本篇总结的是Java基础知识相关的面试题,后续也会更新其他相关内容
文章目录
- 1、== 和 equals 的区别是什么?
- 2、你重写过 hashcode 和 equals 吗,为什么重写equals时必须重写hashCode方法?
- 3、为什么Java中只有值传递?
- 4、BIO、NIO、AIO 有什么区别?
- 5、什么是反射机制?反射机制的应用场景有哪些?
- 6、String有哪些特性?
- 7、String和StringBuffer、StringBuilder的区别是什么?String 为什么是不可变的?
- 8、集合和数组的区别是什么?
- 9、List,Set,Map三者的区别?
- 10、在使用 HashMap 的时候,用 String 做 key 有什么好处?
1、== 和 equals 的区别是什么?
答:
- ==:它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型比较的是值,引用数据类型比较的是内存地址)
- equals:它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况1:类没有覆盖equals() 方法。则通过 equals() 比较该类的两个对象时, 等价于通过“==”比较这两个对象。
- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来比较两个对象的内容是否相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
String中的equals方法是被重写过的,因为object的equals方法是比较的对象的内存地址,而String的equals方法比较的是对象的值。
当创建String类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个String对象。
2、你重写过 hashcode 和 equals 吗,为什么重写equals时必须重写hashCode方法?
答:如果我们只重写了equals方法没有重写hashcode方法的时候,就可能会导致两个对象通过equals方法比较之后判断相等,而两个对象的hashcode不同,因为它们的引用地址是不同的。
但是这时候就违背了hashcode 的规则:两个对象相等其 hash 值一定要相等,这样就会导致我们在使用hashcode计算存储地址的时候,两个相同的对象却存储在不同的位置,这显然是不合理的。所以我们在重写equals时,必须要重写hashCode方法。
如下:
public class Main {
public static void main(String[] args) {
// 对象 1
Persion p1 = new Persion();
p1.setName("Java");
p1.setAge(18);
// 对象 2
Persion p2 = new Persion();
p2.setName("Java");
p2.setAge(18);
// 创建 Set 对象
Set<Persion> set = new HashSet<Persion>();
set.add(p1);
set.add(p2);
// 打印 Set 中的所有数据
set.forEach(p -> {
System.out.println(p);
});
}
}
class Persion {
private String name;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true; // 引用相等返回 true
// 如果等于 null,或者对象类型不同返回 false
if (o == null || getClass() != o.getClass()) return false;
// 强转为自定义 Persion 类型
Persion persion = (Persion) o;
// 如果 age 和 name 都相等,就返回 true
return age == persion.age &&
Objects.equals(name, persion.name);
}
@Override
public int hashCode() {
// 对比 name 和 age 是否相等
return Objects.hash(name, age);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Persion{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
如果你还不理解可以看这篇:文章
3、为什么Java中只有值传递?
答:当方法参数是基本数据类型时,我们进行参数传递的时候就是将这个基本数据类型复制一份然后作为参数传递。当方法参数是引用类型时,我们进行参数传递的时候就是将这个引用复制一份然后作为参数传递。
4、BIO、NIO、AIO 有什么区别?
答:
- BIO:
Block IO同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。 - NIO:
Non IO同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过
Channel(通道)通讯,实现了多路复用。 - AIO:
Asynchronous IO是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO
,异步 IO 的操作基于事件和回调机制。
5、什么是反射机制?反射机制的应用场景有哪些?
答:JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
- 静态编译:在编译时确定类型,绑定对象
- 动态编译:在运行时确定类型,绑定对象
反射机制优缺点:
优点: 运行期类型的判断,动态加载类,提高代码灵活度。
缺点: 性能瓶颈,反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的java代码要慢很多。
反射机制的应用场景:
- ①我们在使用JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序;
- ②Spring框架也用到很多反射机制, 经典的就是xml的配置模式。Spring 通过 XML 配置模式装载 Bean
的过程:- 将程序内所有 XML 或 Properties 配置文件加载入内存中;
- Java类里面解析xml或properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息;
- 使用反射机制,根据这个字符串获得某个类的Class实例;
- 动态配置实例的属性;
6、String有哪些特性?
答:
- 不变性:String 是只读字符串,是一个典型的 immutable 对象,**对它进行任何操作,其实都是创
建一个新的对象,再把引用指向该对象。**不变模式的主要作用在于当一个对象需要被多线程共享并
频繁访问时,可以保证数据的一致性。 - 常量池优化:String 对象创建之后,会在字符串常量池中进行缓存,如果下次创建同样的对象时,
会直接返回缓存的引用。 - final:使用 final 来定义 String 类,表示 String 类不能被继承,提高了系统的安全性。
7、String和StringBuffer、StringBuilder的区别是什么?String 为什么是不可变的?
答:我们分别从可变性、线程安全性和性能三个方面来讲:
可变性:
- String类中使用字符数组保存字符串,
private final char value[],但是使用了final关键字来修饰,所以 string对象是不可变的。 - StringBuilder类时继承自
AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串,char[] value,StringBuilder对象都是可变的。 - StringBuffer类时继承自
AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串,char[] value,StringBuffer对象都是可变的。
线程安全性:
- String中的对象是不可变的,也就可以理解为常量,线程安全。
- StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。
- StringBuilder并没有对方法进行加同步锁,所以是非线程安全的。
性能:
- String类型:每次对String 类型进行改变的时候,都会生成一个新的String对象,然后将指针指向新的String 对象。
- StringBuffer类型:每次都会对StringBuffer对象本身进行操作,而不是生成新的对象并改变对象引用,所以性能强于String类型。
- StringBuilder:StringBuilder类型与StringBuffer类型相似,但是由于StringBuilder没有对方法加锁,所以性能强于StringBuffer。
使用场景选择:
- String :要操作少量的数据可以选择String;
- StringBuilder:单线程操作字符串缓冲区下操作大量数据;
- StringBuffer:多线程操作字符串缓冲区下操作大量数据;
8、集合和数组的区别是什么?
答:
- 数组是固定长度的;集合可变长度的。
- 数组可以存储基本数据类型,也可以存储引用数据类型;集合只能存储引用数据类型。
- 数组存储的元素必须是同一个数据类型;集合存储的对象可以是不同数据类型。
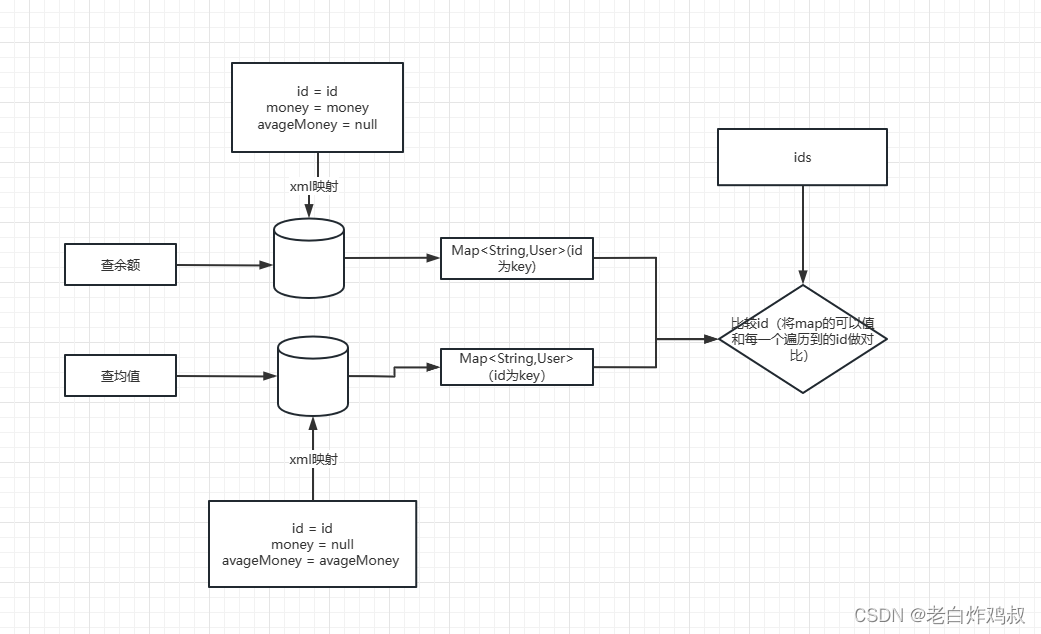
9、List,Set,Map三者的区别?
答:Java 容器分为 Collection 和 Map 两大类,Collection集合的子接口有Set、 List、Queue三种子接口。
我们比较常用的是Set、List,Map接口不是 collection的子接口。
如下图:
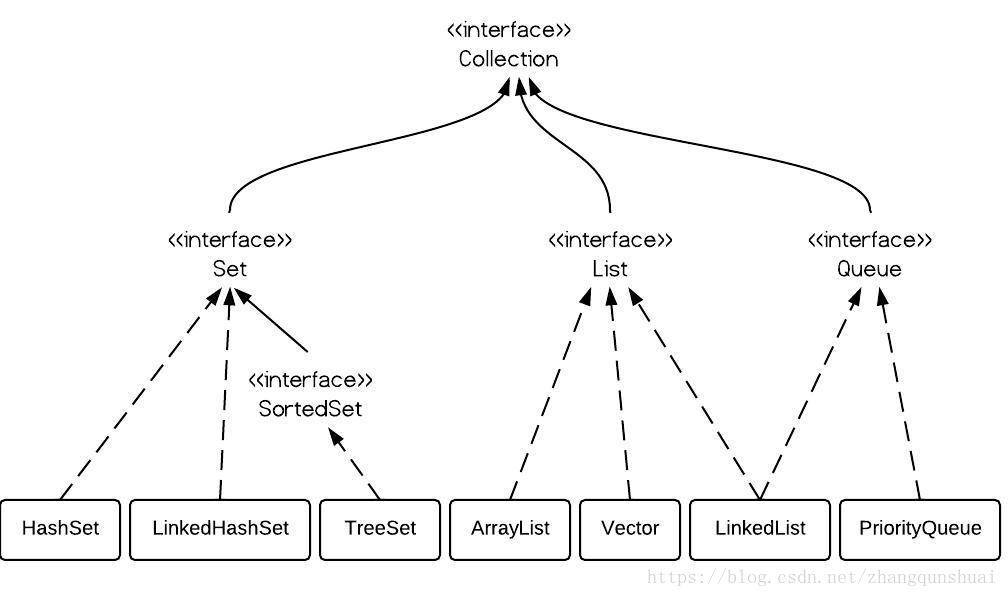
图片来源:Java集合中List,Set以及Map等集合体系详解(史上最全)
Collection集合主要有List和Set两大接口:
- List:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个
null元素,元素都有索引。 - Set:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素, 只允许存入一个
null元素,必须保证元素唯一性。 - Map是一个键值对集合,存储键、值和之间的映射。 Key无序,唯一;value 不要求有序,允许重复。Map没有继承于Collection接口,从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
List接口常用的实现类有
ArrayList、LinkedList和Vector。
Set接口常用的实现类有HashSet、LinkedHashSet以及TreeSet。
Map接口常用的实现类:HashMap、TreeMap、HashTable、LinkedHashMap、ConcurrentHashMap。
10、在使用 HashMap 的时候,用 String 做 key 有什么好处?
答:HashMap 内部实现是通过 key 的 hashcode 来确定 value 的存储位置,因为字符串是不可变的,所以
当创建字符串时,它的 hashcode 被缓存下来,不需要再次计算它的hashcode,所以相比于其他对象更快。