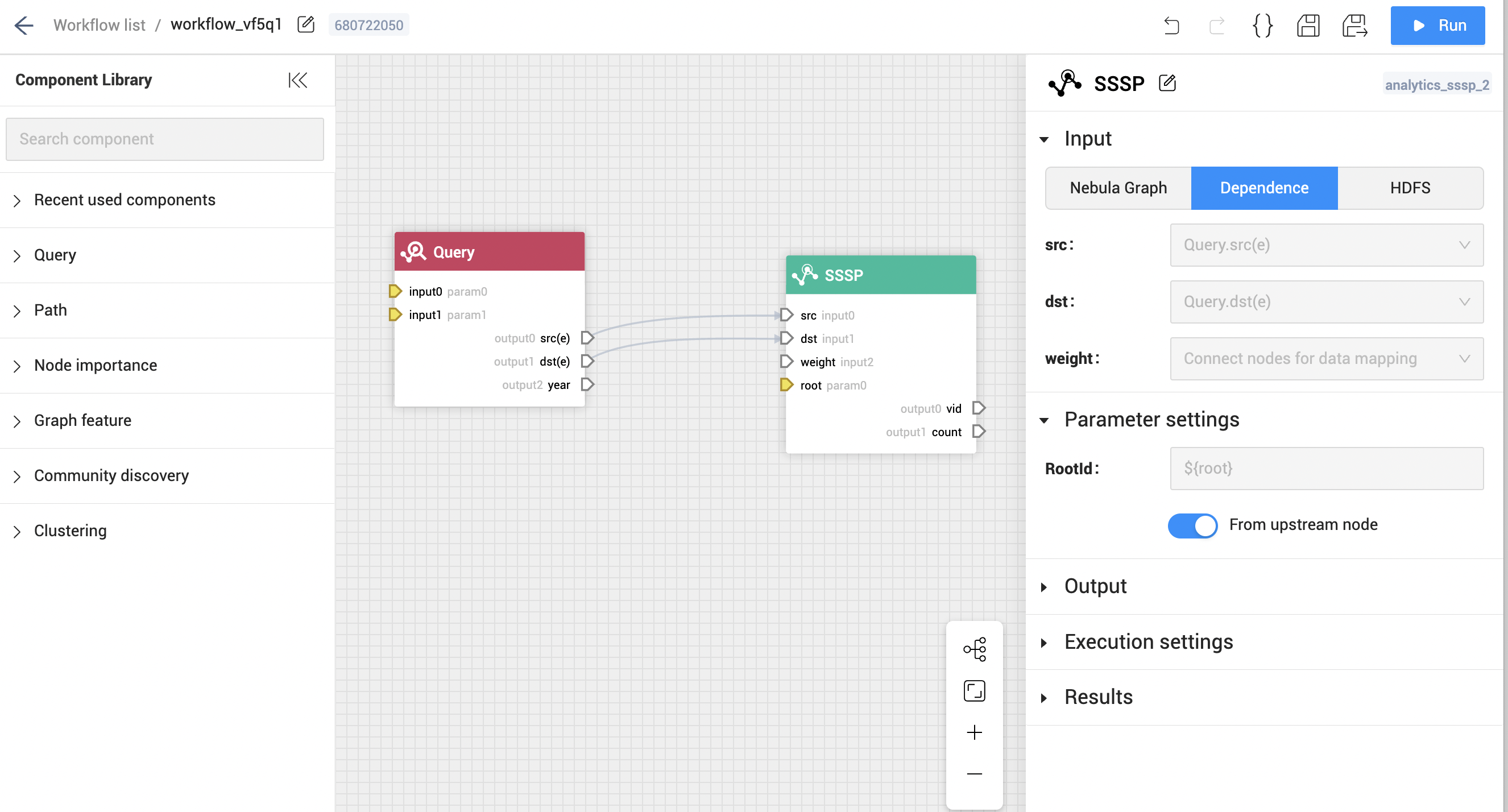
我们在 NebulaGraph Explorer 界面上利用高定制、轻量级的开源自研流程图库 NebulaGraph-VEditor 开发。通过拖拉拽的交互方式,生成 DAG(有向无环图),并生成对应的 Workflow Code(流程描述代码),其中的各种算法节点通过 JSON 配置对应到 DAG-Ctrl 和 Analytics 的算法配置,可以灵活添加新任务节点。其配置结构大致如下:
analytics_sssp:{
name: 'SSSP',//算法名称
input: ['src', 'dst', 'weight'],// 输入字段和列
output: ['vid', 'count'],// 输出字段和列
form: {// 表单配置
root: {
component: 'input',
isParam: true,
label: 'RootId',
},
},
algorithm: ""// Web图算法函数
}
其中,通过设计两种锚点(参数锚点,数据锚点)来进行 Task 节点间的数据交互,中间数据格式统一抽象为 M*N 的 csv 格式。
- 对于数据锚点,可以通过连线,将上游节点的输出锚点匹配到下游节点的输入锚点上,因此对于每个节点来说,数据输出和输入都表达为列的匹配即可。例如 Query 查询节点,其输入输出可以根据 nGQL 动态变化,因此输入输出的锚点也是动态可变的,用户可以自由地将 Query 输出的结果输出到一个或多个计算任务节点中。
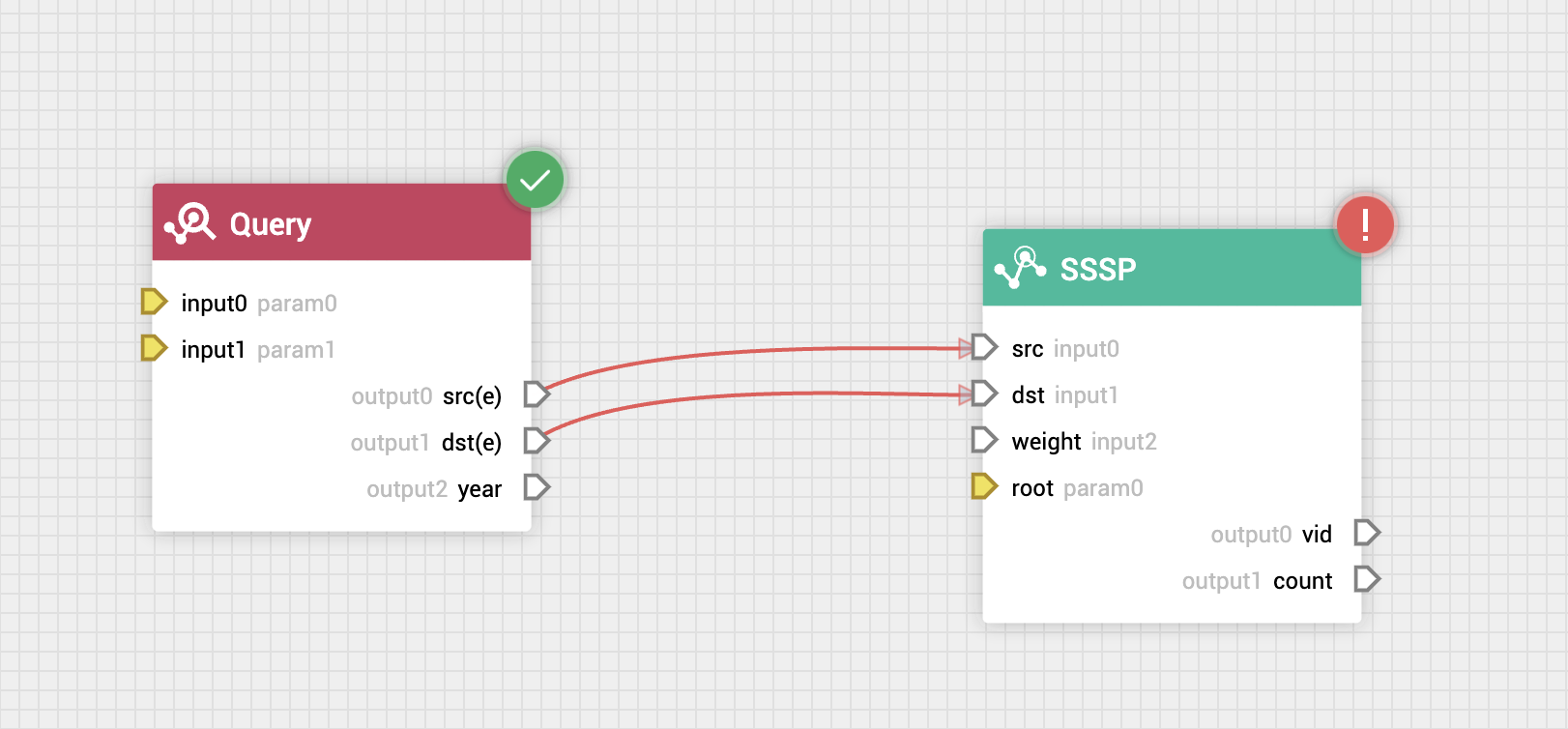
- 对于参数锚点,则可以改变算法的配置参数,或 nGQL 的字符串变量,这对于经常调整算法参数的计算流程非常有用,另外参数锚点也可以来自于上游的数据锚点,例如对图进行 SSSP(单源最短路径)运算,就可以通过参数锚点动态的从上游数据锚点中获取需要进行计算的根节点 ID,如下图:
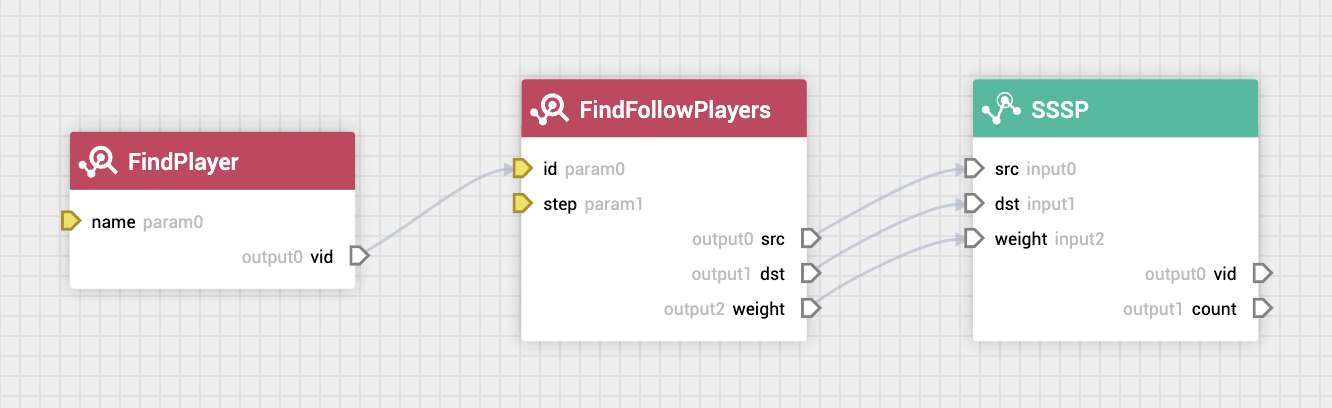
(黄色标识的为参数锚点,白色标识的为数据锚点)
可以利用这个特性,将常用的 nGQL 功能模块抽象为函数节点,快速构建图业务流程。
NebulaGraph Explorer Server 任务管理
NebulaGraph Explorer Server 会存储用户的 workflow 做为模板,用户可以利用前台界面和 API 网关调用 workflow 生成对应 Job 实例,将对应的 workflow 配置逻辑传输到 DAG-Ctrl 中运行。目前只支持手动生成实例,未来会加入定时调度能力,加强对 workflow 和 job 的管理能力。
在生成 Job 实例后,NebulaGraph Explorer Server 端会定时同步 DAG-Ctrl 的 Job 运行情况。
DAG-Ctrl
DAG 对用户配置的有向图进行解析后,会下发到 Analytics 集群中并行运算。这里我们抽离了 DAG 作为独立 Server,支持和 Explorer 分离部署,通过 HTTP 进行数据互通,NebulaGraph Explorer 默认会附带 DAG-Ctrl 包一键启动,并发压力情况较小的情况下,适合部署在一台机器上运行。
由于下发任务需要登入相应的 Analytics 机器,因此需要用户先安装好 Analytics 后,对 DAG 所在机器给予 SSH 授权后才能使用。
DAG 在拿到对应的有向节点任务后会进行依赖优先级排序,依次 SSH 到 Analytics 机器中启动进行运算,并将运算结果地址传入下个节点任务中作为输入。
DAG 通过独立的 DB 用来存储运行过程中产生的任务和日志等数据。
NebulaGraph Analytics
NebulaGraph Analytics 是一款高性能的图计算工具,Explorer 不会附带 Analytics 启动,也不会感知到 Analytics 节点,主要通过 DAG-Ctrl 完成 Analytics 集群节点的交互配置,因此 NebulaGraph Explorer 提供一个配置界面供用户在线配置 DAG 需要的相关配置。
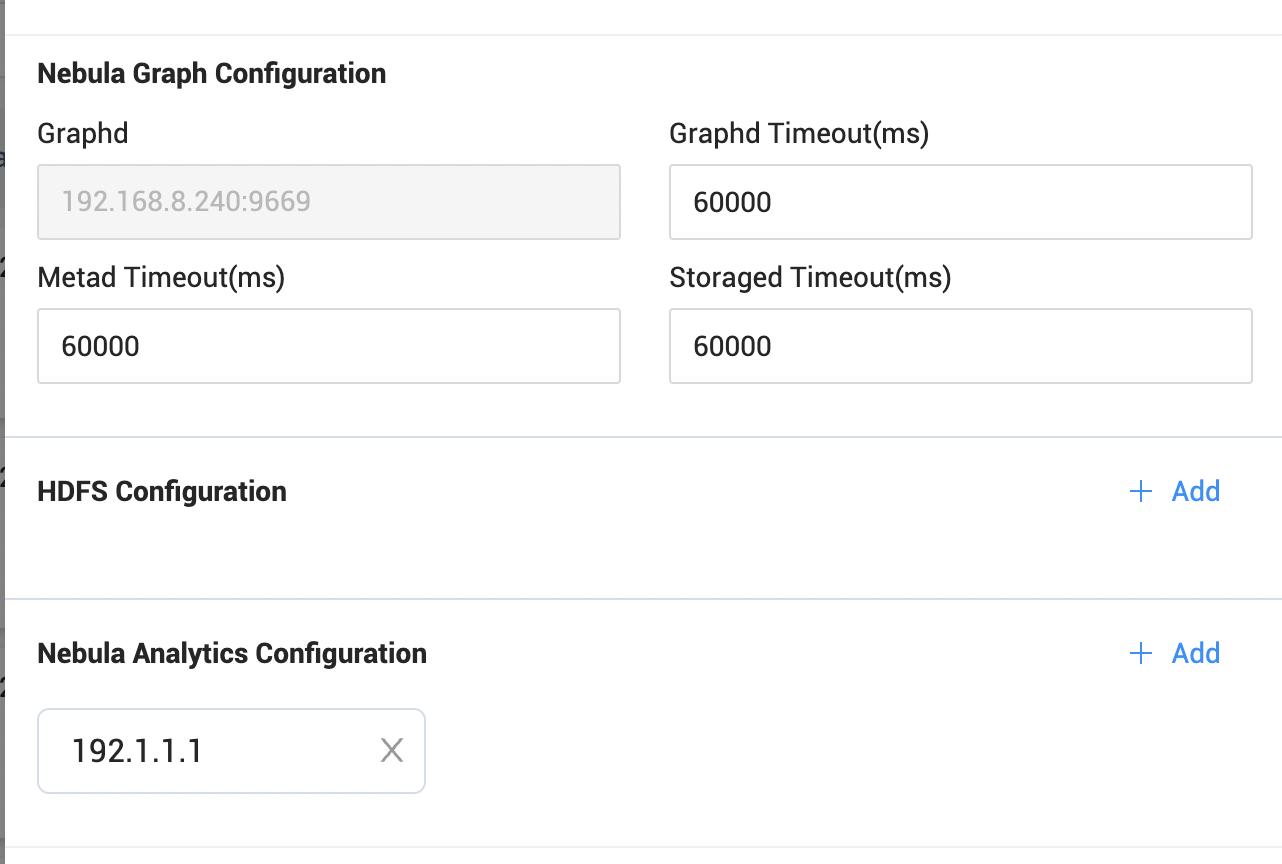
其中,Analytics 集群和 HDFS 地址通过配置直接存储在 DAG-Ctrl 中,NebulaGraph 则会默认在 NebulaGraph Explorer 登录后将登录信息加密后直接传输到 DAG-Ctrl 中。在 Analytics 计算服务运行时会从 DAG-Ctrl 下发的配置中取得需要写入或读取的数据源地址及相关的验证信息,完成计算后将数据写入到指定数据源中。关于 Analytics 的详细介绍可以参考我们之前发布的文章。
工作流结果
NebulaGraph Explorer 对结果的读取主要有两种
- 直接捞取数据源中的数据,如直接读取 NebulaGraph、HDFS、CSV 等,这样在海量数据下可以获取到完整的计算结果。
- 通过 Explorer 可视化查看,因为受限于 HTTP 的传输能力,在大数据量下,取 HDFS 数据会取指定大小的一部分文件回来进行渲染可视化,因此相当于对数据进行了采样后再展示。而对于 NebulaGraph 数据源则会通过分页在前台展示全量工作流结果。
在计算结果导入到 NebulaGraph Explorer 的画布上可视化后,由于计算结果返回的是一系列点 ID,不能展示边和详细数据,因此我们提供了一个自动补齐数据的方案,会请求导入到画布的点之间所有可能的边数据,这样我们可以大致模拟出工作流结果间的图拓扑结构。
图计算可视化
对图计算出的结果集,我们针对图算法的类别进行了针对性的可视化展示。
- 节点重要度、聚类系数、路径长度 - 值归一化到节点尺寸
- 聚类 - 通过颜色标记 label
- 图特征 - 对应形状的边颜色 / 高亮
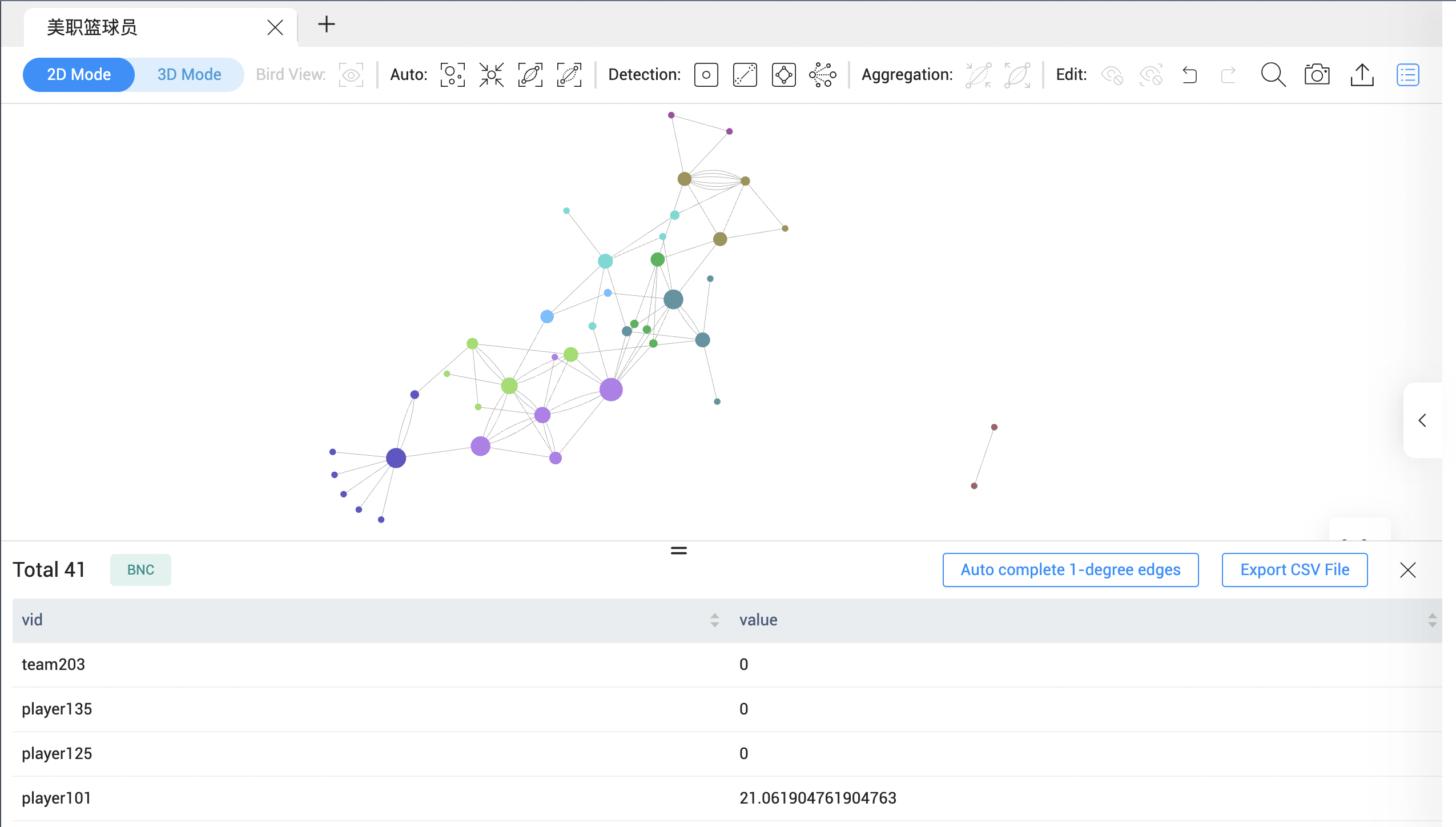
如上图进行 BNC (中介中心性计算)后,节点重要度一目了然。
Web 图计算
除了以上介绍的图计算工作流外,针对小数据量,重可视化分析的场景,NebulaGraph Explorer 额外提供了一套轻量级的 Web 端单机图计算方案,针对画布中用户已探索出的图数据进行实时图计算。
如下图所示,目前支持工作流中的所有图算法,但由于部分不稳定算法(如 LPA), 分布单机及同步异步算法间的差异,少部分图算法会和工作流图计算结果有一些差异。
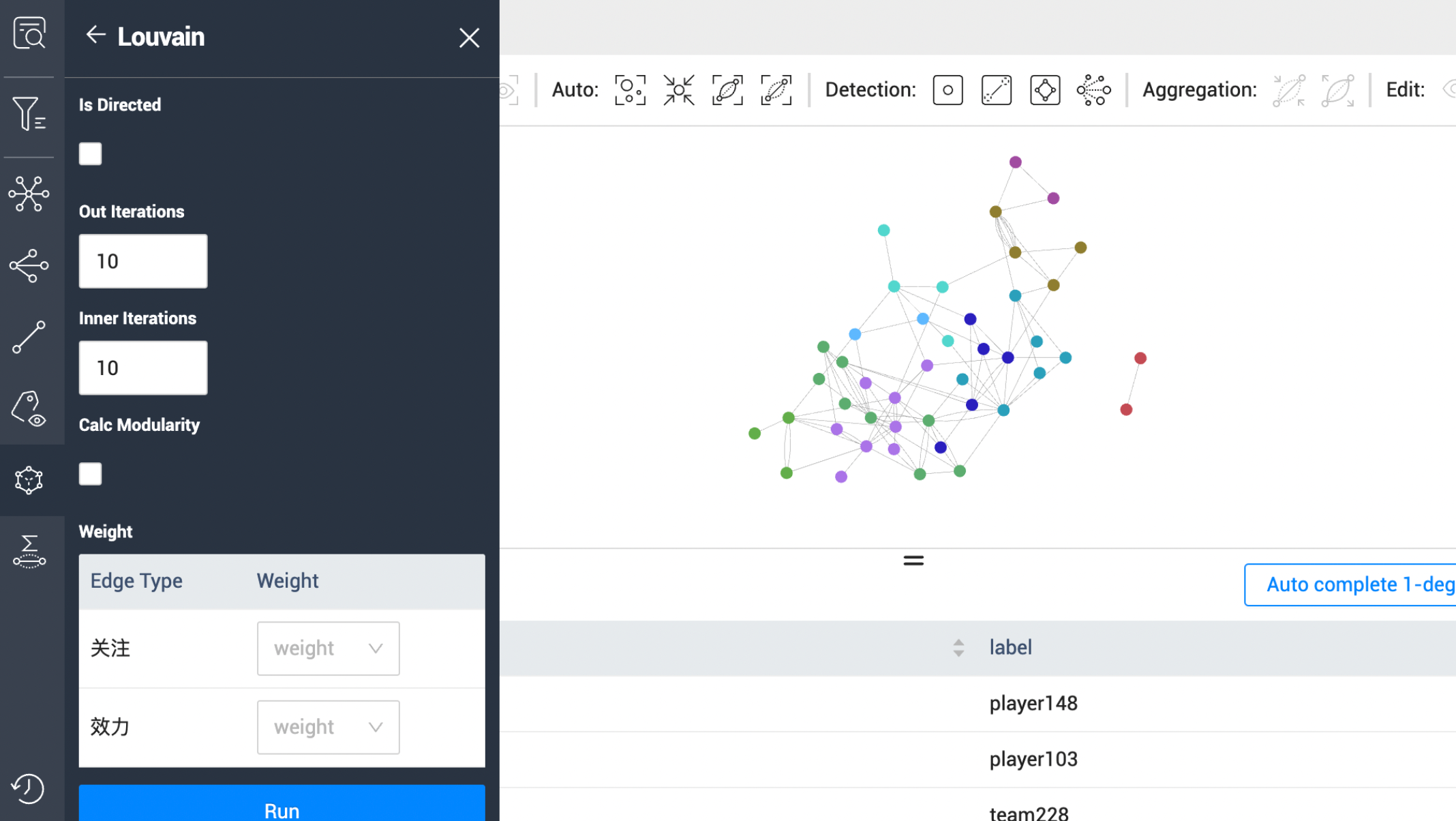
性能方面,我们通过利用 Rust 将图算法编译为 WASM 在 Web 端运行,对于点边数量 1w 左右的场景, Floyd-Warshall 这类 O(n^3) 基本在 2s 左右即可完成,能实时快速的对画布图数据进行可视化分析,提升小数据量下的图算法可视化体验。
关于未来
未来 NebulaGraph Explorer Workflow 会逐渐完善并丰富目前的功能,同时在实际业务需求的基础上对现有功能进行优化,主要包含以下几个方向:
- 加入定时调度,任务监控
- 接入更多算子来实现数据清洗,合并等完备的ETL逻辑
- 接入更多数据源
- 定义完备的图计算可视化语言
欢迎免费试用我们的 NebulaGraph Explorer,体验完整的 workflow 流程。
谢谢你读完本文 (///▽///)
NebulaGraph Desktop,Windows 和 macOS 用户安装图数据库的绿色通道,10s 拉起搞定海量数据的图服务。通道传送门:http://c.nxw.so/aved3
想看源码的小伙伴可以前往 GitHub 阅读、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呢~


![[Datawhale][CS224W]图神经网络(八)](https://img-blog.csdnimg.cn/20210606150918449.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1BvbGFyaXNSaXNpbmdXYXI=,size_16,color_FFFFFF,t_70)