文章目录
- 什么是浮点数
- 浮点数表示数字
- 浮点数的二进制表示
- 浮点数的「IEEE754标准」二进制表示
- 背景
- 特殊约定
- 示例
- 浮点数为什么有精度损失
- 浮点数的范围和精度有多大
- 参考资料
用定点数表示数字时,会约定小数点的位置固定不变,整数部分和小数部分分别转换为二进制,就是定点数的结果。
但用定点数表示小数时,存在数值范围、精度范围有限的缺点,所以一般用「浮点数」来表示小数。
什么是浮点数
浮点数,是用科学计数法表示的,而这种方式其「小数点的位置是漂浮不定的」,故命名为浮点数。如下例:
25.125 = 0.25125 * 10 ^ 2
25.125 = 2.5125 * 10 ^ 1
25.125 = 25.125 * 10 ^ 0
25.125 = 251.25 * 10 ^ -1
25.125 = 2512.5 * 10 ^ -2
25.125 = 25125.0 * 10 ^ -3
25.125 = 251250 * 10 ^ -4
而同样的规则,二进制数也可以用科学计数法表示,将基数 10 换成 2 即可。
浮点数表示数字
浮点数用科学计数法表示数字的格式如下:
V = ( − 1 ) S ∗ M ∗ R E V = (-1)^S * M * R^E V=(−1)S∗M∗RE
如果要在计算机中,用浮点数表示一个数字,只需要确认这几个变量即可。其中各变量含义如下:
- S:符号位,0 表示正数,1 表示负数
- M:尾数,用小数表示,例如 3.254 ∗ 1 0 − 2 3.254 * 10^{-2} 3.254∗10−2 中 3.254 3.254 3.254 就是尾数
- R:基数,表示十进制数则 R 就是 10,表示二进制数则 R 就是 2
- E:指数,用整数表示,例如 3.254 ∗ 1 0 − 2 3.254 * 10^{-2} 3.254∗10−2 中 − 2 -2 −2 就是指数
如果要用 32bit 表示一个浮点数,则只要把以上变量,填充到这些 bit 上就可以了:
假如我们定义如下填充这些 bit 的规则,图示如下:
- 符号位 S 占 1 bit
- 指数 E 占 10 bit
- 尾数 M 占 21 bit
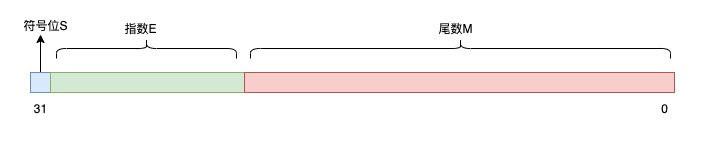
浮点数的二进制表示
按此规则,将十进制数 25.125 转换为浮点数,过程如下图(D 表示十进制,B 表示二进制):
- 整数部分:25(D) = 11011(B)
- 小数部分:0.125 = 0.001(B)
- 用二进制的科学计数法表示:25.125(D) = 11001.001(B) = 1.1001001 * 2^4(B)

所以将上述 S、M、R、E 填充到 32 bit 中,则如下图即为「浮点数的二进制表示」:
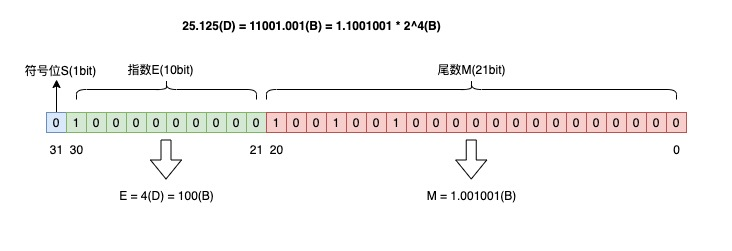
浮点数的「IEEE754标准」二进制表示
背景
从上例可知,浮点数的格式会因为定义规则的不同,而导致范围和精度都不同:
- 指数位约多,则尾数位越少:则其表示的范围越大,但精度也越差。
- 指数位越少,则尾数位越多:则其表示的范围越小,但精度也会变好。
而早期各计算机厂商(如 IBM、微软)都会定义自己的一套浮点数规则,就会导致同一个程序在不同厂商的计算机下做浮点数运算时,必须「先转换」成此厂商规定的浮点数格式,才能计算,则加重了计算成本。
因此业界迫切需要统一的浮点数标准,1985年 IEEE 组织提出了 「IEEE754 浮点数标准」,其统一定义了浮点数的表示形式:
- 单精度浮点数 float:32 位,符号位 S 占 1 bit,指数 E 占 8 bit,尾数 M 占 23 bit
- 双精度浮点数 float:64 位,符号位 S 占 1 bit,指数 E 占 11 bit,尾数 M 占 52 bit
特殊约定
为了让其表示范围、精度最大化,还厎指数和尾数做了如下规定:
- 因为尾数 M 的第一位总是 1(因为 1 <= M < 2),因此这个 1 可以省略不写,它是个隐藏位,这样单精度 23 位尾数可以表示了 24 位有效数字,双精度 52 位尾数可以表示 53 位有效数字
- 因为指数 E 是个「无符号」整数,表示 float 时,一共占 8 bit,所以它的取值范围为 0 ~ 255。但因为指数可以是负的,所以规定在存入 E 时在它原本的值「加上一个中间数 127」,这样 E 的取值范围为 -127 ~ 128。表示 double 时,一共占 11 bit,存入 E 时加上中间数 1023,这样取值范围为 -1023 ~ 1024。
除了规定尾数和指数位,还做了以下规定,如下图:
- 指数 E 非全 0 且非全 1:规格化数字,按上面的规则正常计算
- 指数 E 全 0,尾数非 0:非规格化数,尾数隐藏位不再是 1,而是 0(M = 0.xxxxx),这样可以表示 0 和很小的数
- 指数 E 全 1,尾数全 0:正无穷大/负无穷大(正负取决于 S 符号位)
- 指数 E 全 1,尾数非 0:NaN(Not a Number)

示例
有了这个统一的浮点数标准,我们再把 25.125 转换为标准的 float 浮点数:
- 整数部分:25(D) = 11001(B)
- 小数部分:0.125(D) = 0.001(B)
- 用二进制科学计数法表示:25.125(D) = 11001.001(B) = 1.1001001 * 2^4(B)
所以 S = 0,尾数 M = 1.001001 = 001001(去掉1,隐藏位),指数 E = 4 + 127(中间数) = 135(D) = 10000111(B)。填充到 32 bit 中,如下:
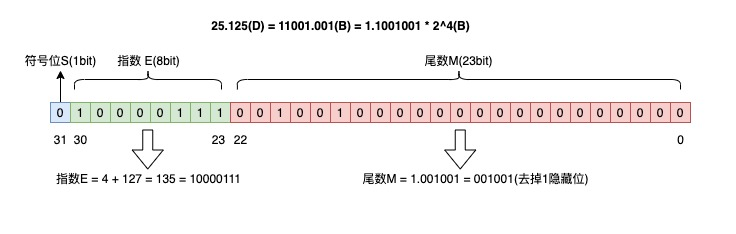
这就是标准 32 位浮点数的结果。
如果用 double 表示,和这个规则类似,指数位 E 用 11 bit 填充,尾数位 M 用 52 bit 填充即可。
浮点数为什么有精度损失
经常听到的浮点数会有精度损失的情况是怎么回事?
如果我们现在想用浮点数表示 0.2,它的结果会是多少呢?
0.2 转换为二进制数的过程为,不断乘以 2,直到不存在小数为止,在这个计算过程中,得到的整数部分从上到下排列就是二进制的结果。
0.2 * 2 = 0.4 -> 0
0.4 * 2 = 0.8 -> 0
0.8 * 2 = 1.6 -> 1
0.6 * 2 = 1.2 -> 1
0.2 * 2 = 0.4 -> 0(发生循环)
...
所以 0.2(D) = 0.00110…(B)。
因为十进制的 0.2 无法精确转换成二进制小数,而计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。
浮点数的范围和精度有多大
以单精度浮点数 float 为例,它能表示的最大二进制数为 +1.1.11111…1 * 2^127(小数点后23个1),而二进制 1.11111…1 ≈ 2,所以 float 能表示的最大数为 2^128 = 3.4 * 10^38,即 float 的表示范围为:-3.4 * 10^38 ~ 3.4 * 10 ^38。
它能表示的精度有多小呢?
float 能表示的最小二进制数为 0.0000….1(小数点后22个0,1个1),用十进制数表示就是 1/2^23。
用同样的方法可以算出,double 能表示的最大二进制数为 +1.111…111(小数点后52个1) * 2^1023 ≈ 2^1024 = 1.79 * 10^308,所以 double 能表示范围为:-1.79 * 10^308 ~ +1.79 * 10^308。
double 的最小精度为:0.0000…1(51个0,1个1),用十进制表示就是 1/2^52。
从这里可以看出,虽然浮点数的范围和精度也有限,但其范围和精度都已非常之大,所以在计算机中,对于小数的表示我们通常会使用浮点数来存储。
参考资料
浮点数的二进制表示、IEEE754标准
浮点数的二进制转换示例




![【项目设计】高并发内存池 (四)[pagecache实现]](https://img-blog.csdnimg.cn/ca656d66a1484fd89961465b5276ba34.png)