Sqoop 概述
Sqoop 是Apache 旗下的一款开源工具,用于Hadoop与关系型数据库之间传送数据,其核心功能有两个:导入数据和导出数据。导入数据是指将MySQL、Oracle等关系型数据库导入Hadoop的HDFS、Hive、HBase等数据存储系统;导出数据是指将Hadoop文件系统中的数据导出到MySQL、Oracle等关系型数据库。Sqoop 本质是一个命令行工具,与HDFS、Hive、MySQL经常一起使用。
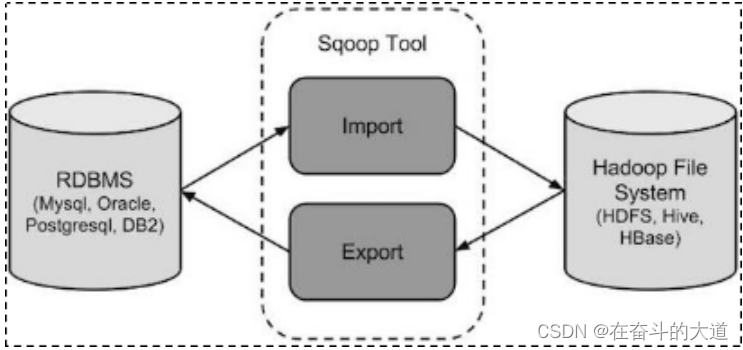
sqoop 工作机制
工作机制:将导入或导出命令翻译成mapreduce程序来实现。
翻译出的 mapreduce中主要是对 inputformat和 outputformat进行定制。
Sqoop 安装
将sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz,上传到CentOS-7的/usr/local 目录下.
温馨提示:sqoop-1.4.6 兼容Hadoop 2.6 及其以上版本。
解压
使用cd 命令切换至/usr/local 目录,然后使用tar -xvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 解压文件。
[root@Hadoop3-master ~]# cd /usr/local
[root@Hadoop3-master local]# tar -xvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz使用mv 命令重命名解压文件sqoop-1.4.7.bin__hadoop-2.6.0 为sqoop
[root@Hadoop3-master local]# mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop配置环境变量
配置对应的环境变量,在 /etc/profile 添加如下 内容:
[root@Hadoop3-master local]# cat /etc/profile
# /etc/profile
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SQOOP_HOME/bin环境变量修改后使用source 命令使配置环境变量生效
[root@Hadoop3-master local]# source /etc/profileMySQL-8驱动赋值
拷贝MySQL-8 的jdbc 驱动至Sqoop的lib 目录
[root@Hadoop3-master local]# cp mysql-connector-java-8.0.12.jar /usr/local/sqoop/lib修改Sqoop 配置文件
使用cd 命令切换至/usr/local/sqoop/config 目录,基于sqoop-env-template.sh 配置脚本模板创建sqoop-env.sh 配置脚本。
[root@Hadoop3-master local]# cd /usr/local/sqoop/conf
[root@Hadoop3-master conf]# ll
总用量 28
-rw-rw-r-- 1 1000 1000 3895 12月 19 2017 oraoop-site-template.xml
-rw-rw-r-- 1 1000 1000 1404 12月 19 2017 sqoop-env-template.cmd
-rwxr-xr-x 1 1000 1000 1345 12月 19 2017 sqoop-env-template.sh
-rw-rw-r-- 1 1000 1000 6044 12月 19 2017 sqoop-site-template.xml
-rw-rw-r-- 1 1000 1000 6044 12月 19 2017 sqoop-site.xml
[root@Hadoop3-master conf]# mv sqoop-env-template.sh sqoop-env.sh
[root@Hadoop3-master conf]# ll
总用量 28
-rw-rw-r-- 1 1000 1000 3895 12月 19 2017 oraoop-site-template.xml
-rwxr-xr-x 1 1000 1000 1345 12月 19 2017 sqoop-env.sh
-rw-rw-r-- 1 1000 1000 1404 12月 19 2017 sqoop-env-template.cmd
-rw-rw-r-- 1 1000 1000 6044 12月 19 2017 sqoop-site-template.xml
-rw-rw-r-- 1 1000 1000 6044 12月 19 2017 sqoop-site.xml打开sqoop-env.sh并编辑下面几行:(温馨提示:先配置Hadoop 安装目录地址)
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/usr/local/hadoop/
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/usr/local/hadoop/
启动Sqoop 工具
不带任何参数启动Sqoop 是没有任何意义的。我们可以使用sqoop version查看Sqoop 的版本信息。
[root@Hadoop3-master local]# sqoop version
Warning: /usr/local/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
2023-02-12 14:44:49,745 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Sqoop 1.4.7
git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8
Compiled by maugli on Thu Dec 21 15:59:58 STD 2017Sqoop 导入数据
Sqoop导入:导入单个表从RDBMS到HDFS,表中的每一行被视为HDFS的记录,所有记录都存储为文本文件的文本数据(或者Avro、sequence文件等二进制数据) 。
关系型数据库导入HDFS语法:
$ sqoop import (generic-args) (import-args) 实战:将MySQL数据库中的用户表(base_house) 全表导入HDFS 中。
MySQL 表结构和初始化数据
-- ----------------------------
-- Table structure for `base_house`
-- ----------------------------
DROP TABLE IF EXISTS `base_house`;
CREATE TABLE `base_house` (
`id` varchar(64) NOT NULL,
`project_no` varchar(128) DEFAULT NULL,
`project_name` varchar(256) DEFAULT NULL,
`project_address` varchar(256) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of base_house
-- ----------------------------
INSERT INTO `base_house` VALUES ('1', '20230301', '龙岗区安居房', '深圳市龙岗区布吉街道1120号');
INSERT INTO `base_house` VALUES ('2', '20230302', '罗湖区安居房', '深圳市罗湖区黄贝岭街道1100号');
导入全表数据到HDFS
下面的命令用于从MySQL数据库服务器中的base_house表导入HDFS:
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --target-dir '/sqoop/base-house' --fields-terminated-by ',' -m 1;如果成功执行,那么会得到下面的输出:
[root@Hadoop3-master bin]# sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --target-dir '/sqoop/base-house' --fields-terminated-by ',' -m 1;
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2023-03-01 15:23:07,047 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
2023-03-01 15:23:07,202 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2023-03-01 15:23:07,405 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
2023-03-01 15:23:07,405 INFO tool.CodeGenTool: Beginning code generation
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
2023-03-01 15:23:07,949 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `base_house` AS t LIMIT 1
2023-03-01 15:23:08,037 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `base_house` AS t LIMIT 1
2023-03-01 15:23:08,052 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
注: /tmp/sqoop-root/compile/134ee3c5a21fd73cc90cac58b11ed36e/base_house.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2023-03-01 15:23:10,324 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/134ee3c5a21fd73cc90cac58b11ed36e/base_house.jar
2023-03-01 15:23:10,350 WARN manager.MySQLManager: It looks like you are importing from mysql.
2023-03-01 15:23:10,350 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
2023-03-01 15:23:10,350 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
2023-03-01 15:23:10,368 INFO mapreduce.ImportJobBase: Beginning import of base_house
2023-03-01 15:23:10,370 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2023-03-01 15:23:10,627 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2023-03-01 15:23:11,818 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2023-03-01 15:23:11,969 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties
2023-03-01 15:23:12,100 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2023-03-01 15:23:12,101 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2023-03-01 15:23:12,694 INFO db.DBInputFormat: Using read commited transaction isolation
2023-03-01 15:23:12,729 INFO mapreduce.JobSubmitter: number of splits:1
2023-03-01 15:23:12,936 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local755394790_0001
2023-03-01 15:23:12,936 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-03-01 15:23:13,290 INFO mapred.LocalDistributedCacheManager: Creating symlink: /tmp/hadoop-root/mapred/local/job_local755394790_0001_58e4f0dd-e37b-41eb-9676-cf81b9c11936/libjars <- /usr/local/sqoop/bin/libjars/*
2023-03-01 15:23:13,302 WARN fs.FileUtil: Command 'ln -s /tmp/hadoop-root/mapred/local/job_local755394790_0001_58e4f0dd-e37b-41eb-9676-cf81b9c11936/libjars /usr/local/sqoop/bin/libjars/*' failed 1 with: ln: 无法创建符号链接"/usr/local/sqoop/bin/libjars/*": 没有那个文件或目录
2023-03-01 15:23:13,303 WARN mapred.LocalDistributedCacheManager: Failed to create symlink: /tmp/hadoop-root/mapred/local/job_local755394790_0001_58e4f0dd-e37b-41eb-9676-cf81b9c11936/libjars <- /usr/local/sqoop/bin/libjars/*
2023-03-01 15:23:13,303 INFO mapred.LocalDistributedCacheManager: Localized file:/tmp/hadoop/mapred/staging/root755394790/.staging/job_local755394790_0001/libjars as file:/tmp/hadoop-root/mapred/local/job_local755394790_0001_58e4f0dd-e37b-41eb-9676-cf81b9c11936/libjars
2023-03-01 15:23:13,394 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
2023-03-01 15:23:13,395 INFO mapreduce.Job: Running job: job_local755394790_0001
2023-03-01 15:23:13,401 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2023-03-01 15:23:13,423 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2023-03-01 15:23:13,423 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2023-03-01 15:23:13,426 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2023-03-01 15:23:13,538 INFO mapred.LocalJobRunner: Waiting for map tasks
2023-03-01 15:23:13,539 INFO mapred.LocalJobRunner: Starting task: attempt_local755394790_0001_m_000000_0
2023-03-01 15:23:13,595 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2023-03-01 15:23:13,597 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2023-03-01 15:23:13,645 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-01 15:23:13,671 INFO db.DBInputFormat: Using read commited transaction isolation
2023-03-01 15:23:13,679 INFO mapred.MapTask: Processing split: 1=1 AND 1=1
2023-03-01 15:23:13,825 INFO db.DBRecordReader: Working on split: 1=1 AND 1=1
2023-03-01 15:23:13,826 INFO db.DBRecordReader: Executing query: SELECT `id`, `project_no`, `project_name`, `project_address` FROM `base_house` AS `base_house` WHERE ( 1=1 ) AND ( 1=1 )
2023-03-01 15:23:13,840 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-01 15:23:13,847 INFO mapred.LocalJobRunner:
2023-03-01 15:23:14,322 INFO mapred.Task: Task:attempt_local755394790_0001_m_000000_0 is done. And is in the process of committing
2023-03-01 15:23:14,328 INFO mapred.LocalJobRunner:
2023-03-01 15:23:14,328 INFO mapred.Task: Task attempt_local755394790_0001_m_000000_0 is allowed to commit now
2023-03-01 15:23:14,363 INFO output.FileOutputCommitter: Saved output of task 'attempt_local755394790_0001_m_000000_0' to hdfs://Hadoop3-master:9000/sqoop/base-house
2023-03-01 15:23:14,367 INFO mapred.LocalJobRunner: map
2023-03-01 15:23:14,367 INFO mapred.Task: Task 'attempt_local755394790_0001_m_000000_0' done.
2023-03-01 15:23:14,380 INFO mapred.Task: Final Counters for attempt_local755394790_0001_m_000000_0: Counters: 21
File System Counters
FILE: Number of bytes read=6729
FILE: Number of bytes written=567339
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=0
HDFS: Number of bytes written=139
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=2
Map output records=2
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=228
Total committed heap usage (bytes)=215482368
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=139
2023-03-01 15:23:14,381 INFO mapred.LocalJobRunner: Finishing task: attempt_local755394790_0001_m_000000_0
2023-03-01 15:23:14,381 INFO mapred.LocalJobRunner: map task executor complete.
2023-03-01 15:23:14,412 INFO mapreduce.Job: Job job_local755394790_0001 running in uber mode : false
2023-03-01 15:23:14,415 INFO mapreduce.Job: map 100% reduce 0%
2023-03-01 15:23:14,419 INFO mapreduce.Job: Job job_local755394790_0001 completed successfully
2023-03-01 15:23:14,444 INFO mapreduce.Job: Counters: 21
File System Counters
FILE: Number of bytes read=6729
FILE: Number of bytes written=567339
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=0
HDFS: Number of bytes written=139
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=2
Map output records=2
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=228
Total committed heap usage (bytes)=215482368
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=139
2023-03-01 15:23:14,449 INFO mapreduce.ImportJobBase: Transferred 139 bytes in 2.6131 seconds (53.1939 bytes/sec)
2023-03-01 15:23:14,452 INFO mapreduce.ImportJobBase: Retrieved 2 records.为了验证在HDFS导入的数据,请使用以下命令查看导入的数据:
# 查看指定文件夹详细信息
[root@Hadoop3-master bin]# hadoop fs -ls -R /sqoop/base-house
# 查看指定文件内容
[root@Hadoop3-master bin]# hadoop fs -cat /sqoop/base-house/part-m-00000[root@Hadoop3-master compile]# cd /usr/local/hadoop/bin
[root@Hadoop3-master bin]# hadoop fs -ls -R /sqoop/base-house
-rw-r--r-- 3 root supergroup 0 2023-03-01 15:23 /sqoop/base-house/_SUCCESS
-rw-r--r-- 3 root supergroup 139 2023-03-01 15:23 /sqoop/base-house/part-m-00000
[root@Hadoop3-master bin]# hadoop fs -cat /sqoop/base-house/part-m-00000
1,20230301,龙岗区安居房,深圳市龙岗区布吉街道1120号
2,20230302,罗湖区安居房,深圳市罗湖区黄贝岭街道1100号实战:将MySQL数据库中的用户表(base_house) 条件导入HDFS 中。
向base_house 表中新增一条记录
INSERT INTO `base_house` VALUES ('3', '20230301', '南山区安居房', '深圳市南山区高新科技园1001号');导入满足条件数据到HDFS
下面的命令用于从MySQL数据库服务器查询满足条件的记录base_house表导入HDFS:
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --target-dir '/sqoop/base-house-query' --fields-terminated-by ',' -m 1 --query 'select * from base_house where id=3 and $CONDITIONS';如果成功执行,那么会得到下面的输出:
[root@Hadoop3-master sqoop]# sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --target-dir '/sqoop/base-house-query' --fields-terminated-by ',' -m 1 --query 'select * from base_house where id=3 and $CONDITIONS';
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2023-03-01 16:23:31,744 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
2023-03-01 16:23:31,878 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2023-03-01 16:23:32,022 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
2023-03-01 16:23:32,022 INFO tool.CodeGenTool: Beginning code generation
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
2023-03-01 16:23:32,459 INFO manager.SqlManager: Executing SQL statement: select * from base_house where id=3 and (1 = 0)
2023-03-01 16:23:32,503 INFO manager.SqlManager: Executing SQL statement: select * from base_house where id=3 and (1 = 0)
2023-03-01 16:23:32,537 INFO manager.SqlManager: Executing SQL statement: select * from base_house where id=3 and (1 = 0)
2023-03-01 16:23:32,551 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
注: /tmp/sqoop-root/compile/173426e674f02b7f7b2381f41f12a9a5/QueryResult.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2023-03-01 16:23:34,319 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/173426e674f02b7f7b2381f41f12a9a5/QueryResult.jar
2023-03-01 16:23:34,344 INFO mapreduce.ImportJobBase: Beginning query import.
2023-03-01 16:23:34,345 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2023-03-01 16:23:34,529 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2023-03-01 16:23:35,418 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2023-03-01 16:23:35,532 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties
2023-03-01 16:23:35,631 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2023-03-01 16:23:35,631 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2023-03-01 16:23:36,113 INFO db.DBInputFormat: Using read commited transaction isolation
2023-03-01 16:23:36,138 INFO mapreduce.JobSubmitter: number of splits:1
2023-03-01 16:23:36,285 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local791858248_0001
2023-03-01 16:23:36,285 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-03-01 16:23:36,549 INFO mapred.LocalDistributedCacheManager: Creating symlink: /tmp/hadoop-root/mapred/local/job_local791858248_0001_84c3a417-8c91-4c3c-a754-2792257a32fd/libjars <- /usr/local/sqoop/libjars/*
2023-03-01 16:23:36,559 WARN fs.FileUtil: Command 'ln -s /tmp/hadoop-root/mapred/local/job_local791858248_0001_84c3a417-8c91-4c3c-a754-2792257a32fd/libjars /usr/local/sqoop/libjars/*' failed 1 with: ln: 无法创建符号链接"/usr/local/sqoop/libjars/*": 没有那个文件或目录
2023-03-01 16:23:36,559 WARN mapred.LocalDistributedCacheManager: Failed to create symlink: /tmp/hadoop-root/mapred/local/job_local791858248_0001_84c3a417-8c91-4c3c-a754-2792257a32fd/libjars <- /usr/local/sqoop/libjars/*
2023-03-01 16:23:36,560 INFO mapred.LocalDistributedCacheManager: Localized file:/tmp/hadoop/mapred/staging/root791858248/.staging/job_local791858248_0001/libjars as file:/tmp/hadoop-root/mapred/local/job_local791858248_0001_84c3a417-8c91-4c3c-a754-2792257a32fd/libjars
2023-03-01 16:23:36,621 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
2023-03-01 16:23:36,623 INFO mapreduce.Job: Running job: job_local791858248_0001
2023-03-01 16:23:36,626 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2023-03-01 16:23:36,636 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2023-03-01 16:23:36,636 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2023-03-01 16:23:36,637 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2023-03-01 16:23:36,719 INFO mapred.LocalJobRunner: Waiting for map tasks
2023-03-01 16:23:36,721 INFO mapred.LocalJobRunner: Starting task: attempt_local791858248_0001_m_000000_0
2023-03-01 16:23:36,766 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2023-03-01 16:23:36,767 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2023-03-01 16:23:36,807 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-01 16:23:36,825 INFO db.DBInputFormat: Using read commited transaction isolation
2023-03-01 16:23:36,830 INFO mapred.MapTask: Processing split: 1=1 AND 1=1
2023-03-01 16:23:36,942 INFO db.DBRecordReader: Working on split: 1=1 AND 1=1
2023-03-01 16:23:36,942 INFO db.DBRecordReader: Executing query: select * from base_house where id=3 and ( 1=1 ) AND ( 1=1 )
2023-03-01 16:23:37,119 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-01 16:23:37,124 INFO mapred.LocalJobRunner:
2023-03-01 16:23:37,326 INFO mapred.Task: Task:attempt_local791858248_0001_m_000000_0 is done. And is in the process of committing
2023-03-01 16:23:37,333 INFO mapred.LocalJobRunner:
2023-03-01 16:23:37,333 INFO mapred.Task: Task attempt_local791858248_0001_m_000000_0 is allowed to commit now
2023-03-01 16:23:37,371 INFO output.FileOutputCommitter: Saved output of task 'attempt_local791858248_0001_m_000000_0' to hdfs://Hadoop3-master:9000/sqoop/base-house-query
2023-03-01 16:23:37,373 INFO mapred.LocalJobRunner: map
2023-03-01 16:23:37,373 INFO mapred.Task: Task 'attempt_local791858248_0001_m_000000_0' done.
2023-03-01 16:23:37,392 INFO mapred.Task: Final Counters for attempt_local791858248_0001_m_000000_0: Counters: 21
File System Counters
FILE: Number of bytes read=6749
FILE: Number of bytes written=566883
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=0
HDFS: Number of bytes written=71
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=1
Map output records=1
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=155
Total committed heap usage (bytes)=216530944
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=71
2023-03-01 16:23:37,392 INFO mapred.LocalJobRunner: Finishing task: attempt_local791858248_0001_m_000000_0
2023-03-01 16:23:37,393 INFO mapred.LocalJobRunner: map task executor complete.
2023-03-01 16:23:37,633 INFO mapreduce.Job: Job job_local791858248_0001 running in uber mode : false
2023-03-01 16:23:37,635 INFO mapreduce.Job: map 100% reduce 0%
2023-03-01 16:23:37,641 INFO mapreduce.Job: Job job_local791858248_0001 completed successfully
2023-03-01 16:23:37,660 INFO mapreduce.Job: Counters: 21
File System Counters
FILE: Number of bytes read=6749
FILE: Number of bytes written=566883
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=0
HDFS: Number of bytes written=71
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=1
Map output records=1
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=155
Total committed heap usage (bytes)=216530944
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=71
2023-03-01 16:23:37,664 INFO mapreduce.ImportJobBase: Transferred 71 bytes in 2.2319 seconds (31.8115 bytes/sec)
2023-03-01 16:23:37,666 INFO mapreduce.ImportJobBase: Retrieved 1 records.温馨提示:where语句中必须有 $CONDITIONS,表示将查询结果带回。
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据:
# 查看指定文件夹详细信息
[root@Hadoop3-master bin]# hadoop fs -ls -R /sqoop/base-house-query
# 查看指定文件内容
[root@Hadoop3-master bin]# hadoop fs -cat /sqoop/base-house-query/part-m-00000[root@Hadoop3-master sqoop]# hadoop fs -ls -R /sqoop/base-house-query
-rw-r--r-- 3 root supergroup 0 2023-03-01 16:23 /sqoop/base-house-query/_SUCCESS
-rw-r--r-- 3 root supergroup 71 2023-03-01 16:23 /sqoop/base-house-query/part-m-00000
[root@Hadoop3-master sqoop]# hadoop fs -cat /sqoop/base-house-query/part-m-0000
cat: `/sqoop/base-house-query/part-m-0000': No such file or directory
[root@Hadoop3-master sqoop]# hadoop fs -cat /sqoop/base-house-query/part-m-00000
3,20230301,南山区安居房,深圳市南山区高新科技园1001号条件导入与全表导入的区别:
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --target-dir '/sqoop/base-house' --fields-terminated-by ',' -m 1;
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --target-dir '/sqoop/base-house-query' --fields-terminated-by ',' -m 1 --query 'select * from base_house where id=3 and $CONDITIONS';
条件导入移除 --table 属性配置
条件导入新增 --query 查询SQL实战:将MySQL数据库中的用户表(base_house) 指定字段导入HDFS 中。
下面的命令用于从MySQL数据库服务器查询指定字段记录base_house表导入HDFS:
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --columns id,project_no,project_name --target-dir '/sqoop/base-house-column' --fields-terminated-by ',' -m 1;如果成功执行,那么会得到下面的输出:
[root@Hadoop3-master bin]# sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --columns id,project_no,project_name --target-dir '/sqoop/base-house-column' --fields-terminated-by ',' -m 1;
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2023-03-01 17:16:55,991 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
2023-03-01 17:16:56,120 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2023-03-01 17:16:56,278 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
2023-03-01 17:16:56,278 INFO tool.CodeGenTool: Beginning code generation
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
2023-03-01 17:16:56,672 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `base_house` AS t LIMIT 1
2023-03-01 17:16:56,746 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `base_house` AS t LIMIT 1
2023-03-01 17:16:56,756 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
注: /tmp/sqoop-root/compile/4901fb073c2a588df1269835d31e467a/base_house.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2023-03-01 17:16:58,483 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/4901fb073c2a588df1269835d31e467a/base_house.jar
2023-03-01 17:16:58,502 WARN manager.MySQLManager: It looks like you are importing from mysql.
2023-03-01 17:16:58,502 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
2023-03-01 17:16:58,502 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
2023-03-01 17:16:58,517 INFO mapreduce.ImportJobBase: Beginning import of base_house
2023-03-01 17:16:58,518 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2023-03-01 17:16:58,703 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2023-03-01 17:16:59,676 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2023-03-01 17:16:59,796 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties
2023-03-01 17:16:59,897 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2023-03-01 17:16:59,898 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2023-03-01 17:17:00,381 INFO db.DBInputFormat: Using read commited transaction isolation
2023-03-01 17:17:00,408 INFO mapreduce.JobSubmitter: number of splits:1
2023-03-01 17:17:00,575 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local620808761_0001
2023-03-01 17:17:00,575 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-03-01 17:17:00,903 INFO mapred.LocalDistributedCacheManager: Creating symlink: /tmp/hadoop-root/mapred/local/job_local620808761_0001_aa086058-7939-434b-a562-64ce6ca45f63/libjars <- /usr/local/sqoop/bin/libjars/*
2023-03-01 17:17:00,916 WARN fs.FileUtil: Command 'ln -s /tmp/hadoop-root/mapred/local/job_local620808761_0001_aa086058-7939-434b-a562-64ce6ca45f63/libjars /usr/local/sqoop/bin/libjars/*' failed 1 with: ln: 无法创建符号链接"/usr/local/sqoop/bin/libjars/*": 没有那个文件或目录
2023-03-01 17:17:00,916 WARN mapred.LocalDistributedCacheManager: Failed to create symlink: /tmp/hadoop-root/mapred/local/job_local620808761_0001_aa086058-7939-434b-a562-64ce6ca45f63/libjars <- /usr/local/sqoop/bin/libjars/*
2023-03-01 17:17:00,917 INFO mapred.LocalDistributedCacheManager: Localized file:/tmp/hadoop/mapred/staging/root620808761/.staging/job_local620808761_0001/libjars as file:/tmp/hadoop-root/mapred/local/job_local620808761_0001_aa086058-7939-434b-a562-64ce6ca45f63/libjars
2023-03-01 17:17:00,984 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
2023-03-01 17:17:00,986 INFO mapreduce.Job: Running job: job_local620808761_0001
2023-03-01 17:17:00,994 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2023-03-01 17:17:01,006 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2023-03-01 17:17:01,006 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2023-03-01 17:17:01,007 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2023-03-01 17:17:01,104 INFO mapred.LocalJobRunner: Waiting for map tasks
2023-03-01 17:17:01,121 INFO mapred.LocalJobRunner: Starting task: attempt_local620808761_0001_m_000000_0
2023-03-01 17:17:01,176 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
2023-03-01 17:17:01,178 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2023-03-01 17:17:01,217 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-01 17:17:01,239 INFO db.DBInputFormat: Using read commited transaction isolation
2023-03-01 17:17:01,244 INFO mapred.MapTask: Processing split: 1=1 AND 1=1
2023-03-01 17:17:01,363 INFO db.DBRecordReader: Working on split: 1=1 AND 1=1
2023-03-01 17:17:01,363 INFO db.DBRecordReader: Executing query: SELECT `id`, `project_no`, `project_name` FROM `base_house` AS `base_house` WHERE ( 1=1 ) AND ( 1=1 )
2023-03-01 17:17:01,373 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-01 17:17:01,378 INFO mapred.LocalJobRunner:
2023-03-01 17:17:01,592 INFO mapred.Task: Task:attempt_local620808761_0001_m_000000_0 is done. And is in the process of committing
2023-03-01 17:17:01,598 INFO mapred.LocalJobRunner:
2023-03-01 17:17:01,599 INFO mapred.Task: Task attempt_local620808761_0001_m_000000_0 is allowed to commit now
2023-03-01 17:17:01,636 INFO output.FileOutputCommitter: Saved output of task 'attempt_local620808761_0001_m_000000_0' to hdfs://Hadoop3-master:9000/sqoop/base-house-column
2023-03-01 17:17:01,640 INFO mapred.LocalJobRunner: map
2023-03-01 17:17:01,641 INFO mapred.Task: Task 'attempt_local620808761_0001_m_000000_0' done.
2023-03-01 17:17:01,652 INFO mapred.Task: Final Counters for attempt_local620808761_0001_m_000000_0: Counters: 21
File System Counters
FILE: Number of bytes read=5937
FILE: Number of bytes written=566683
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=0
HDFS: Number of bytes written=90
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=214433792
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=90
2023-03-01 17:17:01,653 INFO mapred.LocalJobRunner: Finishing task: attempt_local620808761_0001_m_000000_0
2023-03-01 17:17:01,654 INFO mapred.LocalJobRunner: map task executor complete.
2023-03-01 17:17:01,999 INFO mapreduce.Job: Job job_local620808761_0001 running in uber mode : false
2023-03-01 17:17:02,001 INFO mapreduce.Job: map 100% reduce 0%
2023-03-01 17:17:02,005 INFO mapreduce.Job: Job job_local620808761_0001 completed successfully
2023-03-01 17:17:02,020 INFO mapreduce.Job: Counters: 21
File System Counters
FILE: Number of bytes read=5937
FILE: Number of bytes written=566683
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=0
HDFS: Number of bytes written=90
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=214433792
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=90
2023-03-01 17:17:02,023 INFO mapreduce.ImportJobBase: Transferred 90 bytes in 2.3355 seconds (38.5354 bytes/sec)
2023-03-01 17:17:02,024 INFO mapreduce.ImportJobBase: Retrieved 3 records.为了验证在HDFS导入的数据,请使用以下命令查看导入的数据:
# 查看指定文件夹详细信息
[root@Hadoop3-master bin]# hadoop fs -ls -R /sqoop/base-house-column
# 查看指定文件内容
[root@Hadoop3-master bin]# hadoop fs -cat /sqoop/base-house-column/part-m-00000[root@Hadoop3-master bin]# hadoop fs -cat /sqoop/base-house-column/part-m-00000
1,20230301,龙岗区安居房
2,20230302,罗湖区安居房
3,20230301,南山区安居房指定字段导入与全表导入的区别:
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --target-dir '/sqoop/base-house' --fields-terminated-by ',' -m 1;
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --columns id,project_no,project_name --target-dir '/sqoop/base-house-column' --fields-terminated-by ',' -m 1;
指定字段导入新增 --columns 查询指定字段实战:将MySQL数据库中的用户表(base_house) 通过Where 条件筛选记录导入HDFS 中。
下面的命令用于从MySQL数据库服务器查询满足where条件记录base_house表导入HDFS:
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --where "id =3" \ --target-dir '/sqoop/base-house-where' --fields-terminated-by ',' -m 1;相关验证截图:省略****
wher导入与全表导入的区别:
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --target-dir '/sqoop/base-house' --fields-terminated-by ',' -m 1;
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --where "id =3" \ --target-dir '/sqoop/base-house-where' --fields-terminated-by ',' -m 1;
where导入新增 --where 查询条件实战:将MySQL数据库中的用户表(base_house) 通过append增量导入HDFS 中。
下面的命令用于从MySQL数据库服务器通过append 增量方式导入HDFS:
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --target-dir '/sqoop/base-house-append' --fields-terminated-by ',' --query 'select * from base_house where $CONDITIONS' --split-by id -m 2 --incremental append --check-column id --last-value 0;指定参数说明:
--split-by 和 -m 结合实现numberReduceTasks并行。
--check-column id 和--last-value 0 结合实现类似where id > 0 的查询效果
相关验证截图:省略****
append增量导入与全量导入区别:
添加模式和查询条件:
--incremental append # 模式
--check-column id --last-value 0 #查询条件
实战:将MySQL数据库中的用户表(base_house) 通过lastmodified增量导入HDFS 中。
下面的命令用于从MySQL数据库服务器通过lastmodified 增量方式导入HDFS:
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --target-dir '/sqoop/base-house-append' --fields-terminated-by ',' --query 'select * from base_house where $CONDITIONS' --split-by id -m 2 --incremental lastmodified --check-column id --last-value 2;指定参数说明:
--incremental 增量模式(lastmodified/append)。
--check-column id --last-value 2 结合实现类似where id > 2 的查询效果
相关验证截图:省略****
lastmodified增量导入与全量导入区别:
添加模式和查询条件:
--incremental lastmodified # 模式
--check-column id --last-value 2 #查询条件
关系型数据库导入HBASE
第一步:在HBase 先创建namespace,名称为:house
hbase(main):001:0> list_namespace
NAMESPACE
default
hbase
test
3 row(s)
Took 0.9580 seconds
hbase(main):002:0> create_namespace "house"
Took 0.2816 seconds第二步:创建base_house 表,同时指定namespace 为house
hbase(main):006:0* create 'house:base_house', 'projectinfo'
Created table house:base_house
Took 1.4626 seconds第三步:使用sqoop开始导入数据
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --hbase-table house:base_house --column-family projectinfo --hbase-create-table --hbase-row-key id温馨提示:
–column-family projectinfo
指定列族为projectinfo
–hbase-create-table
若表不存在,则自动创建
–hbase-row-key id
指定行键为id
第四步:查看"base_house"表数据
scan 'house:base_house'关系型数据库导入Hive
第一步:创建house 数据库
hive> show databases;
OK
db_hive
default
Time taken: 1.565 seconds, Fetched: 2 row(s)
hive> create database house
> ;
OK
Time taken: 0.416 seconds
hive> show databases;
OK
db_hive
default
house
Time taken: 0.059 seconds, Fetched: 3 row(s)第二步:创建base_house 表
hive> create table base_house(id string, project_no string, project_name string, project_address string) row format delimited fields terminated by '\t';
OK
Time taken: 1.379 seconds
hive> show tables;
OK
base_house第三步:使用sqoop开始导入数据
sqoop import --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table base_house --hive-import --hive-database house --create-hive-table --hive-table base_house --hive-overwrite -m 3执行此命令,提示如下错误
2023-03-02 16:07:50,260 ERROR tool.ImportTool: Import failed: java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
at org.apache.sqoop.hive.HiveConfig.getHiveConf(HiveConfig.java:50)
at org.apache.sqoop.hive.HiveImport.getHiveArgs(HiveImport.java:392)
at org.apache.sqoop.hive.HiveImport.executeExternalHiveScript(HiveImport.java:379)
at org.apache.sqoop.hive.HiveImport.executeScript(HiveImport.java:337)
at org.apache.sqoop.hive.HiveImport.importTable(HiveImport.java:241)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:537)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:628)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at org.apache.sqoop.hive.HiveConfig.getHiveConf(HiveConfig.java:44)
... 12 more造成原因:缺少了hive-common-*.jar包,在hive的lib目录下,拷贝到sqoop的lib目录下即可。
解决办法:
-- 拷贝HiveConfig 类依赖jar 包
cp /usr/local/hive/lib/hive-common-3.1.2.jar /usr/local/sqoop/lib/温馨提示:
--hive-import :导入Hive
--hive-database:导入Hive 数据库
--create-hive-table --hive-table:导入Hive指定表名,如果不存在,直接 创建
--hive-overwrite: 是否覆盖
第四步:查看Hive 中"base.base_house"表数据
hive> show databases;
OK
db_hive
default
house
Time taken: 0.925 seconds, Fetched: 3 row(s)
hive> use house;
OK
Time taken: 0.091 seconds
hive> show tables;
OK
base_house
Time taken: 0.082 seconds, Fetched: 1 row(s)
hive> select * from base_house;Sqoop 导出数据
HDFS 导入MySQL 8
第一步:创建本地数据文件并上传Hadoop,编辑文件内容如下:
cd /usr/local/tmp # 切换数据临时目录
vi emp_data #编辑emp_data 同步数据数据内容如下:
[root@Hadoop3-master tmp]# cat /usr/local/tmp/emp_data
1201, gopal, manager, 50000, TP
1202, manisha, preader, 50000, TP
1203, kalil, php dev, 30000, AC
1204, prasanth, php dev, 30000, AC
1205, kranthi, admin, 20000, TP
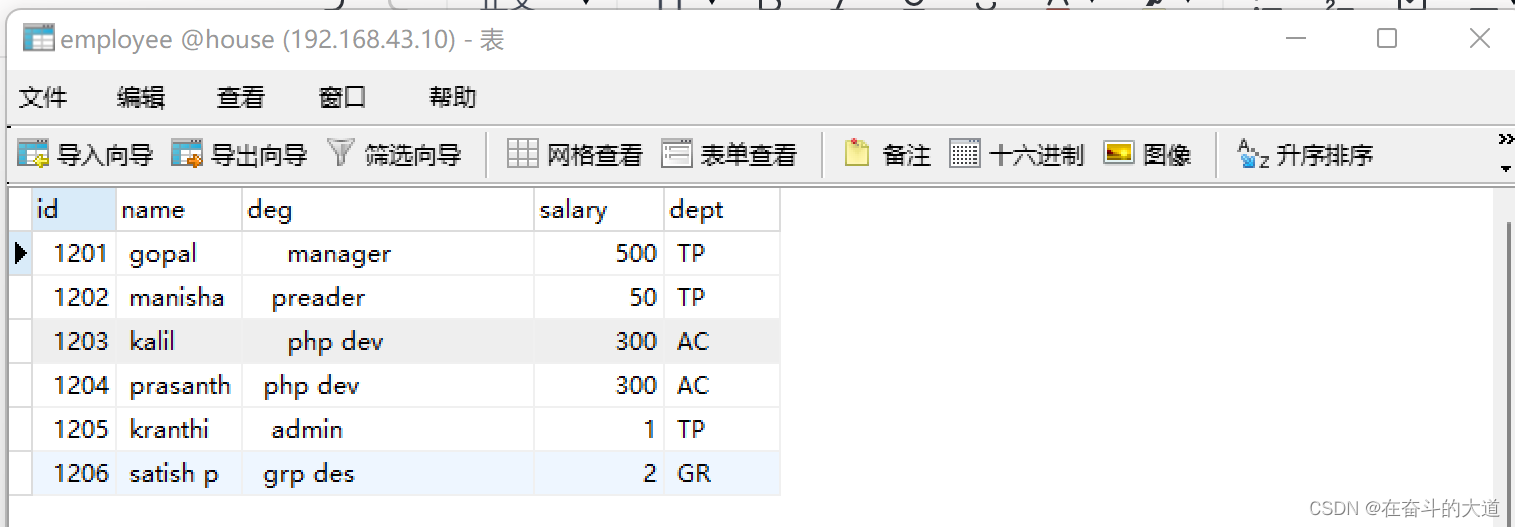
1206, satish p, grp des, 20000, GR温馨提示:上面提供的数据内容会提示NumberException 异常,正确内容如下:
[root@Hadoop3-master tmp]# cat /usr/local/tmp/emp_data
1201, gopal, manager,500, TP
1202, manisha, preader,50, TP
1203, kalil, php dev,300, AC
1204, prasanth, php dev,300, AC
1205, kranthi, admin,1, TP
1206, satish p, grp des,2, GR本地数据文件上传Hadoop
hdfs dfs -put /usr/local/tmp/emp_data /tmp #上传Hadoop 临时目录
[root@Hadoop3-master tmp]# hdfs dfs -ls /tmp/emp_data #查看上传文件目录
-rw-r--r-- 3 root supergroup 216 2023-03-02 17:05 /tmp/emp_data数据库建库脚本:
CREATE TABLE employee (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20),
deg VARCHAR(20),
salary INT,
dept VARCHAR(10));第三步:使用sqoop开始导入数据
sqoop export --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table employee --input-fields-terminated-by ',' --export-dir /tmp/emp_data运行结果:
[root@Hadoop3-master tmp]# sqoop export --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table employee --input-fields-terminated-by ',' --export-dir /tmp/emp_data
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2023-03-02 17:26:48,829 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
2023-03-02 17:26:48,939 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2023-03-02 17:26:49,069 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
2023-03-02 17:26:49,075 INFO tool.CodeGenTool: Beginning code generation
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
2023-03-02 17:26:49,506 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `employee` AS t LIMIT 1
2023-03-02 17:26:49,571 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `employee` AS t LIMIT 1
2023-03-02 17:26:49,584 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
注: /tmp/sqoop-root/compile/c4cc7bb32aac602a701cfc5adcb0d133/employee.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2023-03-02 17:26:51,313 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/c4cc7bb32aac602a701cfc5adcb0d133/employee.jar
2023-03-02 17:26:51,337 INFO mapreduce.ExportJobBase: Beginning export of employee
2023-03-02 17:26:51,337 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2023-03-02 17:26:51,516 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2023-03-02 17:26:52,812 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
2023-03-02 17:26:52,817 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
2023-03-02 17:26:52,818 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2023-03-02 17:26:52,936 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties
2023-03-02 17:26:53,047 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2023-03-02 17:26:53,048 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2023-03-02 17:26:53,389 INFO input.FileInputFormat: Total input files to process : 1
2023-03-02 17:26:53,393 INFO input.FileInputFormat: Total input files to process : 1
2023-03-02 17:26:53,449 INFO mapreduce.JobSubmitter: number of splits:4
2023-03-02 17:26:53,499 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
2023-03-02 17:26:53,615 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1972622522_0001
2023-03-02 17:26:53,615 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-03-02 17:26:54,077 INFO mapred.LocalDistributedCacheManager: Creating symlink: /tmp/hadoop-root/mapred/local/job_local1972622522_0001_25c51b6b-5b27-4a9e-b597-a3f7c9f0aa83/libjars <- /usr/local/tmp/libjars/*
2023-03-02 17:26:54,083 WARN fs.FileUtil: Command 'ln -s /tmp/hadoop-root/mapred/local/job_local1972622522_0001_25c51b6b-5b27-4a9e-b597-a3f7c9f0aa83/libjars /usr/local/tmp/libjars/*' failed 1 with: ln: 无法创建符号链接"/usr/local/tmp/libjars/*": 没有那个文件或目录
2023-03-02 17:26:54,083 WARN mapred.LocalDistributedCacheManager: Failed to create symlink: /tmp/hadoop-root/mapred/local/job_local1972622522_0001_25c51b6b-5b27-4a9e-b597-a3f7c9f0aa83/libjars <- /usr/local/tmp/libjars/*
2023-03-02 17:26:54,084 INFO mapred.LocalDistributedCacheManager: Localized file:/tmp/hadoop/mapred/staging/root1972622522/.staging/job_local1972622522_0001/libjars as file:/tmp/hadoop-root/mapred/local/job_local1972622522_0001_25c51b6b-5b27-4a9e-b597-a3f7c9f0aa83/libjars
2023-03-02 17:26:54,159 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
2023-03-02 17:26:54,160 INFO mapreduce.Job: Running job: job_local1972622522_0001
2023-03-02 17:26:54,166 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2023-03-02 17:26:54,173 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.sqoop.mapreduce.NullOutputCommitter
2023-03-02 17:26:54,233 INFO mapred.LocalJobRunner: Waiting for map tasks
2023-03-02 17:26:54,235 INFO mapred.LocalJobRunner: Starting task: attempt_local1972622522_0001_m_000000_0
2023-03-02 17:26:54,307 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-02 17:26:54,314 INFO mapred.MapTask: Processing split: Paths:/tmp/emp_data:141+25,/tmp/emp_data:166+25
2023-03-02 17:26:54,328 INFO Configuration.deprecation: map.input.file is deprecated. Instead, use mapreduce.map.input.file
2023-03-02 17:26:54,329 INFO Configuration.deprecation: map.input.start is deprecated. Instead, use mapreduce.map.input.start
2023-03-02 17:26:54,329 INFO Configuration.deprecation: map.input.length is deprecated. Instead, use mapreduce.map.input.length
2023-03-02 17:26:54,456 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-02 17:26:54,464 INFO mapred.LocalJobRunner:
2023-03-02 17:26:54,512 INFO mapred.Task: Task:attempt_local1972622522_0001_m_000000_0 is done. And is in the process of committing
2023-03-02 17:26:54,518 INFO mapred.LocalJobRunner: map
2023-03-02 17:26:54,518 INFO mapred.Task: Task 'attempt_local1972622522_0001_m_000000_0' done.
2023-03-02 17:26:54,532 INFO mapred.Task: Final Counters for attempt_local1972622522_0001_m_000000_0: Counters: 21
File System Counters
FILE: Number of bytes read=8236
FILE: Number of bytes written=571103
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=84
HDFS: Number of bytes written=0
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=1
Map output records=1
Input split bytes=176
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=220200960
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2023-03-02 17:26:54,532 INFO mapred.LocalJobRunner: Finishing task: attempt_local1972622522_0001_m_000000_0
2023-03-02 17:26:54,533 INFO mapred.LocalJobRunner: Starting task: attempt_local1972622522_0001_m_000001_0
2023-03-02 17:26:54,536 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-02 17:26:54,537 INFO mapred.MapTask: Processing split: Paths:/tmp/emp_data:0+47
2023-03-02 17:26:54,573 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-02 17:26:54,579 INFO mapred.LocalJobRunner:
2023-03-02 17:26:54,588 INFO mapred.Task: Task:attempt_local1972622522_0001_m_000001_0 is done. And is in the process of committing
2023-03-02 17:26:54,590 INFO mapred.LocalJobRunner: map
2023-03-02 17:26:54,591 INFO mapred.Task: Task 'attempt_local1972622522_0001_m_000001_0' done.
2023-03-02 17:26:54,591 INFO mapred.Task: Final Counters for attempt_local1972622522_0001_m_000001_0: Counters: 21
File System Counters
FILE: Number of bytes read=8795
FILE: Number of bytes written=571103
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=278
HDFS: Number of bytes written=0
HDFS: Number of read operations=15
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=2
Map output records=2
Input split bytes=120
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=220200960
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2023-03-02 17:26:54,591 INFO mapred.LocalJobRunner: Finishing task: attempt_local1972622522_0001_m_000001_0
2023-03-02 17:26:54,591 INFO mapred.LocalJobRunner: Starting task: attempt_local1972622522_0001_m_000002_0
2023-03-02 17:26:54,593 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-02 17:26:54,594 INFO mapred.MapTask: Processing split: Paths:/tmp/emp_data:47+47
2023-03-02 17:26:54,629 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-02 17:26:54,630 INFO mapred.LocalJobRunner:
2023-03-02 17:26:54,640 INFO mapred.Task: Task:attempt_local1972622522_0001_m_000002_0 is done. And is in the process of committing
2023-03-02 17:26:54,642 INFO mapred.LocalJobRunner: map
2023-03-02 17:26:54,642 INFO mapred.Task: Task 'attempt_local1972622522_0001_m_000002_0' done.
2023-03-02 17:26:54,643 INFO mapred.Task: Final Counters for attempt_local1972622522_0001_m_000002_0: Counters: 21
File System Counters
FILE: Number of bytes read=9354
FILE: Number of bytes written=571103
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=425
HDFS: Number of bytes written=0
HDFS: Number of read operations=18
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=1
Map output records=1
Input split bytes=120
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=220200960
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2023-03-02 17:26:54,643 INFO mapred.LocalJobRunner: Finishing task: attempt_local1972622522_0001_m_000002_0
2023-03-02 17:26:54,643 INFO mapred.LocalJobRunner: Starting task: attempt_local1972622522_0001_m_000003_0
2023-03-02 17:26:54,645 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-02 17:26:54,646 INFO mapred.MapTask: Processing split: Paths:/tmp/emp_data:94+47
2023-03-02 17:26:54,678 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-02 17:26:54,679 INFO mapred.LocalJobRunner:
2023-03-02 17:26:54,690 INFO mapred.Task: Task:attempt_local1972622522_0001_m_000003_0 is done. And is in the process of committing
2023-03-02 17:26:54,692 INFO mapred.LocalJobRunner: map
2023-03-02 17:26:54,693 INFO mapred.Task: Task 'attempt_local1972622522_0001_m_000003_0' done.
2023-03-02 17:26:54,693 INFO mapred.Task: Final Counters for attempt_local1972622522_0001_m_000003_0: Counters: 21
File System Counters
FILE: Number of bytes read=9913
FILE: Number of bytes written=571103
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=525
HDFS: Number of bytes written=0
HDFS: Number of read operations=21
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=2
Map output records=2
Input split bytes=120
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=220200960
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2023-03-02 17:26:54,693 INFO mapred.LocalJobRunner: Finishing task: attempt_local1972622522_0001_m_000003_0
2023-03-02 17:26:54,694 INFO mapred.LocalJobRunner: map task executor complete.
2023-03-02 17:26:55,169 INFO mapreduce.Job: Job job_local1972622522_0001 running in uber mode : false
2023-03-02 17:26:55,171 INFO mapreduce.Job: map 100% reduce 0%
2023-03-02 17:26:55,174 INFO mapreduce.Job: Job job_local1972622522_0001 completed successfully
2023-03-02 17:26:55,209 INFO mapreduce.Job: Counters: 21
File System Counters
FILE: Number of bytes read=36298
FILE: Number of bytes written=2284412
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1312
HDFS: Number of bytes written=0
HDFS: Number of read operations=66
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=6
Map output records=6
Input split bytes=536
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=880803840
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2023-03-02 17:26:55,220 INFO mapreduce.ExportJobBase: Transferred 1.2812 KB in 2.3797 seconds (551.3292 bytes/sec)
2023-03-02 17:26:55,228 INFO mapreduce.ExportJobBase: Exported 6 records.MySQL 查询:
Hive/Hbase 导入MySQL 8
第一步:在MySQL 8 创建hiveTomysql, 建表语句如下:
create table hiveTomysql(
sid int primary key,
sname varchar(5) not null,
gender varchar(1) default '男',
age int not null
);第二步:在Hive 中新建hiveTomysql 表,并插入相关数据
[root@Hadoop3-master tmp]# cd /usr/local/hive/bin
[root@Hadoop3-master bin]# hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-reload4j-1.7.35.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = 4552807f-c6fc-4ebb-86a6-1cd8c3b013ec选择default 数据库,并创建hiveTomysql 表
hive> show databases;
OK
db_hive
default
house
Time taken: 1.026 seconds, Fetched: 3 row(s)
hive> use default;
OK
Time taken: 0.097 seconds
hive> show tables;
OK
employee
student
student2
student3
Time taken: 0.085 seconds, Fetched: 4 row(s)
hive> CREATE TABLE IF NOT EXISTS hiveTomysql(sid INT,sname string,gender string, age int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
OK
Time taken: 1.371 seconds
hive> show tables;
OK
employee
hivetomysql
student
student2
student3
Time taken: 0.126 seconds, Fetched: 5 row(s)第三步:加载本地数据至default.hiveTomysql 表
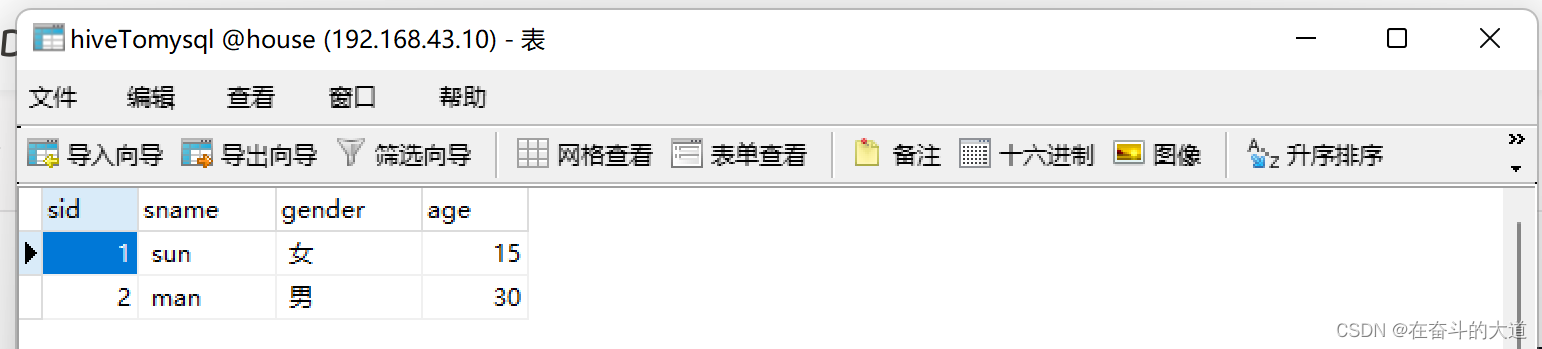
在/usr/local/tmp/目录下,创建hiveTomysql 数据文件,文件内容如下:
[root@Hadoop3-master bin]# cat /usr/local/tmp/hiveTomysql
1, sun, 女, 15
2, man, 男, 30在Hive Shell窗口,将数据上传,执行如下指令:
hive> load data local inpath '/usr/local/tmp/hiveTomysql' overwrite into table d efault.hiveTomysql;
Loading data to table default.hivetomysql
OK
Time taken: 2.962 seconds
hive> show databases;
OK
db_hive
default
house
Time taken: 0.196 seconds, Fetched: 3 row(s)
hive> use def
default defined
hive> use default;
OK
Time taken: 0.086 seconds
hive> show tables;
OK
employee
hivetomysql
student
student2
student3
Time taken: 0.073 seconds, Fetched: 5 row(s)
hive> select * from hiveTomysql;
OK
1 sun 女 NULL
2 man 男 NULL
Time taken: 2.947 seconds, Fetched: 2 row(s)查看Hive 中default.hiveTomysql 对应Hadoop 文件存储路径地址
hive> desc formatted default.hiveTomysql
> ;
OK
# col_name data_type comment
sid int
sname string
gender string
age int
# Detailed Table Information
Database: default
OwnerType: USER
Owner: root
CreateTime: Thu Mar 02 17:42:49 CST 2023
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://Hadoop3-master:9000/user/hive/warehouse/hivetomysql
Table Type: MANAGED_TABLE
Table Parameters:
bucketing_version 2
numFiles 1
numRows 0
rawDataSize 0
totalSize 32
transient_lastDdlTime 1677750562
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim ,
serialization.format ,
Time taken: 1.534 seconds, Fetched: 34 row(s)通过上面信息可以得知:hiveTomysql 对应Hadoop存储路径地址:/user/hive/warehouse/hivetomysql
第四步:使用sqoop开始导入数据
sqoop export --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table hiveTomysql --input-fields-terminated-by ',' --export-dir /user/hive/warehouse/hivetomysql运行结果:
[root@Hadoop3-master bin]# sqoop export --connect "jdbc:mysql://192.168.43.10:3306/house?useSSL=false&serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL" --username root --password 123456 --table hiveTomysql --input-fields-terminated-by ',' --export-dir /user/hive/warehouse/hivetomysql
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2023-03-02 18:38:58,547 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
2023-03-02 18:38:58,716 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2023-03-02 18:38:58,944 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
2023-03-02 18:38:58,951 INFO tool.CodeGenTool: Beginning code generation
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
2023-03-02 18:38:59,468 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `hiveTomysql` AS t LIMIT 1
2023-03-02 18:38:59,542 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `hiveTomysql` AS t LIMIT 1
2023-03-02 18:38:59,556 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
注: /tmp/sqoop-root/compile/1c58db7d5bb356feff82eeeb0c50e534/hiveTomysql.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2023-03-02 18:39:01,546 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/1c58db7d5bb356feff82eeeb0c50e534/hiveTomysql.jar
2023-03-02 18:39:01,579 INFO mapreduce.ExportJobBase: Beginning export of hiveTomysql
2023-03-02 18:39:01,579 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2023-03-02 18:39:01,812 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2023-03-02 18:39:03,451 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
2023-03-02 18:39:03,458 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
2023-03-02 18:39:03,459 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2023-03-02 18:39:03,604 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties
2023-03-02 18:39:03,739 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2023-03-02 18:39:03,740 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2023-03-02 18:39:04,159 INFO input.FileInputFormat: Total input files to process : 1
2023-03-02 18:39:04,170 INFO input.FileInputFormat: Total input files to process : 1
2023-03-02 18:39:04,238 INFO mapreduce.JobSubmitter: number of splits:4
2023-03-02 18:39:04,319 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
2023-03-02 18:39:04,460 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1924785693_0001
2023-03-02 18:39:04,460 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-03-02 18:39:04,924 INFO mapred.LocalDistributedCacheManager: Creating symlink: /tmp/hadoop-root/mapred/local/job_local1924785693_0001_a259a15d-5e77-4451-a2d6-8c30b49acfa6/libjars <- /usr/local/sqoop/bin/libjars/*
2023-03-02 18:39:04,938 WARN fs.FileUtil: Command 'ln -s /tmp/hadoop-root/mapred/local/job_local1924785693_0001_a259a15d-5e77-4451-a2d6-8c30b49acfa6/libjars /usr/local/sqoop/bin/libjars/*' failed 1 with: ln: 无法创建符号链接"/usr/local/sqoop/bin/libjars/*": 没有那个文件或目录
2023-03-02 18:39:04,938 WARN mapred.LocalDistributedCacheManager: Failed to create symlink: /tmp/hadoop-root/mapred/local/job_local1924785693_0001_a259a15d-5e77-4451-a2d6-8c30b49acfa6/libjars <- /usr/local/sqoop/bin/libjars/*
2023-03-02 18:39:04,939 INFO mapred.LocalDistributedCacheManager: Localized file:/tmp/hadoop/mapred/staging/root1924785693/.staging/job_local1924785693_0001/libjars as file:/tmp/hadoop-root/mapred/local/job_local1924785693_0001_a259a15d-5e77-4451-a2d6-8c30b49acfa6/libjars
2023-03-02 18:39:05,041 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
2023-03-02 18:39:05,042 INFO mapreduce.Job: Running job: job_local1924785693_0001
2023-03-02 18:39:05,050 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2023-03-02 18:39:05,056 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.sqoop.mapreduce.NullOutputCommitter
2023-03-02 18:39:05,124 INFO mapred.LocalJobRunner: Waiting for map tasks
2023-03-02 18:39:05,126 INFO mapred.LocalJobRunner: Starting task: attempt_local1924785693_0001_m_000000_0
2023-03-02 18:39:05,214 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-02 18:39:05,219 INFO mapred.MapTask: Processing split: Paths:/user/hive/warehouse/hivetomysql/hiveTomysql:21+4,/user/hive/warehouse/hivetomysql/hiveTomysql:25+5
2023-03-02 18:39:05,233 INFO Configuration.deprecation: map.input.file is deprecated. Instead, use mapreduce.map.input.file
2023-03-02 18:39:05,233 INFO Configuration.deprecation: map.input.start is deprecated. Instead, use mapreduce.map.input.start
2023-03-02 18:39:05,233 INFO Configuration.deprecation: map.input.length is deprecated. Instead, use mapreduce.map.input.length
2023-03-02 18:39:05,367 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-02 18:39:05,378 INFO mapred.LocalJobRunner:
2023-03-02 18:39:05,414 INFO mapred.Task: Task:attempt_local1924785693_0001_m_000000_0 is done. And is in the process of committing
2023-03-02 18:39:05,417 INFO mapred.LocalJobRunner: map
2023-03-02 18:39:05,417 INFO mapred.Task: Task 'attempt_local1924785693_0001_m_000000_0' done.
2023-03-02 18:39:05,437 INFO mapred.Task: Final Counters for attempt_local1924785693_0001_m_000000_0: Counters: 21
File System Counters
FILE: Number of bytes read=7675
FILE: Number of bytes written=570742
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=23
HDFS: Number of bytes written=0
HDFS: Number of read operations=15
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=0
Map output records=0
Input split bytes=238
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=213909504
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2023-03-02 18:39:05,437 INFO mapred.LocalJobRunner: Finishing task: attempt_local1924785693_0001_m_000000_0
2023-03-02 18:39:05,438 INFO mapred.LocalJobRunner: Starting task: attempt_local1924785693_0001_m_000001_0
2023-03-02 18:39:05,440 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-02 18:39:05,441 INFO mapred.MapTask: Processing split: Paths:/user/hive/warehouse/hivetomysql/hiveTomysql:0+7
2023-03-02 18:39:05,492 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-02 18:39:05,494 INFO mapred.LocalJobRunner:
2023-03-02 18:39:05,514 INFO mapred.Task: Task:attempt_local1924785693_0001_m_000001_0 is done. And is in the process of committing
2023-03-02 18:39:05,516 INFO mapred.LocalJobRunner: map
2023-03-02 18:39:05,516 INFO mapred.Task: Task 'attempt_local1924785693_0001_m_000001_0' done.
2023-03-02 18:39:05,516 INFO mapred.Task: Final Counters for attempt_local1924785693_0001_m_000001_0: Counters: 21
File System Counters
FILE: Number of bytes read=8389
FILE: Number of bytes written=570742
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=56
HDFS: Number of bytes written=0
HDFS: Number of read operations=18
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=1
Map output records=1
Input split bytes=151
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=213909504
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2023-03-02 18:39:05,516 INFO mapred.LocalJobRunner: Finishing task: attempt_local1924785693_0001_m_000001_0
2023-03-02 18:39:05,516 INFO mapred.LocalJobRunner: Starting task: attempt_local1924785693_0001_m_000002_0
2023-03-02 18:39:05,518 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-02 18:39:05,521 INFO mapred.MapTask: Processing split: Paths:/user/hive/warehouse/hivetomysql/hiveTomysql:7+7
2023-03-02 18:39:05,564 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-02 18:39:05,566 INFO mapred.LocalJobRunner:
2023-03-02 18:39:05,572 INFO mapred.Task: Task:attempt_local1924785693_0001_m_000002_0 is done. And is in the process of committing
2023-03-02 18:39:05,574 INFO mapred.LocalJobRunner: map
2023-03-02 18:39:05,574 INFO mapred.Task: Task 'attempt_local1924785693_0001_m_000002_0' done.
2023-03-02 18:39:05,575 INFO mapred.Task: Final Counters for attempt_local1924785693_0001_m_000002_0: Counters: 21
File System Counters
FILE: Number of bytes read=9103
FILE: Number of bytes written=570742
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=82
HDFS: Number of bytes written=0
HDFS: Number of read operations=21
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=0
Map output records=0
Input split bytes=151
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=213909504
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2023-03-02 18:39:05,575 INFO mapred.LocalJobRunner: Finishing task: attempt_local1924785693_0001_m_000002_0
2023-03-02 18:39:05,575 INFO mapred.LocalJobRunner: Starting task: attempt_local1924785693_0001_m_000003_0
2023-03-02 18:39:05,576 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2023-03-02 18:39:05,577 INFO mapred.MapTask: Processing split: Paths:/user/hive/warehouse/hivetomysql/hiveTomysql:14+7
2023-03-02 18:39:05,618 INFO mapreduce.AutoProgressMapper: Auto-progress thread is finished. keepGoing=false
2023-03-02 18:39:05,619 INFO mapred.LocalJobRunner:
2023-03-02 18:39:05,631 INFO mapred.Task: Task:attempt_local1924785693_0001_m_000003_0 is done. And is in the process of committing
2023-03-02 18:39:05,632 INFO mapred.LocalJobRunner: map
2023-03-02 18:39:05,632 INFO mapred.Task: Task 'attempt_local1924785693_0001_m_000003_0' done.
2023-03-02 18:39:05,632 INFO mapred.Task: Final Counters for attempt_local1924785693_0001_m_000003_0: Counters: 21
File System Counters
FILE: Number of bytes read=9305
FILE: Number of bytes written=570742
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=101
HDFS: Number of bytes written=0
HDFS: Number of read operations=24
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=1
Map output records=1
Input split bytes=151
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=213909504
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2023-03-02 18:39:05,632 INFO mapred.LocalJobRunner: Finishing task: attempt_local1924785693_0001_m_000003_0
2023-03-02 18:39:05,633 INFO mapred.LocalJobRunner: map task executor complete.
2023-03-02 18:39:06,052 INFO mapreduce.Job: Job job_local1924785693_0001 running in uber mode : false
2023-03-02 18:39:06,063 INFO mapreduce.Job: map 100% reduce 0%
2023-03-02 18:39:06,067 INFO mapreduce.Job: Job job_local1924785693_0001 completed successfully
2023-03-02 18:39:06,108 INFO mapreduce.Job: Counters: 21
File System Counters
FILE: Number of bytes read=34472
FILE: Number of bytes written=2282968
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=262
HDFS: Number of bytes written=0
HDFS: Number of read operations=78
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=2
Map output records=2
Input split bytes=691
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=855638016
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
2023-03-02 18:39:06,117 INFO mapreduce.ExportJobBase: Transferred 262 bytes in 2.6339 seconds (99.4716 bytes/sec)
2023-03-02 18:39:06,125 INFO mapreduce.ExportJobBase: Exported 2 records.
MySQL 结果展示
Sqoop 深入理解
Sqoop原理
Sqoop的原理:其实就是将导入导出命令转化为mapreduce程序来执行,sqoop在接收到命令后,都要生成mapreduce程序。
Sqoop 代码定制
使用sqoop的代码生成工具可以方便查看到sqoop所生成的java代码,并可在此基础之上进行深入定制开发。
代码定制语法
以下是Sqoop代码生成命令的语法:
$ sqoop-codegen (generic-args) (codegen-args)
$ sqoop-codegen (generic-args) (codegen-args)代码定制案例
示例:以USERDB数据库中的表emp来生成Java代码为例,下面的命令用来生成导入:
$ sqoop-codegen \
--import
--connect jdbc:mysql://localhost/userdb \
--username root \
--table emp如果命令成功执行,那么它就会产生如下的输出:
14/12/23 02:34:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5
14/12/23 02:34:41 INFO tool.CodeGenTool: Beginning code generation
……………….
14/12/23 02:34:42 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
Note: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
14/12/23 02:34:47 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.jar验证: 查看输出目录下的文件
$ cd /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/
$ ls
emp.class
emp.jar
emp.java如果想做深入定制导出,则可修改上述代码文件!
Sqoop、DataX关系与对比
Sqoop特点

DataX特点

Sqoop与DataX的区别

Datax 参考资料:Datax 一文读懂