简介
在写这篇文章的时候doris 1.2 的物化视图只是支持单表建立物化视图,现在说下ClickHouse多表的物化视图。
前言
本文翻译自 Altinity 针对 ClickHouse 的系列技术文章。面向联机分析处理(OLAP)的开源分析引擎 ClickHouse,因其优良的查询性能,PB 级的数据规模,简单的架构,被国内外公司广泛采用。
阿里云 EMR-OLAP 团队,基于开源 ClickHouse 进行了系列优化,提供了开源 OLAP 分析引擎 ClickHouse 的云上托管服务。EMR ClickHouse 完全兼容开源版本的产品特性,同时提供集群快速部署、集群管理、扩容、缩容和监控告警等云上产品功能,并且在开源的基础上优化了 ClickHouse 的读写性能,提升了 ClickHouse 与 EMR 其他组件快速集成的能力。访问https://help.aliyun.com/document_detail/212195.html
了解详情。
在 ClickHouse 物化视图中使用 Join
ClickHouse 物化视图提供了一种在 ClickHouse 中重组数据的强大方法。我们已经在网络研讨会、博客文章和会议讲座中多次讨论了其能力。我们收到的最常见的后续问题之一是:物化视图是否支持 Join。
答案是肯定的。这篇博客文章展示了具体方法。如果你想要简短的答案,那就是:物化视图会触发 Join 中最左侧的表。物化视图将从 Join 中的右侧表提取值,但如果这些表发生变化,则不会触发。
请继续阅读关于物化视图与 Join 行为的详细示例。我们还将解释底层的原理,帮助你在创建自己的视图时更好地理解 ClickHouse 行为。注:示例来自 ClickHouse 版本 20.3。
表定义
物化视图可以用各种有趣的方式转换数据,但我们只说简单的。我们将以 download 表为例,演示如何构建从几个维度表中提取信息的每日下载总数指标。该模式的摘要如下。
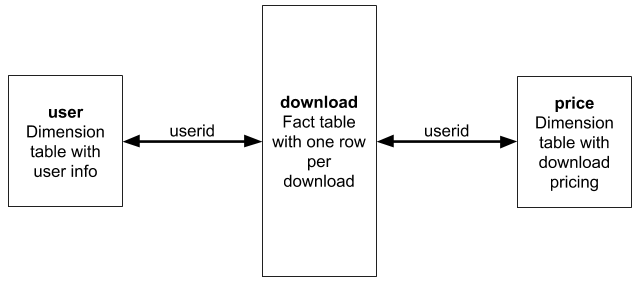
我们首先定义 download 表。这个表可能会变得非常大。
CREATE TABLE download (
when DateTime,
userid UInt32,
bytes UInt64
) ENGINE=MergeTree
PARTITION BY toYYYYMM(when)
ORDER BY (userid, when)
接下来,我们定义一个维度表,该表将用户 ID 映射到每 GB 下载量的价格。这个表相对较小。
CREATE TABLE price (
userid UInt32,
price_per_gb Float64
) ENGINE=MergeTree
PARTITION BY tuple()
ORDER BY userid最后,我们定义一个维度表,该表将用户 ID 映射到名称。这个表也同样很小。
CREATE TABLE user (
userid UInt32,
name String
) ENGINE=MergeTree
PARTITION BY tuple()
ORDER BY userid物化视图定义
现在,让我们创建一个物化视图,该视图按用户 ID 汇总每日下载次数和字节数,并根据下载的字节数计算价格。我们需要直接创建目标表,然后使用一个带有 TO 关键字(指向我们的表)的物化视图定义。
目标表如下。
CREATE TABLE download_daily (
day Date,
userid UInt32,
downloads UInt32,
total_gb Float64,
total_price Float64
)
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(day) ORDER BY (userid, day)上面的定义利用了专门的 SummingMergeTree 行为。任何非键数字字段均视为一个聚合,因此我们不必在列定义中使用聚合函数。
最后,这是我们的物化视图定义。也可以用更紧凑的方式来定义它,但是你很快就会看到,这种形式更容易扩展视图,从而与更多的表 Join。
CREATE MATERIALIZED VIEW download_daily_mv
TO download_daily AS
SELECT
day AS day, userid AS userid, count() AS downloads,
sum(gb) as total_gb, sum(price) as total_price
FROM (
SELECT
toDate(when) AS day,
userid AS userid,
download.bytes / (1024*1024*1024) AS gb,
gb * price.price_per_gb AS price
FROM download LEFT JOIN price ON download.userid = price.userid
)
GROUP BY userid, day加载数据
我们现在可以通过加载数据来测试视图。我们首先加载带有用户名和价格信息的两个维度表。
INSERT INTO price VALUES (25, 0.10), (26, 0.05), (27, 0.01);
INSERT INTO user VALUES (25, 'Bob'), (26, 'Sue'), (27, 'Sam');
接下来,我们将示例样本数据添加到 download 事实表中。下面的 INSERT 添加了 5000 行,按 user 表中列出的 userid 值均匀分布。
INSERT INTO download
WITH
(SELECT groupArray(userid) FROM user) AS user_ids
SELECT
now() + number * 60 AS when,
user_ids[(number % length(user_ids)) + 1] AS user_id,
rand() % 100000000 AS bytes
FROM system.numbers
LIMIT 5000
此时我们可以看到,物化视图将数据填充到 download_daily 中。下面是一个示例查询。
SELECT day, downloads, total_gb, total_price
FROM download_daily WHERE userid = 25
┌────────day─┬─downloads─┬───────────total_gb─┬────────total_price─┐
│ 2020-07-14 │ 108 │ 5.054316438734531 │ 0.5054316438734532 │
│ 2020-07-15 │ 480 │ 22.81532768998295 │ 2.281532768998296 │
│ 2020-07-16 │ 480 │ 21.07045224122703 │ 2.107045224122702 │
│ 2020-07-17 │ 480 │ 21.606687822379172 │ 2.1606687822379183 │
│ 2020-07-18 │ 119 │ 5.548438269644976 │ 0.5548438269644972 │
└────────────┴───────────┴────────────────────┴────────────────────┘目前还不错。但我们还能更进一步。我们首先看看 ClickHouse 背后的原理。
刨根问底
要有效地使用物化视图,了解其背后的原理是大有帮助的。物化视图作为后插入触发器对单个表运行。如果物化视图定义中的查询包括 Join,那么来源表就是 Join 中的左侧表。
在我们的示例中,download 是左侧表。因此,任何对 download 的插入都会导致一个分片被写入 download_daily。尽管将值添加到了 Join 中,但对 user 的插入没有效果。
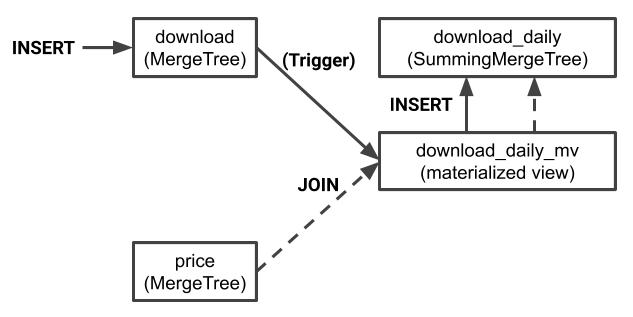
如果我们创建一个更有趣的物化视图,就很容易展示这种行为。让我们定义一个对 user 表进行右侧外部联接的视图。在这种情况下,我们将使用一个简单的 MergeTree 表,这样我们就可以看到所有生成的行,而不用像 SummingMergeTree 那样进行合并。下面是一个简单的目标表,后面是一个物化视图,它将从 download 表填充目标表。
CREATE TABLE download_right_outer (
when DateTime,
userid UInt32,
name String,
bytes UInt64
) ENGINE=MergeTree
PARTITION BY toYYYYMM(when)
ORDER BY (when, userid)
CREATE MATERIALIZED VIEW download_right_outer_mv
TO download_right_outer
AS SELECT
when AS when,
user.userid AS userid,
user.name AS name,
bytes AS bytes
FROM download RIGHT OUTER JOIN user ON (download.userid = user.userid)当我们在 download 表中插入一行时会发生什么?物化视图为 user 表中的每次插入*以及*任何不匹配的行生成一行,因为我们进行的是右侧外部联接。(你可能已经注意到了,这个视图也有一个潜在缺陷。我们很快就会处理这个问题。)
INSERT INTO download VALUES (now(), 26, 555)
SELECT * FROM download_right_outer
┌────────────────when─┬─userid─┬─name─┬─bytes─┐
│ 2020-07-12 17:27:35 │ 26 │ Sue │ 555 │
└─────────────────────┴────────┴──────┴───────┘
┌────────────────when─┬─userid─┬─name─┬─bytes─┐
│ 0000-00-00 00:00:00 │ 25 │ Bob │ 0 │
│ 0000-00-00 00:00:00 │ 27 │ Sam │ 0 │
└─────────────────────┴────────┴──────┴───────┘另一方面,如果你在 user 表中插入一行,物化视图中不会发生任何变化。
INSERT INTO user VALUES (28, 'Kate')
SELECT * FROM download_right_outer
┌────────────────when─┬─userid─┬─name─┬─bytes─┐
│ 2020-07-12 17:27:35 │ 26 │ Sue │ 555 │
└─────────────────────┴────────┴──────┴───────┘
┌────────────────when─┬─userid─┬─name─┬─bytes─┐
│ 0000-00-00 00:00:00 │ 25 │ Bob │ 0 │
│ 0000-00-00 00:00:00 │ 27 │ Sam │ 0 │
└─────────────────────┴────────┴──────┴───────┘只有当你向 download 表添加更多的行时,才会看到新用户行的效果。
对多个表 Join
像 SELECT 语句一样,物化视图可以对多个表 Join。在第一个示例中,我们 Join 了下载价格(因 userid 而异)。现在我们来 Join 第二个 user 表,该表将 userid 映射到一个 username。在这个示例中,我们将添加一个新的目标表,其中添加了 username 列。由于 username 不是聚合,我们也将其添加到 ORDER BY。这将防止 SummingMergeTree 引擎尝试聚合它。
CREATE TABLE download_daily_with_name (
day Date,
userid UInt32,
username String,
downloads UInt32,
total_gb Float64,
total_price Float64
)
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(day) ORDER BY (userid, day, username)现在我们来定义物化视图,它以简单直接的方式扩展了第一个示例的 SELECT。
CREATE MATERIALIZED VIEW download_daily_with_name_mv
TO download_daily_with_name AS
SELECT
day AS day, userid AS userid, user.name AS username,
count() AS downloads, sum(gb) as total_gb, sum(price) as total_price
FROM (
SELECT
toDate(when) AS day,
userid AS userid,
download.bytes / (1024*1024*1024) AS gb,
gb * price.price_per_gb AS price
FROM download LEFT JOIN price ON download.userid = price.userid
) AS join1
LEFT JOIN user ON join1.userid = user.userid
GROUP BY userid, day, username
你可以截断 download 表并重新加载数据,以此测试新视图。这将留给读者作为练习。
慎重许愿
ClickHouse SELECT 语句支持广泛的 Join 类型,这为物化视图所实现的转换提供了很大的灵活性。灵活性可能是把双刃剑,因为它创造了更多的机会,有可能产生并非预期的结果。
例如,如果你在 download 中插入一条 userid 30 的行,会发生什么?这个 userid 在 user 表或 price 表中都不存在。
INSERT INTO download VALUES (now(), 30, 222)简而言之:如果你不仔细定义物化视图,该行可能不会出现在目标表中。为了确保匹配,你必须进行 LEFT OUTER JOIN 或者 FULL OUTER JOIN。这是有道理的,因为这和运行 SELECT 本身产生的行为是一样的。download_right_outer_mv 示例正是存在如上所述的问题。
视图定义也会产生不易察觉的语法错误。例如,遗漏 GROUP BY 项会导致令人费解的失败。下面是一个简单示例。
CREATE MATERIALIZED VIEW download_daily_join_old_style_mv
ENGINE = SummingMergeTree PARTITION BY toYYYYMM(day)
ORDER BY (userid, day) POPULATE AS SELECT
toDate(when) AS day,
download.userid AS userid,
user.username AS name,
count() AS downloads,
sum(bytes) AS bytes
FROM download INNER JOIN user ON download.userid = user.userid
GROUP BY userid, day -- Column `username` is missing!
Received exception from server (version 20.3.8):
Code: 10.DB::Exception: Received from localhost:9000.DB::Exception: Not found column name in block. There are only columns: userid, toStartOfDay(when), count(), sum(bytes).哪儿出问题了?username 列中遗漏了 GROUP BY。ClickHouse 拒绝视图定义的做法是合理的,但报错信息有点难以解读。
最后,当列在联接的表之间重叠时,务必要仔细指定列。下面是与上文的 RIGHT OUTER JOIN 示例略有不同的版本。
CREATE MATERIALIZED VIEW download_right_outer_mv
TO download_right_outer
AS SELECT
when AS when,
userid,
user.name AS name,
bytes AS bytes
FROM download RIGHT OUTER JOIN user ON (download.userid = user.userid)
当你在 download 中插入行时,你会得到如下的结果,其中 userid 已从不匹配的行中删除。
SELECT * FROM download_right_outer
┌────────────────when─┬─userid─┬─name─┬─bytes─┐
│ 0000-00-00 00:00:00 │ 0 │ Sue │ 0 │
│ 0000-00-00 00:00:00 │ 0 │ Sam │ 0 │
└─────────────────────┴────────┴──────┴───────┘
┌────────────────when─┬─userid─┬─name─┬─bytes─┐
│ 2020-07-12 18:04:56 │ 25 │ Bob │ 222 │
└─────────────────────┴────────┴──────┴───────┘在这种情况下,ClickHouse 似乎输入了默认值,而不是从 user.userid 分配值。你必须明确地命名列值并且使用 AS userid 来分配名称。如果你单独运行 SELECT 查询,是达不到这种效果的。这种行为看起来像一个缺陷。
结论
物化视图是 ClickHouse 用户可用的最通用的功能之一。物化视图是由一个 SELECT 语句填充的,该 SELECT 可以 Join 多个表。要了解的关键是,ClickHouse 仅触发 Join 中最左侧的表。其他表可提供用于转换的数据,但是视图不会对这些表上的插入做出反应。
Join 带来了新的灵活性,但也可能导致意料之外的结果。因此,最好仔细测试物化视图,尤其是存在 Join 时。
参考
Using Joins in ClickHouse Materialized Views – Altinity | The Real Time Data Company