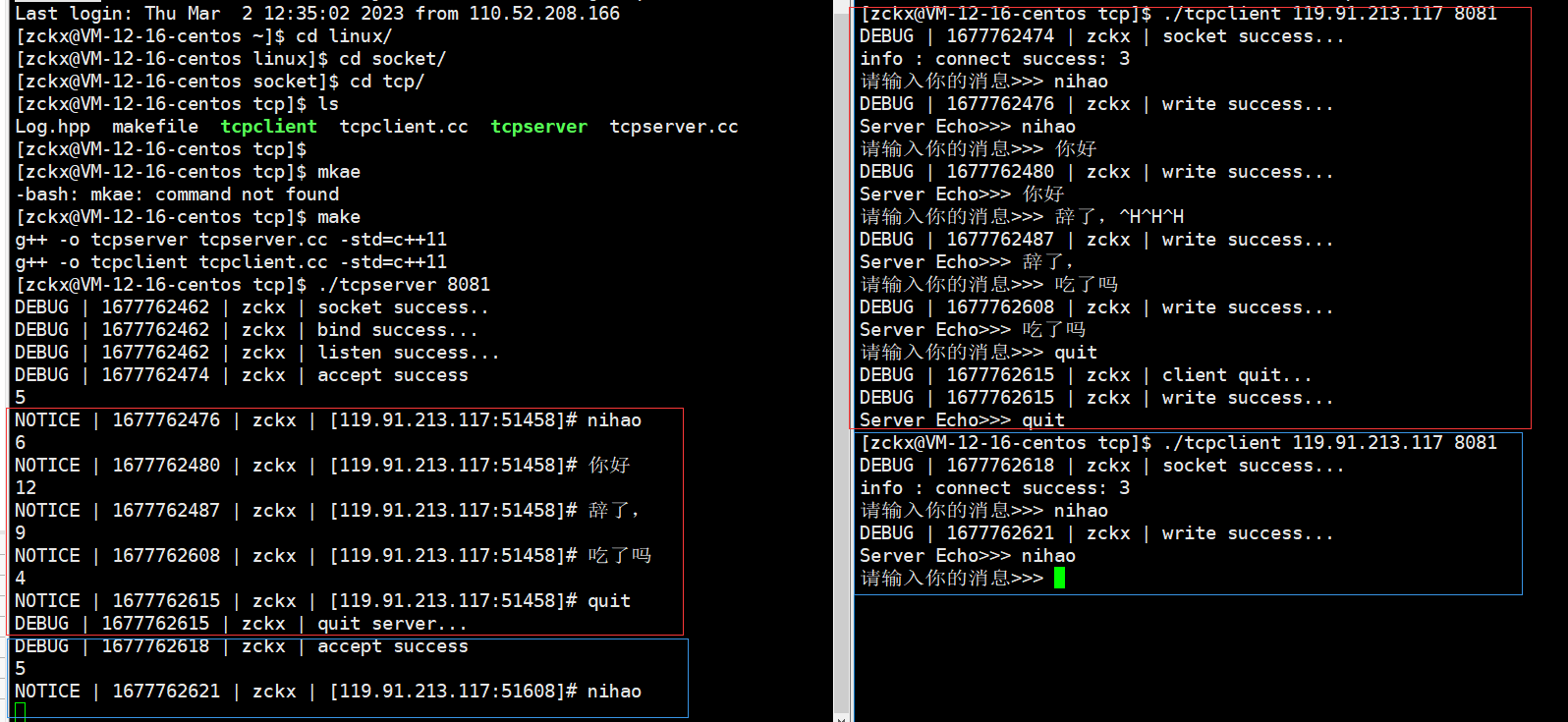
测试人员为了测试某个特定场景,往往需要在测试环境数据库中插入特定的测试数据来满足需求;
性能测试时,常需要在测试环境生成大量可用测试数据来支持性能测试;
建设持续集成持续交付体系时,我们往往也需要在测试环境生成测试数据来保障自动化用例可以持续稳定的运行。

因此,如何在测试数据库批量生成大量可用的测试数据就成为了测试领域一个关键而难解决的问题,本文就来讲讲测试数据批量生成工具的一种实现方案。
测试数据生成的难点
测试数据生成主要难点大致可以归结为以下几个方面:
<1>编写大量的sql语句费事耗力。
<2>由于主键、外键和业务本身的逻辑约束,很难通过写sql一次性大批量插入测试数据,往往的情况是需要对sql的一些关键字段进行一些修改,如对id字段进行修改避免重复。
<3>造数sql脚本复用性差。
传统数据生成工具的问题
传统批量数据生成工具基本思路有两大类:
方式1
通过程序随机的生成测试数据,而实际的实现过程中,对随机的方式没有精准的控制,往往造成以下结果,导致工具无法满足实际需要:
<1>数据随机性太大,造出来的数据和真实数据差别太大。
<2>随机生成的数据往往存在大量不可用的脏数据。
<3>很难解决多表关联的数据生成。
<4>生成的数据往往无法满足特定场景的数据要求。
方式2
精准的针对某个特定场景编写代码造数,这种方式的缺点也很明显:
<1>代码针对性太强,没有通用性。
<2>对测试人员代码能力要求高。
<3>业务逻辑或数据表结构发生变化,需要修改代码,成本高。
测试数据批量生成工具设计思路
能够真正满足实际需要的数据生成工具,应当满足以下要求:
<1>有较好的通用性,不需要关心具体的业务或针对具体的系统。
<2>对数据随机生成有精准的控制能力,可以控制生成字段的长度、类型、能否重复、由什么字符组成等等。
<3>必须解决表关联数据生成的问题。
<4>可配置化,不需要因为数据需求修改而改动程序代码。
本文介绍的工具实现方案遵循的基本思路是:在数据库造数归根结底是针对数据表的每个字段进行造数,需要设计一套配置方法,可以精准的描述每一个表字段数据的生成规则和限制。然后通过工具解析规则,批量生成数据。
举一个简单的例子,有一张数据表的主键是一个长度固定为27位的数字,作为主键它不能重复。这时候对于这个字段的生成规则就有4条:
<1>长度是27;
<2>由纯数字组成;
<3>不能重复;
<4>生成方式是随机生成。
我们只需要将每一张表的每一个字段的数据生成规则都拆解成上边例子一样,然后用特定的格式描述出来,利用程序解析这些规则,就可以批量的生成符合要求的测试数据了。
实践方案整体介绍
通过上一节的例子不难看出,按照本文介绍的方式设计实现批量造数,核心重点在于如何用固定的,程序可解析的格式来描述数据生成的规则。下边就详细介绍一种方式。
我们使用以下的json结构来描述整个数据生成的规则:
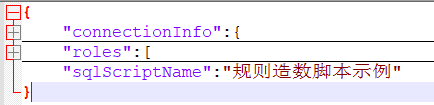
json配置文件最外层有3个字段:
connectionInfo:描述数据库链接信息,将要造数的目标数据信息写在这里。
roles:这是一个json数据,用于描述多张表的数据生成规则,有几张表,这个数组中就有几个元素。
sqlScriptNmae:最终生成的sql脚本名称,本文介绍的工具不是直接将生成的数据写入数据库,而是将生成的数据转换为对应的insert语句,生成sql脚本,以便根据需要执行。
下边看下connectionInfo和roles的具体内容:
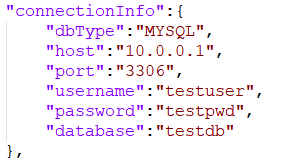
connectionInfo包括数据库类型、host、端口、用户名、密码、连接的数据库名称6个字段,用于描述造数目标数据库链接信息。
再来看一下roles字段:

roles描述数据生成规则,roles是一个数组,数组中的每一项描述一张表的数据生成规则,roles中的每一项有3个字段:
tableName:当前配置规则是哪张表的。
size:想要一次性批量生成数据的数量,如上图一次为tableA表生成100条数据。
fields:一个json数据,里边的每一项对应tableA的一个字段,描述这个字段的详细生成规则。
最后看一下fields中的每一项:

每一个字段的生成规则,都是用上图中的12个字段进行描述,字段说明如下:

字段规则详细说明
上一节看到字段的生成方式总共有9种,本节详细说明这9种生成方式和它们的配合字段如何描述生成规则。
<1>FIXED(固定值)

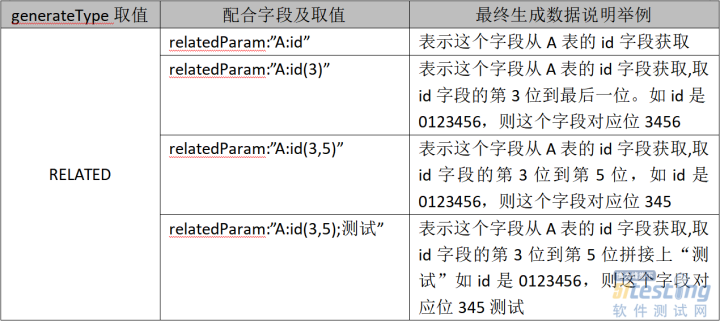
<2>RELATED(关联)
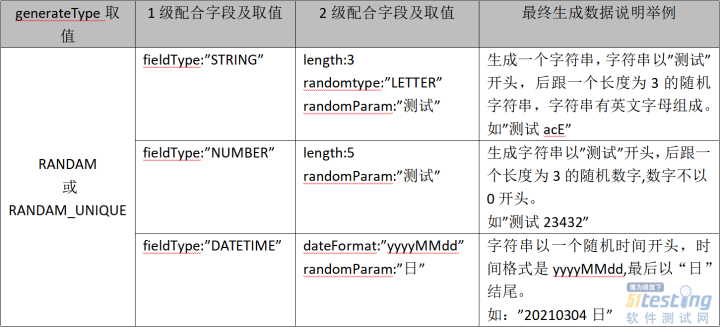
<3>RANDAM(随机)或RANDAM_UNIQUE(随机不重复)
<4>ENUM(枚举)

<5>NUMRANGE(数字范围)或NUMRANGE_UNIQUE(数字范围不重复)

<6>SQL(sql提取)或SQL_UNIQUE(sql提取不重复)

总结
本文提出了一种通过配置字段生成规则来精准批量的生成测试数据的方案。这种方案增加了数据生成的通用性,同时能在较大程度上满足对测试数据精准性的要求。
但本文举例的实践方案也只是这种思路的一个具体实践,相比较方案本身,笔者认为这种规则配置的数据生成思路更加重要。希望这篇文章可以在批量测试数据自动生成方面为你和你的团队提供参考。
最后:
可以到我的个人号:atstudy-js,可以免费领取一份10G软件测试工程师面试宝典文档资料。以及相对应的视频学习教程免费分享!其中包括了有基础知识、Linux必备、Mysql数据库、抓包工具、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试等。
这些测试资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!