目录
什么是逻辑复制
逻辑解析
复制槽
output plugin
几个常见的outputplugin
几个能手动接收解析数据的函数和工具
逻辑解析测试1:观察用2个不同的output plugin解析数据
逻辑解析测试2:使用pg_recvlogical工具接收逻辑解析数据,模拟一个逻辑复制链路
逻辑复制的前置条件
1.参数
2 权限
pg间的逻辑同步——发布与订阅
发布
订阅
发布订阅相关视图
创建一个发布和订阅
创建发布
创建订阅
发布订阅模式 测试1:truncate同步
发布订阅模式 测试2:新增表同步
replica identity复制标识
复制标识测试1:将一个没有主键的表的复制标识设置为非空唯一索引
复制标识测试2:full模式,多条重复数据时,是否可以正常同步
第三方同步软件
创建ogg同步pg到oracle的同步
逻辑复制监控
pg_replication_slots
pg_stat_replication
sent_lsn、write_lsn、flush_lsn、replay_lsn的关系
pg_stat_replication_slots
逻辑复制槽的事务快照和pg_logical目录
逻辑解析工作内存和溢出到pg_replslot
logical_decoding_work_mem
相关reorderbuffer和溢出
总结
参考资料
什么是逻辑复制
pg逻辑复制基于逻辑解析(logicaldecoding),将wal日志流解析成一定格式输出(output),订阅节点收到解析后的数据进行应用。
逻辑复制不同于流复制(物理复制)基于实例级别主从库物理结构上就是一样,逻辑复制可以基于表级别选择性复制。逻辑复制(Logical Replication)在官方文档里专指”复制-订阅“模式,其实有许多工具可以基于逻辑解析做异构数据库间数据同步。
pg9.4 pglogical插件可以支持逻辑复制(https://github.com/2ndQuadrant/pglogical),pg10开始原生支持逻辑复制。
逻辑复制可以用于数据库升级、异构数据迁移、表级数据同步链路、订阅数据流等等
逻辑解析
逻辑解析可以将wal日志中的表数据变更解析成行数据流或sql文本,这些行数据流或sql文本可以被其他类型的数据库或软件消费。而具体的解析格式由outputplugin决定。
复制槽
在逻辑复制中,复制槽代表着数据变更流。跟物理复制槽一样,逻辑复制槽也可以保证复制异常中断后,相关的wal日志不被删除,以保证复制重连后仍然可以继续解析wal日志。一个数据库可以有多个复制槽,一个复制槽只有一个outputplugin,一个复制槽代表一条复制链路。复制槽本质上是用来管理复制链路的。不同于流复制可以没有复制槽,逻辑复制是必须有复制槽的。
output plugin
output plugin转换wal日志信息成复制槽所要的格式。pg中内置了一些outputplugin,也可以通过插件添加一些额外的outputplugin。每个逻辑复制槽都有一个output plugin用于解析wal相关工作。
outputplugin使用回调函数管理解析。比如OUTPUT_PLUGIN_BINARY_OUTPUT ,OUTPUT_PLUGIN_TEXTUAL_OUTPUT 用于设置out_type是二进制还是文本。还有一些回调函数用于通知plugin事务数据变更,并把事务排序。回调函数当然不用我们人为使用,一些内置的outputplugin已经打包好了。
每个output plugin都有一些不同的解析行为和输出格式
几个常见的outputplugin
test_decoding:这是一个outputplugin样例,相当于output plugin原始形态。官方文档说这是一个template,但是它仍然可以解析。这个output plugin是pg自带的,但需要在contrib中编译。
pgoutput:发布订阅模式的默认outputplugin。在发布订阅中,walsender进程使用该outputplugin逻辑解码wal日志。
decoder_raw:解析成sql文本格式。这个不是pg自带的,自行编译:https://github.com/michaelpq/pg_plugins/tree/main/decoder_raw
wal2json:这个outputplugin会将wal日志信息转化为json格式
有些其他的output plugin可参考:https://wiki.postgresql.org/wiki/Logical_Decoding_Plugins。有些国内也有厂商做了自己outputplugin
几个output plugin和逻辑复制插件的关系:
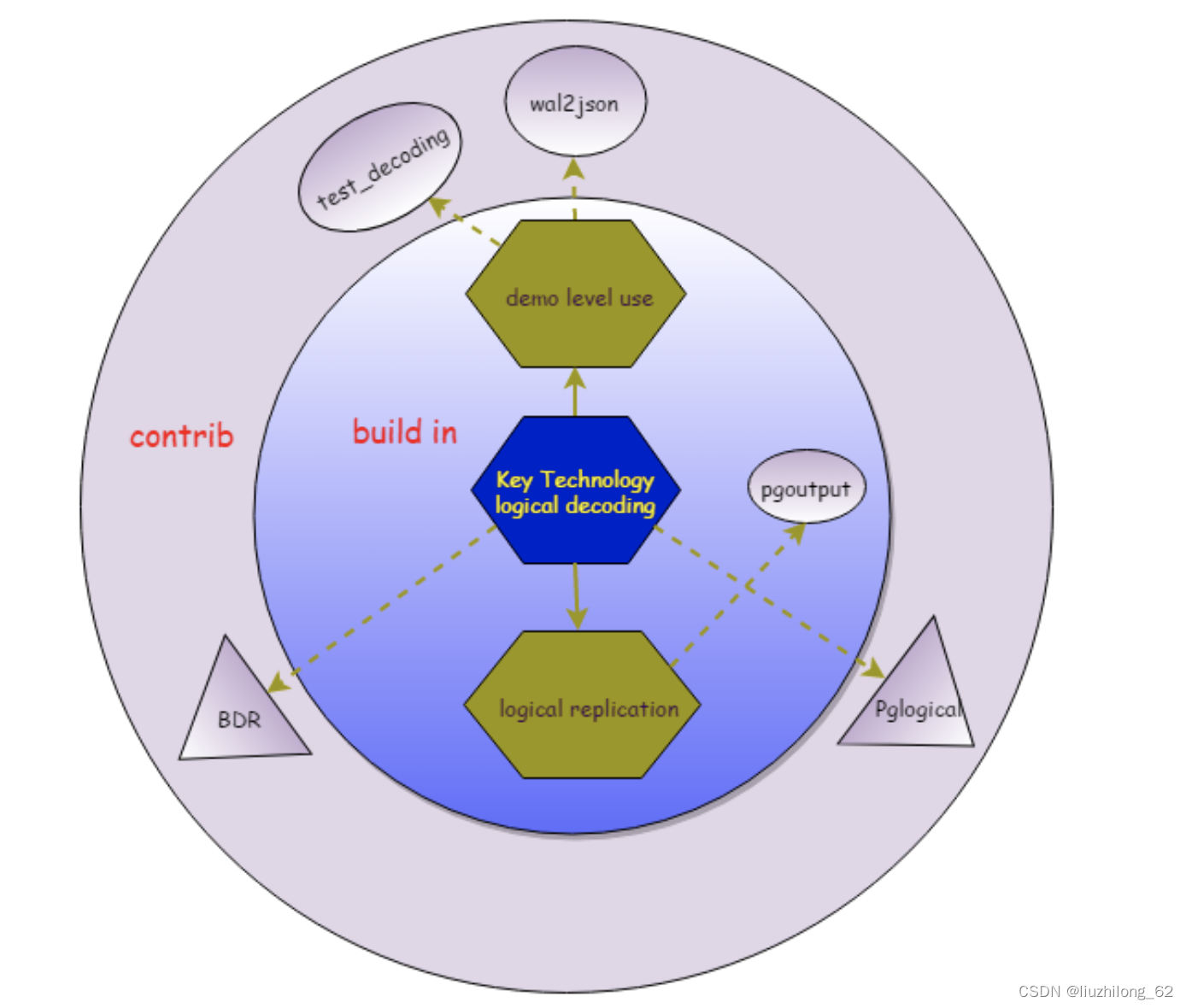
pgoutput、test_decoding、wa2json上面已经介绍了
pglogical在pg9.4是pglogical replication的前身
BDR是2ndQuadrant开发,支持双向复制、DDL同步,功能更强大,BDR3.0开始闭源
几个能手动接收解析数据的函数和工具
pg_logical_slot_get_changes()函数展示解析数据并消费掉;
pg_logical_slot_peek_changes()函数展示解析数据不会消费掉;
pg_recvlogical,pg自带的工具,能消费复制槽内的数据,相当于逻辑复制的下游。对应物理wal接收工具为 pg_receivewal
逻辑解析测试1:观察用2个不同的output plugin解析数据
--创建两个逻辑复制槽,分别使用logical_test和logical_raw
lzldb=# select pg_create_logical_replication_slot('logical_test','test_decoding');
pg_create_logical_replication_slot
------------------------------------
(logical_test,0/1756F50)
lzldb=# select pg_create_logical_replication_slot('logical_raw','decoder_raw');
pg_create_logical_replication_slot
------------------------------------
(logical_raw,0/1756F88)
--只创建上游,slot是f状态
lzldb=# select * from pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn | wal_status | safe_wal_size
--------------+---------------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+---------------------+------------+---------------
logical_test | test_decoding | logical | 16385 | lzldb | f | f | | | 558 | 0/1766878 | 0/17668B0 | reserved |
logical_raw | decoder_raw | logical | 16385 | lzldb | f | f | | | 557 | 0/1756F50 | 0/1756F88 | reserved |
--创建一张表
lzldb=# create table tdecoder222(a int,b varchar(10));
CREATE TABLE
--尝试获得这个ddl
lzldb=# SELECT * FROM pg_logical_slot_get_changes('logical_raw', NULL, NULL, 'include-xids', '0');
ERROR: option "include-xids" = "0" is unknown
CONTEXT: slot "logical_raw", output plugin "decoder_raw", in the startup callback
lzldb=# SELECT * FROM pg_logical_slot_get_changes('logical_test', NULL, NULL, 'include-xids', '0');
lsn | xid | data
-----------+-----+--------
0/17669C8 | 558 | BEGIN
0/1776778 | 558 | COMMIT
--能看出decoder_raw完全没有解析ddl,logical_test只是获取了ddl的事物,没有ddl语句本身,相当于没解析ddl
--插入一条数据
lzldb=# insert into tdecoder222 values(1,'lzl');
INSERT 0 1
lzldb=# select * from pg_logical_slot_peek_changes('logical_test',null,null);
lsn | xid | data
-----------+-----+---------------------------------------------------------------------------
0/1776890 | 560 | BEGIN 560
0/1776890 | 560 | table public.tdecoder222: INSERT: a[integer]:1 b[character varying]:'lzl'
0/1776900 | 560 | COMMIT 560
lzldb=# select * from pg_logical_slot_peek_changes('logical_raw',null,null);
lsn | xid | data
-----------+-----+----------------------------------------------------------
0/1776890 | 560 | INSERT INTO public.tdecoder222 (a, b) VALUES (1, 'lzl');
--test_decoding解析了事物
--decoder_raw把事务解析成了sql语句这个测试可以得出结论:
1.复制槽在f状态仍会解析,等待下游消费
2.每个output plugin都有一些不同的解析行为和输出格式
逻辑解析测试2:使用pg_recvlogical工具接收逻辑解析数据,模拟一个逻辑复制链路
--配置免密登陆
[pg@lzl ~]$ vi .pgpass
[pg@lzl ~]$ cat .pgpass
lzl:5410:lzldb:pg:pg
[pg@lzl ~]$ chmod 0600 .pgpass
--启动pg_recvlogical
[pg@lzl ~]$ pg_recvlogical -h lzl -p 5410 -d lzldb -U pg --slot=logical_raw --start -f recv.sql &
[pg@lzl ~]$ ps -ef|grep recv|grep -v grep
pg 7747 7355 0 21:40 pts/3 00:00:00 pg_recvlogical -h lzl -p 5410 -d lzldb -U pg --slot=logical_raw --start -f recv.sqllzldb=# insert into tdecoder222 values(2,'qwe');
INSERT 0 1
lzldb=# update tdecoder222 set b='asd' where a=2;
UPDATE 1
[pg@lzl ~]$ tail -2f recv.sql
INSERT INTO public.tdecoder222 (a, b) VALUES (2, 'qwe');
--update没有正确解析
--给表加主键
lzldb=# alter table tdecoder222 add primary key(a);
ALTER TABLE
lzldb=# insert into tdecoder222 values(100,'lzl1');
INSERT 0 1
lzldb=# insert into tdecoder222 values(200,'lzl2');
INSERT 0 1
lzldb=# update tdecoder222 set b='lzlupdate' where a=200;
UPDATE 1
[pg@lzl ~]$ tail -3f recv.sql
INSERT INTO public.tdecoder222 (a, b) VALUES (100, 'lzl1');
INSERT INTO public.tdecoder222 (a, b) VALUES (200, 'lzl2');
UPDATE public.tdecoder222 SET a = 200, b = 'lzlupdate' WHERE a = 200;--加了主键后update被decoder_raw正确解析
--没有主键不会正确解析,这跟replicaidentity复制标识相关,后面会介绍
逻辑复制的前置条件
1.参数
1.1基本的必要参数
- wal_level。重启生效,默认是replica。wal_level参数必须是logical。logical不是把wal改成逻辑的,它表示在支持物理复制(replica)的基础上增加逻辑解析所必要的信息。在pg9.6以后只有minimal、replica、logical,信息量依次递增。
- max_replication_slots。重启生效,在pg9.6版本以下默认值为0,pg10以上为10,10个一般都够了。与物理复制相同,逻辑复制一般也要用到复制槽。pg的备份、物理复制均可以占用到复制槽的数量。
1.2源端必要参数
- max_wal_senders。重启生效,默认10。sender进程数限制,发布端的sender传递解析后的日志。一般一个逻辑复制槽对应了一个sender和一个worker。这个跟物理复制类似,一个物理复制对应一个sender和一个receiver。
1.3目标端必要参数
- max_worker_processes。重启生效,默认8。工作进程数限制。并行进程(并行查询、并行统计信息收集等,这些并行进程由 max_parallel_workers限制)、逻辑复制工作进程(max_logical_replication_workers)和一些其他需要forkworker的程序均与该参数有关。应该设置为max_parallel_workers+逻辑复制应用端worker+其他后台worker。
- max_logical_replication_workers。重启生效,默认4。逻辑复制工作进程数,包括逻辑复制的应用工作进程和表同步工作进程。
- max_sync_workers_per_subscription。reload生效,默认2。逻辑同步新增表时同步工作进程,目前一张表只有一个并行。
- 以上三个参数是梯度式的max_sync_workers_per_subscription<max_logical_replication_workers<max_worker_processes。总之得有worker可用。
2 权限
- 复制用户的权限。逻辑复制的用户需要有replication权限。
ALTER ROLE <usename>WITH REPLICATION;
- hba访问限制,允许下游使用复制用户访问数据库
host lzldb user1 172.17.100.150/32 md5
- 对于发布订阅模式。需要database上的create权限或ssuperuser权限。
在创建发布时只有fortable至少需要带create权限的表owner,其余发布都必须要superuser
在创建订阅时必须要superuser。
grantcreate on database lzl1db to owner1; 或者
alter user replicate1 superuser;
- 另外复制过程中表的读或写权限也是必要的。
pg间的逻辑同步——发布与订阅
pg的内置逻辑复制基于发布订阅模型。发布与订阅模式不是解析成sql应用。
发布
- 发布者可以有多个发布,每个发布可以有多个表。
- 发布时可以指定
fortable 发布某些表,新增表需要显示添加ALTER PUBLICATION ADD TABLE。创建此发布至少是表的owner。
forall tables 发布database下的所有表,新增表自动发布。创建此发布必须是superuser
forall tables in schema 发布schema下的所有表,新增表自动发布。创建此发布必须是superuser。pg15开始支持
- 发布默认包含INSERT, UPDATE, DELETE, and TRUNCATE,也可以指定复制某些命令。不同步DDL。(官方文档原话。也就是说truncate在pg里面不算ddl,这个留坑后面再研究。truncate在mysql和oracle中是ddl)
- 只能发布基表;临时表、外部表、视图、序列等等都不能发布。分区表发布与pg版本和分区属性有关,pg15默认发布分区表所有分区
- publish_via_partition_root。pg13开始支持。该发布参数表示分区表使用分区进行过滤(fales,默认)还是用户父分区进行行过滤。如果设置为true,那么支持了异构分区表逻辑复制,比如分区表到普通表的复制。true时不能进行truncate复制。
订阅
- 一个订阅只有一个发布者,但可订阅发布者上的多个发布。
- 订阅者可以有多个订阅,每个订阅都会从一个复制槽中接收数据。
- 一个订阅对应一个复制槽,这个复制槽在发布端。
- 在创建或删除订阅时,默认自动在发布者创建或删除复制槽。
- 创建订阅必须要superuser
- DDL不会被同步,表必须是已建好的。
- 存量数据默认同步,存量数据通过copy的方式快照拷贝到订阅者
- 同步可以暂停和继续ALTER SUBSCRIPTION sub1 {ENABLE|DISABLE}
- 当发布新增表后,需要在订阅端refresh。alter subscription sub1 refresh publication
- 发布和订阅的表schema名、表名、字段名必须一致,字段类型可以不一致(只要能隐式转换成功),字段顺序可以不一致。
- 订阅还有些属性,比如二进制传输、流传输、同步提交、两阶段提交等
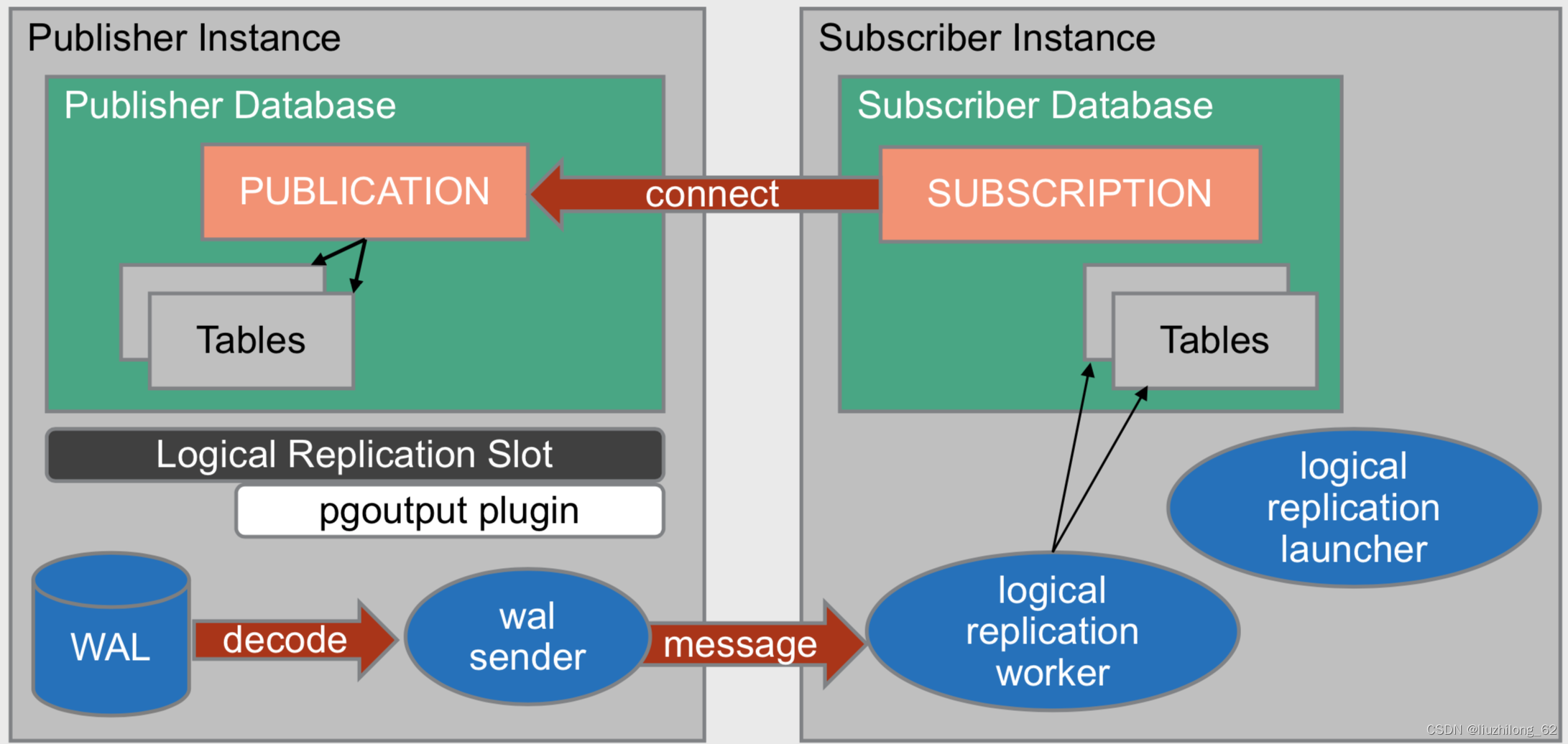
-
logicalreplication launcher是用来启动订阅端的worker进程的,只在启动时存在
/*------------------------------------------------------------------------- ... * IDENTIFICATION * src/backend/replication/logical/launcher.c ... * NOTES * This module contains the logical replication worker launcher which * uses the background worker infrastructure to start the logical * replication workers for every enabled subscription. *------------------------------------------------------------------------- */发布订阅相关视图
pg_publication; --查看发布。发布本身是无状态的,复制槽是有状态的,所以没有pg_stat_publication
pg_publication_tables --查看发布的表,简单明了
pg_publication_rel --查看发布的表,都是id
pg_stat_subscription --查看订阅状态,pid是worker进程的pid
pg_subscription --查看订阅
pg_subscription_rel --查看订阅表,没有pg_subscription_tables。另外该视图可以查看订阅下面各个表的同步情况,这是复制槽视图做不到的
\dRp list replication publications
\dRs list replication subscriptions
创建一个发布和订阅
用专门的复制用户replicate1,在库lzldb下创建一个发布和订阅,实现逻辑复制表trep1
角色主机ip端口库名schema表名复制用户版本发布节点172.17.100.1505410lzldbpublictrep1replicate1pg13订阅节点172.17.100.1505412lzlbdpublictrep1replicate1pg13创建发布
#修改postgres.conf,wal_level参数重启生效 wal_level=logical #修改pg_hba.conf文件,reload生效 host lzldb replicate1 172.17.100.150/32 md5 --创建复制用户并赋权 create user replicate1 with password 'replicate1'; alter user replicate1 with replication; grant create on database lzldb to replicate1; --创建要复制的表并授权给复制用户 \c lzldb replicate1 --如果复制用户不是表的owner,应该授权grantselect on trep1 to replicate1 create table trep1(a int primary key,b char(10)); insert into trep1 values(1,'abc') --创建发布,用superuser用户也可以 \c lzldb replicate1 create publication pub_lzl1 for table trep1; --查看发布。\dRp或pg_publication lzldb=# select * from pg_publication; oid | pubname | pubowner | puballtables | pubinsert | pubupdate | pubdelete | pubtruncate | pubviaroot -------+----------+----------+--------------+-----------+-----------+-----------+-------------+----------- 16400 | pub_lzl1 | 16392 | f | t | t | t | t | f创建订阅
--创建表定义 create table trep1(a int primary key,b char(10)); --用superuser用户创建订阅 CREATE SUBSCRIPTION sub_test CONNECTION 'host=172.17.100.150 port=5410 dbname=lzldb user=replicate1 password=replicate1' PUBLICATION pub_lzl1; lzlbd=# select * from pg_subscription; --查看订阅。\dRs或pg_subscription oid | subdbid | subname | subowner | subenabled | subconninfo | subslotname | subsynccommit | subpublications -------+---------+----------+----------+------------+--------------------------------------------------------------------------------+-------------+---------------+----------------- 16394 | 16384 | sub_test | 10 | t | host=172.17.100.150 port=5410 dbname=lzldb user=replicate1 password=replicate1 | sub_test | off | {pub_lzl1} lzlbd=# select * from trep1;--查看存量数据已同步 a | b ---+------------ 1 | abc发布订阅模式 测试1:truncate同步lzldb=# truncate table trep1; TRUNCATE TABLE lzldb=# select * from trep1; a | b ---+--- (0 rows) lzlbd=# select * from trep1; --发布订阅模式,truncate可以同步 a | b ---+--- (0 rows)发布订阅模式 测试2:新增表同步--在已有发布订阅下,新增一个表同步。lzldb是发布者,lzlbd是订阅者 lzldb=# create table tab_pk(a int,b varchar(10)); CREATE TABLE lzldb=# alter table tab_pk add primary key(a); ALTER TABLE lzldb=# alter publication pub_lzl1 add table tab_pk; ALTER PUBLICATION --发布端新增表后需要在订阅端执行refresh,refresh默认同步存量数据 lzlbd=# alter subscription sub_test refresh publication; ALTER SUBSCRIPTION lzlbd=# select * from pg_subscription_rel ; srsubid | srrelid | srsubstate | srsublsn ---------+---------+------------+----------- 16394 | 16389 | r | 0/15F2898 16394 | 16400 | d | --订阅的状态码: i = 初始化, d =正在复制数据, s = 已同步, r =准备好(普通复制) --此时表tab_pk数据并没有同步,因为订阅端复制用户缺少查询表的权限 lzldb=# grant select on tab_full to replicate1; GRANT lzlbd=# select * from pg_subscription_rel ; srsubid | srrelid | srsubstate | srsublsn ---------+---------+------------+----------- 16394 | 16389 | r | 0/15F2898 16394 | 16400 | r | 0/172D830 --订阅为ready状态,新增表同步完成
replica identity复制标识
复制标识写进wal日志以标识一行数据。无论是发布订阅还是第三方逻辑同步工具,都需要定位表中的行,以标识update、delete到底作用在下游的哪一条数据。
pg中可以设置4种复制标识模式。
- default(d) 非系统表的默认标识。表有主键就用主键,如果没有主键就是nothing
- index(i) 将一个非空唯一索引作为标识。必须是非空且唯一,这样才能标识一行。如果只是唯一,可以有多个空值。其实也可以显示指定主键为index模式。
- full(f) 将行的所有列作为标识。full模式会增大wal日志量
- nothing(n) 系统表的默认模式,没有标识,update、delete无法作用到下游
查看表的复制标识:
select relname,relreplident from pg_class where relname='tabname1';
当表的复制标识是i时,查看索引是否是复制标识
\d tabname
select rel.relname,idx.indisreplident from pg_index idx ,pg_class rel where idx.indexrelid=rel.oid and relname='idx_1';
修改表的复制标识:
ALTER TABLE tab1REPLICA IDENTITY { DEFAULT | USING INDEX index_name | FULL | NOTHING };
复制标识测试1:将一个没有主键的表的复制标识设置为非空唯一索引
lzldb=# create table tab_idx(a int,b varchar(10));
CREATE TABLE
lzldb=# select relname,relreplident from pg_class where relname='tab_idx';
relname | relreplident
---------+--------------
tab_idx | d
lzldb=# create unique index idx_1 on tab_idx(b);
CREATE INDEX
lzldb=# alter table tab_idx alter b set not null; --当做复制标识的索引必须是非空唯一索引
ALTER TABLE
lzldb=# select rel.relname,idx.indisreplident from pg_index idx ,pg_class rel where idx.indexrelid=rel.oid and relname='idx_1';
relname | indisreplident
---------+----------------
idx_1 | f
lzldb=# alter table tab_idx REPLICA IDENTITY using index idx_1; --修改表的复制标识
ALTER TABLE
lzldb=# select rel.relname,idx.indisreplident from pg_index idx ,pg_class rel where idx.indexrelid=rel.oid and relname='idx_1';
relname | indisreplident
---------+----------------
idx_1 | t
lzldb=# \d tab_idx --pg_index或者\d查看索引复制标识,\d只能查看显示修改的索引复制标识
Table "public.tab_idx"
Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------
a | integer | | |
b | character varying(10) | | not null |
Indexes:
"idx_1" UNIQUE, btree (b) REPLICA IDENTITY复制标识测试2:full模式,多条重复数据时,是否可以正常同步
--发布端执行一下命令
lzldb=# create table tab_full (a int,b varchar(10)); --添加一个无主键和非空索引的表同步
CREATE TABLE
lzldb=# insert into tab_full values(1,'abc'); --插入相同的5条数据
INSERT 0 1
lzldb=# grant select on tab_full to replicate1;
GRANT
lzldb=# alter publication tab_full add table tab_pk;
ALTER PUBLICATION
--
lzlbd=# alter subscription sub_test refresh publication;
ALTER SUBSCRIPTION
lzlbd=# select ctid,* from tab_full ;
ctid | a | b
-------+---+-----
(0,1) | 1 | abc
(0,2) | 1 | abc
(0,3) | 1 | abc
(0,4) | 1 | abc
(0,5) | 1 | abc
lzldb=# delete from tab_full where ctid='(0,2)';
ERROR: cannot delete from table "tab_full" because it does not have a replica identity and publishes deletes
HINT: To enable deleting from the table, set REPLICA IDENTITY using ALTER TABLE.
lzldb=# update tab_full set a=2 where ctid='(0,5)';
ERROR: cannot update table "tab_full" because it does not have a replica identity and publishes updates
HINT: To enable updating the table, set REPLICA IDENTITY using ALTER TABLE.
--当表的replica identity是d(default)时,没有主键就是nothing。nothing无法复制delete和update。
lzldb=# alter table tab_full replica identity full;
ALTER TABLE
lzldb=# delete from tab_full where ctid='(0,2)'; --复制标识设置为full后,删除成功
DELETE 1
lzlbd=# select ctid,* from tab_full ; --
ctid | a | b
-------+---+-----
(0,2) | 1 | abc
(0,3) | 1 | abc
(0,4) | 1 | abc
(0,5) | 1 | abc
lzldb=# update tab_full set a=2 where ctid='(0,5)';
UPDATE 1
lzldb=# select ctid,* from tab_full;
ctid | a | b
-------+---+-----
(0,1) | 1 | abc
(0,3) | 1 | abc
(0,4) | 1 | abc
(0,6) | 2 | abc
lzlbd=# select ctid,* from tab_full ;
ctid | a | b
-------+---+-----
(0,3) | 1 | abc
(0,4) | 1 | abc
(0,5) | 1 | abc
(0,6) | 2 | abc--这个例子可以证明3个点
--1.当复制标识为d(default)时,默认用主键,如果没有主键就是nothing
--2.nothing不能复制delete和update
--3.full时的重复数据也可以正常逻辑复制,虽然数据行的ctid不一样,但是也达到了复制目的
第三方同步软件
第三方同步软件已经有比较成熟的方案,而且使用比较多,比如ogg、dts、ktl等等
这些同步软件非常灵活,他们可以实现真正的异构同步,可以从pg库同步到不同的数据库或者kafka、大数据消费平台等等。
当然也可以从其他架构的数据平台同步到pg库里,比如如今场景比较多的oracle到pg的同步。
因为我们这里主要讨论pg数据库本身,当pg充当下游入库时,只是一些数据写入问题,问题非常少,不会有逻辑解析、复制槽等等问题,所以这一小章节不讨论pg作为异构同步下游的情况,只观察和总结pg作为上游往异构数据库同步的场景。这些第三方软件一般都利用了pg自身的逻辑解析,自行指定outputplugin并自动创建复制槽和复制链路,有些软件自动创建了订阅,而有些就没有订阅只有复制槽。
前面已经了解了逻辑解析、outputplugin、复制槽、replicaidentity、复制的前置条件等知识点,下面模拟一个pg到oracle的同步,直接将前置条件配置好开始同步。
创建ogg同步pg到oracle的同步
安装软件:
ogg for oracle:Oracle GoldenGate 21.3.0.0.0 for Oracle on Linux x86-64
ogg for pg :Oracle GoldenGate 21.3.0.0.0 for PostgreSQL on Linux x86-64
oracle :11.2.0.4
pg :13.10
安装步骤:
ogg的安装和部署就不介绍了,我也是参照文章的安装步骤一步步搭建,安装文章参考:https://liuzhilong.blog.csdn.net/article/details/129252320?spm=1001.2014.3001.5502
同步架构图:
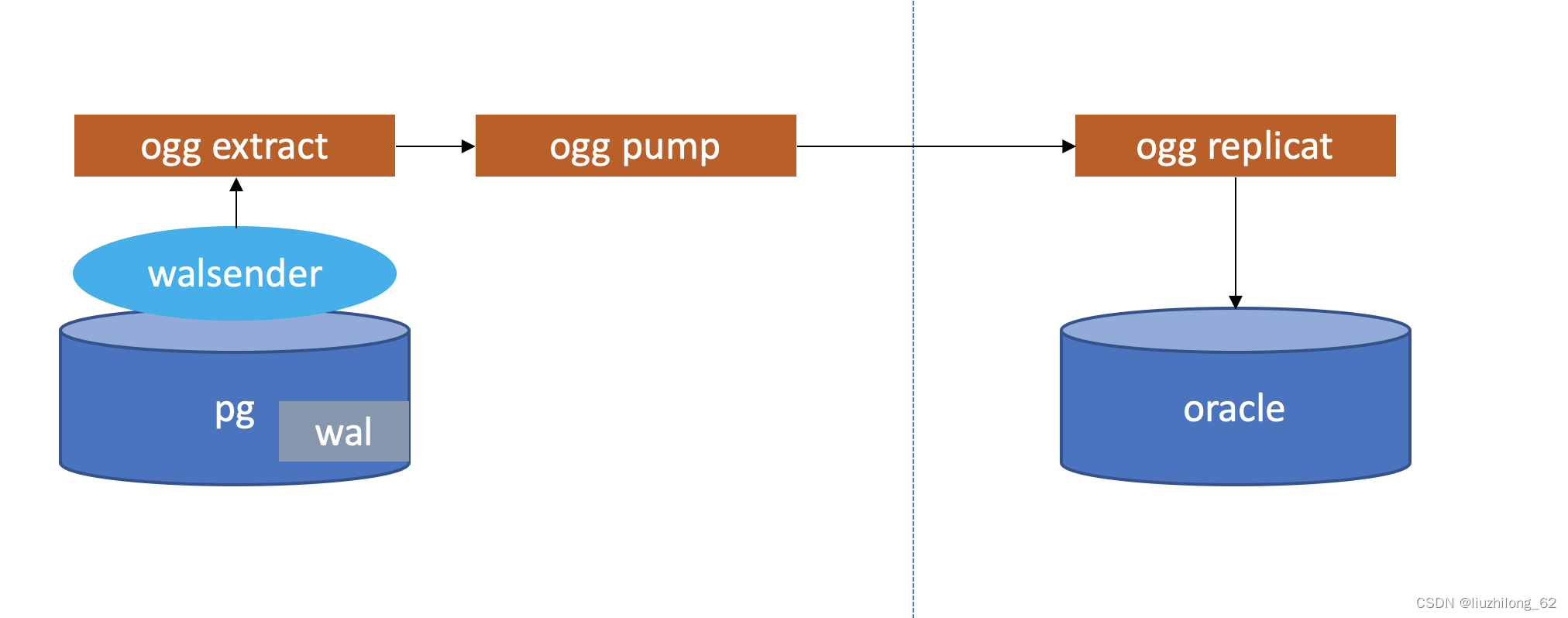
lzldb=# select * from pg_replication_slots where slot_name='ext_pg_5d4b1d39f7494f79';
-[ RECORD 1 ]-------+------------------------
slot_name | ext_pg_5d4b1d39f7494f79
plugin | test_decoding --ogg默认使用test-decoding
slot_type | logical
datoid | 16385
database | lzldb
temporary | f
active | t --只要ogg extract是running的,复制槽就是active状态
active_pid | 3509
xmin |
catalog_xmin | 591
restart_lsn | 0/17F3E38
confirmed_flush_lsn | 0/17F4020
wal_status | reserved
safe_wal_size |
select * from pg_stat_replication
-[ RECORD 2 ]----+------------------------------
pid | 3509
usesysid | 10
usename | pg
application_name |GoldenGateCapture
client_addr | 127.0.0.1
client_hostname |
client_port | 43665
backend_start | 2023-02-28 15:12:17.350469+08
backend_xmin |
state | streaming
sent_lsn | 0/17F4140
write_lsn | 0/17F4020
flush_lsn | 0/17F4020
replay_lsn |
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2023-02-28 16:39:44.986625+08
--replay_lsn没有值
--连lag都没有值逻辑复制监控
逻辑复制延迟监控有一个重要的手段是从复制软件看延迟。如果没有就只有从复制槽视图查看,复制槽视图的信息是比较多的,比如复制槽是否active就直接代表了复制链路是否在同步。
复制槽视图对于逻辑复制监控非常重要,发布订阅的一些额外监控前面已介绍过,这里着重介绍宽泛的逻辑复制的监控
pg_replication_slots
复制槽视图,每个复制槽的信息和一些复制槽状态。手工创建复制槽或者工具、订阅自动创建了复制槽,都会在这里展示
| slot_name | 复制槽名 |
| plugin | 逻辑复制槽output plugin的名字,如果是空那么就是物理复制槽 |
| slot_type | physical or logical |
| datoid | 逻辑复制槽的database id |
| database | 逻辑复制槽的database |
| temporary | 是否是临时复制槽。临时复制槽不会写到磁盘,会话结束临时复制槽自动删除。pg_basebackup默认使用的就是临时复制槽 |
| active | 复制槽状态 t or f。如果是f,需要尽快考虑把复制链路拉起或者删除,因为可能阻碍wal日志删除导致主库磁盘打满,这个跟参数max_slot_wal_keep_size相关 |
| active_pid | 使用复制槽的walsender pid。当复制槽状态是t的时候,才有walsender pid |
| xmin | 复制槽需要持有的最小事务id |
| catalog_xmin | 复制槽需要持有的catalog最小事务id |
| restart_lsn | slot需要保留的wal的位置lsn号,以确保下游消费端需要的wal不会被清理。max_slot_wal_keep_size 参数是slot需要保留wal的最大大小,超过这个值wal也能被删除,默认值-1表示不会清理。 这个值表示下游最新checkpoint消费后的lsn位置,可以帮助定位复制链路的延迟 |
| confirmed_flush_lsn | 逻辑复制下游确认接收的lsn。物理复制槽为空 |
| wal_status |
|
| safe_wal_size | 到在被删除WAL文件之前,可以写入的WAL字节数。如果这个值是负数或者是0,意味着已经超过了max_slot_wal_keep_size设置的值,只要做检查点,就会删除wal文件,这样使用插槽的备库就必须重建了 |
pg_stat_replication
与其说是复制状态,其实walsender状态更准确。该视图展示每个walsender的状态,一个walsender一条记录。
- 如果pg_replication_slots中有而pg_stat_replication中没有,那么说明walsender不在了,逻辑复制挂了,pg_replication_slots active应该是f
- 如果pg_replication_slots中没有而pg_stat_replication中有,那么说明这是个不带复制槽的物理复制
没有复制槽也可以有replicationstat信息,有walsender的复制槽也需看该视图,因为该视图比pg_replication_slots揭示更多复制状态信息
所以当复制槽没有挂时,pg_stat_replication对于监控逻辑复制延迟非常重要
| pid | walsender pid ,同pg_replication_slotsactive_pid |
| usesysid | 连入这个walsender的user oid,也就是下游使用的复制用户oid |
| usename | 连入这个walsender的usename |
| application_name | 下游的的应用程序名称。如果是订阅,那么就是订阅名。如果是pg_recvlogical就是pg_recvlogical |
| client_addr | 下游的IP,如果是空就是本地socket连接 |
| client_hostname | 下游的主机名 |
| client_port | 下游的端口,如果是-1就是本地socket连接 |
| backend_start | backend启动时间,也就是下游连入walsender的时间 |
| backend_xmin | hot_standby_feedback打开时,standby的xmin。这个明显是物理复制的 |
| state | 状态比较简单易懂
|
| sent_lsn | 发送的lsn |
| write_lsn | 下游write到磁盘的lsn |
| flush_lsn | 下游flush到磁盘的lsn |
| replay_lsn | 下游重放的lsn |
| write_lag | 主库flush wal和下游write之间的日志lag |
| flush_lag | 主库flush wal和下游flush之间的日志lag |
| replay_lag | 主库flush wal和下游relay之间的日志lag |
| sync_priority | 同步优先级 |
| sync_state | 同步状态 |
| reply_time | 上次答复时间 |
sent_lsn、write_lsn、flush_lsn、replay_lsn的关系
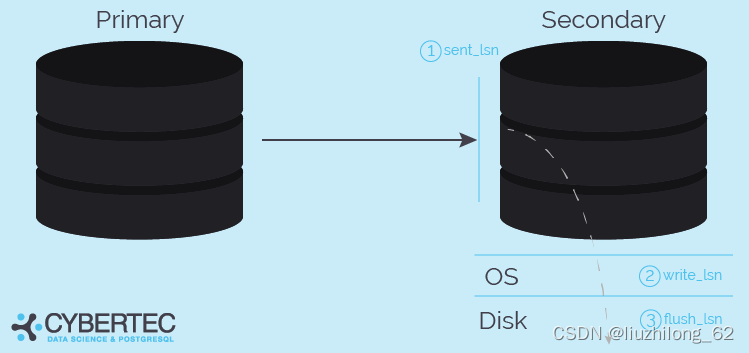
上面很好的展示了sent_lsn、write_lsn、flush_lsn的层级关系
这些监控指标看上去很像流复制的,对于逻辑复制来说sent_lsn、write_lsn、flush_lsn也一般都有值
但是在逻辑复制不清楚下游是什么东西的情况下,replay这个日志回放动作可能是没有的,所以逻辑复制可能没有replay_lsn
但是有一个东西是确认有效的,就是sent_lsn
看完pg_replication_slots和pg_stat_replication视图监控,发现都没有展示日志解析延迟,最多只能看到日志传输延迟
pg_stat_replication_slots
这个视图从pg14开始才有,这个视图专门监控逻辑复制槽状态,可以额外监控spill的状态。pg13只有查看pg_replslot目录。spill后面会介绍
逻辑复制槽的事务快照和pg_logical目录
复制槽所需的事物快照会持久化到磁盘,源码在snapbuild.c中
void
SnapBuildSerializationPoint(SnapBuild *builder, XLogRecPtr lsn)
{
if (builder->state < SNAPBUILD_CONSISTENT)
SnapBuildRestore(builder, lsn);
else
SnapBuildSerialize(builder, lsn);
} snap持久化有2种行为:一种是restore从磁盘加载到内存,一种是serialize从内存持久化到磁盘
事物快照持久化:
SnapBuildSerialize(SnapBuild *builder, XLogRecPtr lsn)
...
sprintf(path, "pg_logical/snapshots/%X-%X.snap",
(uint32) (lsn >> 32), (uint32) lsn);
...
else if (ret == 0)
{
/*
* somebody else has already serialized to this point, don't overwrite
* but remember location, so we don't need to read old data again.
*
* To be sure it has been synced to disk after the rename() from the
* tempfile filename to the real filename, we just repeat the fsync.
* That ought to be cheap because in most scenarios it should already
* be safely on disk.
*/
fsync_fname(path, false);
fsync_fname("pg_logical/snapshots", true);
builder->last_serialized_snapshot = lsn;
goto out;
}事物快照加载到内存:
SnapBuildRestore(SnapBuild *builder, XLogRecPtr lsn)
...
if (builder->state == SNAPBUILD_CONSISTENT)
return false;
sprintf(path, "pg_logical/snapshots/%X-%X.snap",
(uint32) (lsn >> 32), (uint32) lsn);
fd = OpenTransientFile(path, O_RDONLY | PG_BINARY);逻辑复制槽需要的事物在未提交以前,会将事物脏数据和未消费的数据存放在pg_logical/snapshots/ 下面。在提交数据或启动复制槽后交给reorderbuffer:或者清理复制槽后,数据被释放
我的环境有一个长时间未启用的slot,它的restart_lsn为0/1776858
postgres=# select slot_name,plugin,slot_type,database,active,restart_lsn from pg_replication_slots where slot_name='logical_test';
slot_name | plugin | slot_type | database | active | restart_lsn
--------------+---------------+-----------+----------+--------+-------------
logical_test | test_decoding | logical | lzldb | f | 0/1776858
pg_logical/snapshots/下最旧的snapshot就是它
[pg@lzl snapshots]$ ll
total 300
-rw------- 1 pg pg 144 Feb 23 20:410-1776858.snap
-rw------- 1 pg pg 144 Feb 23 20:44 0-1776900.snap
-rw------- 1 pg pg 144 Feb 23 20:45 0-1776938.snap
删除不要的复制槽
select pg_drop_replication_slot('logical_test');
等了几分钟snap被删除
[pg@lzl snapshots]$ ll 0-1776858.snap
ls: cannot access 0-1776858.snap: No such file or directory
逻辑解析工作内存和溢出到pg_replslot
logical_decoding_work_mem
pg13以前,逻辑解析的最多会在内存中保留4096条变更(max_changes_in_memory代码中写死),超过4096条变更,事务数据会写入磁盘
pg13引入参数logical_decoding_work_mem。逻辑解析使用的工作内存,所有walsender解析都会使用这个共享内存区。如果逻辑解析持有的数据大过该内存值,会写入磁盘。逻辑解析工作内存大小默认64m。
相关reorderbuffer和溢出
reorderbuffer.c中的描述
* This module gets handed individual pieces of transactions in the order
* toplevel transaction sized pieces. When a transaction is completely
* reassembled - signaled by reading the transaction commit record - it
* will then call the output plugin (cf. ReorderBufferCommit()) with the
* individual changes. The output plugins rely on snapshots built by
* snapbuild.c which hands them to us.当事务提交后,reorderbuffer能接收事务条目并排序,并把数据变更发给outputplugin输出。output plugin依赖于snapbuild.c构建的快照,快照交给reorderbuffer
/*
* Maximum number of changes kept in memory, per transaction. After that,
* changes are spooled to disk.
*
* The current value should be sufficient to decode the entire transaction
* without hitting disk in OLTP workloads, while starting to spool to disk in
* other workloads reasonably fast.
*
* At some point in the future it probably makes sense to have a more elaborate
* resource management here, but it's not entirely clear what that would look
* like.
*/
int logical_decoding_work_mem;
static const Size max_changes_in_memory = 4096; /* XXX for restore only */解析数据超过logical_decoding_work_mem后写入磁盘,max_changes_in_memory为写死的4096,现在只用作触发磁盘恢复restore。在pg12源码里面没有intlogical_decoding_work_mem,后面的serialization也是根据max_changes_in_memory来判断的。
pg13里面Disk serialization源码从2333行开始
当内存中的解析的数据大于logical_decoding_work_mem时,把最大的那个事务spill到磁盘
ReorderBufferLargestTXN(rb)找到那个最大的事务
ReorderBufferSerializeTXN(rb, txn);将这个事务持久化紧接着的代码就是ReorderBufferSerializeTXN()
/*
* Spill data of a large transaction (and its subtransactions) to disk.
*/
static void
ReorderBufferSerializeTXN(ReorderBuffer *rb, ReorderBufferTXN *txn)
{
dlist_iter subtxn_i;
dlist_mutable_iter change_i;
int fd = -1;
XLogSegNo curOpenSegNo = 0;
Size spilled = 0;
elog(DEBUG2, "spill %u changes in XID %u to disk",
(uint32) txn->nentries_mem, txn->xid);
/* do the same to all child TXs */
...在debug2级别,输出spill日志
/*
* Given a replication slot, transaction ID and segment number, fill in the
* corresponding spill file into 'path', which is a caller-owned buffer of size
* at least MAXPGPATH.
*/
static void
ReorderBufferSerializedPath(char *path, ReplicationSlot *slot, TransactionId xid,
XLogSegNo segno)
{
XLogRecPtr recptr;
XLogSegNoOffsetToRecPtr(segno, 0, wal_segment_size, recptr);
snprintf(path, MAXPGPATH, "pg_replslot/%s/xid-%u-lsn-%X-%X.spill",
NameStr(MyReplicationSlot->data.name),
xid,
(uint32) (recptr >> 32), (uint32) recptr);
}持久化到pg_replslot/复制槽名/xid-%u-lsn-%X-%X.spill
同样的,除了serialize,还有restore
/*
* Restore a number of changes spilled to disk back into memory.
*/
static Size
ReorderBufferRestoreChanges(ReorderBuffer *rb, ReorderBufferTXN *txn,
TXNEntryFile *file, XLogSegNo *segno)
{
Size restored = 0;
XLogSegNo last_segno;
...
while (restored < max_changes_in_memory && *segno <= last_segno)
{
int readBytes;
ReorderBufferDiskChange *ondisk;
...
/*
* Read the statically sized part of a change which has information
* about the total size. If we couldn't read a record, we're at the
* end of this file.
*/
ReorderBufferSerializeReserve(rb, sizeof(ReorderBufferDiskChange));
readBytes = FileRead(file->vfd, rb->outbuf,
sizeof(ReorderBufferDiskChange),
file->curOffset, WAIT_EVENT_REORDER_BUFFER_READ);
...
/*
* ok, read a full change from disk, now restore it into proper
* in-memory format
*/
ReorderBufferRestoreChange(rb, txn, rb->outbuf);
restored++;
}
return restored;
}ReorderBufferRestoreChanges()只是做了判断和循环(restored++),调用的是ReorderBufferRestoreChange()
static void
ReorderBufferRestoreChange(ReorderBuffer *rb, ReorderBufferTXN *txn,
char *data)
{
...
/*
* Update memory accounting for the restored change. We need to do this
* although we don't check the memory limit when restoring the changes in
* this branch (we only do that when initially queueing the changes after
* decoding), because we will release the changes later, and that will
* update the accounting too (subtracting the size from the counters). And
* we don't want to underflow there.
*/
ReorderBufferChangeMemoryUpdate(rb, change, true,
ReorderBufferChangeSize(change));
}看了眼ReorderBufferRestoreChanges(),它的while循环判断是restored < max_changes_in_memory,而restored的初始值为0,它会循环执行4096次。ReorderBufferRestoreChange中有段注释说明了,虽然restore不是根据memorylimit来判断的,但是仍要更新内存使用量,以防下溢。也就是说我才retore上来就别再套娃spill下去了
(感觉这有点怪,明显以memorylimit来判断更好,而不是写死restore循环次数)
根据源码解读逻辑解析过程:
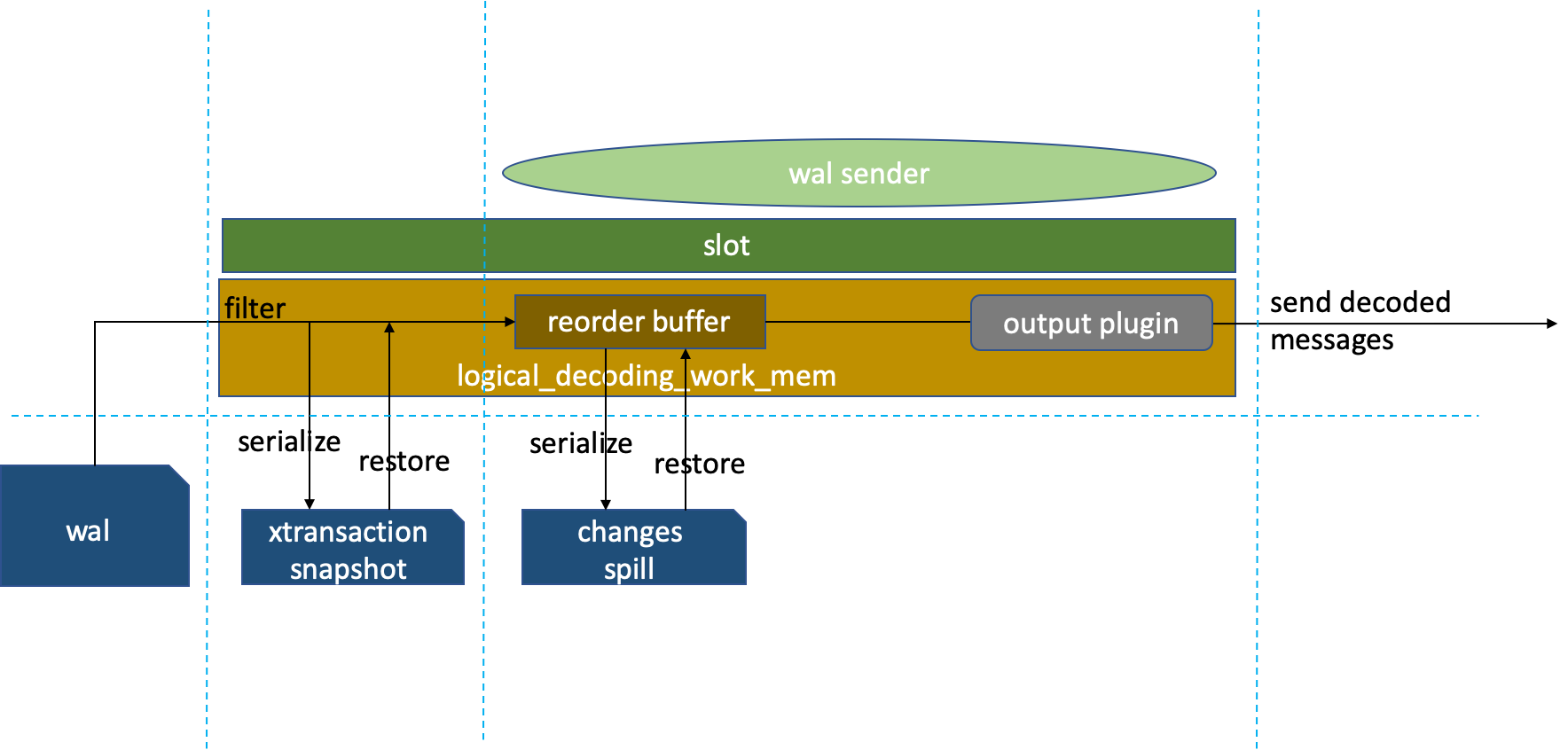
wal日志经过过滤,因复制槽处于非活动状态或事物未提交,将过滤后的事物持久化pg_logical/snapshots/%restart_lsn.snap,复制槽重新启动后或事物提交后,将磁盘上的事物snap读到内存发送给reorderbuffer以事物的执行顺序排序。如果逻辑解析数据将logical_decoding_work_mem内存区打满,变更条目会将最大的事物持久化到pg_replslot/复制槽名/xid-%u-lsn-%X-%X.spill,将其他的在内存中的事物发送给outputplugin转化输出格式,最后把解码后的信息发送给下游。
其实可以看出来,长事物和大事物可以将整个逻辑复制链路搞的很慢,这些事务可能要额外2次写入磁盘和读到内存
总结
- 逻辑复制通过复制槽管理,一个复制槽一个walsender进程,一个outputplugin
- output plugin决定了逻辑解析后的数据输出形态,在创建复制槽时指定
- 复制标识replicaidentity建议优先:主键->非空唯一索引->full
- 发布订阅模式是pg内置的逻辑复制,默认使用pgoutput。发布可以单独使用
- 发布端进程是walsender,订阅端进程是worker。需要关注各自进程的参数
- 逻辑复制第三方软件较多,他们一般都使用pg逻辑解析这套体系
- 监控复制链路需要关注pg_replication_slots,pg_stat_replication
- pg_logical目录会存放事务的snap,等待事务提交后解析
- pg_replslot目录会存放超过logical_decoding_work_mem的事物信息,称为spill
参考资料
书:《postgreSQL实战》
官方文档:
PostgreSQL: Documentation: 15: Chapter 49. Logical Decoding
PostgreSQL: Documentation: 15: 49.1. Logical Decoding Examples
PostgreSQL: Documentation: 15: pg_recvlogical
PostgreSQL: Documentation: 14: 52.81. pg_replication_slots
PostgreSQL: Documentation: 13: 19.6. Replication
PostgreSQL: Documentation: 13: 48.6. Logical Decoding Output Plugins
PostgreSQL: Documentation: 15: 31.1. Publication
PostgreSQL: Documentation: 15: 31.2. Subscription
PostgreSQL: Documentation: 15: CREATE PUBLICATION
超推荐的资料:
https://www.pgconf.asia/JA/2017/wp-content/uploads/sites/2/2017/12/D2-A7-EN.pdf
Logical replication internals | Select * from Adrien
An Overview of Logical Replication in PostgreSQL - Highgo Software Inc.
从实际案例聊聊逻辑解码
折磨许久的逻辑解码异常
Monitoring replication: pg_stat_replication - CYBERTEC
其他资料:
https://zhuanlan.zhihu.com/p/311496301
A Guide to PostgreSQL Change Data Capture - DZone
Change data capture in Postgres: How to use logical decoding and wal2json - Microsoft Community Hub
PgSQL · PostgreSQL 逻辑流复制技术的秘密 · 数据库内核月报 · 看云
剖析postgresql逻辑复制原理_postgresql 逻辑复制_麒思妙想的博客-CSDN博客
http://pigsty.cc/zh/blog/2021/03/03/postgres逻辑复制详解/
Logical replication and logical decoding - Azure Database for PostgreSQL - Flexible Server | Microsoft Learn